@ -153,14 +153,18 @@ Each subset comprises images categorized into 10 classes, with their annotations
If you use the CIFAR-10 dataset in your research or development projects, make sure to cite the following paper:
If you use the CIFAR-10 dataset in your research or development projects, make sure to cite the following paper:
```bibtex
!!! Quote ""
@TECHREPORT{Krizhevsky09learningmultiple,
author={Alex Krizhevsky},
=== "BibTeX"
title={Learning multiple layers of features from tiny images},
institution={},
```bibtex
year={2009}
@TECHREPORT{Krizhevsky09learningmultiple,
}
author={Alex Krizhevsky},
```
title={Learning multiple layers of features from tiny images},
institution={},
year={2009}
}
```
Acknowledging the dataset's creators helps support continued research and development in the field. For more details, see the [citations and acknowledgments](#citations-and-acknowledgments) section.
Acknowledging the dataset's creators helps support continued research and development in the field. For more details, see the [citations and acknowledgments](#citations-and-acknowledgments) section.
It's important to note that using smaller images will likely yield lower performance in terms of classification accuracy. However, it's an excellent way to iterate quickly in the early stages of model development and prototyping.
It's important to note that using smaller images will likely yield lower performance in terms of classification accuracy. However, it's an excellent way to iterate quickly in the early stages of model development and prototyping.
Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) ensures efficient and safe parking by organizing spaces and monitoring availability. YOLOv8 can improve parking lot management through real-time vehicle detection, and insights into parking occupancy.
Parking management with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) ensures efficient and safe parking by organizing spaces and monitoring availability. YOLOv8 can improve parking lot management through real-time vehicle detection, and insights into parking occupancy.
@ -98,6 +98,18 @@ Next, [train a model](./models.md#train-model) on your dataset.
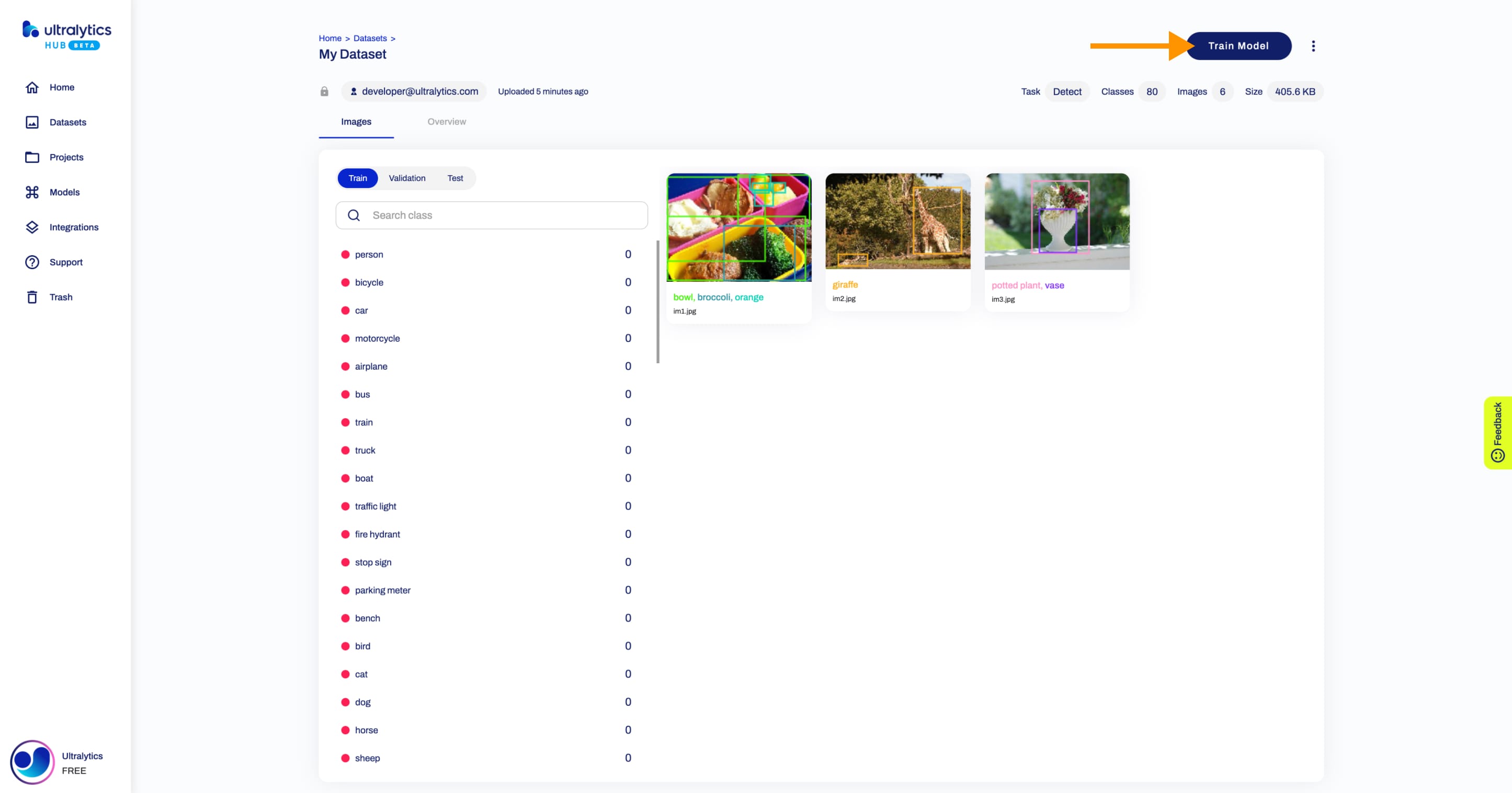

## Download Dataset
Navigate to the Dataset page of the dataset you want to download, open the dataset actions dropdown and click on the **Download** option. This action will start downloading your dataset.
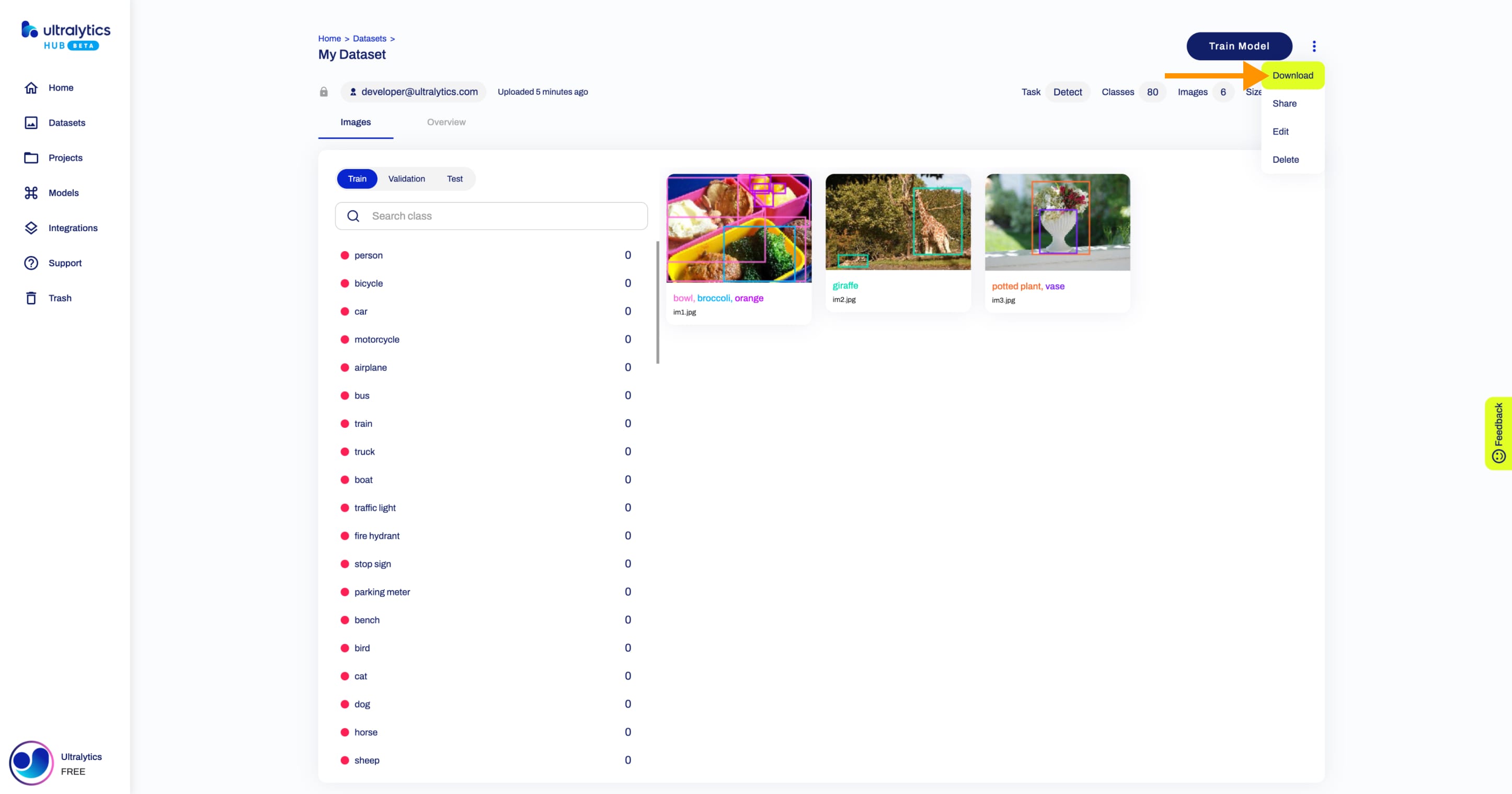
??? tip "Tip"
You can download a dataset directly from the [Datasets](https://hub.ultralytics.com/datasets) page.
