commit
f0bf3ca0a9
48 changed files with 3997 additions and 104 deletions
@ -0,0 +1,349 @@ |
|||||||
|
--- |
||||||
|
comments: true |
||||||
|
description: Discover SAM 2, the next generation of Meta's Segment Anything Model, supporting real-time promptable segmentation in both images and videos with state-of-the-art performance. Learn about its key features, datasets, and how to use it. |
||||||
|
keywords: SAM 2, Segment Anything, video segmentation, image segmentation, promptable segmentation, zero-shot performance, SA-V dataset, Ultralytics, real-time segmentation, AI, machine learning |
||||||
|
--- |
||||||
|
|
||||||
|
# SAM 2: Segment Anything Model 2 |
||||||
|
|
||||||
|
!!! Note "🚧 SAM 2 Integration In Progress 🚧" |
||||||
|
|
||||||
|
The SAM 2 features described in this documentation are currently not enabled in the `ultralytics` package. The Ultralytics team is actively working on integrating SAM 2, and these capabilities should be available soon. We appreciate your patience as we work to implement this exciting new model. |
||||||
|
|
||||||
|
SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization. |
||||||
|
|
||||||
|
 |
||||||
|
|
||||||
|
## Key Features |
||||||
|
|
||||||
|
### Unified Model Architecture |
||||||
|
|
||||||
|
SAM 2 combines the capabilities of image and video segmentation in a single model. This unification simplifies deployment and allows for consistent performance across different media types. It leverages a flexible prompt-based interface, enabling users to specify objects of interest through various prompt types, such as points, bounding boxes, or masks. |
||||||
|
|
||||||
|
### Real-Time Performance |
||||||
|
|
||||||
|
The model achieves real-time inference speeds, processing approximately 44 frames per second. This makes SAM 2 suitable for applications requiring immediate feedback, such as video editing and augmented reality. |
||||||
|
|
||||||
|
### Zero-Shot Generalization |
||||||
|
|
||||||
|
SAM 2 can segment objects it has never encountered before, demonstrating strong zero-shot generalization. This is particularly useful in diverse or evolving visual domains where pre-defined categories may not cover all possible objects. |
||||||
|
|
||||||
|
### Interactive Refinement |
||||||
|
|
||||||
|
Users can iteratively refine the segmentation results by providing additional prompts, allowing for precise control over the output. This interactivity is essential for fine-tuning results in applications like video annotation or medical imaging. |
||||||
|
|
||||||
|
### Advanced Handling of Visual Challenges |
||||||
|
|
||||||
|
SAM 2 includes mechanisms to manage common video segmentation challenges, such as object occlusion and reappearance. It uses a sophisticated memory mechanism to keep track of objects across frames, ensuring continuity even when objects are temporarily obscured or exit and re-enter the scene. |
||||||
|
|
||||||
|
For a deeper understanding of SAM 2's architecture and capabilities, explore the [SAM 2 research paper](https://arxiv.org/abs/2401.12741). |
||||||
|
|
||||||
|
## Performance and Technical Details |
||||||
|
|
||||||
|
SAM 2 sets a new benchmark in the field, outperforming previous models on various metrics: |
||||||
|
|
||||||
|
| Metric | SAM 2 | Previous SOTA | |
||||||
|
| ---------------------------------- | ------------- | ------------- | |
||||||
|
| **Interactive Video Segmentation** | **Best** | - | |
||||||
|
| **Human Interactions Required** | **3x fewer** | Baseline | |
||||||
|
| **Image Segmentation Accuracy** | **Improved** | SAM | |
||||||
|
| **Inference Speed** | **6x faster** | SAM | |
||||||
|
|
||||||
|
## Model Architecture |
||||||
|
|
||||||
|
### Core Components |
||||||
|
|
||||||
|
- **Image and Video Encoder**: Utilizes a transformer-based architecture to extract high-level features from both images and video frames. This component is responsible for understanding the visual content at each timestep. |
||||||
|
- **Prompt Encoder**: Processes user-provided prompts (points, boxes, masks) to guide the segmentation task. This allows SAM 2 to adapt to user input and target specific objects within a scene. |
||||||
|
- **Memory Mechanism**: Includes a memory encoder, memory bank, and memory attention module. These components collectively store and utilize information from past frames, enabling the model to maintain consistent object tracking over time. |
||||||
|
- **Mask Decoder**: Generates the final segmentation masks based on the encoded image features and prompts. In video, it also uses memory context to ensure accurate tracking across frames. |
||||||
|
|
||||||
|
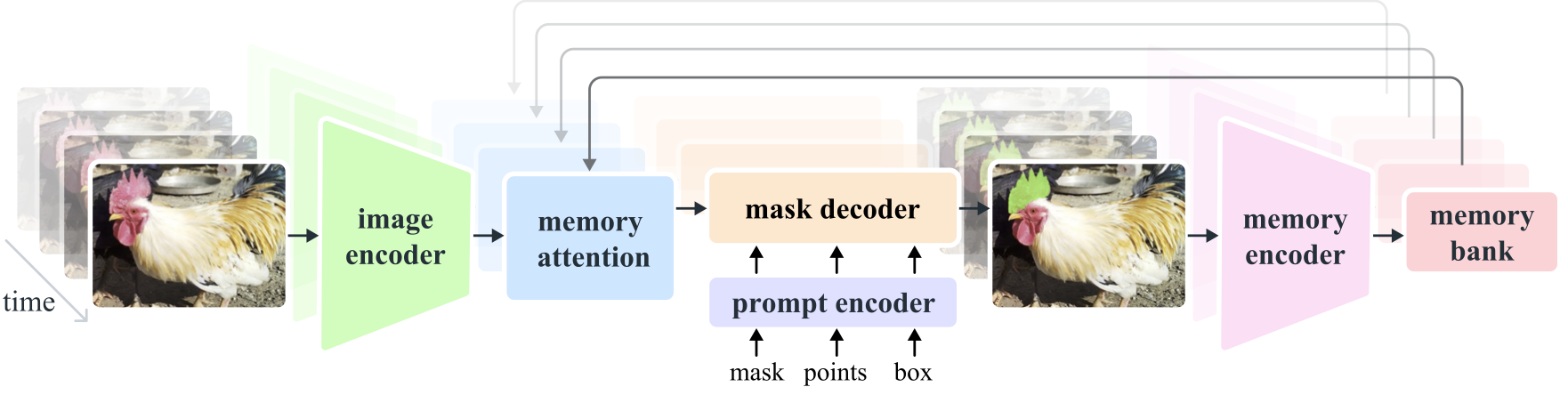 |
||||||
|
|
||||||
|
### Memory Mechanism and Occlusion Handling |
||||||
|
|
||||||
|
The memory mechanism allows SAM 2 to handle temporal dependencies and occlusions in video data. As objects move and interact, SAM 2 records their features in a memory bank. When an object becomes occluded, the model can rely on this memory to predict its position and appearance when it reappears. The occlusion head specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded. |
||||||
|
|
||||||
|
### Multi-Mask Ambiguity Resolution |
||||||
|
|
||||||
|
In situations with ambiguity (e.g., overlapping objects), SAM 2 can generate multiple mask predictions. This feature is crucial for accurately representing complex scenes where a single mask might not sufficiently describe the scene's nuances. |
||||||
|
|
||||||
|
## SA-V Dataset |
||||||
|
|
||||||
|
The SA-V dataset, developed for SAM 2's training, is one of the largest and most diverse video segmentation datasets available. It includes: |
||||||
|
|
||||||
|
- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios. |
||||||
|
- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts. |
||||||
|
- **Dataset Scale**: It features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity. |
||||||
|
|
||||||
|
## Benchmarks |
||||||
|
|
||||||
|
### Video Object Segmentation |
||||||
|
|
||||||
|
SAM 2 has demonstrated superior performance across major video segmentation benchmarks: |
||||||
|
|
||||||
|
| Dataset | J&F | J | F | |
||||||
|
| --------------- | ---- | ---- | ---- | |
||||||
|
| **DAVIS 2017** | 82.5 | 79.8 | 85.2 | |
||||||
|
| **YouTube-VOS** | 81.2 | 78.9 | 83.5 | |
||||||
|
|
||||||
|
### Interactive Segmentation |
||||||
|
|
||||||
|
In interactive segmentation tasks, SAM 2 shows significant efficiency and accuracy: |
||||||
|
|
||||||
|
| Dataset | NoC@90 | AUC | |
||||||
|
| --------------------- | ------ | ----- | |
||||||
|
| **DAVIS Interactive** | 1.54 | 0.872 | |
||||||
|
|
||||||
|
## Installation |
||||||
|
|
||||||
|
To install SAM 2, use the following command. All SAM 2 models will automatically download on first use. |
||||||
|
|
||||||
|
```bash |
||||||
|
pip install ultralytics |
||||||
|
``` |
||||||
|
|
||||||
|
## How to Use SAM 2: Versatility in Image and Video Segmentation |
||||||
|
|
||||||
|
!!! Note "🚧 SAM 2 Integration In Progress 🚧" |
||||||
|
|
||||||
|
The SAM 2 features described in this documentation are currently not enabled in the `ultralytics` package. The Ultralytics team is actively working on integrating SAM 2, and these capabilities should be available soon. We appreciate your patience as we work to implement this exciting new model. |
||||||
|
|
||||||
|
The following table details the available SAM 2 models, their pre-trained weights, supported tasks, and compatibility with different operating modes like [Inference](../modes/predict.md), [Validation](../modes/val.md), [Training](../modes/train.md), and [Export](../modes/export.md). |
||||||
|
|
||||||
|
| Model Type | Pre-trained Weights | Tasks Supported | Inference | Validation | Training | Export | |
||||||
|
| ----------- | ------------------------------------------------------------------------------------- | -------------------------------------------- | --------- | ---------- | -------- | ------ | |
||||||
|
| SAM 2 tiny | [sam2_t.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_t.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||||
|
| SAM 2 small | [sam2_s.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_s.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||||
|
| SAM 2 base | [sam2_b.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_b.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||||
|
| SAM 2 large | [sam2_l.pt](https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_l.pt) | [Instance Segmentation](../tasks/segment.md) | ✅ | ❌ | ❌ | ❌ | |
||||||
|
|
||||||
|
### SAM 2 Prediction Examples |
||||||
|
|
||||||
|
SAM 2 can be utilized across a broad spectrum of tasks, including real-time video editing, medical imaging, and autonomous systems. Its ability to segment both static and dynamic visual data makes it a versatile tool for researchers and developers. |
||||||
|
|
||||||
|
#### Segment with Prompts |
||||||
|
|
||||||
|
!!! Example "Segment with Prompts" |
||||||
|
|
||||||
|
Use prompts to segment specific objects in images or videos. |
||||||
|
|
||||||
|
=== "Python" |
||||||
|
|
||||||
|
```python |
||||||
|
from ultralytics import SAM |
||||||
|
|
||||||
|
# Load a model |
||||||
|
model = SAM("sam2_b.pt") |
||||||
|
|
||||||
|
# Display model information (optional) |
||||||
|
model.info() |
||||||
|
|
||||||
|
# Segment with bounding box prompt |
||||||
|
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200]) |
||||||
|
|
||||||
|
# Segment with point prompt |
||||||
|
results = model("path/to/image.jpg", points=[150, 150], labels=[1]) |
||||||
|
``` |
||||||
|
|
||||||
|
#### Segment Everything |
||||||
|
|
||||||
|
!!! Example "Segment Everything" |
||||||
|
|
||||||
|
Segment the entire image or video content without specific prompts. |
||||||
|
|
||||||
|
=== "Python" |
||||||
|
|
||||||
|
```python |
||||||
|
from ultralytics import SAM |
||||||
|
|
||||||
|
# Load a model |
||||||
|
model = SAM("sam2_b.pt") |
||||||
|
|
||||||
|
# Display model information (optional) |
||||||
|
model.info() |
||||||
|
|
||||||
|
# Run inference |
||||||
|
model("path/to/video.mp4") |
||||||
|
``` |
||||||
|
|
||||||
|
=== "CLI" |
||||||
|
|
||||||
|
```bash |
||||||
|
# Run inference with a SAM 2 model |
||||||
|
yolo predict model=sam2_b.pt source=path/to/video.mp4 |
||||||
|
``` |
||||||
|
|
||||||
|
- This example demonstrates how SAM 2 can be used to segment the entire content of an image or video if no prompts (bboxes/points/masks) are provided. |
||||||
|
|
||||||
|
## SAM comparison vs YOLOv8 |
||||||
|
|
||||||
|
Here we compare Meta's smallest SAM model, SAM-b, with Ultralytics smallest segmentation model, [YOLOv8n-seg](../tasks/segment.md): |
||||||
|
|
||||||
|
| Model | Size | Parameters | Speed (CPU) | |
||||||
|
| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- | |
||||||
|
| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im | |
||||||
|
| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im | |
||||||
|
| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im | |
||||||
|
| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) | |
||||||
|
|
||||||
|
This comparison shows the order-of-magnitude differences in the model sizes and speeds between models. Whereas SAM presents unique capabilities for automatic segmenting, it is not a direct competitor to YOLOv8 segment models, which are smaller, faster and more efficient. |
||||||
|
|
||||||
|
Tests run on a 2023 Apple M2 Macbook with 16GB of RAM. To reproduce this test: |
||||||
|
|
||||||
|
!!! Example |
||||||
|
|
||||||
|
=== "Python" |
||||||
|
|
||||||
|
```python |
||||||
|
from ultralytics import SAM, YOLO, FastSAM |
||||||
|
|
||||||
|
# Profile SAM-b |
||||||
|
model = SAM("sam_b.pt") |
||||||
|
model.info() |
||||||
|
model("ultralytics/assets") |
||||||
|
|
||||||
|
# Profile MobileSAM |
||||||
|
model = SAM("mobile_sam.pt") |
||||||
|
model.info() |
||||||
|
model("ultralytics/assets") |
||||||
|
|
||||||
|
# Profile FastSAM-s |
||||||
|
model = FastSAM("FastSAM-s.pt") |
||||||
|
model.info() |
||||||
|
model("ultralytics/assets") |
||||||
|
|
||||||
|
# Profile YOLOv8n-seg |
||||||
|
model = YOLO("yolov8n-seg.pt") |
||||||
|
model.info() |
||||||
|
model("ultralytics/assets") |
||||||
|
``` |
||||||
|
|
||||||
|
## Auto-Annotation: Efficient Dataset Creation |
||||||
|
|
||||||
|
Auto-annotation is a powerful feature of SAM 2, enabling users to generate segmentation datasets quickly and accurately by leveraging pre-trained models. This capability is particularly useful for creating large, high-quality datasets without extensive manual effort. |
||||||
|
|
||||||
|
### How to Auto-Annotate with SAM 2 |
||||||
|
|
||||||
|
To auto-annotate your dataset using SAM 2, follow this example: |
||||||
|
|
||||||
|
!!! Example "Auto-Annotation Example" |
||||||
|
|
||||||
|
```python |
||||||
|
from ultralytics.data.annotator import auto_annotate |
||||||
|
|
||||||
|
auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam2_b.pt") |
||||||
|
``` |
||||||
|
|
||||||
|
| Argument | Type | Description | Default | |
||||||
|
| ------------ | ----------------------- | ------------------------------------------------------------------------------------------------------- | -------------- | |
||||||
|
| `data` | `str` | Path to a folder containing images to be annotated. | | |
||||||
|
| `det_model` | `str`, optional | Pre-trained YOLO detection model. Defaults to 'yolov8x.pt'. | `'yolov8x.pt'` | |
||||||
|
| `sam_model` | `str`, optional | Pre-trained SAM 2 segmentation model. Defaults to 'sam2_b.pt'. | `'sam2_b.pt'` | |
||||||
|
| `device` | `str`, optional | Device to run the models on. Defaults to an empty string (CPU or GPU, if available). | | |
||||||
|
| `output_dir` | `str`, `None`, optional | Directory to save the annotated results. Defaults to a 'labels' folder in the same directory as 'data'. | `None` | |
||||||
|
|
||||||
|
This function facilitates the rapid creation of high-quality segmentation datasets, ideal for researchers and developers aiming to accelerate their projects. |
||||||
|
|
||||||
|
## Limitations |
||||||
|
|
||||||
|
Despite its strengths, SAM 2 has certain limitations: |
||||||
|
|
||||||
|
- **Tracking Stability**: SAM 2 may lose track of objects during extended sequences or significant viewpoint changes. |
||||||
|
- **Object Confusion**: The model can sometimes confuse similar-looking objects, particularly in crowded scenes. |
||||||
|
- **Efficiency with Multiple Objects**: Segmentation efficiency decreases when processing multiple objects simultaneously due to the lack of inter-object communication. |
||||||
|
- **Detail Accuracy**: May miss fine details, especially with fast-moving objects. Additional prompts can partially address this issue, but temporal smoothness is not guaranteed. |
||||||
|
|
||||||
|
## Citations and Acknowledgements |
||||||
|
|
||||||
|
If SAM 2 is a crucial part of your research or development work, please cite it using the following reference: |
||||||
|
|
||||||
|
!!! Quote "" |
||||||
|
|
||||||
|
=== "BibTeX" |
||||||
|
|
||||||
|
```bibtex |
||||||
|
@article{ravi2024sam2, |
||||||
|
title={SAM 2: Segment Anything in Images and Videos}, |
||||||
|
author={Ravi, Nikhila and Gabeur, Valentin and Hu, Yuan-Ting and Hu, Ronghang and Ryali, Chaitanya and Ma, Tengyu and Khedr, Haitham and R{\"a}dle, Roman and Rolland, Chloe and Gustafson, Laura and Mintun, Eric and Pan, Junting and Alwala, Kalyan Vasudev and Carion, Nicolas and Wu, Chao-Yuan and Girshick, Ross and Doll{\'a}r, Piotr and Feichtenhofer, Christoph}, |
||||||
|
journal={arXiv preprint}, |
||||||
|
year={2024} |
||||||
|
} |
||||||
|
``` |
||||||
|
|
||||||
|
We extend our gratitude to Meta AI for their contributions to the AI community with this groundbreaking model and dataset. |
||||||
|
|
||||||
|
## FAQ |
||||||
|
|
||||||
|
### What is SAM 2 and how does it improve upon the original Segment Anything Model (SAM)? |
||||||
|
|
||||||
|
SAM 2, the successor to Meta's [Segment Anything Model (SAM)](sam.md), is a cutting-edge tool designed for comprehensive object segmentation in both images and videos. It excels in handling complex visual data through a unified, promptable model architecture that supports real-time processing and zero-shot generalization. SAM 2 offers several improvements over the original SAM, including: |
||||||
|
|
||||||
|
- **Unified Model Architecture**: Combines image and video segmentation capabilities in a single model. |
||||||
|
- **Real-Time Performance**: Processes approximately 44 frames per second, making it suitable for applications requiring immediate feedback. |
||||||
|
- **Zero-Shot Generalization**: Segments objects it has never encountered before, useful in diverse visual domains. |
||||||
|
- **Interactive Refinement**: Allows users to iteratively refine segmentation results by providing additional prompts. |
||||||
|
- **Advanced Handling of Visual Challenges**: Manages common video segmentation challenges like object occlusion and reappearance. |
||||||
|
|
||||||
|
For more details on SAM 2's architecture and capabilities, explore the [SAM 2 research paper](https://arxiv.org/abs/2401.12741). |
||||||
|
|
||||||
|
### How can I use SAM 2 for real-time video segmentation? |
||||||
|
|
||||||
|
SAM 2 can be utilized for real-time video segmentation by leveraging its promptable interface and real-time inference capabilities. Here's a basic example: |
||||||
|
|
||||||
|
!!! Example "Segment with Prompts" |
||||||
|
|
||||||
|
Use prompts to segment specific objects in images or videos. |
||||||
|
|
||||||
|
=== "Python" |
||||||
|
|
||||||
|
```python |
||||||
|
from ultralytics import SAM |
||||||
|
|
||||||
|
# Load a model |
||||||
|
model = SAM("sam2_b.pt") |
||||||
|
|
||||||
|
# Display model information (optional) |
||||||
|
model.info() |
||||||
|
|
||||||
|
# Segment with bounding box prompt |
||||||
|
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200]) |
||||||
|
|
||||||
|
# Segment with point prompt |
||||||
|
results = model("path/to/image.jpg", points=[150, 150], labels=[1]) |
||||||
|
``` |
||||||
|
|
||||||
|
For more comprehensive usage, refer to the [How to Use SAM 2](#how-to-use-sam-2-versatility-in-image-and-video-segmentation) section. |
||||||
|
|
||||||
|
### What datasets are used to train SAM 2, and how do they enhance its performance? |
||||||
|
|
||||||
|
SAM 2 is trained on the SA-V dataset, one of the largest and most diverse video segmentation datasets available. The SA-V dataset includes: |
||||||
|
|
||||||
|
- **51,000+ Videos**: Captured across 47 countries, providing a wide range of real-world scenarios. |
||||||
|
- **600,000+ Mask Annotations**: Detailed spatio-temporal mask annotations, referred to as "masklets," covering whole objects and parts. |
||||||
|
- **Dataset Scale**: Features 4.5 times more videos and 53 times more annotations than previous largest datasets, offering unprecedented diversity and complexity. |
||||||
|
|
||||||
|
This extensive dataset allows SAM 2 to achieve superior performance across major video segmentation benchmarks and enhances its zero-shot generalization capabilities. For more information, see the [SA-V Dataset](#sa-v-dataset) section. |
||||||
|
|
||||||
|
### How does SAM 2 handle occlusions and object reappearances in video segmentation? |
||||||
|
|
||||||
|
SAM 2 includes a sophisticated memory mechanism to manage temporal dependencies and occlusions in video data. The memory mechanism consists of: |
||||||
|
|
||||||
|
- **Memory Encoder and Memory Bank**: Stores features from past frames. |
||||||
|
- **Memory Attention Module**: Utilizes stored information to maintain consistent object tracking over time. |
||||||
|
- **Occlusion Head**: Specifically handles scenarios where objects are not visible, predicting the likelihood of an object being occluded. |
||||||
|
|
||||||
|
This mechanism ensures continuity even when objects are temporarily obscured or exit and re-enter the scene. For more details, refer to the [Memory Mechanism and Occlusion Handling](#memory-mechanism-and-occlusion-handling) section. |
||||||
|
|
||||||
|
### How does SAM 2 compare to other segmentation models like YOLOv8? |
||||||
|
|
||||||
|
