commit
9ef317fbf3
87 changed files with 952 additions and 254 deletions
@ -0,0 +1,120 @@ |
||||
--- |
||||
comments: true |
||||
description: Uncover how to improve your Ultralytics YOLOv8 model's performance using the NCNN export format that is suitable for devices with limited computation resources. |
||||
keywords: Ultralytics, YOLOv8, NCNN Export, Export YOLOv8, Model Deployment |
||||
--- |
||||
|
||||
# How to Export to NCNN from YOLOv8 for Smooth Deployment |
||||
|
||||
Deploying computer vision models on devices with limited computational power, such as mobile or embedded systems, can be tricky. You need to make sure you use a format optimized for optimal performance. This makes sure that even devices with limited processing power can handle advanced computer vision tasks well. |
||||
|
||||
The export to NCNN format feature allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for lightweight device-based applications. In this guide, we'll walk you through how to convert your models to the NCNN format, making it easier for your models to perform well on various mobile and embedded devices. |
||||
|
||||
## Why should you export to NCNN? |
||||
|
||||
<p align="center"> |
||||
<img width="100%" src="https://repository-images.githubusercontent.com/494294418/207a2e12-dc16-41a6-a39e-eae26e662638" alt="NCNN overview"> |
||||
</p> |
||||
|
||||
The [NCNN](https://github.com/Tencent/ncnn) framework, developed by Tencent, is a high-performance neural network inference computing framework optimized specifically for mobile platforms, including mobile phones, embedded devices, and IoT devices. NCNN is compatible with a wide range of platforms, including Linux, Android, iOS, and macOS. |
||||
|
||||
NCNN is known for its fast processing speed on mobile CPUs and enables rapid deployment of deep learning models to mobile platforms. This makes it easier to build smart apps, putting the power of AI right at your fingertips. |
||||
|
||||
## Key Features of NCNN Models |
||||
|
||||
NCNN models offer a wide range of key features that enable on-device machine learning by helping developers run their models on mobile, embedded, and edge devices: |
||||
|
||||
- **Efficient and High-Performance**: NCNN models are made to be efficient and lightweight, optimized for running on mobile and embedded devices like Raspberry Pi with limited resources. They can also achieve high performance with high accuracy on various computer vision-based tasks. |
||||
|
||||
- **Quantization**: NCNN models often support quantization which is a technique that reduces the precision of the model's weights and activations. This leads to further improvements in performance and reduces memory footprint. |
||||
|
||||
- **Compatibility**: NCNN models are compatible with popular deep learning frameworks like [TensorFlow](https://www.tensorflow.org/), [Caffe](https://caffe.berkeleyvision.org/), and [ONNX](https://onnx.ai/). This compatibility allows developers to use existing models and workflows easily. |
||||
|
||||
- **Easy to Use**: NCNN models are designed for easy integration into various applications, thanks to their compatibility with popular deep learning frameworks. Additionally, NCNN offers user-friendly tools for converting models between different formats, ensuring smooth interoperability across the development landscape. |
||||
|
||||
## Deployment Options with NCNN |
||||
|
||||
Before we look at the code for exporting YOLOv8 models to the NCNN format, let’s understand how NCNN models are normally used. |
||||
|
||||
NCNN models, designed for efficiency and performance, are compatible with a variety of deployment platforms: |