ning the usage code snippet above, you can expect the following output:
text
ard: Start with 'tensorboard --logdir path_to_your_tensorboard_logs', view at http://localhost:6006/
```
```
put indicates that TensorBoard is now actively monitoring your YOLOv8 training session. You can access the TensorBoard dashboard by visiting the provided URL (http://localhost:6006/) to view real-time training metrics and model performance. For users working in Google Colab, the TensorBoard will be displayed in the same cell where you executed the TensorBoard configuration commands.
Upon running the usage code snippet above, you can expect the following output:
information related to the model training process, be sure to check our [YOLOv8 Model Training guide](../modes/train.md). If you are interested in learning more about logging, checkpoints, plotting, and file management, read our [usage guide on configuration](../usage/cfg.md).
standing Your TensorBoard for YOLOv8 Training
's focus on understanding the various features and components of TensorBoard in the context of YOLOv8 training. The three key sections of the TensorBoard are Time Series, Scalars, and Graphs.
Series
Series feature in the TensorBoard offers a dynamic and detailed perspective of various training metrics over time for YOLOv8 models. It focuses on the progression and trends of metrics across training epochs. Here's an example of what you can expect to see.
```bash
TensorBoard: Start with 'tensorboard --logdir path_to_your_tensorboard_logs', view at http://localhost:6006/
er Tags and Pinned Cards**: This functionality allows users to filter specific metrics and pin cards for quick comparison and access. It's particularly useful for focusing on specific aspects of the training process.
iled Metric Cards**: Time Series divides metrics into different categories like learning rate (lr), training (train), and validation (val) metrics, each represented by individual cards.
hical Display**: Each card in the Time Series section shows a detailed graph of a specific metric over the course of training. This visual representation aids in identifying trends, patterns, or anomalies in the training process.
This output indicates that TensorBoard is now actively monitoring your YOLOv8 training session. You can access the TensorBoard dashboard by visiting the provided URL (http://localhost:6006/) to view real-time training metrics and model performance. For users working in Google Colab, the TensorBoard will be displayed in the same cell where you executed the TensorBoard configuration commands.
epth Analysis**: Time Series provides an in-depth analysis of each metric. For instance, different learning rate segments are shown, offering insights into how adjustments in learning rate impact the model's learning curve.
For more information related to the model training process, be sure to check our [YOLOv8 Model Training guide](../modes/train.md). If you are interested in learning more about logging, checkpoints, plotting, and file management, read our [usage guide on configuration](../usage/cfg.md).
ortance of Time Series in YOLOv8 Training
## Understanding Your TensorBoard for YOLOv8 Training
Series section is essential for a thorough analysis of the YOLOv8 model's training progress. It lets you track the metrics in real time to promptly identify and solve issues. It also offers a detailed view of each metrics progression, which is crucial for fine-tuning the model and enhancing its performance.
Now, let's focus on understanding the various features and components of TensorBoard in the context of YOLOv8 training. The three key sections of the TensorBoard are Time Series, Scalars, and Graphs.
ars
### Time Series
in the TensorBoard are crucial for plotting and analyzing simple metrics like loss and accuracy during the training of YOLOv8 models. They offer a clear and concise view of how these metrics evolve with each training epoch, providing insights into the model's learning effectiveness and stability. Here's an example of what you can expect to see.
The Time Series feature in the TensorBoard offers a dynamic and detailed perspective of various training metrics over time for YOLOv8 models. It focuses on the progression and trends of metrics across training epochs. Here's an example of what you can expect to see.
ning Rate (lr) Tags**: These tags show the variations in the learning rate across different segments (e.g., `pg0`, `pg1`, `pg2`). This helps us understand the impact of learning rate adjustments on the training process.
