You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
714 lines
36 KiB
714 lines
36 KiB
--- |
|
comments: true |
|
description: 了解如何使用 YOLOv8 预测模式进行各种任务。学习关于不同推理源如图像,视频和数据格式的内容。 |
|
keywords: Ultralytics, YOLOv8, 预测模式, 推理源, 预测任务, 流式模式, 图像处理, 视频处理, 机器学习, 人工智能 |
|
--- |
|
|
|
# 使用 Ultralytics YOLO 进行模型预测 |
|
|
|
<img width="1024" src="https://github.com/ultralytics/assets/raw/main/yolov8/banner-integrations.png" alt="Ultralytics YOLO 生态系统和集成"> |
|
|
|
## 引言 |
|
|
|
在机器学习和计算机视觉领域,将视觉数据转化为有用信息的过程被称为'推理'或'预测'。Ultralytics YOLOv8 提供了一个强大的功能,称为 **预测模式**,它专为各种数据来源的高性能实时推理而设计。 |
|
|
|
<p align="center"> |
|
<br> |
|
<iframe width="720" height="405" src="https://www.youtube.com/embed/QtsI0TnwDZs?si=ljesw75cMO2Eas14" |
|
title="YouTube 视频播放器" frameborder="0" |
|
allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" |
|
allowfullscreen> |
|
</iframe> |
|
<br> |
|
<strong>观看:</strong> 如何从 Ultralytics YOLOv8 模型中提取输出,用于自定义项目。 |
|
</p> |
|
|
|
## 实际应用领域 |
|
|
|
| 制造业 | 体育 | 安全 | |
|
|:-------------------------------------------------------------------------------------------------------------:|:-------------------------------------------------------------------------------------------------------------:|:------------------------------------------------------------------------------------------------------------:| |
|
| 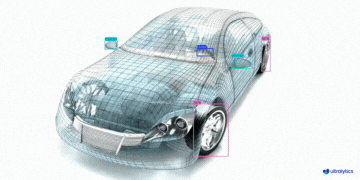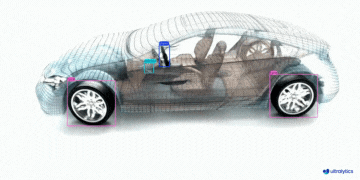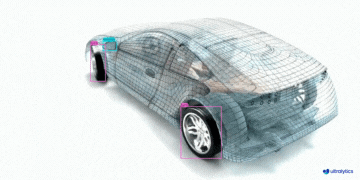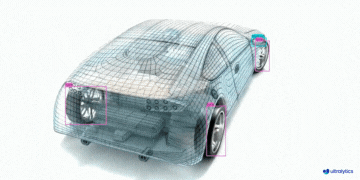 | 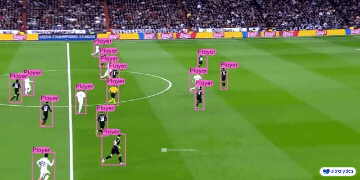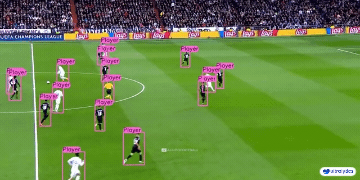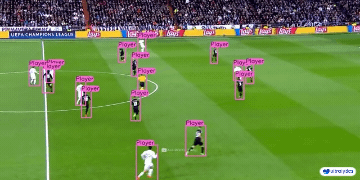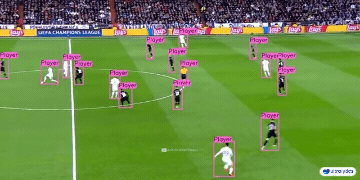 |  | |
|
| 车辆零部件检测 | 足球运动员检测 | 人员摔倒检测 | |
|
|
|
## 为何使用 Ultralytics YOLO 进行推理? |
|
|
|
以下是考虑使用 YOLOv8 的预测模式满足您的各种推理需求的几个原因: |
|
|
|
- **多功能性:** 能够对图像、视频乃至实时流进行推理。 |
|
- **性能:** 工程化为实时、高速处理而设计,不牺牲准确性。 |
|
- **易用性:** 直观的 Python 和 CLI 接口,便于快速部署和测试。 |
|
- **高度可定制性:** 多种设置和参数可调,依据您的具体需求调整模型的推理行为。 |
|
|
|
### 预测模式的关键特性 |
|
|
|
YOLOv8 的预测模式被设计为强大且多功能,包括以下特性: |
|
|
|
- **兼容多个数据来源:** 无论您的数据是单独图片,图片集合,视频文件,还是实时视频流,预测模式都能胜任。 |
|
- **流式模式:** 使用流式功能生成一个内存高效的 `Results` 对象生成器。在调用预测器时,通过设置 `stream=True` 来启用此功能。 |
|
- **批处理:** 能够在单个批次中处理多个图片或视频帧,进一步加快推理时间。 |
|
- **易于集成:** 由于其灵活的 API,易于与现有数据管道和其他软件组件集成。 |
|
|
|
Ultralytics YOLO 模型在进行推理时返回一个 Python `Results` 对象列表,或者当传入 `stream=True` 时,返回一个内存高效的 Python `Results` 对象生成器: |
|
|
|
!!! Example "预测" |
|
|
|
=== "使用 `stream=False` 返回列表" |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载模型 |
|
model = YOLO('yolov8n.pt') # 预训练的 YOLOv8n 模型 |
|
|
|
# 在图片列表上运行批量推理 |
|
results = model(['im1.jpg', 'im2.jpg']) # 返回 Results 对象列表 |
|
|
|
# 处理结果列表 |
|
for result in results: |
|
boxes = result.boxes # 边界框输出的 Boxes 对象 |
|
