15 KiB
| comments | description | keywords |
|---|---|---|
| true | Explore effective methods for testing computer vision models to make sure they are reliable, perform well, and are ready to be deployed. | Overfitting and Underfitting in Machine Learning, Model Testing, Data Leakage Machine Learning, Testing a Model, Testing Machine Learning Models, How to Test AI Models |
A Guide on Model Testing
Introduction
After training and evaluating your model, it's time to test it. Model testing involves assessing how well it performs in real-world scenarios. Testing considers factors like accuracy, reliability, fairness, and how easy it is to understand the model's decisions. The goal is to make sure the model performs as intended, delivers the expected results, and fits into the overall objective of your application or project.
Model testing is quite similar to model evaluation, but they are two distinct steps in a computer vision project. Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your computer vision models.
Model Testing Vs. Model Evaluation
First, let's understand the difference between model evaluation and testing with an example.
Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, precision, recall, and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
After evaluation, you test the model using images from a pet store to see how well it identifies cats and dogs in more varied and realistic conditions. You check if it can correctly label cats and dogs when they are moving, in different lighting conditions, or partially obscured by objects like toys or furniture. Model testing checks that the model behaves as expected outside the controlled evaluation environment.
Preparing for Model Testing
Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These datasets are usually divided into training and testing sets to simulate real-world conditions. Training data teaches the model while testing data verifies its accuracy.
Here are two points to keep in mind before testing your model:
- Realistic Representation: The previously unseen testing data should be similar to the data that the model will have to handle when deployed. This helps get a realistic understanding of the model's capabilities.
- Sufficient Size: The size of the testing dataset needs to be large enough to provide reliable insights into how well the model performs.
Testing Your Computer Vision Model
Here are the key steps to take to test your computer vision model and understand its performance.
- Run Predictions: Use the model to make predictions on the test dataset.
- Compare Predictions: Check how well the model's predictions match the actual labels (ground truth).
- Calculate Performance Metrics: Compute metrics like accuracy, precision, recall, and F1 score to understand the model's strengths and weaknesses. Testing focuses on how these metrics reflect real-world performance.
- Visualize Results: Create visual aids like confusion matrices and ROC curves. These help you spot specific areas where the model might not be performing well in practical applications.
Next, the testing results can be analyzed:
- Misclassified Images: Identify and review images that the model misclassified to understand where it is going wrong.
- Error Analysis: Perform a thorough error analysis to understand the types of errors (e.g., false positives vs. false negatives) and their potential causes.
- Bias and Fairness: Check for any biases in the model's predictions. Ensure that the model performs equally well across different subsets of the data, especially if it includes sensitive attributes like race, gender, or age.
Testing Your YOLOv8 Model
To test your YOLOv8 model, you can use the validation mode. It's a straightforward way to understand the model's strengths and areas that need improvement. Also, you'll need to format your test dataset correctly for YOLOv8. For more details on how to use the validation mode, check out the Model Validation docs page.
Using YOLOv8 to Predict on Multiple Test Images
If you want to test your trained YOLOv8 model on multiple images stored in a folder, you can easily do so in one go. Instead of using the validation mode, which is typically used to evaluate model performance on a validation set and provide detailed metrics, you might just want to see predictions on all images in your test set. For this, you can use the prediction mode.
Difference Between Validation and Prediction Modes
- Validation Mode: Used to evaluate the model's performance by comparing predictions against known labels (ground truth). It provides detailed metrics such as accuracy, precision, recall, and F1 score.
- Prediction Mode: Used to run the model on new, unseen data to generate predictions. It does not provide detailed performance metrics but allows you to see how the model performs on real-world images.
Running YOLOv8 Predictions Without Custom Training
If you are interested in testing the basic YOLOv8 model to understand whether it can be used for your application without custom training, you can use the prediction mode. While the model is pre-trained on datasets like COCO, running predictions on your own dataset can give you a quick sense of how well it might perform in your specific context.