||||
|
||||
- **Mobile Deployment**: Specifically optimized for Android and iOS, allowing for seamless integration into mobile applications for efficient on-device inference. |
||||
|
||||
- **Embedded Systems and IoT Devices**: If you find that running inference on a Raspberry Pi with the [Ultralytics Guide](../guides/raspberry-pi.md) isn't fast enough, switching to an NCNN exported model could help speed things up. NCNN is great for devices like Raspberry Pi and NVIDIA Jetson, especially in situations where you need quick processing right on the device. |
||||
|
||||
- **Desktop and Server Deployment**: Capable of being deployed in desktop and server environments across Linux, Windows, and macOS, supporting development, training, and evaluation with higher computational capacities. |
||||
|
||||
## Export to NCNN: Converting Your YOLOv8 Model |
||||
|
||||
You can expand model compatibility and deployment flexibility by converting YOLOv8 models to NCNN format. |
||||
|
||||
### Installation |
||||
|
||||
To install the required packages, run: |
||||
|
||||
!!! Tip "Installation" |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Install the required package for YOLOv8 |
||||
pip install ultralytics |
||||
``` |
||||
|
||||
For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips. |
||||
|
||||
### Usage |
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md). |
||||
|
||||
!!! Example "Usage" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load the YOLOv8 model |
||||
model = YOLO('yolov8n.pt') |
||||
|
||||
# Export the model to NCNN format |
||||
model.export(format='ncnn') # creates '/yolov8n_ncnn_model' |
||||
|
||||
# Load the exported NCNN model |
||||
ncnn_model = YOLO('./yolov8n_ncnn_model') |
||||
|
||||
# Run inference |
||||
results = ncnn_model('https://ultralytics.com/images/bus.jpg') |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Export a YOLOv8n PyTorch model to NCNN format |
||||
yolo export model=yolov8n.pt format=ncnn # creates '/yolov8n_ncnn_model' |
||||
|
||||
# Run inference with the exported model |
||||
yolo predict model='./yolov8n_ncnn_model' source='https://ultralytics.com/images/bus.jpg' |
||||
``` |
||||
|
||||
For more details about supported export options, visit the [Ultralytics documentation page on deployment options](../guides/model-deployment-options.md). |
||||
|
||||
## Deploying Exported YOLOv8 NCNN Models |
||||
|
||||
After successfully exporting your Ultralytics YOLOv8 models to NCNN format, you can now deploy them. The primary and recommended first step for running a NCNN model is to utilize the YOLO("./model_ncnn_model") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your NCNN models in various other settings, take a look at the following resources: |
||||
|
||||
- **[Android](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-android)**: This blog explains how to use NCNN models for performing tasks like object detection through Android applications. |
||||
|
||||
- **[macOS](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-macos)**: Understand how to use NCNN models for performing tasks through macOS. |
||||
|
||||
- **[Linux](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux)**: Explore this page to learn how to deploy NCNN models on limited resource devices like Raspberry Pi and other similar devices. |
||||
|
||||
- **[Windows x64 using VS2017](https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-windows-x64-using-visual-studio-community-2017)**: Explore this blog to learn how to deploy NCNN models on windows x64 using Visual Studio Community 2017. |
||||
