---
comments: true
description: Understand the key practices for monitoring, maintaining, and documenting computer vision models to guarantee accuracy, spot anomalies, and mitigate data drift.
keywords: Computer Vision Models, AI Model Monitoring, Data Drift Detection, Anomaly Detection in AI, Model Monitoring
---
# Maintaining Your Computer Vision Models After Deployment
## Introduction
If you are here, we can assume you've completed many [steps in your computer vision project](./steps-of-a-cv-project.md): from [gathering requirements](./defining-project-goals.md), [annotating data](./data-collection-and-annotation.md), and [training the model](./model-training-tips.md) to finally [deploying](./model-deployment-practices.md) it. Your application is now running in production, but your project doesn't end here. The most important part of a computer vision project is making sure your model continues to fulfill your [project's objectives](./defining-project-goals.md) over time, and that's where monitoring, maintaining, and documenting your computer vision model enters the picture.
In this guide, we'll take a closer look at how you can maintain your computer vision models after deployment. We'll explore how model monitoring can help you catch problems early on, how to keep your model accurate and up-to-date, and why documentation is important for troubleshooting.
## Model Monitoring is Key
Keeping a close eye on your deployed computer vision models is essential. Without proper monitoring, models can lose accuracy. A common issue is data distribution shift or data drift, where the data the model encounters changes from what it was trained on. When the model has to make predictions on data it doesn't recognize, it can lead to misinterpretations and poor performance. Outliers, or unusual data points, can also throw off the model's accuracy.
Regular model monitoring helps developers track the [model's performance](./model-evaluation-insights.md), spot anomalies, and quickly address problems like data drift. It also helps manage resources by indicating when updates are needed, avoiding expensive overhauls, and keeping the model relevant.
### Best Practices for Model Monitoring
Here are some best practices to keep in mind while monitoring your computer vision model in production:
- **Track Performance Regularly**: Continuously monitor the model's performance to detect changes over time.
- **Double Check the Data Quality**: Check for missing values or anomalies in the data.
- **Use Diverse Data Sources**: Monitor data from various sources to get a comprehensive view of the model's performance.
- **Combine Monitoring Techniques**: Use a mix of drift detection algorithms and rule-based approaches to identify a wide range of issues.
- **Monitor Inputs and Outputs**: Keep an eye on both the data the model processes and the results it produces to make sure everything is functioning correctly.
- **Set Up Alerts**: Implement alerts for unusual behavior, such as performance drops, to be able to make quick corrective actions.
### Tools for AI Model Monitoring
You can use automated monitoring tools to make it easier to monitor models after deployment. Many tools offer real-time insights and alerting capabilities. Here are some examples of open-source model monitoring tools that can work together:
- **[Prometheus](https://prometheus.io/)**: Prometheus is an open-source monitoring tool that collects and stores metrics for detailed performance tracking. It integrates easily with Kubernetes and Docker, collecting data at set intervals and storing it in a time-series database. Prometheus can also scrape HTTP endpoints to gather real-time metrics. Collected data can be queried using the PromQL language.
- **[Grafana](https://grafana.com/)**: Grafana is an open-source data visualization and monitoring tool that allows you to query, visualize, alert on, and understand your metrics no matter where they are stored. It works well with Prometheus and offers advanced data visualization features. You can create custom dashboards to show important metrics for your computer vision models, like inference latency, error rates, and resource usage. Grafana turns collected data into easy-to-read dashboards with line graphs, heat maps, and histograms. It also supports alerts, which can be sent through channels like Slack to quickly notify teams of any issues.
- **[Evidently AI](https://www.evidentlyai.com/)**: Evidently AI is an open-source tool designed for monitoring and debugging machine learning models in production. It generates interactive reports from pandas DataFrames, helping analyze machine learning models. Evidently AI can detect data drift, model performance degradation, and other issues that may arise with your deployed models.
The three tools introduced above, Evidently AI, Prometheus, and Grafana, can work together seamlessly as a fully open-source ML monitoring solution that is ready for production. Evidently AI is used to collect and calculate metrics, Prometheus stores these metrics, and Grafana displays them and sets up alerts. While there are many other tools available, this setup is an exciting open-source option that provides robust capabilities for monitoring and maintaining your models.

