
 +
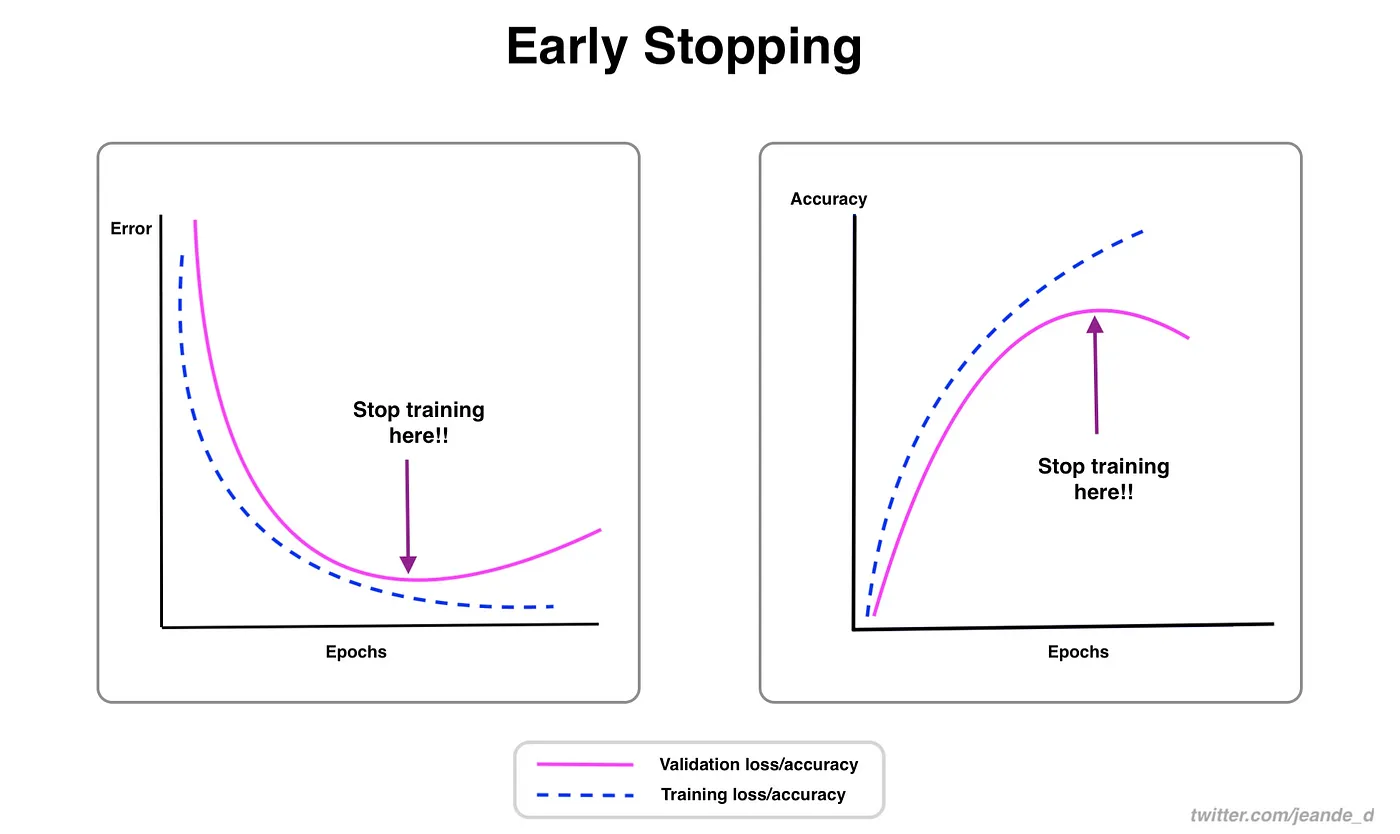
+ - **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/detect/globalwheat2020.md b/docs/en/datasets/detect/globalwheat2020.md
index 28c95c10f7..a8e255b5a0 100644
--- a/docs/en/datasets/detect/globalwheat2020.md
+++ b/docs/en/datasets/detect/globalwheat2020.md
@@ -65,7 +65,7 @@ To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
-
+
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
diff --git a/docs/en/datasets/detect/index.md b/docs/en/datasets/detect/index.md
index 97806cb0d7..934fe38536 100644
--- a/docs/en/datasets/detect/index.md
+++ b/docs/en/datasets/detect/index.md
@@ -34,15 +34,15 @@ names:
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
-
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/detect/globalwheat2020.md b/docs/en/datasets/detect/globalwheat2020.md
index 28c95c10f7..a8e255b5a0 100644
--- a/docs/en/datasets/detect/globalwheat2020.md
+++ b/docs/en/datasets/detect/globalwheat2020.md
@@ -65,7 +65,7 @@ To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an
The Global Wheat Head Dataset contains a diverse set of outdoor field images, capturing the natural variability in wheat head appearances, environments, and conditions. Here are some examples of data from the dataset, along with their corresponding annotations:
-
+
- **Wheat Head Detection**: This image demonstrates an example of wheat head detection, where wheat heads are annotated with bounding boxes. The dataset provides a variety of images to facilitate the development of models for this task.
diff --git a/docs/en/datasets/detect/index.md b/docs/en/datasets/detect/index.md
index 97806cb0d7..934fe38536 100644
--- a/docs/en/datasets/detect/index.md
+++ b/docs/en/datasets/detect/index.md
@@ -34,15 +34,15 @@ names:
Labels for this format should be exported to YOLO format with one `*.txt` file per image. If there are no objects in an image, no `*.txt` file is required. The `*.txt` file should be formatted with one row per object in `class x_center y_center width height` format. Box coordinates must be in **normalized xywh** format (from 0 to 1). If your boxes are in pixels, you should divide `x_center` and `width` by image width, and `y_center` and `height` by image height. Class numbers should be zero-indexed (start with 0).
-




