---
comments: true
description: Explore how to improve your Ultralytics YOLOv8 model's performance and interoperability using the ONNX (Open Neural Network Exchange) export format that is suitable for diverse hardware and software environments.
keywords: Ultralytics, YOLOv8, ONNX Format, Export YOLOv8, CUDA Support, Model Deployment
---
# ONNX Export for YOLOv8 Models
Often, when deploying computer vision models, you’ll need a model format that's both flexible and compatible with multiple platforms.
Exporting [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models to ONNX format streamlines deployment and ensures optimal performance across various environments. This guide will show you how to easily convert your YOLOv8 models to ONNX and enhance their scalability and effectiveness in real-world applications.
## ONNX and ONNX Runtime
[ONNX](https://onnx.ai/), which stands for Open Neural Network Exchange, is a community project that Facebook and Microsoft initially developed. The ongoing development of ONNX is a collaborative effort supported by various organizations like IBM, Amazon (through AWS), and Google. The project aims to create an open file format designed to represent machine learning models in a way that allows them to be used across different AI frameworks and hardware.
ONNX models can be used to transition between different frameworks seamlessly. For instance, a deep learning model trained in PyTorch can be exported to ONNX format and then easily imported into TensorFlow.
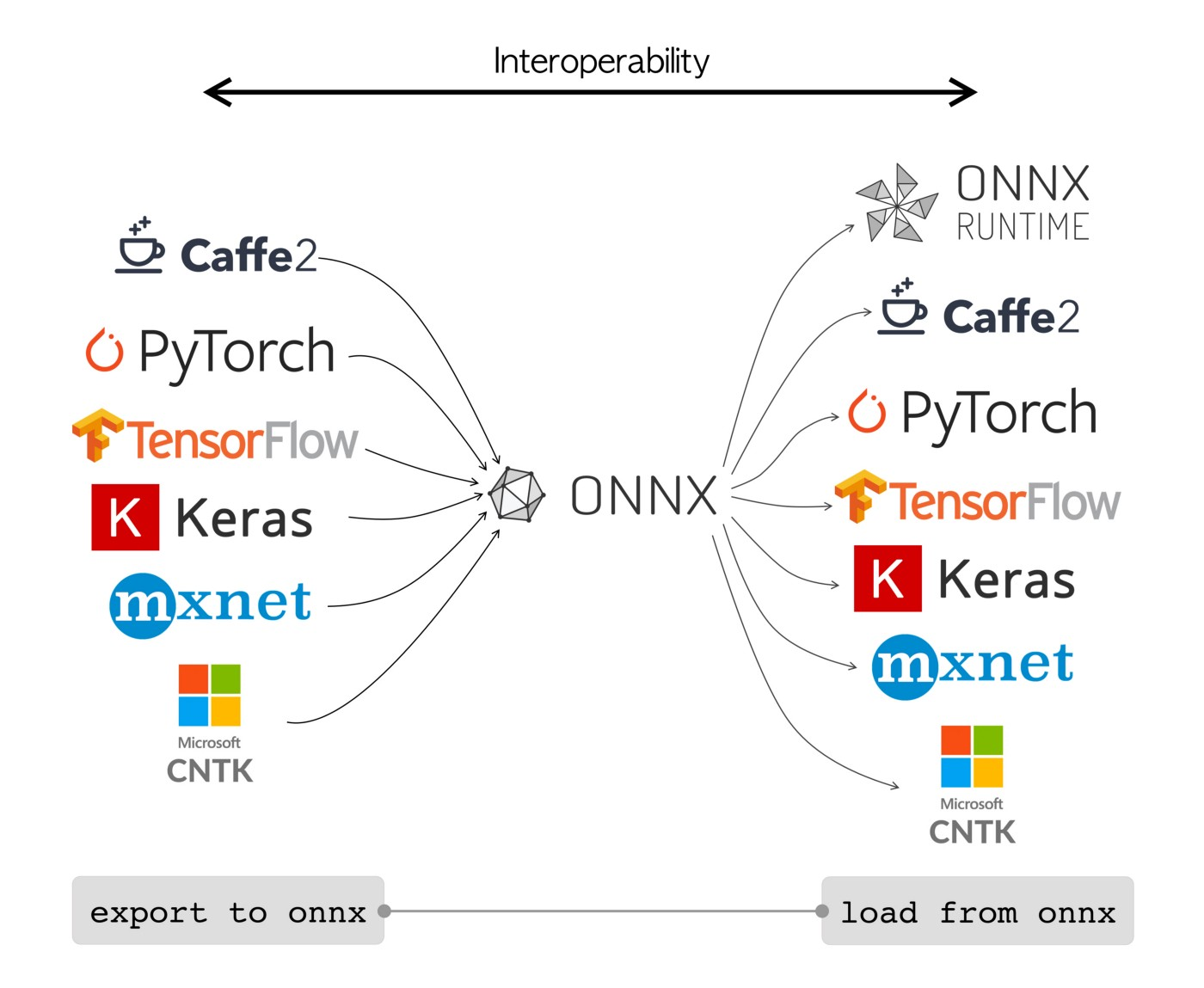
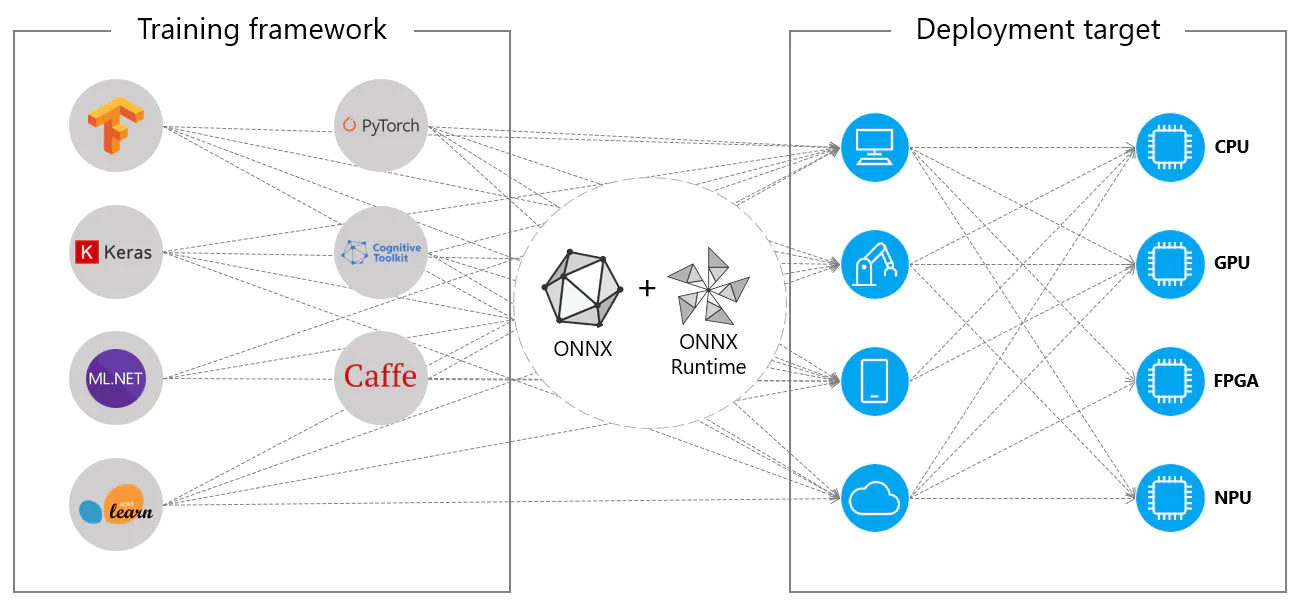
Alternatively, ONNX models can be used with ONNX Runtime. [ONNX Runtime](https://onnxruntime.ai/) is a versatile cross-platform accelerator for machine learning models that is compatible with frameworks like PyTorch, TensorFlow, TFLite, scikit-learn, etc.
ONNX Runtime optimizes the execution of ONNX models by leveraging hardware-specific capabilities. This optimization allows the models to run efficiently and with high performance on various hardware platforms, including CPUs, GPUs, and specialized accelerators.
Whether used independently or in tandem with ONNX Runtime, ONNX provides a flexible solution for machine learning model deployment and compatibility.