### Anomaly Detection and Alert Systems
An anomaly is any data point or pattern that deviates quite a bit from what is expected. With respect to computer vision models, anomalies can be images that are very different from the ones the model was trained on. These unexpected images can be signs of issues like changes in data distribution, outliers, or behaviors that might reduce model performance. Setting up alert systems to detect these anomalies is an important part of model monitoring.
By setting standard performance levels and limits for key metrics, you can catch problems early. When performance goes outside these limits, alerts are triggered, prompting quick fixes. Regularly updating and retraining models with new data keeps them relevant and accurate as the data changes.
#### Things to Keep in Mind When Configuring Thresholds and Alerts
When you are setting up your alert systems, keep these best practices in mind:
- **Standardized Alerts**: Use consistent tools and formats for all alerts, such as email or messaging apps like Slack. Standardization makes it easier for you to quickly understand and respond to alerts.
- **Include Expected Behavior**: Alert messages should clearly state what went wrong, what was expected, and the timeframe evaluated. It helps you gauge the urgency and context of the alert.
- **Configurable Alerts**: Make alerts easily configurable to adapt to changing conditions. Allow yourself to edit thresholds, snooze, disable, or acknowledge alerts.
### Data Drift Detection
Data drift detection is a concept that helps identify when the statistical properties of the input data change over time, which can degrade model performance. Before you decide to retrain or adjust your models, this technique helps spot that there is an issue. Data drift deals with changes in the overall data landscape over time, while anomaly detection focuses on identifying rare or unexpected data points that may require immediate attention.

Here are several methods to detect data drift:
**Continuous Monitoring**: Regularly monitor the model's input data and outputs for signs of drift. Track key metrics and compare them against historical data to identify significant changes.
**Statistical Techniques**: Use methods like the Kolmogorov-Smirnov test or Population Stability Index (PSI) to detect changes in data distributions. These tests compare the distribution of new data with the training data to identify significant differences.
**Feature Drift**: Monitor individual features for drift. Sometimes, the overall data distribution may remain stable, but individual features may drift. Identifying which features are drifting helps in fine-tuning the retraining process.
## Model Maintenance
Model maintenance is crucial to keep computer vision models accurate and relevant over time. Model maintenance involves regularly updating and retraining models, addressing data drift, and ensuring the model stays relevant as data and environments change. You might be wondering how model maintenance differs from model monitoring. Monitoring is about watching the model's performance in real time to catch issues early. Maintenance, on the other hand, is about fixing these issues.
### Regular Updates and Re-training
Once a model is deployed, while monitoring, you may notice changes in data patterns or performance, indicating model drift. Regular updates and re-training become essential parts of model maintenance to ensure the model can handle new patterns and scenarios. There are a few techniques you can use based on how your data is changing.
