Docs cleanup and Google-style tracker docstrings (#6751)
Signed-off-by: Glenn Jocher <glenn.jocher@ultralytics.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>pull/4100/merge
parent
60041014a8
commit
80802be1e5
44 changed files with 755 additions and 544 deletions
@ -1,49 +1,87 @@ |
||||
--- |
||||
comments: true |
||||
description: Step-by-step tutorial on how to set up and run YOLOv5 on Google Cloud Platform Deep Learning VM. Perfect guide for beginners and GCP new users!. |
||||
keywords: YOLOv5, Google Cloud Platform, GCP, Deep Learning VM, Ultralytics |
||||
description: Discover how to deploy YOLOv5 on a GCP Deep Learning VM for seamless object detection. Ideal for ML beginners and cloud learners. Get started with our easy-to-follow tutorial! |
||||
keywords: YOLOv5, Google Cloud Platform, GCP, Deep Learning VM, ML model training, object detection, AI tutorial, cloud-based AI, machine learning setup |
||||
--- |
||||
|
||||
# Run YOLOv5 🚀 on Google Cloud Platform (GCP) Deep Learning Virtual Machine (VM) ⭐ |
||||
# Mastering YOLOv5 🚀 Deployment on Google Cloud Platform (GCP) Deep Learning Virtual Machine (VM) ⭐ |
||||
|
||||
This tutorial will guide you through the process of setting up and running YOLOv5 on a GCP Deep Learning VM. New GCP users are eligible for a [$300 free credit offer](https://cloud.google.com/free/docs/gcp-free-tier#free-trial). |
||||
Embarking on the journey of artificial intelligence and machine learning can be exhilarating, especially when you leverage the power and flexibility of a cloud platform. Google Cloud Platform (GCP) offers robust tools tailored for machine learning enthusiasts and professionals alike. One such tool is the Deep Learning VM that is preconfigured for data science and ML tasks. In this tutorial, we will navigate through the process of setting up YOLOv5 on a GCP Deep Learning VM. Whether you’re taking your first steps in ML or you’re a seasoned practitioner, this guide is designed to provide you with a clear pathway to implementing object detection models powered by YOLOv5. |
||||
|
||||
You can also explore other quickstart options for YOLOv5, such as our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a> <a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>, [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial) and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) <a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>. *Updated: 21 April 2023*. |
||||
🆓 Plus, if you're a fresh GCP user, you’re in luck with a [$300 free credit offer](https://cloud.google.com/free/docs/gcp-free-tier#free-trial) to kickstart your projects. |
||||
|
||||
**Last Updated**: 6 May 2022 |
||||
In addition to GCP, explore other accessible quickstart options for YOLOv5, like our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) <img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"> for a browser-based experience, or the scalability of [Amazon AWS](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial). Furthermore, container aficionados can utilize our official Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) <img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"> for an encapsulated environment. |