- **Filter Tags and Pinned Cards**: This functionality allows users to filter specific metrics and pin cards for quick comparison and access. It's particularly useful for focusing on specific aspects of the training process.
ics Tags**: Scalars include performance indicators such as:
- **Detailed Metric Cards**: Time Series divides metrics into different categories like learning rate (lr), training (train), and validation (val) metrics, each represented by individual cards.
AP50 (B)`: Mean Average Precision at 50% Intersection over Union (IoU), crucial for assessing object detection accuracy.
- **Graphical Display**: Each card in the Time Series section shows a detailed graph of a specific metric over the course of training. This visual representation aids in identifying trends, patterns, or anomalies in the training process.
AP50-95 (B)`: Mean Average Precision calculated over a range of IoU thresholds, offering a more comprehensive evaluation of accuracy.
- **In-Depth Analysis**: Time Series provides an in-depth analysis of each metric. For instance, different learning rate segments are shown, offering insights into how adjustments in learning rate impact the model's learning curve.
recision (B)`: Indicates the ratio of correctly predicted positive observations, key to understanding prediction accuracy.
#### Importance of Time Series in YOLOv8 Training
ecall (B)`: Important for models where missing a detection is significant, this metric measures the ability to detect all relevant instances.
The Time Series section is essential for a thorough analysis of the YOLOv8 model's training progress. It lets you track the metrics in real time to promptly identify and solve issues. It also offers a detailed view of each metrics progression, which is crucial for fine-tuning the model and enhancing its performance.
learn more about the different metrics, read our guide on [performance metrics](../guides/yolo-performance-metrics.md).
### Scalars
ning and Validation Tags (`train`, `val`)**: These tags display metrics specifically for the training and validation datasets, allowing for a comparative analysis of model performance across different data sets.
Scalars in the TensorBoard are crucial for plotting and analyzing simple metrics like loss and accuracy during the training of YOLOv8 models. They offer a clear and concise view of how these metrics evolve with each training epoch, providing insights into the model's learning effectiveness and stability. Here's an example of what you can expect to see.
g scalar metrics is crucial for fine-tuning the YOLOv8 model. Variations in these metrics, such as spikes or irregular patterns in loss graphs, can highlight potential issues such as overfitting, underfitting, or inappropriate learning rate settings. By closely monitoring these scalars, you can make informed decisions to optimize the training process, ensuring that the model learns effectively and achieves the desired performance.
#### Key Features of Scalars in TensorBoard
erence Between Scalars and Time Series
- **Learning Rate (lr) Tags**: These tags show the variations in the learning rate across different segments (e.g., `pg0`, `pg1`, `pg2`). This helps us understand the impact of learning rate adjustments on the training process.
th Scalars and Time Series in TensorBoard are used for tracking metrics, they serve slightly different purposes. Scalars focus on plotting simple metrics such as loss and accuracy as scalar values. They provide a high-level overview of how these metrics change with each training epoch. While, the time-series section of the TensorBoard offers a more detailed timeline view of various metrics. It is particularly useful for monitoring the progression and trends of metrics over time, providing a deeper dive into the specifics of the training process.
- **Metrics Tags**: Scalars include performance indicators such as:
hs
- `mAP50 (B)`: Mean Average Precision at 50% Intersection over Union (IoU), crucial for assessing object detection accuracy.
hs section of the TensorBoard visualizes the computational graph of the YOLOv8 model, showing how operations and data flow within the model. It's a powerful tool for understanding the model's structure, ensuring that all layers are connected correctly, and for identifying any potential bottlenecks in data flow. Here's an example of what you can expect to see.
- `mAP50-95 (B)`: Mean Average Precision calculated over a range of IoU thresholds, offering a more comprehensive evaluation of accuracy.
- `Precision (B)`: Indicates the ratio of correctly predicted positive observations, key to understanding prediction accuracy.
re particularly useful for debugging the model, especially in complex architectures typical in deep learning models like YOLOv8. They help in verifying layer connections and the overall design of the model.
- `Recall (B)`: Important for models where missing a detection is significant, this metric measures the ability to detect all relevant instances.
ry
-Tolearnmoreabout the different metrics, read our guide on [performance metrics](../guides/yolo-performance-metrics.md).
de aims to help you use TensorBoard with YOLOv8 for visualization and analysis of machine learning model training. It focuses on explaining how key TensorBoard features can provide insights into training metrics and model performance during YOLOv8 training sessions.
