diff --git a/docs/en/datasets/classify/caltech101.md b/docs/en/datasets/classify/caltech101.md
index b50a51916b..51faa4957c 100644
--- a/docs/en/datasets/classify/caltech101.md
+++ b/docs/en/datasets/classify/caltech101.md
@@ -22,7 +22,7 @@ Unlike many other datasets, the Caltech-101 dataset is not formally split into t
## Applications
-The Caltech-101 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its wide variety of categories and high-quality images make it an excellent dataset for research and development in the field of machine learning and computer vision.
+The Caltech-101 dataset is extensively used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object recognition tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its wide variety of categories and high-quality images make it an excellent dataset for research and development in the field of machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv).
## Usage
@@ -84,11 +84,11 @@ We would like to acknowledge Li Fei-Fei, Rob Fergus, and Pietro Perona for creat
### What is the Caltech-101 dataset used for in machine learning?
-The [Caltech-101](https://data.caltech.edu/records/mzrjq-6wc02) dataset is widely used in machine learning for object recognition tasks. It contains around 9,000 images across 101 categories, providing a challenging benchmark for evaluating object recognition algorithms. Researchers leverage it to train and test models, especially Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs), in computer vision.
+The [Caltech-101](https://data.caltech.edu/records/mzrjq-6wc02) dataset is widely used in machine learning for object recognition tasks. It contains around 9,000 images across 101 categories, providing a challenging benchmark for evaluating object recognition algorithms. Researchers leverage it to train and test models, especially Convolutional [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) (CNNs) and [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs), in computer vision.
### How can I train an Ultralytics YOLO model on the Caltech-101 dataset?
-To train an Ultralytics YOLO model on the Caltech-101 dataset, you can use the provided code snippets. For example, to train for 100 epochs:
+To train an Ultralytics YOLO model on the Caltech-101 dataset, you can use the provided code snippets. For example, to train for 100 [epochs](https://www.ultralytics.com/glossary/epoch):
!!! example "Train Example"
@@ -122,7 +122,7 @@ The Caltech-101 dataset includes:
- Variable number of images per category, typically between 40 and 800.
- Variable image sizes, with most being medium resolution.
-These features make it an excellent choice for training and evaluating object recognition models in machine learning and computer vision.
+These features make it an excellent choice for training and evaluating object recognition models in [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision.
### Why should I cite the Caltech-101 dataset in my research?
diff --git a/docs/en/datasets/classify/caltech256.md b/docs/en/datasets/classify/caltech256.md
index c337721009..de7c2ea461 100644
--- a/docs/en/datasets/classify/caltech256.md
+++ b/docs/en/datasets/classify/caltech256.md
@@ -16,7 +16,7 @@ The [Caltech-256](https://data.caltech.edu/records/nyy15-4j048) dataset is an ex
allowfullscreen>
- Watch: How to Train Image Classification Model using Caltech-256 Dataset with Ultralytics HUB
+ Watch: How to Train [Image Classification](https://www.ultralytics.com/glossary/image-classification) Model using Caltech-256 Dataset with Ultralytics HUB
## Key Features
@@ -33,7 +33,7 @@ Like Caltech-101, the Caltech-256 dataset does not have a formal split between t
## Applications
-The Caltech-256 dataset is extensively used for training and evaluating deep learning models in object recognition tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its diverse set of categories and high-quality images make it an invaluable dataset for research and development in the field of machine learning and computer vision.
+The Caltech-256 dataset is extensively used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object recognition tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. Its diverse set of categories and high-quality images make it an invaluable dataset for research and development in the field of machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv).
## Usage
@@ -84,7 +84,7 @@ If you use the Caltech-256 dataset in your research or development work, please
}
```
-We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the
+We would like to acknowledge Gregory Griffin, Alex Holub, and Pietro Perona for creating and maintaining the Caltech-256 dataset as a valuable resource for the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision research community. For more information about the
Caltech-256 dataset and its creators, visit the [Caltech-256 dataset website](https://data.caltech.edu/records/nyy15-4j048).
@@ -96,7 +96,7 @@ The [Caltech-256](https://data.caltech.edu/records/nyy15-4j048) dataset is a lar
### How can I train a YOLO model on the Caltech-256 dataset using Python or CLI?
-To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the following code snippets. Refer to the model [Training](../../modes/train.md) page for additional options.
+To train a YOLO model on the Caltech-256 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch), you can use the following code snippets. Refer to the model [Training](../../modes/train.md) page for additional options.
!!! example "Train Example"
@@ -123,10 +123,10 @@ To train a YOLO model on the Caltech-256 dataset for 100 epochs, you can use the
The Caltech-256 dataset is widely used for various object recognition tasks such as:
-- Training Convolutional Neural Networks (CNNs)
-- Evaluating the performance of Support Vector Machines (SVMs)
+- Training Convolutional [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) (CNNs)
+- Evaluating the performance of [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs)
- Benchmarking new deep learning algorithms
-- Developing object detection models using frameworks like Ultralytics YOLO
+- Developing [object detection](https://www.ultralytics.com/glossary/object-detection) models using frameworks like Ultralytics YOLO
Its diversity and comprehensive annotations make it ideal for research and development in machine learning and computer vision.
@@ -141,6 +141,6 @@ Ultralytics YOLO models offer several advantages for training on the Caltech-256
- **High Accuracy**: YOLO models are known for their state-of-the-art performance in object detection tasks.
- **Speed**: They provide real-time inference capabilities, making them suitable for applications requiring quick predictions.
- **Ease of Use**: With Ultralytics HUB, users can train, validate, and deploy models without extensive coding.
-- **Pretrained Models**: Starting from pretrained models, like `yolov8n-cls.pt`, can significantly reduce training time and improve model accuracy.
+- **Pretrained Models**: Starting from pretrained models, like `yolov8n-cls.pt`, can significantly reduce training time and improve model [accuracy](https://www.ultralytics.com/glossary/accuracy).
For more details, explore our [comprehensive training guide](../../modes/train.md).
diff --git a/docs/en/datasets/classify/cifar10.md b/docs/en/datasets/classify/cifar10.md
index 865c80865f..7bae78b38a 100644
--- a/docs/en/datasets/classify/cifar10.md
+++ b/docs/en/datasets/classify/cifar10.md
@@ -6,7 +6,7 @@ keywords: CIFAR-10, dataset, machine learning, computer vision, image classifica
# CIFAR-10 Dataset
-The [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a collection of images used widely for machine learning and computer vision algorithms. It was developed by researchers at the CIFAR institute and consists of 60,000 32x32 color images in 10 different classes.
+The [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a collection of images used widely for [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision algorithms. It was developed by researchers at the CIFAR institute and consists of 60,000 32x32 color images in 10 different classes.
@@ -16,7 +16,7 @@ The [CIFAR-10](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute
allowfullscreen>
- Watch: How to Train an Image Classification Model with CIFAR-10 Dataset using Ultralytics YOLOv8
+ Watch: How to Train an [Image Classification](https://www.ultralytics.com/glossary/image-classification) Model with CIFAR-10 Dataset using Ultralytics YOLOv8
## Key Features
@@ -36,7 +36,7 @@ The CIFAR-10 dataset is split into two subsets:
## Applications
-The CIFAR-10 dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a well-rounded dataset for research and development in the field of machine learning and computer vision.