|
||||
## Summary |
||||
|
||||
In this guide, we've gone over exporting Ultralytics YOLOv8 models to the NCNN format. This conversion step is crucial for improving the efficiency and speed of YOLOv8 models, making them more effective and suitable for limited-resource computing environments. |
||||
|
||||
For detailed instructions on usage, please refer to the [official NCNN documentation](https://ncnn.readthedocs.io/en/latest/index.html). |
||||
|
||||
Also, if you're interested in exploring other integration options for Ultralytics YOLOv8, be sure to visit our [integration guide page](index.md) for further insights and information. |
||||
@ -0,0 +1,122 @@ |
||||
--- |
||||
comments: true |
||||
description: Explore how to improve your Ultralytics YOLOv8 model's performance and interoperability using the TFLite export format suitable for edge computing environments. |
||||
keywords: Ultralytics, YOLOv8, TFLite Export, Export YOLOv8, Model Deployment |
||||
--- |
||||
|
||||
# A Guide on YOLOv8 Model Export to TFLite for Deployment |
||||
|
||||
<p align="center"> |
||||
<img width="75%" src="https://github.com/ultralytics/ultralytics/assets/26833433/6ecf34b9-9187-4d6f-815c-72394290a4d3" alt="TFLite Logo"> |
||||
</p> |
||||
|
||||
Deploying computer vision models on edge devices or embedded devices requires a format that can ensure seamless performance. |
||||
|
||||
The TensorFlow Lite or TFLite export format allows you to optimize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for tasks like object detection and image classification in edge device-based applications. In this guide, we'll walk through the steps for converting your models to the TFLite format, making it easier for your models to perform well on various edge devices. |
||||
|
||||
## Why should you export to TFLite? |
||||
|
||||
Introduced by Google in May 2017 as part of their TensorFlow framework, [TensorFlow Lite](https://www.tensorflow.org/lite/guide), or TFLite for short, is an open-source deep learning framework designed for on-device inference, also known as edge computing. It gives developers the necessary tools to execute their trained models on mobile, embedded, and IoT devices, as well as traditional computers. |
||||
|
||||
TensorFlow Lite is compatible with a wide range of platforms, including embedded Linux, Android, iOS, and MCU. Exporting your model to TFLite makes your applications faster, more reliable, and capable of running offline. |
||||
|
||||
## Key Features of TFLite Models |
||||
|
||||
TFLite models offer a wide range of key features that enable on-device machine learning by helping developers run their models on mobile, embedded, and edge devices: |
||||
|
||||
- **On-device Optimization**: TFLite optimizes for on-device ML, reducing latency by processing data locally, enhancing privacy by not transmitting personal data, and minimizing model size to save space. |
||||
|
||||
- **Multiple Platform Support**: TFLite offers extensive platform compatibility, supporting Android, iOS, embedded Linux, and microcontrollers. |
||||
|
||||
- **Diverse Language Support**: TFLite is compatible with various programming languages, including Java, Swift, Objective-C, C++, and Python. |
||||
|
||||
- **High Performance**: Achieves superior performance through hardware acceleration and model optimization. |
||||
|
||||
## Deployment Options in TFLite |
||||
|
||||
Before we look at the code for exporting YOLOv8 models to the TFLite format, let’s understand how TFLite models are normally used. |
||||
|
||||
TFLite offers various on-device deployment options for machine learning models, including: |