-
+

-  +
+ 
-  +
+ 
-
+

@@ -41,19 +41,19 @@ Semantic search is a technique for finding similar images to a given image. It i For example: In this VOC Exploration dashboard, user selects a couple airplane images like this:
-
+

-
+

-
+

-
+

-
+
-
+

-
+

 - **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index f7708a10a0..106317034f 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -20,7 +20,7 @@ class_index x1 y1 x2 y2 x3 y3 x4 y4
Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
-
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index f7708a10a0..106317034f 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -20,7 +20,7 @@ class_index x1 y1 x2 y2 x3 y3 x4 y4
Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
-

 +
+ - **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/pose/tiger-pose.md b/docs/en/datasets/pose/tiger-pose.md
index d1e338ccac..457e8fefe7 100644
--- a/docs/en/datasets/pose/tiger-pose.md
+++ b/docs/en/datasets/pose/tiger-pose.md
@@ -64,7 +64,7 @@ To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an i
Here are some examples of images from the Tiger-Pose dataset, along with their corresponding annotations:
-
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/pose/tiger-pose.md b/docs/en/datasets/pose/tiger-pose.md
index d1e338ccac..457e8fefe7 100644
--- a/docs/en/datasets/pose/tiger-pose.md
+++ b/docs/en/datasets/pose/tiger-pose.md
@@ -64,7 +64,7 @@ To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an i
Here are some examples of images from the Tiger-Pose dataset, along with their corresponding annotations:
- +
+ - **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/carparts-seg.md b/docs/en/datasets/segment/carparts-seg.md
index 60890e062e..d5799954be 100644
--- a/docs/en/datasets/segment/carparts-seg.md
+++ b/docs/en/datasets/segment/carparts-seg.md
@@ -72,7 +72,7 @@ To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100
The Carparts Segmentation dataset includes a diverse array of images and videos taken from various perspectives. Below, you'll find examples of data from the dataset along with their corresponding annotations:
-
+
- This image illustrates object segmentation within a sample, featuring annotated bounding boxes with masks surrounding identified objects. The dataset consists of a varied set of images captured in various locations, environments, and densities, serving as a comprehensive resource for crafting models specific to this task.
- This instance highlights the diversity and complexity inherent in the dataset, emphasizing the crucial role of high-quality data in computer vision tasks, particularly in the realm of car parts segmentation.
diff --git a/docs/en/datasets/segment/coco.md b/docs/en/datasets/segment/coco.md
index e02b677115..bb88a232b4 100644
--- a/docs/en/datasets/segment/coco.md
+++ b/docs/en/datasets/segment/coco.md
@@ -76,7 +76,7 @@ To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an imag
COCO-Seg, like its predecessor COCO, contains a diverse set of images with various object categories and complex scenes. However, COCO-Seg introduces more detailed instance segmentation masks for each object in the images. Here are some examples of images from the dataset, along with their corresponding instance segmentation masks:
-
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This aids the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/coco8-seg.md b/docs/en/datasets/segment/coco8-seg.md
index bcca4a2641..f22d6a68a3 100644
--- a/docs/en/datasets/segment/coco8-seg.md
+++ b/docs/en/datasets/segment/coco8-seg.md
@@ -51,7 +51,7 @@ To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an ima
Here are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:
-
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/carparts-seg.md b/docs/en/datasets/segment/carparts-seg.md
index 60890e062e..d5799954be 100644
--- a/docs/en/datasets/segment/carparts-seg.md
+++ b/docs/en/datasets/segment/carparts-seg.md
@@ -72,7 +72,7 @@ To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100
The Carparts Segmentation dataset includes a diverse array of images and videos taken from various perspectives. Below, you'll find examples of data from the dataset along with their corresponding annotations:
-
+
- This image illustrates object segmentation within a sample, featuring annotated bounding boxes with masks surrounding identified objects. The dataset consists of a varied set of images captured in various locations, environments, and densities, serving as a comprehensive resource for crafting models specific to this task.
- This instance highlights the diversity and complexity inherent in the dataset, emphasizing the crucial role of high-quality data in computer vision tasks, particularly in the realm of car parts segmentation.
diff --git a/docs/en/datasets/segment/coco.md b/docs/en/datasets/segment/coco.md
index e02b677115..bb88a232b4 100644
--- a/docs/en/datasets/segment/coco.md
+++ b/docs/en/datasets/segment/coco.md
@@ -76,7 +76,7 @@ To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an imag
COCO-Seg, like its predecessor COCO, contains a diverse set of images with various object categories and complex scenes. However, COCO-Seg introduces more detailed instance segmentation masks for each object in the images. Here are some examples of images from the dataset, along with their corresponding instance segmentation masks:
-
+
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This aids the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/coco8-seg.md b/docs/en/datasets/segment/coco8-seg.md
index bcca4a2641..f22d6a68a3 100644
--- a/docs/en/datasets/segment/coco8-seg.md
