commit
4ccd40b944
122 changed files with 4042 additions and 826 deletions
@ -0,0 +1,98 @@ |
||||
--- |
||||
comments: true |
||||
description: Learn how LVIS, a leading dataset for object detection and segmentation, integrates with Ultralytics. Discover ways to use it for training YOLO models. |
||||
keywords: Ultralytics, LVIS dataset, object detection, YOLO, YOLO model training, image segmentation, computer vision, deep learning models |
||||
--- |
||||
|
||||
# LVIS Dataset |
||||
|
||||
The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and instance segmentation with a large vocabulary of categories, aiming to drive further advancements in computer vision field. |
||||
|
||||
<p align="center"> |
||||
<img width="640" src="https://github.com/ultralytics/ultralytics/assets/26833433/40230a80-e7bc-4310-a860-4cc0ef4bb02a" alt="LVIS Dataset example images"> |
||||
</p> |
||||
|
||||
## Key Features |
||||
|
||||
- LVIS contains 160k images and 2M instance annotations for object detection, segmentation, and captioning tasks. |
||||
- The dataset comprises 1203 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment. |
||||
- Annotations include object bounding boxes, segmentation masks, and captions for each image. |
||||
- LVIS provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance. |
||||
- LVIS uses the exactly the same images as [COCO](./coco.md) dataset, but with different splits and different annotations. |
||||
|
||||
## Dataset Structure |
||||
|
||||
The LVIS dataset is split into three subsets: |
||||
|
||||
1. **Train**: This subset contains 100k images for training object detection, segmentation, and captioning models. |
||||
2. **Val**: This subset has 20k images used for validation purposes during model training. |
||||
3. **Minival**: This subset is exactly the same as COCO val2017 set which has 5k images used for validation purposes during model training. |
||||
4. **Test**: This subset consists of 20k images used for testing and benchmarking the trained models. Ground truth annotations for this subset are not publicly available, and the results are submitted to the [LVIS evaluation server](https://eval.ai/web/challenges/challenge-page/675/overview) for performance evaluation. |
||||
|
||||
## Applications |
||||
|
||||
The LVIS dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners. |
||||
|
||||
## Dataset YAML |
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the LVIS dataset, the `lvis.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/lvis.yaml). |
||||
|
||||
!!! Example "ultralytics/cfg/datasets/lvis.yaml" |
||||
|
||||
```yaml |
||||
--8<-- "ultralytics/cfg/datasets/lvis.yaml" |
||||
``` |
||||
|
||||
## Usage |
||||
|
||||
To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page. |
||||
|
||||
!!! Example "Train Example" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load a model |
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training) |
||||
|
||||
# Train the model |
||||
results = model.train(data='lvis.yaml', epochs=100, imgsz=640) |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Start training from a pretrained *.pt model |
||||
yolo detect train data=lvis.yaml model=yolov8n.pt epochs=100 imgsz=640 |
||||
``` |
||||
|
||||
## Sample Images and Annotations |
||||
|
||||
The LVIS dataset contains a diverse set of images with various object categories and complex scenes. Here are some examples of images from the dataset, along with their corresponding annotations: |
||||
|
||||
 |
||||
|
||||
- **Mosaiced Image**: This image demonstrates a training batch composed of mosaiced dataset images. Mosaicing is a technique used during training that combines multiple images into a single image to increase the variety of objects and scenes within each training batch. This helps improve the model's ability to generalize to different object sizes, aspect ratios, and contexts. |
||||
|
||||
The example showcases the variety and complexity of the images in the LVIS dataset and the benefits of using mosaicing during the training process. |
||||
|
||||
## Citations and Acknowledgments |
||||
|
||||
If you use the LVIS dataset in your research or development work, please cite the following paper: |
||||
|
||||
!!! Quote "" |
||||
|
||||
=== "BibTeX" |
||||
|
||||
```bibtex |
||||
@inproceedings{gupta2019lvis, |
||||
title={{LVIS}: A Dataset for Large Vocabulary Instance Segmentation}, |
||||
author={Gupta, Agrim and Dollar, Piotr and Girshick, Ross}, |
||||
booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition}, |
||||
year={2019} |
||||
} |
||||
``` |
||||
|
||||
We would like to acknowledge the LVIS Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the LVIS dataset and its creators, visit the [LVIS dataset website](https://www.lvisdataset.org/). |
||||
@ -0,0 +1,256 @@ |
||||
--- |
||||
comments: true |
||||
description: Quick start guide to setting up YOLOv8 on a NVIDIA Jetson device with comprehensive benchmarks. |
||||
keywords: Ultralytics, YOLO, NVIDIA, Jetson, TensorRT, quick start guide, hardware setup, machine learning, AI |
||||
--- |
||||
|
||||
# Quick Start Guide: NVIDIA Jetson with Ultralytics YOLOv8 |
||||
|
||||
This comprehensive guide provides a detailed walkthrough for deploying Ultralytics YOLOv8 on [NVIDIA Jetson](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/) devices. Additionally, it showcases performance benchmarks to demonstrate the capabilities of YOLOv8 on these small and powerful devices. |
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/ultralytics/assets/20147381/c68fb2eb-371a-43e5-b7b8-2b869d90bc07" alt="NVIDIA Jetson Ecosystem"> |
||||
|
||||
!!! Note |
||||
|
||||
