New Meta Segment Anything Model 2 (SAM2) Docs page (#14794)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: UltralyticsAssistant <web@ultralytics.com>pull/14796/head
parent
6d5a68ec47
commit
ff1fc55aac
9 changed files with 679 additions and 17 deletions
@ -0,0 +1,347 @@ |
||||
--- |
||||
comments: true |
||||
description: Discover SAM2, the next generation of Meta's Segment Anything Model, supporting real-time promptable segmentation in both images and videos with state-of-the-art performance. Learn about its key features, datasets, and how to use it. |
||||
keywords: SAM2, Segment Anything, video segmentation, image segmentation, promptable segmentation, zero-shot performance, SA-V dataset, Ultralytics, real-time segmentation, AI, machine learning |
||||
--- |
||||
|
||||
!!! Note "🚧 SAM2 Integration In Progress 🚧" |
||||
|
||||
The SAM2 features described in this documentation are currently not enabled in the `ultralytics` package. The Ultralytics team is actively working on integrating SAM2, and these capabilities should be available soon. We appreciate your patience as we work to implement this exciting new model. |
||||
|
||||
# SAM2: Segment Anything Model 2 |
||||
|
||||
SAM2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization. |
||||
|
||||
 |
||||
|
||||
## Key Features |
||||
|
||||
### Unified Model Architecture |
||||
|
||||
SAM2 combines the capabilities of image and video segmentation in a single model. This unification simplifies deployment and allows for consistent performance across different media types. It leverages a flexible prompt-based interface, enabling users to specify objects of interest through various prompt types, such as points, bounding boxes, or masks. |
||||
|
||||
### Real-Time Performance |
||||
|
||||
The model achieves real-time inference speeds, processing approximately 44 frames per second. This makes SAM2 suitable for applications requiring immediate feedback, such as video editing and augmented reality. |
||||
|
||||
### Zero-Shot Generalization |
||||
|
||||
SAM2 can segment objects it has never encountered before, demonstrating strong zero-shot generalization. This is particularly useful in diverse or evolving visual domains where pre-defined categories may not cover all possible objects. |
||||
|
||||
### Interactive Refinement |
||||
|
||||
Users can iteratively refine the segmentation results by providing additional prompts, allowing for precise control over the output. This interactivity is essential for fine-tuning results in applications like video annotation or medical imaging. |
||||
|
||||
### Advanced Handling of Visual Challenges |
||||
|
||||
SAM2 includes mechanisms to manage common video segmentation challenges, such as object occlusion and reappearance. It uses a sophisticated memory mechanism to keep track of objects across frames, ensuring continuity even when objects are temporarily obscured or exit and re-enter the scene. |
||||
|
||||
For a deeper understanding of SAM2's architecture and capabilities, explore the [SAM2 research paper](https://arxiv.org/abs/2401.12741). |
||||
|
||||
## Performance and Technical Details |
||||
|
||||
SAM2 sets a new benchmark in the field, outperforming previous models on various metrics: |
||||
|
||||
| Metric | SAM2 | Previous SOTA | |
||||
| ---------------------------------- | ------------- | ------------- | |
||||
| **Interactive Video Segmentation** | **Best** | - | |
||||
| **Human Interactions Required** | **3x fewer** | Baseline | |
||||
| **Image Segmentation Accuracy** | **Improved** | SAM | |
||||
| **Inference Speed** | **6x faster** | SAM | |
||||
|
||||
## Model Architecture |
||||
|
||||
### Core Components |
||||
|
||||
- **Image and Video Encoder**: Utilizes a transformer-based architecture to extract high-level features from both images and video frames. This component is responsible for understanding the visual content at each timestep. |
||||
- **Prompt Encoder**: Processes user-provided prompts (points, boxes, masks) to guide the segmentation task. This allows SAM2 to adapt to user input and target specific objects within a scene. |
||||
- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent object tracking over time. |
||||
- **Mask Decoder**: Generates the final segmentation masks based on the encoded image features and prompts. In video, it also uses memory context to ensure accurate tracking across frames. |
||||
|
||||
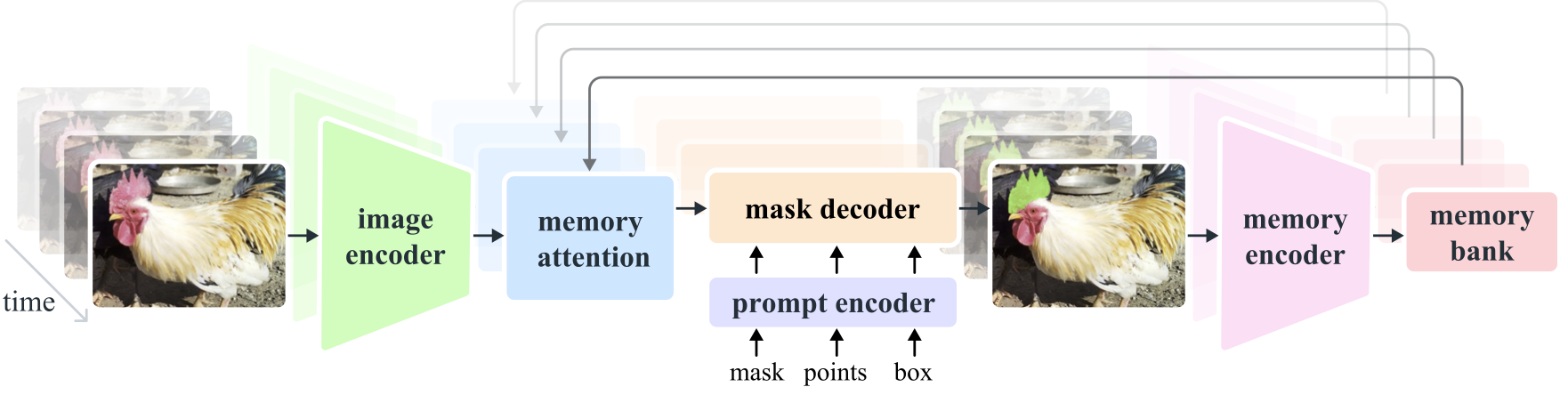 |
||||