SAM 2 and Ultralytics YOLOv8 serve different purposes and excel in different areas. While SAM 2 is designed for comprehensive object segmentation with advanced features like zero-shot generalization and real-time performance, YOLOv8 is optimized for speed and efficiency in object detection and segmentation tasks. Here's a comparison: |
||||||
|
|
||||||
|
| Model | Size | Parameters | Speed (CPU) | |
||||||
|
| ---------------------------------------------- | -------------------------- | ---------------------- | -------------------------- | |
||||||
|
| Meta's SAM-b | 358 MB | 94.7 M | 51096 ms/im | |
||||||
|
| [MobileSAM](mobile-sam.md) | 40.7 MB | 10.1 M | 46122 ms/im | |
||||||
|
| [FastSAM-s](fast-sam.md) with YOLOv8 backbone | 23.7 MB | 11.8 M | 115 ms/im | |
||||||
|
| Ultralytics [YOLOv8n-seg](../tasks/segment.md) | **6.7 MB** (53.4x smaller) | **3.4 M** (27.9x less) | **59 ms/im** (866x faster) | |
||||||
|
|
||||||
|
For more details, see the [SAM comparison vs YOLOv8](#sam-comparison-vs-yolov8) section. |
||||||
@ -0,0 +1,6 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
from .model import SAM2 |
||||||
|
from .predict import SAM2Predictor |
||||||
|
|
||||||
|
__all__ = "SAM2", "SAM2Predictor" # tuple or list |
||||||
@ -0,0 +1,156 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import torch |
||||||
|
|
||||||
|
from ultralytics.utils.downloads import attempt_download_asset |
||||||
|
|
||||||
|
from .modules.encoders import FpnNeck, Hiera, ImageEncoder, MemoryEncoder |
||||||
|
from .modules.memory_attention import MemoryAttention, MemoryAttentionLayer |
||||||
|
from .modules.sam2 import SAM2Model |
||||||
|
|
||||||
|
|
||||||
|
def build_sam2_t(checkpoint=None): |
||||||
|
"""Build and return a Segment Anything Model (SAM2) tiny-size model with specified architecture parameters.""" |
||||||
|
return _build_sam2( |
||||||
|
encoder_embed_dim=96, |
||||||
|
encoder_stages=[1, 2, 7, 2], |
||||||
|
encoder_num_heads=1, |
||||||
|
encoder_global_att_blocks=[5, 7, 9], |
||||||
|
encoder_window_spec=[8, 4, 14, 7], |
||||||
|
encoder_backbone_channel_list=[768, 384, 192, 96], |
||||||
|
checkpoint=checkpoint, |
||||||
|
) |
||||||
|
|
||||||
|
|
||||||
|
def build_sam2_s(checkpoint=None): |
||||||
|
"""Builds and returns a small-size Segment Anything Model (SAM2) with specified architecture parameters.""" |
||||||
|
return _build_sam2( |
||||||
|
encoder_embed_dim=96, |
||||||
|
encoder_stages=[1, 2, 11, 2], |
||||||
|
encoder_num_heads=1, |
||||||
|
encoder_global_att_blocks=[7, 10, 13], |
||||||
|
encoder_window_spec=[8, 4, 14, 7], |
||||||
|
encoder_backbone_channel_list=[768, 384, 192, 96], |
||||||
|
checkpoint=checkpoint, |
||||||
|
) |
||||||
|
|
||||||
|
|
||||||
|
def build_sam2_b(checkpoint=None): |
||||||
|
"""Builds and returns a Segment Anything Model (SAM2) base-size model with specified architecture parameters.""" |
||||||
|
return _build_sam2( |
||||||
|
encoder_embed_dim=112, |
||||||
|
encoder_stages=[2, 3, 16, 3], |
||||||
|
encoder_num_heads=2, |
||||||
|
encoder_global_att_blocks=[12, 16, 20], |
||||||
|
encoder_window_spec=[8, 4, 14, 7], |
||||||
|
encoder_window_spatial_size=[14, 14], |
||||||
|
encoder_backbone_channel_list=[896, 448, 224, 112], |
||||||
|
checkpoint=checkpoint, |
||||||
|
) |
||||||
|
|
||||||
|
|
||||||
|
def build_sam2_l(checkpoint=None): |
||||||
|
"""Build and return a Segment Anything Model (SAM2) large-size model with specified architecture parameters.""" |
||||||
|
return _build_sam2( |
||||||
|
encoder_embed_dim=144, |
||||||
|
encoder_stages=[2, 6, 36, 4], |
||||||
|
encoder_num_heads=2, |
||||||
|
encoder_global_att_blocks=[23, 33, 43], |
||||||
|
encoder_window_spec=[8, 4, 16, 8], |
||||||
|
encoder_backbone_channel_list=[1152, 576, 288, 144], |
||||||
|
checkpoint=checkpoint, |
||||||
|
) |
||||||
|
|
||||||
|
|
||||||
|
def _build_sam2( |
||||||
|
encoder_embed_dim=1280, |
||||||
|
encoder_stages=[2, 6, 36, 4], |
||||||
|
encoder_num_heads=2, |
||||||
|
encoder_global_att_blocks=[7, 15, 23, 31], |
||||||
|
encoder_backbone_channel_list=[1152, 576, 288, 144], |
||||||
|
encoder_window_spatial_size=[7, 7], |
||||||
|
encoder_window_spec=[8, 4, 16, 8], |
||||||
|
checkpoint=None, |
||||||
|
): |
||||||
|
"""Builds a SAM2 model with specified architecture parameters and optional checkpoint loading.""" |
||||||
|
image_encoder = ImageEncoder( |
||||||
|
trunk=Hiera( |
||||||
|
embed_dim=encoder_embed_dim, |
||||||
|
num_heads=encoder_num_heads, |
||||||
|
stages=encoder_stages, |
||||||
|
global_att_blocks=encoder_global_att_blocks, |
||||||
|
window_pos_embed_bkg_spatial_size=encoder_window_spatial_size, |
||||||
|
window_spec=encoder_window_spec, |
||||||
|
), |
||||||
|
neck=FpnNeck( |
||||||
|
d_model=256, |
||||||
|
backbone_channel_list=encoder_backbone_channel_list, |
||||||
|
fpn_top_down_levels=[2, 3], |
||||||
|
fpn_interp_model="nearest", |
||||||
|
), |
||||||
|
scalp=1, |
||||||
|
) |
||||||
|
memory_attention = MemoryAttention(d_model=256, pos_enc_at_input=True, num_layers=4, layer=MemoryAttentionLayer()) |
||||||
|
memory_encoder = MemoryEncoder(out_dim=64) |
||||||
|
|
||||||
|
sam2 = SAM2Model( |
||||||
|
image_encoder=image_encoder, |
||||||
|
memory_attention=memory_attention, |
||||||
|
memory_encoder=memory_encoder, |
||||||
|
num_maskmem=7, |
||||||
|
image_size=1024, |
||||||
|
sigmoid_scale_for_mem_enc=20.0, |
||||||
|
sigmoid_bias_for_mem_enc=-10.0, |
||||||
|
use_mask_input_as_output_without_sam=True, |
||||||
|
directly_add_no_mem_embed=True, |
||||||
|
use_high_res_features_in_sam=True, |
||||||
|
multimask_output_in_sam=True, |
||||||
|
iou_prediction_use_sigmoid=True, |
||||||
|
use_obj_ptrs_in_encoder=True, |
||||||
|
add_tpos_enc_to_obj_ptrs=True, |
||||||
|
only_obj_ptrs_in_the_past_for_eval=True, |
||||||
|
pred_obj_scores=True, |
||||||
|
pred_obj_scores_mlp=True, |
||||||
|
fixed_no_obj_ptr=True, |
||||||
|
multimask_output_for_tracking=True, |
||||||
|
use_multimask_token_for_obj_ptr=True, |
||||||
|
multimask_min_pt_num=0, |
||||||
|
multimask_max_pt_num=1, |
||||||
|
use_mlp_for_obj_ptr_proj=True, |
||||||
|
compile_image_encoder=False, |
||||||
|
sam_mask_decoder_extra_args=dict( |
||||||
|
dynamic_multimask_via_stability=True, |
||||||
|
dynamic_multimask_stability_delta=0.05, |
||||||
|
dynamic_multimask_stability_thresh=0.98, |
||||||
|
), |
||||||
|
) |
||||||
|
|
||||||
|
if checkpoint is not None: |
||||||
|
checkpoint = attempt_download_asset(checkpoint) |
||||||
|
with open(checkpoint, "rb") as f: |
||||||
|
state_dict = torch.load(f)["model"] |
||||||
|
sam2.load_state_dict(state_dict) |
||||||
|
sam2.eval() |
||||||
|
return sam2 |
||||||
|
|
||||||
|
|
||||||
|
sam_model_map = { |
||||||
|
"sam2_t.pt": build_sam2_t, |
||||||
|
"sam2_s.pt": build_sam2_s, |
||||||
|
"sam2_b.pt": build_sam2_b, |
||||||
|
"sam2_l.pt": build_sam2_l, |
||||||
|
} |
||||||
|
|
||||||
|
|
||||||
|
def build_sam2(ckpt="sam_b.pt"): |
||||||
|
"""Constructs a Segment Anything Model (SAM2) based on the specified checkpoint, with various size options.""" |
||||||
|
model_builder = None |
||||||
|
ckpt = str(ckpt) # to allow Path ckpt types |
||||||
|
for k in sam_model_map.keys(): |
||||||
|
if ckpt.endswith(k): |
||||||
|
model_builder = sam_model_map.get(k) |
||||||
|
|
||||||
|
if not model_builder: |
||||||
|
raise FileNotFoundError(f"{ckpt} is not a supported SAM model. Available models are: \n {sam_model_map.keys()}") |
||||||
|
|
||||||
|
return model_builder(ckpt) |
||||||
@ -0,0 +1,97 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
""" |
||||||
|
SAM2 model interface. |
||||||
|
|
||||||
|
This module provides an interface to the Segment Anything Model (SAM2) from Ultralytics, designed for real-time image |
||||||
|
segmentation tasks. The SAM2 model allows for promptable segmentation with unparalleled versatility in image analysis, |
||||||
|
and has been trained on the SA-1B dataset. It features zero-shot performance capabilities, enabling it to adapt to new |
||||||
|
image distributions and tasks without prior knowledge. |
||||||
|
|
||||||
|
Key Features: |
||||||
|
- Promptable segmentation |
||||||
|
- Real-time performance |
||||||
|
- Zero-shot transfer capabilities |
||||||
|
- Trained on SA-1B dataset |
||||||
|
""" |
||||||
|
|
||||||
|
from ultralytics.models.sam import SAM |
||||||
|
|
||||||
|
from .build import build_sam2 |
||||||
|
from .predict import SAM2Predictor |
||||||
|
|
||||||
|
|
||||||
|
class SAM2(SAM): |
||||||
|
""" |
||||||
|
SAM2 class for real-time image segmentation using the Segment Anything Model (SAM2). |
||||||
|
|
||||||
|
This class extends the SAM base class, providing an interface to the SAM2 model for promptable segmentation |
||||||
|
tasks. It supports loading pre-trained weights and offers zero-shot performance capabilities. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
model (torch.nn.Module): The loaded SAM2 model. |
||||||
|
task_map (Dict[str, Type[SAM2Predictor]]): Mapping of 'segment' task to SAM2Predictor. |
||||||
|
|
||||||
|
Methods: |
||||||
|
__init__: Initializes the SAM2 model with pre-trained weights. |
||||||
|
_load: Loads specified weights into the SAM2 model. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> sam2 = SAM2("sam2_b.pt") |
||||||
|
>>> sam2._load('path/to/sam2_weights.pt') |
||||||
|
>>> task_map = sam2.task_map |
||||||
|
>>> print(task_map) |
||||||
|
{'segment': SAM2Predictor} |
||||||
|
|
||||||
|
Notes: |
||||||
|
- Supports .pt and .pth file extensions for model weights. |
||||||
|
- Offers zero-shot transfer capabilities for new image distributions and tasks. |
||||||
|
""" |
||||||
|
|
||||||
|
def __init__(self, model="sam2_b.pt") -> None: |
||||||
|
""" |
||||||
|
Initializes the SAM2 model with a pre-trained model file. |
||||||
|
|
||||||
|
Args: |
||||||
|
model (str): Path to the pre-trained SAM2 model file. File should have a .pt or .pth extension. |
||||||
|
|
||||||
|
Raises: |
||||||
|
NotImplementedError: If the model file extension is not .pt or .pth. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> sam2 = SAM2("sam2_b.pt") |
||||||
|
""" |
||||||
|
super().__init__(model=model) |
||||||
|
|
||||||
|
def _load(self, weights: str, task=None): |
||||||
|
""" |
||||||
|
Loads the specified weights into the SAM2 model. |
||||||
|
|
||||||
|
This method is responsible for loading pre-trained weights into the SAM2 model. It supports loading |
||||||
|
weights from files with .pt or .pth extensions. |
||||||
|
|
||||||
|
Args: |
||||||
|
weights (str): Path to the weights file. Should be a file with .pt or .pth extension. |
||||||
|
task (str | None): Task name. If provided, it may be used to configure model-specific settings. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> sam2_model = SAM2() |
||||||
|
>>> sam2_model._load('path/to/sam2_weights.pt') |
||||||
|
""" |
||||||
|
self.model = build_sam2(weights) |
||||||
|
|
||||||
|
@property |
||||||
|
def task_map(self): |
||||||
|
""" |
||||||
|
Provides a mapping from the 'segment' task to its corresponding 'Predictor'. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Dict[str, Type[SAM2Predictor]]): A dictionary mapping the 'segment' task to its corresponding |
||||||
|
SAM2Predictor class. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> sam2 = SAM2() |
||||||
|
>>> task_map = sam2.task_map |
||||||
|
>>> print(task_map) |
||||||
|
{'segment': SAM2Predictor} |
||||||
|
""" |
||||||
|
return {"segment": {"predictor": SAM2Predictor}} |
||||||
@ -0,0 +1 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
@ -0,0 +1,305 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
from typing import List, Optional, Tuple, Type |
||||||
|
|
||||||
|
import torch |
||||||
|
from torch import nn |
||||||
|
|
||||||
|
from ultralytics.nn.modules import MLP, LayerNorm2d |
||||||
|
|
||||||
|
|
||||||
|
class MaskDecoder(nn.Module): |
||||||
|
"""Transformer-based decoder predicting instance segmentation masks from image and prompt embeddings.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
transformer_dim: int, |
||||||
|
transformer: nn.Module, |
||||||
|
num_multimask_outputs: int = 3, |
||||||
|
activation: Type[nn.Module] = nn.GELU, |
||||||
|
iou_head_depth: int = 3, |
||||||
|
iou_head_hidden_dim: int = 256, |
||||||
|
use_high_res_features: bool = False, |
||||||
|
iou_prediction_use_sigmoid=False, |
||||||
|
dynamic_multimask_via_stability=False, |
||||||
|
dynamic_multimask_stability_delta=0.05, |
||||||
|
dynamic_multimask_stability_thresh=0.98, |
||||||
|
pred_obj_scores: bool = False, |
||||||
|
pred_obj_scores_mlp: bool = False, |
||||||
|
use_multimask_token_for_obj_ptr: bool = False, |
||||||
|
) -> None: |
||||||
|
""" |
||||||
|
Initializes the MaskDecoder module for predicting instance segmentation masks. |
||||||
|
|
||||||
|
Args: |
||||||
|
transformer_dim (int): Channel dimension of the transformer. |
||||||
|
transformer (nn.Module): Transformer used to predict masks. |
||||||
|
num_multimask_outputs (int): Number of masks to predict when disambiguating masks. |
||||||
|
activation (Type[nn.Module]): Type of activation to use when upscaling masks. |
||||||
|
iou_head_depth (int): Depth of the MLP used to predict mask quality. |
||||||
|
iou_head_hidden_dim (int): Hidden dimension of the MLP used to predict mask quality. |
||||||
|
use_high_res_features (bool): Whether to use high-resolution features. |
||||||
|
iou_prediction_use_sigmoid (bool): Whether to use sigmoid for IOU prediction. |
||||||
|
dynamic_multimask_via_stability (bool): Whether to use dynamic multimask via stability. |
||||||
|
dynamic_multimask_stability_delta (float): Delta value for dynamic multimask stability. |
||||||
|
dynamic_multimask_stability_thresh (float): Threshold for dynamic multimask stability. |
||||||
|
pred_obj_scores (bool): Whether to predict object scores. |
||||||
|
pred_obj_scores_mlp (bool): Whether to use MLP for object score prediction. |
||||||
|
use_multimask_token_for_obj_ptr (bool): Whether to use multimask token for object pointer. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
transformer_dim (int): Channel dimension of the transformer. |
||||||
|
transformer (nn.Module): Transformer used to predict masks. |
||||||
|
num_multimask_outputs (int): Number of masks to predict when disambiguating masks. |
||||||
|
iou_token (nn.Embedding): Embedding for IOU token. |
||||||
|
num_mask_tokens (int): Total number of mask tokens. |
||||||
|
mask_tokens (nn.Embedding): Embedding for mask tokens. |
||||||
|
pred_obj_scores (bool): Whether to predict object scores. |
||||||
|
obj_score_token (nn.Embedding): Embedding for object score token. |
||||||
|
use_multimask_token_for_obj_ptr (bool): Whether to use multimask token for object pointer. |
||||||
|
output_upscaling (nn.Sequential): Upscaling layers for output. |
||||||
|
use_high_res_features (bool): Whether to use high-resolution features. |
||||||
|
conv_s0 (nn.Conv2d): Convolutional layer for high-resolution features (s0). |
||||||
|
conv_s1 (nn.Conv2d): Convolutional layer for high-resolution features (s1). |
||||||
|
output_hypernetworks_mlps (nn.ModuleList): List of MLPs for output hypernetworks. |
||||||
|
iou_prediction_head (MLP): MLP for IOU prediction. |
||||||
|
pred_obj_score_head (nn.Linear | MLP): Linear layer or MLP for object score prediction. |
||||||
|
dynamic_multimask_via_stability (bool): Whether to use dynamic multimask via stability. |
||||||
|
dynamic_multimask_stability_delta (float): Delta value for dynamic multimask stability. |
||||||
|
""" |
||||||
|
super().__init__() |
||||||
|
self.transformer_dim = transformer_dim |
||||||
|
self.transformer = transformer |
||||||
|
|
||||||
|
self.num_multimask_outputs = num_multimask_outputs |
||||||
|
|
||||||
|
self.iou_token = nn.Embedding(1, transformer_dim) |
||||||
|
self.num_mask_tokens = num_multimask_outputs + 1 |
||||||
|
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim) |
||||||
|
|
||||||
|
self.pred_obj_scores = pred_obj_scores |
||||||
|
if self.pred_obj_scores: |
||||||
|
self.obj_score_token = nn.Embedding(1, transformer_dim) |
||||||
|
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr |
||||||
|
|
||||||
|
self.output_upscaling = nn.Sequential( |
||||||
|
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2), |
||||||
|
LayerNorm2d(transformer_dim // 4), |
||||||
|
activation(), |
||||||
|
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2), |
||||||
|
activation(), |
||||||
|
) |
||||||
|
self.use_high_res_features = use_high_res_features |
||||||
|
if use_high_res_features: |
||||||
|
self.conv_s0 = nn.Conv2d(transformer_dim, transformer_dim // 8, kernel_size=1, stride=1) |
||||||
|
self.conv_s1 = nn.Conv2d(transformer_dim, transformer_dim // 4, kernel_size=1, stride=1) |
||||||
|
|
||||||
|
self.output_hypernetworks_mlps = nn.ModuleList( |
||||||
|
[MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3) for _ in range(self.num_mask_tokens)] |
||||||
|
) |
||||||
|
|
||||||
|
self.iou_prediction_head = MLP( |
||||||
|
transformer_dim, |
||||||
|
iou_head_hidden_dim, |
||||||
|
self.num_mask_tokens, |
||||||
|
iou_head_depth, |
||||||
|
sigmoid=iou_prediction_use_sigmoid, |
||||||
|
) |
||||||
|
if self.pred_obj_scores: |
||||||
|
self.pred_obj_score_head = nn.Linear(transformer_dim, 1) |
||||||
|
if pred_obj_scores_mlp: |
||||||
|
self.pred_obj_score_head = MLP(transformer_dim, transformer_dim, 1, 3) |
||||||
|
|
||||||
|
# When outputting a single mask, optionally we can dynamically fall back to the best |
||||||
|
# multimask output token if the single mask output token gives low stability scores. |
||||||
|
self.dynamic_multimask_via_stability = dynamic_multimask_via_stability |
||||||
|
self.dynamic_multimask_stability_delta = dynamic_multimask_stability_delta |
||||||
|
self.dynamic_multimask_stability_thresh = dynamic_multimask_stability_thresh |
||||||
|
|
||||||
|
def forward( |
||||||
|
self, |
||||||
|
image_embeddings: torch.Tensor, |
||||||
|
image_pe: torch.Tensor, |
||||||
|
sparse_prompt_embeddings: torch.Tensor, |
||||||
|
dense_prompt_embeddings: torch.Tensor, |
||||||
|
multimask_output: bool, |
||||||
|
repeat_image: bool, |
||||||
|
high_res_features: Optional[List[torch.Tensor]] = None, |
||||||
|
) -> Tuple[torch.Tensor, torch.Tensor]: |
||||||
|
""" |
||||||
|
Predicts masks given image and prompt embeddings. |
||||||
|
|
||||||
|
Args: |
||||||
|
image_embeddings (torch.Tensor): Embeddings from the image encoder. |
||||||
|
image_pe (torch.Tensor): Positional encoding with the shape of image_embeddings. |
||||||
|
sparse_prompt_embeddings (torch.Tensor): Embeddings of the points and boxes. |
||||||
|
dense_prompt_embeddings (torch.Tensor): Embeddings of the mask inputs. |
||||||
|
multimask_output (bool): Whether to return multiple masks or a single mask. |
||||||
|
repeat_image (bool): Flag to repeat the image embeddings. |
||||||
|
high_res_features (List[torch.Tensor] | None): Optional high-resolution features. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Tuple[torch.Tensor, torch.Tensor, torch.Tensor]): A tuple containing: |
||||||
|
- masks (torch.Tensor): Batched predicted masks. |
||||||
|
- iou_pred (torch.Tensor): Batched predictions of mask quality. |
||||||
|
- sam_tokens_out (torch.Tensor): Batched SAM token for mask output. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> image_embeddings = torch.rand(1, 256, 64, 64) |
||||||
|
>>> image_pe = torch.rand(1, 256, 64, 64) |
||||||
|
>>> sparse_prompt_embeddings = torch.rand(1, 2, 256) |
||||||
|
>>> dense_prompt_embeddings = torch.rand(1, 256, 64, 64) |
||||||
|
>>> decoder = MaskDecoder(256, transformer) |
||||||
|
>>> masks, iou_pred, sam_tokens_out = decoder.forward(image_embeddings, image_pe, |
||||||
|
... sparse_prompt_embeddings, dense_prompt_embeddings, True, False) |
||||||
|
""" |
||||||
|
masks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks( |
||||||
|
image_embeddings=image_embeddings, |
||||||
|
image_pe=image_pe, |
||||||
|
sparse_prompt_embeddings=sparse_prompt_embeddings, |
||||||
|
dense_prompt_embeddings=dense_prompt_embeddings, |
||||||
|
repeat_image=repeat_image, |
||||||
|
high_res_features=high_res_features, |
||||||
|
) |
||||||
|
|
||||||
|
# Select the correct mask or masks for output |
||||||
|
if multimask_output: |
||||||
|
masks = masks[:, 1:, :, :] |
||||||
|