masks = result.masks # 分割掩码输出的 Masks 对象 |
|
keypoints = result.keypoints # 姿态输出的 Keypoints 对象 |
|
probs = result.probs # 分类输出的 Probs 对象 |
|
``` |
|
|
|
=== "使用 `stream=True` 返回生成器" |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载模型 |
|
model = YOLO('yolov8n.pt') # 预训练的 YOLOv8n 模型 |
|
|
|
# 在图片列表上运行批量推理 |
|
results = model(['im1.jpg', 'im2.jpg'], stream=True) # 返回 Results 对象生成器 |
|
|
|
# 处理结果生成器 |
|
for result in results: |
|
boxes = result.boxes # 边界框输出的 Boxes 对象 |
|
masks = result.masks # 分割掩码输出的 Masks 对象 |
|
keypoints = result.keypoints # 姿态输出的 Keypoints 对象 |
|
probs = result.probs # 分类输出的 Probs 对象 |
|
``` |
|
|
|
## 推理来源 |
|
|
|
YOLOv8 可以处理推理输入的不同类型,如下表所示。来源包括静态图像、视频流和各种数据格式。表格还表示了每种来源是否可以在流式模式下使用,使用参数 `stream=True` ✅。流式模式对于处理视频或实时流非常有利,因为它创建了结果的生成器,而不是将所有帧加载到内存。 |
|
|
|
!!! Tip "提示" |
|
|
|
使用 `stream=True` 处理长视频或大型数据集来高效地管理内存。当 `stream=False` 时,所有帧或数据点的结果都将存储在内存中,这可能很快导致内存不足错误。相对地,`stream=True` 使用生成器,只保留当前帧或数据点的结果在内存中,显著减少了内存消耗,防止内存不足问题。 |
|
|
|
| 来源 | 参数 | 类型 | 备注 | |
|
|-----------|--------------------------------------------|----------------|----------------------------------------------------| |
|
| 图像 | `'image.jpg'` | `str` 或 `Path` | 单个图像文件。 | |
|
| URL | `'https://ultralytics.com/images/bus.jpg'` | `str` | 图像的 URL 地址。 | |
|
| 截屏 | `'screen'` | `str` | 截取屏幕图像。 | |
|
| PIL | `Image.open('im.jpg')` | `PIL.Image` | RGB 通道的 HWC 格式图像。 | |
|
| OpenCV | `cv2.imread('im.jpg')` | `np.ndarray` | BGR 通道的 HWC 格式图像 `uint8 (0-255)`。 | |
|
| numpy | `np.zeros((640,1280,3))` | `np.ndarray` | BGR 通道的 HWC 格式图像 `uint8 (0-255)`。 | |
|
| torch | `torch.zeros(16,3,320,640)` | `torch.Tensor` | RGB 通道的 BCHW 格式图像 `float32 (0.0-1.0)`。 | |
|
| CSV | `'sources.csv'` | `str` 或 `Path` | 包含图像、视频或目录路径的 CSV 文件。 | |
|
| 视频 ✅ | `'video.mp4'` | `str` 或 `Path` | 如 MP4, AVI 等格式的视频文件。 | |
|
| 目录 ✅ | `'path/'` | `str` 或 `Path` | 包含图像或视频文件的目录路径。 | |
|
| 通配符 ✅ | `'path/*.jpg'` | `str` | 匹配多个文件的通配符模式。使用 `*` 字符作为通配符。 | |
|
| YouTube ✅ | `'https://youtu.be/LNwODJXcvt4'` | `str` | YouTube 视频的 URL 地址。 | |
|
| 流媒体 ✅ | `'rtsp://example.com/media.mp4'` | `str` | RTSP, RTMP, TCP 或 IP 地址等流协议的 URL 地址。 | |
|
| 多流媒体 ✅ | `'list.streams'` | `str` 或 `Path` | 一个流 URL 每行的 `*.streams` 文本文件,例如 8 个流将以 8 的批处理大小运行。 | |
|
|
|
下面为每种来源类型使用代码的示例: |
|
|
|
!!! Example "预测来源" |
|
|
|
=== "图像" |
|
对图像文件进行推理。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义图像文件的路径 |
|
source = 'path/to/image.jpg' |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "截屏" |
|
对当前屏幕内容作为截屏进行推理。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义当前截屏为来源 |
|
source = 'screen' |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "URL" |
|
对通过 URL 远程托管的图像或视频进行推理。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义远程图像或视频 URL |
|