+The CIFAR-10 dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in image classification tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a well-rounded dataset for research and development in the field of machine learning and computer vision.
## Usage
@@ -88,13 +88,13 @@ If you use the CIFAR-10 dataset in your research or development work, please cit
}
```
-We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
+We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-10 dataset as a valuable resource for the machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) research community. For more information about the CIFAR-10 dataset and its creator, visit the [CIFAR-10 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
## FAQ
### How can I train a YOLO model on the CIFAR-10 dataset?
-To train a YOLO model on the CIFAR-10 dataset using Ultralytics, you can follow the examples provided for both Python and CLI. Here is a basic example to train your model for 100 epochs with an image size of 32x32 pixels:
+To train a YOLO model on the CIFAR-10 dataset using Ultralytics, you can follow the examples provided for both Python and CLI. Here is a basic example to train your model for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 32x32 pixels:
!!! example
@@ -138,7 +138,7 @@ This diverse dataset is essential for training image classification models in fi
### Why use the CIFAR-10 dataset for image classification tasks?
-The CIFAR-10 dataset is an excellent benchmark for image classification due to its diversity and structure. It contains a balanced mix of 60,000 labeled images across 10 different categories, which helps in training robust and generalized models. It is widely used for evaluating deep learning models, including Convolutional Neural Networks (CNNs) and other machine learning algorithms. The dataset is relatively small, making it suitable for quick experimentation and algorithm development. Explore its numerous applications in the [applications](#applications) section.
+The CIFAR-10 dataset is an excellent benchmark for image classification due to its diversity and structure. It contains a balanced mix of 60,000 labeled images across 10 different categories, which helps in training robust and generalized models. It is widely used for evaluating deep learning models, including Convolutional [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) (CNNs) and other machine learning algorithms. The dataset is relatively small, making it suitable for quick experimentation and algorithm development. Explore its numerous applications in the [applications](#applications) section.
### How is the CIFAR-10 dataset structured?
@@ -170,4 +170,4 @@ Acknowledging the dataset's creators helps support continued research and develo
### What are some practical examples of using the CIFAR-10 dataset?
-The CIFAR-10 dataset is often used for training image classification models, such as Convolutional Neural Networks (CNNs) and Support Vector Machines (SVMs). These models can be employed in various computer vision tasks including object detection, image recognition, and automated tagging. To see some practical examples, check the code snippets in the [usage](#usage) section.
+The CIFAR-10 dataset is often used for training image classification models, such as Convolutional Neural Networks (CNNs) and [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs). These models can be employed in various computer vision tasks including [object detection](https://www.ultralytics.com/glossary/object-detection), [image recognition](https://www.ultralytics.com/glossary/image-recognition), and automated tagging. To see some practical examples, check the code snippets in the [usage](#usage) section.
diff --git a/docs/en/datasets/classify/cifar100.md b/docs/en/datasets/classify/cifar100.md
index ca868240f7..a6735bbcc4 100644
--- a/docs/en/datasets/classify/cifar100.md
+++ b/docs/en/datasets/classify/cifar100.md
@@ -6,7 +6,7 @@ keywords: CIFAR-100, dataset, machine learning, computer vision, image classific
# CIFAR-100 Dataset
-The [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a significant extension of the CIFAR-10 dataset, composed of 60,000 32x32 color images in 100 different classes. It was developed by researchers at the CIFAR institute, offering a more challenging dataset for more complex machine learning and computer vision tasks.
+The [CIFAR-100](https://www.cs.toronto.edu/~kriz/cifar.html) (Canadian Institute For Advanced Research) dataset is a significant extension of the CIFAR-10 dataset, composed of 60,000 32x32 color images in 100 different classes. It was developed by researchers at the CIFAR institute, offering a more challenging dataset for more complex machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks.
## Key Features
@@ -25,11 +25,11 @@ The CIFAR-100 dataset is split into two subsets:
## Applications
-The CIFAR-100 dataset is extensively used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a more challenging and comprehensive dataset for research and development in the field of machine learning and computer vision.
+The CIFAR-100 dataset is extensively used for training and evaluating deep learning models in image classification tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The diversity of the dataset in terms of classes and the presence of color images make it a more challenging and comprehensive dataset for research and development in the field of machine learning and computer vision.
## Usage
-To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLO model on the CIFAR-100 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -54,7 +54,7 @@ To train a YOLO model on the CIFAR-100 dataset for 100 epochs with an image size
## Sample Images and Annotations
-The CIFAR-100 dataset contains color images of various objects, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+The CIFAR-100 dataset contains color images of various objects, providing a well-structured dataset for [image classification](https://www.ultralytics.com/glossary/image-classification) tasks. Here are some examples of images from the dataset:

@@ -77,13 +77,13 @@ If you use the CIFAR-100 dataset in your research or development work, please ci
}
```
-We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the machine learning and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
+We would like to acknowledge Alex Krizhevsky for creating and maintaining the CIFAR-100 dataset as a valuable resource for the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision research community. For more information about the CIFAR-100 dataset and its creator, visit the [CIFAR-100 dataset website](https://www.cs.toronto.edu/~kriz/cifar.html).
## FAQ
### What is the CIFAR-100 dataset and why is it significant?
-The [CIFAR-100 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) is a large collection of 60,000 32x32 color images classified into 100 classes. Developed by the Canadian Institute For Advanced Research (CIFAR), it provides a challenging dataset ideal for complex machine learning and computer vision tasks. Its significance lies in the diversity of classes and the small size of the images, making it a valuable resource for training and testing deep learning models, like Convolutional Neural Networks (CNNs), using frameworks such as Ultralytics YOLO.
+The [CIFAR-100 dataset](https://www.cs.toronto.edu/~kriz/cifar.html) is a large collection of 60,000 32x32 color images classified into 100 classes. Developed by the Canadian Institute For Advanced Research (CIFAR), it provides a challenging dataset ideal for complex machine learning and computer vision tasks. Its significance lies in the diversity of classes and the small size of the images, making it a valuable resource for training and testing deep learning models, like Convolutional [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) (CNNs), using frameworks such as Ultralytics YOLO.
### How do I train a YOLO model on the CIFAR-100 dataset?
@@ -114,7 +114,7 @@ For a comprehensive list of available arguments, please refer to the model [Trai
### What are the primary applications of the CIFAR-100 dataset?
-The CIFAR-100 dataset is extensively used in training and evaluating deep learning models for image classification. Its diverse set of 100 classes, grouped into 20 coarse categories, provides a challenging environment for testing algorithms such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning approaches. This dataset is a key resource in research and development within machine learning and computer vision fields.
+The CIFAR-100 dataset is extensively used in training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models for image classification. Its diverse set of 100 classes, grouped into 20 coarse categories, provides a challenging environment for testing algorithms such as Convolutional Neural Networks (CNNs), [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs), and various other machine learning approaches. This dataset is a key resource in research and development within machine learning and computer vision fields.
