@ -52,8 +52,7 @@ To test a deep learning model on the ImageNet10 dataset with an image size of 22
The ImageNet10 dataset contains a subset of images from the original ImageNet dataset. These images are chosen to represent the first 10 classes in the dataset, providing a diverse yet compact dataset for quick testing and evaluation.
The example showcases the variety and complexity of the images in the ImageNet10 dataset, highlighting its usefulness for sanity checks and quick testing of computer vision models.
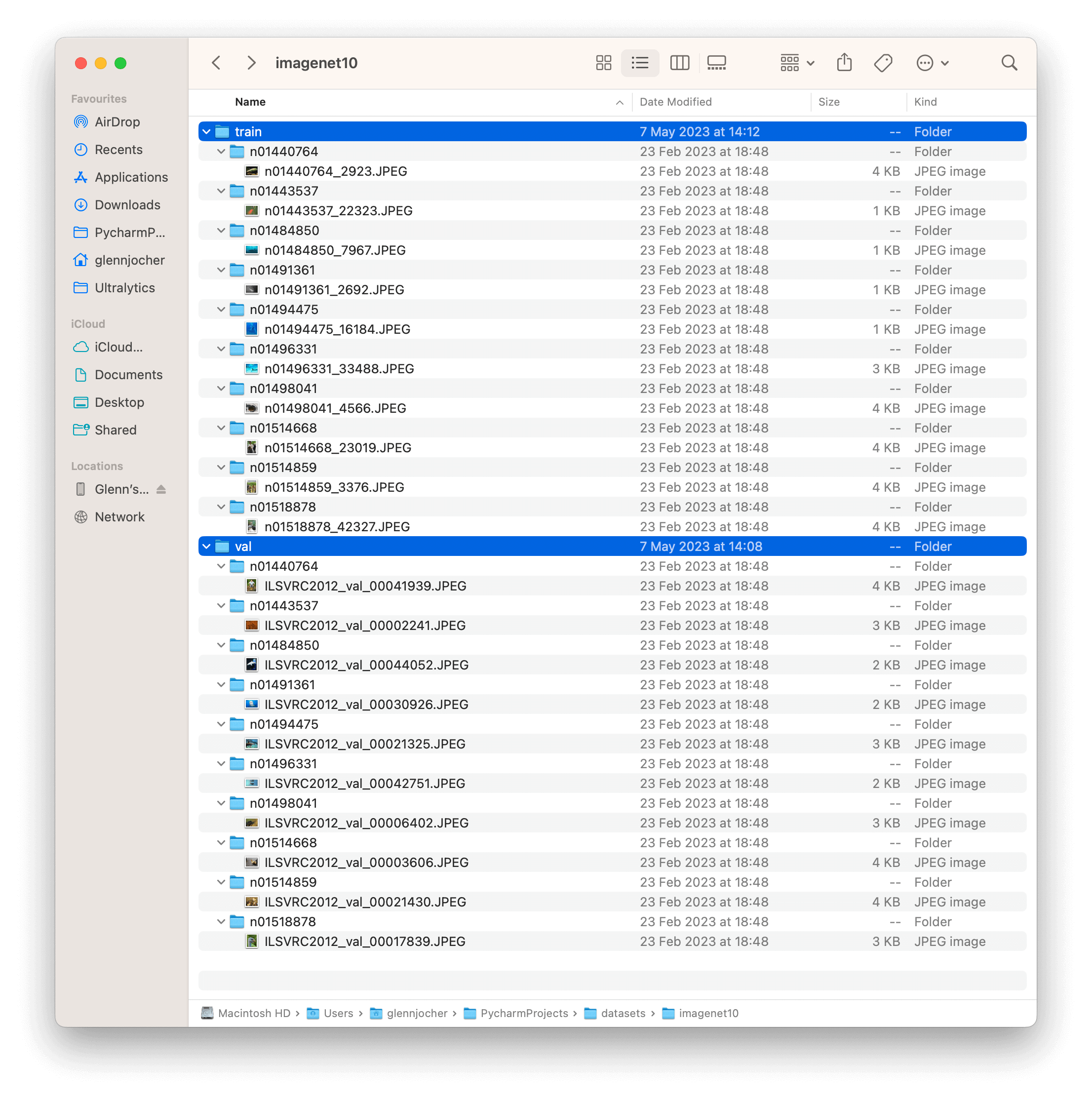 The example showcases the variety and complexity of the images in the ImageNet10 dataset, highlighting its usefulness for sanity checks and quick testing of computer vision models.
@ -10,8 +10,7 @@ keywords: Ultralytics, COCO8 dataset, object detection, model testing, dataset c
[Ultralytics](https://ultralytics.com) COCO8 is a small, but versatile object detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
and [YOLOv8](https://github.com/ultralytics/ultralytics).
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
Similarity search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings.
One the embeddings table is built, you can get run semantic search in any of the following ways:
Similarity search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. One the embeddings table is built, you can get run semantic search in any of the following ways:
- On a given index / list of indices in the dataset like - `exp.get_similar(idx=[1,10], limit=10)`
- On any image/ list of images not in the dataset - `exp.get_similar(img=["path/to/img1", "path/to/img2"], limit=10)`
@ -210,8 +209,7 @@ When using large datasets, you can also create a dedicated vector index for fast
Find more details on the type vector indices available and parameters [here](https://lancedb.github.io/lancedb/ann_indexes/#types-of-index)
In the future, we will add support for creating vector indices directly from Explorer API.
Find more details on the type vector indices available and parameters [here](https://lancedb.github.io/lancedb/ann_indexes/#types-of-index) In the future, we will add support for creating vector indices directly from Explorer API.
## 4. Embeddings Applications
@ -221,15 +219,15 @@ You can use the embeddings table to perform a variety of exploratory analysis. H
Explorer comes with a `similarity_index` operation:
* It tries to estimate how similar each data point is with the rest of the dataset.
* It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.
- It tries to estimate how similar each data point is with the rest of the dataset.
- It does that by counting how many image embeddings lie closer than `max_dist` to the current image in the generated embedding space, considering `top_k` similar images at a time.
It returns a pandas dataframe with the following columns:
*`idx`: Index of the image in the dataset
*`im_file`: Path to the image file
*`count`: Number of images in the dataset that are closer than `max_dist` to the current image
*`sim_im_files`: List of paths to the `count` similar images
-`idx`: Index of the image in the dataset
-`im_file`: Path to the image file
-`count`: Number of images in the dataset that are closer than `max_dist` to the current image
-`sim_im_files`: List of paths to the `count` similar images
[Ultralytics](https://ultralytics.com) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
and [YOLOv8](https://github.com/ultralytics/ultralytics).
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
Despite its manageable size of 210 images, tiger-pose dataset offers diversity, making it suitable for assessing training pipelines, identifying potential errors, and serving as a valuable preliminary step before working with larger datasets for pose estimation.
This dataset is intended for use with [Ultralytics HUB](https://hub.ultralytics.com)
and [YOLOv8](https://github.com/ultralytics/ultralytics).