+++ b/docs/en/datasets/segment/coco8-seg.md
@@ -51,7 +51,7 @@ To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an ima
Here are some examples of images from the COCO8-Seg dataset, along with their corresponding annotations:
- +
+ - **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/crack-seg.md b/docs/en/datasets/segment/crack-seg.md
index 83f019871f..5fa99dfbbf 100644
--- a/docs/en/datasets/segment/crack-seg.md
+++ b/docs/en/datasets/segment/crack-seg.md
@@ -61,7 +61,7 @@ To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epo
The Crack Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
-
+
- This image presents an example of image object segmentation, featuring annotated bounding boxes with masks outlining identified objects. The dataset includes a diverse array of images taken in different locations, environments, and densities, making it a comprehensive resource for developing models designed for this particular task.
diff --git a/docs/en/datasets/segment/package-seg.md b/docs/en/datasets/segment/package-seg.md
index 86fad9e9b4..bf88410fb6 100644
--- a/docs/en/datasets/segment/package-seg.md
+++ b/docs/en/datasets/segment/package-seg.md
@@ -61,7 +61,7 @@ To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 e
The Package Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
-
+
- This image displays an instance of image object detection, featuring annotated bounding boxes with masks outlining recognized objects. The dataset incorporates a diverse collection of images taken in different locations, environments, and densities. It serves as a comprehensive resource for developing models specific to this task.
- The example emphasizes the diversity and complexity present in the VisDrone dataset, underscoring the significance of high-quality sensor data for computer vision tasks involving drones.
diff --git a/docs/en/guides/analytics.md b/docs/en/guides/analytics.md
index 96cadb86f3..a29e6abe45 100644
--- a/docs/en/guides/analytics.md
+++ b/docs/en/guides/analytics.md
@@ -12,9 +12,9 @@ This guide provides a comprehensive overview of three fundamental types of data
### Visual Samples
-| Line Graph | Bar Plot | Pie Chart |
-| :----------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------: |
-|  |  |  |
+| Line Graph | Bar Plot | Pie Chart |
+| :------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------: |
+|  |  |  |
### Why Graphs are Important
diff --git a/docs/en/guides/azureml-quickstart.md b/docs/en/guides/azureml-quickstart.md
index 0ffaa45d60..92e3d83787 100644
--- a/docs/en/guides/azureml-quickstart.md
+++ b/docs/en/guides/azureml-quickstart.md
@@ -33,7 +33,7 @@ Before you can get started, make sure you have access to an AzureML workspace. I
From your AzureML workspace, select Compute > Compute instances > New, select the instance with the resources you need.
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts.
diff --git a/docs/en/datasets/segment/crack-seg.md b/docs/en/datasets/segment/crack-seg.md
index 83f019871f..5fa99dfbbf 100644
--- a/docs/en/datasets/segment/crack-seg.md
+++ b/docs/en/datasets/segment/crack-seg.md
@@ -61,7 +61,7 @@ To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epo
The Crack Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
-
+
- This image presents an example of image object segmentation, featuring annotated bounding boxes with masks outlining identified objects. The dataset includes a diverse array of images taken in different locations, environments, and densities, making it a comprehensive resource for developing models designed for this particular task.
diff --git a/docs/en/datasets/segment/package-seg.md b/docs/en/datasets/segment/package-seg.md
index 86fad9e9b4..bf88410fb6 100644
--- a/docs/en/datasets/segment/package-seg.md
+++ b/docs/en/datasets/segment/package-seg.md
@@ -61,7 +61,7 @@ To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 e
The Package Segmentation dataset comprises a varied collection of images and videos captured from multiple perspectives. Below are instances of data from the dataset, accompanied by their respective annotations:
-
+
- This image displays an instance of image object detection, featuring annotated bounding boxes with masks outlining recognized objects. The dataset incorporates a diverse collection of images taken in different locations, environments, and densities. It serves as a comprehensive resource for developing models specific to this task.
- The example emphasizes the diversity and complexity present in the VisDrone dataset, underscoring the significance of high-quality sensor data for computer vision tasks involving drones.
diff --git a/docs/en/guides/analytics.md b/docs/en/guides/analytics.md
index 96cadb86f3..a29e6abe45 100644
--- a/docs/en/guides/analytics.md
+++ b/docs/en/guides/analytics.md
@@ -12,9 +12,9 @@ This guide provides a comprehensive overview of three fundamental types of data
### Visual Samples
-| Line Graph | Bar Plot | Pie Chart |
-| :----------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------: |
-|  |  |  |
+| Line Graph | Bar Plot | Pie Chart |
+| :------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------: |
+|  |  |  |
### Why Graphs are Important
diff --git a/docs/en/guides/azureml-quickstart.md b/docs/en/guides/azureml-quickstart.md
index 0ffaa45d60..92e3d83787 100644
--- a/docs/en/guides/azureml-quickstart.md
+++ b/docs/en/guides/azureml-quickstart.md
@@ -33,7 +33,7 @@ Before you can get started, make sure you have access to an AzureML workspace. I
From your AzureML workspace, select Compute > Compute instances > New, select the instance with the resources you need.
-
+
![]()
-
+