### How is the CIFAR-100 dataset structured?
diff --git a/docs/en/datasets/classify/fashion-mnist.md b/docs/en/datasets/classify/fashion-mnist.md
index d1c87e2676..531cd2c1bd 100644
--- a/docs/en/datasets/classify/fashion-mnist.md
+++ b/docs/en/datasets/classify/fashion-mnist.md
@@ -6,7 +6,7 @@ keywords: Fashion-MNIST, image classification, Zalando dataset, machine learning
# Fashion-MNIST Dataset
-The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is a database of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Fashion-MNIST is intended to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms.
+The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is a database of Zalando's article images—consisting of a training set of 60,000 examples and a test set of 10,000 examples. Each example is a 28x28 grayscale image, associated with a label from 10 classes. Fashion-MNIST is intended to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) algorithms.
@@ -16,7 +16,7 @@ The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is
allowfullscreen>
- Watch: How to do Image Classification on Fashion MNIST Dataset using Ultralytics YOLOv8
+ Watch: How to do [Image Classification](https://www.ultralytics.com/glossary/image-classification) on Fashion MNIST Dataset using Ultralytics YOLOv8
## Key Features
@@ -50,11 +50,11 @@ Each training and test example is assigned to one of the following labels:
## Applications
-The Fashion-MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
+The Fashion-MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
## Usage
-To train a CNN model on the Fashion-MNIST dataset for 100 epochs with an image size of 28x28, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a CNN model on the Fashion-MNIST dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 28x28, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -124,7 +124,7 @@ For more detailed training parameters, refer to the [Training page](../../modes/
### Why should I use the Fashion-MNIST dataset for benchmarking my machine learning models?
-The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is widely recognized in the deep learning community as a robust alternative to MNIST. It offers a more complex and varied set of images, making it an excellent choice for benchmarking image classification models. The dataset's structure, comprising 60,000 training images and 10,000 testing images, each labeled with one of 10 classes, makes it ideal for evaluating the performance of different machine learning algorithms in a more challenging context.
+The [Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset is widely recognized in the [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) community as a robust alternative to MNIST. It offers a more complex and varied set of images, making it an excellent choice for benchmarking image classification models. The dataset's structure, comprising 60,000 training images and 10,000 testing images, each labeled with one of 10 classes, makes it ideal for evaluating the performance of different machine learning algorithms in a more challenging context.
### Can I use Ultralytics YOLO for image classification tasks like Fashion-MNIST?
@@ -132,7 +132,7 @@ Yes, Ultralytics YOLO models can be used for image classification tasks, includi
### What are the key features and structure of the Fashion-MNIST dataset?
-The Fashion-MNIST dataset is divided into two main subsets: 60,000 training images and 10,000 testing images. Each image is a 28x28-pixel grayscale picture representing one of 10 fashion-related classes. The simplicity and well-structured format make it ideal for training and evaluating models in machine learning and computer vision tasks. For more details on the dataset structure, see the [Dataset Structure section](#dataset-structure).
+The Fashion-MNIST dataset is divided into two main subsets: 60,000 training images and 10,000 testing images. Each image is a 28x28-pixel grayscale picture representing one of 10 fashion-related classes. The simplicity and well-structured format make it ideal for training and evaluating models in machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks. For more details on the dataset structure, see the [Dataset Structure section](#dataset-structure).
### How can I acknowledge the use of the Fashion-MNIST dataset in my research?
diff --git a/docs/en/datasets/classify/imagenet.md b/docs/en/datasets/classify/imagenet.md
index 8c4102caf8..76e59b3f18 100644
--- a/docs/en/datasets/classify/imagenet.md
+++ b/docs/en/datasets/classify/imagenet.md
@@ -6,7 +6,7 @@ keywords: ImageNet, deep learning, visual recognition, computer vision, pretrain
# ImageNet Dataset
-[ImageNet](https://www.image-net.org/) is a large-scale database of annotated images designed for use in visual object recognition research. It contains over 14 million images, with each image annotated using WordNet synsets, making it one of the most extensive resources available for training deep learning models in computer vision tasks.
+[ImageNet](https://www.image-net.org/) is a large-scale database of annotated images designed for use in visual object recognition research. It contains over 14 million images, with each image annotated using WordNet synsets, making it one of the most extensive resources available for training [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks.
## ImageNet Pretrained Models
@@ -22,7 +22,7 @@ keywords: ImageNet, deep learning, visual recognition, computer vision, pretrain
- ImageNet contains over 14 million high-resolution images spanning thousands of object categories.
- The dataset is organized according to the WordNet hierarchy, with each synset representing a category.
-- ImageNet is widely used for training and benchmarking in the field of computer vision, particularly for image classification and object detection tasks.
+- ImageNet is widely used for training and benchmarking in the field of computer vision, particularly for [image classification](https://www.ultralytics.com/glossary/image-classification) and [object detection](https://www.ultralytics.com/glossary/object-detection) tasks.
- The annual ImageNet Large Scale Visual Recognition Challenge (ILSVRC) has been instrumental in advancing computer vision research.
## Dataset Structure
@@ -39,7 +39,7 @@ The ImageNet dataset is widely used for training and evaluating deep learning mo
## Usage
-To train a deep learning model on the ImageNet dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a deep learning model on the ImageNet dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -90,7 +90,7 @@ If you use the ImageNet dataset in your research or development work, please cit
}
```
-We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
+We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset as a valuable resource for the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
## FAQ
@@ -127,7 +127,7 @@ For more in-depth training instruction, refer to our [Training page](../../modes
### Why should I use the Ultralytics YOLOv8 pretrained models for my ImageNet dataset projects?
-Ultralytics YOLOv8 pretrained models offer state-of-the-art performance in terms of speed and accuracy for various computer vision tasks. For example, the YOLOv8n-cls model, with a top-1 accuracy of 69.0% and a top-5 accuracy of 88.3%, is optimized for real-time applications. Pretrained models reduce the computational resources required for training from scratch and accelerate development cycles. Learn more about the performance metrics of YOLOv8 models in the [ImageNet Pretrained Models section](#imagenet-pretrained-models).
+Ultralytics YOLOv8 pretrained models offer state-of-the-art performance in terms of speed and [accuracy](https://www.ultralytics.com/glossary/accuracy) for various computer vision tasks. For example, the YOLOv8n-cls model, with a top-1 accuracy of 69.0% and a top-5 accuracy of 88.3%, is optimized for real-time applications. Pretrained models reduce the computational resources required for training from scratch and accelerate development cycles. Learn more about the performance metrics of YOLOv8 models in the [ImageNet Pretrained Models section](#imagenet-pretrained-models).
### How is the ImageNet dataset structured, and why is it important?
@@ -135,4 +135,4 @@ The ImageNet dataset is organized using the WordNet hierarchy, where each node i
### What role does the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) play in computer vision?
-The annual [ImageNet Large Scale Visual Recognition Challenge (ILSVRC)](https://image-net.org/challenges/LSVRC/) has been pivotal in driving advancements in computer vision by providing a competitive platform for evaluating algorithms on a large-scale, standardized dataset. It offers standardized evaluation metrics, fostering innovation and development in areas such as image classification, object detection, and image segmentation. The challenge has continuously pushed the boundaries of what is possible with deep learning and computer vision technologies.