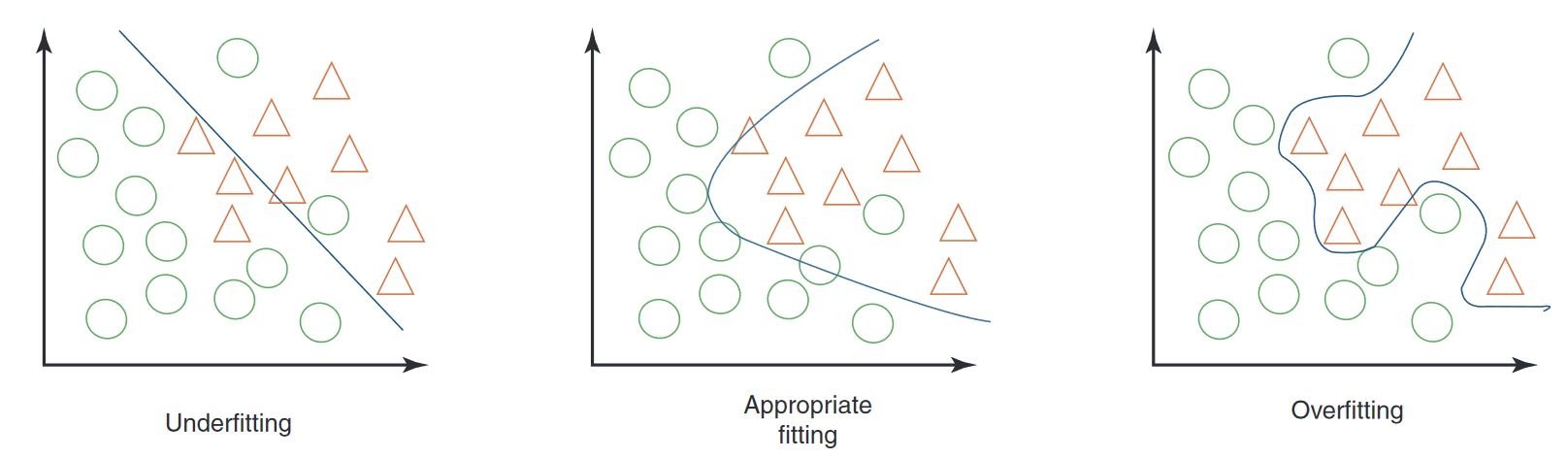
Overfitting and Underfitting in Machine Learning
When testing a machine learning model, especially in computer vision, it's important to watch out for overfitting and underfitting. These issues can significantly affect how well your model works with new data.
Overfitting
Overfitting happens when your model learns the training data too well, including the noise and details that don't generalize to new data. In computer vision, this means your model might do great with training images but struggle with new ones.
Signs of Overfitting
- High Training Accuracy, Low Validation Accuracy: If your model performs very well on training data but poorly on validation or test data, it's likely overfitting.
- Visual Inspection: Sometimes, you can see overfitting if your model is too sensitive to minor changes or irrelevant details in images.
Underfitting
Underfitting occurs when your model can't capture the underlying patterns in the data. In computer vision, an underfitted model might not even recognize objects correctly in the training images.
Signs of Underfitting
- Low Training Accuracy: If your model can't achieve high accuracy on the training set, it might be underfitting.
- Visual Misclassification: Consistent failure to recognize obvious features or objects suggests underfitting.
Balancing Overfitting and Underfitting
The key is to find a balance between overfitting and underfitting. Ideally, a model should perform well on both training and validation datasets. Regularly monitoring your model's performance through metrics and visual inspections, along with applying the right strategies, can help you achieve the best results.
Data Leakage in Computer Vision and How to Avoid It
While testing your model, something important to keep in mind is data leakage. Data leakage happens when information from outside the training dataset accidentally gets used to train the model. The model may seem very accurate during training, but it won't perform well on new, unseen data when data leakage occurs.
Why Data Leakage Happens
Data leakage can be tricky to spot and often comes from hidden biases in the training data. Here are some common ways it can happen in computer vision:
- Camera Bias: Different angles, lighting, shadows, and camera movements can introduce unwanted patterns.