iou_pred = iou_pred[:, 1:] |
||||||
|
elif self.dynamic_multimask_via_stability and not self.training: |
||||||
|
masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred) |
||||||
|
else: |
||||||
|
masks = masks[:, 0:1, :, :] |
||||||
|
iou_pred = iou_pred[:, 0:1] |
||||||
|
|
||||||
|
if multimask_output and self.use_multimask_token_for_obj_ptr: |
||||||
|
sam_tokens_out = mask_tokens_out[:, 1:] # [b, 3, c] shape |
||||||
|
else: |
||||||
|
# Take the mask output token. Here we *always* use the token for single mask output. |
||||||
|
# At test time, even if we track after 1-click (and using multimask_output=True), |
||||||
|
# we still take the single mask token here. The rationale is that we always track |
||||||
|
# after multiple clicks during training, so the past tokens seen during training |
||||||
|
# are always the single mask token (and we'll let it be the object-memory token). |
||||||
|
sam_tokens_out = mask_tokens_out[:, 0:1] # [b, 1, c] shape |
||||||
|
|
||||||
|
# Prepare output |
||||||
|
return masks, iou_pred, sam_tokens_out, object_score_logits |
||||||
|
|
||||||
|
def predict_masks( |
||||||
|
self, |
||||||
|
image_embeddings: torch.Tensor, |
||||||
|
image_pe: torch.Tensor, |
||||||
|
sparse_prompt_embeddings: torch.Tensor, |
||||||
|
dense_prompt_embeddings: torch.Tensor, |
||||||
|
repeat_image: bool, |
||||||
|
high_res_features: Optional[List[torch.Tensor]] = None, |
||||||
|
) -> Tuple[torch.Tensor, torch.Tensor]: |
||||||
|
"""Predicts instance segmentation masks from image and prompt embeddings using a transformer architecture.""" |
||||||
|
# Concatenate output tokens |
||||||
|
s = 0 |
||||||
|
if self.pred_obj_scores: |
||||||
|
output_tokens = torch.cat( |
||||||
|
[ |
||||||
|
self.obj_score_token.weight, |
||||||
|
self.iou_token.weight, |
||||||
|
self.mask_tokens.weight, |
||||||
|
], |
||||||
|
dim=0, |
||||||
|
) |
||||||
|
s = 1 |
||||||
|
else: |
||||||
|
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0) |
||||||
|
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1) |
||||||
|
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1) |
||||||
|
|
||||||
|
# Expand per-image data in batch direction to be per-mask |
||||||
|
if repeat_image: |
||||||
|
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0) |
||||||
|
else: |
||||||
|
assert image_embeddings.shape[0] == tokens.shape[0] |
||||||
|
src = image_embeddings |
||||||
|
src = src + dense_prompt_embeddings |
||||||
|
assert image_pe.size(0) == 1, "image_pe should have size 1 in batch dim (from `get_dense_pe()`)" |
||||||
|
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0) |
||||||
|
b, c, h, w = src.shape |
||||||
|
|
||||||
|
# Run the transformer |
||||||
|
hs, src = self.transformer(src, pos_src, tokens) |
||||||
|
iou_token_out = hs[:, s, :] |
||||||
|
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :] |
||||||
|
|
||||||
|
# Upscale mask embeddings and predict masks using the mask tokens |
||||||
|
src = src.transpose(1, 2).view(b, c, h, w) |
||||||
|
if not self.use_high_res_features: |
||||||
|
upscaled_embedding = self.output_upscaling(src) |
||||||
|
else: |
||||||
|
dc1, ln1, act1, dc2, act2 = self.output_upscaling |
||||||
|
feat_s0, feat_s1 = high_res_features |
||||||
|
upscaled_embedding = act1(ln1(dc1(src) + feat_s1)) |
||||||
|
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0) |
||||||
|
|
||||||
|
hyper_in_list: List[torch.Tensor] = [] |
||||||
|
for i in range(self.num_mask_tokens): |
||||||
|
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])) |
||||||
|
hyper_in = torch.stack(hyper_in_list, dim=1) |
||||||
|
b, c, h, w = upscaled_embedding.shape |
||||||
|
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w) |
||||||
|
|
||||||
|
# Generate mask quality predictions |
||||||
|
iou_pred = self.iou_prediction_head(iou_token_out) |
||||||
|
if self.pred_obj_scores: |
||||||
|
assert s == 1 |
||||||
|
object_score_logits = self.pred_obj_score_head(hs[:, 0, :]) |
||||||
|
else: |
||||||
|
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1 |
||||||
|
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1) |
||||||
|
|
||||||
|
return masks, iou_pred, mask_tokens_out, object_score_logits |
||||||
|
|
||||||
|
def _get_stability_scores(self, mask_logits): |
||||||
|
"""Computes mask stability scores based on IoU between upper and lower thresholds.""" |
||||||
|
mask_logits = mask_logits.flatten(-2) |
||||||
|
stability_delta = self.dynamic_multimask_stability_delta |
||||||
|
area_i = torch.sum(mask_logits > stability_delta, dim=-1).float() |
||||||
|
area_u = torch.sum(mask_logits > -stability_delta, dim=-1).float() |
||||||
|
stability_scores = torch.where(area_u > 0, area_i / area_u, 1.0) |
||||||
|
return stability_scores |
||||||
|
|
||||||
|
def _dynamic_multimask_via_stability(self, all_mask_logits, all_iou_scores): |
||||||
|
""" |
||||||
|
Dynamically selects the most stable mask output based on stability scores and IoU predictions. |
||||||
|
|
||||||
|
When outputting a single mask, if the stability score from the current single-mask output (based on output token |
||||||
|
0) falls below a threshold, we instead select from multi-mask outputs (based on output token 1~3) the mask with |
||||||
|
the highest predicted IoU score. |
||||||
|
|
||||||
|
This is intended to ensure a valid mask for both clicking and tracking. |
||||||
|
""" |
||||||
|
# The best mask from multimask output tokens (1~3) |
||||||
|
multimask_logits = all_mask_logits[:, 1:, :, :] |
||||||
|
multimask_iou_scores = all_iou_scores[:, 1:] |
||||||
|
best_scores_inds = torch.argmax(multimask_iou_scores, dim=-1) |
||||||
|
batch_inds = torch.arange(multimask_iou_scores.size(0), device=all_iou_scores.device) |
||||||
|
best_multimask_logits = multimask_logits[batch_inds, best_scores_inds] |
||||||
|
best_multimask_logits = best_multimask_logits.unsqueeze(1) |
||||||
|
best_multimask_iou_scores = multimask_iou_scores[batch_inds, best_scores_inds] |
||||||
|
best_multimask_iou_scores = best_multimask_iou_scores.unsqueeze(1) |
||||||
|
|
||||||
|
# The mask from singlemask output token 0 and its stability score |
||||||
|
singlemask_logits = all_mask_logits[:, 0:1, :, :] |
||||||
|
singlemask_iou_scores = all_iou_scores[:, 0:1] |
||||||
|
stability_scores = self._get_stability_scores(singlemask_logits) |
||||||
|
is_stable = stability_scores >= self.dynamic_multimask_stability_thresh |
||||||
|
|
||||||
|
# Dynamically fall back to best multimask output upon low stability scores. |
||||||
|
mask_logits_out = torch.where( |
||||||
|
is_stable[..., None, None].expand_as(singlemask_logits), |
||||||
|
singlemask_logits, |
||||||
|
best_multimask_logits, |
||||||
|
) |
||||||
|
iou_scores_out = torch.where( |
||||||
|
is_stable.expand_as(singlemask_iou_scores), |
||||||
|
singlemask_iou_scores, |
||||||
|
best_multimask_iou_scores, |
||||||
|
) |
||||||
|
return mask_logits_out, iou_scores_out |
||||||
@ -0,0 +1,332 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
from typing import List, Optional, Tuple |
||||||
|
|
||||||
|
import torch |
||||||
|
import torch.nn as nn |
||||||
|
import torch.nn.functional as F |
||||||
|
|
||||||
|
from ultralytics.models.sam.modules.encoders import PatchEmbed |
||||||
|
|
||||||
|
from .sam2_blocks import CXBlock, Fuser, MaskDownSampler, MultiScaleBlock, PositionEmbeddingSine |
||||||
|
|
||||||
|
|
||||||
|
class MemoryEncoder(nn.Module): |
||||||
|
"""Encodes pixel features and masks into a memory representation for efficient image segmentation.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
out_dim, |
||||||
|
in_dim=256, # in_dim of pix_feats |
||||||
|
): |
||||||
|
"""Initializes the MemoryEncoder module for encoding pixel features and masks in SAM-like models.""" |
||||||
|
super().__init__() |
||||||
|
|
||||||
|
self.mask_downsampler = MaskDownSampler(kernel_size=3, stride=2, padding=1) |
||||||
|
|
||||||
|
self.pix_feat_proj = nn.Conv2d(in_dim, in_dim, kernel_size=1) |
||||||
|
self.fuser = Fuser(CXBlock(dim=256), num_layers=2) |
||||||
|
self.position_encoding = PositionEmbeddingSine(num_pos_feats=64) |
||||||
|
self.out_proj = nn.Identity() |
||||||
|
if out_dim != in_dim: |
||||||
|
self.out_proj = nn.Conv2d(in_dim, out_dim, kernel_size=1) |
||||||
|
|
||||||
|
def forward( |
||||||
|
self, |
||||||
|
pix_feat: torch.Tensor, |
||||||
|
masks: torch.Tensor, |
||||||
|
skip_mask_sigmoid: bool = False, |
||||||
|
) -> Tuple[torch.Tensor, torch.Tensor]: |
||||||
|
"""Processes pixel features and masks, fusing them to generate encoded memory representations.""" |
||||||
|
if not skip_mask_sigmoid: |
||||||
|
masks = F.sigmoid(masks) |
||||||
|
masks = self.mask_downsampler(masks) |
||||||
|
|
||||||
|
# Fuse pix_feats and downsampled masks, in case the visual features are on CPU, cast them to CUDA |
||||||
|
pix_feat = pix_feat.to(masks.device) |
||||||
|
|
||||||
|
x = self.pix_feat_proj(pix_feat) |
||||||
|
x = x + masks |
||||||
|
x = self.fuser(x) |
||||||
|
x = self.out_proj(x) |
||||||
|
|
||||||
|
pos = self.position_encoding(x).to(x.dtype) |
||||||
|
|
||||||
|
return {"vision_features": x, "vision_pos_enc": [pos]} |
||||||
|
|
||||||
|
|
||||||
|
class ImageEncoder(nn.Module): |
||||||
|
"""Encodes images using a trunk-neck architecture, producing multiscale features and positional encodings.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
trunk: nn.Module, |
||||||
|
neck: nn.Module, |
||||||
|
scalp: int = 0, |
||||||
|
): |
||||||
|
"""Initializes an image encoder with a trunk, neck, and optional scalp for feature extraction.""" |
||||||
|
super().__init__() |
||||||
|
self.trunk = trunk |
||||||
|
self.neck = neck |
||||||
|
self.scalp = scalp |
||||||
|
assert ( |
||||||
|
self.trunk.channel_list == self.neck.backbone_channel_list |
||||||
|
), f"Channel dims of trunk {self.trunk.channel_list} and neck {self.neck.backbone_channel_list} do not match." |
||||||
|
|
||||||
|
def forward(self, sample: torch.Tensor): |
||||||
|
"""Processes image input through trunk and neck, returning features, positional encodings, and FPN outputs.""" |
||||||
|
features, pos = self.neck(self.trunk(sample)) |
||||||
|
if self.scalp > 0: |
||||||
|
# Discard the lowest resolution features |
||||||
|
features, pos = features[: -self.scalp], pos[: -self.scalp] |
||||||
|
|
||||||
|
src = features[-1] |
||||||
|
output = { |
||||||
|
"vision_features": src, |
||||||
|
"vision_pos_enc": pos, |
||||||
|
"backbone_fpn": features, |
||||||
|
} |
||||||
|
return output |
||||||
|
|
||||||
|
|
||||||
|
class FpnNeck(nn.Module): |
||||||
|
"""Feature Pyramid Network (FPN) neck variant for multiscale feature fusion in object detection models.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
d_model: int, |
||||||
|
backbone_channel_list: List[int], |
||||||
|
kernel_size: int = 1, |
||||||
|
stride: int = 1, |
||||||
|
padding: int = 0, |
||||||
|
fpn_interp_model: str = "bilinear", |
||||||
|
fuse_type: str = "sum", |
||||||
|
fpn_top_down_levels: Optional[List[int]] = None, |
||||||
|
): |
||||||
|
""" |
||||||
|
Initializes a modified Feature Pyramid Network (FPN) neck. |
||||||
|
|
||||||
|
This FPN variant removes the output convolution and uses bicubic interpolation for feature resizing, |
||||||
|
similar to ViT positional embedding interpolation. |
||||||
|
|
||||||
|
Args: |
||||||
|
d_model (int): Dimension of the model. |
||||||
|
backbone_channel_list (List[int]): List of channel dimensions from the backbone. |
||||||
|
kernel_size (int): Kernel size for the convolutional layers. |
||||||
|
stride (int): Stride for the convolutional layers. |
||||||
|
padding (int): Padding for the convolutional layers. |
||||||
|
fpn_interp_model (str): Interpolation mode for FPN feature resizing. |
||||||
|
fuse_type (str): Type of feature fusion, either 'sum' or 'avg'. |
||||||
|
fpn_top_down_levels (Optional[List[int]]): Levels to have top-down features in outputs. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
position_encoding (PositionEmbeddingSine): Sinusoidal positional encoding. |
||||||
|
convs (nn.ModuleList): List of convolutional layers for each backbone level. |
||||||
|
backbone_channel_list (List[int]): List of channel dimensions from the backbone. |
||||||
|
fpn_interp_model (str): Interpolation mode for FPN feature resizing. |
||||||
|
fuse_type (str): Type of feature fusion. |
||||||
|
fpn_top_down_levels (List[int]): Levels with top-down feature propagation. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> backbone_channels = [64, 128, 256, 512] |
||||||
|
>>> fpn_neck = FpnNeck(256, backbone_channels) |
||||||
|
>>> print(fpn_neck) |
||||||
|
""" |
||||||
|
super().__init__() |
||||||
|
self.position_encoding = PositionEmbeddingSine(num_pos_feats=256) |
||||||
|
self.convs = nn.ModuleList() |
||||||
|
self.backbone_channel_list = backbone_channel_list |
||||||
|
for dim in backbone_channel_list: |
||||||
|
current = nn.Sequential() |
||||||
|
current.add_module( |
||||||
|
"conv", |
||||||
|
nn.Conv2d( |
||||||
|
in_channels=dim, |
||||||
|
out_channels=d_model, |
||||||
|
kernel_size=kernel_size, |
||||||
|
stride=stride, |
||||||
|
padding=padding, |
||||||
|
), |
||||||
|
) |
||||||
|
|
||||||
|
self.convs.append(current) |
||||||
|
self.fpn_interp_model = fpn_interp_model |
||||||
|
assert fuse_type in ["sum", "avg"] |
||||||
|
self.fuse_type = fuse_type |
||||||
|
|
||||||
|
# levels to have top-down features in its outputs |
||||||
|
# e.g. if fpn_top_down_levels is [2, 3], then only outputs of level 2 and 3 |
||||||
|
# have top-down propagation, while outputs of level 0 and level 1 have only |
||||||
|
# lateral features from the same backbone level. |
||||||
|
if fpn_top_down_levels is None: |
||||||
|
# default is to have top-down features on all levels |
||||||
|
fpn_top_down_levels = range(len(self.convs)) |
||||||
|
self.fpn_top_down_levels = list(fpn_top_down_levels) |
||||||
|
|
||||||
|
def forward(self, xs: List[torch.Tensor]): |
||||||
|
""" |
||||||
|
Performs forward pass through the Feature Pyramid Network (FPN) neck. |
||||||
|
|
||||||
|
Args: |
||||||
|
xs (List[torch.Tensor]): List of input tensors from the backbone, with shape (B, C, H, W) for each tensor. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Tuple[List[torch.Tensor], List[torch.Tensor]]): A tuple containing two lists: |
||||||
|
- out: List of output feature maps after FPN processing, with shape (B, d_model, H, W) for each tensor. |
||||||
|
- pos: List of positional encodings corresponding to each output feature map. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> fpn_neck = FpnNeck(d_model=256, backbone_channel_list=[64, 128, 256, 512]) |
||||||
|
>>> inputs = [torch.rand(1, c, 32, 32) for c in [64, 128, 256, 512]] |
||||||
|
>>> outputs, positions = fpn_neck(inputs) |
||||||
|
""" |
||||||
|
out = [None] * len(self.convs) |
||||||
|
pos = [None] * len(self.convs) |
||||||
|
assert len(xs) == len(self.convs) |
||||||
|
# fpn forward pass |
||||||
|
# see https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/fpn.py |
||||||
|
prev_features = None |
||||||
|
# forward in top-down order (from low to high resolution) |
||||||
|
n = len(self.convs) - 1 |
||||||
|
for i in range(n, -1, -1): |
||||||
|
x = xs[i] |
||||||
|
lateral_features = self.convs[n - i](x) |
||||||
|
if i in self.fpn_top_down_levels and prev_features is not None: |
||||||
|
top_down_features = F.interpolate( |
||||||
|
prev_features.to(dtype=torch.float32), |
||||||
|
scale_factor=2.0, |
||||||
|
mode=self.fpn_interp_model, |
||||||
|
align_corners=(None if self.fpn_interp_model == "nearest" else False), |
||||||
|
antialias=False, |
||||||
|
) |
||||||
|
prev_features = lateral_features + top_down_features |
||||||
|
if self.fuse_type == "avg": |
||||||
|
prev_features /= 2 |
||||||
|
else: |
||||||
|
prev_features = lateral_features |
||||||
|
x_out = prev_features |
||||||
|
out[i] = x_out |
||||||
|
pos[i] = self.position_encoding(x_out).to(x_out.dtype) |
||||||
|
|
||||||
|
return out, pos |
||||||
|
|
||||||
|
|
||||||
|
class Hiera(nn.Module): |
||||||
|
"""Hierarchical vision transformer for efficient multiscale feature extraction in image processing tasks.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
embed_dim: int = 96, # initial embed dim |
||||||
|
num_heads: int = 1, # initial number of heads |
||||||
|
drop_path_rate: float = 0.0, # stochastic depth |
||||||
|
q_pool: int = 3, # number of q_pool stages |
||||||
|
q_stride: Tuple[int, int] = (2, 2), # downsample stride bet. stages |
||||||
|
stages: Tuple[int, ...] = (2, 3, 16, 3), # blocks per stage |
||||||
|
dim_mul: float = 2.0, # dim_mul factor at stage shift |
||||||
|
head_mul: float = 2.0, # head_mul factor at stage shift |
||||||
|
window_pos_embed_bkg_spatial_size: Tuple[int, int] = (14, 14), |
||||||
|
# window size per stage, when not using global att. |
||||||
|
window_spec: Tuple[int, ...] = ( |
||||||
|
8, |
||||||
|
4, |
||||||
|
14, |
||||||
|
7, |
||||||
|
), |
||||||
|
# global attn in these blocks |
||||||
|
global_att_blocks: Tuple[int, ...] = ( |
||||||
|
12, |
||||||
|
16, |
||||||
|
20, |
||||||
|
), |
||||||
|
return_interm_layers=True, # return feats from every stage |
||||||
|
): |
||||||
|
"""Initializes a Hiera model with configurable architecture for hierarchical vision transformers.""" |
||||||
|
super().__init__() |
||||||
|
|
||||||
|
assert len(stages) == len(window_spec) |
||||||
|
self.window_spec = window_spec |
||||||
|
|
||||||
|
depth = sum(stages) |
||||||
|
self.q_stride = q_stride |
||||||
|
self.stage_ends = [sum(stages[:i]) - 1 for i in range(1, len(stages) + 1)] |
||||||
|
assert 0 <= q_pool <= len(self.stage_ends[:-1]) |
||||||
|
self.q_pool_blocks = [x + 1 for x in self.stage_ends[:-1]][:q_pool] |
||||||
|
self.return_interm_layers = return_interm_layers |
||||||
|
|
||||||
|
self.patch_embed = PatchEmbed( |
||||||
|
embed_dim=embed_dim, |
||||||
|
kernel_size=(7, 7), |
||||||
|
stride=(4, 4), |
||||||
|
padding=(3, 3), |
||||||
|
) |
||||||
|
# Which blocks have global att? |
||||||
|
self.global_att_blocks = global_att_blocks |
||||||
|
|
||||||
|
# Windowed positional embedding (https://arxiv.org/abs/2311.05613) |
||||||
|
self.window_pos_embed_bkg_spatial_size = window_pos_embed_bkg_spatial_size |
||||||
|
self.pos_embed = nn.Parameter(torch.zeros(1, embed_dim, *self.window_pos_embed_bkg_spatial_size)) |
||||||
|
self.pos_embed_window = nn.Parameter(torch.zeros(1, embed_dim, self.window_spec[0], self.window_spec[0])) |
||||||
|
|
||||||
|
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule |
||||||
|
|
||||||
|
cur_stage = 1 |
||||||
|
self.blocks = nn.ModuleList() |
||||||
|
|
||||||
|
for i in range(depth): |
||||||
|
dim_out = embed_dim |
||||||
|
# lags by a block, so first block of |
||||||
|
# next stage uses an initial window size |
||||||
|
# of previous stage and final window size of current stage |
||||||
|
window_size = self.window_spec[cur_stage - 1] |
||||||
|
|
||||||
|
if self.global_att_blocks is not None: |
||||||
|
window_size = 0 if i in self.global_att_blocks else window_size |
||||||
|
|
||||||
|
if i - 1 in self.stage_ends: |
||||||
|
dim_out = int(embed_dim * dim_mul) |
||||||
|
num_heads = int(num_heads * head_mul) |
||||||
|
cur_stage += 1 |
||||||
|
|
||||||
|
block = MultiScaleBlock( |
||||||
|
dim=embed_dim, |
||||||
|
dim_out=dim_out, |
||||||
|
num_heads=num_heads, |
||||||
|
drop_path=dpr[i], |
||||||
|
q_stride=self.q_stride if i in self.q_pool_blocks else None, |
||||||
|
window_size=window_size, |
||||||
|
) |
||||||
|
|
||||||
|
embed_dim = dim_out |
||||||
|
self.blocks.append(block) |
||||||
|
|
||||||
|
self.channel_list = ( |
||||||
|
[self.blocks[i].dim_out for i in self.stage_ends[::-1]] |
||||||
|
if return_interm_layers |
||||||
|
else [self.blocks[-1].dim_out] |
||||||
|
) |
||||||
|
|
||||||
|
def _get_pos_embed(self, hw: Tuple[int, int]) -> torch.Tensor: |
||||||
|
"""Generate positional embeddings by interpolating and combining window and background embeddings.""" |
||||||
|
h, w = hw |
||||||
|
window_embed = self.pos_embed_window |
||||||
|
pos_embed = F.interpolate(self.pos_embed, size=(h, w), mode="bicubic") |
||||||
|
pos_embed = pos_embed + window_embed.tile([x // y for x, y in zip(pos_embed.shape, window_embed.shape)]) |
||||||
|