+The annual [ImageNet Large Scale Visual Recognition Challenge (ILSVRC)](https://image-net.org/challenges/LSVRC/) has been pivotal in driving advancements in computer vision by providing a competitive platform for evaluating algorithms on a large-scale, standardized dataset. It offers standardized evaluation metrics, fostering innovation and development in areas such as image classification, object detection, and [image segmentation](https://www.ultralytics.com/glossary/image-segmentation). The challenge has continuously pushed the boundaries of what is possible with deep learning and computer vision technologies.
diff --git a/docs/en/datasets/classify/imagenet10.md b/docs/en/datasets/classify/imagenet10.md
index b74e2a7a62..4e40e6655f 100644
--- a/docs/en/datasets/classify/imagenet10.md
+++ b/docs/en/datasets/classify/imagenet10.md
@@ -12,7 +12,7 @@ The [ImageNet10](https://github.com/ultralytics/assets/releases/download/v0.0.0/
- ImageNet10 is a compact version of ImageNet, with 20 images representing the first 10 classes of the original dataset.
- The dataset is organized according to the WordNet hierarchy, mirroring the structure of the full ImageNet dataset.
-- It is ideally suited for CI tests, sanity checks, and rapid testing of training pipelines in computer vision tasks.
+- It is ideally suited for CI tests, sanity checks, and rapid testing of training pipelines in [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks.
- Although not designed for model benchmarking, it can provide a quick indication of a model's basic functionality and correctness.
## Dataset Structure
@@ -74,7 +74,7 @@ If you use the ImageNet10 dataset in your research or development work, please c
}
```
-We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the machine learning and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
+We would like to acknowledge the ImageNet team, led by Olga Russakovsky, Jia Deng, and Li Fei-Fei, for creating and maintaining the ImageNet dataset. The ImageNet10 dataset, while a compact subset, is a valuable resource for quick testing and debugging in the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision research community. For more information about the ImageNet dataset and its creators, visit the [ImageNet website](https://www.image-net.org/).
## FAQ
@@ -111,7 +111,7 @@ Refer to the [Training](../../modes/train.md) page for a comprehensive list of a
### Why should I use the ImageNet10 dataset for CI tests and sanity checks?
-The ImageNet10 dataset is designed specifically for CI tests, sanity checks, and quick evaluations in deep learning pipelines. Its small size allows for rapid iteration and testing, making it perfect for continuous integration processes where speed is crucial. By maintaining the structural complexity and diversity of the original ImageNet dataset, ImageNet10 provides a reliable indication of a model's basic functionality and correctness without the overhead of processing a large dataset.
+The ImageNet10 dataset is designed specifically for CI tests, sanity checks, and quick evaluations in [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) pipelines. Its small size allows for rapid iteration and testing, making it perfect for continuous integration processes where speed is crucial. By maintaining the structural complexity and diversity of the original ImageNet dataset, ImageNet10 provides a reliable indication of a model's basic functionality and correctness without the overhead of processing a large dataset.
### What are the main features of the ImageNet10 dataset?
diff --git a/docs/en/datasets/classify/imagenette.md b/docs/en/datasets/classify/imagenette.md
index 42368a672a..bf371502ad 100644
--- a/docs/en/datasets/classify/imagenette.md
+++ b/docs/en/datasets/classify/imagenette.md
@@ -23,7 +23,7 @@ The ImageNette dataset is split into two subsets:
## Applications
-The ImageNette dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), and various other machine learning algorithms. The dataset's straightforward format and well-chosen classes make it a handy resource for both beginner and experienced practitioners in the field of machine learning and computer vision.
+The ImageNette dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in image classification tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), and various other machine learning algorithms. The dataset's straightforward format and well-chosen classes make it a handy resource for both beginner and experienced practitioners in the field of machine learning and computer vision.
## Usage
@@ -52,7 +52,7 @@ To train a model on the ImageNette dataset for 100 epochs with a standard image
## Sample Images and Annotations
-The ImageNette dataset contains colored images of various objects and scenes, providing a diverse dataset for image classification tasks. Here are some examples of images from the dataset:
+The ImageNette dataset contains colored images of various objects and scenes, providing a diverse dataset for [image classification](https://www.ultralytics.com/glossary/image-classification) tasks. Here are some examples of images from the dataset:

@@ -116,11 +116,11 @@ If you use the ImageNette dataset in your research or development work, please a
### What is the ImageNette dataset?
-The [ImageNette dataset](https://github.com/fastai/imagenette) is a simplified subset of the larger [ImageNet dataset](https://www.image-net.org/), featuring only 10 easily distinguishable classes such as tench, English springer, and French horn. It was created to offer a more manageable dataset for efficient training and evaluation of image classification models. This dataset is particularly useful for quick software development and educational purposes in machine learning and computer vision.
+The [ImageNette dataset](https://github.com/fastai/imagenette) is a simplified subset of the larger [ImageNet dataset](https://www.image-net.org/), featuring only 10 easily distinguishable classes such as tench, English springer, and French horn. It was created to offer a more manageable dataset for efficient training and evaluation of image classification models. This dataset is particularly useful for quick software development and educational purposes in [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision.
### How can I use the ImageNette dataset for training a YOLO model?
-To train a YOLO model on the ImageNette dataset for 100 epochs, you can use the following commands. Make sure to have the Ultralytics YOLO environment set up.
+To train a YOLO model on the ImageNette dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch), you can use the following commands. Make sure to have the Ultralytics YOLO environment set up.
!!! example "Train Example"
@@ -186,8 +186,8 @@ For more information, refer to [Training with ImageNette160 and ImageNette320](#
The ImageNette dataset is extensively used in:
-- **Educational Settings**: To educate beginners in machine learning and computer vision.
+- **Educational Settings**: To educate beginners in machine learning and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv).
- **Software Development**: For rapid prototyping and development of image classification models.
-- **Deep Learning Research**: To evaluate and benchmark the performance of various deep learning models, especially Convolutional Neural Networks (CNNs).
+- **Deep Learning Research**: To evaluate and benchmark the performance of various deep learning models, especially Convolutional [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) (CNNs).
Explore the [Applications](#applications) section for detailed use cases.
diff --git a/docs/en/datasets/classify/imagewoof.md b/docs/en/datasets/classify/imagewoof.md
index 54361abc60..2ed0273b60 100644
--- a/docs/en/datasets/classify/imagewoof.md
+++ b/docs/en/datasets/classify/imagewoof.md
@@ -6,7 +6,7 @@ keywords: ImageWoof dataset, ImageNet subset, dog breeds, image classification,
# ImageWoof Dataset
-The [ImageWoof](https://github.com/fastai/imagenette) dataset is a subset of the ImageNet consisting of 10 classes that are challenging to classify, since they're all dog breeds. It was created as a more difficult task for image classification algorithms to solve, aiming at encouraging development of more advanced models.
