9.8 KiB
| comments | description |
|---|---|
| true | Deploy YOLOv5 on NVIDIA Jetson using TensorRT and DeepStream SDK for high performance inference. Step-by-step guide with code snippets. |
Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
📚 This guide explains how to deploy a trained model into NVIDIA Jetson Platform and perform inference using TensorRT and DeepStream SDK. Here we use TensorRT to maximize the inference performance on the Jetson platform.
UPDATED 18 November 2022.
Hardware Verification
We have tested and verified this guide on the following Jetson devices
- Seeed reComputer J1010 built with Jetson Nano module
- Seeed reComputer J2021 built with Jetson Xavier NX module
Before You Start
Make sure you have properly installed JetPack SDK with all the SDK Components and DeepStream SDK on the Jetson device as this includes CUDA, TensorRT and DeepStream SDK which are needed for this guide.
JetPack SDK provides a full development environment for hardware-accelerated AI-at-the-edge development. All Jetson modules and developer kits are supported by JetPack SDK.
There are two major installation methods including,
- SD Card Image Method
- NVIDIA SDK Manager Method
You can find a very detailed installation guide from NVIDIA official website. You can also find guides corresponding to the above-mentioned reComputer J1010 and reComputer J2021.
Install Necessary Packages
- Step 1. Access the terminal of Jetson device, install pip and upgrade it
