20 KiB
| comments | description | keywords |
|---|---|---|
| true | Discover the power of deploying your Ultralytics YOLOv8 model using OpenVINO format for up to 10x speedup vs PyTorch. | ultralytics docs, YOLOv8, export YOLOv8, YOLOv8 model deployment, exporting YOLOv8, OpenVINO, OpenVINO format |
Intel OpenVINO Export
In this guide, we cover exporting YOLOv8 models to the OpenVINO format, which can provide up to 3x CPU speedup, as well as accelerating YOLO inference on Intel GPU and NPU hardware.
OpenVINO, short for Open Visual Inference & Neural Network Optimization toolkit, is a comprehensive toolkit for optimizing and deploying AI inference models. Even though the name contains Visual, OpenVINO also supports various additional tasks including language, audio, time series, etc.
Watch: How To Export and Optimize an Ultralytics YOLOv8 Model for Inference with OpenVINO.
Usage Examples
Export a YOLOv8n model to OpenVINO format and run inference with the exported model.
!!! Example
=== "Python"
```python
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO('yolov8n.pt')
# Export the model
model.export(format='openvino') # creates 'yolov8n_openvino_model/'
# Load the exported OpenVINO model
ov_model = YOLO('yolov8n_openvino_model/')
# Run inference
results = ov_model('https://ultralytics.com/images/bus.jpg')
```
=== "CLI"
```bash
# Export a YOLOv8n PyTorch model to OpenVINO format
yolo export model=yolov8n.pt format=openvino # creates 'yolov8n_openvino_model/'
# Run inference with the exported model
yolo predict model=yolov8n_openvino_model source='https://ultralytics.com/images/bus.jpg'
```
Arguments
| Key | Value | Description |
|---|---|---|
format |
'openvino' |
format to export to |
imgsz |
640 |
image size as scalar or (h, w) list, i.e. (640, 480) |
half |
False |
FP16 quantization |
Benefits of OpenVINO
- Performance: OpenVINO delivers high-performance inference by utilizing the power of Intel CPUs, integrated and discrete GPUs, and FPGAs.
- Support for Heterogeneous Execution: OpenVINO provides an API to write once and deploy on any supported Intel hardware (CPU, GPU, FPGA, VPU, etc.).
- Model Optimizer: OpenVINO provides a Model Optimizer that imports, converts, and optimizes models from popular deep learning frameworks such as PyTorch, TensorFlow, TensorFlow Lite, Keras, ONNX, PaddlePaddle, and Caffe.
- Ease of Use: The toolkit comes with more than 80 tutorial notebooks (including YOLOv8 optimization) teaching different aspects of the toolkit.
OpenVINO Export Structure
When you export a model to OpenVINO format, it results in a directory containing the following:
- XML file: Describes the network topology.
- BIN file: Contains the weights and biases binary data.
- Mapping file: Holds mapping of original model output tensors to OpenVINO tensor names.
You can use these files to run inference with the OpenVINO Inference Engine.
Using OpenVINO Export in Deployment
Once you have the OpenVINO files, you can use the OpenVINO Runtime to run the model. The Runtime provides a unified API to inference across all supported Intel hardware. It also provides advanced capabilities like load balancing across Intel hardware and asynchronous execution. For more information on running the inference, refer to the Inference with OpenVINO Runtime Guide.
Remember, you'll need the XML and BIN files as well as any application-specific settings like input size, scale factor for normalization, etc., to correctly set up and use the model with the Runtime.
In your deployment application, you would typically do the following steps:
- Initialize OpenVINO by creating
core = Core(). - Load the model using the
core.read_model()method. - Compile the model using the
core.compile_model()function. - Prepare the input (image, text, audio, etc.).
- Run inference using
compiled_model(input_data).
For more detailed steps and code snippets, refer to the OpenVINO documentation or API tutorial.