||||
|
||||
- **Deploying with Android and iOS**: Both Android and iOS applications with TFLite can analyze edge-based camera feeds and sensors to detect and identify objects. TFLite also offers native iOS libraries written in [Swift](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/swift) and [Objective-C](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/objc). The architecture diagram below shows the process of deploying a trained model onto Android and iOS platforms using TensorFlow Lite. |
||||
|
||||
<p align="center"> |
||||
<img width="75%" src="https://1.bp.blogspot.com/-6fS9FD8KD7g/XhJ1l8y2S4I/AAAAAAAACKw/MW9MQZ8gtiYmUe0naRdN0n2FwkT1l4trACLcBGAsYHQ/s1600/architecture.png" alt="Architecture"> |
||||
</p> |
||||
|
||||
- **Implementing with Embedded Linux**: If running inferences on a [Raspberry Pi](https://www.raspberrypi.org/) using the [Ultralytics Guide](../guides/raspberry-pi.md) does not meet the speed requirements for your use case, you can use an exported TFLite model to accelerate inference times. Additionally, it's possible to further improve performance by utilizing a [Coral Edge TPU device](https://coral.withgoogle.com/). |
||||
|
||||
- **Deploying with Microcontrollers**: TFLite models can also be deployed on microcontrollers and other devices with only a few kilobytes of memory. The core runtime just fits in 16 KB on an Arm Cortex M3 and can run many basic models. It doesn't require operating system support, any standard C or C++ libraries, or dynamic memory allocation. |
||||
|
||||
## Export to TFLite: Converting Your YOLOv8 Model |
||||
|
||||
You can improve on-device model execution efficiency and optimize performance by converting them to TFLite format. |
||||
|
||||
### Installation |
||||
|
||||
To install the required packages, run: |
||||
|
||||
!!! Tip "Installation" |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Install the required package for YOLOv8 |
||||
pip install ultralytics |
||||
``` |
||||
|
||||
For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips. |
||||
|
||||
### Usage |
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md). |
||||
|
||||
!!! Example "Usage" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load the YOLOv8 model |
||||
model = YOLO('yolov8n.pt') |
||||
|
||||
# Export the model to TFLite format |
||||
model.export(format='tflite') # creates 'yolov8n_float32.tflite' |
||||
|
||||
# Load the exported TFLite model |
||||
tflite_model = YOLO('yolov8n_float32.tflite') |
||||
|
||||
# Run inference |
||||
results = tflite_model('https://ultralytics.com/images/bus.jpg') |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Export a YOLOv8n PyTorch model to TFLite format |
||||
yolo export model=yolov8n.pt format=tflite # creates 'yolov8n_float32.tflite' |
||||
|
||||
# Run inference with the exported model |
||||
yolo predict model='yolov8n_float32.tflite' source='https://ultralytics.com/images/bus.jpg' |
||||
``` |
||||
|
||||
For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md). |
||||
|
||||
## Deploying Exported YOLOv8 TFLite Models |
||||
|
||||
After successfully exporting your Ultralytics YOLOv8 models to TFLite format, you can now deploy them. The primary and recommended first step for running a TFLite model is to utilize the YOLO("model.tflite") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your TFLite models in various other settings, take a look at the following resources: |
||||
|
||||
- **[Android](https://www.tensorflow.org/lite/android/quickstart)**: A quick start guide for integrating TensorFlow Lite into Android applications, providing easy-to-follow steps for setting up and running machine learning models. |