This dataset is intended for use with [Ultralytics HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
[Ultralytics](https://ultralytics.com) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com)
and [YOLOv8](https://github.com/ultralytics/ultralytics).
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@ -14,31 +14,31 @@ Whether you're a beginner or an expert in deep learning, our tutorials offer val
Here's a compilation of in-depth guides to help you master different aspects of Ultralytics YOLO.
* [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
* [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
* [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
* [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
* [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
* [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
* [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
* [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
* [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
* [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
* [Triton Inference Server Integration](triton-inference-server.md) 🚀 NEW: Dive into the integration of Ultralytics YOLOv8 with NVIDIA's Triton Inference Server for scalable and efficient deep learning inference deployments.
* [YOLO Thread-Safe Inference](yolo-thread-safe-inference.md) 🚀 NEW: Guidelines for performing inference with YOLO models in a thread-safe manner. Learn the importance of thread safety and best practices to prevent race conditions and ensure consistent predictions.
* [Isolating Segmentation Objects](isolating-segmentation-objects.md) 🚀 NEW: Step-by-step recipe and explanation on how to extract and/or isolate objects from images using Ultralytics Segmentation.
- [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
- [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
- [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
- [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
- [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
- [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
- [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
- [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
- [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
- [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
- [Triton Inference Server Integration](triton-inference-server.md) 🚀 NEW: Dive into the integration of Ultralytics YOLOv8 with NVIDIA's Triton Inference Server for scalable and efficient deep learning inference deployments.
- [YOLO Thread-Safe Inference](yolo-thread-safe-inference.md) 🚀 NEW: Guidelines for performing inference with YOLO models in a thread-safe manner. Learn the importance of thread safety and best practices to prevent race conditions and ensure consistent predictions.
- [Isolating Segmentation Objects](isolating-segmentation-objects.md) 🚀 NEW: Step-by-step recipe and explanation on how to extract and/or isolate objects from images using Ultralytics Segmentation.
## Real-World Projects
* [Object Counting](object-counting.md) 🚀 NEW: Explore the process of real-time object counting with Ultralytics YOLOv8 and acquire the knowledge to effectively count objects in a live video stream.
* [Workouts Monitoring](workouts-monitoring.md) 🚀 NEW: Discover the comprehensive approach to monitoring workouts with Ultralytics YOLOv8. Acquire the skills and insights necessary to effectively use YOLOv8 for tracking and analyzing various aspects of fitness routines in real time.
* [Objects Counting in Regions](region-counting.md) 🚀 NEW: Explore counting objects in specific regions with Ultralytics YOLOv8 for precise and efficient object detection in varied areas.
* [Security Alarm System](security-alarm-system.md) 🚀 NEW: Discover the process of creating a security alarm system with Ultralytics YOLOv8. This system triggers alerts upon detecting new objects in the frame. Subsequently, you can customize the code to align with your specific use case.
* [Heatmaps](heatmaps.md) 🚀 NEW: Elevate your understanding of data with our Detection Heatmaps! These intuitive visual tools use vibrant color gradients to vividly illustrate the intensity of data values across a matrix. Essential in computer vision, heatmaps are skillfully designed to highlight areas of interest, providing an immediate, impactful way to interpret spatial information.
* [Instance Segmentation with Object Tracking](instance-segmentation-and-tracking.md) 🚀 NEW: Explore our feature on Object Segmentation in Bounding Boxes Shape, providing a visual representation of precise object boundaries for enhanced understanding and analysis.
* [VisionEye View Objects Mapping](vision-eye.md) 🚀 NEW: This feature aim computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
* [Speed Estimation](speed-estimation.md) 🚀 NEW: Speed estimation in computer vision relies on analyzing object motion through techniques like [object tracking](https://docs.ultralytics.com/modes/track/), crucial for applications like autonomous vehicles and traffic monitoring.
* [Distance Calculation](distance-calculation.md) 🚀 NEW: Distance calculation, which involves measuring the separation between two objects within a defined space, is a crucial aspect. In the context of Ultralytics YOLOv8, the method employed for this involves using the bounding box centroid to determine the distance associated with user-highlighted bounding boxes.
- [Object Counting](object-counting.md) 🚀 NEW: Explore the process of real-time object counting with Ultralytics YOLOv8 and acquire the knowledge to effectively count objects in a live video stream.
- [Workouts Monitoring](workouts-monitoring.md) 🚀 NEW: Discover the comprehensive approach to monitoring workouts with Ultralytics YOLOv8. Acquire the skills and insights necessary to effectively use YOLOv8 for tracking and analyzing various aspects of fitness routines in real time.
- [Objects Counting in Regions](region-counting.md) 🚀 NEW: Explore counting objects in specific regions with Ultralytics YOLOv8 for precise and efficient object detection in varied areas.
- [Security Alarm System](security-alarm-system.md) 🚀 NEW: Discover the process of creating a security alarm system with Ultralytics YOLOv8. This system triggers alerts upon detecting new objects in the frame. Subsequently, you can customize the code to align with your specific use case.
- [Heatmaps](heatmaps.md) 🚀 NEW: Elevate your understanding of data with our Detection Heatmaps! These intuitive visual tools use vibrant color gradients to vividly illustrate the intensity of data values across a matrix. Essential in computer vision, heatmaps are skillfully designed to highlight areas of interest, providing an immediate, impactful way to interpret spatial information.
- [Instance Segmentation with Object Tracking](instance-segmentation-and-tracking.md) 🚀 NEW: Explore our feature on Object Segmentation in Bounding Boxes Shape, providing a visual representation of precise object boundaries for enhanced understanding and analysis.
- [VisionEye View Objects Mapping](vision-eye.md) 🚀 NEW: This feature aim computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
- [Speed Estimation](speed-estimation.md) 🚀 NEW: Speed estimation in computer vision relies on analyzing object motion through techniques like [object tracking](https://docs.ultralytics.com/modes/track/), crucial for applications like autonomous vehicles and traffic monitoring.
- [Distance Calculation](distance-calculation.md) 🚀 NEW: Distance calculation, which involves measuring the separation between two objects within a defined space, is a crucial aspect. In the context of Ultralytics YOLOv8, the method employed for this involves using the bounding box centroid to determine the distance associated with user-highlighted bounding boxes.
@ -17,11 +17,9 @@ You agree that the following terms apply to all of your past, present and future
**Third Party Content/Rights.** If your Contribution includes or is based on any source code, object code, bug fixes, configuration changes, tools, specifications, documentation, data, materials, feedback, information or other works of authorship that were not authored by you (“Third Party Content”) or if you are aware of any third party intellectual property or proprietary rights associated with your Contribution (“Third Party Rights”), then you agree to include with the submission of your Contribution full details respecting such Third Party Content and Third Party Rights, including, without limitation, identification of which aspects of your Contribution contain Third Party Content or are associated with Third Party Rights, the owner/author of the Third Party Content and Third Party Rights, where you obtained the Third Party Content, and any applicable third party license terms or restrictions respecting the Third Party Content and Third Party Rights. For greater certainty, the foregoing obligations respecting the identification of Third Party Content and Third Party Rights do not apply to any portion of a Project that is incorporated into your Contribution to that same Project.