This guide has been tested with [Seeed Studio reComputer J4012](https://www.seeedstudio.com/reComputer-J4012-p-5586.html) which is based on NVIDIA Jetson Orin NX 16GB running the latest stable JetPack release of [JP5.1.3](https://developer.nvidia.com/embedded/jetpack-sdk-513). Using this guide for older Jetson devices such as the Jetson Nano (this only supports until JP4.6.4) may not be guaranteed to work. However this is expected to work on all Jetson Orin, Xavier NX, AGX Xavier devices running JP5.1.3. |
||||
|
||||
## What is NVIDIA Jetson? |
||||
|
||||
NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and deep learning models directly on the device, without needing to rely on cloud computing resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices. |
||||
|
||||
## NVIDIA Jetson Series Comparison |
||||
|
||||
[Jetson Orin](https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-orin/) is the latest iteration of the NVIDIA Jetson family based on NVIDIA Ampere architecture which brings drastically improved AI performance when compared to the previous generations. Below table compared few of the Jetson devices in the ecosystem. |
||||
|
||||
| | Jetson AGX Orin 64GB | Jetson Orin NX 16GB | Jetson Orin Nano 8GB | Jetson AGX Xavier | Jetson Xavier NX | Jetson Nano | |
||||
|-------------------|------------------------------------------------------------------|-----------------------------------------------------------------|---------------------------------------------------------------|-------------------------------------------------------------|--------------------------------------------------------------|---------------------------------------------| |
||||
| AI Performance | 275 TOPS | 100 TOPS | 40 TOPs | 32 TOPS | 21 TOPS | 472 GFLOPS | |
||||
| GPU | 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 1024-core NVIDIA Ampere architecture GPU with 32 Tensor Cores | 512-core NVIDIA Volta architecture GPU with 64 Tensor Cores | 384-core NVIDIA Volta™ architecture GPU with 48 Tensor Cores | 128-core NVIDIA Maxwell™ architecture GPU | |
||||
| GPU Max Frequency | 1.3 GHz | 918 MHz | 625 MHz | 1377 MHz | 1100 MHz | 921MHz | |
||||
| CPU | 12-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 3MB L2 + 6MB L3 | 8-core NVIDIA Arm® Cortex A78AE v8.2 64-bit CPU 2MB L2 + 4MB L3 | 6-core Arm® Cortex®-A78AE v8.2 64-bit CPU 1.5MB L2 + 4MB L3 | 8-core NVIDIA Carmel Arm®v8.2 64-bit CPU 8MB L2 + 4MB L3 | 6-core NVIDIA Carmel Arm®v8.2 64-bit CPU 6MB L2 + 4MB L3 | Quad-Core Arm® Cortex®-A57 MPCore processor | |
||||
| CPU Max Frequency | 2.2 GHz | 2.0 GHz | 1.5 GHz | 2.2 GHz | 1.9 GHz | 1.43GHz | |
||||
| Memory | 64GB 256-bit LPDDR5 204.8GB/s | 16GB 128-bit LPDDR5 102.4GB/s | 8GB 128-bit LPDDR5 68 GB/s | 32GB 256-bit LPDDR4x 136.5GB/s | 8GB 128-bit LPDDR4x 59.7GB/s | 4GB 64-bit LPDDR4 25.6GB/s" | |
||||
|
||||
For a more detailed comparison table, please visit the **Technical Specifications** section of [official NVIDIA Jetson page](https://developer.nvidia.com/embedded/jetson-modules). |
||||
|
||||
## What is NVIDIA JetPack? |
||||
|
||||
[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and computer vision. It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI. |
||||
|
||||
## Flash JetPack to NVIDIA Jetson |
||||
|
||||
The first step after getting your hands on an NVIDIA Jetson device is to flash NVIDIA JetPack to the device. There are several different way of flashing NVIDIA Jetson devices. |
||||
|
||||
1. If you own an official NVIDIA Development Kit such as the Jetson Orin Nano Developer Kit, you can visit [this link](https://developer.nvidia.com/embedded/learn/get-started-jetson-orin-nano-devkit) to download an image and prepare an SD card with JetPack for booting the device. |
||||
2. If you own any other NVIDIA Development Kit, you can visit [this link](https://docs.nvidia.com/sdk-manager/install-with-sdkm-jetson/index.html) to flash JetPack to the device using [SDK Manager](https://developer.nvidia.com/sdk-manager). |
||||
3. If you own a Seeed Studio reComputer J4012 device, you can visit [this link](https://wiki.seeedstudio.com/reComputer_J4012_Flash_Jetpack) to flash JetPack to the included SSD. |
||||
4. If you own any other third party device powered by the NVIDIA Jetson module, it is recommended to follow command-line flashing by visiting [this link](https://docs.nvidia.com/jetson/archives/r35.5.0/DeveloperGuide/IN/QuickStart.html). |
||||
|
||||
!!! Note |
||||
|
||||
For methods 3 and 4 above, after flashing the system and booting the device, please enter "sudo apt update && sudo apt install nvidia-jetpack -y" on the device terminal to install all the remaining JetPack components needed. |
||||
|
||||
## Start with Docker |
||||
|
||||
The fastest way to get started with Ultralytics YOLOv8 on NVIDIA Jetson is to run with pre-built docker image for Jetson. |
||||
|
||||
Execute the below command to pull the Docker containter and run on Jetson. This is based on [l4t-pytorch](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch) docker image which contains PyTorch and Torchvision in a Python3 environment. |
||||
|
||||
```sh |
||||
t=ultralytics/ultralytics:latest-jetson && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t |
||||
``` |
||||
|
||||
## Start without Docker |
||||
|
||||
### Install Ultralytics Package |
||||
|
||||
Here we will install ultralyics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](https://docs.ultralytics.com/integrations/tensorrt) because TensoRT will make sure we can get the maximum performance out of the Jetson devices. |
||||
|
||||
1. Update packages list, install pip and upgrade to latest |
||||
|
||||
```sh |
||||
sudo apt update |
||||
sudo apt install python3-pip -y |
||||
pip install -U pip |
||||
``` |
||||
|
||||
2. Install `ultralytics` pip package with optional dependencies |
||||
|
||||
```sh |
||||
pip install ultralytics[export] |
||||
``` |
||||
|
||||
3. Reboot the device |
||||
|
||||
```sh |
||||
sudo reboot |
||||
``` |
||||
|
||||