OpenVINO YOLOv8 Benchmarks
YOLOv8 benchmarks below were run by the Ultralytics team on 4 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX and OpenVINO. Benchmarks were run on Intel Flex and Arc GPUs, and on Intel Xeon CPUs at FP32 precision (with the half=False argument).
!!! Note
The benchmarking results below are for reference and might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run.
All benchmarks run with `openvino` Python package version [2023.0.1](https://pypi.org/project/openvino/2023.0.1/).
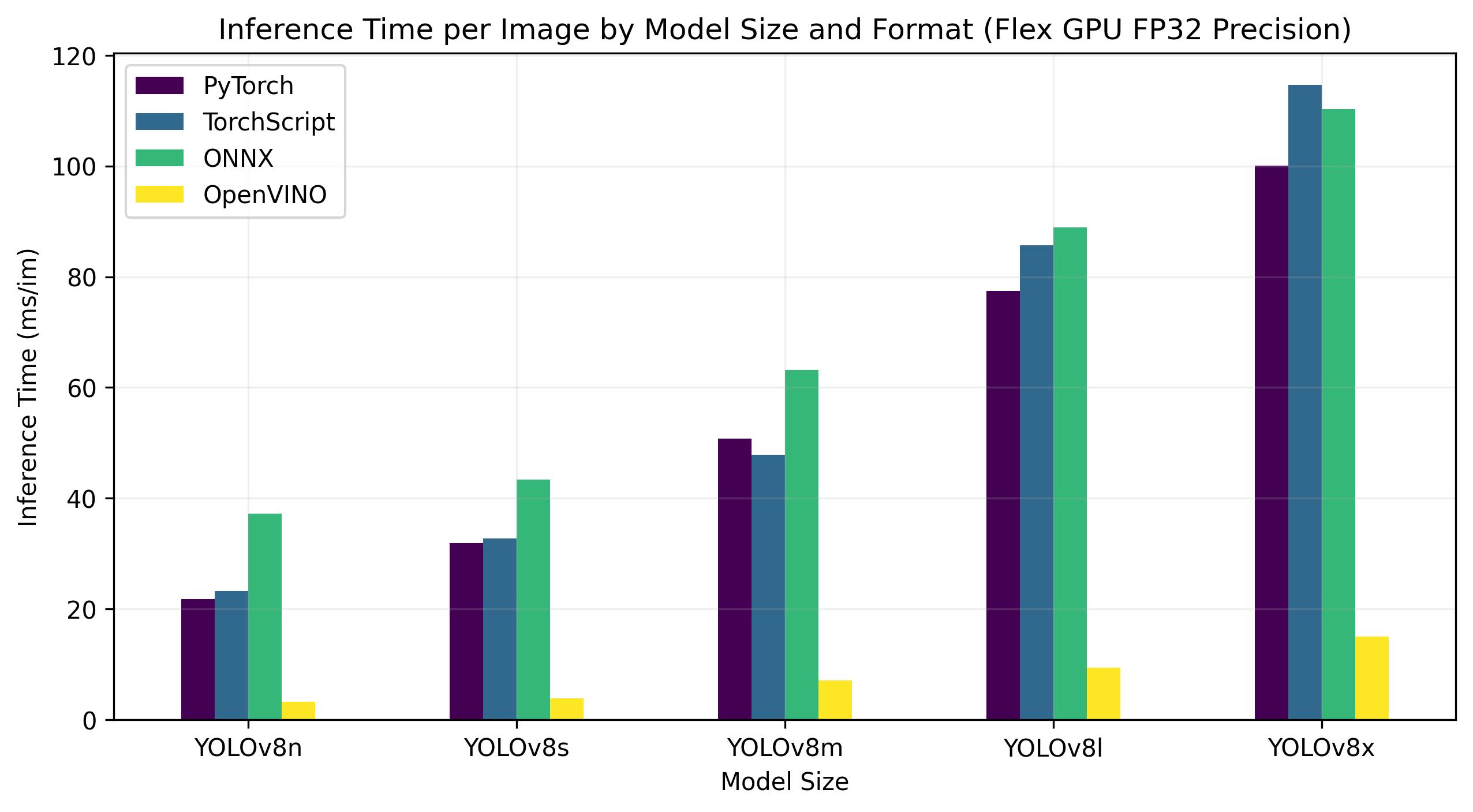
Intel Flex GPU
The Intel® Data Center GPU Flex Series is a versatile and robust solution designed for the intelligent visual cloud. This GPU supports a wide array of workloads including media streaming, cloud gaming, AI visual inference, and virtual desktop Infrastructure workloads. It stands out for its open architecture and built-in support for the AV1 encode, providing a standards-based software stack for high-performance, cross-architecture applications. The Flex Series GPU is optimized for density and quality, offering high reliability, availability, and scalability.