-
+
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
 !!! Note
@@ -168,7 +168,7 @@ deepstream-app -c deepstream_app_config.txt
It will take a long time to generate the TensorRT engine file before starting the inference. So please be patient.
-
!!! Note
@@ -168,7 +168,7 @@ deepstream-app -c deepstream_app_config.txt
It will take a long time to generate the TensorRT engine file before starting the inference. So please be patient.
-

-  +
+ 
-  +
+ ![]()
-  +
+ 
- 

-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-
+

-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
 !!! Note
@@ -287,7 +287,7 @@ YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats
Even though all model exports are working with NVIDIA Jetson, we have only included **PyTorch, TorchScript, TensorRT** for the comparison chart below because, they make use of the GPU on the Jetson and are guaranteed to produce the best results. All the other exports only utilize the CPU and the performance is not as good as the above three. You can find benchmarks for all exports in the section after this chart.
!!! Note
@@ -287,7 +287,7 @@ YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats
Even though all model exports are working with NVIDIA Jetson, we have only included **PyTorch, TorchScript, TensorRT** for the comparison chart below because, they make use of the GPU on the Jetson and are guaranteed to produce the best results. All the other exports only utilize the CPU and the performance is not as good as the above three. You can find benchmarks for all exports in the section after this chart.