||||
|
||||
## Step 1: Create a Deep Learning VM |
||||
## Step 1: Create and Configure Your Deep Learning VM |
||||
|
||||
1. Go to the [GCP marketplace](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning) and select a **Deep Learning VM**. |
||||
2. Choose an **n1-standard-8** instance (with 8 vCPUs and 30 GB memory). |
||||
3. Add a GPU of your choice. |
||||
4. Check 'Install NVIDIA GPU driver automatically on first startup?' |
||||
5. Select a 300 GB SSD Persistent Disk for sufficient I/O speed. |
||||
6. Click 'Deploy'. |
||||
Let’s begin by creating a virtual machine that’s tuned for deep learning: |
||||
|
||||
The preinstalled [Anaconda](https://docs.anaconda.com/anaconda/packages/pkg-docs/) Python environment includes all dependencies. |
||||
1. Head over to the [GCP marketplace](https://console.cloud.google.com/marketplace/details/click-to-deploy-images/deeplearning) and select the **Deep Learning VM**. |
||||
2. Opt for a **n1-standard-8** instance; it offers a balance of 8 vCPUs and 30 GB of memory, ideally suited for our needs. |
||||
3. Next, select a GPU. This depends on your workload; even a basic one like the Tesla T4 will markedly accelerate your model training. |
||||
4. Tick the box for 'Install NVIDIA GPU driver automatically on first startup?' for hassle-free setup. |
||||
5. Allocate a 300 GB SSD Persistent Disk to ensure you don't bottleneck on I/O operations. |
||||
6. Hit 'Deploy' and let GCP do its magic in provisioning your custom Deep Learning VM. |
||||
|
||||
<img width="1000" alt="GCP Marketplace" src="https://user-images.githubusercontent.com/26833433/105811495-95863880-5f61-11eb-841d-c2f2a5aa0ffe.png"> |
||||
This VM comes loaded with a treasure trove of preinstalled tools and frameworks, including the [Anaconda](https://docs.anaconda.com/anaconda/packages/pkg-docs/) Python distribution, which conveniently bundles all the necessary dependencies for YOLOv5. |
||||
|
||||
## Step 2: Set Up the VM |
||||
 |
||||
|
||||
Clone the YOLOv5 repository and install the [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a [**Python>=3.8.0**](https://www.python.org/) environment, including [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/). [Models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) will be downloaded automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). |
||||
## Step 2: Ready the VM for YOLOv5 |
||||
|
||||
Following the environment setup, let's get YOLOv5 up and running: |
||||
|
||||
```bash |
||||
git clone https://github.com/ultralytics/yolov5 # clone |
||||
# Clone the YOLOv5 repository |
||||
git clone https://github.com/ultralytics/yolov5 |
||||
|
||||
# Change the directory to the cloned repository |
||||
cd yolov5 |
||||
pip install -r requirements.txt # install |
||||
|
||||
# Install the necessary Python packages from requirements.txt |
||||
pip install -r requirements.txt |
||||
``` |
||||
|
||||
## Step 3: Run YOLOv5 🚀 on the VM |
||||