source = 'https://ultralytics.com/images/bus.jpg' |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "PIL" |
|
对使用 Python Imaging Library (PIL) 打开的图像进行推理。 |
|
```python |
|
from PIL import Image |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 使用 PIL 打开图像 |
|
source = Image.open('path/to/image.jpg') |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "OpenCV" |
|
对使用 OpenCV 读取的图像进行推理。 |
|
```python |
|
import cv2 |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 使用 OpenCV 读取图像 |
|
source = cv2.imread('path/to/image.jpg') |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "numpy" |
|
对表示为 numpy 数组的图像进行推理。 |
|
```python |
|
import numpy as np |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 创建一个 HWC 形状 (640, 640, 3) 的随机 numpy 数组,数值范围 [0, 255] 类型为 uint8 |
|
source = np.random.randint(low=0, high=255, size=(640, 640, 3), dtype='uint8') |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "torch" |
|
对表示为 PyTorch 张量的图像进行推理。 |
|
```python |
|
import torch |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 创建一个 BCHW 形状 (1, 3, 640, 640) 的随机 torch 张量,数值范围 [0, 1] 类型为 float32 |
|
source = torch.rand(1, 3, 640, 640, dtype=torch.float32) |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "CSV" |
|
对 CSV 文件中列出的图像、URLs、视频和目录进行推理。 |
|
```python |
|
import torch |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义一个包含图像、URLs、视频和目录路径的 CSV 文件路径 |
|
source = 'path/to/file.csv' |
|
|
|
# 对来源进行推理 |
|
results = model(source) # Results 对象列表 |
|
``` |
|
|
|
=== "视频" |
|
对视频文件进行推理。使用 `stream=True` 时,可以创建一个 Results 对象的生成器,减少内存使用。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义视频文件路径 |
|
source = 'path/to/video.mp4' |
|
|
|
# 对来源进行推理 |
|
results = model(source, stream=True) # Results 对象的生成器 |
|
``` |
|
|
|
=== "目录" |
|
对目录中的所有图像和视频进行推理。要包含子目录中的图像和视频,使用通配符模式,例如 `path/to/dir/**/*`。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义包含图像和视频文件用于推理的目录路径 |
|
source = 'path/to/dir' |
|
|
|
# 对来源进行推理 |
|
results = model(source, stream=True) # Results 对象的生成器 |
|
``` |
|
|
|
=== "通配符" |
|
对与 `*` 字符匹配的所有图像和视频进行推理。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的 YOLOv8n 模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义一个目录下所有 JPG 文件的通配符搜索 |
|
source = 'path/to/dir/*.jpg' |
|
|
|
# 或定义一个包括子目录的所有 JPG 文件的递归通配符搜索 |
|
source = 'path/to/dir/**/*.jpg' |
|
|
|
# 对来源进行推理 |
|
results = model(source, stream=True) # Results 对象的生成器 |
|
``` |
|
|
|
=== "YouTube" |
|
在YouTube视频上运行推理。通过使用`stream=True`,您可以创建一个Results对象的生成器,以减少长视频的内存使用。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 定义源为YouTube视频URL |
|
source = 'https://youtu.be/LNwODJXcvt4' |
|
|
|
# 在源上运行推理 |
|
results = model(source, stream=True) # Results对象的生成器 |
|
``` |
|
|
|
=== "Streams" |
|