Benchmarks below run on Intel® Data Center GPU Flex 170 at FP32 precision.
| Model | Format | Status | Size (MB) | mAP50-95(B) | Inference time (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 21.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.24 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 37.22 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 3.29 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 31.89 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 32.71 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.42 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4470 | 3.92 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 50.75 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 47.90 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 63.16 |
| YOLOv8m | OpenVINO | ✅ | 49.8 | 0.4997 | 7.11 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 77.45 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 85.71 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.94 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5264 | 9.37 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 100.09 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.64 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 110.32 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 15.02 |
This table represents the benchmark results for five different models (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) across four different formats (PyTorch, TorchScript, ONNX, OpenVINO), giving us the status, size, mAP50-95(B) metric, and inference time for each combination.
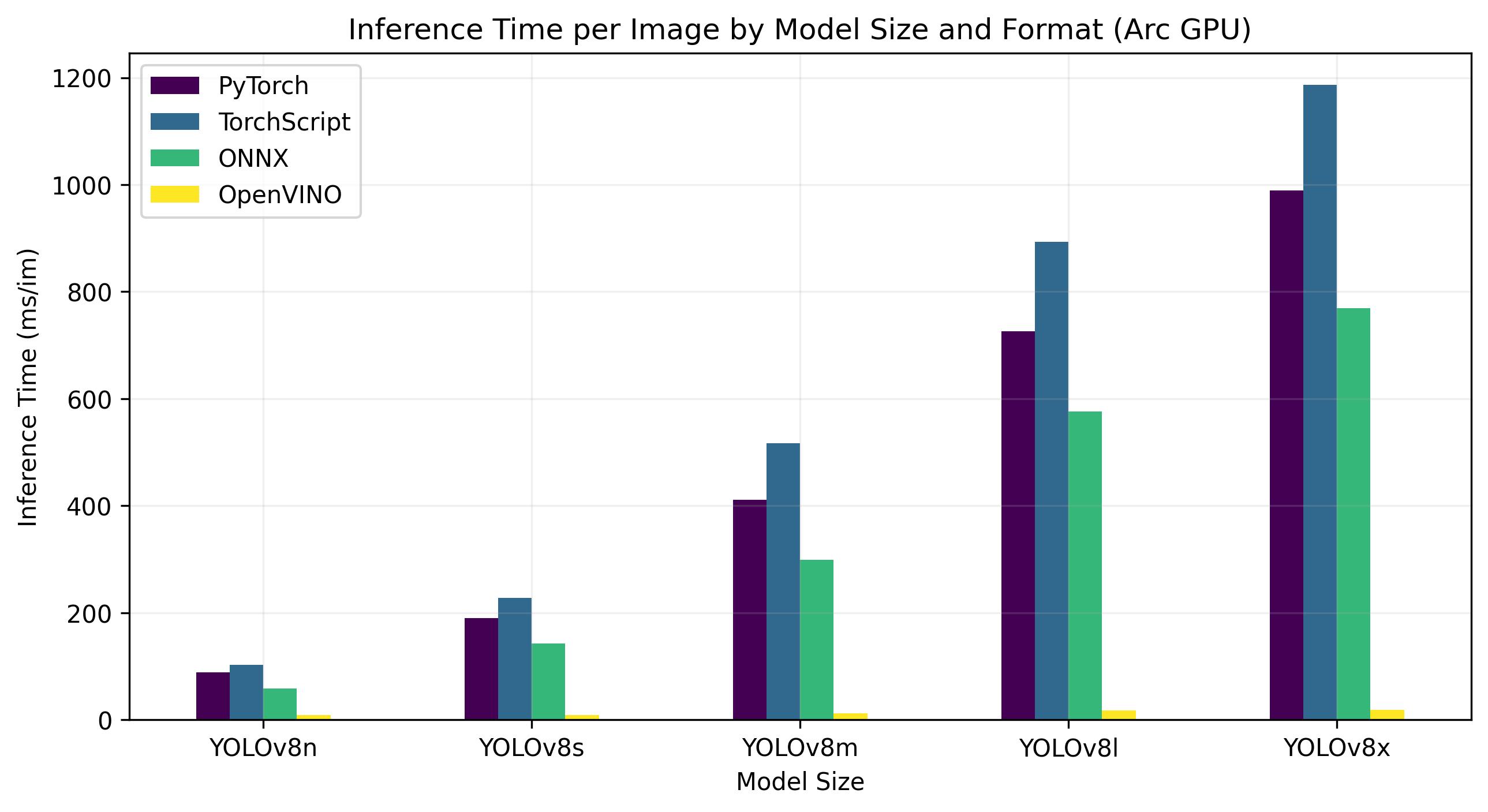
Intel Arc GPU
Intel® Arc™ represents Intel's foray into the dedicated GPU market. The Arc™ series, designed to compete with leading GPU manufacturers like AMD and Nvidia, caters to both the laptop and desktop markets. The series includes mobile versions for compact devices like laptops, and larger, more powerful versions for desktop computers.
The Arc™ series is divided into three categories: Arc™ 3, Arc™ 5, and Arc™ 7, with each number indicating the performance level. Each category includes several models, and the 'M' in the GPU model name signifies a mobile, integrated variant.
Early reviews have praised the Arc™ series, particularly the integrated A770M GPU, for its impressive graphics performance. The availability of the Arc™ series varies by region, and additional models are expected to be released soon. Intel® Arc™ GPUs offer high-performance solutions for a range of computing needs, from gaming to content creation.
Benchmarks below run on Intel® Arc 770 GPU at FP32 precision.
| Model | Format | Status | Size (MB) | metrics/mAP50-95(B) | Inference time (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 88.79 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 102.66 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 57.98 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3703 | 8.52 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 189.83 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 227.58 |