+The [ImageWoof](https://github.com/fastai/imagenette) dataset is a subset of the ImageNet consisting of 10 classes that are challenging to classify, since they're all dog breeds. It was created as a more difficult task for [image classification](https://www.ultralytics.com/glossary/image-classification) algorithms to solve, aiming at encouraging development of more advanced models.
## Key Features
@@ -24,7 +24,7 @@ The ImageWoof dataset is widely used for training and evaluating deep learning m
## Usage
-To train a CNN model on the ImageWoof dataset for 100 epochs with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a CNN model on the ImageWoof dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 224x224, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -97,7 +97,7 @@ The example showcases the subtle differences and similarities among the differen
If you use the ImageWoof dataset in your research or development work, please make sure to acknowledge the creators of the dataset by linking to the [official dataset repository](https://github.com/fastai/imagenette).
-We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the machine learning and computer vision research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
+We would like to acknowledge the FastAI team for creating and maintaining the ImageWoof dataset as a valuable resource for the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) research community. For more information about the ImageWoof dataset, visit the [ImageWoof dataset repository](https://github.com/fastai/imagenette).
## FAQ
@@ -107,7 +107,7 @@ The [ImageWoof](https://github.com/fastai/imagenette) dataset is a challenging s
### How can I train a model using the ImageWoof dataset with Ultralytics YOLO?
-To train a Convolutional Neural Network (CNN) model on the ImageWoof dataset using Ultralytics YOLO for 100 epochs at an image size of 224x224, you can use the following code:
+To train a [Convolutional Neural Network](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNN) model on the ImageWoof dataset using Ultralytics YOLO for 100 epochs at an image size of 224x224, you can use the following code:
!!! example "Train Example"
@@ -137,7 +137,7 @@ The ImageWoof dataset comes in three sizes:
2. **Medium Size (imagewoof320)**: Resized images with a maximum edge length of 320 pixels, suited for faster training.
3. **Small Size (imagewoof160)**: Resized images with a maximum edge length of 160 pixels, perfect for rapid prototyping.
-Use these versions by replacing 'imagewoof' in the dataset argument accordingly. Note, however, that smaller images may yield lower classification accuracy but can be useful for quicker iterations.
+Use these versions by replacing 'imagewoof' in the dataset argument accordingly. Note, however, that smaller images may yield lower classification [accuracy](https://www.ultralytics.com/glossary/accuracy) but can be useful for quicker iterations.
### How do noisy labels in the ImageWoof dataset benefit training?
@@ -145,4 +145,4 @@ Noisy labels in the ImageWoof dataset simulate real-world conditions where label
### What are the key challenges of using the ImageWoof dataset?
-The primary challenge of the ImageWoof dataset lies in the subtle differences among the dog breeds it includes. Since it focuses on 10 closely related breeds, distinguishing between them requires more advanced and fine-tuned image classification models. This makes ImageWoof an excellent benchmark to test the capabilities and improvements of deep learning models.
+The primary challenge of the ImageWoof dataset lies in the subtle differences among the dog breeds it includes. Since it focuses on 10 closely related breeds, distinguishing between them requires more advanced and fine-tuned image classification models. This makes ImageWoof an excellent benchmark to test the capabilities and improvements of [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models.
diff --git a/docs/en/datasets/classify/index.md b/docs/en/datasets/classify/index.md
index 2b01824a96..3567d6a295 100644
--- a/docs/en/datasets/classify/index.md
+++ b/docs/en/datasets/classify/index.md
@@ -103,12 +103,12 @@ This structured approach ensures that the model can effectively learn from well-
Ultralytics supports the following datasets with automatic download:
-- [Caltech 101](caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
+- [Caltech 101](caltech101.md): A dataset containing images of 101 object categories for [image classification](https://www.ultralytics.com/glossary/image-classification) tasks.
- [Caltech 256](caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
- [CIFAR-10](cifar10.md): A dataset of 60K 32x32 color images in 10 classes, with 6K images per class.
- [CIFAR-100](cifar100.md): An extended version of CIFAR-10 with 100 object categories and 600 images per class.
- [Fashion-MNIST](fashion-mnist.md): A dataset consisting of 70,000 grayscale images of 10 fashion categories for image classification tasks.
-- [ImageNet](imagenet.md): A large-scale dataset for object detection and image classification with over 14 million images and 20,000 categories.
+- [ImageNet](imagenet.md): A large-scale dataset for [object detection](https://www.ultralytics.com/glossary/object-detection) and image classification with over 14 million images and 20,000 categories.
- [ImageNet-10](imagenet10.md): A smaller subset of ImageNet with 10 categories for faster experimentation and testing.
- [Imagenette](imagenette.md): A smaller subset of ImageNet that contains 10 easily distinguishable classes for quicker training and testing.
- [Imagewoof](imagewoof.md): A more challenging subset of ImageNet containing 10 dog breed categories for image classification tasks.
@@ -184,7 +184,7 @@ Ultralytics YOLO offers several benefits for image classification, including:
- **Pretrained Models**: Load pretrained models like `yolov8n-cls.pt` to jump-start your training process.
- **Ease of Use**: Simple API and CLI commands for training and evaluation.
-- **High Performance**: State-of-the-art accuracy and speed, ideal for real-time applications.
+- **High Performance**: State-of-the-art [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed, ideal for real-time applications.
- **Support for Multiple Datasets**: Seamless integration with various popular datasets like CIFAR-10, ImageNet, and more.
- **Community and Support**: Access to extensive documentation and an active community for troubleshooting and improvements.
diff --git a/docs/en/datasets/classify/mnist.md b/docs/en/datasets/classify/mnist.md
index 7ee4531392..07f0a70a1d 100644
--- a/docs/en/datasets/classify/mnist.md
+++ b/docs/en/datasets/classify/mnist.md
@@ -12,7 +12,7 @@ The [MNIST](http://yann.lecun.com/exdb/mnist/) (Modified National Institute of S
- MNIST contains 60,000 training images and 10,000 testing images of handwritten digits.
- The dataset comprises grayscale images of size 28x28 pixels.
-- The images are normalized to fit into a 28x28 pixel bounding box and anti-aliased, introducing grayscale levels.
+- The images are normalized to fit into a 28x28 pixel [bounding box](https://www.ultralytics.com/glossary/bounding-box) and anti-aliased, introducing grayscale levels.
- MNIST is widely used for training and testing in the field of machine learning, especially for image classification tasks.
## Dataset Structure
@@ -28,11 +28,11 @@ Extended MNIST (EMNIST) is a newer dataset developed and released by NIST to be
## Applications
-The MNIST dataset is widely used for training and evaluating deep learning models in image classification tasks, such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
+The MNIST dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in image classification tasks, such as [Convolutional Neural Networks](https://www.ultralytics.com/glossary/convolutional-neural-network-cnn) (CNNs), [Support Vector Machines](https://www.ultralytics.com/glossary/support-vector-machine-svm) (SVMs), and various other machine learning algorithms. The dataset's simple and well-structured format makes it an essential resource for researchers and practitioners in the field of machine learning and computer vision.