This setup process ensures you're working with a Python environment version 3.8.0 or newer and PyTorch 1.8 or above. Our scripts smoothly download [models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) rending from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases), making it hassle-free to start model training. |
||||
|
||||
You can now train, test, detect, and export YOLOv5 models on your VM: |
||||
## Step 3: Train and Deploy Your YOLOv5 Models 🌐 |
||||
|
||||
With the setup complete, you're ready to delve into training and inference with YOLOv5 on your GCP VM: |
||||
|
||||
```bash |
||||
python train.py # train a model |
||||
python val.py --weights yolov5s.pt # validate a model for Precision, Recall, and mAP |
||||
python detect.py --weights yolov5s.pt --source path/to/images # run inference on images and videos |
||||
python export.py --weights yolov5s.pt --include onnx coreml tflite # export models to other formats |
||||
# Train a model on your data |
||||
python train.py |
||||
|
||||
# Validate the trained model for Precision, Recall, and mAP |
||||
python val.py --weights yolov5s.pt |
||||
|
||||
# Run inference using the trained model on your images or videos |
||||
python detect.py --weights yolov5s.pt --source path/to/images |
||||
|
||||
# Export the trained model to other formats for deployment |
||||
python export.py --weights yolov5s.pt --include onnx coreml tflite |
||||
``` |
||||
|
||||
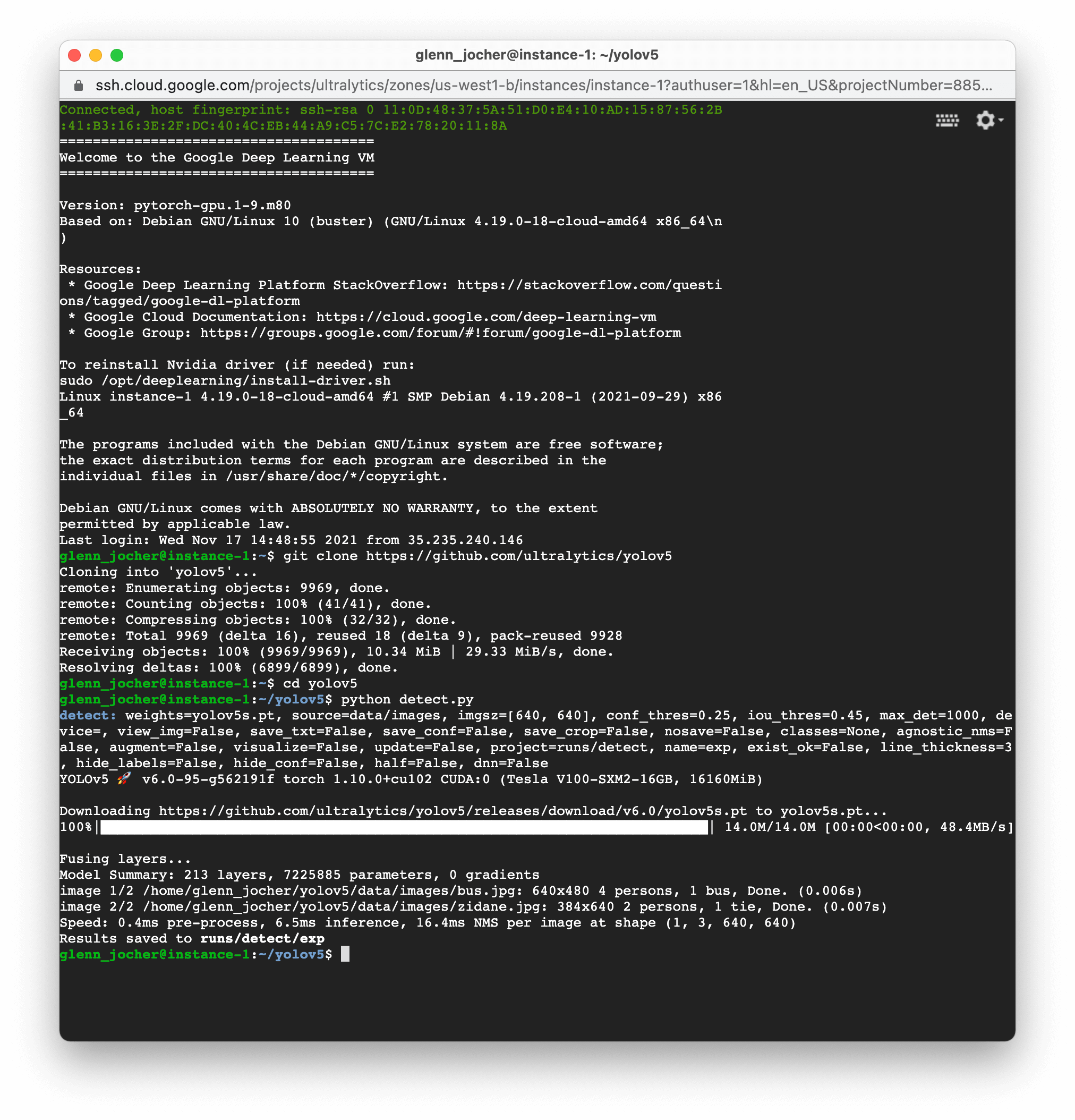
<img width="1000" alt="GCP terminal" src="https://user-images.githubusercontent.com/26833433/142223900-275e5c9e-e2b5-43f7-a21c-35c4ca7de87c.png"> |
||||
With just a few commands, YOLOv5 allows you to train custom object detection models tailored to your specific needs or utilize pre-trained weights for quick results on a variety of tasks. |
||||
|
||||
 |
||||
|
||||
## Allocate Swap Space (optional) |
||||
|
||||
For those dealing with hefty datasets, consider amplifying your GCP instance with an additional 64GB of swap memory: |
||||
|
||||
```bash |
||||
sudo fallocate -l 64G /swapfile |
||||
sudo chmod 600 /swapfile |
||||
sudo mkswap /swapfile |
||||
sudo swapon /swapfile |
||||
free -h # confirm the memory increment |
||||
``` |
||||
|
||||
### Concluding Thoughts |
||||
|
||||
Congratulations! You are now empowered to harness the capabilities of YOLOv5 with the computational prowess of Google Cloud Platform. This combination provides scalability, efficiency, and versatility for your object detection tasks. Whether for personal projects, academic research, or industrial applications, you have taken a pivotal step into the world of AI and machine learning on the cloud. |
||||
|
||||
Do remember to document your journey, share insights with the Ultralytics community, and leverage the collaborative arenas such as [GitHub discussions](https://github.com/ultralytics/yolov5/discussions) to grow further. Now, go forth and innovate with YOLOv5 and GCP! 🌟 |
||||
|
||||
Want to keep improving your ML skills and knowledge? Dive into our [documentation and tutorials](https://docs.ultralytics.com/) for more resources. Let your AI adventure continue! |
||||
|
||||
Loading…
Reference in new issue