**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer
(s) has waived all of their right, title or interest in or to your Contributions.
**Representations.** You represent that, other than the Third Party Content and Third Party Rights identified by you in accordance with this Agreement, you are the sole author of your Contributions and are legally entitled to grant the foregoing licenses and waivers in respect of your Contributions. If your Contributions were created in the course of your employment with your past or present employer(s), you represent that such employer(s) has authorized you to make your Contributions on behalf of such employer(s) or such employer (s) has waived all of their right, title or interest in or to your Contributions.
**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis"
basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
**Disclaimer.** To the fullest extent permitted under applicable law, your Contributions are provided on an "asis" basis, without any warranties or conditions, express or implied, including, without limitation, any implied warranties or conditions of non-infringement, merchantability or fitness for a particular purpose. You are not required to provide support for your Contributions, except to the extent you desire to provide support.
**No Obligation.** You acknowledge that Ultralytics is under no obligation to use or incorporate your Contributions into any of the Projects. The decision to use or incorporate your Contributions into any of the Projects will be made at the sole discretion of Ultralytics or its authorized delegates.
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 2.0, available at https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct enforcement ladder](https://github.com/mozilla/diversity).
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
For answers to common questions about this code of conduct, see the FAQ at https://www.contributor-covenant.org/faq. Translations are available at https://www.contributor-covenant.org/translations.
The YOLO Inference API allows you to access the YOLOv8 object detection capabilities via a RESTful API. This enables you to run object detection on images without the need to install and set up the YOLOv8 environment locally.
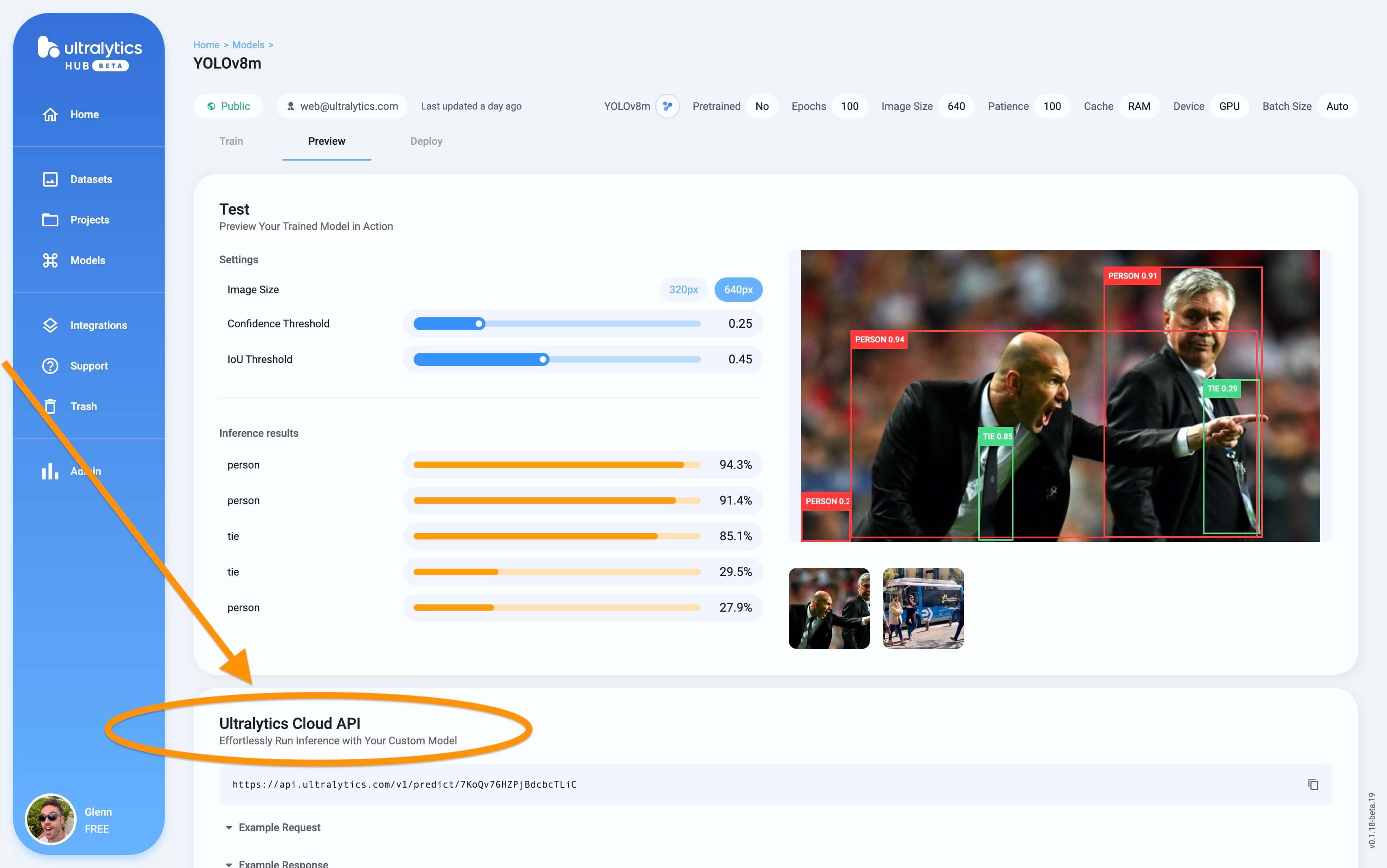
Screenshot of the Inference API section in the trained model Preview tab.
 Screenshot of the Inference API section in the trained model Preview tab.
@ -34,9 +34,9 @@ First, ensure you have the following prerequisites in place:
- Configured IAM Roles: You’ll need an IAM role with the necessary permissions for Amazon SageMaker, AWS CloudFormation, and Amazon S3. This role should have policies that allow it to access these services.
- AWS CLI: If not already installed, download and install the AWS Command Line Interface (CLI) and configure it with your account details. Follow [the AWS CLI instructions](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) for installation.
- AWS CLI: If not already installed, download and install the AWS Command Line Interface (CLI) and configure it with your account details. Follow [the AWS CLI instructions](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) for installation.
- AWS CDK: If not already installed, install the AWS Cloud Development Kit (CDK), which will be used for scripting the deployment. Follow [the AWS CDK instructions](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install) for installation.
- AWS CDK: If not already installed, install the AWS Cloud Development Kit (CDK), which will be used for scripting the deployment. Follow [the AWS CDK instructions](https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html#getting_started_install) for installation.
- Adequate Service Quota: Confirm that you have sufficient quotas for two separate resources in Amazon SageMaker: one for ml.m5.4xlarge for endpoint usage and another for ml.m5.4xlarge for notebook instance usage. Each of these requires a minimum of one quota value. If your current quotas are below this requirement, it's important to request an increase for each. You can request a quota increase by following the detailed instructions in the [AWS Service Quotas documentation](https://docs.aws.amazon.com/servicequotas/latest/userguide/request-quota-increase.html#quota-console-increase).