pos_embed = pos_embed.permute(0, 2, 3, 1) |
||||||
|
return pos_embed |
||||||
|
|
||||||
|
def forward(self, x: torch.Tensor) -> List[torch.Tensor]: |
||||||
|
"""Performs hierarchical vision transformer forward pass, returning multiscale feature maps.""" |
||||||
|
x = self.patch_embed(x) |
||||||
|
# x: (B, H, W, C) |
||||||
|
|
||||||
|
# Add pos embed |
||||||
|
x = x + self._get_pos_embed(x.shape[1:3]) |
||||||
|
|
||||||
|
outputs = [] |
||||||
|
for i, blk in enumerate(self.blocks): |
||||||
|
x = blk(x) |
||||||
|
if (i == self.stage_ends[-1]) or (i in self.stage_ends and self.return_interm_layers): |
||||||
|
feats = x.permute(0, 3, 1, 2) |
||||||
|
outputs.append(feats) |
||||||
|
|
||||||
|
return outputs |
||||||
@ -0,0 +1,170 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import copy |
||||||
|
from typing import Optional |
||||||
|
|
||||||
|
import torch |
||||||
|
from torch import Tensor, nn |
||||||
|
|
||||||
|
from .sam2_blocks import RoPEAttention |
||||||
|
|
||||||
|
|
||||||
|
class MemoryAttentionLayer(nn.Module): |
||||||
|
"""Implements a memory attention layer with self-attention and cross-attention mechanisms for neural networks.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
d_model: int = 256, |
||||||
|
dim_feedforward: int = 2048, |
||||||
|
dropout: float = 0.1, |
||||||
|
pos_enc_at_attn: bool = False, |
||||||
|
pos_enc_at_cross_attn_keys: bool = True, |
||||||
|
pos_enc_at_cross_attn_queries: bool = False, |
||||||
|
): |
||||||
|
"""Initializes a MemoryAttentionLayer with self-attention, cross-attention, and feedforward components.""" |
||||||
|
super().__init__() |
||||||
|
self.d_model = d_model |
||||||
|
self.dim_feedforward = dim_feedforward |
||||||
|
self.dropout_value = dropout |
||||||
|
self.self_attn = RoPEAttention(embedding_dim=256, num_heads=1, downsample_rate=1) |
||||||
|
self.cross_attn_image = RoPEAttention( |
||||||
|
rope_k_repeat=True, |
||||||
|
embedding_dim=256, |
||||||
|
num_heads=1, |
||||||
|
downsample_rate=1, |
||||||
|
kv_in_dim=64, |
||||||
|
) |
||||||
|
|
||||||
|
# Implementation of Feedforward model |
||||||
|
self.linear1 = nn.Linear(d_model, dim_feedforward) |
||||||
|
self.dropout = nn.Dropout(dropout) |
||||||
|
self.linear2 = nn.Linear(dim_feedforward, d_model) |
||||||
|
|
||||||
|
self.norm1 = nn.LayerNorm(d_model) |
||||||
|
self.norm2 = nn.LayerNorm(d_model) |
||||||
|
self.norm3 = nn.LayerNorm(d_model) |
||||||
|
self.dropout1 = nn.Dropout(dropout) |
||||||
|
self.dropout2 = nn.Dropout(dropout) |
||||||
|
self.dropout3 = nn.Dropout(dropout) |
||||||
|
|
||||||
|
self.activation = nn.ReLU() |
||||||
|
|
||||||
|
# Where to add pos enc |
||||||
|
self.pos_enc_at_attn = pos_enc_at_attn |
||||||
|
self.pos_enc_at_cross_attn_queries = pos_enc_at_cross_attn_queries |
||||||
|
self.pos_enc_at_cross_attn_keys = pos_enc_at_cross_attn_keys |
||||||
|
|
||||||
|
def _forward_sa(self, tgt, query_pos): |
||||||
|
"""Performs self-attention on input tensor using positional encoding and RoPE attention mechanism.""" |
||||||
|
tgt2 = self.norm1(tgt) |
||||||
|
q = k = tgt2 + query_pos if self.pos_enc_at_attn else tgt2 |
||||||
|
tgt2 = self.self_attn(q, k, v=tgt2) |
||||||
|
tgt = tgt + self.dropout1(tgt2) |
||||||
|
return tgt |
||||||
|
|
||||||
|
def _forward_ca(self, tgt, memory, query_pos, pos, num_k_exclude_rope=0): |
||||||
|
"""Performs cross-attention between target and memory tensors using RoPEAttention mechanism.""" |
||||||
|
kwds = {} |
||||||
|
if num_k_exclude_rope > 0: |
||||||
|
assert isinstance(self.cross_attn_image, RoPEAttention) |
||||||
|
kwds = {"num_k_exclude_rope": num_k_exclude_rope} |
||||||
|
|
||||||
|
# Cross-Attention |
||||||
|
tgt2 = self.norm2(tgt) |
||||||
|
tgt2 = self.cross_attn_image( |
||||||
|
q=tgt2 + query_pos if self.pos_enc_at_cross_attn_queries else tgt2, |
||||||
|
k=memory + pos if self.pos_enc_at_cross_attn_keys else memory, |
||||||
|
v=memory, |
||||||
|
**kwds, |
||||||
|
) |
||||||
|
tgt = tgt + self.dropout2(tgt2) |
||||||
|
return tgt |
||||||
|
|
||||||
|
def forward( |
||||||
|
self, |
||||||
|
tgt, |
||||||
|
memory, |
||||||
|
pos: Optional[Tensor] = None, |
||||||
|
query_pos: Optional[Tensor] = None, |
||||||
|
num_k_exclude_rope: int = 0, |
||||||
|
) -> torch.Tensor: |
||||||
|
"""Performs self-attention, cross-attention, and MLP operations on input tensors for memory-based attention.""" |
||||||
|
tgt = self._forward_sa(tgt, query_pos) |
||||||
|
tgt = self._forward_ca(tgt, memory, query_pos, pos, num_k_exclude_rope) |
||||||
|
# MLP |
||||||
|
tgt2 = self.norm3(tgt) |
||||||
|
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2)))) |
||||||
|
tgt = tgt + self.dropout3(tgt2) |
||||||
|
return tgt |
||||||
|
|
||||||
|
|
||||||
|
class MemoryAttention(nn.Module): |
||||||
|
"""Memory attention module for processing sequential data with self and cross-attention mechanisms.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
d_model: int, |
||||||
|
pos_enc_at_input: bool, |
||||||
|
layer: nn.Module, |
||||||
|
num_layers: int, |
||||||
|
batch_first: bool = True, # Do layers expect batch first input? |
||||||
|
): |
||||||
|
"""Initializes MemoryAttention module with layers and normalization for attention processing.""" |
||||||
|
super().__init__() |
||||||
|
self.d_model = d_model |
||||||
|
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(num_layers)]) |
||||||
|
self.num_layers = num_layers |
||||||
|
self.norm = nn.LayerNorm(d_model) |
||||||
|
self.pos_enc_at_input = pos_enc_at_input |
||||||
|
self.batch_first = batch_first |
||||||
|
|
||||||
|
def forward( |
||||||
|
self, |
||||||
|
curr: torch.Tensor, # self-attention inputs |
||||||
|
memory: torch.Tensor, # cross-attention inputs |
||||||
|
curr_pos: Optional[Tensor] = None, # pos_enc for self-attention inputs |
||||||
|
memory_pos: Optional[Tensor] = None, # pos_enc for cross-attention inputs |
||||||
|
num_obj_ptr_tokens: int = 0, # number of object pointer *tokens* |
||||||
|
): |
||||||
|
"""Applies self-attention and cross-attention to input tensors, processing through multiple layers.""" |
||||||
|
if isinstance(curr, list): |
||||||
|
assert isinstance(curr_pos, list) |
||||||
|
assert len(curr) == len(curr_pos) == 1 |
||||||
|
curr, curr_pos = ( |
||||||
|
curr[0], |
||||||
|
curr_pos[0], |
||||||
|
) |
||||||
|
|
||||||
|
assert curr.shape[1] == memory.shape[1], "Batch size must be the same for curr and memory" |
||||||
|
|
||||||
|
output = curr |
||||||
|
if self.pos_enc_at_input and curr_pos is not None: |
||||||
|
output = output + 0.1 * curr_pos |
||||||
|
|
||||||
|
if self.batch_first: |
||||||
|
# Convert to batch first |
||||||
|
output = output.transpose(0, 1) |
||||||
|
curr_pos = curr_pos.transpose(0, 1) |
||||||
|
memory = memory.transpose(0, 1) |
||||||
|
memory_pos = memory_pos.transpose(0, 1) |
||||||
|
|
||||||
|
for layer in self.layers: |
||||||
|
kwds = {} |
||||||
|
if isinstance(layer.cross_attn_image, RoPEAttention): |
||||||
|
kwds = {"num_k_exclude_rope": num_obj_ptr_tokens} |
||||||
|
|
||||||
|
output = layer( |
||||||
|
tgt=output, |
||||||
|
memory=memory, |
||||||
|
pos=memory_pos, |
||||||
|
query_pos=curr_pos, |
||||||
|
**kwds, |
||||||
|
) |
||||||
|
normed_output = self.norm(output) |
||||||
|
|
||||||
|
if self.batch_first: |
||||||
|
# Convert back to seq first |
||||||
|
normed_output = normed_output.transpose(0, 1) |
||||||
|
curr_pos = curr_pos.transpose(0, 1) |
||||||
|
|
||||||
|
return normed_output |
||||||
@ -0,0 +1,804 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import torch |
||||||
|
import torch.distributed |
||||||
|
import torch.nn.functional as F |
||||||
|
from torch.nn.init import trunc_normal_ |
||||||
|
|
||||||
|
from ultralytics.models.sam.modules.encoders import PromptEncoder |
||||||
|
from ultralytics.nn.modules import MLP |
||||||
|
|
||||||
|
from .decoders import MaskDecoder |
||||||
|
from .sam2_blocks import TwoWayTransformer |
||||||
|
from .utils import get_1d_sine_pe, select_closest_cond_frames |
||||||
|
|
||||||
|
# a large negative value as a placeholder score for missing objects |
||||||
|
NO_OBJ_SCORE = -1024.0 |
||||||
|
|
||||||
|
|
||||||
|
class SAM2Model(torch.nn.Module): |
||||||
|
"""SAM2Model class for Segment Anything Model 2 with memory-based video object segmentation capabilities.""" |
||||||
|
|
||||||
|
mask_threshold: float = 0.0 |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
image_encoder, |
||||||
|
memory_attention, |
||||||
|
memory_encoder, |
||||||
|
num_maskmem=7, # default 1 input frame + 6 previous frames |
||||||
|
image_size=512, |
||||||
|
backbone_stride=16, # stride of the image backbone output |
||||||
|
sigmoid_scale_for_mem_enc=1.0, # scale factor for mask sigmoid prob |
||||||
|
sigmoid_bias_for_mem_enc=0.0, # bias factor for mask sigmoid prob |
||||||
|
# During evaluation, whether to binarize the sigmoid mask logits on interacted frames with clicks |
||||||
|
binarize_mask_from_pts_for_mem_enc=False, |
||||||
|
use_mask_input_as_output_without_sam=False, # on frames with mask input, whether to directly output the input mask without using a SAM prompt encoder + mask decoder |
||||||
|
# The maximum number of conditioning frames to participate in the memory attention (-1 means no limit; if there are more conditioning frames than this limit, |
||||||
|
# we only cross-attend to the temporally closest `max_cond_frames_in_attn` conditioning frames in the encoder when tracking each frame). This gives the model |
||||||
|
# a temporal locality when handling a large number of annotated frames (since closer frames should be more important) and also avoids GPU OOM. |
||||||
|
max_cond_frames_in_attn=-1, |
||||||
|
# on the first frame, whether to directly add the no-memory embedding to the image feature |
||||||
|
# (instead of using the transformer encoder) |
||||||
|
directly_add_no_mem_embed=False, |
||||||
|
# whether to use high-resolution feature maps in the SAM mask decoder |
||||||
|
use_high_res_features_in_sam=False, |
||||||
|
# whether to output multiple (3) masks for the first click on initial conditioning frames |
||||||
|
multimask_output_in_sam=False, |
||||||
|
# the minimum and maximum number of clicks to use multimask_output_in_sam (only relevant when `multimask_output_in_sam=True`; |
||||||
|
# default is 1 for both, meaning that only the first click gives multimask output; also note that a box counts as two points) |
||||||
|
multimask_min_pt_num=1, |
||||||
|
multimask_max_pt_num=1, |
||||||
|
# whether to also use multimask output for tracking (not just for the first click on initial conditioning frames; only relevant when `multimask_output_in_sam=True`) |
||||||
|
multimask_output_for_tracking=False, |
||||||
|
# Whether to use multimask tokens for obj ptr; Only relevant when both |
||||||
|
# use_obj_ptrs_in_encoder=True and multimask_output_for_tracking=True |
||||||
|
use_multimask_token_for_obj_ptr: bool = False, |
||||||
|
# whether to use sigmoid to restrict ious prediction to [0-1] |
||||||
|
iou_prediction_use_sigmoid=False, |
||||||
|
# The memory bank's temporal stride during evaluation (i.e. the `r` parameter in XMem and Cutie; XMem and Cutie use r=5). |
||||||
|
# For r>1, the (self.num_maskmem - 1) non-conditioning memory frames consist of |
||||||
|
# (self.num_maskmem - 2) nearest frames from every r-th frames, plus the last frame. |
||||||
|
memory_temporal_stride_for_eval=1, |
||||||
|
# if `add_all_frames_to_correct_as_cond` is True, we also append to the conditioning frame list any frame that receives a later correction click |
||||||
|
# if `add_all_frames_to_correct_as_cond` is False, we conditioning frame list to only use those initial conditioning frames |
||||||
|
add_all_frames_to_correct_as_cond=False, |
||||||
|
# whether to apply non-overlapping constraints on the object masks in the memory encoder during evaluation (to avoid/alleviate superposing masks) |
||||||
|
non_overlap_masks_for_mem_enc=False, |
||||||
|
# whether to cross-attend to object pointers from other frames (based on SAM output tokens) in the encoder |
||||||
|
use_obj_ptrs_in_encoder=False, |
||||||
|
# the maximum number of object pointers from other frames in encoder cross attention (only relevant when `use_obj_ptrs_in_encoder=True`) |
||||||
|
max_obj_ptrs_in_encoder=16, |
||||||
|
# whether to add temporal positional encoding to the object pointers in the encoder (only relevant when `use_obj_ptrs_in_encoder=True`) |
||||||
|
add_tpos_enc_to_obj_ptrs=True, |
||||||
|
# whether to add an extra linear projection layer for the temporal positional encoding in the object pointers to avoid potential interference |
||||||
|
# with spatial positional encoding (only relevant when both `use_obj_ptrs_in_encoder=True` and `add_tpos_enc_to_obj_ptrs=True`) |
||||||
|
proj_tpos_enc_in_obj_ptrs=False, |
||||||
|
# whether to only attend to object pointers in the past (before the current frame) in the encoder during evaluation |
||||||
|
# (only relevant when `use_obj_ptrs_in_encoder=True`; this might avoid pointer information too far in the future to distract the initial tracking) |
||||||
|
only_obj_ptrs_in_the_past_for_eval=False, |
||||||
|
# Whether to predict if there is an object in the frame |
||||||
|
pred_obj_scores: bool = False, |
||||||
|
# Whether to use an MLP to predict object scores |
||||||
|
pred_obj_scores_mlp: bool = False, |
||||||
|
# Only relevant if pred_obj_scores=True and use_obj_ptrs_in_encoder=True; |
||||||
|
# Whether to have a fixed no obj pointer when there is no object present |
||||||
|
# or to use it as an additive embedding with obj_ptr produced by decoder |
||||||
|
fixed_no_obj_ptr: bool = False, |
||||||
|
# Soft no object, i.e. mix in no_obj_ptr softly, |
||||||
|
# hope to make recovery easier if there is a mistake and mitigate accumulation of errors |
||||||
|
soft_no_obj_ptr: bool = False, |
||||||
|
use_mlp_for_obj_ptr_proj: bool = False, |
||||||
|
# extra arguments used to construct the SAM mask decoder; if not None, it should be a dict of kwargs to be passed into `MaskDecoder` class. |
||||||
|
sam_mask_decoder_extra_args=None, |
||||||
|
compile_image_encoder: bool = False, |
||||||
|
): |
||||||
|
"""Initializes SAM2Model model with image encoder, memory attention, and memory encoder components.""" |
||||||
|
super().__init__() |
||||||
|
|
||||||
|
# Part 1: the image backbone |
||||||
|
self.image_encoder = image_encoder |
||||||
|
# Use level 0, 1, 2 for high-res setting, or just level 2 for the default setting |
||||||
|
self.use_high_res_features_in_sam = use_high_res_features_in_sam |
||||||
|
self.num_feature_levels = 3 if use_high_res_features_in_sam else 1 |
||||||
|
self.use_obj_ptrs_in_encoder = use_obj_ptrs_in_encoder |
||||||
|
self.max_obj_ptrs_in_encoder = max_obj_ptrs_in_encoder |
||||||
|
if use_obj_ptrs_in_encoder: |
||||||
|
# A conv layer to downsample the mask prompt to stride 4 (the same stride as |
||||||
|
# low-res SAM mask logits) and to change its scales from 0~1 to SAM logit scale, |
||||||
|
# so that it can be fed into the SAM mask decoder to generate a pointer. |
||||||
|
self.mask_downsample = torch.nn.Conv2d(1, 1, kernel_size=4, stride=4) |
||||||
|
self.add_tpos_enc_to_obj_ptrs = add_tpos_enc_to_obj_ptrs |
||||||
|
if proj_tpos_enc_in_obj_ptrs: |
||||||
|
assert add_tpos_enc_to_obj_ptrs # these options need to be used together |
||||||
|
self.proj_tpos_enc_in_obj_ptrs = proj_tpos_enc_in_obj_ptrs |
||||||
|
self.only_obj_ptrs_in_the_past_for_eval = only_obj_ptrs_in_the_past_for_eval |
||||||
|
|
||||||
|
# Part 2: memory attention to condition current frame's visual features |
||||||
|
# with memories (and obj ptrs) from past frames |
||||||
|
self.memory_attention = memory_attention |
||||||
|
self.hidden_dim = memory_attention.d_model |
||||||
|
|
||||||
|
# Part 3: memory encoder for the previous frame's outputs |
||||||
|
self.memory_encoder = memory_encoder |
||||||
|
self.mem_dim = self.hidden_dim |
||||||
|
if hasattr(self.memory_encoder, "out_proj") and hasattr(self.memory_encoder.out_proj, "weight"): |
||||||
|
# if there is compression of memories along channel dim |
||||||
|
self.mem_dim = self.memory_encoder.out_proj.weight.shape[0] |
||||||
|
self.num_maskmem = num_maskmem # Number of memories accessible |
||||||
|
# Temporal encoding of the memories |
||||||
|
self.maskmem_tpos_enc = torch.nn.Parameter(torch.zeros(num_maskmem, 1, 1, self.mem_dim)) |
||||||
|
trunc_normal_(self.maskmem_tpos_enc, std=0.02) |
||||||
|
# a single token to indicate no memory embedding from previous frames |
||||||
|
self.no_mem_embed = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim)) |
||||||
|
self.no_mem_pos_enc = torch.nn.Parameter(torch.zeros(1, 1, self.hidden_dim)) |
||||||
|
trunc_normal_(self.no_mem_embed, std=0.02) |
||||||
|
trunc_normal_(self.no_mem_pos_enc, std=0.02) |
||||||
|
self.directly_add_no_mem_embed = directly_add_no_mem_embed |
||||||
|
# Apply sigmoid to the output raw mask logits (to turn them from |
||||||
|
# range (-inf, +inf) to range (0, 1)) before feeding them into the memory encoder |
||||||
|
self.sigmoid_scale_for_mem_enc = sigmoid_scale_for_mem_enc |
||||||
|
self.sigmoid_bias_for_mem_enc = sigmoid_bias_for_mem_enc |
||||||
|
self.binarize_mask_from_pts_for_mem_enc = binarize_mask_from_pts_for_mem_enc |
||||||
|
self.non_overlap_masks_for_mem_enc = non_overlap_masks_for_mem_enc |
||||||
|
self.memory_temporal_stride_for_eval = memory_temporal_stride_for_eval |
||||||
|
# On frames with mask input, whether to directly output the input mask without |
||||||
|
# using a SAM prompt encoder + mask decoder |
||||||
|
self.use_mask_input_as_output_without_sam = use_mask_input_as_output_without_sam |
||||||
|
self.multimask_output_in_sam = multimask_output_in_sam |
||||||
|
self.multimask_min_pt_num = multimask_min_pt_num |
||||||
|
self.multimask_max_pt_num = multimask_max_pt_num |
||||||
|
self.multimask_output_for_tracking = multimask_output_for_tracking |
||||||
|
self.use_multimask_token_for_obj_ptr = use_multimask_token_for_obj_ptr |
||||||
|
self.iou_prediction_use_sigmoid = iou_prediction_use_sigmoid |
||||||
|
|
||||||
|
# Part 4: SAM-style prompt encoder (for both mask and point inputs) |
||||||
|
# and SAM-style mask decoder for the final mask output |
||||||
|
self.image_size = image_size |
||||||
|
self.backbone_stride = backbone_stride |
||||||
|
self.sam_mask_decoder_extra_args = sam_mask_decoder_extra_args |
||||||
|
self.pred_obj_scores = pred_obj_scores |
||||||
|
self.pred_obj_scores_mlp = pred_obj_scores_mlp |
||||||
|
self.fixed_no_obj_ptr = fixed_no_obj_ptr |
||||||
|
self.soft_no_obj_ptr = soft_no_obj_ptr |
||||||
|
if self.fixed_no_obj_ptr: |
||||||
|
assert self.pred_obj_scores |
||||||
|
assert self.use_obj_ptrs_in_encoder |
||||||
|
if self.pred_obj_scores and self.use_obj_ptrs_in_encoder: |
||||||
|
self.no_obj_ptr = torch.nn.Parameter(torch.zeros(1, self.hidden_dim)) |
||||||
|
trunc_normal_(self.no_obj_ptr, std=0.02) |
||||||
|
self.use_mlp_for_obj_ptr_proj = use_mlp_for_obj_ptr_proj |
||||||
|
|
||||||
|
self._build_sam_heads() |
||||||
|
self.add_all_frames_to_correct_as_cond = add_all_frames_to_correct_as_cond |
||||||
|
self.max_cond_frames_in_attn = max_cond_frames_in_attn |
||||||
|
|
||||||
|
# Model compilation |
||||||
|
if compile_image_encoder: |
||||||
|
# Compile the forward function (not the full module) to allow loading checkpoints. |
||||||
|
print("Image encoder compilation is enabled. First forward pass will be slow.") |
||||||
|
self.image_encoder.forward = torch.compile( |
||||||
|
self.image_encoder.forward, |
||||||
|
mode="max-autotune", |
||||||
|
fullgraph=True, |
||||||
|
dynamic=False, |
||||||
|
) |
||||||
|
|
||||||
|
@property |
||||||
|
def device(self): |
||||||
|
"""Returns the device on which the model's parameters are stored.""" |
||||||
|
return next(self.parameters()).device |
||||||
|
|
||||||
|
def forward(self, *args, **kwargs): |
||||||
|
"""Processes input frames and prompts to generate object masks and scores in video sequences.""" |
||||||
|
raise NotImplementedError( |
||||||
|
"Please use the corresponding methods in SAM2VideoPredictor for inference." |
||||||
|
"See notebooks/video_predictor_example.ipynb for an example." |
||||||
|
) |
||||||
|
|
||||||
|
def _build_sam_heads(self): |