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
- Step 2. Clone the following repo
git clone https://github.com/ultralytics/yolov5
- Step 3. Open requirements.txt
cd yolov5
vi requirements.txt
- Step 5. Edit the following lines. Here you need to press i first to enter editing mode. Press ESC, then type :wq to save and quit
# torch>=1.7.0
# torchvision>=0.8.1
Note: torch and torchvision are excluded for now because they will be installed later.
- Step 6. install the below dependency
sudo apt install -y libfreetype6-dev
- Step 7. Install the necessary packages
pip3 install -r requirements.txt
Install PyTorch and Torchvision
We cannot install PyTorch and Torchvision from pip because they are not compatible to run on Jetson platform which is based on ARM aarch64 architecture. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source.
Visit this page to access all the PyTorch and Torchvision links.
Here are some of the versions supported by JetPack 4.6 and above.
PyTorch v1.10.0
Supported by JetPack 4.4 (L4T R32.4.3) / JetPack 4.4.1 (L4T R32.4.4) / JetPack 4.5 (L4T R32.5.0) / JetPack 4.5.1 (L4T R32.5.1) / JetPack 4.6 (L4T R32.6.1) with Python 3.6
file_name: torch-1.10.0-cp36-cp36m-linux_aarch64.whl URL: https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl
PyTorch v1.12.0
Supported by JetPack 5.0 (L4T R34.1.0) / JetPack 5.0.1 (L4T R34.1.1) / JetPack 5.0.2 (L4T R35.1.0) with Python 3.8