Or use the `project=<project>` argument when training a YOLO model, i.e. `yolo train project=my_project`.
2. **Set a Run Name**: Similar to setting a project name, you can set the run name via an environment variable:
```bash
export MLFLOW_RUN=<your_run_name>
```
Or use the `name=<name>` argument when training a YOLO model, i.e. `yolo train project=my_project name=my_name`.
3. **Start Local MLflow Server**: To start tracking, use:
```bash
mlflow server --backend-store-uri runs/mlflow'
```
This will start a local server at http://127.0.0.1:5000 by default and save all mlflow logs to the 'runs/mlflow' directory. To specify a different URI, set the `MLFLOW_TRACKING_URI` environment variable.
4. **Kill MLflow Server Instances**: To stop all running MLflow instances, run:
@ -93,11 +100,9 @@ The logging is taken care of by the `on_pretrain_routine_end`, `on_fit_epoch_end
1. **Logging Custom Metrics**: You can add custom metrics to be logged by modifying the `trainer.metrics` dictionary before `on_fit_epoch_end` is called.
2. **View Experiment**: To view your logs, navigate to your MLflow server (usually http://127.0.0.1:5000) and select your experiment and run.
2. **View Experiment**: To view your logs, navigate to your MLflow server (usually http://127.0.0.1:5000) and select your experiment and run. <imgwidth="1024"src="https://user-images.githubusercontent.com/26833433/274933329-3127aa8c-4491-48ea-81df-ed09a5837f2a.png"alt="YOLO MLflow Experiment">
3. **View Run**: Runs are individual models inside an experiment. Click on a Run and see the Run details, including uploaded artifacts and model weights.
3. **View Run**: Runs are individual models inside an experiment. Click on a Run and see the Run details, including uploaded artifacts and model weights. <imgwidth="1024"src="https://user-images.githubusercontent.com/26833433/274933337-ac61371c-2867-4099-a733-147a2583b3de.png"alt="YOLO MLflow Run">
@ -37,7 +37,6 @@ Universe is an online repository with over 250,000 vision datasets totalling ove
With a [free Roboflow account](https://app.roboflow.com/?ref=ultralytics), you can export any dataset available on Universe. To export a dataset, click the "Download this Dataset" button on any dataset.
@ -126,7 +126,7 @@ After running the usage code snippet, you can access the Weights & Biases (W&B)
- **Real-Time Metrics Tracking**: Observe metrics like loss, accuracy, and validation scores as they evolve during the training, offering immediate insights for model tuning.
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/TB76U9O"><ahref="//imgur.com/D6NVnmN">Take a look at how the experiments are tracked using Weights & Biases.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/TB76U9O"><ahref="//imgur.com/D6NVnmN">Take a look at how the experiments are tracked using Weights & Biases.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
- **Hyperparameter Optimization**: Weights & Biases aids in fine-tuning critical parameters such as learning rate, batch size, and more, enhancing the performance of YOLOv8.
@ -134,7 +134,7 @@ After running the usage code snippet, you can access the Weights & Biases (W&B)
- **Visualization of Training Progress**: Graphical representations of key metrics provide an intuitive understanding of the model's performance across epochs.
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/kU5h7W4"data-context="false"><ahref="//imgur.com/a/kU5h7W4">Take a look at how Weights & Biases helps you visualize validation results.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/kU5h7W4"data-context="false"><ahref="//imgur.com/a/kU5h7W4">Take a look at how Weights & Biases helps you visualize validation results.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
- **Resource Monitoring**: Keep track of CPU, GPU, and memory usage to optimize the efficiency of the training process.
@ -142,7 +142,7 @@ After running the usage code snippet, you can access the Weights & Biases (W&B)
- **Viewing Inference Results with Image Overlay**: Visualize the prediction results on images using interactive overlays in Weights & Biases, providing a clear and detailed view of model performance on real-world data. For more detailed information on Weights & Biases’ image overlay capabilities, check out this [link](https://docs.wandb.ai/guides/track/log/media#image-overlays).
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/UTSiufs"data-context="false"><ahref="//imgur.com/a/UTSiufs">Take a look at how Weights & Biases’ image overlays helps visualize model inferences.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
<divstyle="text-align:center;"><blockquoteclass="imgur-embed-pub"lang="en"data-id="a/UTSiufs"data-context="false"><ahref="//imgur.com/a/UTSiufs">Take a look at how Weights & Biases’ image overlays helps visualize model inferences.</a></blockquote></div><scriptasyncsrc="//s.imgur.com/min/embed.js"charset="utf-8"></script>
By using these features, you can effectively track, analyze, and optimize your YOLOv8 model's training, ensuring the best possible performance and efficiency.
@ -37,7 +37,7 @@ Here are some of the key models supported:
## Getting Started: Usage Examples
This example provides simple YOLO training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple YOLO training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for object detection. For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md) and [Pose](../tasks/pose.md) docs.
Real-Time Detection Transformer (RT-DETR), developed by Baidu, is a cutting-edge end-to-end object detector that provides real-time performance while maintaining high accuracy. It leverages the power of Vision Transformers (ViT) to efficiently process multiscale features by decoupling intra-scale interaction and cross-scale fusion. RT-DETR is highly adaptable, supporting flexible adjustment of inference speed using different decoder layers without retraining. The model excels on accelerated backends like CUDA with TensorRT, outperforming many other real-time object detectors.

**Overview of Baidu's RT-DETR.** The RT-DETR model architecture diagram shows the last three stages of the backbone {S3, S4, S5} as the input to the encoder. The efficient hybrid encoder transforms multiscale features into a sequence of image features through intrascale feature interaction (AIFI) and cross-scale feature-fusion module (CCFM). The IoU-aware query selection is employed to select a fixed number of image features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores ([source](https://arxiv.org/pdf/2304.08069.pdf)).
 **Overview of Baidu's RT-DETR.** The RT-DETR model architecture diagram shows the last three stages of the backbone {S3, S4, S5} as the input to the encoder. The efficient hybrid encoder transforms multiscale features into a sequence of image features through intrascale feature interaction (AIFI) and cross-scale feature-fusion module (CCFM). The IoU-aware query selection is employed to select a fixed number of image features to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores ([source](https://arxiv.org/pdf/2304.08069.pdf)).
### Key Features
@ -28,7 +27,7 @@ The Ultralytics Python API provides pre-trained PaddlePaddle RT-DETR models with
## Usage Examples
This example provides simple RT-DETRR training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple RT-DETRR training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
@ -14,8 +14,7 @@ The Segment Anything Model, or SAM, is a cutting-edge image segmentation model t
SAM's advanced design allows it to adapt to new image distributions and tasks without prior knowledge, a feature known as zero-shot transfer. Trained on the expansive [SA-1B dataset](https://ai.facebook.com/datasets/segment-anything/), which contains more than 1 billion masks spread over 11 million carefully curated images, SAM has displayed impressive zero-shot performance, surpassing previous fully supervised results in many cases.