||||||
|
"""Builds SAM-style prompt encoder and mask decoder for image segmentation tasks.""" |
||||||
|
self.sam_prompt_embed_dim = self.hidden_dim |
||||||
|
self.sam_image_embedding_size = self.image_size // self.backbone_stride |
||||||
|
|
||||||
|
# build PromptEncoder and MaskDecoder from SAM |
||||||
|
# (their hyperparameters like `mask_in_chans=16` are from SAM code) |
||||||
|
self.sam_prompt_encoder = PromptEncoder( |
||||||
|
embed_dim=self.sam_prompt_embed_dim, |
||||||
|
image_embedding_size=( |
||||||
|
self.sam_image_embedding_size, |
||||||
|
self.sam_image_embedding_size, |
||||||
|
), |
||||||
|
input_image_size=(self.image_size, self.image_size), |
||||||
|
mask_in_chans=16, |
||||||
|
) |
||||||
|
self.sam_mask_decoder = MaskDecoder( |
||||||
|
num_multimask_outputs=3, |
||||||
|
transformer=TwoWayTransformer( |
||||||
|
depth=2, |
||||||
|
embedding_dim=self.sam_prompt_embed_dim, |
||||||
|
mlp_dim=2048, |
||||||
|
num_heads=8, |
||||||
|
), |
||||||
|
transformer_dim=self.sam_prompt_embed_dim, |
||||||
|
iou_head_depth=3, |
||||||
|
iou_head_hidden_dim=256, |
||||||
|
use_high_res_features=self.use_high_res_features_in_sam, |
||||||
|
iou_prediction_use_sigmoid=self.iou_prediction_use_sigmoid, |
||||||
|
pred_obj_scores=self.pred_obj_scores, |
||||||
|
pred_obj_scores_mlp=self.pred_obj_scores_mlp, |
||||||
|
use_multimask_token_for_obj_ptr=self.use_multimask_token_for_obj_ptr, |
||||||
|
**(self.sam_mask_decoder_extra_args or {}), |
||||||
|
) |
||||||
|
if self.use_obj_ptrs_in_encoder: |
||||||
|
# a linear projection on SAM output tokens to turn them into object pointers |
||||||
|
self.obj_ptr_proj = torch.nn.Linear(self.hidden_dim, self.hidden_dim) |
||||||
|
if self.use_mlp_for_obj_ptr_proj: |
||||||
|
self.obj_ptr_proj = MLP(self.hidden_dim, self.hidden_dim, self.hidden_dim, 3) |
||||||
|
else: |
||||||
|
self.obj_ptr_proj = torch.nn.Identity() |
||||||
|
if self.proj_tpos_enc_in_obj_ptrs: |
||||||
|
# a linear projection on temporal positional encoding in object pointers to |
||||||
|
# avoid potential interference with spatial positional encoding |
||||||
|
self.obj_ptr_tpos_proj = torch.nn.Linear(self.hidden_dim, self.mem_dim) |
||||||
|
else: |
||||||
|
self.obj_ptr_tpos_proj = torch.nn.Identity() |
||||||
|
|
||||||
|
def _forward_sam_heads( |
||||||
|
self, |
||||||
|
backbone_features, |
||||||
|
point_inputs=None, |
||||||
|
mask_inputs=None, |
||||||
|
high_res_features=None, |
||||||
|
multimask_output=False, |
||||||
|
): |
||||||
|
""" |
||||||
|
Forward SAM prompt encoders and mask heads. |
||||||
|
|
||||||
|
Args: |
||||||
|
backbone_features (torch.Tensor): Image features with shape (B, C, H, W). |
||||||
|
point_inputs (Dict[str, torch.Tensor] | None): Dictionary containing point prompts. |
||||||
|
'point_coords': Tensor of shape (B, P, 2) with float32 dtype, containing absolute |
||||||
|
pixel-unit coordinates in (x, y) format for P input points. |
||||||
|
'point_labels': Tensor of shape (B, P) with int32 dtype, where 1 means positive clicks, |
||||||
|
0 means negative clicks, and -1 means padding. |
||||||
|
mask_inputs (torch.Tensor | None): Mask of shape (B, 1, H*16, W*16), float or bool, with the |
||||||
|
same spatial size as the image. |
||||||
|
high_res_features (List[torch.Tensor] | None): List of two feature maps with shapes |
||||||
|
(B, C, 4*H, 4*W) and (B, C, 2*H, 2*W) respectively, used as high-resolution feature maps |
||||||
|
for SAM decoder. |
||||||
|
multimask_output (bool): If True, output 3 candidate masks and their IoU estimates; if False, |
||||||
|
output only 1 mask and its IoU estimate. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]): |
||||||
|
low_res_multimasks: Tensor of shape (B, M, H*4, W*4) with SAM output mask logits. |
||||||
|
high_res_multimasks: Tensor of shape (B, M, H*16, W*16) with upsampled mask logits. |
||||||
|
ious: Tensor of shape (B, M) with estimated IoU for each output mask. |
||||||
|
low_res_masks: Tensor of shape (B, 1, H*4, W*4) with best low-resolution mask. |
||||||
|
high_res_masks: Tensor of shape (B, 1, H*16, W*16) with best high-resolution mask. |
||||||
|
obj_ptr: Tensor of shape (B, C) with object pointer vector for the output mask. |
||||||
|
object_score_logits: Tensor of shape (B,) with object score logits. |
||||||
|
|
||||||
|
Where M is 3 if multimask_output=True, and 1 if multimask_output=False. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> backbone_features = torch.rand(1, 256, 32, 32) |
||||||
|
>>> point_inputs = {"point_coords": torch.rand(1, 2, 2), "point_labels": torch.tensor([[1, 0]])} |
||||||
|
>>> mask_inputs = torch.rand(1, 1, 512, 512) |
||||||
|
>>> results = model._forward_sam_heads(backbone_features, point_inputs, mask_inputs) |
||||||
|
>>> low_res_multimasks, high_res_multimasks, ious, low_res_masks, high_res_masks, obj_ptr, object_score_logits = results |
||||||
|
""" |
||||||
|
B = backbone_features.size(0) |
||||||
|
device = backbone_features.device |
||||||
|
assert backbone_features.size(1) == self.sam_prompt_embed_dim |
||||||
|
assert backbone_features.size(2) == self.sam_image_embedding_size |
||||||
|
assert backbone_features.size(3) == self.sam_image_embedding_size |
||||||
|
|
||||||
|
# a) Handle point prompts |
||||||
|
if point_inputs is not None: |
||||||
|
sam_point_coords = point_inputs["point_coords"] |
||||||
|
sam_point_labels = point_inputs["point_labels"] |
||||||
|
assert sam_point_coords.size(0) == B and sam_point_labels.size(0) == B |
||||||
|
else: |
||||||
|
# If no points are provide, pad with an empty point (with label -1) |
||||||
|
sam_point_coords = torch.zeros(B, 1, 2, device=device) |
||||||
|
sam_point_labels = -torch.ones(B, 1, dtype=torch.int32, device=device) |
||||||
|
|
||||||
|
# b) Handle mask prompts |
||||||
|
if mask_inputs is not None: |
||||||
|
# If mask_inputs is provided, downsize it into low-res mask input if needed |
||||||
|
# and feed it as a dense mask prompt into the SAM mask encoder |
||||||
|
assert len(mask_inputs.shape) == 4 and mask_inputs.shape[:2] == (B, 1) |
||||||
|
if mask_inputs.shape[-2:] != self.sam_prompt_encoder.mask_input_size: |
||||||
|
sam_mask_prompt = F.interpolate( |
||||||
|
mask_inputs.float(), |
||||||
|
size=self.sam_prompt_encoder.mask_input_size, |
||||||
|
align_corners=False, |
||||||
|
mode="bilinear", |
||||||
|
antialias=True, # use antialias for downsampling |
||||||
|
) |
||||||
|
else: |
||||||
|
sam_mask_prompt = mask_inputs |
||||||
|
else: |
||||||
|
# Otherwise, simply feed None (and SAM's prompt encoder will add |
||||||
|
# a learned `no_mask_embed` to indicate no mask input in this case). |
||||||
|
sam_mask_prompt = None |
||||||
|
|
||||||
|
sparse_embeddings, dense_embeddings = self.sam_prompt_encoder( |
||||||
|
points=(sam_point_coords, sam_point_labels), |
||||||
|
boxes=None, |
||||||
|
masks=sam_mask_prompt, |
||||||
|
) |
||||||
|
( |
||||||
|
low_res_multimasks, |
||||||
|
ious, |
||||||
|
sam_output_tokens, |
||||||
|
object_score_logits, |
||||||
|
) = self.sam_mask_decoder( |
||||||
|
image_embeddings=backbone_features, |
||||||
|
image_pe=self.sam_prompt_encoder.get_dense_pe(), |
||||||
|
sparse_prompt_embeddings=sparse_embeddings, |
||||||
|
dense_prompt_embeddings=dense_embeddings, |
||||||
|
multimask_output=multimask_output, |
||||||
|
repeat_image=False, # the image is already batched |
||||||
|
high_res_features=high_res_features, |
||||||
|
) |
||||||
|
if self.pred_obj_scores: |
||||||
|
is_obj_appearing = object_score_logits > 0 |
||||||
|
|
||||||
|
# Mask used for spatial memories is always a *hard* choice between obj and no obj, |
||||||
|
# consistent with the actual mask prediction |
||||||
|
low_res_multimasks = torch.where( |
||||||
|
is_obj_appearing[:, None, None], |
||||||
|
low_res_multimasks, |
||||||
|
NO_OBJ_SCORE, |
||||||
|
) |
||||||
|
|
||||||
|
# convert masks from possibly bfloat16 (or float16) to float32 |
||||||
|
# (older PyTorch versions before 2.1 don't support `interpolate` on bf16) |
||||||
|
low_res_multimasks = low_res_multimasks.float() |
||||||
|
high_res_multimasks = F.interpolate( |
||||||
|
low_res_multimasks, |
||||||
|
size=(self.image_size, self.image_size), |
||||||
|
mode="bilinear", |
||||||
|
align_corners=False, |
||||||
|
) |
||||||
|
|
||||||
|
sam_output_token = sam_output_tokens[:, 0] |
||||||
|
if multimask_output: |
||||||
|
# take the best mask prediction (with the highest IoU estimation) |
||||||
|
best_iou_inds = torch.argmax(ious, dim=-1) |
||||||
|
batch_inds = torch.arange(B, device=device) |
||||||
|
low_res_masks = low_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1) |
||||||
|
high_res_masks = high_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1) |
||||||
|
if sam_output_tokens.size(1) > 1: |
||||||
|
sam_output_token = sam_output_tokens[batch_inds, best_iou_inds] |
||||||
|
else: |
||||||
|
low_res_masks, high_res_masks = low_res_multimasks, high_res_multimasks |
||||||
|
|
||||||
|
# Extract object pointer from the SAM output token (with occlusion handling) |
||||||
|
obj_ptr = self.obj_ptr_proj(sam_output_token) |
||||||
|
if self.pred_obj_scores: |
||||||
|
# Allow *soft* no obj ptr, unlike for masks |
||||||
|
if self.soft_no_obj_ptr: |
||||||
|
# Only hard possible with gt |
||||||
|
assert not self.teacher_force_obj_scores_for_mem |
||||||
|
lambda_is_obj_appearing = object_score_logits.sigmoid() |
||||||
|
else: |
||||||
|
lambda_is_obj_appearing = is_obj_appearing.float() |
||||||
|
|
||||||
|
if self.fixed_no_obj_ptr: |
||||||
|
obj_ptr = lambda_is_obj_appearing * obj_ptr |
||||||
|
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr |
||||||
|
|
||||||
|
return ( |
||||||
|
low_res_multimasks, |
||||||
|
high_res_multimasks, |
||||||
|
ious, |
||||||
|
low_res_masks, |
||||||
|
high_res_masks, |
||||||
|
obj_ptr, |
||||||
|
object_score_logits, |
||||||
|
) |
||||||
|
|
||||||
|
def _use_mask_as_output(self, backbone_features, high_res_features, mask_inputs): |
||||||
|
"""Processes mask inputs to generate output mask logits and object pointers without using SAM.""" |
||||||
|
# Use -10/+10 as logits for neg/pos pixels (very close to 0/1 in prob after sigmoid). |
||||||
|
out_scale, out_bias = 20.0, -10.0 # sigmoid(-10.0)=4.5398e-05 |
||||||
|
mask_inputs_float = mask_inputs.float() |
||||||
|
high_res_masks = mask_inputs_float * out_scale + out_bias |
||||||
|
low_res_masks = F.interpolate( |
||||||
|
high_res_masks, |
||||||
|
size=(high_res_masks.size(-2) // 4, high_res_masks.size(-1) // 4), |
||||||
|
align_corners=False, |
||||||
|
mode="bilinear", |
||||||
|
antialias=True, # use antialias for downsampling |
||||||
|
) |
||||||
|
# a dummy IoU prediction of all 1's under mask input |
||||||
|
ious = mask_inputs.new_ones(mask_inputs.size(0), 1).float() |
||||||
|
if not self.use_obj_ptrs_in_encoder: |
||||||
|
# all zeros as a dummy object pointer (of shape [B, C]) |
||||||
|
obj_ptr = torch.zeros(mask_inputs.size(0), self.hidden_dim, device=mask_inputs.device) |
||||||
|
else: |
||||||
|
# produce an object pointer using the SAM decoder from the mask input |
||||||
|
_, _, _, _, _, obj_ptr, _ = self._forward_sam_heads( |
||||||
|
backbone_features=backbone_features, |
||||||
|
mask_inputs=self.mask_downsample(mask_inputs_float), |
||||||
|
high_res_features=high_res_features, |
||||||
|
) |
||||||
|
# In this method, we are treating mask_input as output, e.g. using it directly to create spatial mem; |
||||||
|
# Below, we follow the same design axiom to use mask_input to decide if obj appears or not instead of relying |
||||||
|
# on the object_scores from the SAM decoder. |
||||||
|
is_obj_appearing = torch.any(mask_inputs.flatten(1).float() > 0.0, dim=1) |
||||||
|
is_obj_appearing = is_obj_appearing[..., None] |
||||||
|
lambda_is_obj_appearing = is_obj_appearing.float() |
||||||
|
object_score_logits = out_scale * lambda_is_obj_appearing + out_bias |
||||||
|
if self.pred_obj_scores: |
||||||
|
if self.fixed_no_obj_ptr: |
||||||
|
obj_ptr = lambda_is_obj_appearing * obj_ptr |
||||||
|
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr |
||||||
|
|
||||||
|
return ( |
||||||
|
low_res_masks, |
||||||
|
high_res_masks, |
||||||
|
ious, |
||||||
|
low_res_masks, |
||||||
|
high_res_masks, |
||||||
|
obj_ptr, |
||||||
|
object_score_logits, |
||||||
|
) |
||||||
|
|
||||||
|
def forward_image(self, img_batch: torch.Tensor): |
||||||
|
"""Process image batch through encoder to extract multi-level features for SAM model.""" |
||||||
|
backbone_out = self.image_encoder(img_batch) |
||||||
|
if self.use_high_res_features_in_sam: |
||||||
|
# precompute projected level 0 and level 1 features in SAM decoder |
||||||
|
# to avoid running it again on every SAM click |
||||||
|
backbone_out["backbone_fpn"][0] = self.sam_mask_decoder.conv_s0(backbone_out["backbone_fpn"][0]) |
||||||
|
backbone_out["backbone_fpn"][1] = self.sam_mask_decoder.conv_s1(backbone_out["backbone_fpn"][1]) |
||||||
|
return backbone_out |
||||||
|
|
||||||
|
def _prepare_backbone_features(self, backbone_out): |
||||||
|
"""Prepare and flatten visual features from the image backbone output.""" |
||||||
|
backbone_out = backbone_out.copy() |
||||||
|
assert len(backbone_out["backbone_fpn"]) == len(backbone_out["vision_pos_enc"]) |
||||||
|
assert len(backbone_out["backbone_fpn"]) >= self.num_feature_levels |
||||||
|
|
||||||
|
feature_maps = backbone_out["backbone_fpn"][-self.num_feature_levels :] |
||||||
|
vision_pos_embeds = backbone_out["vision_pos_enc"][-self.num_feature_levels :] |
||||||
|
|
||||||
|
feat_sizes = [(x.shape[-2], x.shape[-1]) for x in vision_pos_embeds] |
||||||
|
# flatten NxCxHxW to HWxNxC |
||||||
|
vision_feats = [x.flatten(2).permute(2, 0, 1) for x in feature_maps] |
||||||
|
vision_pos_embeds = [x.flatten(2).permute(2, 0, 1) for x in vision_pos_embeds] |
||||||
|
|
||||||
|
return backbone_out, vision_feats, vision_pos_embeds, feat_sizes |
||||||
|
|
||||||
|
def _prepare_memory_conditioned_features( |
||||||
|
self, |
||||||
|
frame_idx, |
||||||
|
is_init_cond_frame, |
||||||
|
current_vision_feats, |
||||||
|
current_vision_pos_embeds, |
||||||
|
feat_sizes, |
||||||
|
output_dict, |
||||||
|
num_frames, |
||||||
|
track_in_reverse=False, # tracking in reverse time order (for demo usage) |
||||||
|
): |
||||||
|
"""Prepares memory-conditioned features by fusing current frame's visual features with previous memories.""" |
||||||
|
B = current_vision_feats[-1].size(1) # batch size on this frame |
||||||
|
C = self.hidden_dim |
||||||
|
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size |
||||||
|
device = current_vision_feats[-1].device |
||||||
|
# The case of `self.num_maskmem == 0` below is primarily used for reproducing SAM on images. |
||||||
|
# In this case, we skip the fusion with any memory. |
||||||
|
if self.num_maskmem == 0: # Disable memory and skip fusion |
||||||
|
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W) |
||||||
|
return pix_feat |
||||||
|
|
||||||
|
num_obj_ptr_tokens = 0 |
||||||
|
# Step 1: condition the visual features of the current frame on previous memories |
||||||
|
if not is_init_cond_frame: |
||||||
|
# Retrieve the memories encoded with the maskmem backbone |
||||||
|
to_cat_memory, to_cat_memory_pos_embed = [], [] |
||||||
|
# Add conditioning frames's output first (all cond frames have t_pos=0 for |
||||||
|
# when getting temporal positional embedding below) |
||||||
|
assert len(output_dict["cond_frame_outputs"]) > 0 |
||||||
|
# Select a maximum number of temporally closest cond frames for cross attention |
||||||
|
cond_outputs = output_dict["cond_frame_outputs"] |
||||||
|
selected_cond_outputs, unselected_cond_outputs = select_closest_cond_frames( |
||||||
|
frame_idx, cond_outputs, self.max_cond_frames_in_attn |
||||||
|
) |
||||||
|
t_pos_and_prevs = [(0, out) for out in selected_cond_outputs.values()] |
||||||
|
# Add last (self.num_maskmem - 1) frames before current frame for non-conditioning memory |
||||||
|
# the earliest one has t_pos=1 and the latest one has t_pos=self.num_maskmem-1 |
||||||
|
# We also allow taking the memory frame non-consecutively (with r>1), in which case |
||||||
|
# we take (self.num_maskmem - 2) frames among every r-th frames plus the last frame. |
||||||
|
r = self.memory_temporal_stride_for_eval |
||||||
|
for t_pos in range(1, self.num_maskmem): |
||||||
|
t_rel = self.num_maskmem - t_pos # how many frames before current frame |
||||||
|
if t_rel == 1: |
||||||
|
# for t_rel == 1, we take the last frame (regardless of r) |
||||||
|
if not track_in_reverse: |
||||||
|
# the frame immediately before this frame (i.e. frame_idx - 1) |
||||||
|
prev_frame_idx = frame_idx - t_rel |
||||||
|
else: |
||||||
|
# the frame immediately after this frame (i.e. frame_idx + 1) |
||||||
|
prev_frame_idx = frame_idx + t_rel |
||||||
|
else: |
||||||
|
# for t_rel >= 2, we take the memory frame from every r-th frames |
||||||
|
if not track_in_reverse: |
||||||
|
# first find the nearest frame among every r-th frames before this frame |
||||||
|
# for r=1, this would be (frame_idx - 2) |
||||||
|
prev_frame_idx = ((frame_idx - 2) // r) * r |
||||||
|
# then seek further among every r-th frames |
||||||
|
prev_frame_idx = prev_frame_idx - (t_rel - 2) * r |
||||||
|
else: |
||||||
|
# first find the nearest frame among every r-th frames after this frame |
||||||
|
# for r=1, this would be (frame_idx + 2) |
||||||
|
prev_frame_idx = -(-(frame_idx + 2) // r) * r |
||||||
|
# then seek further among every r-th frames |
||||||
|
prev_frame_idx = prev_frame_idx + (t_rel - 2) * r |
||||||
|
out = output_dict["non_cond_frame_outputs"].get(prev_frame_idx, None) |
||||||
|
if out is None: |
||||||
|
# If an unselected conditioning frame is among the last (self.num_maskmem - 1) |
||||||
|
# frames, we still attend to it as if it's a non-conditioning frame. |
||||||
|
out = unselected_cond_outputs.get(prev_frame_idx, None) |
||||||
|
t_pos_and_prevs.append((t_pos, out)) |
||||||
|
|
||||||
|
for t_pos, prev in t_pos_and_prevs: |
||||||
|
if prev is None: |
||||||
|
continue # skip padding frames |
||||||
|
# "maskmem_features" might have been offloaded to CPU in demo use cases, |
||||||
|
# so we load it back to GPU (it's a no-op if it's already on GPU). |
||||||
|
feats = prev["maskmem_features"].cuda(non_blocking=True) |
||||||
|
to_cat_memory.append(feats.flatten(2).permute(2, 0, 1)) |
||||||
|
# Spatial positional encoding (it might have been offloaded to CPU in eval) |
||||||
|
maskmem_enc = prev["maskmem_pos_enc"][-1].cuda() |
||||||
|
maskmem_enc = maskmem_enc.flatten(2).permute(2, 0, 1) |
||||||
|
# Temporal positional encoding |
||||||
|
maskmem_enc = maskmem_enc + self.maskmem_tpos_enc[self.num_maskmem - t_pos - 1] |
||||||
|
to_cat_memory_pos_embed.append(maskmem_enc) |
||||||
|
|
||||||
|
# Construct the list of past object pointers |
||||||
|
if self.use_obj_ptrs_in_encoder: |
||||||
|
max_obj_ptrs_in_encoder = min(num_frames, self.max_obj_ptrs_in_encoder) |
||||||
|
# First add those object pointers from selected conditioning frames |
||||||
|
# (optionally, only include object pointers in the past during evaluation) |
||||||
|
if not self.training and self.only_obj_ptrs_in_the_past_for_eval: |
||||||
|
ptr_cond_outputs = { |
||||||
|
t: out |
||||||
|
for t, out in selected_cond_outputs.items() |
||||||
|
if (t >= frame_idx if track_in_reverse else t <= frame_idx) |
||||||
|
} |
||||||
|
else: |
||||||
|
ptr_cond_outputs = selected_cond_outputs |
||||||
|
pos_and_ptrs = [ |
||||||
|
# Temporal pos encoding contains how far away each pointer is from current frame |
||||||
|
(abs(frame_idx - t), out["obj_ptr"]) |
||||||
|
for t, out in ptr_cond_outputs.items() |
||||||
|
] |
||||||
|
# Add up to (max_obj_ptrs_in_encoder - 1) non-conditioning frames before current frame |
||||||
|
for t_diff in range(1, max_obj_ptrs_in_encoder): |
||||||
|
t = frame_idx + t_diff if track_in_reverse else frame_idx - t_diff |
||||||
|
if t < 0 or (num_frames is not None and t >= num_frames): |
||||||
|
break |
||||||
|
out = output_dict["non_cond_frame_outputs"].get(t, unselected_cond_outputs.get(t, None)) |
||||||
|
if out is not None: |
||||||
|
pos_and_ptrs.append((t_diff, out["obj_ptr"])) |
||||||
|
# If we have at least one object pointer, add them to the across attention |
||||||