使用RTSP、RTMP、TCP和IP地址协议在远程流媒体源上运行推理。如果在`*.streams`文本文件中提供了多个流,则将运行批量推理,例如,8个流将以批大小8运行,否则单个流将以批大小1运行。 |
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 单流媒体源批大小1推理 |
|
source = 'rtsp://example.com/media.mp4' # RTSP、RTMP、TCP或IP流媒体地址 |
|
|
|
# 多个流媒体源的批量推理(例如,8个流的批大小为8) |
|
source = 'path/to/list.streams' # *.streams文本文件,每行一个流媒体地址 |
|
|
|
# 在源上运行推理 |
|
results = model(source, stream=True) # Results对象的生成器 |
|
``` |
|
|
|
## 推理参数 |
|
|
|
`model.predict()` 在推理时接受多个参数,可以用来覆盖默认值: |
|
|
|
!!! Example "示例" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 在'bus.jpg'上运行推理,并附加参数 |
|
model.predict('bus.jpg', save=True, imgsz=320, conf=0.5) |
|
``` |
|
|
|
支持的所有参数: |
|
|
|
| 名称 | 类型 | 默认值 | 描述 | |
|
|-----------------|----------------|------------------------|------------------------------------------| |
|
| `source` | `str` | `'ultralytics/assets'` | 图像或视频的源目录 | |
|
| `conf` | `float` | `0.25` | 检测对象的置信度阈值 | |
|
| `iou` | `float` | `0.7` | 用于NMS的交并比(IoU)阈值 | |
|
| `imgsz` | `int or tuple` | `640` | 图像大小,可以是标量或(h, w)列表,例如(640, 480) | |
|
| `half` | `bool` | `False` | 使用半精度(FP16) | |
|
| `device` | `None or str` | `None` | 运行设备,例如 cuda device=0/1/2/3 或 device=cpu | |
|
| `show` | `bool` | `False` | 如果可能,显示结果 | |
|
| `save` | `bool` | `False` | 保存带有结果的图像 | |
|
| `save_txt` | `bool` | `False` | 将结果保存为.txt文件 | |
|
| `save_conf` | `bool` | `False` | 保存带有置信度分数的结果 | |
|
| `save_crop` | `bool` | `False` | 保存带有结果的裁剪图像 | |
|
| `show_labels` | `bool` | `True` | 隐藏标签 | |
|
| `show_conf` | `bool` | `True` | 隐藏置信度分数 | |
|
| `max_det` | `int` | `300` | 每张图像的最大检测数量 | |
|
| `vid_stride` | `bool` | `False` | 视频帧速率跳跃 | |
|
| `stream_buffer` | `bool` | `False` | 缓冲所有流媒体帧(True)或返回最新帧(False) | |
|
| `line_width` | `None or int` | `None` | 边框线宽度。如果为None,则按图像大小缩放。 | |
|
| `visualize` | `bool` | `False` | 可视化模型特征 | |
|
| `augment` | `bool` | `False` | 应用图像增强到预测源 | |
|
| `agnostic_nms` | `bool` | `False` | 类别不敏感的NMS | |
|
| `retina_masks` | `bool` | `False` | 使用高分辨率分割掩码 | |
|
| `classes` | `None or list` | `None` | 按类别过滤结果,例如 classes=0,或 classes=[0,2,3] | |
|
| `boxes` | `bool` | `True` | 在分割预测中显示框 | |
|
|
|
## 图像和视频格式 |
|
|
|
YOLOv8支持多种图像和视频格式,如[data/utils.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/data/utils.py)所指定。请参阅下表了解有效的后缀名和示例预测命令。 |
|
|
|
### 图像 |
|
|
|
下表包含了Ultralytics支持的有效图像格式。 |
|
|
|
| 图像后缀 | 示例预测命令 | 参考链接 | |
|
|-------|----------------------------------|-------------------------------------------------------------------------------| |
|
| .bmp | `yolo predict source=image.bmp` | [Microsoft BMP文件格式](https://en.wikipedia.org/wiki/BMP_file_format) | |
|
| .dng | `yolo predict source=image.dng` | [Adobe DNG](https://www.adobe.com/products/photoshop/extend.displayTab2.html) | |
|