Example images with overlaid masks from our newly introduced dataset, SA-1B. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
 **SA-1B Example images.** Dataset images overlaid masks from the newly introduced SA-1B dataset. SA-1B contains 11M diverse, high-resolution, licensed, and privacy protecting images and 1.1B high-quality segmentation masks. These masks were annotated fully automatically by SAM, and as verified by human ratings and numerous experiments, are of high quality and diversity. Images are grouped by number of masks per image for visualization (there are ∼100 masks per image on average).
## Key Features of the Segment Anything Model (SAM)
@ -10,8 +10,7 @@ keywords: YOLO-NAS, Deci AI, object detection, deep learning, neural architectur
Developed by Deci AI, YOLO-NAS is a groundbreaking object detection foundational model. It is the product of advanced Neural Architecture Search technology, meticulously designed to address the limitations of previous YOLO models. With significant improvements in quantization support and accuracy-latency trade-offs, YOLO-NAS represents a major leap in object detection.

**Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
 **Overview of YOLO-NAS.** YOLO-NAS employs quantization-aware blocks and selective quantization for optimal performance. The model, when converted to its INT8 quantized version, experiences a minimal precision drop, a significant improvement over other models. These advancements culminate in a superior architecture with unprecedented object detection capabilities and outstanding performance.
@ -42,7 +42,7 @@ This table provides an at-a-glance view of the capabilities of each YOLOv3 varia
## Usage Examples
This example provides simple YOLOv3 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple YOLOv3 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
Welcome to the Ultralytics documentation page for YOLOv4, a state-of-the-art, real-time object detector launched in 2020 by Alexey Bochkovskiy at [https://github.com/AlexeyAB/darknet](https://github.com/AlexeyAB/darknet). YOLOv4 is designed to provide the optimal balance between speed and accuracy, making it an excellent choice for many applications.
**YOLOv4 architecture diagram**. Showcasing the intricate network design of YOLOv4, including the backbone, neck, and head components, and their interconnected layers for optimal real-time object detection.
 **YOLOv4 architecture diagram**. Showcasing the intricate network design of YOLOv4, including the backbone, neck, and head components, and their interconnected layers for optimal real-time object detection.
@ -54,7 +54,7 @@ This table provides a detailed overview of the YOLOv5u model variants, highlight
## Usage Examples
This example provides simple YOLOv5 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple YOLOv5 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
[Meituan](https://about.meituan.com/) YOLOv6 is a cutting-edge object detector that offers remarkable balance between speed and accuracy, making it a popular choice for real-time applications. This model introduces several notable enhancements on its architecture and training scheme, including the implementation of a Bi-directional Concatenation (BiC) module, an anchor-aided training (AAT) strategy, and an improved backbone and neck design for state-of-the-art accuracy on the COCO dataset.

**Overview of YOLOv6.** Model architecture diagram showing the redesigned network components and training strategies that have led to significant performance improvements. (a) The neck of YOLOv6 (N and S are shown). Note for M/L, RepBlocks is replaced with CSPStackRep. (b) The structure of a BiC module. (c) A SimCSPSPPF block. ([source](https://arxiv.org/pdf/2301.05586.pdf)).
 **Overview of YOLOv6.** Model architecture diagram showing the redesigned network components and training strategies that have led to significant performance improvements. (a) The neck of YOLOv6 (N and S are shown). Note for M/L, RepBlocks is replaced with CSPStackRep. (b) The structure of a BiC module. (c) A SimCSPSPPF block. ([source](https://arxiv.org/pdf/2301.05586.pdf)).
### Key Features
@ -35,7 +34,7 @@ YOLOv6 also provides quantized models for different precisions and models optimi
## Usage Examples
This example provides simple YOLOv6 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple YOLOv6 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
@ -8,8 +8,8 @@ keywords: YOLOv7, real-time object detector, state-of-the-art, Ultralytics, MS C
YOLOv7 is a state-of-the-art real-time object detector that surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS. It has the highest accuracy (56.8% AP) among all known real-time object detectors with 30 FPS or higher on GPU V100. Moreover, YOLOv7 outperforms other object detectors such as YOLOR, YOLOX, Scaled-YOLOv4, YOLOv5, and many others in speed and accuracy. The model is trained on the MS COCO dataset from scratch without using any other datasets or pre-trained weights. Source code for YOLOv7 is available on GitHub.

**Comparison of state-of-the-art object detectors.** From the results in Table 2 we know that the proposed method has the best speed-accuracy trade-off comprehensively. If we compare YOLOv7-tiny-SiLU with YOLOv5-N (r6.1), our method is 127 fps faster and 10.7% more accurate on AP. In addition, YOLOv7 has 51.4% AP at frame rate of 161 fps, while PPYOLOE-L with the same AP has only 78 fps frame rate. In terms of parameter usage, YOLOv7 is 41% less than PPYOLOE-L. If we compare YOLOv7-X with 114 fps inference speed to YOLOv5-L (r6.1) with 99 fps inference speed, YOLOv7-X can improve AP by 3.9%. If YOLOv7-X is compared with YOLOv5-X (r6.1) of similar scale, the inference speed of YOLOv7-X is 31 fps faster. In addition, in terms the amount of parameters and computation, YOLOv7-X reduces 22% of parameters and 8% of computation compared to YOLOv5-X (r6.1), but improves AP by 2.2% ([Source](https://arxiv.org/pdf/2207.02696.pdf)).
 **Comparison of state-of-the-art object detectors.
** From the results in Table 2 we know that the proposed method has the best speed-accuracy trade-off comprehensively. If we compare YOLOv7-tiny-SiLU with YOLOv5-N (r6.1), our method is 127 fps faster and 10.7% more accurate on AP. In addition, YOLOv7 has 51.4% AP at frame rate of 161 fps, while PPYOLOE-L with the same AP has only 78 fps frame rate. In terms of parameter usage, YOLOv7 is 41% less than PPYOLOE-L. If we compare YOLOv7-X with 114 fps inference speed to YOLOv5-L (r6.1) with 99 fps inference speed, YOLOv7-X can improve AP by 3.9%. If YOLOv7-X is compared with YOLOv5-X (r6.1) of similar scale, the inference speed of YOLOv7-X is 31 fps faster. In addition, in terms the amount of parameters and computation, YOLOv7-X reduces 22% of parameters and 8% of computation compared to YOLOv5-X (r6.1), but improves AP by 2.2% ([Source](https://arxiv.org/pdf/2207.02696.pdf)).
@ -125,7 +125,7 @@ This table provides an overview of the YOLOv8 model variants, highlighting their
## Usage Examples
This example provides simple YOLOv8 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
This example provides simple YOLOv8 training and inference examples. For full documentation on these and other [modes](../modes/index.md) see the [Predict](../modes/predict.md), [Train](../modes/train.md), [Val](../modes/val.md) and [Export](../modes/export.md) docs pages.