||||
|
||||
- **[iOS](https://www.tensorflow.org/lite/guide/ios)**: Check out this detailed guide for developers on integrating and deploying TensorFlow Lite models in iOS applications, offering step-by-step instructions and resources. |
||||
|
||||
- **[End-To-End Examples](https://www.tensorflow.org/lite/examples)**: This page provides an overview of various TensorFlow Lite examples, showcasing practical applications and tutorials designed to help developers implement TensorFlow Lite in their machine learning projects on mobile and edge devices. |
||||
|
||||
## Summary |
||||
|
||||
In this guide, we focused on how to export to TFLite format. By converting your Ultralytics YOLOv8 models to TFLite model format, you can improve the efficiency and speed of YOLOv8 models, making them more effective and suitable for edge computing environments. |
||||
|
||||
For further details on usage, visit [TFLite’s official documentation](https://www.tensorflow.org/lite/guide). |
||||
|
||||
Also, if you're curious about other Ultralytics YOLOv8 integrations, make sure to check out our [integration guide page](../integrations/index.md). You'll find tons of helpful info and insights waiting for you there. |
||||
@ -0,0 +1,126 @@ |
||||
--- |
||||
comments: true |
||||
description: Learn to export your Ultralytics YOLOv8 models to TorchScript format for deployment through platforms like embedded systems, web browsers, and C++ applications. |
||||
keywords: Ultralytics, YOLOv8, Export to Torchscript, Model Optimization, Deployment, PyTorch, C++, Faster Inference |
||||
--- |
||||
|
||||
# YOLOv8 Model Export to TorchScript for Quick Deployment |
||||
|
||||
Deploying computer vision models across different environments, including embedded systems, web browsers, or platforms with limited Python support, requires a flexible and portable solution. TorchScript focuses on portability and the ability to run models in environments where the entire Python framework is unavailable. This makes it ideal for scenarios where you need to deploy your computer vision capabilities across various devices or platforms. |
||||
|
||||
Export to Torchscript to serialize your [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) models for cross-platform compatibility and streamlined deployment. In this guide, we'll show you how to export your YOLOv8 models to the TorchScript format, making it easier for you to use them across a wider range of applications. |
||||
|
||||
## Why should you export to TorchScript? |
||||
|
||||
 |
||||
|
||||
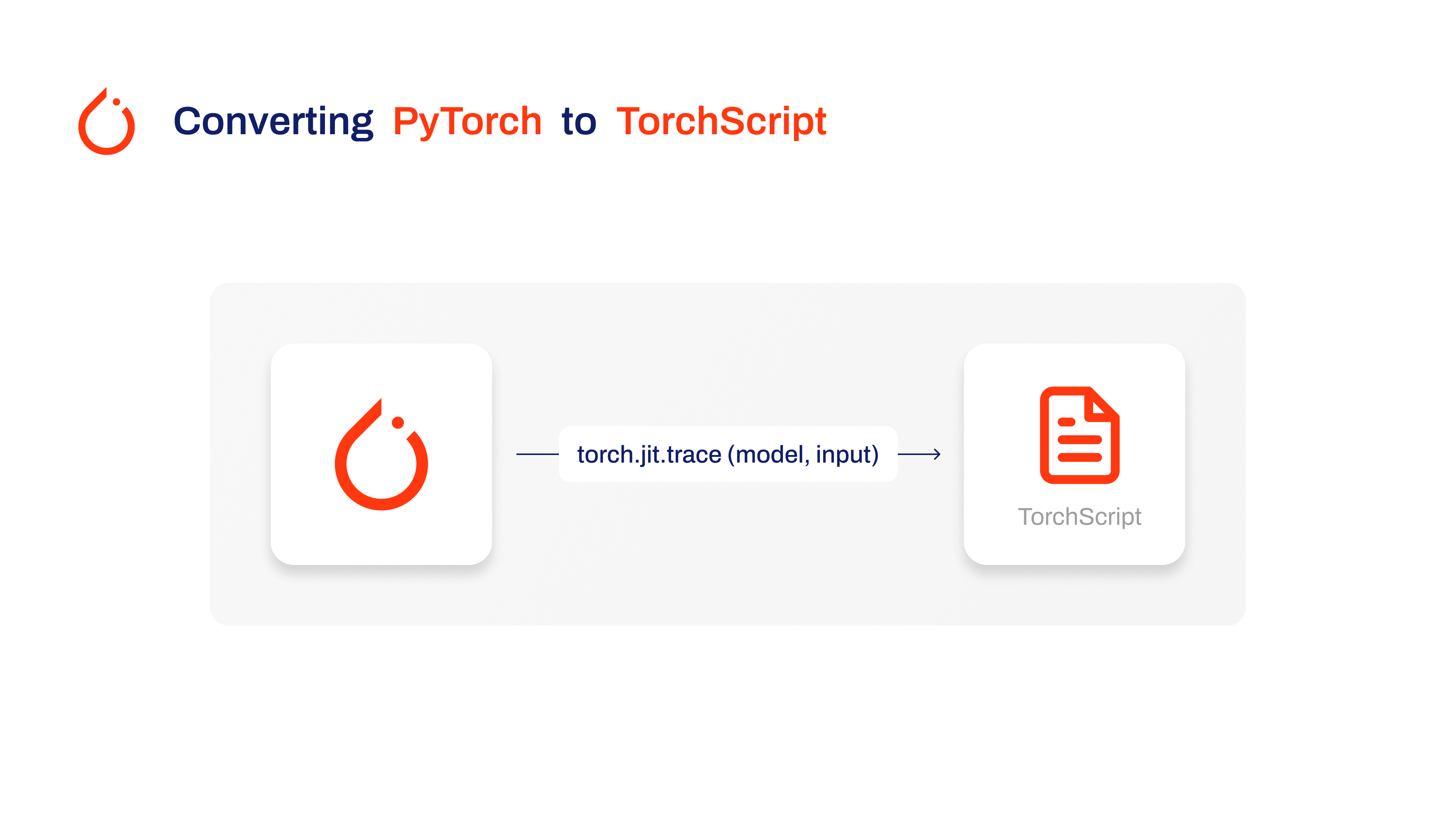
Developed by the creators of PyTorch, TorchScript is a powerful tool for optimizing and deploying PyTorch models across a variety of platforms. Exporting YOLOv8 models to [TorchScript](https://pytorch.org/docs/stable/jit.html) is crucial for moving from research to real-world applications. TorchScript, part of the PyTorch framework, helps make this transition smoother by allowing PyTorch models to be used in environments that don't support Python. |
||||
|
||||
The process involves two techniques: tracing and scripting. Tracing records operations during model execution, while scripting allows for the definition of models using a subset of Python. These techniques ensure that models like YOLOv8 can still work their magic even outside their usual Python environment. |
||||
|
||||
 |
||||
|
||||