### Install PyTorch and Torchvision |
||||
|
||||
The above ultralytics installation will install Torch and Torchvision. However, these 2 packages installed via pip are not compatible to run on Jetson platform which is based on ARM64 architecture. Therefore, we need to manually install pre-built PyTorch pip wheel and compile/ install Torchvision from source. |
||||
|
||||
1. Uninstall currently installed PyTorch and Torchvision |
||||
|
||||
```sh |
||||
pip uninstall torch torchvision |
||||
``` |
||||
|
||||
2. Install PyTorch 2.1.0 according to JP5.1.3 |
||||
|
||||
```sh |
||||
sudo apt-get install -y libopenblas-base libopenmpi-dev |
||||
wget https://developer.download.nvidia.com/compute/redist/jp/v512/pytorch/torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl -O torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl |
||||
pip install torch-2.1.0a0+41361538.nv23.06-cp38-cp38-linux_aarch64.whl |
||||
``` |
||||
|
||||
3. Install Torchvision v0.16.2 according to PyTorch v2.1.0 |
||||
|
||||
```sh |
||||
sudo apt install -y libjpeg-dev zlib1g-dev |
||||
git clone https://github.com/pytorch/vision torchvision |
||||
cd torchvision |
||||
git checkout v0.16.2 |
||||
python3 setup.py install --user |
||||
``` |
||||
|
||||
Visit [this page](https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048) to access all different versions of PyTorch for different JetPack versions. For a more detailed list on the PyTorch, Torchvision compatibility, please check [here](https://github.com/pytorch/vision). |
||||
|
||||
## Use TensorRT on NVIDIA Jetson |
||||
|
||||
Out of all the model export formats supported by Ultralytics, TensorRT delivers the best inference performance when working with NVIDIA Jetson devices and our recommendation is to use TensorRT with Jetson. We also have a detailed document on TensorRT [here](https://docs.ultralytics.com/integrations/tensorrt). |
||||
|
||||
## Convert Model to TensorRT and Run Inference |
||||
|
||||
The YOLOv8n model in PyTorch format is converted to TensorRT to run inference with the exported model. |
||||
|
||||
!!! Example |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load a YOLOv8n PyTorch model |
||||
model = YOLO('yolov8n.pt') |
||||
|
||||
# Export the model |
||||
model.export(format='engine') # creates 'yolov8n.engine' |
||||
|
||||
# Load the exported TensorRT model |
||||
trt_model = YOLO('yolov8n.engine') |
||||
|
||||
# Run inference |
||||
results = trt_model('https://ultralytics.com/images/bus.jpg') |
||||
``` |
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Export a YOLOv8n PyTorch model to TensorRT format |
||||
yolo export model=yolov8n.pt format=engine # creates 'yolov8n.engine' |
||||
|
||||
# Run inference with the exported model |
||||
yolo predict model=yolov8n.engine source='https://ultralytics.com/images/bus.jpg' |
||||
``` |
||||
|
||||
## Arguments |
||||
|
||||
| Key | Value | Description | |
||||
|----------|------------|------------------------------------------------------| |
||||
| `format` | `'engine'` | format to export to | |
||||
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) | |
||||
| `half` | `False` | FP16 quantization | |
||||
|
||||
## NVIDIA Jetson Orin YOLOv8 Benchmarks |
||||
|
||||
YOLOv8 benchmarks below were run by the Ultralytics team on 3 different model formats measuring speed and accuracy: PyTorch, TorchScript and TensorRT. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 precision with default input image size of 640. |
||||
|
||||
<div style="text-align: center;"> |
||||
<img width="800" src="https://github.com/ultralytics/ultralytics/assets/20147381/202950fa-c24a-43ec-90c8-4d7b6a6c406e" alt="NVIDIA Jetson Ecosystem"> |
||||
</div> |
||||
|
||||
| Model | Format | Status | Size (MB) | mAP50-95(B) | Inference time (ms/im) | |
||||
|---------|-------------|--------|-----------|-------------|------------------------| |
||||
| YOLOv8n | PyTorch | ✅ | 6.2 | 0.4473 | 14.3 | |
||||
| YOLOv8n | TorchScript | ✅ | 12.4 | 0.4520 | 13.3 | |
||||
| YOLOv8n | TensorRT | ✅ | 13.6 | 0.4520 | 8.7 | |
||||
| YOLOv8s | PyTorch | ✅ | 21.5 | 0.5868 | 18 | |
||||
| YOLOv8s | TorchScript | ✅ | 43.0 | 0.5971 | 23.9 | |
||||
| YOLOv8s | TensorRT | ✅ | 44.0 | 0.5965 | 14.82 | |
||||
| YOLOv8m | PyTorch | ✅ | 49.7 | 0.6101 | 36.4 | |
||||
| YOLOv8m | TorchScript | ✅ | 99.2 | 0.6125 | 53.34 | |
||||
| YOLOv8m | TensorRT | ✅ | 100.3 | 0.6123 | 33.28 | |
||||
| YOLOv8l | PyTorch | ✅ | 83.7 | 0.6588 | 61.3 | |
||||
| YOLOv8l | TorchScript | ✅ | 167.2 | 0.6587 | 85.21 | |
||||
| YOLOv8l | TensorRT | ✅ | 168.3 | 0.6591 | 51.34 | |
||||
| YOLOv8x | PyTorch | ✅ | 130.5 | 0.6650 | 93 | |
||||
| YOLOv8x | TorchScript | ✅ | 260.7 | 0.6651 | 135.3 | |
||||
| YOLOv8x | TensorRT | ✅ | 261.8 | 0.6645 | 84.5 | |
||||
|
||||
This table represents the benchmark results for five different models (YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x) across three different formats (PyTorch, TorchScript, TensorRT), giving us the status, size, mAP50-95(B) metric, and inference time for each combination. |
||||
|
||||
Visit [this link](https://www.seeedstudio.com/blog/2023/03/30/yolov8-performance-benchmarks-on-nvidia-jetson-devices) to explore more benchmarking efforts by Seeed Studio running on different versions of NVIDIA Jetson hardware. |
||||
|
||||
## Reproduce Our Results |
||||
|
||||
To reproduce the above Ultralytics benchmarks on all export [formats](../modes/export.md) run this code: |
||||
|
||||
!!! Example |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load a YOLOv8n PyTorch model |
||||
model = YOLO('yolov8n.pt') |
||||
|
||||
# Benchmark YOLOv8n speed and accuracy on the COCO128 dataset for all all export formats |
||||
results = model.benchmarks(data='coco128.yaml', imgsz=640) |
||||
``` |