Note the below example is for YOLOv8 [Detect](../tasks/detect.md) models for object detection. For additional supported tasks see the [Segment](../tasks/segment.md), [Classify](../tasks/classify.md), [Obb](../tasks/obb.md) docs and [Pose](../tasks/pose.md) docs.
@ -68,7 +68,6 @@ Track mode is used for tracking objects in real-time using a YOLOv8 model. In th
## [Benchmark](benchmark.md)
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose)
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection, segmentation and pose) or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
@ -722,7 +722,5 @@ Here's a Python script using OpenCV (`cv2`) and YOLOv8 to run inference on video
This script will run predictions on each frame of the video, visualize the results, and display them in a window. The loop can be exited by pressing 'q'.
@ -49,8 +49,8 @@ Ultralytics YOLO extends its object detection features to provide robust and ver
Ultralytics YOLO supports the following tracking algorithms. They can be enabled by passing the relevant YAML configuration file such as `tracker=tracker_type.yaml`:
* [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - Use `botsort.yaml` to enable this tracker.
* [ByteTrack](https://github.com/ifzhang/ByteTrack) - Use `bytetrack.yaml` to enable this tracker.
- [BoT-SORT](https://github.com/NirAharon/BoT-SORT) - Use `botsort.yaml` to enable this tracker.
- [ByteTrack](https://github.com/ifzhang/ByteTrack) - Use `bytetrack.yaml` to enable this tracker.
The default tracker is BoT-SORT.
@ -353,6 +353,9 @@ To initiate your contribution, please refer to our [Contributing Guide](https://
Together, let's enhance the tracking capabilities of the Ultralytics YOLO ecosystem 🙏!
- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set.
<br>Reproduce by `yolo val classify data=path/to/ImageNet device=0`
- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
instance.
<br>Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
- **acc** values are model accuracies on the [ImageNet](https://www.image-net.org/) dataset validation set. <br>Reproduce by `yolo val classify data=path/to/ImageNet device=0`
- **Speed** averaged over ImageNet val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val classify data=path/to/ImageNet batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.
<br>Reproduce by `yolo val detect data=coco.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
instance.
<br>Reproduce by `yolo val detect data=coco128.yaml batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset. <br>Reproduce by `yolo val detect data=coco.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val detect data=coco128.yaml batch=1 device=0|cpu`
@ -12,10 +12,8 @@ Oriented object detection goes a step further than object detection and introduc
The output of an oriented object detector is a set of rotated bounding boxes that exactly enclose the objects in the image, along with class labels and confidence scores for each box. Object detection is a good choice when you need to identify objects of interest in a scene, but don't need to know exactly where the object is or its exact shape.
<!-- youtube video link for obb task -->
!!! Tip "Tip"
YOLOv8 Obb models use the `-obb` suffix, i.e. `yolov8n-obb.pt` and are pretrained on [DOTAv1](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/DOTAv1.yaml).
@ -36,15 +34,13 @@ YOLOv8 pretrained Obb models are shown here, which are pretrained on the [DOTAv1
<!-- TODO: should we report multi-scale results only as they're better or both multi-scale and single-scale. -->
- **mAP<sup>val</sup>** values are for single-model single-scale on [DOTAv1 test](http://cocodataset.org) dataset.
<br>Reproduce by `yolo val obb data=DOTAv1.yaml device=0`
- **Speed** averaged over DOTAv1 val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
instance.
<br>Reproduce by `yolo val obb data=DOTAv1.yaml batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [DOTAv1 test](http://cocodataset.org) dataset. <br>Reproduce by `yolo val obb data=DOTAv1.yaml device=0`
- **Speed** averaged over DOTAv1 val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val obb data=DOTAv1.yaml batch=1 device=0|cpu`
## Train
<!-- TODO: probably we should create a sample dataset like coco128.yaml, named dota128.yaml? -->
Train YOLOv8n-obb on the dota128.yaml dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
Pose estimation is a task that involves identifying the location of specific points in an image, usually referred to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]`
coordinates.
Pose estimation is a task that involves identifying the location of specific points in an image, usually referred to as keypoints. The keypoints can represent various parts of the object such as joints, landmarks, or other distinctive features. The locations of the keypoints are usually represented as a set of 2D `[x, y]` or 3D `[x, y, visible]` coordinates.
The output of a pose estimation model is a set of points that represent the keypoints on an object in the image, usually along with the confidence scores for each point. Pose estimation is a good choice when you need to identify specific parts of an object in a scene, and their location in relation to each other.
@ -43,12 +42,8 @@ YOLOv8 pretrained Pose models are shown here. Detect, Segment and Pose models ar
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO Keypoints val2017](http://cocodataset.org)
dataset.
<br>Reproduce by `yolo val pose data=coco-pose.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
instance.
<br>Reproduce by `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO Keypoints val2017](http://cocodataset.org) dataset. <br>Reproduce by `yolo val pose data=coco-pose.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val pose data=coco8-pose.yaml batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.
<br>Reproduce by `yolo val segment data=coco.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/)
instance.
<br>Reproduce by `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset. <br>Reproduce by `yolo val segment data=coco.yaml device=0`
- **Speed** averaged over COCO val images using an [Amazon EC2 P4d](https://aws.amazon.com/ec2/instance-types/p4/) instance. <br>Reproduce by `yolo val segment data=coco128-seg.yaml batch=1 device=0|cpu`
@ -51,10 +51,10 @@ Default `ARG` values are defined on this page from the `cfg/defaults.yaml` [file
YOLO models can be used for a variety of tasks, including detection, segmentation, classification and pose. These tasks differ in the type of output they produce and the specific problem they are designed to solve.
**Detect**: For identifying and localizing objects or regions of interest in an image or video.
**Segment**: For dividing an image or video into regions or pixels that correspond to different objects or classes.
**Classify**: For predicting the class label of an input image.
**Pose**: For identifying objects and estimating their keypoints in an image or video.
- **Detect**: For identifying and localizing objects or regions of interest in an image or video.
- **Segment**: For dividing an image or video into regions or pixels that correspond to different objects or classes.
- **Classify**: For predicting the class label of an input image.
- **Pose**: For identifying objects and estimating their keypoints in an image or video.
@ -21,8 +21,8 @@ Both the Ultralytics YOLO command-line and Python interfaces are simply a high-l
BaseTrainer contains the generic boilerplate training routine. It can be customized for any task based over overriding the required functions or operations as long the as correct formats are followed. For example, you can support your own custom model and dataloader by just overriding these functions:
*`get_model(cfg, weights)` - The function that builds the model to be trained
*`get_dataloader()` - The function that builds the dataloader More details and source code can be found in [`BaseTrainer` Reference](../reference/engine/trainer.md)
-`get_model(cfg, weights)` - The function that builds the model to be trained
-`get_dataloader()` - The function that builds the dataloader More details and source code can be found in [`BaseTrainer` Reference](../reference/engine/trainer.md)
## DetectionTrainer
@ -55,9 +55,8 @@ trainer.train()
You now realize that you need to customize the trainer further to:
* Customize the `loss function`.