 ## Next Steps
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index 033b845fc8..00aa917454 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -41,10 +41,10 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
## Real World Applications
-| Logistics | Aquaculture |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |  |
-| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
+| Logistics | Aquaculture |
+| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
!!! Example "Object Counting using YOLOv8 Example"
diff --git a/docs/en/guides/object-cropping.md b/docs/en/guides/object-cropping.md
index d314cee04e..3efaba93e1 100644
--- a/docs/en/guides/object-cropping.md
+++ b/docs/en/guides/object-cropping.md
@@ -29,10 +29,10 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
## Visuals
-| Airport Luggage |
-| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |
-| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
+| Airport Luggage |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |
+| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
!!! Example "Object Cropping using YOLOv8 Example"
diff --git a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
index b6886d5db6..a9acfb123d 100644
--- a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
+++ b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
@@ -6,7 +6,7 @@ keywords: Ultralytics YOLO, OpenVINO optimization, deep learning, model inferenc
# Optimizing OpenVINO Inference for Ultralytics YOLO Models: A Comprehensive Guide
-
## Next Steps
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index 033b845fc8..00aa917454 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -41,10 +41,10 @@ Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
## Real World Applications
-| Logistics | Aquaculture |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |  |
-| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
+| Logistics | Aquaculture |
+| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Conveyor Belt Packets Counting Using Ultralytics YOLOv8 | Fish Counting in Sea using Ultralytics YOLOv8 |
!!! Example "Object Counting using YOLOv8 Example"
diff --git a/docs/en/guides/object-cropping.md b/docs/en/guides/object-cropping.md
index d314cee04e..3efaba93e1 100644
--- a/docs/en/guides/object-cropping.md
+++ b/docs/en/guides/object-cropping.md
@@ -29,10 +29,10 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
## Visuals
-| Airport Luggage |
-| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |
-| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
+| Airport Luggage |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |
+| Suitcases Cropping at airport conveyor belt using Ultralytics YOLOv8 |
!!! Example "Object Cropping using YOLOv8 Example"
diff --git a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
index b6886d5db6..a9acfb123d 100644
--- a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
+++ b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
@@ -6,7 +6,7 @@ keywords: Ultralytics YOLO, OpenVINO optimization, deep learning, model inferenc