file_name: torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl URL: https://developer.download.nvidia.com/compute/redist/jp/v50/pytorch/torch-1.12.0a0+2c916ef.nv22.3-cp38-cp38-linux_aarch64.whl
- Step 1. Install torch according to your JetPack version in the following format
wget <URL> -O <file_name>
pip3 install <file_name>
For example, here we are running JP4.6.1, and therefore we choose PyTorch v1.10.0
cd ~
sudo apt-get install -y libopenblas-base libopenmpi-dev
wget https://nvidia.box.com/shared/static/fjtbno0vpo676a25cgvuqc1wty0fkkg6.whl -O torch-1.10.0-cp36-cp36m-linux_aarch64.whl
pip3 install torch-1.10.0-cp36-cp36m-linux_aarch64.whl
- Step 2. Install torchvision depending on the version of PyTorch that you have installed. For example, we chose PyTorch v1.10.0, which means, we need to choose Torchvision v0.11.1
sudo apt install -y libjpeg-dev zlib1g-dev
git clone --branch v0.11.1 https://github.com/pytorch/vision torchvision
cd torchvision
sudo python3 setup.py install
Here a list of the corresponding torchvision version that you need to install according to the PyTorch version:
- PyTorch v1.10 - torchvision v0.11.1
- PyTorch v1.12 - torchvision v0.13.0
DeepStream Configuration for YOLOv5
- Step 1. Clone the following repo
cd ~
git clone https://github.com/marcoslucianops/DeepStream-Yolo
- Step 2. Copy gen_wts_yoloV5.py from DeepStream-Yolo/utils into yolov5 directory
cp DeepStream-Yolo/utils/gen_wts_yoloV5.py yolov5
- Step 3. Inside the yolov5 repo, download pt file from YOLOv5 releases (example for YOLOv5s 6.1)
cd yolov5
wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