* Add `callback` that uploads model to your Google Drive after every 10 `epochs`
Here's how you can do it:
- Customize the `loss function`.
- Add `callback` that uploads model to your Google Drive after every 10 `epochs` Here's how you can do it:
```python
from ultralytics.models.yolo.detect import DetectionTrainer
@ -89,5 +88,4 @@ To know more about Callback triggering events and entry point, checkout our [Cal
## Other engine components
There are other components that can be customized similarly like `Validators` and `Predictors`
See Reference section for more information on these.
There are other components that can be customized similarly like `Validators` and `Predictors`. See Reference section for more information on these.
@ -224,8 +224,7 @@ Track mode is used for tracking objects in real-time using a YOLOv8 model. In th
## [Benchmark](../modes/benchmark.md)
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation)
or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
Benchmark mode is used to profile the speed and accuracy of various export formats for YOLOv8. The benchmarks provide information on the size of the exported format, its `mAP50-95` metrics (for object detection and segmentation) or `accuracy_top5` metrics (for classification), and the inference time in milliseconds per image across various export formats like ONNX, OpenVINO, TensorRT and others. This information can help users choose the optimal export format for their specific use case based on their requirements for speed and accuracy.
Note that if you want to run these commands from a Notebook, you need to [create a new Kernel](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-access-terminal?view=azureml-api-2#add-new-kernels)
and select your new Kernel on the top of your Notebook.
Note that if you want to run these commands from a Notebook, you need to [create a new Kernel](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-access-terminal?view=azureml-api-2#add-new-kernels) and select your new Kernel on the top of your Notebook.
If you create Python cells it will automatically use your custom environment, but if you add bash cells, you will need to run `source activate <your-env>` on each of these cells to make sure it uses your custom environment.
Welcome to the Ultralytics' <ahref="https://github.com/ultralytics/yolov5">YOLOv5</a>🚀 Documentation! YOLOv5, the fifth iteration of the revolutionary "You Only Look Once" object detection model, is designed to deliver high-speed, high-accuracy results in real-time.
<br><br>
Built on PyTorch, this powerful deep learning framework has garnered immense popularity for its versatility, ease of use, and high performance. Our documentation guides you through the installation process, explains the architectural nuances of the model, showcases various use-cases, and provides a series of detailed tutorials. These resources will help you harness the full potential of YOLOv5 for your computer vision projects. Let's get started!
</div>
@ -32,22 +34,22 @@ Built on PyTorch, this powerful deep learning framework has garnered immense pop
Here's a compilation of comprehensive tutorials that will guide you through different aspects of YOLOv5.
* [Train Custom Data](tutorials/train_custom_data.md) 🚀 RECOMMENDED: Learn how to train the YOLOv5 model on your custom dataset.
* [Tips for Best Training Results](tutorials/tips_for_best_training_results.md) ☘️: Uncover practical tips to optimize your model training process.
* [Multi-GPU Training](tutorials/multi_gpu_training.md): Understand how to leverage multiple GPUs to expedite your training.
* [PyTorch Hub](tutorials/pytorch_hub_model_loading.md) 🌟 NEW: Learn to load pre-trained models via PyTorch Hub.
* [TFLite, ONNX, CoreML, TensorRT Export](tutorials/model_export.md) 🚀: Understand how to export your model to different formats.
* [NVIDIA Jetson platform Deployment](tutorials/running_on_jetson_nano.md) 🌟 NEW: Learn how to deploy your YOLOv5 model on NVIDIA Jetson platform.
* [Test-Time Augmentation (TTA)](tutorials/test_time_augmentation.md): Explore how to use TTA to improve your model's prediction accuracy.
* [Model Ensembling](tutorials/model_ensembling.md): Learn the strategy of combining multiple models for improved performance.
* [Model Pruning/Sparsity](tutorials/model_pruning_and_sparsity.md): Understand pruning and sparsity concepts, and how to create a more efficient model.
* [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md): Discover the process of automated hyperparameter tuning for better model performance.
* [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md): Learn how to implement transfer learning by freezing layers in YOLOv5.
* [Architecture Summary](tutorials/architecture_description.md) 🌟 Delve into the structural details of the YOLOv5 model.
* [Roboflow for Datasets](tutorials/roboflow_datasets_integration.md): Understand how to utilize Roboflow for dataset management, labeling, and active learning.
* [ClearML Logging](tutorials/clearml_logging_integration.md) 🌟 Learn how to integrate ClearML for efficient logging during your model training.
* [YOLOv5 with Neural Magic](tutorials/neural_magic_pruning_quantization.md) Discover how to use Neural Magic's Deepsparse to prune and quantize your YOLOv5 model.
* [Comet Logging](tutorials/comet_logging_integration.md) 🌟 NEW: Explore how to utilize Comet for improved model training logging.
- [Train Custom Data](tutorials/train_custom_data.md) 🚀 RECOMMENDED: Learn how to train the YOLOv5 model on your custom dataset.
- [Tips for Best Training Results](tutorials/tips_for_best_training_results.md) ☘️: Uncover practical tips to optimize your model training process.
- [Multi-GPU Training](tutorials/multi_gpu_training.md): Understand how to leverage multiple GPUs to expedite your training.
- [PyTorch Hub](tutorials/pytorch_hub_model_loading.md) 🌟 NEW: Learn to load pre-trained models via PyTorch Hub.
- [TFLite, ONNX, CoreML, TensorRT Export](tutorials/model_export.md) 🚀: Understand how to export your model to different formats.
- [NVIDIA Jetson platform Deployment](tutorials/running_on_jetson_nano.md) 🌟 NEW: Learn how to deploy your YOLOv5 model on NVIDIA Jetson platform.
- [Test-Time Augmentation (TTA)](tutorials/test_time_augmentation.md): Explore how to use TTA to improve your model's prediction accuracy.
- [Model Ensembling](tutorials/model_ensembling.md): Learn the strategy of combining multiple models for improved performance.
- [Model Pruning/Sparsity](tutorials/model_pruning_and_sparsity.md): Understand pruning and sparsity concepts, and how to create a more efficient model.
- [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md): Discover the process of automated hyperparameter tuning for better model performance.
- [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md): Learn how to implement transfer learning by freezing layers in YOLOv5.
- [Architecture Summary](tutorials/architecture_description.md) 🌟 Delve into the structural details of the YOLOv5 model.
- [Roboflow for Datasets](tutorials/roboflow_datasets_integration.md): Understand how to utilize Roboflow for dataset management, labeling, and active learning.
- [ClearML Logging](tutorials/clearml_logging_integration.md) 🌟 Learn how to integrate ClearML for efficient logging during your model training.
- [YOLOv5 with Neural Magic](tutorials/neural_magic_pruning_quantization.md) Discover how to use Neural Magic's Deepsparse to prune and quantize your YOLOv5 model.