# Optimizing OpenVINO Inference for Ultralytics YOLO Models: A Comprehensive Guide
- ## Introduction
diff --git a/docs/en/guides/parking-management.md b/docs/en/guides/parking-management.md
index cc42fb9b45..e25936fbd3 100644
--- a/docs/en/guides/parking-management.md
+++ b/docs/en/guides/parking-management.md
@@ -29,10 +29,10 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
## Real World Applications
-| Parking Management System | Parking Management System |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |  |
-| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
+| Parking Management System | Parking Management System |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
## Parking Management System Code Workflow
@@ -61,7 +61,7 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
- After defining the parking areas with polygons, click `save` to store a JSON file with the data in your working directory.
-
+
### Python Code for Parking Management
diff --git a/docs/en/guides/preprocessing_annotated_data.md b/docs/en/guides/preprocessing_annotated_data.md
index 8935d7d8a5..ef771a28ae 100644
--- a/docs/en/guides/preprocessing_annotated_data.md
+++ b/docs/en/guides/preprocessing_annotated_data.md
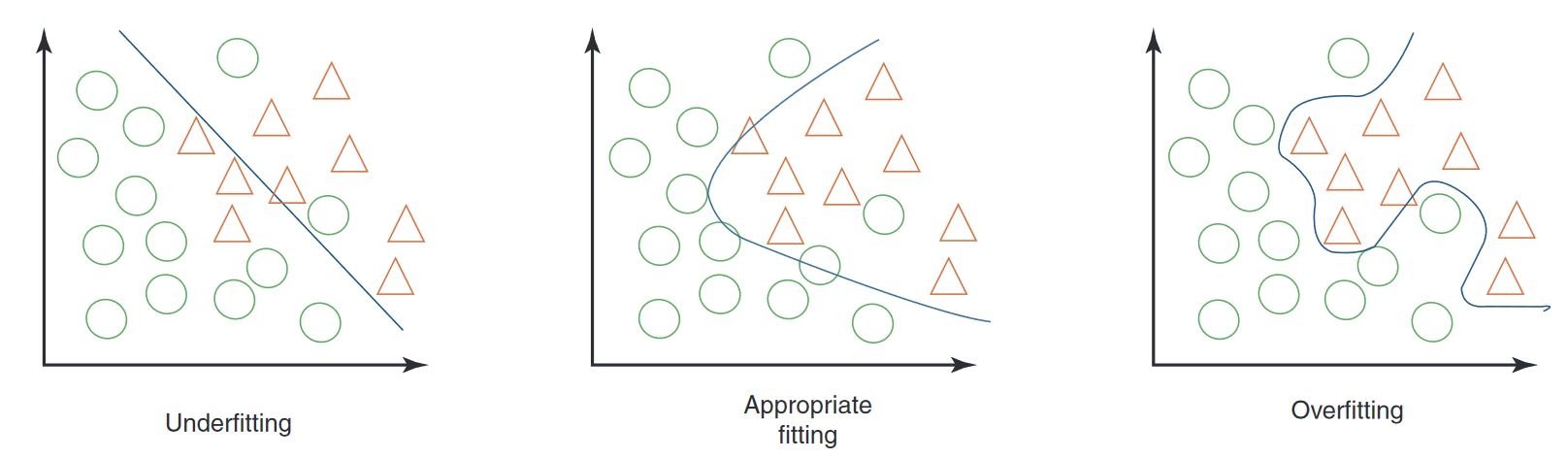
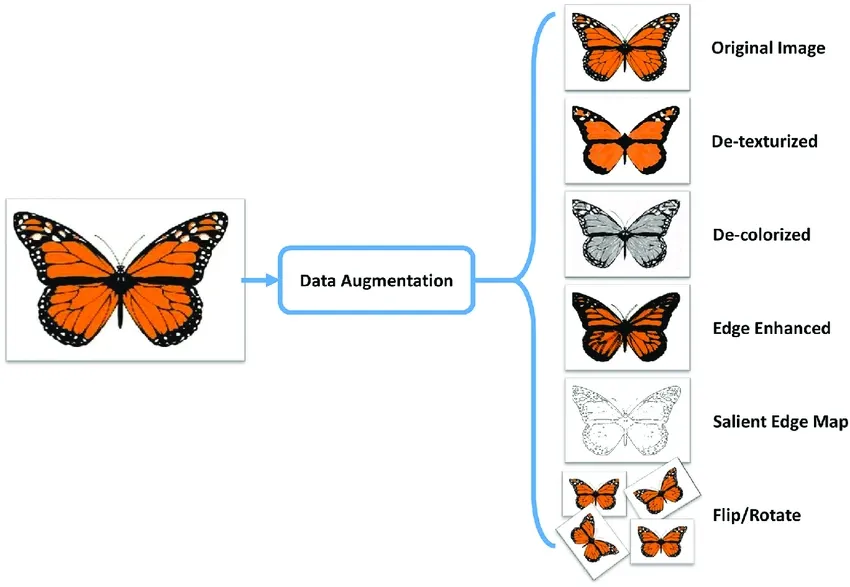
@@ -73,7 +73,7 @@ Here are some other benefits of data augmentation:
Common augmentation techniques include flipping, rotation, scaling, and color adjustments. Several libraries, such as Albumentations, Imgaug, and TensorFlow's ImageDataGenerator, can generate these augmentations.
## Introduction
diff --git a/docs/en/guides/parking-management.md b/docs/en/guides/parking-management.md
index cc42fb9b45..e25936fbd3 100644
--- a/docs/en/guides/parking-management.md
+++ b/docs/en/guides/parking-management.md
@@ -29,10 +29,10 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
## Real World Applications
-| Parking Management System | Parking Management System |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |  |
-| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
+| Parking Management System | Parking Management System |
+| :----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Parking management Aerial View using Ultralytics YOLOv8 | Parking management Top View using Ultralytics YOLOv8 |
## Parking Management System Code Workflow
@@ -61,7 +61,7 @@ Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultr
- After defining the parking areas with polygons, click `save` to store a JSON file with the data in your working directory.
-
+
### Python Code for Parking Management
diff --git a/docs/en/guides/preprocessing_annotated_data.md b/docs/en/guides/preprocessing_annotated_data.md
index 8935d7d8a5..ef771a28ae 100644
--- a/docs/en/guides/preprocessing_annotated_data.md
+++ b/docs/en/guides/preprocessing_annotated_data.md
@@ -73,7 +73,7 @@ Here are some other benefits of data augmentation:
Common augmentation techniques include flipping, rotation, scaling, and color adjustments. Several libraries, such as Albumentations, Imgaug, and TensorFlow's ImageDataGenerator, can generate these augmentations.
-  +
+ 
-
+