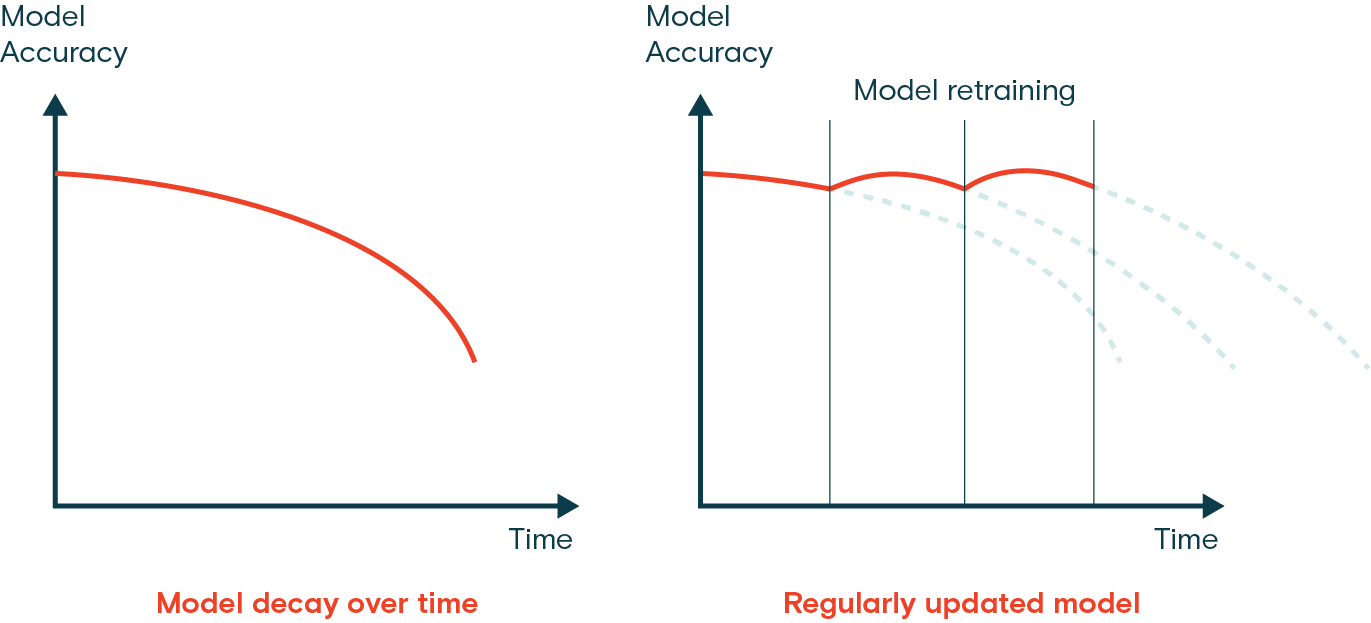
For example, if the data is changing gradually over time, incremental learning is a good approach. Incremental learning involves updating the model with new data without completely retraining it from scratch, saving computational resources and time. However, if the data has changed drastically, a periodic full re-training might be a better option to ensure the model does not overfit on the new data while losing track of older patterns.
Regardless of the method, validation and testing are a must after updates. It is important to validate the model on a separate [test dataset](./model-testing.md) to check for performance improvements or degradation.
### Deciding When to Retrain Your Model
The frequency of retraining your computer vision model depends on data changes and model performance. Retrain your model whenever you observe a significant performance drop or detect data drift. Regular evaluations can help determine the right retraining schedule by testing the model against new data. Monitoring performance metrics and data patterns lets you decide if your model needs more frequent updates to maintain accuracy.

## Documentation
Documenting a computer vision project makes it easier to understand, reproduce, and collaborate on. Good documentation covers model architecture, hyperparameters, datasets, evaluation metrics, and more. It provides transparency, helping team members and stakeholders understand what has been done and why. Documentation also aids in troubleshooting, maintenance, and future enhancements by providing a clear reference of past decisions and methods.
### Key Elements to Document
These are some of the key elements that should be included in project documentation:
- **[Project Overview](./steps-of-a-cv-project.md)**: Provide a high-level summary of the project, including the problem statement, solution approach, expected outcomes, and project scope. Explain the role of computer vision in addressing the problem and outline the stages and deliverables.
- **Model Architecture**: Detail the structure and design of the model, including its components, layers, and connections. Explain the chosen hyperparameters and the rationale behind these choices.
- **[Data Preparation](./data-collection-and-annotation.md)**: Describe the data sources, types, formats, sizes, and preprocessing steps. Discuss data quality, reliability, and any transformations applied before training the model.
- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and loss functions. Explain how the model was trained and any challenges encountered during training.
- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, precision, recall, and F1-score. Include performance results and an analysis of these metrics.
- **[Deployment Steps](./model-deployment-options.md)**: Outline the steps taken to deploy the model, including the tools and platforms used, deployment configurations, and any specific challenges or considerations.
- **Monitoring and Maintenance Procedure**: Provide a detailed plan for monitoring the model's performance post-deployment. Include methods for detecting and addressing data and model drift, and describe the process for regular updates and retraining.