- Step 4. Generate the cfg and wts files
python3 gen_wts_yoloV5.py -w yolov5s.pt
Note: To change the inference size (default: 640)
-s SIZE
--size SIZE
-s HEIGHT WIDTH
--size HEIGHT WIDTH
Example for 1280:
-s 1280
or
-s 1280 1280
- Step 5. Copy the generated cfg and wts files into the DeepStream-Yolo folder
cp yolov5s.cfg ~/DeepStream-Yolo
cp yolov5s.wts ~/DeepStream-Yolo
- Step 6. Open the DeepStream-Yolo folder and compile the library
cd ~/DeepStream-Yolo
CUDA_VER=11.4 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
CUDA_VER=10.2 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
- Step 7. Edit the config_infer_primary_yoloV5.txt file according to your model
[property]
...
custom-network-config=yolov5s.cfg
model-file=yolov5s.wts
...
- Step 8. Edit the deepstream_app_config file
...
[primary-gie]
...
config-file=config_infer_primary_yoloV5.txt
- Step 9. Change the video source in deepstream_app_config file. Here a default video file is loaded as you can see below
...
[source0]
...
uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
Run the Inference
deepstream-app -c deepstream_app_config.txt
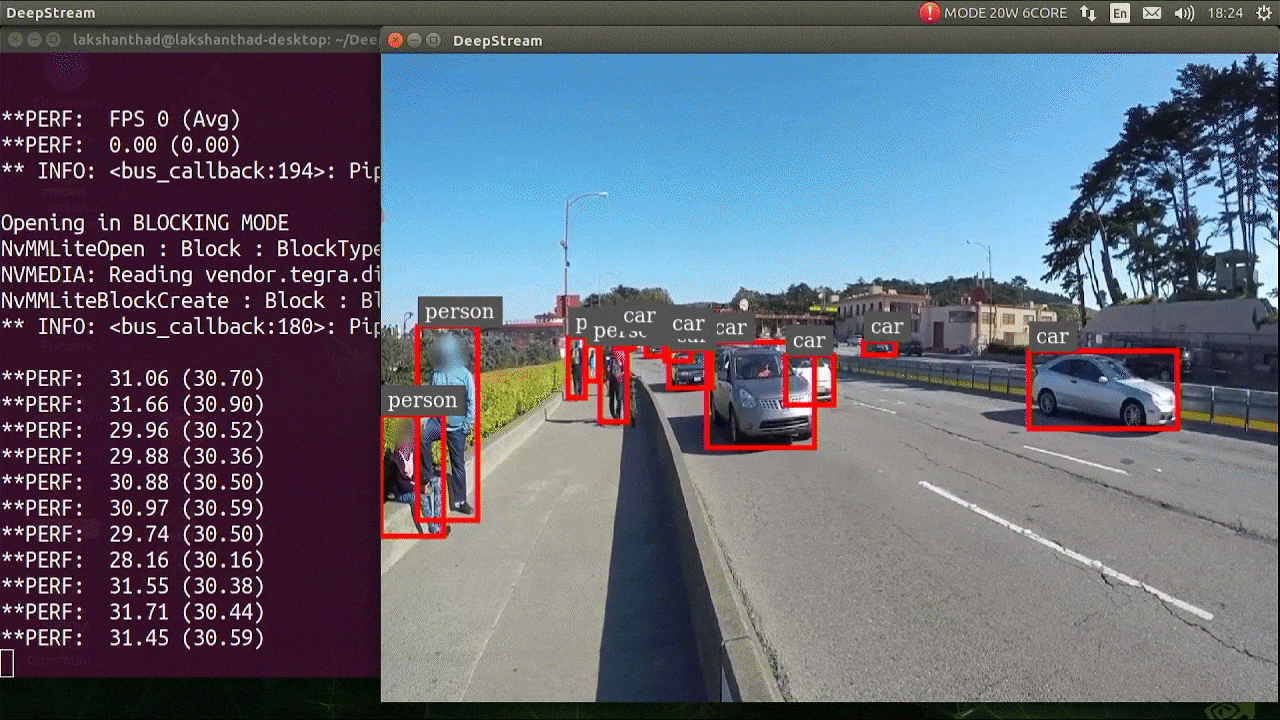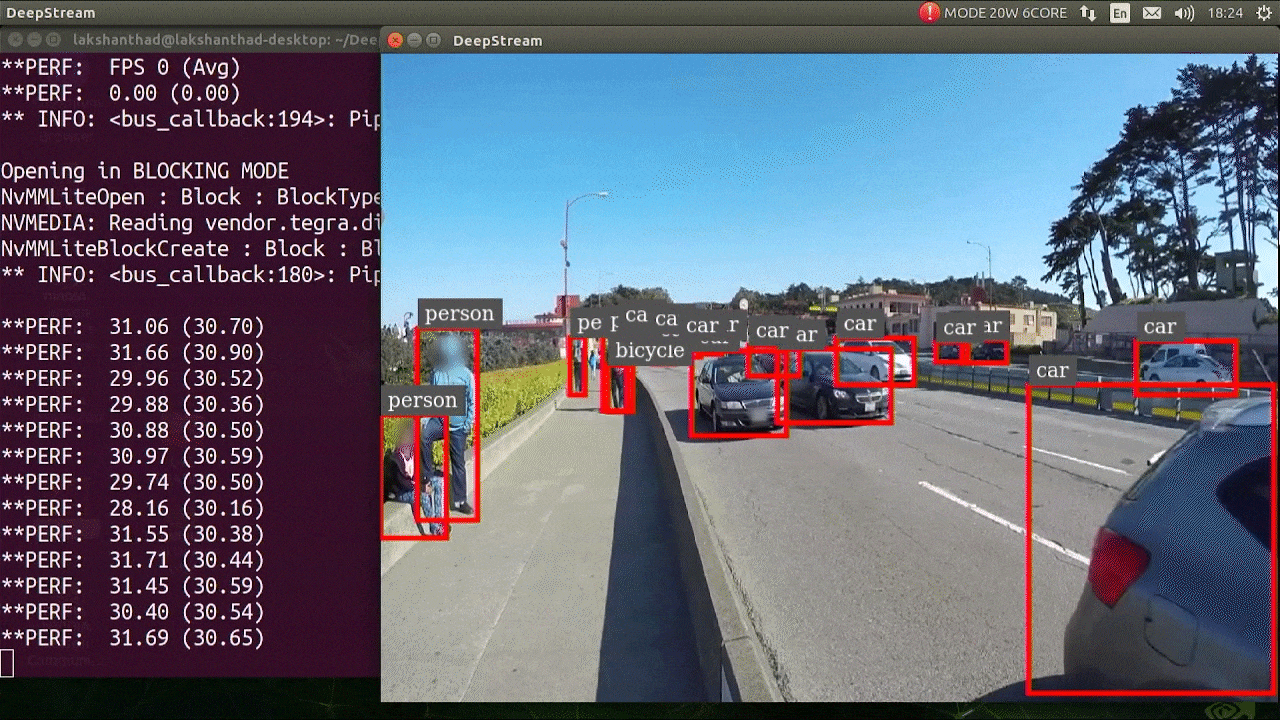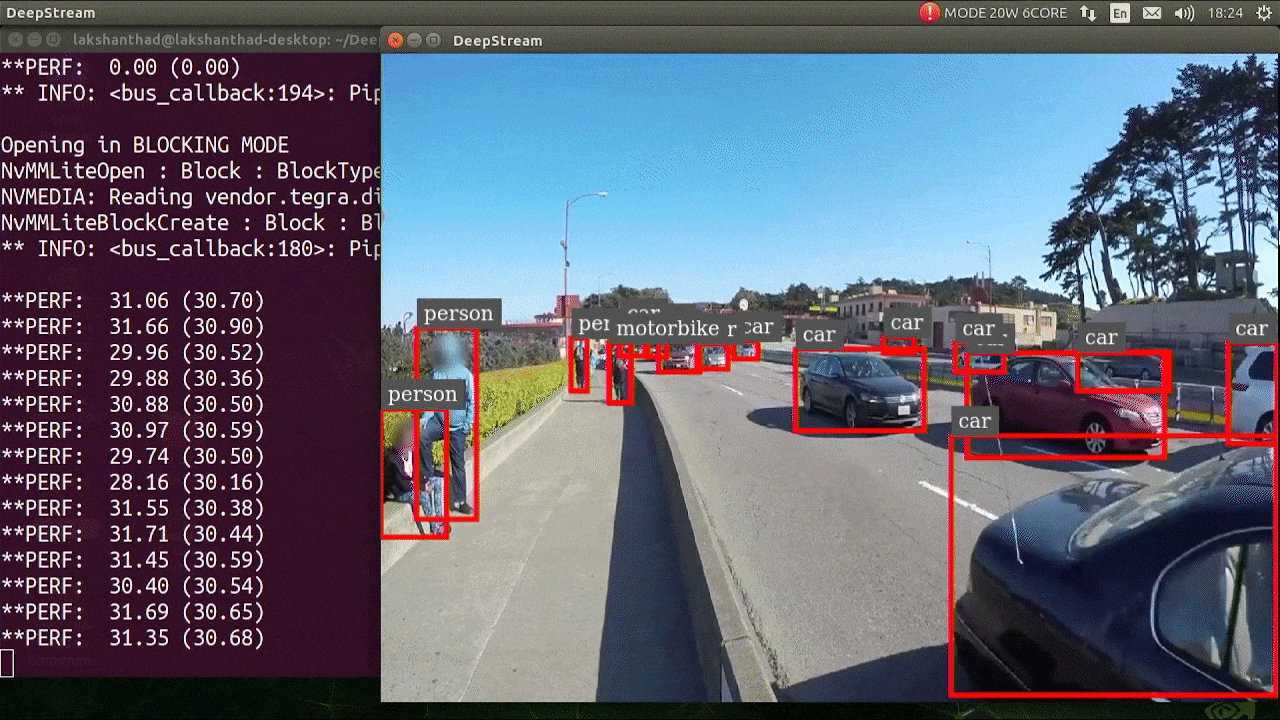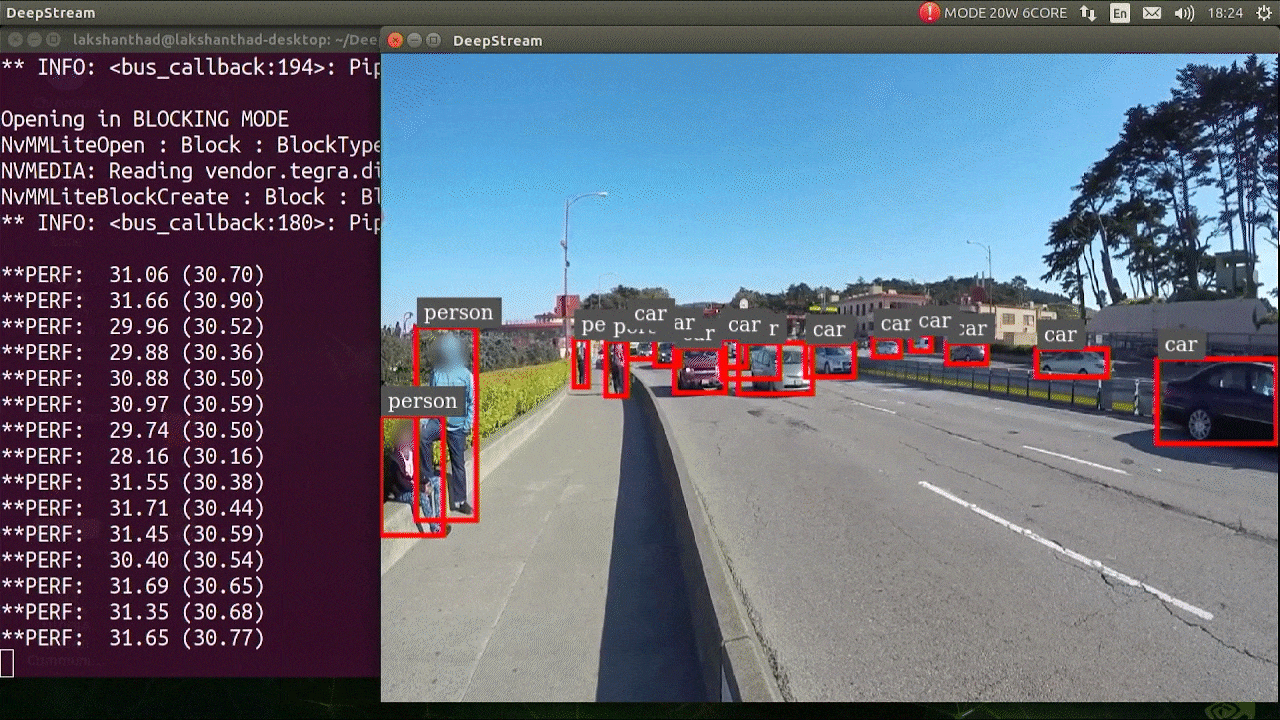
The above result is running on Jetson Xavier NX with FP32 and YOLOv5s 640x640. We can see that the FPS is around 30.
INT8 Calibration
If you want to use INT8 precision for inference, you need to follow the steps below