| .jpeg | `yolo predict source=image.jpeg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) | |
|
| .jpg | `yolo predict source=image.jpg` | [JPEG](https://en.wikipedia.org/wiki/JPEG) | |
|
| .mpo | `yolo predict source=image.mpo` | [多图像对象](https://fileinfo.com/extension/mpo) | |
|
| .png | `yolo predict source=image.png` | [便携式网络图形](https://en.wikipedia.org/wiki/PNG) | |
|
| .tif | `yolo predict source=image.tif` | [标签图像文件格式](https://en.wikipedia.org/wiki/TIFF) | |
|
| .tiff | `yolo predict source=image.tiff` | [标签图像文件格式](https://en.wikipedia.org/wiki/TIFF) | |
|
| .webp | `yolo predict source=image.webp` | [WebP](https://en.wikipedia.org/wiki/WebP) | |
|
| .pfm | `yolo predict source=image.pfm` | [便携式浮点映射](https://en.wikipedia.org/wiki/Netpbm#File_formats) | |
|
|
|
### 视频 |
|
|
|
以下表格包含有效的Ultralytics视频格式。 |
|
|
|
| 视频后缀名 | 示例预测命令 | 参考链接 | |
|
|-------|----------------------------------|----------------------------------------------------------------------| |
|
| .asf | `yolo predict source=video.asf` | [高级系统格式](https://en.wikipedia.org/wiki/Advanced_Systems_Format) | |
|
| .avi | `yolo predict source=video.avi` | [音视频交错](https://en.wikipedia.org/wiki/Audio_Video_Interleave) | |
|
| .gif | `yolo predict source=video.gif` | [图形交换格式](https://en.wikipedia.org/wiki/GIF) | |
|
| .m4v | `yolo predict source=video.m4v` | [MPEG-4第14部分](https://en.wikipedia.org/wiki/M4V) | |
|
| .mkv | `yolo predict source=video.mkv` | [Matroska](https://en.wikipedia.org/wiki/Matroska) | |
|
| .mov | `yolo predict source=video.mov` | [QuickTime文件格式](https://en.wikipedia.org/wiki/QuickTime_File_Format) | |
|
| .mp4 | `yolo predict source=video.mp4` | [MPEG-4第14部分](https://en.wikipedia.org/wiki/MPEG-4_Part_14) | |
|
| .mpeg | `yolo predict source=video.mpeg` | [MPEG-1第2部分](https://en.wikipedia.org/wiki/MPEG-1) | |
|
| .mpg | `yolo predict source=video.mpg` | [MPEG-1第2部分](https://en.wikipedia.org/wiki/MPEG-1) | |
|
| .ts | `yolo predict source=video.ts` | [MPEG传输流](https://en.wikipedia.org/wiki/MPEG_transport_stream) | |
|
| .wmv | `yolo predict source=video.wmv` | [Windows媒体视频](https://en.wikipedia.org/wiki/Windows_Media_Video) | |
|
| .webm | `yolo predict source=video.webm` | [WebM项目](https://en.wikipedia.org/wiki/WebM) | |
|
|
|
## 处理结果 |
|
|
|
所有Ultralytics的`predict()`调用都将返回一个`Results`对象列表: |
|
|
|
!!! Example "结果" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 在图片上运行推理 |
|
results = model('bus.jpg') # 1个Results对象的列表 |
|
results = model(['bus.jpg', 'zidane.jpg']) # 2个Results对象的列表 |
|
``` |
|
|
|
`Results`对象具有以下属性: |
|
|
|
| 属性 | 类型 | 描述 | |
|
|--------------|-----------------|------------------------------| |
|
| `orig_img` | `numpy.ndarray` | 原始图像的numpy数组。 | |
|
| `orig_shape` | `tuple` | 原始图像的形状,格式为(高度,宽度)。 | |