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Benchmark YOLOv8n speed and accuracy on the COCO128 dataset for all all export formats |
||||
yolo benchmark model=yolov8n.pt data=coco128.yaml imgsz=640 |
||||
``` |
||||
|
||||
Note that benchmarking results might vary based on the exact hardware and software configuration of a system, as well as the current workload of the system at the time the benchmarks are run. For the most reliable results use a dataset with a large number of images, i.e. `data='coco128.yaml' (128 val images), or `data='coco.yaml'` (5000 val images). |
||||
|
||||
!!! Note |
||||
|
||||
Currently only PyTorch, Torchscript and TensorRT are working with the benchmarking tools. We will update it to support other exports in the future. |
||||
|
||||
## Best Practices when using NVIDIA Jetson |
||||
|
||||
When using NVIDIA Jetson, there are a couple of best practices to follow in order to enable maximum performance on the NVIDIA Jetson running YOLOv8. |
||||
|
||||
1. Enable MAX Power Mode |
||||
|
||||
Enabling MAX Power Mode on the Jetson will make sure all CPU, GPU cores are turned on. |
||||
```sh |
||||
sudo nvpmodel -m 0 |
||||
``` |
||||
|
||||
2. Enable Jetson Clocks |
||||
|
||||
Enabling Jetson Clocks will make sure all CPU, GPU cores are clocked at their maximum frequency. |
||||
```sh |
||||
sudo jetson_clocks |
||||
``` |
||||
|
||||
3. Install Jetson Stats Application |
||||
|
||||
We can use jetson stats application to monitor the temperatures of the system components and check other system details such as view CPU, GPU, RAM utilization, change power modes, set to max clocks, check JetPack information |
||||
```sh |
||||
sudo apt update |
||||
sudo pip install jetson-stats |
||||
sudo reboot |
||||
jtop |
||||
``` |
||||
|
||||
<img width="1024" src="https://github.com/ultralytics/ultralytics/assets/20147381/f7017975-6eaa-4d02-8007-ab52314cebfd" alt="Jetson Stats"> |
||||
|
||||
## Next Steps |
||||
|
||||
Congratulations on successfully setting up YOLOv8 on your NVIDIA Jetson! For further learning and support, visit more guide at [Ultralytics YOLOv8 Docs](../index.md)! |
||||
@ -0,0 +1,152 @@ |
||||
--- |
||||
comments: true |
||||
description: Queue Management Using Ultralytics YOLOv8 |
||||
keywords: Ultralytics, YOLOv8, Queue Management, Object Counting, Object Tracking, Object Detection, Notebook, IPython Kernel, CLI, Python SDK |
||||
--- |
||||
|
||||
# Queue Management using Ultralytics YOLOv8 🚀 |
||||
|
||||
## What is Queue Management? |
||||
|
||||
Queue management using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves organizing and controlling lines of people or vehicles to reduce wait times and enhance efficiency. It's about optimizing queues to improve customer satisfaction and system performance in various settings like retail, banks, airports, and healthcare facilities. |
||||
|
||||
## Advantages of Queue Management? |
||||
|
||||
- **Reduced Waiting Times:** Queue management systems efficiently organize queues, minimizing wait times for customers. This leads to improved satisfaction levels as customers spend less time waiting and more time engaging with products or services. |
||||
- **Increased Efficiency:** Implementing queue management allows businesses to allocate resources more effectively. By analyzing queue data and optimizing staff deployment, businesses can streamline operations, reduce costs, and improve overall productivity. |
||||
|
||||
## Real World Applications |
||||
|
||||
| Logistics | Retail | |
||||
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------:| |
||||
| 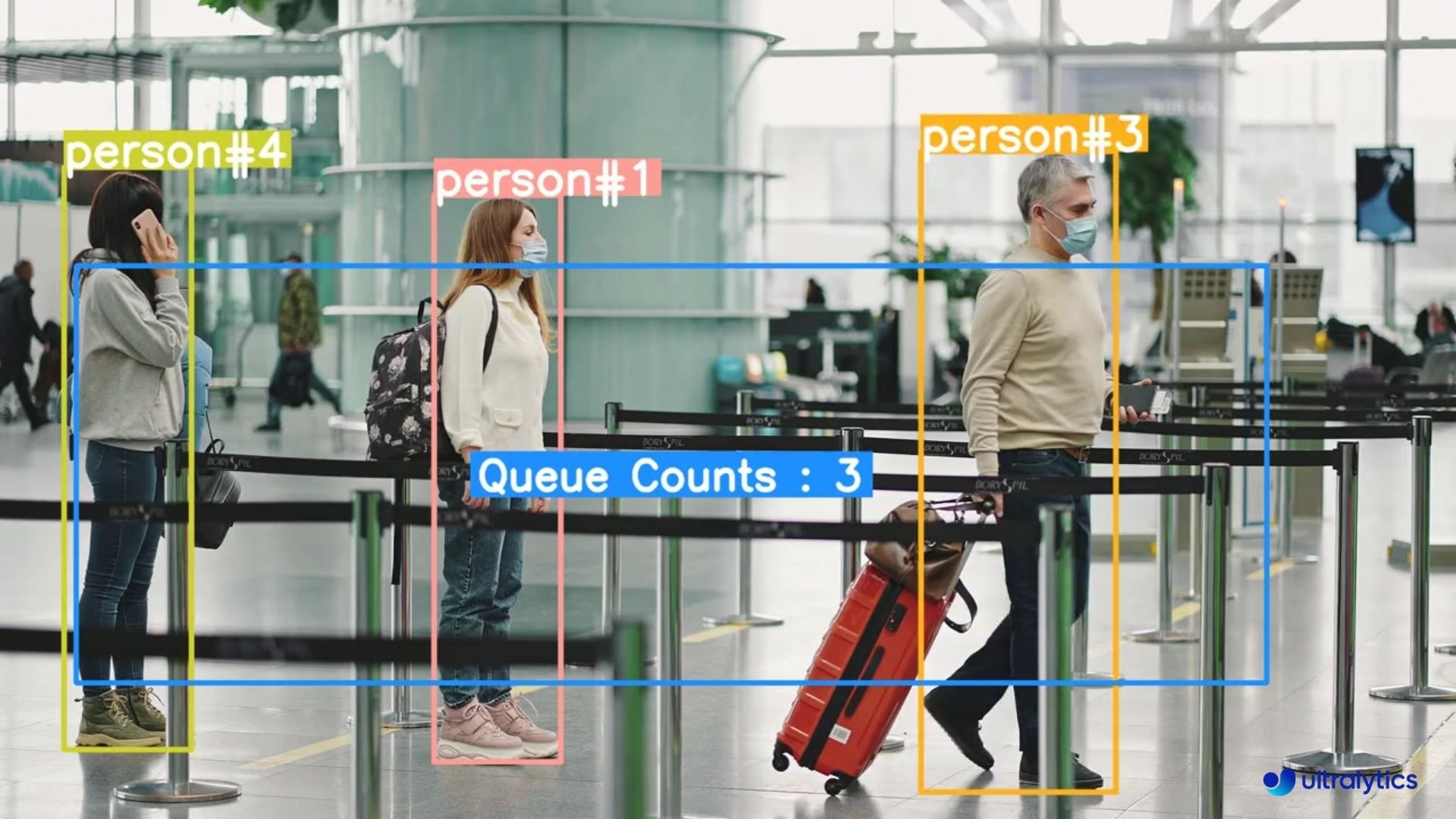 | 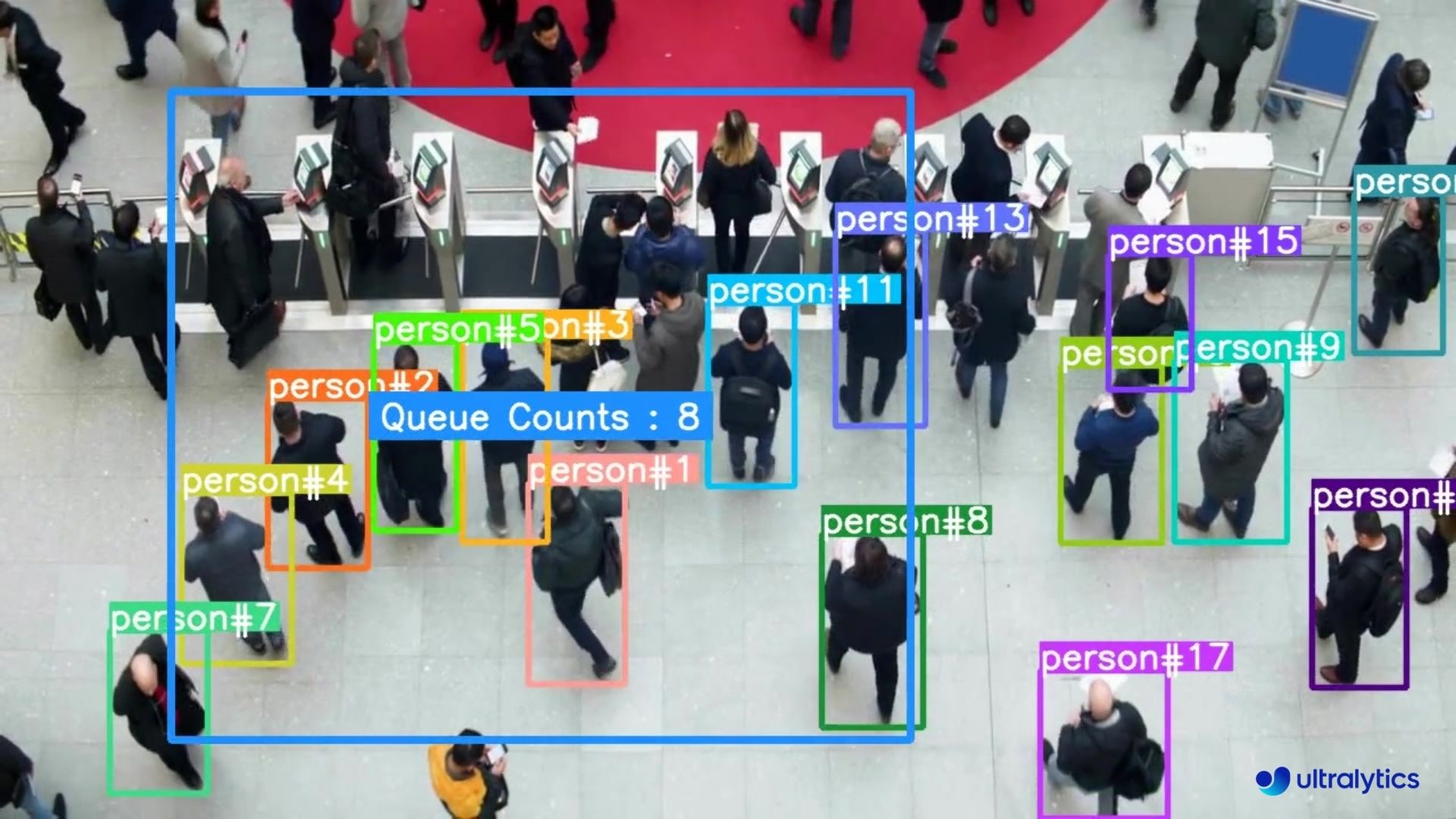 | |
||||
| Queue management at airport ticket counter Using Ultralytics YOLOv8 | Queue monitoring in crowd Ultralytics YOLOv8 | |
||||
|
||||
!!! Example "Queue Management using YOLOv8 Example" |
||||
|
||||
=== "Queue Manager" |
||||
|
||||
```python |
||||
import cv2 |
||||
from ultralytics import YOLO |
||||
from ultralytics.solutions import queue_management |
||||
|
||||
model = YOLO("yolov8n.pt") |
||||
cap = cv2.VideoCapture("path/to/video/file.mp4") |
||||
|
||||
assert cap.isOpened(), "Error reading video file" |
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, |
||||
cv2.CAP_PROP_FRAME_HEIGHT, |
||||
cv2.CAP_PROP_FPS)) |
||||
|
||||
video_writer = cv2.VideoWriter("queue_management.avi", |
||||
cv2.VideoWriter_fourcc(*'mp4v'), |
||||
fps, |
||||
(w, h)) |
||||
|
||||
queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)] |
||||
|
||||
queue = queue_management.QueueManager() |
||||
queue.set_args(classes_names=model.names, |
||||
reg_pts=queue_region, |
||||
line_thickness=3, |
||||
fontsize=1.0, |
||||
region_color=(255, 144, 31)) |
||||
|
||||
while cap.isOpened(): |
||||
success, im0 = cap.read() |
||||
|
||||
if success: |
||||
tracks = model.track(im0, show=False, persist=True, |
||||
verbose=False) |
||||
out = queue.process_queue(im0, tracks) |
||||
|
||||
video_writer.write(im0) |
||||
if cv2.waitKey(1) & 0xFF == ord('q'): |
||||
break |
||||
continue |
||||
|
||||
print("Video frame is empty or video processing has been successfully completed.") |
||||
break |
||||
|
||||
cap.release() |
||||
cv2.destroyAllWindows() |
||||
``` |
||||
|
||||
=== "Queue Manager Specific Classes" |
||||
|
||||
```python |
||||
import cv2 |
||||
from ultralytics import YOLO |
||||
from ultralytics.solutions import queue_management |
||||
|
||||
model = YOLO("yolov8n.pt") |
||||
cap = cv2.VideoCapture("path/to/video/file.mp4") |
||||
|
||||
assert cap.isOpened(), "Error reading video file" |
||||
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, |
||||
cv2.CAP_PROP_FRAME_HEIGHT, |
||||
cv2.CAP_PROP_FPS)) |
||||
|
||||
video_writer = cv2.VideoWriter("queue_management.avi", |
||||
cv2.VideoWriter_fourcc(*'mp4v'), |
||||
fps, |
||||
(w, h)) |
||||
|
||||
queue_region = [(20, 400), (1080, 404), (1080, 360), (20, 360)] |