TorchScript models can also be optimized through techniques such as operator fusion and refinements in memory usage, ensuring efficient execution. Another advantage of exporting to TorchScript is its potential to accelerate model execution across various hardware platforms. It creates a standalone, production-ready representation of your PyTorch model that can be integrated into C++ environments, embedded systems, or deployed in web or mobile applications. |
||||
|
||||
## Key Features of TorchScript Models |
||||
|
||||
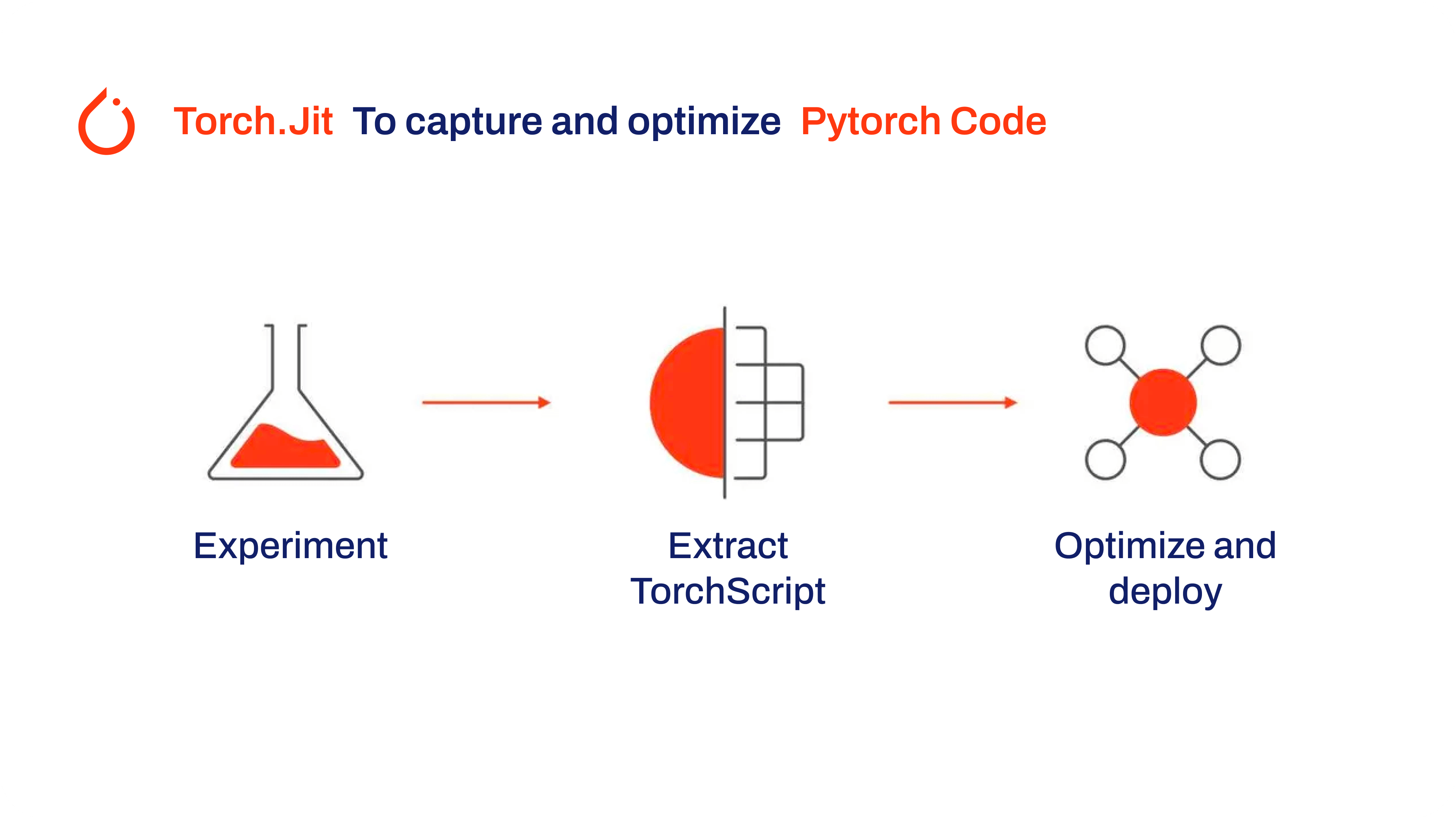
TorchScript, a key part of the PyTorch ecosystem, provides powerful features for optimizing and deploying deep learning models. |
||||
|
||||
 |
||||
|
||||
Here are the key features that make TorchScript a valuable tool for developers: |
||||
|
||||
- **Static Graph Execution**: TorchScript uses a static graph representation of the model’s computation, which is different from PyTorch’s dynamic graph execution. In static graph execution, the computational graph is defined and compiled once before the actual execution, resulting in improved performance during inference. |
||||
|
||||
- **Model Serialization**: TorchScript allows you to serialize PyTorch models into a platform-independent format. Serialized models can be loaded without requiring the original Python code, enabling deployment in different runtime environments. |
||||
|
||||
- **JIT Compilation**: TorchScript uses Just-In-Time (JIT) compilation to convert PyTorch models into an optimized intermediate representation. JIT compiles the model’s computational graph, enabling efficient execution on target devices. |
||||
|
||||
- **Cross-Language Integration**: With TorchScript, you can export PyTorch models to other languages such as C++, Java, and JavaScript. This makes it easier to integrate PyTorch models into existing software systems written in different languages. |
||||
|
||||
- **Gradual Conversion**: TorchScript provides a gradual conversion approach, allowing you to incrementally convert parts of your PyTorch model into TorchScript. This flexibility is particularly useful when dealing with complex models or when you want to optimize specific portions of the code. |
||||
|
||||
## Deployment Options in TorchScript |
||||
|
||||
Before we look at the code for exporting YOLOv8 models to the TorchScript format, let’s understand where TorchScript models are normally used. |
||||
|
||||
TorchScript offers various deployment options for machine learning models, such as: |
||||
|
||||
- **C++ API**: The most common use case for TorchScript is its C++ API, which allows you to load and execute optimized TorchScript models directly within C++ applications. This is ideal for production environments where Python may not be suitable or available. The C++ API offers low-overhead and efficient execution of TorchScript models, maximizing performance potential. |
||||
|
||||
- **Mobile Deployment**: TorchScript offers tools for converting models into formats readily deployable on mobile devices. PyTorch Mobile provides a runtime for executing these models within iOS and Android apps. This enables low-latency, offline inference capabilities, enhancing user experience and data privacy. |
||||
|
||||
- **Cloud Deployment**: TorchScript models can be deployed to cloud-based servers using solutions like TorchServe. It provides features like model versioning, batching, and metrics monitoring for scalable deployment in production environments. Cloud deployment with TorchScript can make your models accessible via APIs or other web services. |
||||
|
||||
## Export to TorchScript: Converting Your YOLOv8 Model |
||||
|
||||
Exporting YOLOv8 models to TorchScript makes it easier to use them in different places and helps them run faster and more efficiently. This is great for anyone looking to use deep learning models more effectively in real-world applications. |