- **Training and Validation Tags (`train`, `val`)**: These tags display metrics specifically for the training and validation datasets, allowing for a comparative analysis of model performance across different data sets.
re detailed exploration of these features and effective utilization strategies, you can refer to TensorFlow's official [TensorBoard documentation](https://www.tensorflow.org/tensorboard/get_started) and their [GitHub repository](https://github.com/tensorflow/tensorboard).
#### Importance of Monitoring Scalars
learn more about the various integrations of Ultralytics? Check out the [Ultralytics integrations guide page](../integrations/index.md) to see what other exciting capabilities are waiting to be discovered!
Observing scalar metrics is crucial for fine-tuning the YOLOv8 model. Variations in these metrics, such as spikes or irregular patterns in loss graphs, can highlight potential issues such as overfitting, underfitting, or inappropriate learning rate settings. By closely monitoring these scalars, you can make informed decisions to optimize the training process, ensuring that the model learns effectively and achieves the desired performance.
## FAQ
### Difference Between Scalars and Time Series
do I integrate YOLOv8 with TensorBoard for real-time visualization?
While both Scalars and Time Series in TensorBoard are used for tracking metrics, they serve slightly different purposes. Scalars focus on plotting simple metrics such as loss and accuracy as scalar values. They provide a high-level overview of how these metrics change with each training epoch. While, the time-series section of the TensorBoard offers a more detailed timeline view of various metrics. It is particularly useful for monitoring the progression and trends of metrics over time, providing a deeper dive into the specifics of the training process.
ing YOLOv8 with TensorBoard allows for real-time visual insights during model training. First, install the necessary package:
### Graphs
ple "Installation"
The Graphs section of the TensorBoard visualizes the computational graph of the YOLOv8 model, showing how operations and data flow within the model. It's a powerful tool for understanding the model's structure, ensuring that all layers are connected correctly, and for identifying any potential bottlenecks in data flow. Here's an example of what you can expect to see.
# Install the required package for YOLOv8 and Tensorboard
pip install ultralytics
```
Next, configure TensorBoard to log your training runs, then start TensorBoard:
Graphs are particularly useful for debugging the model, especially in complex architectures typical in deep learning models like YOLOv8. They help in verifying layer connections and the overall design of the model.
!!! Example "Configure TensorBoard for Google Colab"
## Summary
=== "Python"
This guide aims to help you use TensorBoard with YOLOv8 for visualization and analysis of machine learning model training. It focuses on explaining how key TensorBoard features can provide insights into training metrics and model performance during YOLOv8 training sessions.
```ipython
For a more detailed exploration of these features and effective utilization strategies, you can refer to TensorFlow's official [TensorBoard documentation](https://www.tensorflow.org/tensorboard/get_started) and their [GitHub repository](https://github.com/tensorflow/tensorboard).
%load_ext tensorboard
%tensorboard --logdir path/to/runs
```
Finally, during training, YOLOv8 automatically logs metrics like loss and accuracy to TensorBoard. You can monitor these metrics by visiting [http://localhost:6006/](http://localhost:6006/).
Want to learn more about the various integrations of Ultralytics? Check out the [Ultralytics integrations guide page](../integrations/index.md) to see what other exciting capabilities are waiting to be discovered!
For a comprehensive guide, refer to our [YOLOv8 Model Training guide](../modes/train.md).
## FAQ
### What benefits does using TensorBoard with YOLOv8 offer?
### What benefits does using TensorBoard with YOLOv8 offer?
@ -225,16 +198,16 @@ Yes, you can use TensorBoard in a Google Colab environment to train YOLOv8 model
TensorBoard will visualize the training progress within Colab, providing real-time insights into metrics like loss and accuracy. For additional details on configuring YOLOv8 training, see our detailed [YOLOv8 Installation guide](../quickstart.md).
TensorBoard will visualize the training progress within Colab, providing real-time insights into metrics like loss and accuracy. For additional details on configuring YOLOv8 training, see our detailed [YOLOv8 Installation guide](../quickstart.md).
@ -82,6 +82,19 @@ Note (2): Due to ONNX Runtime, we need to use CUDA 11 and cuDNN 8. Keep in mind
cmake ..
cmake ..
```
```
**Notice**:
If you encounter an error indicating that the `ONNXRUNTIME_ROOT` variable is not set correctly, you can resolve this by building the project using the appropriate command tailored to your system.