- Step 1. Install OpenCV
sudo apt-get install libopencv-dev
- Step 2. Compile/recompile the nvdsinfer_custom_impl_Yolo library with OpenCV support
cd ~/DeepStream-Yolo
CUDA_VER=11.4 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.1
CUDA_VER=10.2 OPENCV=1 make -C nvdsinfer_custom_impl_Yolo # for DeepStream 6.0.1 / 6.0
-
Step 3. For COCO dataset, download the val2017, extract, and move to DeepStream-Yolo folder
-
Step 4. Make a new directory for calibration images
mkdir calibration
- Step 5. Run the following to select 1000 random images from COCO dataset to run calibration
for jpg in $(ls -1 val2017/*.jpg | sort -R | head -1000); do \
cp ${jpg} calibration/; \
done
Note: NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). Higher INT8_CALIB_BATCH_SIZE values will result in more accuracy and faster calibration speed. Set it according to you GPU memory. You can set it from head -1000. For example, for 2000 images, head -2000. This process can take a long time.
- Step 6. Create the calibration.txt file with all selected images
realpath calibration/*jpg > calibration.txt
- Step 7. Set environment variables
export INT8_CALIB_IMG_PATH=calibration.txt
export INT8_CALIB_BATCH_SIZE=1
- Step 8. Update the config_infer_primary_yoloV5.txt file
From
...
model-engine-file=model_b1_gpu0_fp32.engine
#int8-calib-file=calib.table
...
network-mode=0
...
To
...
model-engine-file=model_b1_gpu0_int8.engine
int8-calib-file=calib.table
...
network-mode=1
...