|
| `boxes` | `Boxes, 可选` | 包含检测边界框的Boxes对象。 | |
|
| `masks` | `Masks, 可选` | 包含检测掩码的Masks对象。 | |
|
| `probs` | `Probs, 可选` | 包含每个类别的概率的Probs对象,用于分类任务。 | |
|
| `keypoints` | `Keypoints, 可选` | 包含每个对象检测到的关键点的Keypoints对象。 | |
|
| `speed` | `dict` | 以毫秒为单位的每张图片的预处理、推理和后处理速度的字典。 | |
|
| `names` | `dict` | 类别名称的字典。 | |
|
| `path` | `str` | 图像文件的路径。 | |
|
|
|
`Results`对象具有以下方法: |
|
|
|
| 方法 | 返回类型 | 描述 | |
|
|-----------------|-----------------|----------------------------------------| |
|
| `__getitem__()` | `Results` | 返回指定索引的Results对象。 | |
|
| `__len__()` | `int` | 返回Results对象中的检测数量。 | |
|
| `update()` | `None` | 更新Results对象的boxes, masks和probs属性。 | |
|
| `cpu()` | `Results` | 将所有张量移动到CPU内存上的Results对象的副本。 | |
|
| `numpy()` | `Results` | 将所有张量转换为numpy数组的Results对象的副本。 | |
|
| `cuda()` | `Results` | 将所有张量移动到GPU内存上的Results对象的副本。 | |
|
| `to()` | `Results` | 返回将张量移动到指定设备和dtype的Results对象的副本。 | |
|
| `new()` | `Results` | 返回一个带有相同图像、路径和名称的新Results对象。 | |
|
| `keys()` | `List[str]` | 返回非空属性名称的列表。 | |
|
| `plot()` | `numpy.ndarray` | 绘制检测结果。返回带有注释的图像的numpy数组。 | |
|
| `verbose()` | `str` | 返回每个任务的日志字符串。 | |
|
| `save_txt()` | `None` | 将预测保存到txt文件中。 | |
|
| `save_crop()` | `None` | 将裁剪的预测保存到`save_dir/cls/file_name.jpg`。 | |
|
| `tojson()` | `None` | 将对象转换为JSON格式。 | |
|
|
|
有关更多详细信息,请参阅`Results`类的[文档](/../reference/engine/results.md)。 |
|
|
|
### 边界框(Boxes) |
|
|
|
`Boxes`对象可用于索引、操作和转换边界框到不同格式。 |
|
|
|
!!! Example "边界框(Boxes)" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 在图片上运行推理 |
|
results = model('bus.jpg') |
|
|
|
# 查看结果 |
|
for r in results: |
|
print(r.boxes) # 打印包含检测边界框的Boxes对象 |
|
``` |
|
|
|
以下是`Boxes`类方法和属性的表格,包括它们的名称、类型和description: |
|
|
|
| 名称 | 类型 | 描述 | |
|
|-----------|---------------------|-------------------------| |
|
| `cpu()` | 方法 | 将对象移动到CPU内存。 | |
|
| `numpy()` | 方法 | 将对象转换为numpy数组。 | |
|
| `cuda()` | 方法 | 将对象移动到CUDA内存。 | |
|
| `to()` | 方法 | 将对象移动到指定的设备。 | |
|
| `xyxy` | 属性 (`torch.Tensor`) | 以xyxy格式返回边界框。 | |
|
| `conf` | 属性 (`torch.Tensor`) | 返回边界框的置信度值。 | |
|
| `cls` | 属性 (`torch.Tensor`) | 返回边界框的类别值。 | |
|
| `id` | 属性 (`torch.Tensor`) | 返回边界框的跟踪ID(如果可用)。 | |
|
| `xywh` | 属性 (`torch.Tensor`) | 以xywh格式返回边界框。 | |
|
| `xyxyn` | 属性 (`torch.Tensor`) | 以原始图像大小归一化的xyxy格式返回边界框。 | |
|
| `xywhn` | 属性 (`torch.Tensor`) | 以原始图像大小归一化的xywh格式返回边界框。 | |
|
|
|
有关更多详细信息,请参阅`Boxes`类的[文档](/../reference/engine/results.md)。 |
|
|
|
### 掩码(Masks) |
|
|
|
`Masks`对象可用于索引、操作和将掩码转换为分段。 |
|
|
|
!!! Example "掩码(Masks)" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n-seg分割模型 |
|
model = YOLO('yolov8n-seg.pt') |
|
|
|
# 在图片上运行推理 |
|
results = model('bus.jpg') # results列表 |
|
|
|
# 查看结果 |
|
for r in results: |
|
print(r.masks) # 打印包含检测到的实例掩码的Masks对象 |
|
``` |
|