## Usage
-To train a CNN model on the MNIST dataset for 100 epochs with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a CNN model on the MNIST dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 32x32, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -57,7 +57,7 @@ To train a CNN model on the MNIST dataset for 100 epochs with an image size of 3
## Sample Images and Annotations
-The MNIST dataset contains grayscale images of handwritten digits, providing a well-structured dataset for image classification tasks. Here are some examples of images from the dataset:
+The MNIST dataset contains grayscale images of handwritten digits, providing a well-structured dataset for [image classification](https://www.ultralytics.com/glossary/image-classification) tasks. Here are some examples of images from the dataset:

@@ -83,7 +83,7 @@ research or development work, please cite the following paper:
}
```
-We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the machine learning and computer vision research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
+We would like to acknowledge Yann LeCun, Corinna Cortes, and Christopher J.C. Burges for creating and maintaining the MNIST dataset as a valuable resource for the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) research community. For more information about the MNIST dataset and its creators, visit the [MNIST dataset website](http://yann.lecun.com/exdb/mnist/).
## FAQ
diff --git a/docs/en/datasets/detect/african-wildlife.md b/docs/en/datasets/detect/african-wildlife.md
index d0c86a0314..0d01372dbd 100644
--- a/docs/en/datasets/detect/african-wildlife.md
+++ b/docs/en/datasets/detect/african-wildlife.md
@@ -6,7 +6,7 @@ keywords: African Wildlife Dataset, South African animals, object detection, com
# African Wildlife Dataset
-This dataset showcases four common animal classes typically found in South African nature reserves. It includes images of African wildlife such as buffalo, elephant, rhino, and zebra, providing valuable insights into their characteristics. Essential for training computer vision algorithms, this dataset aids in identifying animals in various habitats, from zoos to forests, and supports wildlife research.
+This dataset showcases four common animal classes typically found in South African nature reserves. It includes images of African wildlife such as buffalo, elephant, rhino, and zebra, providing valuable insights into their characteristics. Essential for training [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) algorithms, this dataset aids in identifying animals in various habitats, from zoos to forests, and supports wildlife research.
@@ -29,7 +29,7 @@ The African wildlife objects detection dataset is split into three subsets:
## Applications
-This dataset can be applied in various computer vision tasks such as object detection, object tracking, and research. Specifically, it can be used to train and evaluate models for identifying African wildlife objects in images, which can have applications in wildlife conservation, ecological research, and monitoring efforts in natural reserves and protected areas. Additionally, it can serve as a valuable resource for educational purposes, enabling students and researchers to study and understand the characteristics and behaviors of different animal species.
+This dataset can be applied in various computer vision tasks such as [object detection](https://www.ultralytics.com/glossary/object-detection), object tracking, and research. Specifically, it can be used to train and evaluate models for identifying African wildlife objects in images, which can have applications in wildlife conservation, ecological research, and monitoring efforts in natural reserves and protected areas. Additionally, it can serve as a valuable resource for educational purposes, enabling students and researchers to study and understand the characteristics and behaviors of different animal species.
## Dataset YAML
@@ -43,7 +43,7 @@ A YAML (Yet Another Markup Language) file defines the dataset configuration, inc
## Usage
-To train a YOLOv8n model on the African wildlife dataset for 100 epochs with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the African wildlife dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -136,7 +136,7 @@ For additional training parameters and options, refer to the [Training](../../mo
### Where can I find the YAML configuration file for the African Wildlife Dataset?
-The YAML configuration file for the African Wildlife Dataset, named `african-wildlife.yaml`, can be found at [this GitHub link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml). This file defines the dataset configuration, including paths, classes, and other details crucial for training machine learning models. See the [Dataset YAML](#dataset-yaml) section for more details.
+The YAML configuration file for the African Wildlife Dataset, named `african-wildlife.yaml`, can be found at [this GitHub link](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/african-wildlife.yaml). This file defines the dataset configuration, including paths, classes, and other details crucial for training [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models. See the [Dataset YAML](#dataset-yaml) section for more details.
### Can I see sample images and annotations from the African Wildlife Dataset?
diff --git a/docs/en/datasets/detect/argoverse.md b/docs/en/datasets/detect/argoverse.md
index 47ef822b08..a834be90ed 100644
--- a/docs/en/datasets/detect/argoverse.md
+++ b/docs/en/datasets/detect/argoverse.md
@@ -29,7 +29,7 @@ The Argoverse dataset is organized into three main subsets:
## Applications
-The Argoverse dataset is widely used for training and evaluating deep learning models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
+The Argoverse dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in autonomous driving tasks such as 3D object tracking, motion forecasting, and stereo depth estimation. The dataset's diverse set of sensor data, object annotations, and map information make it a valuable resource for researchers and practitioners in the field of autonomous driving.
## Dataset YAML
@@ -43,7 +43,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the Argoverse dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the Argoverse dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
diff --git a/docs/en/datasets/detect/brain-tumor.md b/docs/en/datasets/detect/brain-tumor.md
index aa48c5f9e4..9f108e7388 100644
--- a/docs/en/datasets/detect/brain-tumor.md
+++ b/docs/en/datasets/detect/brain-tumor.md
@@ -6,7 +6,7 @@ keywords: brain tumor dataset, MRI scans, CT scans, brain tumor detection, medic
# Brain Tumor Dataset
-A brain tumor detection dataset consists of medical images from MRI or CT scans, containing information about brain tumor presence, location, and characteristics. This dataset is essential for training computer vision algorithms to automate brain tumor identification, aiding in early diagnosis and treatment planning.
+A brain tumor detection dataset consists of medical images from MRI or CT scans, containing information about brain tumor presence, location, and characteristics. This dataset is essential for training [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) algorithms to automate brain tumor identification, aiding in early diagnosis and treatment planning.
@@ -42,7 +42,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image size of 640, utilize the provided code snippets. For a detailed list of available arguments, consult the model's [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the brain tumor dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, utilize the provided code snippets. For a detailed list of available arguments, consult the model's [Training](../../modes/train.md) page.
!!! example "Train Example"
diff --git a/docs/en/datasets/detect/coco.md b/docs/en/datasets/detect/coco.md
index 25878ed913..d090142838 100644
--- a/docs/en/datasets/detect/coco.md
+++ b/docs/en/datasets/detect/coco.md
@@ -6,7 +6,7 @@ keywords: COCO dataset, object detection, segmentation, benchmarking, computer v
# COCO Dataset
-The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking computer vision models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
+The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is a large-scale object detection, segmentation, and captioning dataset. It is designed to encourage research on a wide variety of object categories and is commonly used for benchmarking [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models. It is an essential dataset for researchers and developers working on object detection, segmentation, and pose estimation tasks.
@@ -34,7 +34,7 @@ The [COCO](https://cocodataset.org/#home) (Common Objects in Context) dataset is
- COCO contains 330K images, with 200K images having annotations for object detection, segmentation, and captioning tasks.
- The dataset comprises 80 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
- Annotations include object bounding boxes, segmentation masks, and captions for each image.