- [Comet Logging](tutorials/comet_logging_integration.md) 🌟 NEW: Explore how to utilize Comet for improved model training logging.
@ -40,15 +40,15 @@ Either sign up for free to the [ClearML Hosted Service](https://cutt.ly/yolov5-t
- Install the `clearml` python package:
```bash
pip install clearml
```
```bash
pip install clearml
```
- Connect the ClearML SDK to the server by [creating credentials](https://app.clear.ml/settings/workspace-configuration) (go right top to Settings -> Workspace -> Create new credentials), then execute the command below and follow the instructions:
@ -14,8 +14,7 @@ This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readm
Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)!
Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
## Getting Started
@ -180,14 +179,11 @@ python train.py \
--upload_dataset
```
You can find the uploaded dataset in the Artifacts tab in your Comet Workspace
You can find the uploaded dataset in the Artifacts tab in your Comet Workspace <imgwidth="1073"alt="artifact-1"src="https://user-images.githubusercontent.com/7529846/186929193-162718bf-ec7b-4eb9-8c3b-86b3763ef8ea.png">
You can preview the data directly in the Comet UI.
You can preview the data directly in the Comet UI. <imgwidth="1082"alt="artifact-2"src="https://user-images.githubusercontent.com/7529846/186929215-432c36a9-c109-4eb0-944b-84c2786590d6.png">
Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file <imgwidth="963"alt="artifact-3"src="https://user-images.githubusercontent.com/7529846/186929256-9d44d6eb-1a19-42de-889a-bcbca3018f2e.png">
### Using a saved Artifact
@ -209,8 +205,7 @@ python train.py \
--weights yolov5s.pt
```
Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset.
Artifacts also allow you to track the lineage of data as it flows through your Experimentation workflow. Here you can see a graph that shows you all the experiments that have used your uploaded dataset. <imgwidth="1391"alt="artifact-4"src="https://user-images.githubusercontent.com/7529846/186929264-4c4014fa-fe51-4f3c-a5c5-f6d24649b1b4.png">
📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
[Netron Viewer](https://github.com/lutzroeder/netron) is recommended for visualizing exported models:
<palign="center"><imgwidth="850"src="https://user-images.githubusercontent.com/26833433/191003260-f94011a7-5b2e-4fe3-93c1-e1a935e0a728.png"alt="YOLO model visualization"></p>
@ -59,15 +59,14 @@ Once you have collected images, you will need to annotate the objects of interes
Whether you [label your images with Roboflow](https://roboflow.com/annotate?ref=ultralytics) or not, you can use it to convert your dataset into YOLO format, create a YOLOv5 YAML configuration file, and host it for importing into your training script.
[Create a free Roboflow account](https://app.roboflow.com/?model=yolov5&ref=ultralytics)
and upload your dataset to a `Public` workspace, label any unannotated images, then generate and export a version of your dataset in `YOLOv5 Pytorch` format.
[Create a free Roboflow account](https://app.roboflow.com/?model=yolov5&ref=ultralytics) and upload your dataset to a `Public` workspace, label any unannotated images, then generate and export a version of your dataset in `YOLOv5 Pytorch` format.
Note: YOLOv5 does online augmentation during training, so we do not recommend applying any augmentation steps in Roboflow for training with YOLOv5. But we recommend applying the following preprocessing steps:
***Auto-Orient** - to strip EXIF orientation from your images.
***Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).
-**Auto-Orient** - to strip EXIF orientation from your images.
-**Resize (Stretch)** - to the square input size of your model (640x640 is the YOLOv5 default).
Generating a version will give you a point in time snapshot of your dataset so you can always go back and compare your future model training runs against it, even if you add more images or change its configuration later.
@ -78,6 +77,7 @@ Export in `YOLOv5 Pytorch` format, then copy the snippet into your training scri
To learn more about all the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://bit.ly/yolov5-colab-comet-docs). Get started by trying out the Comet Colab Notebook:
[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
To learn more about all the supported Comet features for this integration, check out the [Comet Tutorial](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration). If you'd like to learn more about Comet, head over to our [documentation](https://bit.ly/yolov5-colab-comet-docs). Get started by trying out the Comet Colab Notebook: [](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
@ -211,11 +210,11 @@ plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
Once your model is trained you can use your best checkpoint `best.pt` to:
* Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference on new images and videos
* [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
* [Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
* [Evolve](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution) hyperparameters to improve performance
* [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
- Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference on new images and videos
- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
- [Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
- [Evolve](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution) hyperparameters to improve performance
- [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
@ -24,11 +24,11 @@ This repository features a collection of real-world applications and walkthrough
We greatly appreciate contributions from the community, including examples, applications, and guides. If you'd like to contribute, please follow these guidelines:
1. Create a pull request (PR) with the title prefix `[Example]`, adding your new example folder to the `examples/` directory within the repository.
1. Make sure your project adheres to the following standards:
- Makes use of the `ultralytics` package.
- Includes a `README.md` with clear instructions for setting up and running the example.
- Refrains from adding large files or dependencies unless they are absolutely necessary for the example.
- Contributors should be willing to provide support for their examples and address related issues.
2. Make sure your project adheres to the following standards:
- Makes use of the `ultralytics` package.
- Includes a `README.md` with clear instructions for setting up and running the example.
- Refrains from adding large files or dependencies unless they are absolutely necessary for the example.
- Contributors should be willing to provide support for their examples and address related issues.
For more detailed information and guidance on contributing, please visit our [contribution documentation](https://docs.ultralytics.com/help/contributing).
This example demonstrates how to perform inference using YOLOv8 in C++ with ONNX Runtime and OpenCV's API.
@ -15,7 +13,7 @@ This example demonstrates how to perform inference using YOLOv8 in C++ with ONNX
## Note :coffee:
1.~~This repository should also work for YOLOv5, which needs a permute operator for the output of the YOLOv5 model, but this has not been implemented yet.~~ Benefit for ultralytics's latest release,a `Transpose` op is added to the Yolov8 model,while make v8 and v5 has the same output shape.Therefore,you can inference your yolov5/v7/v8 via this project.
1. Benefit for Ultralytics' latest release, a `Transpose` op is added to the YOLOv8 model, while make v8 and v5 has the same output shape. Therefore, you can run inference with YOLOv5/v7/v8 via this project.
## Exporting YOLOv8 Models 📦
@ -70,24 +68,26 @@ Note (2): Due to ONNX Runtime, we need to use CUDA 11 and cuDNN 8. Keep in mind
## Build 🛠️
1. Clone the repository to your local machine.
1. Navigate to the root directory of the repository.
1. Create a build directory and navigate to it:
```console
mkdir build && cd build
```
2. Navigate to the root directory of the repository.
3. Create a build directory and navigate to it:
```console
mkdir build && cd build
```
4. Run CMake to generate the build files:
```console
cmake ..
```
```console
cmake ..
```
5. Build the project:
```console
make
```
```console
make
```
6. The built executable should now be located in the `build` directory.