|
|
以下是`Masks`类方法和属性的表格,包括它们的名称、类型和description: |
|
|
|
| 名称 | 类型 | 描述 | |
|
|-----------|---------------------|----------------------| |
|
| `cpu()` | 方法 | 将掩码张量返回到CPU内存。 | |
|
| `numpy()` | 方法 | 将掩码张量转换为numpy数组。 | |
|
| `cuda()` | 方法 | 将掩码张量返回到GPU内存。 | |
|
| `to()` | 方法 | 将掩码张量带有指定设备和dtype返回。 | |
|
| `xyn` | 属性 (`torch.Tensor`) | 以张量表示的归一化分段的列表。 | |
|
| `xy` | 属性 (`torch.Tensor`) | 以像素坐标表示的分段的张量列表。 | |
|
|
|
有关更多详细信息,请参阅`Masks`类的[文档](/../reference/engine/results.md)。 |
|
|
|
### 关键点 (Keypoints) |
|
|
|
`Keypoints` 对象可以用于索引、操作和规范化坐标。 |
|
|
|
!!! Example "关键点" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n-pose 姿态模型 |
|
model = YOLO('yolov8n-pose.pt') |
|
|
|
# 在图像上运行推理 |
|
results = model('bus.jpg') # 结果列表 |
|
|
|
# 查看结果 |
|
for r in results: |
|
print(r.keypoints) # 打印包含检测到的关键点的Keypoints对象 |
|
``` |
|
|
|
以下是`Keypoints`类方法和属性的表格,包括它们的名称、类型和description: |
|
|
|
| 名称 | 类型 | 描述 | |
|
|-----------|--------------------|---------------------------| |
|
| `cpu()` | 方法 | 返回CPU内存上的关键点张量。 | |
|
| `numpy()` | 方法 | 返回作为numpy数组的关键点张量。 | |
|
| `cuda()` | 方法 | 返回GPU内存上的关键点张量。 | |
|
| `to()` | 方法 | 返回指定设备和dtype的关键点张量。 | |
|
| `xyn` | 属性(`torch.Tensor`) | 规范化关键点的列表,表示为张量。 | |
|
| `xy` | 属性(`torch.Tensor`) | 以像素坐标表示的关键点列表,表示为张量。 | |
|
| `conf` | 属性(`torch.Tensor`) | 返回关键点的置信度值(如果有),否则返回None。 | |
|
|
|
有关更多详细信息,请参阅`Keypoints`类[文档](/../reference/engine/results.md)。 |
|
|
|
### 概率 (Probs) |
|
|
|
`Probs` 对象可以用于索引,获取分类的 `top1` 和 `top5` 索引和分数。 |
|
|
|
!!! Example "概率" |
|
|
|
```python |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n-cls 分类模型 |
|
model = YOLO('yolov8n-cls.pt') |
|
|
|
# 在图像上运行推理 |
|
results = model('bus.jpg') # 结果列表 |
|
|
|
# 查看结果 |
|
for r in results: |
|
print(r.probs) # 打印包含检测到的类别概率的Probs对象 |
|
``` |
|
|
|
以下是`Probs`类的方法和属性的表格总结: |
|
|
|
| 名称 | 类型 | 描述 | |
|
|------------|--------------------|-------------------------| |
|
| `cpu()` | 方法 | 返回CPU内存上的概率张量的副本。 | |
|
| `numpy()` | 方法 | 返回概率张量的副本作为numpy数组。 | |
|
| `cuda()` | 方法 | 返回GPU内存上的概率张量的副本。 | |
|
| `to()` | 方法 | 返回带有指定设备和dtype的概率张量的副本。 | |
|
| `top1` | 属性(`int`) | 第1类的索引。 | |
|
| `top5` | 属性(`list[int]`) | 前5类的索引。 | |
|
| `top1conf` | 属性(`torch.Tensor`) | 第1类的置信度。 | |
|
| `top5conf` | 属性(`torch.Tensor`) | 前5类的置信度。 | |
|
|
|
有关更多详细信息,请参阅`Probs`类[文档](/../reference/engine/results.md)。 |
|
|
|
## 绘制结果 |
|
|
|
您可以使用`Result`对象的`plot()`方法来可视化预测结果。它会将`Results`对象中包含的所有预测类型(框、掩码、关键点、概率等)绘制到一个numpy数组上,然后可以显示或保存。 |
|
|
|
!!! Example "绘制" |
|
|
|
```python |
|
from PIL import Image |
|
from ultralytics import YOLO |
|
|
|
# 加载预训练的YOLOv8n模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 在'bus.jpg'上运行推理 |
|
results = model('bus.jpg') # 结果列表 |
|
|
|
# 展示结果 |
|
for r in results: |
|
im_array = r.plot() # 绘制包含预测结果的BGR numpy数组 |