|
if len(pos_and_ptrs) > 0: |
||||||
|
pos_list, ptrs_list = zip(*pos_and_ptrs) |
||||||
|
# stack object pointers along dim=0 into [ptr_seq_len, B, C] shape |
||||||
|
obj_ptrs = torch.stack(ptrs_list, dim=0) |
||||||
|
# a temporal positional embedding based on how far each object pointer is from |
||||||
|
# the current frame (sine embedding normalized by the max pointer num). |
||||||
|
if self.add_tpos_enc_to_obj_ptrs: |
||||||
|
t_diff_max = max_obj_ptrs_in_encoder - 1 |
||||||
|
tpos_dim = C if self.proj_tpos_enc_in_obj_ptrs else self.mem_dim |
||||||
|
obj_pos = torch.tensor(pos_list, device=device) |
||||||
|
obj_pos = get_1d_sine_pe(obj_pos / t_diff_max, dim=tpos_dim) |
||||||
|
obj_pos = self.obj_ptr_tpos_proj(obj_pos) |
||||||
|
obj_pos = obj_pos.unsqueeze(1).expand(-1, B, self.mem_dim) |
||||||
|
else: |
||||||
|
obj_pos = obj_ptrs.new_zeros(len(pos_list), B, self.mem_dim) |
||||||
|
if self.mem_dim < C: |
||||||
|
# split a pointer into (C // self.mem_dim) tokens for self.mem_dim < C |
||||||
|
obj_ptrs = obj_ptrs.reshape(-1, B, C // self.mem_dim, self.mem_dim) |
||||||
|
obj_ptrs = obj_ptrs.permute(0, 2, 1, 3).flatten(0, 1) |
||||||
|
obj_pos = obj_pos.repeat_interleave(C // self.mem_dim, dim=0) |
||||||
|
to_cat_memory.append(obj_ptrs) |
||||||
|
to_cat_memory_pos_embed.append(obj_pos) |
||||||
|
num_obj_ptr_tokens = obj_ptrs.shape[0] |
||||||
|
else: |
||||||
|
num_obj_ptr_tokens = 0 |
||||||
|
else: |
||||||
|
# for initial conditioning frames, encode them without using any previous memory |
||||||
|
if self.directly_add_no_mem_embed: |
||||||
|
# directly add no-mem embedding (instead of using the transformer encoder) |
||||||
|
pix_feat_with_mem = current_vision_feats[-1] + self.no_mem_embed |
||||||
|
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W) |
||||||
|
return pix_feat_with_mem |
||||||
|
|
||||||
|
# Use a dummy token on the first frame (to avoid empty memory input to transformer encoder) |
||||||
|
to_cat_memory = [self.no_mem_embed.expand(1, B, self.mem_dim)] |
||||||
|
to_cat_memory_pos_embed = [self.no_mem_pos_enc.expand(1, B, self.mem_dim)] |
||||||
|
|
||||||
|
# Step 2: Concatenate the memories and forward through the transformer encoder |
||||||
|
memory = torch.cat(to_cat_memory, dim=0) |
||||||
|
memory_pos_embed = torch.cat(to_cat_memory_pos_embed, dim=0) |
||||||
|
|
||||||
|
pix_feat_with_mem = self.memory_attention( |
||||||
|
curr=current_vision_feats, |
||||||
|
curr_pos=current_vision_pos_embeds, |
||||||
|
memory=memory, |
||||||
|
memory_pos=memory_pos_embed, |
||||||
|
num_obj_ptr_tokens=num_obj_ptr_tokens, |
||||||
|
) |
||||||
|
# reshape the output (HW)BC => BCHW |
||||||
|
pix_feat_with_mem = pix_feat_with_mem.permute(1, 2, 0).view(B, C, H, W) |
||||||
|
return pix_feat_with_mem |
||||||
|
|
||||||
|
def _encode_new_memory( |
||||||
|
self, |
||||||
|
current_vision_feats, |
||||||
|
feat_sizes, |
||||||
|
pred_masks_high_res, |
||||||
|
is_mask_from_pts, |
||||||
|
): |
||||||
|
"""Encodes the current frame's features and predicted masks into a new memory representation.""" |
||||||
|
B = current_vision_feats[-1].size(1) # batch size on this frame |
||||||
|
C = self.hidden_dim |
||||||
|
H, W = feat_sizes[-1] # top-level (lowest-resolution) feature size |
||||||
|
# top-level feature, (HW)BC => BCHW |
||||||
|
pix_feat = current_vision_feats[-1].permute(1, 2, 0).view(B, C, H, W) |
||||||
|
if self.non_overlap_masks_for_mem_enc and not self.training: |
||||||
|
# optionally, apply non-overlapping constraints to the masks (it's applied |
||||||
|
# in the batch dimension and should only be used during eval, where all |
||||||
|
# the objects come from the same video under batch size 1). |
||||||
|
pred_masks_high_res = self._apply_non_overlapping_constraints(pred_masks_high_res) |
||||||
|
# scale the raw mask logits with a temperature before applying sigmoid |
||||||
|
binarize = self.binarize_mask_from_pts_for_mem_enc and is_mask_from_pts |
||||||
|
if binarize and not self.training: |
||||||
|
mask_for_mem = (pred_masks_high_res > 0).float() |
||||||
|
else: |
||||||
|
# apply sigmoid on the raw mask logits to turn them into range (0, 1) |
||||||
|
mask_for_mem = torch.sigmoid(pred_masks_high_res) |
||||||
|
# apply scale and bias terms to the sigmoid probabilities |
||||||
|
if self.sigmoid_scale_for_mem_enc != 1.0: |
||||||
|
mask_for_mem = mask_for_mem * self.sigmoid_scale_for_mem_enc |
||||||
|
if self.sigmoid_bias_for_mem_enc != 0.0: |
||||||
|
mask_for_mem = mask_for_mem + self.sigmoid_bias_for_mem_enc |
||||||
|
maskmem_out = self.memory_encoder( |
||||||
|
pix_feat, |
||||||
|
mask_for_mem, |
||||||
|
skip_mask_sigmoid=True, # sigmoid already applied |
||||||
|
) |
||||||
|
maskmem_features = maskmem_out["vision_features"] |
||||||
|
maskmem_pos_enc = maskmem_out["vision_pos_enc"] |
||||||
|
|
||||||
|
return maskmem_features, maskmem_pos_enc |
||||||
|
|
||||||
|
def track_step( |
||||||
|
self, |
||||||
|
frame_idx, |
||||||
|
is_init_cond_frame, |
||||||
|
current_vision_feats, |
||||||
|
current_vision_pos_embeds, |
||||||
|
feat_sizes, |
||||||
|
point_inputs, |
||||||
|
mask_inputs, |
||||||
|
output_dict, |
||||||
|
num_frames, |
||||||
|
track_in_reverse=False, # tracking in reverse time order (for demo usage) |
||||||
|
# Whether to run the memory encoder on the predicted masks. Sometimes we might want |
||||||
|
# to skip the memory encoder with `run_mem_encoder=False`. For example, |
||||||
|
# in demo we might call `track_step` multiple times for each user click, |
||||||
|
# and only encode the memory when the user finalizes their clicks. And in ablation |
||||||
|
# settings like SAM training on static images, we don't need the memory encoder. |
||||||
|
run_mem_encoder=True, |
||||||
|
# The previously predicted SAM mask logits (which can be fed together with new clicks in demo). |
||||||
|
prev_sam_mask_logits=None, |
||||||
|
): |
||||||
|
"""Performs a single tracking step, updating object masks and memory features based on current frame inputs.""" |
||||||
|
current_out = {"point_inputs": point_inputs, "mask_inputs": mask_inputs} |
||||||
|
# High-resolution feature maps for the SAM head, reshape (HW)BC => BCHW |
||||||
|
if len(current_vision_feats) > 1: |
||||||
|
high_res_features = [ |
||||||
|
x.permute(1, 2, 0).view(x.size(1), x.size(2), *s) |
||||||
|
for x, s in zip(current_vision_feats[:-1], feat_sizes[:-1]) |
||||||
|
] |
||||||
|
else: |
||||||
|
high_res_features = None |
||||||
|
if mask_inputs is not None and self.use_mask_input_as_output_without_sam: |
||||||
|
# When use_mask_input_as_output_without_sam=True, we directly output the mask input |
||||||
|
# (see it as a GT mask) without using a SAM prompt encoder + mask decoder. |
||||||
|
pix_feat = current_vision_feats[-1].permute(1, 2, 0) |
||||||
|
pix_feat = pix_feat.view(-1, self.hidden_dim, *feat_sizes[-1]) |
||||||
|
sam_outputs = self._use_mask_as_output(pix_feat, high_res_features, mask_inputs) |
||||||
|
else: |
||||||
|
# fused the visual feature with previous memory features in the memory bank |
||||||
|
pix_feat_with_mem = self._prepare_memory_conditioned_features( |
||||||
|
frame_idx=frame_idx, |
||||||
|
is_init_cond_frame=is_init_cond_frame, |
||||||
|
current_vision_feats=current_vision_feats[-1:], |
||||||
|
current_vision_pos_embeds=current_vision_pos_embeds[-1:], |
||||||
|
feat_sizes=feat_sizes[-1:], |
||||||
|
output_dict=output_dict, |
||||||
|
num_frames=num_frames, |
||||||
|
track_in_reverse=track_in_reverse, |
||||||
|
) |
||||||
|
# apply SAM-style segmentation head |
||||||
|
# here we might feed previously predicted low-res SAM mask logits into the SAM mask decoder, |
||||||
|
# e.g. in demo where such logits come from earlier interaction instead of correction sampling |
||||||
|
# (in this case, any `mask_inputs` shouldn't reach here as they are sent to _use_mask_as_output instead) |
||||||
|
if prev_sam_mask_logits is not None: |
||||||
|
assert point_inputs is not None and mask_inputs is None |
||||||
|
mask_inputs = prev_sam_mask_logits |
||||||
|
multimask_output = self._use_multimask(is_init_cond_frame, point_inputs) |
||||||
|
sam_outputs = self._forward_sam_heads( |
||||||
|
backbone_features=pix_feat_with_mem, |
||||||
|
point_inputs=point_inputs, |
||||||
|
mask_inputs=mask_inputs, |
||||||
|
high_res_features=high_res_features, |
||||||
|
multimask_output=multimask_output, |
||||||
|
) |
||||||
|
( |
||||||
|
_, |
||||||
|
_, |
||||||
|
_, |
||||||
|
low_res_masks, |
||||||
|
high_res_masks, |
||||||
|
obj_ptr, |
||||||
|
_, |
||||||
|
) = sam_outputs |
||||||
|
|
||||||
|
current_out["pred_masks"] = low_res_masks |
||||||
|
current_out["pred_masks_high_res"] = high_res_masks |
||||||
|
current_out["obj_ptr"] = obj_ptr |
||||||
|
|
||||||
|
# Finally run the memory encoder on the predicted mask to encode |
||||||
|
# it into a new memory feature (that can be used in future frames) |
||||||
|
if run_mem_encoder and self.num_maskmem > 0: |
||||||
|
high_res_masks_for_mem_enc = high_res_masks |
||||||
|
maskmem_features, maskmem_pos_enc = self._encode_new_memory( |
||||||
|
current_vision_feats=current_vision_feats, |
||||||
|
feat_sizes=feat_sizes, |
||||||
|
pred_masks_high_res=high_res_masks_for_mem_enc, |
||||||
|
is_mask_from_pts=(point_inputs is not None), |
||||||
|
) |
||||||
|
current_out["maskmem_features"] = maskmem_features |
||||||
|
current_out["maskmem_pos_enc"] = maskmem_pos_enc |
||||||
|
else: |
||||||
|
current_out["maskmem_features"] = None |
||||||
|
current_out["maskmem_pos_enc"] = None |
||||||
|
|
||||||
|
return current_out |
||||||
|
|
||||||
|
def _use_multimask(self, is_init_cond_frame, point_inputs): |
||||||
|
"""Determines whether to use multiple mask outputs in the SAM head based on configuration and inputs.""" |
||||||
|
num_pts = 0 if point_inputs is None else point_inputs["point_labels"].size(1) |
||||||
|
multimask_output = ( |
||||||
|
self.multimask_output_in_sam |
||||||
|
and (is_init_cond_frame or self.multimask_output_for_tracking) |
||||||
|
and (self.multimask_min_pt_num <= num_pts <= self.multimask_max_pt_num) |
||||||
|
) |
||||||
|
return multimask_output |
||||||
|
|
||||||
|
def _apply_non_overlapping_constraints(self, pred_masks): |
||||||
|
"""Applies non-overlapping constraints to object masks, keeping highest scoring object at each location.""" |
||||||
|
batch_size = pred_masks.size(0) |
||||||
|
if batch_size == 1: |
||||||
|
return pred_masks |
||||||
|
|
||||||
|
device = pred_masks.device |
||||||
|
# "max_obj_inds": object index of the object with the highest score at each location |
||||||
|
max_obj_inds = torch.argmax(pred_masks, dim=0, keepdim=True) |
||||||
|
# "batch_obj_inds": object index of each object slice (along dim 0) in `pred_masks` |
||||||
|
batch_obj_inds = torch.arange(batch_size, device=device)[:, None, None, None] |
||||||
|
keep = max_obj_inds == batch_obj_inds |
||||||
|
# suppress overlapping regions' scores below -10.0 so that the foreground regions |
||||||
|
# don't overlap (here sigmoid(-10.0)=4.5398e-05) |
||||||
|
pred_masks = torch.where(keep, pred_masks, torch.clamp(pred_masks, max=-10.0)) |
||||||
|
return pred_masks |
||||||
@ -0,0 +1,715 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import copy |
||||||
|
import math |
||||||
|
from functools import partial |
||||||
|
from typing import Optional, Tuple, Type, Union |
||||||
|
|
||||||
|
import torch |
||||||
|
import torch.nn.functional as F |
||||||
|
from torch import Tensor, nn |
||||||
|
|
||||||
|
from ultralytics.models.sam.modules.transformer import ( |
||||||
|
Attention, |
||||||
|
) |
||||||
|
from ultralytics.models.sam.modules.transformer import ( |
||||||
|
TwoWayAttentionBlock as SAMTwoWayAttentionBlock, |
||||||
|
) |
||||||
|
from ultralytics.models.sam.modules.transformer import ( |
||||||
|
TwoWayTransformer as SAMTwoWayTransformer, |
||||||
|
) |
||||||
|
from ultralytics.nn.modules import MLP, LayerNorm2d |
||||||
|
|
||||||
|
from .utils import apply_rotary_enc, compute_axial_cis, window_partition, window_unpartition |
||||||
|
|
||||||
|
|
||||||
|
class DropPath(nn.Module): |
||||||
|
"""Implements stochastic depth regularization for neural networks during training.""" |
||||||
|
|
||||||
|
def __init__(self, drop_prob=0.0, scale_by_keep=True): |
||||||
|
"""Initialize DropPath module with specified drop probability and scaling option.""" |
||||||
|
super(DropPath, self).__init__() |
||||||
|
self.drop_prob = drop_prob |
||||||
|
self.scale_by_keep = scale_by_keep |
||||||
|
|
||||||
|
def forward(self, x): |
||||||
|
"""Applies stochastic depth to input tensor during training, with optional scaling.""" |
||||||
|
if self.drop_prob == 0.0 or not self.training: |
||||||
|
return x |
||||||
|
keep_prob = 1 - self.drop_prob |
||||||
|
shape = (x.shape[0],) + (1,) * (x.ndim - 1) |
||||||
|
random_tensor = x.new_empty(shape).bernoulli_(keep_prob) |
||||||
|
if keep_prob > 0.0 and self.scale_by_keep: |
||||||
|
random_tensor.div_(keep_prob) |
||||||
|
return x * random_tensor |
||||||
|
|
||||||
|
|
||||||
|
class MaskDownSampler(nn.Module): |
||||||
|
"""Downsamples and embeds masks using convolutional layers and layer normalization for efficient processing.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
embed_dim=256, |
||||||
|
kernel_size=4, |
||||||
|
stride=4, |
||||||
|
padding=0, |
||||||
|
total_stride=16, |
||||||
|
activation=nn.GELU, |
||||||
|
): |
||||||
|
"""Initializes a mask downsampler module for progressive downsampling and channel expansion.""" |
||||||
|
super().__init__() |
||||||
|
num_layers = int(math.log2(total_stride) // math.log2(stride)) |
||||||
|
assert stride**num_layers == total_stride |
||||||
|
self.encoder = nn.Sequential() |
||||||
|
mask_in_chans, mask_out_chans = 1, 1 |
||||||
|
for _ in range(num_layers): |
||||||
|
mask_out_chans = mask_in_chans * (stride**2) |
||||||
|
self.encoder.append( |
||||||
|
nn.Conv2d( |
||||||
|
mask_in_chans, |
||||||
|
mask_out_chans, |
||||||
|
kernel_size=kernel_size, |
||||||
|
stride=stride, |
||||||
|
padding=padding, |
||||||
|
) |
||||||
|
) |
||||||
|
self.encoder.append(LayerNorm2d(mask_out_chans)) |
||||||
|
self.encoder.append(activation()) |
||||||
|
mask_in_chans = mask_out_chans |
||||||
|
|
||||||
|
self.encoder.append(nn.Conv2d(mask_out_chans, embed_dim, kernel_size=1)) |
||||||
|
|
||||||
|
def forward(self, x): |
||||||
|
"""Downsamples and encodes input mask to embed_dim channels using convolutional layers and LayerNorm2d.""" |
||||||
|
return self.encoder(x) |
||||||
|
|
||||||
|
|
||||||
|
# Lightly adapted from ConvNext (https://github.com/facebookresearch/ConvNeXt) |
||||||
|
class CXBlock(nn.Module): |
||||||
|
""" |
||||||
|
ConvNeXt Block for efficient feature extraction in convolutional neural networks. |
||||||
|
|
||||||
|
This block implements a modified version of the ConvNeXt architecture, offering two equivalent |
||||||
|
implementations for improved performance and flexibility. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
dwconv (nn.Conv2d): Depthwise convolution layer. |
||||||
|
norm (LayerNorm2d): Layer normalization applied to channels. |
||||||
|
pwconv1 (nn.Linear): First pointwise convolution implemented as a linear layer. |
||||||
|
act (nn.GELU): GELU activation function. |
||||||
|
pwconv2 (nn.Linear): Second pointwise convolution implemented as a linear layer. |
||||||
|
gamma (nn.Parameter | None): Learnable scale parameter for layer scaling. |
||||||
|
drop_path (nn.Module): DropPath layer for stochastic depth regularization. |
||||||
|
|
||||||
|
Methods: |
||||||
|
forward: Processes the input tensor through the ConvNeXt block. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> import torch |
||||||
|
>>> x = torch.randn(1, 64, 56, 56) |
||||||
|
>>> block = CXBlock(dim=64, kernel_size=7, padding=3) |
||||||
|
>>> output = block(x) |
||||||
|
>>> print(output.shape) |
||||||
|
torch.Size([1, 64, 56, 56]) |
||||||
|
""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
dim, |
||||||
|
kernel_size=7, |
||||||
|
padding=3, |
||||||
|
drop_path=0.0, |
||||||
|
layer_scale_init_value=1e-6, |
||||||
|
use_dwconv=True, |
||||||
|
): |
||||||
|
""" |
||||||
|
Initialize a ConvNeXt Block. |
||||||
|
|
||||||
|
This block implements a ConvNeXt architecture with optional depthwise convolution, layer normalization, |
||||||
|
pointwise convolutions, and GELU activation. |
||||||
|
|
||||||
|
Args: |
||||||
|
dim (int): Number of input channels. |
||||||
|
kernel_size (int): Size of the convolutional kernel. Default is 7. |
||||||
|
padding (int): Padding size for the convolution. Default is 3. |
||||||
|
drop_path (float): Stochastic depth rate. Default is 0.0. |
||||||
|
layer_scale_init_value (float): Initial value for Layer Scale. Default is 1e-6. |
||||||
|
use_dwconv (bool): Whether to use depthwise convolution. Default is True. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
dwconv (nn.Conv2d): Depthwise or standard 2D convolution layer. |
||||||
|
norm (LayerNorm2d): Layer normalization applied to the output of dwconv. |
||||||
|
pwconv1 (nn.Linear): First pointwise convolution implemented as a linear layer. |
||||||
|
act (nn.GELU): GELU activation function. |
||||||
|
pwconv2 (nn.Linear): Second pointwise convolution implemented as a linear layer. |
||||||
|
gamma (nn.Parameter | None): Learnable scale parameter for the residual path. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> block = CXBlock(dim=64, kernel_size=7, padding=3) |
||||||
|
>>> x = torch.randn(1, 64, 32, 32) |
||||||
|
>>> output = block(x) |
||||||
|
>>> print(output.shape) |
||||||
|
torch.Size([1, 64, 32, 32]) |
||||||
|
""" |
||||||
|
super().__init__() |
||||||
|
self.dwconv = nn.Conv2d( |
||||||
|
dim, |
||||||
|
dim, |
||||||
|
kernel_size=kernel_size, |
||||||
|
padding=padding, |
||||||
|
groups=dim if use_dwconv else 1, |
||||||
|
) # depthwise conv |
||||||
|
self.norm = LayerNorm2d(dim, eps=1e-6) |
||||||
|
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers |
||||||
|
self.act = nn.GELU() |
||||||
|
self.pwconv2 = nn.Linear(4 * dim, dim) |
||||||
|
self.gamma = ( |
||||||
|
nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True) |
||||||
|
if layer_scale_init_value > 0 |
||||||
|
else None |
||||||
|
) |
||||||
|
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity() |
||||||
|
|
||||||
|
def forward(self, x): |
||||||
|
"""Applies ConvNeXt block operations to input tensor, including convolutions and residual connection.""" |
||||||
|
input = x |
||||||
|
x = self.dwconv(x) |
||||||
|
x = self.norm(x) |
||||||
|
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C) |
||||||
|
x = self.pwconv1(x) |
||||||
|
x = self.act(x) |
||||||
|
x = self.pwconv2(x) |
||||||
|
if self.gamma is not None: |
||||||
|
x = self.gamma * x |
||||||
|
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W) |
||||||
|
|
||||||
|
x = input + self.drop_path(x) |
||||||
|
return x |
||||||
|
|
||||||
|
|
||||||
|
class Fuser(nn.Module): |
||||||
|
""" |
||||||
|
A module for fusing features through multiple layers of a neural network. |
||||||
|
|
||||||
|
This class applies a series of identical layers to an input tensor, optionally projecting the input first. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
proj (nn.Module): An optional input projection layer. Identity if no projection is needed. |
||||||
|
layers (nn.ModuleList): A list of identical layers to be applied sequentially. |
||||||
|
|
||||||
|
Methods: |
||||||
|
forward: Applies the fuser to an input tensor. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> layer = CXBlock(dim=256) |
||||||
|
>>> fuser = Fuser(layer, num_layers=3, dim=256, input_projection=True) |
||||||
|
>>> x = torch.randn(1, 256, 32, 32) |
||||||
|
>>> output = fuser(x) |
||||||
|
>>> print(output.shape) |
||||||
|
torch.Size([1, 256, 32, 32]) |
||||||
|
""" |
||||||
|
|
||||||
|
def __init__(self, layer, num_layers, dim=None, input_projection=False): |
||||||
|
""" |
||||||
|
Initializes the Fuser module. |
||||||
|
|
||||||
|
This module creates a sequence of identical layers and optionally applies an input projection. |
||||||
|
|
||||||
|
Args: |
||||||
|
layer (nn.Module): The layer to be replicated in the fuser. |
||||||
|