| YOLOv8s | ONNX | ✅ | 42.7 | 0.4472 | 142.03 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4469 | 9.19 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 411.64 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 517.12 |
| YOLOv8m | ONNX | ✅ | 98.9 | 0.4999 | 298.68 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 12.55 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 725.73 |
| YOLOv8l | TorchScript | ✅ | 167.1 | 0.5268 | 892.83 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 576.11 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5262 | 17.62 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 988.92 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 1186.42 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 768.90 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5367 | 19 |
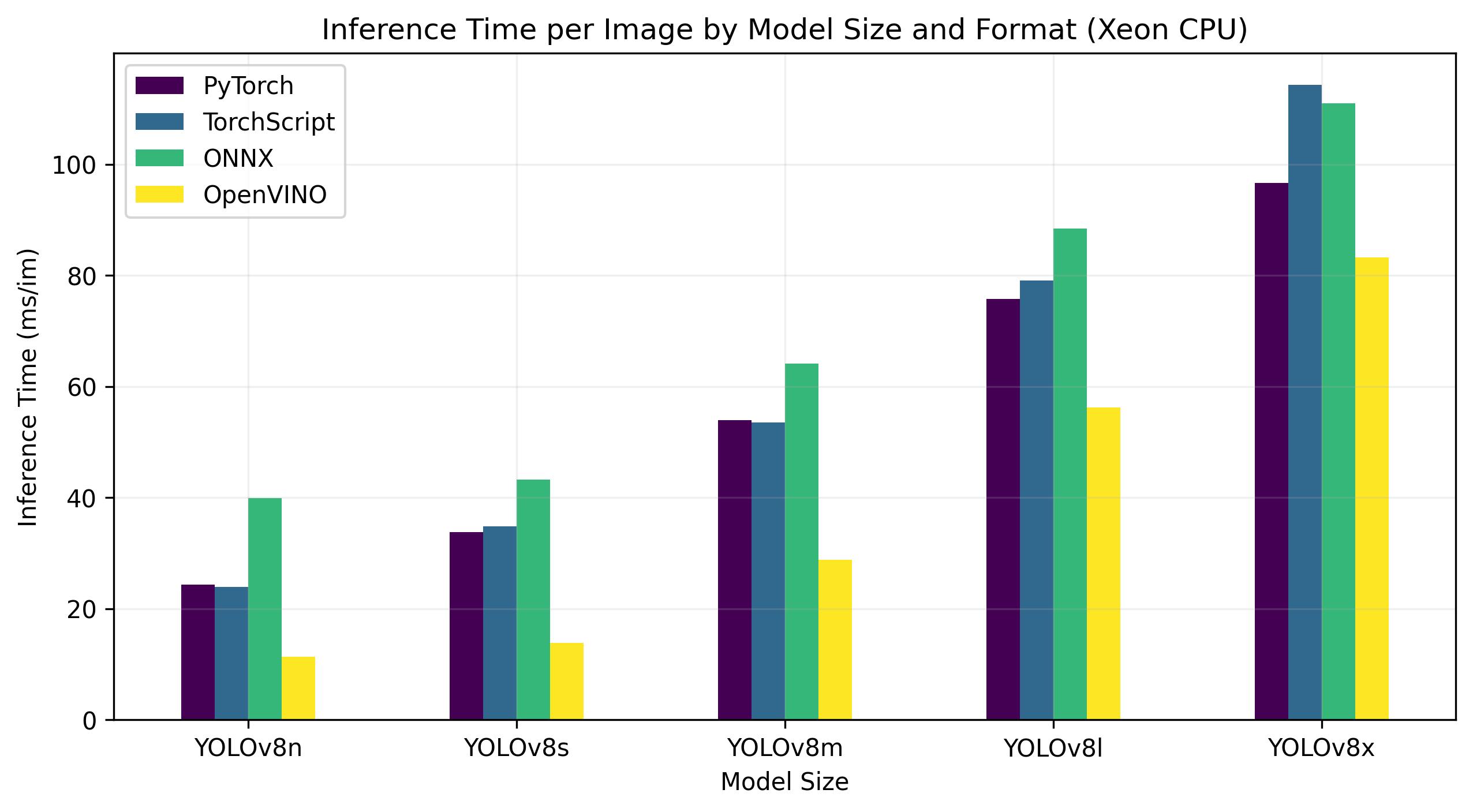
Intel Xeon CPU
The Intel® Xeon® CPU is a high-performance, server-grade processor designed for complex and demanding workloads. From high-end cloud computing and virtualization to artificial intelligence and machine learning applications, Xeon® CPUs provide the power, reliability, and flexibility required for today's data centers.
Notably, Xeon® CPUs deliver high compute density and scalability, making them ideal for both small businesses and large enterprises. By choosing Intel® Xeon® CPUs, organizations can confidently handle their most demanding computing tasks and foster innovation while maintaining cost-effectiveness and operational efficiency.