## Key Features of ONNX Models
The ability of ONNX to handle various formats can be attributed to the following key features:
- **Common Model Representation**: ONNX defines a common set of operators (like convolutions, layers, etc.) and a standard data format. When a model is converted to ONNX format, its architecture and weights are translated into this common representation. This uniformity ensures that the model can be understood by any framework that supports ONNX.
- **Versioning and Backward Compatibility**: ONNX maintains a versioning system for its operators. This ensures that even as the standard evolves, models created in older versions remain usable. Backward compatibility is a crucial feature that prevents models from becoming obsolete quickly.
- **Graph-based Model Representation**: ONNX represents models as computational graphs. This graph-based structure is a universal way of representing machine learning models, where nodes represent operations or computations, and edges represent the tensors flowing between them. This format is easily adaptable to various frameworks which also represent models as graphs.
- **Tools and Ecosystem**: There is a rich ecosystem of tools around ONNX that assist in model conversion, visualization, and optimization. These tools make it easier for developers to work with ONNX models and to convert models between different frameworks seamlessly.
## Common Usage of ONNX
Before we jump into how to export YOLOv8 models to the ONNX format, let’s take a look at where ONNX models are usually used.
### CPU Deployment
ONNX models are often deployed on CPUs due to their compatibility with ONNX Runtime. This runtime is optimized for CPU execution. It significantly improves inference speed and makes real-time CPU deployments feasible.
### Supported Deployment Options
While ONNX models are commonly used on CPUs, they can also be deployed on the following platforms:
- **GPU Acceleration**: ONNX fully supports GPU acceleration, particularly NVIDIA CUDA. This enables efficient execution on NVIDIA GPUs for tasks that demand high computational power.
- **Edge and Mobile Devices**: ONNX extends to edge and mobile devices, perfect for on-device and real-time inference scenarios. It's lightweight and compatible with edge hardware.
- **Web Browsers**: ONNX can run directly in web browsers, powering interactive and dynamic web-based AI applications.
## Exporting YOLOv8 Models to ONNX
You can expand model compatibility and deployment flexibility by converting YOLOv8 models to ONNX format.
### Installation
To install the required package, run:
!!! Tip "Installation"
=== "CLI"
```bash
# Install the required package for YOLOv8
pip install ultralytics
```
For detailed instructions and best practices related to the installation process, check our [YOLOv8 Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
### Usage
Before diving into the usage instructions, be sure to check out the range of [YOLOv8 models offered by Ultralytics](../models/index.md). This will help you choose the most appropriate model for your project requirements.
!!! Example "Usage"
=== "Python"
```python
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Export the model to ONNX format
model.export(format='onnx') # creates 'yolov8n.onnx'
# Load the exported ONNX model
onnx_model = YOLO('yolov8n.onnx')
# Run inference
results = onnx_model('https://ultralytics.com/images/bus.jpg')
```
=== "CLI"
```bash
# Export a YOLOv8n PyTorch model to ONNX format
yolo export model=yolov8n.pt format=onnx # creates 'yolov8n.onnx'
# Run inference with the exported model
yolo predict model=yolov8n.onnx source='https://ultralytics.com/images/bus.jpg'
```
For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md).
## Deploying Exported YOLOv8 ONNX Models
Once you've successfully exported your Ultralytics YOLOv8 models to ONNX format, the next step is deploying these models in various environments. For detailed instructions on deploying your ONNX models, take a look at the following resources:
- **[ONNX Runtime Python API Documentation](https://onnxruntime.ai/docs/api/python/api_summary.html)**: This guide provides essential information for loading and running ONNX models using ONNX Runtime.
- **[Deploying on Edge Devices](https://onnxruntime.ai/docs/tutorials/iot-edge/)**: Check out this docs page for different examples of deploying ONNX models on edge.
- **[ONNX Tutorials on GitHub](https://github.com/onnx/tutorials)**: A collection of comprehensive tutorials that cover various aspects of using and implementing ONNX models in different scenarios.
## Summary
In this guide, you've learned how to export Ultralytics YOLOv8 models to ONNX format to increase their interoperability and performance across various platforms. You were also introduced to the ONNX Runtime and ONNX deployment options.
For further details on usage, visit the [ONNX official documentation](https://onnx.ai/onnx/intro/).
Also, if you’d like to know more about other Ultralytics YOLOv8 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of useful resources and insights there.