||||
|
||||
queue = queue_management.QueueManager() |
||||
queue.set_args(classes_names=model.names, |
||||
reg_pts=queue_region, |
||||
line_thickness=3, |
||||
fontsize=1.0, |
||||
region_color=(255, 144, 31)) |
||||
|
||||
while cap.isOpened(): |
||||
success, im0 = cap.read() |
||||
|
||||
if success: |
||||
tracks = model.track(im0, show=False, persist=True, |
||||
verbose=False, classes=0) # Only person class |
||||
out = queue.process_queue(im0, tracks) |
||||
|
||||
video_writer.write(im0) |
||||
if cv2.waitKey(1) & 0xFF == ord('q'): |
||||
break |
||||
continue |
||||
|
||||
print("Video frame is empty or video processing has been successfully completed.") |
||||
break |
||||
|
||||
cap.release() |
||||
cv2.destroyAllWindows() |
||||
``` |
||||
|
||||
### Optional Arguments `set_args` |
||||
|
||||
| Name | Type | Default | Description | |
||||
|---------------------|-------------|----------------------------|---------------------------------------------| |
||||
| `view_img` | `bool` | `False` | Display frames with counts | |
||||
| `view_queue_counts` | `bool` | `True` | Display Queue counts only on video frame | |
||||
| `line_thickness` | `int` | `2` | Increase bounding boxes thickness | |
||||
| `reg_pts` | `list` | `[(20, 400), (1260, 400)]` | Points defining the Region Area | |
||||
| `classes_names` | `dict` | `model.model.names` | Dictionary of Class Names | |
||||
| `region_color` | `RGB Color` | `(255, 0, 255)` | Color of the Object counting Region or Line | |
||||
| `track_thickness` | `int` | `2` | Thickness of Tracking Lines | |
||||
| `draw_tracks` | `bool` | `False` | Enable drawing Track lines | |
||||
| `track_color` | `RGB Color` | `(0, 255, 0)` | Color for each track line | |
||||
| `count_txt_color` | `RGB Color` | `(255, 255, 255)` | Foreground color for Object counts text | |
||||
| `region_thickness` | `int` | `5` | Thickness for object counter region or line | |
||||
| `fontsize` | `float` | `0.6` | Font size of counting text | |
||||
|
||||
### Arguments `model.track` |
||||
|
||||
| Name | Type | Default | Description | |
||||
|-----------|---------|----------------|-------------------------------------------------------------| |
||||
| `source` | `im0` | `None` | source directory for images or videos | |
||||
| `persist` | `bool` | `False` | persisting tracks between frames | |
||||
| `tracker` | `str` | `botsort.yaml` | Tracking method 'bytetrack' or 'botsort' | |
||||
| `conf` | `float` | `0.3` | Confidence Threshold | |
||||
| `iou` | `float` | `0.5` | IOU Threshold | |
||||
| `classes` | `list` | `None` | filter results by class, i.e. classes=0, or classes=[0,2,3] | |
||||
| `verbose` | `bool` | `True` | Display the object tracking results | |
||||
File diff suppressed because it is too large
Load Diff
@ -0,0 +1,38 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
# YOLOv9c-seg |
||||
# 654 layers, 27897120 parameters, 159.4 GFLOPs |
||||
|
||||
# parameters |
||||
nc: 80 # number of classes |
||||
|
||||
# gelan backbone |
||||
backbone: |
||||
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 |
||||
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 |
||||
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 1]] # 2 |
||||
- [-1, 1, ADown, [256]] # 3-P3/8 |
||||
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 1]] # 4 |
||||
- [-1, 1, ADown, [512]] # 5-P4/16 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]] # 6 |
||||
- [-1, 1, ADown, [512]] # 7-P5/32 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]] # 8 |
||||
- [-1, 1, SPPELAN, [512, 256]] # 9 |
||||
|
||||
head: |
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] |
||||
- [[-1, 6], 1, Concat, [1]] # cat backbone P4 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]] # 12 |
||||
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] |
||||
- [[-1, 4], 1, Concat, [1]] # cat backbone P3 |
||||
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 1]] # 15 (P3/8-small) |
||||
|
||||
- [-1, 1, ADown, [256]] |
||||
- [[-1, 12], 1, Concat, [1]] # cat head P4 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]] # 18 (P4/16-medium) |
||||
|
||||
- [-1, 1, ADown, [512]] |
||||
- [[-1, 9], 1, Concat, [1]] # cat head P5 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 1]] # 21 (P5/32-large) |
||||
|
||||
- [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5) |
||||
@ -0,0 +1,61 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
# YOLOv9c-seg |
||||
# 1261 layers, 60512800 parameters, 248.4 GFLOPs |
||||
|
||||
# parameters |
||||
nc: 80 # number of classes |
||||
|
||||
# gelan backbone |
||||
backbone: |
||||
- [-1, 1, Silence, []] |
||||
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2 |
||||
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4 |
||||
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 2]] # 3 |
||||
- [-1, 1, ADown, [256]] # 4-P3/8 |
||||
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 2]] # 5 |
||||
- [-1, 1, ADown, [512]] # 6-P4/16 |
||||
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 7 |
||||
- [-1, 1, ADown, [1024]] # 8-P5/32 |
||||
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 9 |
||||
|
||||
- [1, 1, CBLinear, [[64]]] # 10 |
||||
- [3, 1, CBLinear, [[64, 128]]] # 11 |
||||
- [5, 1, CBLinear, [[64, 128, 256]]] # 12 |
||||
- [7, 1, CBLinear, [[64, 128, 256, 512]]] # 13 |
||||
- [9, 1, CBLinear, [[64, 128, 256, 512, 1024]]] # 14 |
||||
|
||||
- [0, 1, Conv, [64, 3, 2]] # 15-P1/2 |
||||
- [[10, 11, 12, 13, 14, -1], 1, CBFuse, [[0, 0, 0, 0, 0]]] # 16 |
||||
- [-1, 1, Conv, [128, 3, 2]] # 17-P2/4 |
||||
- [[11, 12, 13, 14, -1], 1, CBFuse, [[1, 1, 1, 1]]] # 18 |
||||
- [-1, 1, RepNCSPELAN4, [256, 128, 64, 2]] # 19 |
||||
- [-1, 1, ADown, [256]] # 20-P3/8 |
||||
- [[12, 13, 14, -1], 1, CBFuse, [[2, 2, 2]]] # 21 |
||||