||||
|
||||
### Installation |
||||
|
||||
To install the required package, run: |
||||
|
||||
!!! Tip "Installation" |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Install the required package for YOLOv8 |
||||
pip install ultralytics |
||||
``` |
||||
|
||||
For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips. |
||||
|
||||
### Usage |
||||
|
||||
Before diving into the usage instructions, it's important to note that while all [Ultralytics YOLOv8 models](../models/index.md) are available for exporting, you can ensure that the model you select supports export functionality [here](../modes/export.md). |
||||
|
||||
!!! Example "Usage" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load the YOLOv8 model |
||||
model = YOLO('yolov8n.pt') |
||||
|
||||
# Export the model to TorchScript format |
||||
model.export(format='torchscript') # creates 'yolov8n.torchscript' |
||||
|
||||
# Load the exported TorchScript model |
||||
torchscript_model = YOLO('yolov8n.torchscript') |
||||
|
||||
# Run inference |
||||
results = torchscript_model('https://ultralytics.com/images/bus.jpg') |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Export a YOLOv8n PyTorch model to TorchScript format |
||||
yolo export model=yolov8n.pt format=torchscript # creates 'yolov8n.torchscript' |
||||
|
||||
# Run inference with the exported model |
||||
yolo predict model=yolov8n.torchscript source='https://ultralytics.com/images/bus.jpg' |
||||
``` |
||||
|
||||
For more details about the export process, visit the [Ultralytics documentation page on exporting](../modes/export.md). |
||||
|
||||
## Deploying Exported YOLOv8 TorchScript Models |
||||
|
||||
After successfully exporting your Ultralytics YOLOv8 models to TorchScript format, you can now deploy them. The primary and recommended first step for running a TorchScript model is to utilize the YOLO("model.torchscript") method, as outlined in the previous usage code snippet. However, for in-depth instructions on deploying your TorchScript models in various other settings, take a look at the following resources: |
||||
|
||||
- **[Explore Mobile Deployment](https://pytorch.org/mobile/home/)**: The PyTorch Mobile Documentation provides comprehensive guidelines for deploying models on mobile devices, ensuring your applications are efficient and responsive. |
||||
|
||||
- **[Master Server-Side Deployment](https://pytorch.org/serve/getting_started.html)**: Learn how to deploy models server-side with TorchServe, offering a step-by-step tutorial for scalable, efficient model serving. |
||||
|
||||
- **[Implement C++ Deployment](https://pytorch.org/tutorials/advanced/cpp_export.html)**: Dive into the Tutorial on Loading a TorchScript Model in C++, facilitating the integration of your TorchScript models into C++ applications for enhanced performance and versatility. |
||||
|
||||
## Summary |
||||
|
||||
In this guide, we explored the process of exporting Ultralytics YOLOv8 models to the TorchScript format. By following the provided instructions, you can optimize YOLOv8 models for performance and gain the flexibility to deploy them across various platforms and environments. |
||||
|
||||
For further details on usage, visit [TorchScript’s official documentation](https://pytorch.org/docs/stable/jit.html). |
||||
|
||||
Also, if you’d like to know more about other Ultralytics YOLOv8 integrations, visit our [integration guide page](../integrations/index.md). You'll find plenty of useful resources and insights there. |
||||
Loading…
Reference in new issue