-
+

-
+

-
+

-
+

-  +
+ 




 The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
@@ -175,7 +175,7 @@ That's it! When you execute the code, you'll receive a single notification on yo
#### Email Received Sample
-
The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
@@ -175,7 +175,7 @@ That's it! When you execute the code, you'll receive a single notification on yo
#### Email Received Sample
- ## FAQ
diff --git a/docs/en/guides/speed-estimation.md b/docs/en/guides/speed-estimation.md
index ee42bfe6bf..9e9ddce5ee 100644
--- a/docs/en/guides/speed-estimation.md
+++ b/docs/en/guides/speed-estimation.md
@@ -33,10 +33,10 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
## Real World Applications
-| Transportation | Transportation |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  | 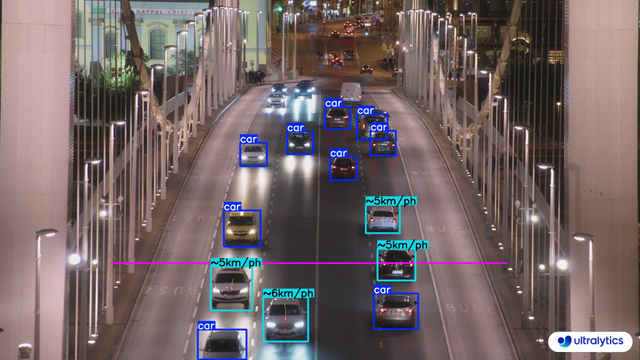 |
-| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
+| Transportation | Transportation |
+| :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
!!! Example "Speed Estimation using YOLOv8 Example"
diff --git a/docs/en/guides/steps-of-a-cv-project.md b/docs/en/guides/steps-of-a-cv-project.md
index a1fbdb5e97..3b98171d30 100644
--- a/docs/en/guides/steps-of-a-cv-project.md
+++ b/docs/en/guides/steps-of-a-cv-project.md
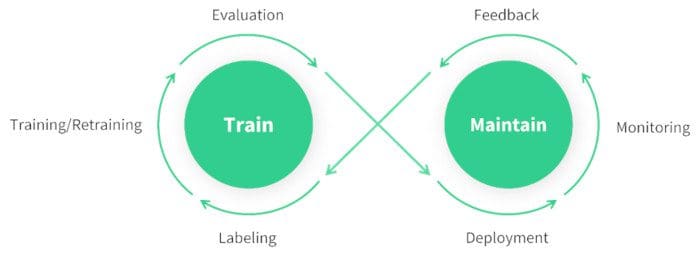
@@ -40,7 +40,7 @@ Before discussing the details of each step involved in a computer vision project
- Finally, you'd deploy your model into the real world and update it based on new insights and feedback.
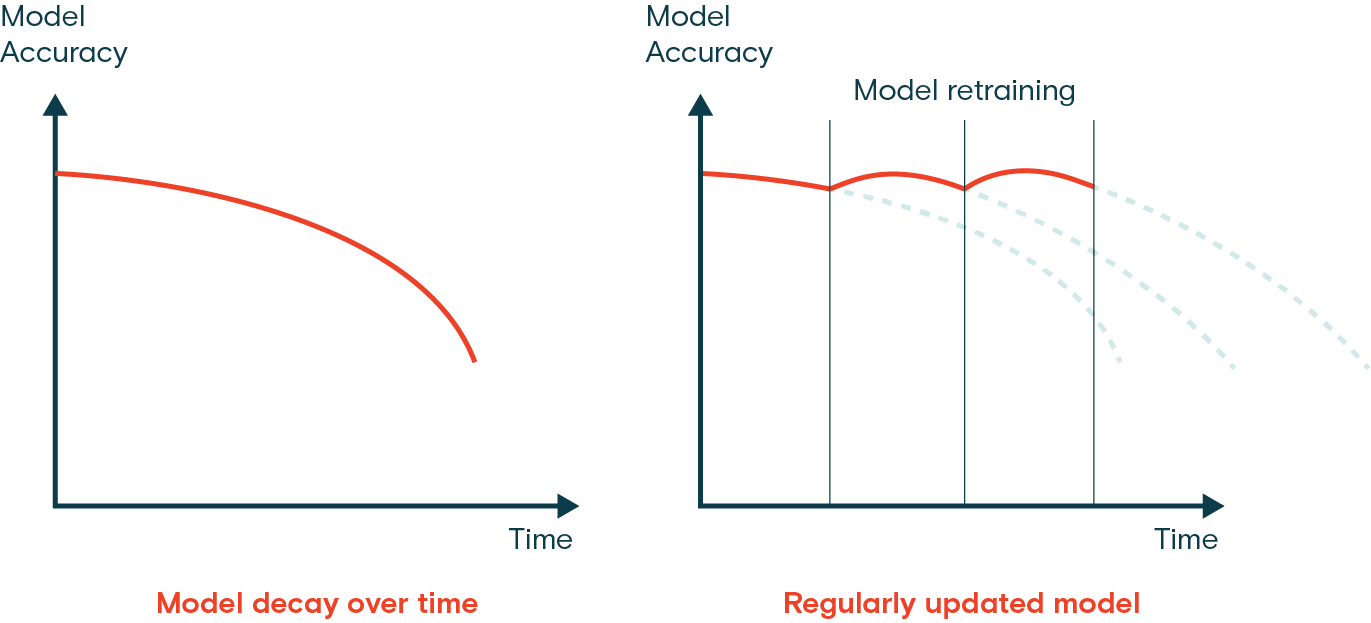
## FAQ
diff --git a/docs/en/guides/speed-estimation.md b/docs/en/guides/speed-estimation.md
index ee42bfe6bf..9e9ddce5ee 100644
--- a/docs/en/guides/speed-estimation.md
+++ b/docs/en/guides/speed-estimation.md
@@ -33,10 +33,10 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
## Real World Applications
-| Transportation | Transportation |
-| :-----------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------: |
-|  |  |
-| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
+| Transportation | Transportation |
+| :------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+|  |  |
+| Speed Estimation on Road using Ultralytics YOLOv8 | Speed Estimation on Bridge using Ultralytics YOLOv8 |
!!! Example "Speed Estimation using YOLOv8 Example"
diff --git a/docs/en/guides/steps-of-a-cv-project.md b/docs/en/guides/steps-of-a-cv-project.md
index a1fbdb5e97..3b98171d30 100644
--- a/docs/en/guides/steps-of-a-cv-project.md
+++ b/docs/en/guides/steps-of-a-cv-project.md
@@ -40,7 +40,7 @@ Before discussing the details of each step involved in a computer vision project
- Finally, you'd deploy your model into the real world and update it based on new insights and feedback.
- .jpeg) +
+ 
-  +
+ 
-
+