num_layers (int): The number of times to replicate the layer. |
||||||
|
dim (int | None): The dimension for input projection, if used. |
||||||
|
input_projection (bool): Whether to use input projection. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
proj (nn.Module): The input projection layer, or nn.Identity if not used. |
||||||
|
layers (nn.ModuleList): A list of replicated layers. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> layer = nn.Linear(64, 64) |
||||||
|
>>> fuser = Fuser(layer, num_layers=3, dim=64, input_projection=True) |
||||||
|
>>> input_tensor = torch.randn(1, 64) |
||||||
|
>>> output = fuser(input_tensor) |
||||||
|
""" |
||||||
|
super().__init__() |
||||||
|
self.proj = nn.Identity() |
||||||
|
self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(num_layers)]) |
||||||
|
|
||||||
|
if input_projection: |
||||||
|
assert dim is not None |
||||||
|
self.proj = nn.Conv2d(dim, dim, kernel_size=1) |
||||||
|
|
||||||
|
def forward(self, x): |
||||||
|
"""Applies a series of layers to the input tensor, optionally projecting it first.""" |
||||||
|
x = self.proj(x) |
||||||
|
for layer in self.layers: |
||||||
|
x = layer(x) |
||||||
|
return x |
||||||
|
|
||||||
|
|
||||||
|
class TwoWayAttentionBlock(SAMTwoWayAttentionBlock): |
||||||
|
""" |
||||||
|
A two-way attention block for performing self-attention and cross-attention in both directions. |
||||||
|
|
||||||
|
This block extends the SAMTwoWayAttentionBlock and consists of four main components: self-attention on |
||||||
|
sparse inputs, cross-attention from sparse to dense inputs, an MLP block on sparse inputs, and |
||||||
|
cross-attention from dense to sparse inputs. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
self_attn (Attention): Self-attention layer for queries. |
||||||
|
norm1 (nn.LayerNorm): Layer normalization after the first attention block. |
||||||
|
cross_attn_token_to_image (Attention): Cross-attention layer from queries to keys. |
||||||
|
norm2 (nn.LayerNorm): Layer normalization after the second attention block. |
||||||
|
mlp (MLP): MLP block for transforming query embeddings. |
||||||
|
norm3 (nn.LayerNorm): Layer normalization after the MLP block. |
||||||
|
norm4 (nn.LayerNorm): Layer normalization after the third attention block. |
||||||
|
cross_attn_image_to_token (Attention): Cross-attention layer from keys to queries. |
||||||
|
skip_first_layer_pe (bool): Flag to skip positional encoding in the first layer. |
||||||
|
|
||||||
|
Methods: |
||||||
|
forward: Processes input through the attention blocks and MLP. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> block = TwoWayAttentionBlock(embedding_dim=256, num_heads=8) |
||||||
|
>>> sparse_input = torch.randn(1, 100, 256) |
||||||
|
>>> dense_input = torch.randn(1, 256, 16, 16) |
||||||
|
>>> sparse_output, dense_output = block(sparse_input, dense_input) |
||||||
|
""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
embedding_dim: int, |
||||||
|
num_heads: int, |
||||||
|
mlp_dim: int = 2048, |
||||||
|
activation: Type[nn.Module] = nn.ReLU, |
||||||
|
attention_downsample_rate: int = 2, |
||||||
|
skip_first_layer_pe: bool = False, |
||||||
|
) -> None: |
||||||
|
""" |
||||||
|
Initializes a TwoWayAttentionBlock for performing self-attention and cross-attention in two directions. |
||||||
|
|
||||||
|
This block consists of four main layers: self-attention on sparse inputs, cross-attention of sparse inputs |
||||||
|
to dense inputs, an MLP block on sparse inputs, and cross-attention of dense inputs to sparse inputs. |
||||||
|
|
||||||
|
Args: |
||||||
|
embedding_dim (int): The channel dimension of the embeddings. |
||||||
|
num_heads (int): The number of heads in the attention layers. |
||||||
|
mlp_dim (int): The hidden dimension of the MLP block. |
||||||
|
activation (Type[nn.Module]): The activation function of the MLP block. |
||||||
|
attention_downsample_rate (int): The downsample rate for attention computations. |
||||||
|
skip_first_layer_pe (bool): Whether to skip the positional encoding in the first layer. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
self_attn (Attention): The self-attention layer for the queries. |
||||||
|
norm1 (nn.LayerNorm): Layer normalization following the first attention block. |
||||||
|
cross_attn_token_to_image (Attention): Cross-attention layer from queries to keys. |
||||||
|
norm2 (nn.LayerNorm): Layer normalization following the second attention block. |
||||||
|
mlp (MLP): MLP block that transforms the query embeddings. |
||||||
|
norm3 (nn.LayerNorm): Layer normalization following the MLP block. |
||||||
|
norm4 (nn.LayerNorm): Layer normalization following the third attention block. |
||||||
|
cross_attn_image_to_token (Attention): Cross-attention layer from keys to queries. |
||||||
|
skip_first_layer_pe (bool): Whether to skip the positional encoding in the first layer. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> block = TwoWayAttentionBlock(embedding_dim=256, num_heads=8, mlp_dim=2048) |
||||||
|
>>> sparse_inputs = torch.randn(1, 100, 256) |
||||||
|
>>> dense_inputs = torch.randn(1, 256, 32, 32) |
||||||
|
>>> sparse_outputs, dense_outputs = block(sparse_inputs, dense_inputs) |
||||||
|
""" |
||||||
|
super().__init__(embedding_dim, num_heads, mlp_dim, activation, attention_downsample_rate, skip_first_layer_pe) |
||||||
|
self.mlp = MLP(embedding_dim, mlp_dim, embedding_dim, num_layers=2, act=activation) |
||||||
|
|
||||||
|
|
||||||
|
class TwoWayTransformer(SAMTwoWayTransformer): |
||||||
|
""" |
||||||
|
A Two-Way Transformer module for simultaneous attention to image and query points. |
||||||
|
|
||||||
|
This class implements a specialized transformer decoder that attends to an input image using queries with |
||||||
|
supplied positional embeddings. It is particularly useful for tasks like object detection, image |
||||||
|
segmentation, and point cloud processing. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
depth (int): Number of layers in the transformer. |
||||||
|
embedding_dim (int): Channel dimension for input embeddings. |
||||||
|
num_heads (int): Number of heads for multihead attention. |
||||||
|
mlp_dim (int): Internal channel dimension for the MLP block. |
||||||
|
layers (nn.ModuleList): List of TwoWayAttentionBlock layers comprising the transformer. |
||||||
|
final_attn_token_to_image (Attention): Final attention layer from queries to image. |
||||||
|
norm_final_attn (nn.LayerNorm): Layer normalization applied to final queries. |
||||||
|
|
||||||
|
Methods: |
||||||
|
forward: Processes input image embeddings and query embeddings through the transformer. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> transformer = TwoWayTransformer(depth=5, embedding_dim=256, num_heads=8, mlp_dim=2048) |
||||||
|
>>> image_embedding = torch.randn(1, 256, 64, 64) |
||||||
|
>>> query_embedding = torch.randn(1, 100, 256) |
||||||
|
>>> output = transformer(image_embedding, query_embedding) |
||||||
|
""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
depth: int, |
||||||
|
embedding_dim: int, |
||||||
|
num_heads: int, |
||||||
|
mlp_dim: int, |
||||||
|
activation: Type[nn.Module] = nn.ReLU, |
||||||
|
attention_downsample_rate: int = 2, |
||||||
|
) -> None: |
||||||
|
""" |
||||||
|
Initializes a TwoWayTransformer instance. |
||||||
|
|
||||||
|
This transformer decoder attends to an input image using queries with supplied positional embeddings. |
||||||
|
It is designed for tasks like object detection, image segmentation, and point cloud processing. |
||||||
|
|
||||||
|
Args: |
||||||
|
depth (int): Number of layers in the transformer. |
||||||
|
embedding_dim (int): Channel dimension for the input embeddings. |
||||||
|
num_heads (int): Number of heads for multihead attention. Must divide embedding_dim. |
||||||
|
mlp_dim (int): Channel dimension internal to the MLP block. |
||||||
|
activation (Type[nn.Module]): Activation function to use in the MLP block. |
||||||
|
attention_downsample_rate (int): Downsampling rate for attention computations. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
depth (int): Number of layers in the transformer. |
||||||
|
embedding_dim (int): Channel dimension for the input embeddings. |
||||||
|
num_heads (int): Number of heads for multihead attention. |
||||||
|
mlp_dim (int): Internal channel dimension for the MLP block. |
||||||
|
layers (nn.ModuleList): List of TwoWayAttentionBlock layers comprising the transformer. |
||||||
|
final_attn_token_to_image (Attention): Final attention layer from queries to image. |
||||||
|
norm_final_attn (nn.LayerNorm): Layer normalization applied to the final queries. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> transformer = TwoWayTransformer(depth=5, embedding_dim=256, num_heads=8, mlp_dim=2048) |
||||||
|
>>> transformer |
||||||
|
TwoWayTransformer( |
||||||
|
(layers): ModuleList( |
||||||
|
(0-4): 5 x TwoWayAttentionBlock(...) |
||||||
|
) |
||||||
|
(final_attn_token_to_image): Attention(...) |
||||||
|
(norm_final_attn): LayerNorm(...) |
||||||
|
) |
||||||
|
""" |
||||||
|
super().__init__(depth, embedding_dim, num_heads, mlp_dim, activation, attention_downsample_rate) |
||||||
|
self.layers = nn.ModuleList() |
||||||
|
for i in range(depth): |
||||||
|
self.layers.append( |
||||||
|
TwoWayAttentionBlock( |
||||||
|
embedding_dim=embedding_dim, |
||||||
|
num_heads=num_heads, |
||||||
|
mlp_dim=mlp_dim, |
||||||
|
activation=activation, |
||||||
|
attention_downsample_rate=attention_downsample_rate, |
||||||
|
skip_first_layer_pe=(i == 0), |
||||||
|
) |
||||||
|
) |
||||||
|
|
||||||
|
|
||||||
|
class RoPEAttention(Attention): |
||||||
|
"""Implements rotary position encoding for attention mechanisms in transformer architectures.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
*args, |
||||||
|
rope_theta=10000.0, |
||||||
|
# whether to repeat q rope to match k length |
||||||
|
# this is needed for cross-attention to memories |
||||||
|
rope_k_repeat=False, |
||||||
|
feat_sizes=(32, 32), # [w, h] for stride 16 feats at 512 resolution |
||||||
|
**kwargs, |
||||||
|
): |
||||||
|
"""Initializes RoPEAttention with rotary position encoding for attention mechanisms.""" |
||||||
|
super().__init__(*args, **kwargs) |
||||||
|
|
||||||
|
self.compute_cis = partial(compute_axial_cis, dim=self.internal_dim // self.num_heads, theta=rope_theta) |
||||||
|
freqs_cis = self.compute_cis(end_x=feat_sizes[0], end_y=feat_sizes[1]) |
||||||
|
self.freqs_cis = freqs_cis |
||||||
|
self.rope_k_repeat = rope_k_repeat |
||||||
|
|
||||||
|
def forward(self, q: Tensor, k: Tensor, v: Tensor, num_k_exclude_rope: int = 0) -> Tensor: |
||||||
|
"""Applies rotary position encoding and computes attention between query, key, and value tensors.""" |
||||||
|
q = self.q_proj(q) |
||||||
|
k = self.k_proj(k) |
||||||
|
v = self.v_proj(v) |
||||||
|
|
||||||
|
# Separate into heads |
||||||
|
q = self._separate_heads(q, self.num_heads) |
||||||
|
k = self._separate_heads(k, self.num_heads) |
||||||
|
v = self._separate_heads(v, self.num_heads) |
||||||
|
|
||||||
|
# Apply rotary position encoding |
||||||
|
w = h = math.sqrt(q.shape[-2]) |
||||||
|
self.freqs_cis = self.freqs_cis.to(q.device) |
||||||
|
if self.freqs_cis.shape[0] != q.shape[-2]: |
||||||
|
self.freqs_cis = self.compute_cis(end_x=w, end_y=h).to(q.device) |
||||||
|
if q.shape[-2] != k.shape[-2]: |
||||||
|
assert self.rope_k_repeat |
||||||
|
|
||||||
|
num_k_rope = k.size(-2) - num_k_exclude_rope |
||||||
|
q, k[:, :, :num_k_rope] = apply_rotary_enc( |
||||||
|
q, |
||||||
|
k[:, :, :num_k_rope], |
||||||
|
freqs_cis=self.freqs_cis, |
||||||
|
repeat_freqs_k=self.rope_k_repeat, |
||||||
|
) |
||||||
|
|
||||||
|
# Attention |
||||||
|
_, _, _, c_per_head = q.shape |
||||||
|
attn = q @ k.permute(0, 1, 3, 2) # B x N_heads x N_tokens x N_tokens |
||||||
|
attn = attn / math.sqrt(c_per_head) |
||||||
|
attn = torch.softmax(attn, dim=-1) |
||||||
|
|
||||||
|
# Get output |
||||||
|
out = attn @ v |
||||||
|
|
||||||
|
out = self._recombine_heads(out) |
||||||
|
out = self.out_proj(out) |
||||||
|
|
||||||
|
return out |
||||||
|
|
||||||
|
|
||||||
|
def do_pool(x: torch.Tensor, pool: nn.Module, norm: nn.Module = None) -> torch.Tensor: |
||||||
|
"""Applies pooling and optional normalization to a tensor, handling permutations for spatial operations.""" |
||||||
|
if pool is None: |
||||||
|
return x |
||||||
|
# (B, H, W, C) -> (B, C, H, W) |
||||||
|
x = x.permute(0, 3, 1, 2) |
||||||
|
x = pool(x) |
||||||
|
# (B, C, H', W') -> (B, H', W', C) |
||||||
|
x = x.permute(0, 2, 3, 1) |
||||||
|
if norm: |
||||||
|
x = norm(x) |
||||||
|
|
||||||
|
return x |
||||||
|
|
||||||
|
|
||||||
|
class MultiScaleAttention(nn.Module): |
||||||
|
"""Implements multi-scale self-attention with optional query pooling for efficient feature extraction.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
dim: int, |
||||||
|
dim_out: int, |
||||||
|
num_heads: int, |
||||||
|
q_pool: nn.Module = None, |
||||||
|
): |
||||||
|
"""Initializes a multi-scale attention module with configurable query pooling and linear projections.""" |
||||||
|
super().__init__() |
||||||
|
|
||||||
|
self.dim = dim |
||||||
|
self.dim_out = dim_out |
||||||
|
|
||||||
|
self.num_heads = num_heads |
||||||
|
head_dim = dim_out // num_heads |
||||||
|
self.scale = head_dim**-0.5 |
||||||
|
|
||||||
|
self.q_pool = q_pool |
||||||
|
self.qkv = nn.Linear(dim, dim_out * 3) |
||||||
|
self.proj = nn.Linear(dim_out, dim_out) |
||||||
|
|
||||||
|
def forward(self, x: torch.Tensor) -> torch.Tensor: |
||||||
|
"""Applies multi-scale attention to input tensor, optionally downsampling query features.""" |
||||||
|
B, H, W, _ = x.shape |
||||||
|
# qkv with shape (B, H * W, 3, nHead, C) |
||||||
|
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1) |
||||||
|
# q, k, v with shape (B, H * W, nheads, C) |
||||||
|
q, k, v = torch.unbind(qkv, 2) |
||||||
|
|
||||||
|
# Q pooling (for downsample at stage changes) |
||||||
|
if self.q_pool: |
||||||
|
q = do_pool(q.reshape(B, H, W, -1), self.q_pool) |
||||||
|
H, W = q.shape[1:3] # downsampled shape |
||||||
|
q = q.reshape(B, H * W, self.num_heads, -1) |
||||||
|
|
||||||
|
# Torch's SDPA expects [B, nheads, H*W, C] so we transpose |
||||||
|
x = F.scaled_dot_product_attention( |
||||||
|
q.transpose(1, 2), |
||||||
|
k.transpose(1, 2), |
||||||
|
v.transpose(1, 2), |
||||||
|
) |
||||||
|
# Transpose back |
||||||
|
x = x.transpose(1, 2) |
||||||
|
x = x.reshape(B, H, W, -1) |
||||||
|
|
||||||
|
x = self.proj(x) |
||||||
|
|
||||||
|
return x |
||||||
|
|
||||||
|
|
||||||
|
class MultiScaleBlock(nn.Module): |
||||||
|
"""Multiscale attention block with window partitioning and query pooling for efficient vision transformers.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
dim: int, |
||||||
|
dim_out: int, |
||||||
|
num_heads: int, |
||||||
|
mlp_ratio: float = 4.0, |
||||||
|
drop_path: float = 0.0, |
||||||
|
norm_layer: Union[nn.Module, str] = "LayerNorm", |
||||||
|
q_stride: Tuple[int, int] = None, |
||||||
|
act_layer: nn.Module = nn.GELU, |
||||||
|
window_size: int = 0, |
||||||
|
): |
||||||
|
"""Initializes a multi-scale attention block with optional window partitioning and downsampling.""" |
||||||
|
super().__init__() |
||||||
|
|
||||||
|
if isinstance(norm_layer, str): |
||||||
|
norm_layer = partial(getattr(nn, norm_layer), eps=1e-6) |
||||||
|
|
||||||
|
self.dim = dim |
||||||
|
self.dim_out = dim_out |
||||||
|
self.norm1 = norm_layer(dim) |
||||||
|
|
||||||
|
self.window_size = window_size |
||||||
|
|
||||||
|
self.pool, self.q_stride = None, q_stride |
||||||
|
if self.q_stride: |
||||||
|
self.pool = nn.MaxPool2d(kernel_size=q_stride, stride=q_stride, ceil_mode=False) |
||||||
|
|
||||||
|
self.attn = MultiScaleAttention( |
||||||
|
dim, |
||||||
|
dim_out, |
||||||
|
num_heads=num_heads, |
||||||
|
q_pool=self.pool, |
||||||
|
) |
||||||
|
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity() |
||||||
|
|
||||||
|
self.norm2 = norm_layer(dim_out) |
||||||
|
self.mlp = MLP( |
||||||
|
dim_out, |
||||||
|
int(dim_out * mlp_ratio), |
||||||
|
dim_out, |
||||||
|
num_layers=2, |
||||||
|
act=act_layer, |
||||||
|
) |
||||||
|
|
||||||
|
if dim != dim_out: |
||||||
|
self.proj = nn.Linear(dim, dim_out) |
||||||
|
|
||||||
|
def forward(self, x: torch.Tensor) -> torch.Tensor: |
||||||
|
"""Applies multi-scale attention and MLP processing to input tensor, with optional windowing.""" |
||||||
|
shortcut = x # B, H, W, C |
||||||
|
x = self.norm1(x) |
||||||
|
|
||||||
|
# Skip connection |
||||||
|
if self.dim != self.dim_out: |
||||||
|
shortcut = do_pool(self.proj(x), self.pool) |
||||||
|
|
||||||
|
# Window partition |
||||||
|
window_size = self.window_size |
||||||
|
if window_size > 0: |
||||||
|
H, W = x.shape[1], x.shape[2] |
||||||
|
x, pad_hw = window_partition(x, window_size) |
||||||
|
|
||||||
|
# Window Attention + Q Pooling (if stage change) |
||||||
|
x = self.attn(x) |
||||||
|
if self.q_stride: |
||||||
|
# Shapes have changed due to Q pooling |
||||||
|
window_size = self.window_size // self.q_stride[0] |
||||||
|
H, W = shortcut.shape[1:3] |
||||||
|
|
||||||
|
pad_h = (window_size - H % window_size) % window_size |
||||||
|
pad_w = (window_size - W % window_size) % window_size |
||||||
|
pad_hw = (H + pad_h, W + pad_w) |
||||||
|
|
||||||
|
# Reverse window partition |
||||||
|
if self.window_size > 0: |
||||||
|
x = window_unpartition(x, window_size, pad_hw, (H, W)) |
||||||
|
|
||||||
|
x = shortcut + self.drop_path(x) |
||||||
|
# MLP |
||||||
|
x = x + self.drop_path(self.mlp(self.norm2(x))) |
||||||
|
return x |
||||||
|
|
||||||
|
|
||||||
|
class PositionEmbeddingSine(nn.Module): |
||||||
|
"""Generates sinusoidal positional embeddings for 2D inputs like images.""" |
||||||
|
|
||||||
|
def __init__( |
||||||
|
self, |
||||||
|
num_pos_feats, |
||||||
|
temperature: int = 10000, |
||||||
|
normalize: bool = True, |
||||||
|
scale: Optional[float] = None, |
||||||
|
): |
||||||
|
"""Initializes sinusoidal position embeddings for 2D image inputs.""" |
||||||
|
super().__init__() |
||||||
|
assert num_pos_feats % 2 == 0, "Expecting even model width" |
||||||
|
self.num_pos_feats = num_pos_feats // 2 |
||||||
|
self.temperature = temperature |
||||||
|
self.normalize = normalize |
||||||
|
if scale is not None and normalize is False: |
||||||
|
raise ValueError("normalize should be True if scale is passed") |
||||||
|
if scale is None: |
||||||
|
scale = 2 * math.pi |
||||||
|
self.scale = scale |
||||||
|
|
||||||
|
self.cache = {} |
||||||
|
|
||||||
|
def _encode_xy(self, x, y): |
||||||
|
"""Encodes 2D positions using sine and cosine functions for positional embeddings.""" |
||||||
|
assert len(x) == len(y) and x.ndim == y.ndim == 1 |
||||||
|
x_embed = x * self.scale |
||||||
|
y_embed = y * self.scale |
||||||
|
|
||||||
|
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device) |
||||||
|
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) |
||||||
|
|
||||||
|
pos_x = x_embed[:, None] / dim_t |
||||||
|
pos_y = y_embed[:, None] / dim_t |
||||||
|
pos_x = torch.stack((pos_x[:, 0::2].sin(), pos_x[:, 1::2].cos()), dim=2).flatten(1) |
||||||
|
pos_y = torch.stack((pos_y[:, 0::2].sin(), pos_y[:, 1::2].cos()), dim=2).flatten(1) |
||||||
|
return pos_x, pos_y |
||||||
|
|
||||||
|
@torch.no_grad() |
||||||
|
def encode_boxes(self, x, y, w, h): |
||||||
|
"""Encodes box coordinates and dimensions into positional embeddings for object detection tasks.""" |
||||||
|
pos_x, pos_y = self._encode_xy(x, y) |
||||||
|
pos = torch.cat((pos_y, pos_x, h[:, None], w[:, None]), dim=1) |
||||||
|
return pos |
||||||
|
|
||||||
|
encode = encode_boxes # Backwards compatibility |
||||||
|
|
||||||
|
@torch.no_grad() |
||||||
|
def encode_points(self, x, y, labels): |
||||||
|
"""Encodes 2D point coordinates with sinusoidal positional embeddings and appends labels.""" |
||||||
|
(bx, nx), (by, ny), (bl, nl) = x.shape, y.shape, labels.shape |
||||||
|
assert bx == by and nx == ny and bx == bl and nx == nl |
||||||
|
pos_x, pos_y = self._encode_xy(x.flatten(), y.flatten()) |
||||||
|
pos_x, pos_y = pos_x.reshape(bx, nx, -1), pos_y.reshape(by, ny, -1) |
||||||
|
pos = torch.cat((pos_y, pos_x, labels[:, :, None]), dim=2) |
||||||