- Step 9. Run the inference
deepstream-app -c deepstream_app_config.txt
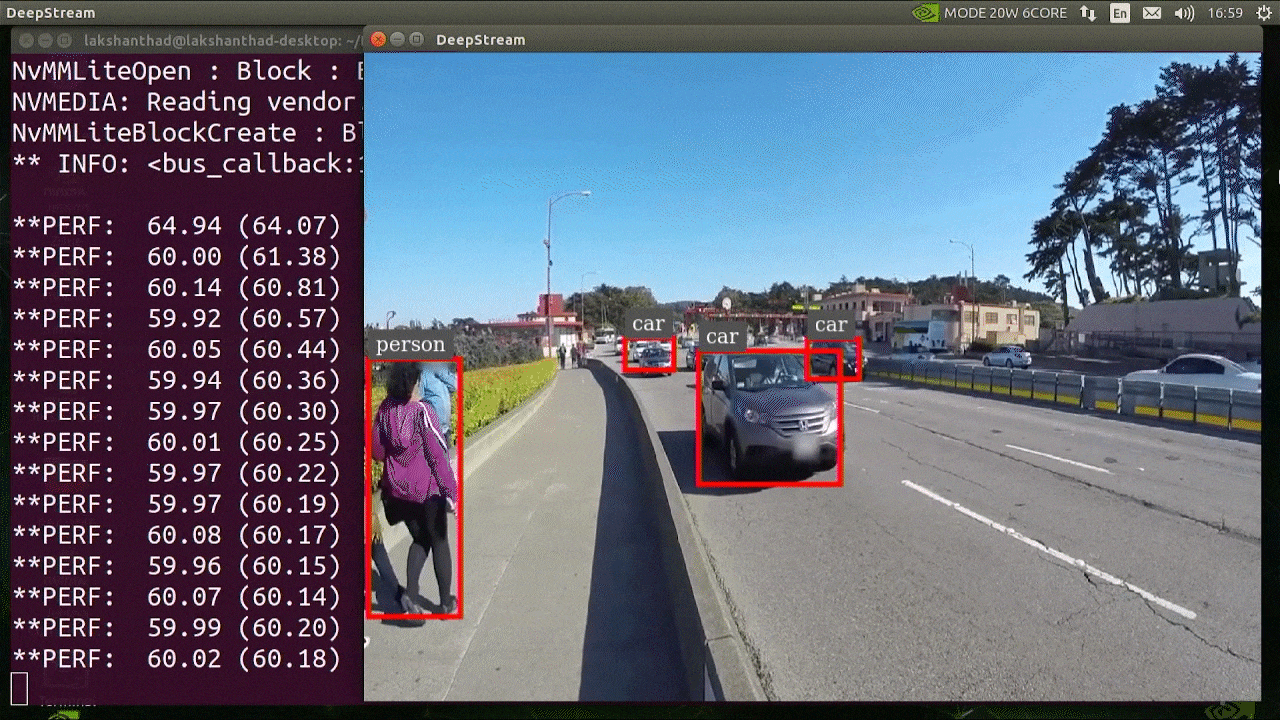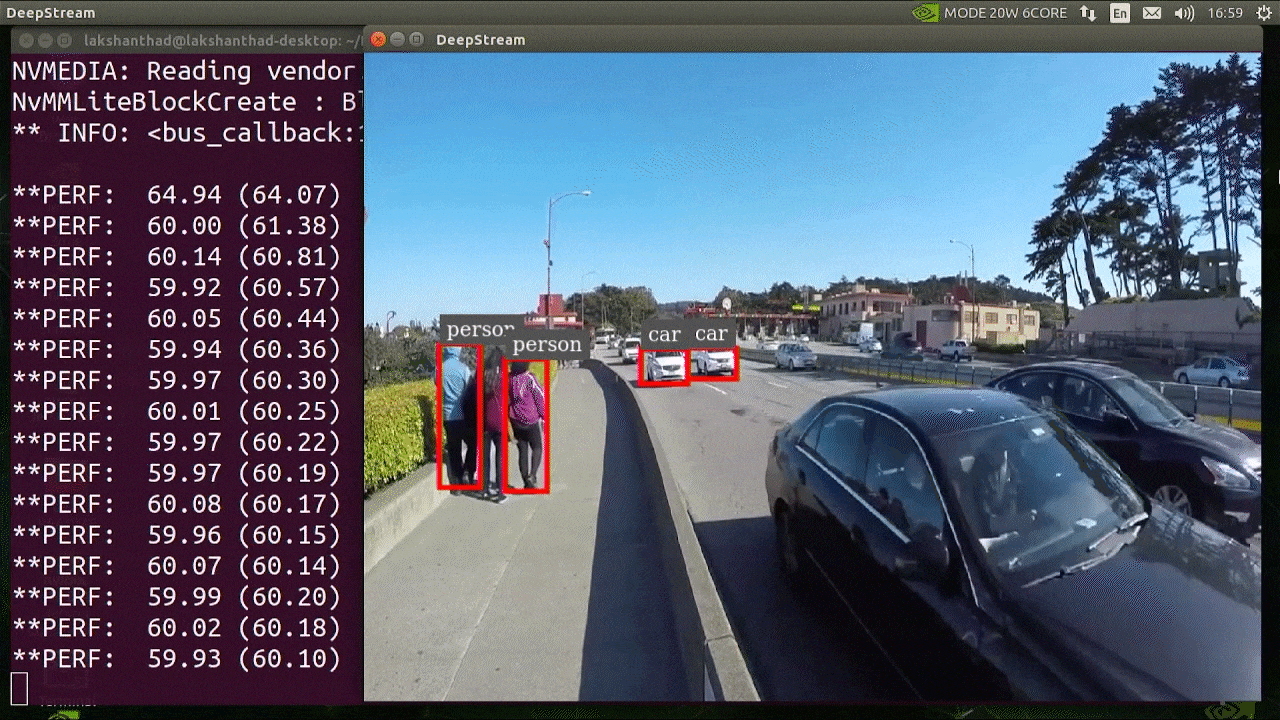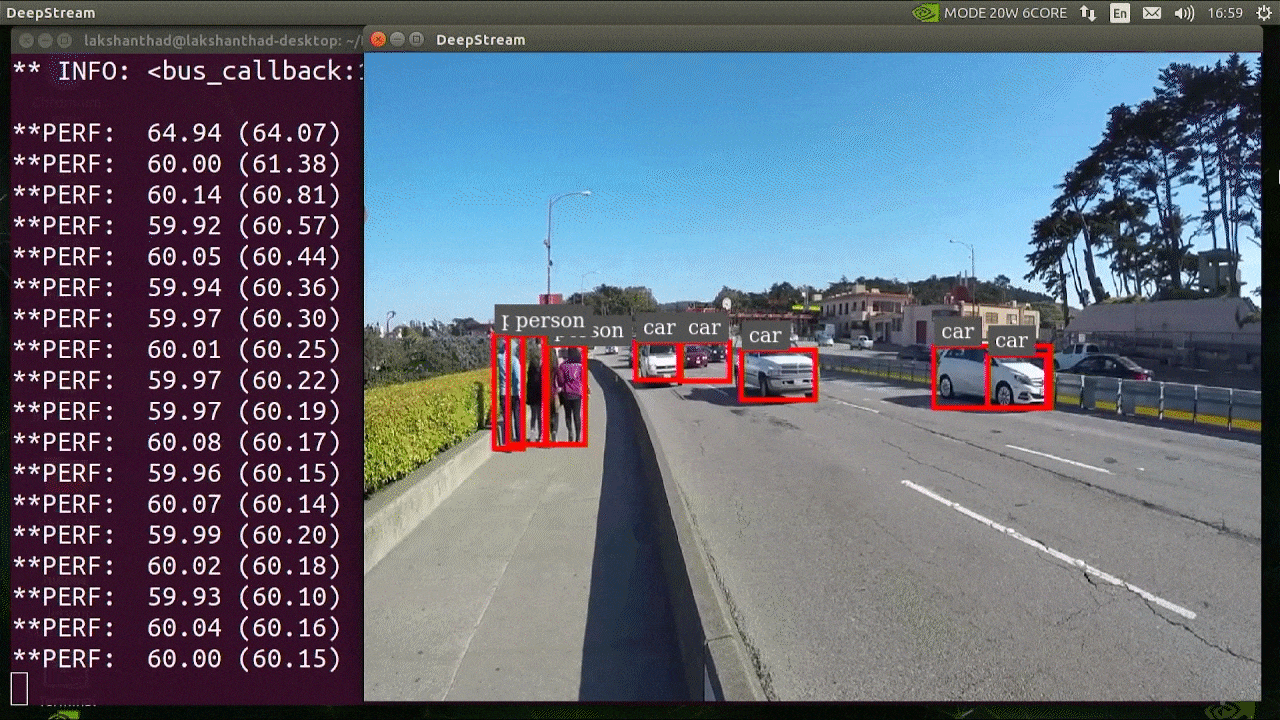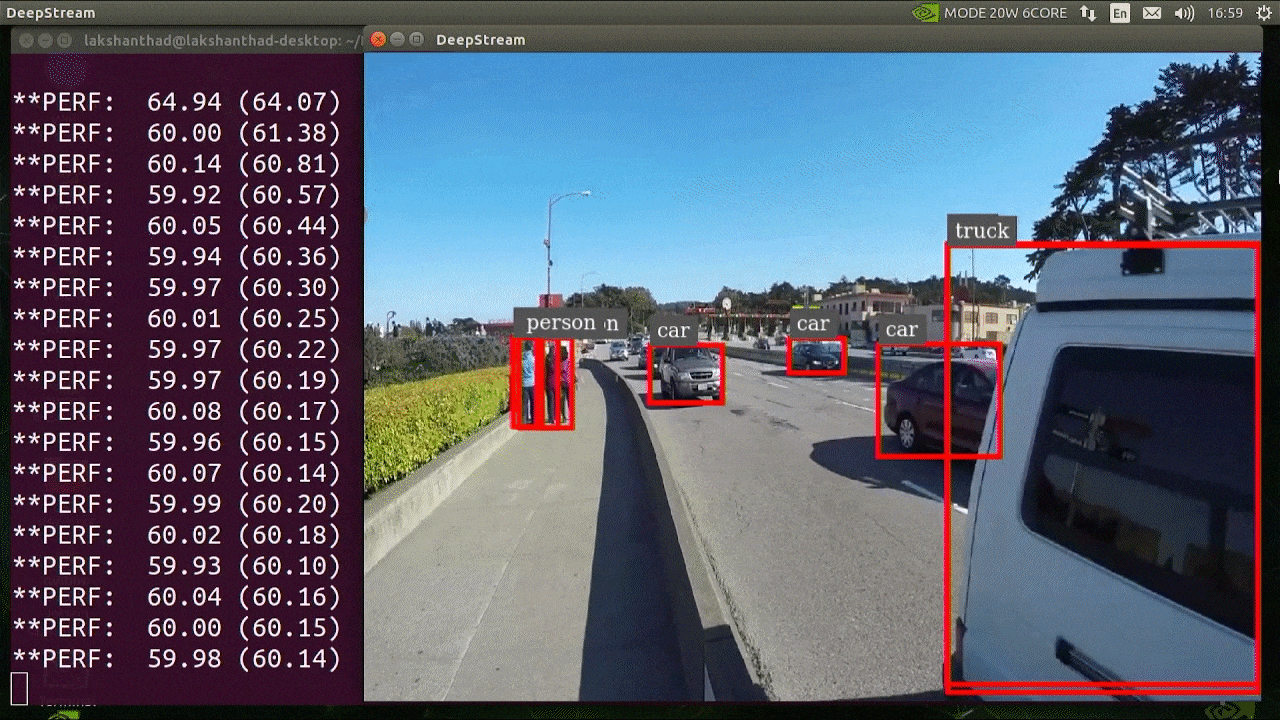
The above result is running on Jetson Xavier NX with INT8 and YOLOv5s 640x640. We can see that the FPS is around 60.
Benchmark results
The following table summarizes how different models perform on Jetson Xavier NX.
| Model Name | Precision | Inference Size | Inference Time (ms) | FPS |
|---|---|---|---|---|
| YOLOv5s | FP32 | 320x320 | 16.66 | 60 |
| FP32 | 640x640 | 33.33 | 30 | |
| INT8 | 640x640 | 16.66 | 60 | |
| YOLOv5n | FP32 | 640x640 | 16.66 | 60 |
Additional
This tutorial is written by our friends at seeed @lakshanthad and Elaine