- Overlay Bias: Logos, timestamps, or other overlays in images can mislead the model.
- Font and Object Bias: Specific fonts or objects that frequently appear in certain classes can skew the model's learning.
- Spatial Bias: Imbalances in foreground-background, bounding box distributions, and object locations can affect training.
- Label and Domain Bias: Incorrect labels or shifts in data types can lead to leakage.
Detecting Data Leakage
To find data leakage, you can:
- Check Performance: If the model's results are surprisingly good, it might be leaking.
- Look at Feature Importance: If one feature is much more important than others, it could indicate leakage.
- Visual Inspection: Double-check that the model's decisions make sense intuitively.
- Verify Data Separation: Make sure data was divided correctly before any processing.
Avoiding Data Leakage
To prevent data leakage, use a diverse dataset with images or videos from different cameras and environments. Carefully review your data and check that there are no hidden biases, such as all positive samples being taken at a specific time of day. Avoiding data leakage will help make your computer vision models more reliable and effective in real-world situations.
What Comes After Model Testing
After testing your model, the next steps depend on the results. If your model performs well, you can deploy it into a real-world environment. If the results aren't satisfactory, you'll need to make improvements. This might involve analyzing errors, gathering more data, improving data quality, adjusting hyperparameters, and retraining the model.
Join the AI Conversation
Becoming part of a community of computer vision enthusiasts can aid in solving problems and learning more efficiently. Here are some ways to connect, seek help, and share your thoughts.
Community Resources
- GitHub Issues: Explore the YOLOv8 GitHub repository and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are very active and ready to help.
- Ultralytics Discord Server: Join the Ultralytics Discord server to chat with other users and developers, get support, and share your experiences.
Official Documentation
- Ultralytics YOLOv8 Documentation: Check out the official YOLOv8 documentation for detailed guides and helpful tips on various computer vision projects.
These resources will help you navigate challenges and remain updated on the latest trends and practices within the computer vision community.
In Summary
Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like overfitting and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
FAQ
What are the key differences between model evaluation and model testing in computer vision?
Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as accuracy, precision, recall, and F1 score, providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the steps in a computer vision project.
How can I test my Ultralytics YOLOv8 model on multiple images?
To test your Ultralytics YOLOv8 model on multiple images, you can use the prediction mode. This mode allows you to run the model on new, unseen data to generate predictions without providing detailed metrics. This is ideal for real-world performance testing on larger image sets stored in a folder. For evaluating performance metrics, use the validation mode instead.
What should I do if my computer vision model shows signs of overfitting or underfitting?
To address overfitting:
- Regularization techniques like dropout.
- Increase the size of the training dataset.
- Simplify the model architecture.
To address underfitting:
- Use a more complex model.
- Provide more relevant features.
- Increase training iterations or epochs.
Review misclassified images, perform thorough error analysis, and regularly track performance metrics to maintain a balance. For more information on these concepts, explore our section on Overfitting and Underfitting.
How can I detect and avoid data leakage in computer vision?
To detect data leakage:
- Verify that the testing performance is not unusually high.
- Check feature importance for unexpected insights.
- Intuitively review model decisions.
- Ensure correct data division before processing.
To avoid data leakage:
- Use diverse datasets with various environments.
- Carefully review data for hidden biases.
- Ensure no overlapping information between training and testing sets.
For detailed strategies on preventing data leakage, refer to our section on Data Leakage in Computer Vision.
What steps should I take after testing my computer vision model?
Post-testing, if the model performance meets the project goals, proceed with deployment. If the results are unsatisfactory, consider:
- Error analysis.
- Gathering more diverse and high-quality data.
- Hyperparameter tuning.
- Retraining the model.
Gain insights from the Model Testing Vs. Model Evaluation section to refine and enhance model effectiveness in real-world applications.
How do I run YOLOv8 predictions without custom training?
You can run predictions using the pre-trained YOLOv8 model on your dataset to see if it suits your application needs. Utilize the prediction mode to get a quick sense of performance results without diving into custom training.