- [-1, 1, RepNCSPELAN4, [512, 256, 128, 2]] # 22 |
||||
- [-1, 1, ADown, [512]] # 23-P4/16 |
||||
- [[13, 14, -1], 1, CBFuse, [[3, 3]]] # 24 |
||||
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 25 |
||||
- [-1, 1, ADown, [1024]] # 26-P5/32 |
||||
- [[14, -1], 1, CBFuse, [[4]]] # 27 |
||||
- [-1, 1, RepNCSPELAN4, [1024, 512, 256, 2]] # 28 |
||||
- [-1, 1, SPPELAN, [512, 256]] # 29 |
||||
|
||||
# gelan head |
||||
head: |
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] |
||||
- [[-1, 25], 1, Concat, [1]] # cat backbone P4 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 2]] # 32 |
||||
|
||||
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] |
||||
- [[-1, 22], 1, Concat, [1]] # cat backbone P3 |
||||
- [-1, 1, RepNCSPELAN4, [256, 256, 128, 2]] # 35 (P3/8-small) |
||||
|
||||
- [-1, 1, ADown, [256]] |
||||
- [[-1, 32], 1, Concat, [1]] # cat head P4 |
||||
- [-1, 1, RepNCSPELAN4, [512, 512, 256, 2]] # 38 (P4/16-medium) |
||||
|
||||
- [-1, 1, ADown, [512]] |
||||
- [[-1, 29], 1, Concat, [1]] # cat head P5 |
||||
- [-1, 1, RepNCSPELAN4, [512, 1024, 512, 2]] # 41 (P5/32-large) |
||||
|
||||
- [[35, 38, 41], 1, Segment, [nc, 32, 256]] # Segment (P3, P4, P5) |
||||
@ -1,15 +1,26 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
|
||||
from .base import BaseDataset |
||||
from .build import build_dataloader, build_yolo_dataset, load_inference_source |
||||
from .dataset import ClassificationDataset, SemanticDataset, YOLODataset |
||||
from .build import build_dataloader, build_grounding, build_yolo_dataset, load_inference_source |
||||
from .dataset import ( |
||||
ClassificationDataset, |
||||
GroundingDataset, |
||||
SemanticDataset, |
||||
YOLOConcatDataset, |
||||
YOLODataset, |
||||
YOLOMultiModalDataset, |
||||
) |
||||
|
||||
__all__ = ( |
||||
"BaseDataset", |
||||
"ClassificationDataset", |
||||
"SemanticDataset", |
||||
"YOLODataset", |
||||
"YOLOMultiModalDataset", |
||||
"YOLOConcatDataset", |
||||
"GroundingDataset", |
||||
"build_yolo_dataset", |
||||
"build_grounding", |
||||
"build_dataloader", |
||||
"load_inference_source", |
||||
) |
||||
|
||||
@ -1,7 +1,7 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
|
||||
from ultralytics.models.yolo import classify, detect, obb, pose, segment |
||||
from ultralytics.models.yolo import classify, detect, obb, pose, segment, world |
||||
|
||||
from .model import YOLO, YOLOWorld |
||||
|
||||
__all__ = "classify", "segment", "detect", "pose", "obb", "YOLO", "YOLOWorld" |
||||
__all__ = "classify", "segment", "detect", "pose", "obb", "world", "YOLO", "YOLOWorld" |
||||
|
||||
@ -0,0 +1,5 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
|
||||
from .train import WorldTrainer |
||||
|
||||
__all__ = ["WorldTrainer"] |
||||
@ -0,0 +1,92 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
|
||||
import itertools |
||||
|
||||
from ultralytics.data import build_yolo_dataset |
||||
from ultralytics.models import yolo |
||||
from ultralytics.nn.tasks import WorldModel |
||||
from ultralytics.utils import DEFAULT_CFG, RANK, checks |
||||
from ultralytics.utils.torch_utils import de_parallel |
||||
|
||||
|
||||
def on_pretrain_routine_end(trainer): |
||||
"""Callback.""" |
||||
if RANK in {-1, 0}: |
||||
# NOTE: for evaluation |
||||
names = [name.split("/")[0] for name in list(trainer.test_loader.dataset.data["names"].values())] |
||||
de_parallel(trainer.ema.ema).set_classes(names, cache_clip_model=False) |
||||
device = next(trainer.model.parameters()).device |
||||
trainer.text_model, _ = trainer.clip.load("ViT-B/32", device=device) |
||||
for p in trainer.text_model.parameters(): |
||||
p.requires_grad_(False) |
||||
|
||||
|
||||
class WorldTrainer(yolo.detect.DetectionTrainer): |
||||
""" |
||||
A class to fine-tune a world model on a close-set dataset. |
||||
|
||||
Example: |
||||
```python |
||||
from ultralytics.models.yolo.world import WorldModel |
||||
|
||||
args = dict(model='yolov8s-world.pt', data='coco8.yaml', epochs=3) |
||||
trainer = WorldTrainer(overrides=args) |
||||
trainer.train() |
||||
``` |
||||
""" |
||||
|
||||
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None): |
||||
"""Initialize a WorldTrainer object with given arguments.""" |
||||
if overrides is None: |
||||
overrides = {} |
||||
super().__init__(cfg, overrides, _callbacks) |
||||
|
||||
# Import and assign clip |
||||
try: |
||||
import clip |
||||
except ImportError: |
||||
checks.check_requirements("git+https://github.com/ultralytics/CLIP.git") |
||||
import clip |
||||
self.clip = clip |
||||
|
||||
def get_model(self, cfg=None, weights=None, verbose=True): |
||||
"""Return WorldModel initialized with specified config and weights.""" |
||||
# NOTE: This `nc` here is the max number of different text samples in one image, rather than the actual `nc`. |
||||
# NOTE: Following the official config, nc hard-coded to 80 for now. |
||||
model = WorldModel( |
||||
cfg["yaml_file"] if isinstance(cfg, dict) else cfg, |
||||
ch=3, |
||||
nc=min(self.data["nc"], 80), |
||||
verbose=verbose and RANK == -1, |
||||
) |
||||
if weights: |
||||
model.load(weights) |
||||
self.add_callback("on_pretrain_routine_end", on_pretrain_routine_end) |
||||
|
||||
return model |
||||
|
||||
def build_dataset(self, img_path, mode="train", batch=None): |
||||
""" |
||||
Build YOLO Dataset. |
||||
|
||||
Args: |
||||
img_path (str): Path to the folder containing images. |
||||
mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode. |
||||
batch (int, optional): Size of batches, this is for `rect`. Defaults to None. |
||||
""" |
||||
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32) |
||||
return build_yolo_dataset( |
||||
self.args, img_path, batch, self.data, mode=mode, rect=mode == "val", stride=gs, multi_modal=mode == "train" |
||||
) |
||||
|
||||
def preprocess_batch(self, batch): |
||||