-  +
+ 
-
+
-  +
+ 
-  +
+ 
-
+

-
+

-  +
+ 
-  +
+ 
 +
+ ## Table of Contents
diff --git a/docs/en/hub/app/android.md b/docs/en/hub/app/android.md
index 847ae9167e..c3c19b0c17 100644
--- a/docs/en/hub/app/android.md
+++ b/docs/en/hub/app/android.md
@@ -7,7 +7,7 @@ keywords: Ultralytics, Android app, real-time object detection, YOLO models, Ten
# Ultralytics Android App: Real-time Object Detection with YOLO Models
-
## Table of Contents
diff --git a/docs/en/hub/app/android.md b/docs/en/hub/app/android.md
index 847ae9167e..c3c19b0c17 100644
--- a/docs/en/hub/app/android.md
+++ b/docs/en/hub/app/android.md
@@ -7,7 +7,7 @@ keywords: Ultralytics, Android app, real-time object detection, YOLO models, Ten
# Ultralytics Android App: Real-time Object Detection with YOLO Models
- 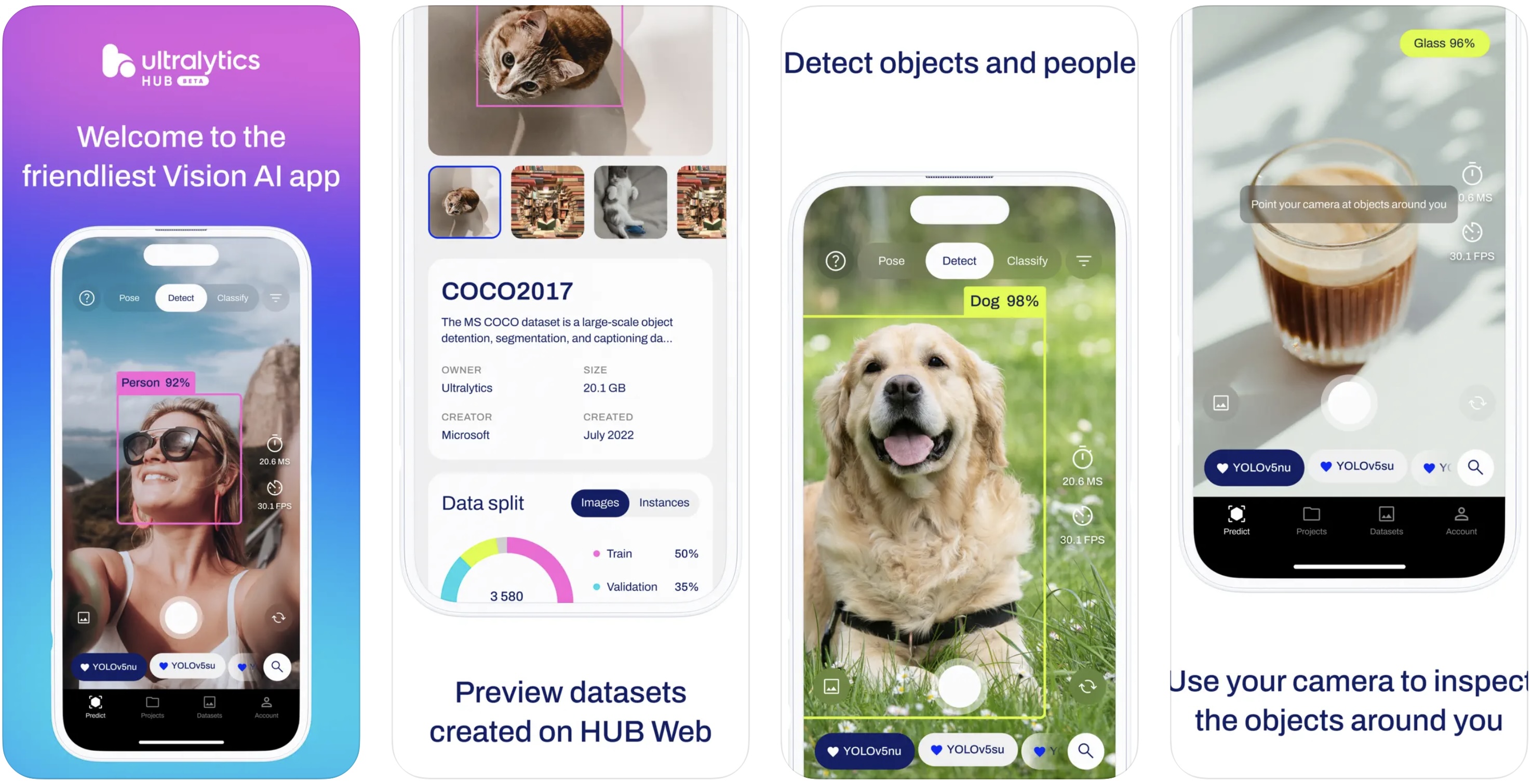 +
+ 
 +
+  +
+