-- COCO provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
+- COCO provides standardized evaluation metrics like [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) for object detection, and mean Average [Recall](https://www.ultralytics.com/glossary/recall) (mAR) for segmentation tasks, making it suitable for comparing model performance.
## Dataset Structure
@@ -46,7 +46,7 @@ The COCO dataset is split into three subsets:
## Applications
-The COCO dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+The COCO dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object detection (such as YOLO, Faster R-CNN, and SSD), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) (such as Mask R-CNN), and keypoint detection (such as OpenPose). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
## Dataset YAML
@@ -60,7 +60,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the COCO dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the COCO dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -118,7 +118,7 @@ We would like to acknowledge the COCO Consortium for creating and maintaining th
### What is the COCO dataset and why is it important for computer vision?
-The [COCO dataset](https://cocodataset.org/#home) (Common Objects in Context) is a large-scale dataset used for object detection, segmentation, and captioning. It contains 330K images with detailed annotations for 80 object categories, making it essential for benchmarking and training computer vision models. Researchers use COCO due to its diverse categories and standardized evaluation metrics like mean Average Precision (mAP).
+The [COCO dataset](https://cocodataset.org/#home) (Common Objects in Context) is a large-scale dataset used for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and captioning. It contains 330K images with detailed annotations for 80 object categories, making it essential for benchmarking and training computer vision models. Researchers use COCO due to its diverse categories and standardized evaluation metrics like mean Average [Precision](https://www.ultralytics.com/glossary/precision) (mAP).
### How can I train a YOLO model using the COCO dataset?
diff --git a/docs/en/datasets/detect/coco8.md b/docs/en/datasets/detect/coco8.md
index a0972693ea..4a8ad5a852 100644
--- a/docs/en/datasets/detect/coco8.md
+++ b/docs/en/datasets/detect/coco8.md
@@ -8,7 +8,7 @@ keywords: COCO8, Ultralytics, dataset, object detection, YOLOv8, training, valid
## Introduction
-[Ultralytics](https://www.ultralytics.com/) COCO8 is a small, but versatile object detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) COCO8 is a small, but versatile [object detection](https://www.ultralytics.com/glossary/object-detection) dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
@@ -35,7 +35,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the COCO8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the COCO8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -87,7 +87,7 @@ If you use the COCO dataset in your research or development work, please cite th
}
```
-We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
## FAQ
diff --git a/docs/en/datasets/detect/globalwheat2020.md b/docs/en/datasets/detect/globalwheat2020.md
index 37b9759f36..ef7ff7ac31 100644
--- a/docs/en/datasets/detect/globalwheat2020.md
+++ b/docs/en/datasets/detect/globalwheat2020.md
@@ -24,7 +24,7 @@ The Global Wheat Head Dataset is organized into two main subsets:
## Applications
-The Global Wheat Head Dataset is widely used for training and evaluating deep learning models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
+The Global Wheat Head Dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in wheat head detection tasks. The dataset's diverse set of images, capturing a wide range of appearances, environments, and conditions, make it a valuable resource for researchers and practitioners in the field of plant phenotyping and crop management.
## Dataset YAML
@@ -38,7 +38,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the Global Wheat Head Dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the Global Wheat Head Dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -130,7 +130,7 @@ Key features of the Global Wheat Head Dataset include:
- Over 3,000 training images from Europe (France, UK, Switzerland) and North America (Canada).
- Approximately 1,000 test images from Australia, Japan, and China.
- High variability in wheat head appearances due to different growing environments.
-- Detailed annotations with wheat head bounding boxes to aid object detection models.
+- Detailed annotations with wheat head bounding boxes to aid [object detection](https://www.ultralytics.com/glossary/object-detection) models.
These features facilitate the development of robust models capable of generalization across multiple regions.
diff --git a/docs/en/datasets/detect/index.md b/docs/en/datasets/detect/index.md
index f76ba40bc2..61640480f6 100644
--- a/docs/en/datasets/detect/index.md
+++ b/docs/en/datasets/detect/index.md
@@ -6,7 +6,7 @@ keywords: Ultralytics, YOLO, object detection datasets, dataset formats, COCO, d
# Object Detection Datasets Overview
-Training a robust and accurate object detection model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
+Training a robust and accurate [object detection](https://www.ultralytics.com/glossary/object-detection) model requires a comprehensive dataset. This guide introduces various formats of datasets that are compatible with the Ultralytics YOLO model and provides insights into their structure, usage, and how to convert between different formats.
## Supported Dataset Formats
diff --git a/docs/en/datasets/detect/lvis.md b/docs/en/datasets/detect/lvis.md
index 8c06920fd6..c4a4ff76ed 100644
--- a/docs/en/datasets/detect/lvis.md
+++ b/docs/en/datasets/detect/lvis.md
@@ -6,7 +6,7 @@ keywords: LVIS dataset, object detection, instance segmentation, Facebook AI Res
# LVIS Dataset
-The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and instance segmentation with a large vocabulary of categories, aiming to drive further advancements in computer vision field.
+The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained vocabulary-level annotation dataset developed and released by Facebook AI Research (FAIR). It is primarily used as a research benchmark for object detection and [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) with a large vocabulary of categories, aiming to drive further advancements in computer vision field.
@@ -28,7 +28,7 @@ The [LVIS dataset](https://www.lvisdataset.org/) is a large-scale, fine-grained
- LVIS contains 160k images and 2M instance annotations for object detection, segmentation, and captioning tasks.
- The dataset comprises 1203 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as umbrellas, handbags, and sports equipment.
- Annotations include object bounding boxes, segmentation masks, and captions for each image.
-- LVIS provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for segmentation tasks, making it suitable for comparing model performance.
+- LVIS provides standardized evaluation metrics like [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) for object detection, and mean Average [Recall](https://www.ultralytics.com/glossary/recall) (mAR) for segmentation tasks, making it suitable for comparing model performance.
- LVIS uses exactly the same images as [COCO](./coco.md) dataset, but with different splits and different annotations.
## Dataset Structure
@@ -42,7 +42,7 @@ The LVIS dataset is split into three subsets:
## Applications
-The LVIS dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+The LVIS dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
## Dataset YAML
@@ -56,7 +56,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the LVIS dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the LVIS dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -106,7 +106,7 @@ If you use the LVIS dataset in your research or development work, please cite th
}
```
-We would like to acknowledge the LVIS Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the LVIS dataset and its creators, visit the [LVIS dataset website](https://www.lvisdataset.org/).
+We would like to acknowledge the LVIS Consortium for creating and maintaining this valuable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the LVIS dataset and its creators, visit the [LVIS dataset website](https://www.lvisdataset.org/).
## FAQ
@@ -144,11 +144,11 @@ For detailed training configurations, refer to the [Training](../../modes/train.
### How does the LVIS dataset differ from the COCO dataset?
-The images in the LVIS dataset are the same as those in the [COCO dataset](./coco.md), but the two differ in terms of splitting and annotations. LVIS provides a larger and more detailed vocabulary with 1203 object categories compared to COCO's 80 categories. Additionally, LVIS focuses on annotation completeness and diversity, aiming to push the limits of object detection and instance segmentation models by offering more nuanced and comprehensive data.