Benchmarks below run on 4th Gen Intel® Xeon® Scalable CPU at FP32 precision.
| Model | Format | Status | Size (MB) | metrics/mAP50-95(B) | Inference time (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.3709 | 24.36 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.3704 | 23.93 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.3704 | 39.86 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.3704 | 11.34 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.4471 | 33.77 |
| YOLOv8s | TorchScript | ✅ | 42.9 | 0.4472 | 34.84 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.4472 | 43.23 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.4471 | 13.86 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.5013 | 53.91 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.4999 | 53.51 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.4999 | 64.16 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.4996 | 28.79 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.5293 | 75.78 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.5268 | 79.13 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.5268 | 88.45 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.5263 | 56.23 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.5404 | 96.60 |
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.5371 | 114.28 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.5371 | 111.02 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.5371 | 83.28 |
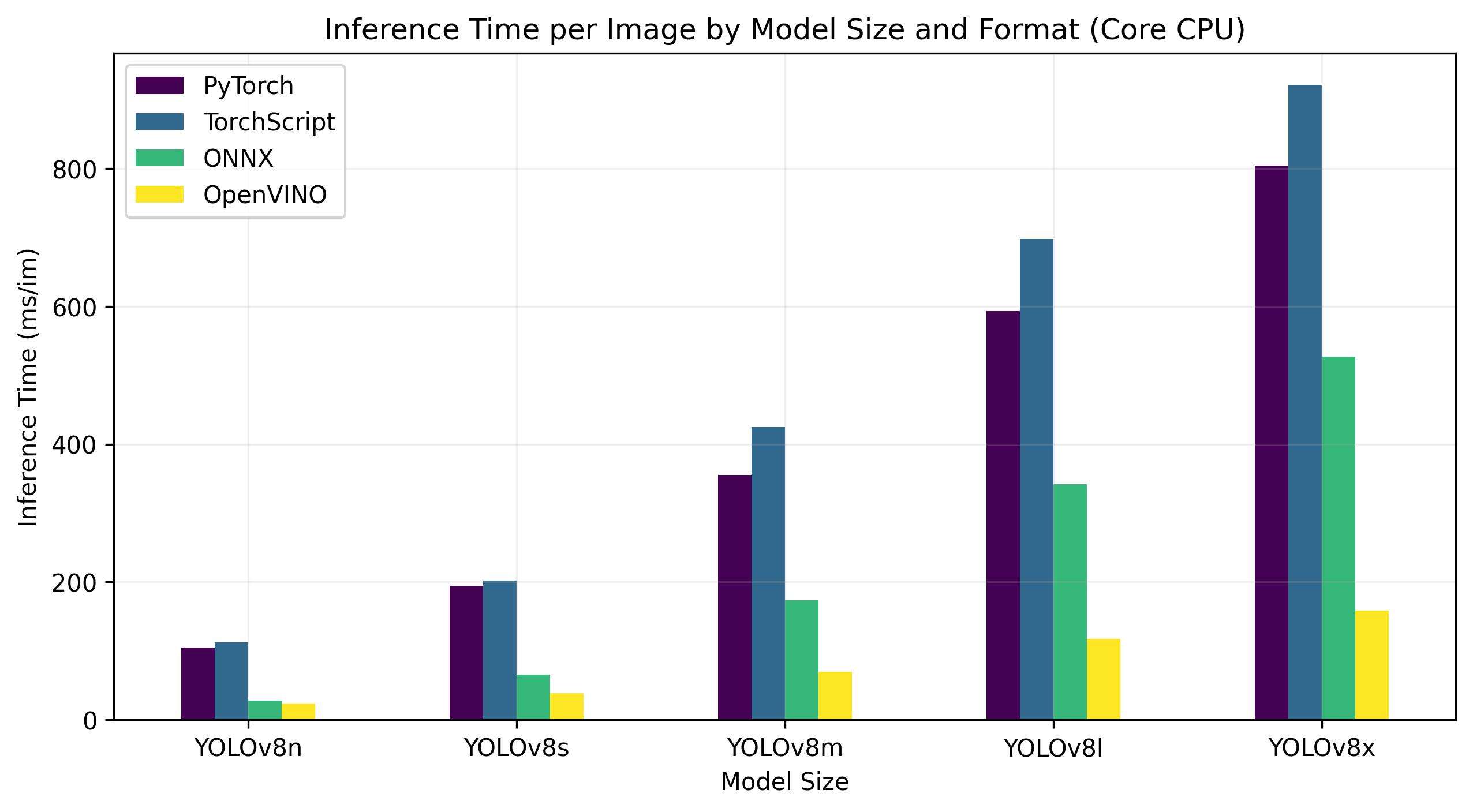
Intel Core CPU
The Intel® Core® series is a range of high-performance processors by Intel. The lineup includes Core i3 (entry-level), Core i5 (mid-range), Core i7 (high-end), and Core i9 (extreme performance). Each series caters to different computing needs and budgets, from everyday tasks to demanding professional workloads. With each new generation, improvements are made to performance, energy efficiency, and features.