### Tools for Documentation
There are many options when it comes to documenting AI projects, with open-source tools being particularly popular. Two of these are Jupyter Notebooks and MkDocs. Jupyter Notebooks allow you to create interactive documents with embedded code, visualizations, and text, making them ideal for sharing experiments and analyses. MkDocs is a static site generator that is easy to set up and deploy and is perfect for creating and hosting project documentation online.
## Connect with the Community
Joining a community of computer vision enthusiasts can help you solve problems and learn more quickly. Here are some ways to connect, get support, and share ideas.
### Community Resources
- **GitHub Issues:** Check out the [YOLOv8 GitHub repository](https://github.com/ultralytics/ultralytics/issues) and use the Issues tab to ask questions, report bugs, and suggest new features. The community and maintainers are highly active and supportive.
- **Ultralytics Discord Server:** Join the [Ultralytics Discord server](https://ultralytics.com/discord/) to chat with other users and developers, get support, and share your experiences.
### Official Documentation
- **Ultralytics YOLOv8 Documentation:** Visit the [official YOLOv8 documentation](./index.md) for detailed guides and helpful tips on various computer vision projects.
Using these resources will help you solve challenges and stay up-to-date with the latest trends and practices in the computer vision community.
## Key Takeaways
We covered key tips for monitoring, maintaining, and documenting your computer vision models. Regular updates and re-training help the model adapt to new data patterns. Detecting and fixing data drift helps your model stay accurate. Continuous monitoring catches issues early, and good documentation makes collaboration and future updates easier. Following these steps will help your computer vision project stay successful and effective over time.
## FAQ
### How do I monitor the performance of my deployed computer vision model?
Monitoring the performance of your deployed computer vision model is crucial to ensure its accuracy and reliability over time. You can use tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) to track key metrics, detect anomalies, and identify data drift. Regularly monitor inputs and outputs, set up alerts for unusual behavior, and use diverse data sources to get a comprehensive view of your model's performance. For more details, check out our section on [Model Monitoring](#model-monitoring-is-key).
### What are the best practices for maintaining computer vision models after deployment?
Maintaining computer vision models involves regular updates, retraining, and monitoring to ensure continued accuracy and relevance. Best practices include:
- **Continuous Monitoring**: Track performance metrics and data quality regularly.
- **Data Drift Detection**: Use statistical techniques to identify changes in data distributions.
- **Regular Updates and Retraining**: Implement incremental learning or periodic full retraining based on data changes.
- **Documentation**: Maintain detailed documentation of model architecture, training processes, and evaluation metrics. For more insights, visit our [Model Maintenance](#model-maintenance) section.
### Why is data drift detection important for AI models?
Data drift detection is essential because it helps identify when the statistical properties of the input data change over time, which can degrade model performance. Techniques like continuous monitoring, statistical tests (e.g., Kolmogorov-Smirnov test), and feature drift analysis can help spot issues early. Addressing data drift ensures that your model remains accurate and relevant in changing environments. Learn more about data drift detection in our [Data Drift Detection](#data-drift-detection) section.
### What tools can I use for anomaly detection in computer vision models?
For anomaly detection in computer vision models, tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) are highly effective. These tools can help you set up alert systems to detect unusual data points or patterns that deviate from expected behavior. Configurable alerts and standardized messages can help you respond quickly to potential issues. Explore more in our [Anomaly Detection and Alert Systems](#anomaly-detection-and-alert-systems) section.
### How can I document my computer vision project effectively?
Effective documentation of a computer vision project should include:
- **Project Overview**: High-level summary, problem statement, and solution approach.
- **Model Architecture**: Details of the model structure, components, and hyperparameters.
- **Data Preparation**: Information on data sources, preprocessing steps, and transformations.
- **Training Process**: Description of the training procedure, datasets used, and challenges encountered.
- **Evaluation Metrics**: Metrics used for performance evaluation and analysis.
- **Deployment Steps**: Steps taken for model deployment and any specific challenges.
- **Monitoring and Maintenance Procedure**: Plan for ongoing monitoring and maintenance. For more comprehensive guidelines, refer to our [Documentation](#documentation) section.