|
||||
### Memory Mechanism and Occlusion Handling |
||||
|
||||
The memory mechanism allows SAM2 to handle temporal dependencies and occlusions in video data. As objects move and interact, SAM2 records their features in a memory bank. When an object becomes occluded, the model can rely on this memory to predict its position and appearance when it reappears. The occlusion head specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded. |
||||
|
||||
### Multi-Mask Ambiguity Resolution |
||||
|
||||
In situations with ambiguity (e.g., overlapping objects), SAM2 can generate multiple mask predictions. This feature is crucial for accurately representing complex scenes where a single mask might not sufficiently describe the scene's nuances. |
||||
|
||||
## SA-V Dataset |
||||
|
||||
The SA-V dataset, developed for SAM2's training, is one of the largest and most diverse video segmentation datasets available. It includes: |
||||
|
||||
- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios. |
||||
- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts. |
||||
- **Dataset Scale**: It features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity. |
||||
|
||||
## Benchmarks |
||||
|
||||
### Video Object Segmentation |
||||
|
||||
SAM2 has demonstrated superior performance across major video segmentation benchmarks: |
||||
|
||||
| Dataset | J&F | J | F | |
||||
| --------------- | ---- | ---- | ---- | |
||||
| **DAVIS 2017** | 82.5 | 79.8 | 85.2 | |
||||
| **YouTube-VOS** | 81.2 | 78.9 | 83.5 | |
||||
|
||||
### Interactive Segmentation |
||||
|
||||
In interactive segmentation tasks, SAM2 shows significant efficiency and accuracy: |
||||
|
||||
| Dataset | NoC@90 | AUC | |
||||
| --------------------- | ------ | ----- | |
||||
| **DAVIS Interactive** | 1.54 | 0.872 | |
||||
|
||||
## Installation |
||||
|
||||
To install SAM2, use the following command. All SAM2 models will automatically download on first use. |
||||
|
||||
```bash |
||||
pip install ultralytics |
||||
``` |
||||
|
||||
## How to Use SAM2: Versatility in Image and Video Segmentation |
||||
|
||||
!!! Note "🚧 SAM2 Integration In Progress 🚧" |
||||
|
||||
The SAM2 features described in this documentation are currently not enabled in the `ultralytics` package. The Ultralytics team is actively working on integrating SAM2, and these capabilities should be available soon. We appreciate your patience as we work to implement this exciting new model. |
||||
|
||||
The following table details the available SAM2 models, their pre-trained weights, supported tasks, and compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). |
||||
|
||||
| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export | |
||||
| ---------- | ------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ | |
||||
| SAM2 base | [sam2_b.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_b.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||
| SAM2 large | [sam2_l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_l.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||
|
||||
### SAM2 Prediction Examples |
||||
|
||||
SAM2 can be utilized across a broad spectrum of tasks, including real-time video editing, medical imaging, and autonomous systems. Its ability to segment both static and dynamic visual data makes it a versatile tool for researchers and developers. |
||||
|
||||
#### Segment with Prompts |
||||
|
||||
!!! Example "Segment with Prompts" |
||||
|
||||
Use prompts to segment specific objects in images or videos. |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import SAM2 |
||||
|
||||
# Load a model |
||||
model = SAM2("sam2_b.pt") |
||||
|
||||
# Display model information (optional) |
||||
model.info() |
||||
|
||||
# Segment with bounding box prompt |
||||
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200]) |
||||
|
||||
# Segment with point prompt |
||||
results = model("path/to/image.jpg", points=[150, 150], labels=[1]) |
||||
``` |
||||
|
||||
#### Segment Everything |
||||
|
||||
!!! Example "Segment Everything" |
||||
|
||||
Segment the entire image or video content without specific prompts. |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import SAM2 |
||||
|
||||
# Load a model |
||||
model = SAM2("sam2_b.pt") |
||||
|
||||
# Display model information (optional) |
||||
model.info() |
||||
|
||||
# Run inference |
||||
model("path/to/video.mp4") |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Run inference with a SAM2 model |