Benchmarks below run on 13th Gen Intel® Core® i7-13700H CPU at FP32 precision.
| Model | Format | Status | Size (MB) | metrics/mAP50-95(B) | Inference time (ms/im) |
|---|---|---|---|---|---|
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4478 | 104.61 |
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4525 | 112.39 |
| YOLOv8n | ONNX | ✅ | 12.2 | 0.4525 | 28.02 |
| YOLOv8n | OpenVINO | ✅ | 12.3 | 0.4504 | 23.53 |
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5885 | 194.83 |
| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5962 | 202.01 |
| YOLOv8s | ONNX | ✅ | 42.8 | 0.5962 | 65.74 |
| YOLOv8s | OpenVINO | ✅ | 42.9 | 0.5966 | 38.66 |
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 355.23 |
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6120 | 424.78 |
| YOLOv8m | ONNX | ✅ | 99.0 | 0.6120 | 173.39 |
| YOLOv8m | OpenVINO | ✅ | 99.1 | 0.6091 | 69.80 |
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6591 | 593.00 |
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6580 | 697.54 |
| YOLOv8l | ONNX | ✅ | 166.8 | 0.6580 | 342.15 |
| YOLOv8l | OpenVINO | ✅ | 167.0 | 0.0708 | 117.69 |
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6651 | 804.65 |
| YOLOv8x | TorchScript | ✅ | 260.8 | 0.6650 | 921.46 |
| YOLOv8x | ONNX | ✅ | 260.4 | 0.6650 | 526.66 |
| YOLOv8x | OpenVINO | ✅ | 260.6 | 0.6619 | 158.73 |
Reproduce Our Results
To reproduce the Ultralytics benchmarks above on all export formats run this code:
!!! Example
=== "Python"
```python
from ultralytics import YOLO
# Load a YOLOv8n PyTorch model
model = YOLO('yolov8n.pt')
# Benchmark YOLOv8n speed and accuracy on the COCO128 dataset for all all export formats
results= model.benchmarks(data='coco128.yaml')
```
=== "CLI"
```bash
# Benchmark YOLOv8n speed and accuracy on the COCO128 dataset for all all export formats
yolo benchmark model=yolov8n.pt data=coco128.yaml
```
Note that benchmarking results might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run. For the most reliable results use a dataset with a large number of images, i.e. `data='coco128.yaml' (128 val images), or `data='coco.yaml'` (5000 val images).
Conclusion
The benchmarking results clearly demonstrate the benefits of exporting the YOLOv8 model to the OpenVINO format. Across different models and hardware platforms, the OpenVINO format consistently outperforms other formats in terms of inference speed while maintaining comparable accuracy.
For the Intel® Data Center GPU Flex Series, the OpenVINO format was able to deliver inference speeds almost 10 times faster than the original PyTorch format. On the Xeon CPU, the OpenVINO format was twice as fast as the PyTorch format. The accuracy of the models remained nearly identical across the different formats.
The benchmarks underline the effectiveness of OpenVINO as a tool for deploying deep learning models. By converting models to the OpenVINO format, developers can achieve significant performance improvements, making it easier to deploy these models in real-world applications.
For more detailed information and instructions on using OpenVINO, refer to the official OpenVINO documentation.