|
im = Image.fromarray(im_array[..., ::-1]) # RGB PIL图像 |
|
im.show() # 显示图像 |
|
im.save('results.jpg') # 保存图像 |
|
``` |
|
|
|
`plot()`方法支持以下参数: |
|
|
|
| 参数 | 类型 | 描述 | 默认值 | |
|
|---------------|-----------------|------------------------------------------------------------------------|---------------| |
|
| `conf` | `bool` | 是否绘制检测置信度分数。 | `True` | |
|
| `line_width` | `float` | 边框线宽度。如果为None,则按图像大小缩放。 | `None` | |
|
| `font_size` | `float` | 文本字体大小。如果为None,则按图像大小缩放。 | `None` | |
|
| `font` | `str` | 文本字体。 | `'Arial.ttf'` | |
|
| `pil` | `bool` | 是否将图像返回为PIL图像。 | `False` | |
|
| `img` | `numpy.ndarray` | 绘制到另一个图像上。如果没有,则绘制到原始图像上。 | `None` | |
|
| `im_gpu` | `torch.Tensor` | 形状为(1, 3, 640, 640)的规范化GPU图像,用于更快地绘制掩码。 | `None` | |
|
| `kpt_radius` | `int` | 绘制关键点的半径。默认为5。 | `5` | |
|
| `kpt_line` | `bool` | 是否绘制连接关键点的线条。 | `True` | |
|
| `labels` | `bool` | 是否绘制边框标签。 | `True` | |
|
| `boxes` | `bool` | 是否绘制边框。 | `True` | |
|
| `masks` | `bool` | 是否绘制掩码。 | `True` | |
|
| `probs` | `bool` | 是否绘制分类概率 | `True` | |
|
|
|
## 线程安全推理 |
|
|
|
在多线程中并行运行多个YOLO模型时,确保推理过程的线程安全性至关重要。线程安全的推理保证了每个线程的预测结果是隔离的,不会相互干扰,避免竞态条件,确保输出的一致性和可靠性。 |
|
|
|
在多线程应用中使用YOLO模型时,重要的是为每个线程实例化单独的模型对象,或使用线程本地存储来防止冲突: |
|
|
|
!!! Example "线程安全推理" |
|
|
|
在每个线程内实例化单个模型以实现线程安全的推理: |
|
```python |
|
from ultralytics import YOLO |
|
from threading import Thread |
|
|
|
def thread_safe_predict(image_path): |
|
# 在线程内实例化新模型 |
|
local_model = YOLO("yolov8n.pt") |
|
results = local_model.predict(image_path) |
|
# 处理结果 |
|
|
|
# 启动拥有各自模型实例的线程 |
|
Thread(target=thread_safe_predict, args=("image1.jpg",)).start() |
|
Thread(target=thread_safe_predict, args=("image2.jpg",)).start() |
|
``` |
|
|
|
有关YOLO模型线程安全推理的深入讨论和逐步指导,请参阅我们的[YOLO线程安全推理指南](/../guides/yolo-thread-safe-inference.md)。该指南将为您提供避免常见陷阱并确保多线程推理顺利进行所需的所有必要信息。 |
|
|
|
## 流媒体源`for`循环 |
|
|
|
以下是使用OpenCV(`cv2`)和YOLOv8在视频帧上运行推理的Python脚本。此脚本假设您已经安装了必要的包(`opencv-python`和`ultralytics`)。 |
|
|
|
!!! Example "流媒体for循环" |
|
|
|
```python |
|
import cv2 |
|
from ultralytics import YOLO |
|
|
|
# 加载YOLOv8模型 |
|
model = YOLO('yolov8n.pt') |
|
|
|
# 打开视频文件 |
|
video_path = "path/to/your/video/file.mp4" |
|
cap = cv2.VideoCapture(video_path) |
|
|
|
# 遍历视频帧 |
|
while cap.isOpened(): |
|
# 从视频中读取一帧 |
|
success, frame = cap.read() |
|
|
|
if success: |
|
# 在该帧上运行YOLOv8推理 |
|
results = model(frame) |
|
|
|
# 在帧上可视化结果 |
|
annotated_frame = results[0].plot() |
|
|
|
# 显示带注释的帧 |
|
cv2.imshow("YOLOv8推理", annotated_frame) |
|
|
|
# 如果按下'q'则中断循环 |
|
if cv2.waitKey(1) & 0xFF == ord("q"): |
|
break |
|
else: |
|
# 如果视频结束则中断循环 |
|
break |
|
|
|
# 释放视频捕获对象并关闭显示窗口 |
|
cap.release() |
|
cv2.destroyAllWindows() |
|
``` |
|
|
|
此脚本将对视频的每一帧进行预测,可视化结果,并在窗口中显示。按下'q'键可以退出循环。
|
|
|