"""Preprocesses a batch of images for YOLOWorld training, adjusting formatting and dimensions as needed.""" |
||||
batch = super().preprocess_batch(batch) |
||||
|
||||
# NOTE: add text features |
||||
texts = list(itertools.chain(*batch["texts"])) |
||||
text_token = self.clip.tokenize(texts).to(batch["img"].device) |
||||
txt_feats = self.text_model.encode_text(text_token).to(dtype=batch["img"].dtype) # torch.float32 |
||||
txt_feats = txt_feats / txt_feats.norm(p=2, dim=-1, keepdim=True) |
||||
batch["txt_feats"] = txt_feats.reshape(len(batch["texts"]), -1, txt_feats.shape[-1]) |
||||
return batch |
||||
@ -0,0 +1,108 @@ |
||||
from ultralytics.data import YOLOConcatDataset, build_grounding, build_yolo_dataset |
||||
from ultralytics.data.utils import check_det_dataset |
||||
from ultralytics.models.yolo.world import WorldTrainer |
||||
from ultralytics.utils import DEFAULT_CFG |
||||
from ultralytics.utils.torch_utils import de_parallel |
||||
|
||||
|
||||
class WorldTrainerFromScratch(WorldTrainer): |
||||
""" |
||||
A class extending the WorldTrainer class for training a world model from scratch on open-set dataset. |
||||
|
||||
Example: |
||||
```python |
||||
from ultralytics.models.yolo.world.train_world import WorldTrainerFromScratch |
||||
from ultralytics import YOLOWorld |
||||
|
||||
data = dict( |
||||
train=dict( |
||||
yolo_data=["Objects365.yaml"], |
||||
grounding_data=[ |
||||
dict( |
||||
img_path="../datasets/flickr30k/images", |
||||
json_file="../datasets/flickr30k/final_flickr_separateGT_train.json", |
||||
), |
||||
dict( |
||||
img_path="../datasets/GQA/images", |
||||
json_file="../datasets/GQA/final_mixed_train_no_coco.json", |
||||
), |
||||
], |
||||
), |
||||
val=dict(yolo_data=["lvis.yaml"]), |
||||
) |
||||
|
||||
model = YOLOWorld("yolov8s-worldv2.yaml") |
||||
model.train(data=data, trainer=WorldTrainerFromScratch) |
||||
``` |
||||
""" |
||||
|
||||
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None): |
||||
"""Initialize a WorldTrainer object with given arguments.""" |
||||
if overrides is None: |
||||
overrides = {} |
||||
super().__init__(cfg, overrides, _callbacks) |
||||
|
||||
def build_dataset(self, img_path, mode="train", batch=None): |
||||
""" |
||||
Build YOLO Dataset. |
||||
|
||||
Args: |
||||
img_path (List[str] | str): Path to the folder containing images. |
||||
mode (str): `train` mode or `val` mode, users are able to customize different augmentations for each mode. |
||||
batch (int, optional): Size of batches, this is for `rect`. Defaults to None. |
||||
""" |
||||
gs = max(int(de_parallel(self.model).stride.max() if self.model else 0), 32) |
||||
if mode == "train": |
||||
dataset = [ |
||||
build_yolo_dataset(self.args, im_path, batch, self.data, stride=gs, multi_modal=True) |
||||
if isinstance(im_path, str) |
||||
else build_grounding(self.args, im_path["img_path"], im_path["json_file"], batch, stride=gs) |
||||
for im_path in img_path |
||||
] |
||||
return YOLOConcatDataset(dataset) if len(dataset) > 1 else dataset[0] |
||||
else: |
||||
return build_yolo_dataset(self.args, img_path, batch, self.data, mode=mode, rect=mode == "val", stride=gs) |
||||
|
||||
def get_dataset(self): |
||||
""" |
||||
Get train, val path from data dict if it exists. |
||||
|
||||
Returns None if data format is not recognized. |
||||
""" |
||||
final_data = dict() |
||||
data_yaml = self.args.data |
||||
assert data_yaml.get("train", False) # object365.yaml |
||||
assert data_yaml.get("val", False) # lvis.yaml |
||||
data = {k: [check_det_dataset(d) for d in v.get("yolo_data", [])] for k, v in data_yaml.items()} |
||||
assert len(data["val"]) == 1, f"Only support validating on 1 dataset for now, but got {len(data['val'])}." |
||||
val_split = "minival" if "lvis" in data["val"][0]["val"] else "val" |
||||
for d in data["val"]: |
||||
if d.get("minival") is None: # for lvis dataset |
||||
continue |
||||
d["minival"] = str(d["path"] / d["minival"]) |
||||
for s in ["train", "val"]: |
||||
final_data[s] = [d["train" if s == "train" else val_split] for d in data[s]] |
||||
# save grounding data if there's one |
||||
grounding_data = data_yaml[s].get("grounding_data") |
||||
if grounding_data is None: |
||||
continue |
||||
grounding_data = [grounding_data] if not isinstance(grounding_data, list) else grounding_data |
||||
for g in grounding_data: |
||||
assert isinstance(g, dict), f"Grounding data should be provided in dict format, but got {type(g)}" |
||||
final_data[s] += grounding_data |
||||
# NOTE: to make training work properly, set `nc` and `names` |
||||
final_data["nc"] = data["val"][0]["nc"] |
||||
final_data["names"] = data["val"][0]["names"] |
||||
self.data = final_data |
||||
return final_data["train"], final_data["val"][0] |
||||
|
||||
def plot_training_labels(self): |
||||
"""DO NOT plot labels.""" |
||||
pass |
||||
|
||||
def final_eval(self): |
||||
"""Performs final evaluation and validation for object detection YOLO-World model.""" |
||||
val = self.args.data["val"]["yolo_data"][0] |
||||
self.validator.args.data = val |
||||
self.validator.args.split = "minival" if isinstance(val, str) and "lvis" in val else "val" |
||||
return super().final_eval() |
||||
@ -0,0 +1,187 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
|
||||
from collections import defaultdict |
||||
|
||||
import cv2 |
||||
|
||||
from ultralytics.utils.checks import check_imshow, check_requirements |
||||
from ultralytics.utils.plotting import Annotator, colors |
||||
|
||||
check_requirements("shapely>=2.0.0") |
||||
|
||||
from shapely.geometry import Point, Polygon |
||||
|
||||
|
||||
class QueueManager: |
||||
"""A class to manage the queue management in real-time video stream based on their tracks.""" |
||||
|
||||
def __init__(self): |
||||
"""Initializes the queue manager with default values for various tracking and counting parameters.""" |