||||
yolo predict model=sam2_b.pt source=path/to/video.mp4 |
||||
``` |
||||
|
||||
- This example demonstrates how SAM2 can be used to segment the entire content of an image or video if no prompts (bboxes/points/masks) are provided. |
||||
|
||||
## SAM comparison vs YOLOv8 |
||||
|
||||
Here we compare Meta's smallest SAM model, SAM-b, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md): |
||||
|
||||
| Model | Size | Parameters | Speed (CPU) | |
||||
| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- | |
||||
| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im | |
||||
| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im | |
||||
| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im | |
||||
| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) | |
||||
|
||||
This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient. |
||||
|
||||
Tests run on a 2023 Apple M2 Macbook with 16GB of RAM. To reproduce this test: |
||||
|
||||
!!! Example |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import SAM, YOLO, FastSAM |
||||
|
||||
# Profile SAM-b |
||||
model = SAM("sam_b.pt") |
||||
model.info() |
||||
model("ultralytics/assets") |
||||
|
||||
# Profile MobileSAM |
||||
model = SAM("mobile_sam.pt") |
||||
model.info() |
||||
model("ultralytics/assets") |
||||
|
||||
# Profile FastSAM-s |
||||
model = FastSAM("FastSAM-s.pt") |
||||
model.info() |
||||
model("ultralytics/assets") |
||||
|
||||
# Profile YOLOv8n-seg |
||||
model = YOLO("yolov8n-seg.pt") |
||||
model.info() |
||||
model("ultralytics/assets") |
||||
``` |
||||
|
||||
## Auto-Annotation: Efficient Dataset Creation |
||||
|
||||
Auto-annotation is a powerful feature of SAM2, enabling users to generate segmentation datasets quickly and accurately by leveraging pre-trained models. This capability is particularly useful for creating large, high-quality datasets without extensive manual effort. |
||||
|
||||
### How to Auto-Annotate with SAM2 |
||||
|
||||
To auto-annotate your dataset using SAM2, follow this example: |
||||
|
||||
!!! Example "Auto-Annotation Example" |
||||
|
||||
```python |
||||
from ultralytics.data.annotator import auto_annotate |
||||
|
||||
auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam2_b.pt") |
||||
``` |
||||
|
||||
| Argument | Type | Description | Default | |
||||
| ------------ | ----------------------- | ------------------------------------------------------------------------------------------------------- | -------------- | |
||||
| `data` | `str` | Path to a folder containing images to be annotated. | | |
||||
| `det_model` | `str`, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | `'yolov8x.pt'` | |
||||
| `sam_model` | `str`, optional | Pre-trained SAM2 segmentation model. Defaults to 'sam2_b.pt'. | `'sam2_b.pt'` | |
||||
| `device` | `str`, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | | |
||||
| `output_dir` | `str`, `None`, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | `None` | |
||||
|
||||
This function facilitates the rapid creation of high-quality segmentation datasets, ideal for researchers and developers aiming to accelerate their projects. |
||||
|
||||
## Limitations |
||||
|
||||
Despite its strengths, SAM2 has certain limitations: |
||||
|
||||
- **Tracking Stability**: SAM2 may lose track of objects during extended sequences or significant viewpoint changes. |
||||
- **Object Confusion**: The model can sometimes confuse similar-looking objects, particularly in crowded scenes. |
||||
- **Efficiency with Multiple Objects**: Segmentation efficiency decreases when processing multiple objects simultaneously due to the lack of inter-object communication. |
||||
- **Detail Accuracy**: May miss fine details, especially with fast-moving objects. Additional prompts can partially address this issue, but temporal smoothness is not guaranteed. |
||||
|
||||
## Citations and Acknowledgements |
||||
|
||||
If SAM2 is a crucial part of your research or development work, please cite it using the following reference: |
||||
|
||||
!!! Quote "" |
||||
|
||||
=== "BibTeX" |
||||
|
||||
```bibtex |
||||
@article{kirillov2024sam2, |
||||
title={SAM2: Segment Anything Model 2}, |
||||
author={Alexander Kirillov and others}, |
||||
journal={arXiv preprint arXiv:2401.12741}, |
||||
year={2024} |
||||
} |
||||
``` |
||||
|
||||
We extend our gratitude to Meta AI for their contributions to the AI community with this groundbreaking model and dataset. |
||||
|
||||