|
return pos |
||||||
|
|
||||||
|
@torch.no_grad() |
||||||
|
def forward(self, x: torch.Tensor): |
||||||
|
"""Generate sinusoidal position embeddings for 2D inputs.""" |
||||||
|
cache_key = (x.shape[-2], x.shape[-1]) |
||||||
|
if cache_key in self.cache: |
||||||
|
return self.cache[cache_key][None].repeat(x.shape[0], 1, 1, 1) |
||||||
|
y_embed = ( |
||||||
|
torch.arange(1, x.shape[-2] + 1, dtype=torch.float32, device=x.device) |
||||||
|
.view(1, -1, 1) |
||||||
|
.repeat(x.shape[0], 1, x.shape[-1]) |
||||||
|
) |
||||||
|
x_embed = ( |
||||||
|
torch.arange(1, x.shape[-1] + 1, dtype=torch.float32, device=x.device) |
||||||
|
.view(1, 1, -1) |
||||||
|
.repeat(x.shape[0], x.shape[-2], 1) |
||||||
|
) |
||||||
|
|
||||||
|
if self.normalize: |
||||||
|
eps = 1e-6 |
||||||
|
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale |
||||||
|
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale |
||||||
|
|
||||||
|
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device) |
||||||
|
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) |
||||||
|
|
||||||
|
pos_x = x_embed[:, :, :, None] / dim_t |
||||||
|
pos_y = y_embed[:, :, :, None] / dim_t |
||||||
|
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) |
||||||
|
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3) |
||||||
|
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2) |
||||||
|
self.cache[cache_key] = pos[0] |
||||||
|
return pos |
||||||
@ -0,0 +1,191 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import torch |
||||||
|
import torch.nn.functional as F |
||||||
|
|
||||||
|
|
||||||
|
def select_closest_cond_frames(frame_idx, cond_frame_outputs, max_cond_frame_num): |
||||||
|
""" |
||||||
|
Selects the closest conditioning frames to a given frame index. |
||||||
|
|
||||||
|
Args: |
||||||
|
frame_idx (int): Current frame index. |
||||||
|
cond_frame_outputs (Dict[int, Any]): Dictionary of conditioning frame outputs keyed by frame indices. |
||||||
|
max_cond_frame_num (int): Maximum number of conditioning frames to select. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Tuple[Dict[int, Any], Dict[int, Any]]): A tuple containing two dictionaries: |
||||||
|
- selected_outputs: Selected items from cond_frame_outputs. |
||||||
|
- unselected_outputs: Items not selected from cond_frame_outputs. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> frame_idx = 5 |
||||||
|
>>> cond_frame_outputs = {1: 'a', 3: 'b', 7: 'c', 9: 'd'} |
||||||
|
>>> max_cond_frame_num = 2 |
||||||
|
>>> selected, unselected = select_closest_cond_frames(frame_idx, cond_frame_outputs, max_cond_frame_num) |
||||||
|
>>> print(selected) |
||||||
|
{3: 'b', 7: 'c'} |
||||||
|
>>> print(unselected) |
||||||
|
{1: 'a', 9: 'd'} |
||||||
|
""" |
||||||
|
if max_cond_frame_num == -1 or len(cond_frame_outputs) <= max_cond_frame_num: |
||||||
|
selected_outputs = cond_frame_outputs |
||||||
|
unselected_outputs = {} |
||||||
|
else: |
||||||
|
assert max_cond_frame_num >= 2, "we should allow using 2+ conditioning frames" |
||||||
|
selected_outputs = {} |
||||||
|
|
||||||
|
# the closest conditioning frame before `frame_idx` (if any) |
||||||
|
idx_before = max((t for t in cond_frame_outputs if t < frame_idx), default=None) |
||||||
|
if idx_before is not None: |
||||||
|
selected_outputs[idx_before] = cond_frame_outputs[idx_before] |
||||||
|
|
||||||
|
# the closest conditioning frame after `frame_idx` (if any) |
||||||
|
idx_after = min((t for t in cond_frame_outputs if t >= frame_idx), default=None) |
||||||
|
if idx_after is not None: |
||||||
|
selected_outputs[idx_after] = cond_frame_outputs[idx_after] |
||||||
|
|
||||||
|
# add other temporally closest conditioning frames until reaching a total |
||||||
|
# of `max_cond_frame_num` conditioning frames. |
||||||
|
num_remain = max_cond_frame_num - len(selected_outputs) |
||||||
|
inds_remain = sorted( |
||||||
|
(t for t in cond_frame_outputs if t not in selected_outputs), |
||||||
|
key=lambda x: abs(x - frame_idx), |
||||||
|
)[:num_remain] |
||||||
|
selected_outputs.update((t, cond_frame_outputs[t]) for t in inds_remain) |
||||||
|
unselected_outputs = {t: v for t, v in cond_frame_outputs.items() if t not in selected_outputs} |
||||||
|
|
||||||
|
return selected_outputs, unselected_outputs |
||||||
|
|
||||||
|
|
||||||
|
def get_1d_sine_pe(pos_inds, dim, temperature=10000): |
||||||
|
"""Generates 1D sinusoidal positional embeddings for given positions and dimensions.""" |
||||||
|
pe_dim = dim // 2 |
||||||
|
dim_t = torch.arange(pe_dim, dtype=torch.float32, device=pos_inds.device) |
||||||
|
dim_t = temperature ** (2 * (dim_t // 2) / pe_dim) |
||||||
|
|
||||||
|
pos_embed = pos_inds.unsqueeze(-1) / dim_t |
||||||
|
pos_embed = torch.cat([pos_embed.sin(), pos_embed.cos()], dim=-1) |
||||||
|
return pos_embed |
||||||
|
|
||||||
|
|
||||||
|
def init_t_xy(end_x: int, end_y: int): |
||||||
|
"""Initializes 1D and 2D coordinate tensors for a grid of size end_x by end_y.""" |
||||||
|
t = torch.arange(end_x * end_y, dtype=torch.float32) |
||||||
|
t_x = (t % end_x).float() |
||||||
|
t_y = torch.div(t, end_x, rounding_mode="floor").float() |
||||||
|
return t_x, t_y |
||||||
|
|
||||||
|
|
||||||
|
def compute_axial_cis(dim: int, end_x: int, end_y: int, theta: float = 10000.0): |
||||||
|
"""Computes axial complex exponential positional encodings for 2D spatial positions.""" |
||||||
|
freqs_x = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim)) |
||||||
|
freqs_y = 1.0 / (theta ** (torch.arange(0, dim, 4)[: (dim // 4)].float() / dim)) |
||||||
|
|
||||||
|
t_x, t_y = init_t_xy(end_x, end_y) |
||||||
|
freqs_x = torch.outer(t_x, freqs_x) |
||||||
|
freqs_y = torch.outer(t_y, freqs_y) |
||||||
|
freqs_cis_x = torch.polar(torch.ones_like(freqs_x), freqs_x) |
||||||
|
freqs_cis_y = torch.polar(torch.ones_like(freqs_y), freqs_y) |
||||||
|
return torch.cat([freqs_cis_x, freqs_cis_y], dim=-1) |
||||||
|
|
||||||
|
|
||||||
|
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor): |
||||||
|
"""Reshapes frequency tensor for broadcasting, ensuring compatibility with input tensor dimensions.""" |
||||||
|
ndim = x.ndim |
||||||
|
assert 0 <= 1 < ndim |
||||||
|
assert freqs_cis.shape == (x.shape[-2], x.shape[-1]) |
||||||
|
shape = [d if i >= ndim - 2 else 1 for i, d in enumerate(x.shape)] |
||||||
|
return freqs_cis.view(*shape) |
||||||
|
|
||||||
|
|
||||||
|
def apply_rotary_enc( |
||||||
|
xq: torch.Tensor, |
||||||
|
xk: torch.Tensor, |
||||||
|
freqs_cis: torch.Tensor, |
||||||
|
repeat_freqs_k: bool = False, |
||||||
|
): |
||||||
|
"""Applies rotary positional encoding to query and key tensors using complex-valued frequency components.""" |
||||||
|
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2)) |
||||||
|
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2)) if xk.shape[-2] != 0 else None |
||||||
|
freqs_cis = reshape_for_broadcast(freqs_cis, xq_) |
||||||
|
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3) |
||||||
|
if xk_ is None: |
||||||
|
# no keys to rotate, due to dropout |
||||||
|
return xq_out.type_as(xq).to(xq.device), xk |
||||||
|
# repeat freqs along seq_len dim to match k seq_len |
||||||
|
if repeat_freqs_k: |
||||||
|
r = xk_.shape[-2] // xq_.shape[-2] |
||||||
|
freqs_cis = freqs_cis.repeat(*([1] * (freqs_cis.ndim - 2)), r, 1) |
||||||
|
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3) |
||||||
|
return xq_out.type_as(xq).to(xq.device), xk_out.type_as(xk).to(xk.device) |
||||||
|
|
||||||
|
|
||||||
|
def window_partition(x, window_size): |
||||||
|
""" |
||||||
|
Partitions input tensor into non-overlapping windows with padding if needed. |
||||||
|
|
||||||
|
Args: |
||||||
|
x (torch.Tensor): Input tensor with shape (B, H, W, C). |
||||||
|
window_size (int): Size of each window. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(Tuple[torch.Tensor, Tuple[int, int]]): A tuple containing: |
||||||
|
- windows (torch.Tensor): Partitioned windows with shape (B * num_windows, window_size, window_size, C). |
||||||
|
- (Hp, Wp) (Tuple[int, int]): Padded height and width before partition. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> x = torch.randn(1, 16, 16, 3) |
||||||
|
>>> windows, (Hp, Wp) = window_partition(x, window_size=4) |
||||||
|
>>> print(windows.shape, Hp, Wp) |
||||||
|
torch.Size([16, 4, 4, 3]) 16 16 |
||||||
|
""" |
||||||
|
B, H, W, C = x.shape |
||||||
|
|
||||||
|
pad_h = (window_size - H % window_size) % window_size |
||||||
|
pad_w = (window_size - W % window_size) % window_size |
||||||
|
if pad_h > 0 or pad_w > 0: |
||||||
|
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h)) |
||||||
|
Hp, Wp = H + pad_h, W + pad_w |
||||||
|
|
||||||
|
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C) |
||||||
|
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C) |
||||||
|
return windows, (Hp, Wp) |
||||||
|
|
||||||
|
|
||||||
|
def window_unpartition(windows, window_size, pad_hw, hw): |
||||||
|
""" |
||||||
|
Unpartitions windowed sequences into original sequences and removes padding. |
||||||
|
|
||||||
|
This function reverses the windowing process, reconstructing the original input from windowed segments |
||||||
|
and removing any padding that was added during the windowing process. |
||||||
|
|
||||||
|
Args: |
||||||
|
windows (torch.Tensor): Input tensor of windowed sequences with shape (B * num_windows, window_size, |
||||||
|
window_size, C), where B is the batch size, num_windows is the number of windows, window_size is |
||||||
|
the size of each window, and C is the number of channels. |
||||||
|
window_size (int): Size of each window. |
||||||
|
pad_hw (Tuple[int, int]): Padded height and width (Hp, Wp) of the input before windowing. |
||||||
|
hw (Tuple[int, int]): Original height and width (H, W) of the input before padding and windowing. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(torch.Tensor): Unpartitioned sequences with shape (B, H, W, C), where B is the batch size, H and W |
||||||
|
are the original height and width, and C is the number of channels. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> windows = torch.rand(32, 8, 8, 64) # 32 windows of size 8x8 with 64 channels |
||||||
|
>>> pad_hw = (16, 16) # Padded height and width |
||||||
|
>>> hw = (15, 14) # Original height and width |
||||||
|
>>> x = window_unpartition(windows, window_size=8, pad_hw=pad_hw, hw=hw) |
||||||
|
>>> print(x.shape) |
||||||
|
torch.Size([1, 15, 14, 64]) |
||||||
|
""" |
||||||
|
Hp, Wp = pad_hw |
||||||
|
H, W = hw |
||||||
|
B = windows.shape[0] // (Hp * Wp // window_size // window_size) |
||||||
|
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1) |
||||||
|
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1) |
||||||
|
|
||||||
|
if Hp > H or Wp > W: |
||||||
|
x = x[:, :H, :W, :].contiguous() |
||||||
|
return x |
||||||
@ -0,0 +1,182 @@ |
|||||||
|
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||||
|
|
||||||
|
import torch |
||||||
|
|
||||||
|
from ..sam.predict import Predictor |
||||||
|
from .build import build_sam2 |
||||||
|
|
||||||
|
|
||||||
|
class SAM2Predictor(Predictor): |
||||||
|
""" |
||||||
|
A predictor class for the Segment Anything Model 2 (SAM2), extending the base Predictor class. |
||||||
|
|
||||||
|
This class provides an interface for model inference tailored to image segmentation tasks, leveraging SAM2's |
||||||
|
advanced architecture and promptable segmentation capabilities. It facilitates flexible and real-time mask |
||||||
|
generation, working with various types of prompts such as bounding boxes, points, and low-resolution masks. |
||||||
|
|
||||||
|
Attributes: |
||||||
|
cfg (Dict): Configuration dictionary specifying model and task-related parameters. |
||||||
|
overrides (Dict): Dictionary containing values that override the default configuration. |
||||||
|
_callbacks (Dict): Dictionary of user-defined callback functions to augment behavior. |
||||||
|
args (namespace): Namespace to hold command-line arguments or other operational variables. |
||||||
|
im (torch.Tensor): Preprocessed input image tensor. |
||||||
|
features (torch.Tensor): Extracted image features used for inference. |
||||||
|
prompts (Dict): Collection of various prompt types, such as bounding boxes and points. |
||||||
|
segment_all (bool): Flag to control whether to segment all objects in the image or only specified ones. |
||||||
|
model (torch.nn.Module): The loaded SAM2 model. |
||||||
|
device (torch.device): The device (CPU or GPU) on which the model is loaded. |
||||||
|
_bb_feat_sizes (List[Tuple[int, int]]): List of feature sizes for different backbone levels. |
||||||
|
|
||||||
|
Methods: |
||||||
|
get_model: Builds and returns the SAM2 model. |
||||||
|
prompt_inference: Performs image segmentation inference based on various prompts. |
||||||
|
set_image: Preprocesses and sets a single image for inference. |
||||||
|
get_im_features: Extracts image features from the SAM2 image encoder. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> predictor = SAM2Predictor(model='sam2_l.pt') |
||||||
|
>>> predictor.set_image('path/to/image.jpg') |
||||||
|
>>> masks, scores = predictor.prompt_inference(im=predictor.im, points=[[500, 375]], labels=[1]) |
||||||
|
>>> print(f"Generated {len(masks)} mask(s) with scores: {scores}") |
||||||
|
""" |
||||||
|
|
||||||
|
_bb_feat_sizes = [ |
||||||
|
(256, 256), |
||||||
|
(128, 128), |
||||||
|
(64, 64), |
||||||
|
] |
||||||
|
|
||||||
|
def get_model(self): |
||||||
|
"""Retrieves and initializes the Segment Anything Model (SAM) for image segmentation tasks.""" |
||||||
|
return build_sam2(self.args.model) |
||||||
|
|
||||||
|
def prompt_inference( |
||||||
|
self, |
||||||
|
im, |
||||||
|
bboxes=None, |
||||||
|
points=None, |
||||||
|
labels=None, |
||||||
|
masks=None, |
||||||
|
multimask_output=False, |
||||||
|
img_idx=-1, |
||||||
|
): |
||||||
|
""" |
||||||
|
Performs image segmentation inference based on various prompts using SAM2 architecture. |
||||||
|
|
||||||
|
Args: |
||||||
|
im (torch.Tensor): Preprocessed input image tensor with shape (N, C, H, W). |
||||||
|
bboxes (np.ndarray | List | None): Bounding boxes in XYXY format with shape (N, 4). |
||||||
|
points (np.ndarray | List | None): Points indicating object locations with shape (N, 2), in pixels. |
||||||
|
labels (np.ndarray | List | None): Labels for point prompts with shape (N,). 1 = foreground, 0 = background. |
||||||
|
masks (np.ndarray | None): Low-resolution masks from previous predictions with shape (N, H, W). |
||||||
|
multimask_output (bool): Flag to return multiple masks for ambiguous prompts. |
||||||
|
img_idx (int): Index of the image in the batch to process. |
||||||
|
|
||||||
|
Returns: |
||||||
|
(tuple): Tuple containing: |
||||||
|
- np.ndarray: Output masks with shape (C, H, W), where C is the number of generated masks. |
||||||
|
- np.ndarray: Quality scores for each mask, with length C. |
||||||
|
- np.ndarray: Low-resolution logits with shape (C, 256, 256) for subsequent inference. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> predictor = SAM2Predictor(cfg) |
||||||
|
>>> image = torch.rand(1, 3, 640, 640) |
||||||
|
>>> bboxes = [[100, 100, 200, 200]] |
||||||
|
>>> masks, scores, logits = predictor.prompt_inference(image, bboxes=bboxes) |
||||||
|
""" |
||||||
|
features = self.get_im_features(im) if self.features is None else self.features |
||||||
|
|
||||||
|
src_shape, dst_shape = self.batch[1][0].shape[:2], im.shape[2:] |
||||||
|
r = 1.0 if self.segment_all else min(dst_shape[0] / src_shape[0], dst_shape[1] / src_shape[1]) |
||||||
|
# Transform input prompts |
||||||
|
if points is not None: |
||||||
|
points = torch.as_tensor(points, dtype=torch.float32, device=self.device) |
||||||
|
points = points[None] if points.ndim == 1 else points |
||||||
|
# Assuming labels are all positive if users don't pass labels. |
||||||
|
if labels is None: |
||||||
|
labels = torch.ones(points.shape[0]) |
||||||
|
labels = torch.as_tensor(labels, dtype=torch.int32, device=self.device) |
||||||
|
points *= r |
||||||
|
# (N, 2) --> (N, 1, 2), (N, ) --> (N, 1) |
||||||
|
points, labels = points[:, None], labels[:, None] |
||||||
|
if bboxes is not None: |
||||||
|
bboxes = torch.as_tensor(bboxes, dtype=torch.float32, device=self.device) |
||||||
|
bboxes = bboxes[None] if bboxes.ndim == 1 else bboxes |
||||||
|
bboxes *= r |
||||||
|
if masks is not None: |
||||||
|
masks = torch.as_tensor(masks, dtype=torch.float32, device=self.device).unsqueeze(1) |
||||||
|
|
||||||
|
points = (points, labels) if points is not None else None |
||||||
|
# TODO: Embed prompts |
||||||
|
# if bboxes is not None: |
||||||
|
# box_coords = bboxes.reshape(-1, 2, 2) |
||||||
|
# box_labels = torch.tensor([[2, 3]], dtype=torch.int, device=bboxes.device) |
||||||
|
# box_labels = box_labels.repeat(bboxes.size(0), 1) |
||||||
|
# # we merge "boxes" and "points" into a single "concat_points" input (where |
||||||
|
# # boxes are added at the beginning) to sam_prompt_encoder |
||||||
|
# if concat_points is not None: |
||||||
|
# concat_coords = torch.cat([box_coords, concat_points[0]], dim=1) |
||||||
|
# concat_labels = torch.cat([box_labels, concat_points[1]], dim=1) |
||||||
|
# concat_points = (concat_coords, concat_labels) |
||||||
|
# else: |
||||||
|
# concat_points = (box_coords, box_labels) |
||||||
|
|
||||||
|
sparse_embeddings, dense_embeddings = self.model.sam_prompt_encoder( |
||||||
|
points=points, |
||||||
|
boxes=bboxes, |
||||||
|
masks=masks, |
||||||
|
) |
||||||
|
# Predict masks |
||||||
|
batched_mode = points is not None and points[0].shape[0] > 1 # multi object prediction |
||||||
|
high_res_features = [feat_level[img_idx].unsqueeze(0) for feat_level in features["high_res_feats"]] |
||||||
|
pred_masks, pred_scores, _, _ = self.model.sam_mask_decoder( |
||||||
|
image_embeddings=features["image_embed"][img_idx].unsqueeze(0), |
||||||
|
image_pe=self.model.sam_prompt_encoder.get_dense_pe(), |
||||||
|
sparse_prompt_embeddings=sparse_embeddings, |
||||||
|
dense_prompt_embeddings=dense_embeddings, |
||||||
|
multimask_output=multimask_output, |
||||||
|
repeat_image=batched_mode, |
||||||
|
high_res_features=high_res_features, |
||||||
|
) |
||||||
|
# (N, d, H, W) --> (N*d, H, W), (N, d) --> (N*d, ) |
||||||
|
# `d` could be 1 or 3 depends on `multimask_output`. |
||||||
|
return pred_masks.flatten(0, 1), pred_scores.flatten(0, 1) |
||||||
|
|
||||||
|
def set_image(self, image): |
||||||
|
""" |
||||||
|
Preprocesses and sets a single image for inference. |
||||||
|
|
||||||
|
This function sets up the model if not already initialized, configures the data source to the specified image, |
||||||
|
and preprocesses the image for feature extraction. Only one image can be set at a time. |
||||||
|
|
||||||
|
Args: |
||||||
|
image (str | np.ndarray): Image file path as a string, or a numpy array image read by cv2. |
||||||
|
|
||||||
|
Raises: |
||||||
|
AssertionError: If more than one image is set. |
||||||
|
|
||||||
|
Examples: |
||||||
|
>>> predictor = SAM2Predictor() |
||||||
|
>>> predictor.set_image("path/to/image.jpg") |
||||||
|
>>> predictor.set_image(np.array([...])) # Using a numpy array |
||||||
|
""" |
||||||
|
if self.model is None: |
||||||
|
self.setup_model(model=None) |
||||||
|
self.setup_source(image) |
||||||
|
assert len(self.dataset) == 1, "`set_image` only supports setting one image!" |
||||||
|
for batch in self.dataset: |
||||||
|
im = self.preprocess(batch[1]) |
||||||
|
self.features = self.get_im_features(im) |
||||||
|
break |
||||||
|
|
||||||
|
def get_im_features(self, im): |
||||||
|
"""Extracts and processes image features using SAM2's image encoder for subsequent segmentation tasks.""" |
||||||
|
backbone_out = self.model.forward_image(im) |
||||||
|
_, vision_feats, _, _ = self.model._prepare_backbone_features(backbone_out) |
||||||
|
if self.model.directly_add_no_mem_embed: |
||||||
|
vision_feats[-1] = vision_feats[-1] + self.model.no_mem_embed |
||||||
|
feats = [ |
||||||
|
feat.permute(1, 2, 0).view(1, -1, *feat_size) |
||||||
|
for feat, feat_size in zip(vision_feats[::-1], self._bb_feat_sizes[::-1]) |
||||||
|
][::-1] |
||||||
|
return {"image_embed": feats[-1], "high_res_feats": feats[:-1]} |
||||||
Loading…
Reference in new issue