||||
|
||||
# Mouse events |
||||
self.is_drawing = False |
||||
self.selected_point = None |
||||
|
||||
# Region & Line Information |
||||
self.reg_pts = [(20, 60), (20, 680), (1120, 680), (1120, 60)] |
||||
self.counting_region = None |
||||
self.region_color = (255, 0, 255) |
||||
self.region_thickness = 5 |
||||
|
||||
# Image and annotation Information |
||||
self.im0 = None |
||||
self.tf = None |
||||
self.view_img = False |
||||
self.view_queue_counts = True |
||||
self.fontsize = 0.6 |
||||
|
||||
self.names = None # Classes names |
||||
self.annotator = None # Annotator |
||||
self.window_name = "Ultralytics YOLOv8 Queue Manager" |
||||
|
||||
# Object counting Information |
||||
self.counts = 0 |
||||
self.count_txt_color = (255, 255, 255) |
||||
|
||||
# Tracks info |
||||
self.track_history = defaultdict(list) |
||||
self.track_thickness = 2 |
||||
self.draw_tracks = False |
||||
self.track_color = None |
||||
|
||||
# Check if environment support imshow |
||||
self.env_check = check_imshow(warn=True) |
||||
|
||||
def set_args( |
||||
self, |
||||
classes_names, |
||||
reg_pts, |
||||
line_thickness=2, |
||||
track_thickness=2, |
||||
view_img=False, |
||||
region_color=(255, 0, 255), |
||||
view_queue_counts=True, |
||||
draw_tracks=False, |
||||
count_txt_color=(255, 255, 255), |
||||
track_color=None, |
||||
region_thickness=5, |
||||
fontsize=0.7, |
||||
): |
||||
""" |
||||
Configures the Counter's image, bounding box line thickness, and counting region points. |
||||
|
||||
Args: |
||||
line_thickness (int): Line thickness for bounding boxes. |
||||
view_img (bool): Flag to control whether to display the video stream. |
||||
view_queue_counts (bool): Flag to control whether to display the counts on video stream. |
||||
reg_pts (list): Initial list of points defining the counting region. |
||||
classes_names (dict): Classes names |
||||
region_color (RGB color): Color of queue region |
||||
track_thickness (int): Track thickness |
||||
draw_tracks (Bool): draw tracks |
||||
count_txt_color (RGB color): count text color value |
||||
track_color (RGB color): color for tracks |
||||
region_thickness (int): Object counting Region thickness |
||||
fontsize (float): Text display font size |
||||
""" |
||||
self.tf = line_thickness |
||||
self.view_img = view_img |
||||
self.view_queue_counts = view_queue_counts |
||||
self.track_thickness = track_thickness |
||||
self.draw_tracks = draw_tracks |
||||
self.region_color = region_color |
||||
|
||||
if len(reg_pts) >= 3: |
||||
print("Queue region initiated...") |
||||
self.reg_pts = reg_pts |
||||
self.counting_region = Polygon(self.reg_pts) |
||||
else: |
||||
print("Invalid region points provided...") |
||||
print("Using default region now....") |
||||
self.counting_region = Polygon(self.reg_pts) |
||||
|
||||
self.names = classes_names |
||||
self.track_color = track_color |
||||
self.count_txt_color = count_txt_color |
||||
self.region_thickness = region_thickness |
||||
self.fontsize = fontsize |
||||
|
||||
def extract_and_process_tracks(self, tracks): |
||||
"""Extracts and processes tracks for queue management in a video stream.""" |
||||
|
||||
# Annotator Init and queue region drawing |
||||
self.annotator = Annotator(self.im0, self.tf, self.names) |
||||
|
||||
if tracks[0].boxes.id is not None: |
||||
boxes = tracks[0].boxes.xyxy.cpu() |
||||
clss = tracks[0].boxes.cls.cpu().tolist() |
||||
track_ids = tracks[0].boxes.id.int().cpu().tolist() |
||||
|
||||
# Extract tracks |
||||
for box, track_id, cls in zip(boxes, track_ids, clss): |
||||
# Draw bounding box |
||||
self.annotator.box_label(box, label=f"{self.names[cls]}#{track_id}", color=colors(int(track_id), True)) |
||||
|
||||
# Draw Tracks |
||||
track_line = self.track_history[track_id] |
||||
track_line.append((float((box[0] + box[2]) / 2), float((box[1] + box[3]) / 2))) |
||||
if len(track_line) > 30: |
||||
track_line.pop(0) |
||||
|
||||
# Draw track trails |
||||
if self.draw_tracks: |
||||
self.annotator.draw_centroid_and_tracks( |
||||
track_line, |
||||
color=self.track_color if self.track_color else colors(int(track_id), True), |
||||
track_thickness=self.track_thickness, |
||||
) |
||||
|
||||
prev_position = self.track_history[track_id][-2] if len(self.track_history[track_id]) > 1 else None |
||||
|
||||
if len(self.reg_pts) >= 3: |
||||
is_inside = self.counting_region.contains(Point(track_line[-1])) |
||||
if prev_position is not None and is_inside: |
||||
self.counts += 1 |
||||
|
||||
label = "Queue Counts : " + str(self.counts) |
||||
|
||||
if label is not None: |
||||
self.annotator.queue_counts_display( |
||||
label, |
||||
points=self.reg_pts, |
||||
region_color=self.region_color, |
||||
txt_color=self.count_txt_color, |
||||
fontsize=self.fontsize, |
||||
) |
||||
|
||||
self.counts = 0 |
||||
self.display_frames() |
||||
|
||||
def display_frames(self): |
||||
"""Display frame.""" |
||||
if self.env_check: |
||||
self.annotator.draw_region(reg_pts=self.reg_pts, thickness=self.region_thickness, color=self.region_color) |
||||
cv2.namedWindow(self.window_name) |
||||
cv2.imshow(self.window_name, self.im0) |
||||
# Break Window |
||||
if cv2.waitKey(1) & 0xFF == ord("q"): |
||||
return |
||||
|
||||
def process_queue(self, im0, tracks): |
||||
""" |
||||
Main function to start the queue management process. |
||||
|
||||
Args: |
||||
im0 (ndarray): Current frame from the video stream. |
||||
tracks (list): List of tracks obtained from the object tracking process. |
||||
""" |
||||
self.im0 = im0 # store image |
||||
self.extract_and_process_tracks(tracks) # draw region even if no objects |
||||
|
||||
if self.view_img: |
||||
self.display_frames() |
||||
return self.im0 |
||||
|
||||
|
||||
if __name__ == "__main__": |
||||
QueueManager() |
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in new issue