## FAQ |
||||
|
||||
### What is SAM2 and how does it improve upon the original Segment Anything Model (SAM)? |
||||
|
||||
SAM2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization. SAM2 offers several improvements over the original SAM, including: |
||||
|
||||
- **Unified Model Architecture**: Combines image and video segmentation capabilities in a single model. |
||||
- **Real-Time Performance**: Processes approximately 44 frames per second, making it suitable for applications requiring immediate feedback. |
||||
- **Zero-Shot Generalization**: Segments objects it has never encountered before, useful in diverse visual domains. |
||||
- **Interactive Refinement**: Allows users to iteratively refine segmentation results by providing additional prompts. |
||||
- **Advanced Handling of Visual Challenges**: Manages common video segmentation challenges like object occlusion and reappearance. |
||||
|
||||
For more details on SAM2's architecture and capabilities, explore the [SAM2 research paper](https://arxiv.org/abs/2401.12741). |
||||
|
||||
### How can I use SAM2 for real-time video segmentation? |
||||
|
||||
SAM2 can be utilized for real-time video segmentation by leveraging its promptable interface and real-time inference capabilities. Here's a basic example: |
||||
|
||||
!!! Example "Segment with Prompts" |
||||
|
||||
Use prompts to segment specific objects in images or videos. |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import SAM2 |
||||
|
||||
# Load a model |
||||
model = SAM2("sam2_b.pt") |
||||
|
||||
# Display model information (optional) |
||||
model.info() |
||||
|
||||
# Segment with bounding box prompt |
||||
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200]) |
||||
|
||||
# Segment with point prompt |
||||
results = model("path/to/image.jpg", points=[150, 150], labels=[1]) |
||||
``` |
||||
|
||||
For more comprehensive usage, refer to the [How to Use SAM2](#how-to-use-sam2-versatility-in-image-and-video-segmentation) section. |
||||
|
||||
### What datasets are used to train SAM2, and how do they enhance its performance? |
||||
|
||||
SAM2 is trained on the SA-V dataset, one of the largest and most diverse video segmentation datasets available. The SA-V dataset includes: |
||||
|
||||
- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios. |
||||
- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts. |
||||
- **Dataset Scale**: Features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity. |
||||
|
||||
This extensive dataset allows SAM2 to achieve superior performance across major video segmentation benchmarks and enhances its zero-shot generalization capabilities. For more information, see the [SA-V Dataset](#sa-v-dataset) section. |
||||
|
||||
### How does SAM2 handle occlusions and object reappearances in video segmentation? |
||||
|
||||
SAM2 includes a sophisticated memory mechanism to manage temporal dependencies and occlusions in video data. The memory mechanism consists of: |
||||
|
||||
- **Memory Encoder and Memory Bank**: Stores features from past frames. |
||||
- **Memory Attention Module**: Utilizes stored information to maintain consistent object tracking over time. |
||||
- **Occlusion Head**: Specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded. |
||||
|
||||
This mechanism ensures continuity even when objects are temporarily obscured or exit and re-enter the scene. For more details, refer to the [Memory Mechanism and Occlusion Handling](#memory-mechanism-and-occlusion-handling) section. |
||||
|
||||
### How does SAM2 compare to other segmentation models like YOLOv8? |
||||
|
||||
SAM2 and Ultralytics YOLOv8 serve different purposes and excel in different areas. While SAM2 is designed for comprehensive object segmentation with advanced features like zero-shot generalization and real-time performance, YOLOv8 is optimized for speed and efficiency in object detection and segmentation tasks. Here's a comparison: |
||||
|
||||
| Model | Size | Parameters | Speed (CPU) | |
||||
| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- | |
||||
| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im | |
||||
| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im | |
||||
| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im | |
||||
| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) | |
||||
|
||||
For more details, see the [SAM comparison vs YOLOv8](#sam-comparison-vs-yolov8) section. |
||||
Loading…
Reference in new issue