+The images in the LVIS dataset are the same as those in the [COCO dataset](./coco.md), but the two differ in terms of splitting and annotations. LVIS provides a larger and more detailed vocabulary with 1203 object categories compared to COCO's 80 categories. Additionally, LVIS focuses on annotation completeness and diversity, aiming to push the limits of [object detection](https://www.ultralytics.com/glossary/object-detection) and instance segmentation models by offering more nuanced and comprehensive data.
### Why should I use Ultralytics YOLO for training on the LVIS dataset?
-Ultralytics YOLO models, including the latest YOLOv8, are optimized for real-time object detection with state-of-the-art accuracy and speed. They support a wide range of annotations, such as the fine-grained ones provided by the LVIS dataset, making them ideal for advanced computer vision applications. Moreover, Ultralytics offers seamless integration with various [training](../../modes/train.md), [validation](../../modes/val.md), and [prediction](../../modes/predict.md) modes, ensuring efficient model development and deployment.
+Ultralytics YOLO models, including the latest YOLOv8, are optimized for real-time object detection with state-of-the-art [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed. They support a wide range of annotations, such as the fine-grained ones provided by the LVIS dataset, making them ideal for advanced computer vision applications. Moreover, Ultralytics offers seamless integration with various [training](../../modes/train.md), [validation](../../modes/val.md), and [prediction](../../modes/predict.md) modes, ensuring efficient model development and deployment.
### Can I see some sample annotations from the LVIS dataset?
diff --git a/docs/en/datasets/detect/objects365.md b/docs/en/datasets/detect/objects365.md
index f2b44f245a..49947617af 100644
--- a/docs/en/datasets/detect/objects365.md
+++ b/docs/en/datasets/detect/objects365.md
@@ -24,7 +24,7 @@ The Objects365 dataset is organized into a single set of images with correspondi
## Applications
-The Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of computer vision.
+The Objects365 dataset is widely used for training and evaluating deep learning models in object detection tasks. The dataset's diverse set of object categories and high-quality annotations make it a valuable resource for researchers and practitioners in the field of [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv).
## Dataset YAML
@@ -38,7 +38,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the Objects365 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -63,7 +63,7 @@ To train a YOLOv8n model on the Objects365 dataset for 100 epochs with an image
## Sample Data and Annotations
-The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for object detection tasks. Here are some examples of the images in the dataset:
+The Objects365 dataset contains a diverse set of high-resolution images with objects from 365 categories, providing rich context for [object detection](https://www.ultralytics.com/glossary/object-detection) tasks. Here are some examples of the images in the dataset:

@@ -95,7 +95,7 @@ We would like to acknowledge the team of researchers who created and maintain th
### What is the Objects365 dataset used for?
-The [Objects365 dataset](https://www.objects365.org/) is designed for object detection tasks in machine learning and computer vision. It provides a large-scale, high-quality dataset with 2 million annotated images and 30 million bounding boxes across 365 categories. Leveraging such a diverse dataset helps improve the performance and generalization of object detection models, making it invaluable for research and development in the field.
+The [Objects365 dataset](https://www.objects365.org/) is designed for object detection tasks in [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and computer vision. It provides a large-scale, high-quality dataset with 2 million annotated images and 30 million bounding boxes across 365 categories. Leveraging such a diverse dataset helps improve the performance and generalization of object detection models, making it invaluable for research and development in the field.
### How can I train a YOLOv8 model on the Objects365 dataset?
@@ -138,4 +138,4 @@ The YAML configuration file for the Objects365 dataset is available at [Objects3
### How does the dataset structure of Objects365 enhance object detection modeling?
-The [Objects365 dataset](https://www.objects365.org/) is organized with 2 million high-resolution images and comprehensive annotations of over 30 million bounding boxes. This structure ensures a robust dataset for training deep learning models in object detection, offering a wide variety of objects and scenarios. Such diversity and volume help in developing models that are more accurate and capable of generalizing well to real-world applications. For more details on the dataset structure, refer to the [Dataset YAML](#dataset-yaml) section.
+The [Objects365 dataset](https://www.objects365.org/) is organized with 2 million high-resolution images and comprehensive annotations of over 30 million bounding boxes. This structure ensures a robust dataset for training [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object detection, offering a wide variety of objects and scenarios. Such diversity and volume help in developing models that are more accurate and capable of generalizing well to real-world applications. For more details on the dataset structure, refer to the [Dataset YAML](#dataset-yaml) section.
diff --git a/docs/en/datasets/detect/open-images-v7.md b/docs/en/datasets/detect/open-images-v7.md
index f6b0c63bc4..1e6f1f7e4f 100644
--- a/docs/en/datasets/detect/open-images-v7.md
+++ b/docs/en/datasets/detect/open-images-v7.md
@@ -6,7 +6,7 @@ keywords: Open Images V7, Google dataset, computer vision, YOLOv8 models, object
# Open Images V7 Dataset
-[Open Images V7](https://storage.googleapis.com/openimages/web/index.html) is a versatile and expansive dataset championed by Google. Aimed at propelling research in the realm of computer vision, it boasts a vast collection of images annotated with a plethora of data, including image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
+[Open Images V7](https://storage.googleapis.com/openimages/web/index.html) is a versatile and expansive dataset championed by Google. Aimed at propelling research in the realm of [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv), it boasts a vast collection of images annotated with a plethora of data, including image-level labels, object bounding boxes, object segmentation masks, visual relationships, and localized narratives.
@@ -16,7 +16,7 @@ keywords: Open Images V7, Google dataset, computer vision, YOLOv8 models, object
allowfullscreen>
- Watch: Object Detection using OpenImagesV7 Pretrained Model
+ Watch: [Object Detection](https://www.ultralytics.com/glossary/object-detection) using OpenImagesV7 Pretrained Model
## Open Images V7 Pretrained Models
@@ -34,13 +34,13 @@ keywords: Open Images V7, Google dataset, computer vision, YOLOv8 models, object
## Key Features
- Encompasses ~9M images annotated in various ways to suit multiple computer vision tasks.
-- Houses a staggering 16M bounding boxes across 600 object classes in 1.9M images. These boxes are primarily hand-drawn by experts ensuring high precision.
+- Houses a staggering 16M bounding boxes across 600 object classes in 1.9M images. These boxes are primarily hand-drawn by experts ensuring high [precision](https://www.ultralytics.com/glossary/precision).
- Visual relationship annotations totaling 3.3M are available, detailing 1,466 unique relationship triplets, object properties, and human activities.
- V5 introduced segmentation masks for 2.8M objects across 350 classes.
- V6 introduced 675k localized narratives that amalgamate voice, text, and mouse traces highlighting described objects.
- V7 introduced 66.4M point-level labels on 1.4M images, spanning 5,827 classes.
- Encompasses 61.4M image-level labels across a diverse set of 20,638 classes.
-- Provides a unified platform for image classification, object detection, relationship detection, instance segmentation, and multimodal image descriptions.
+- Provides a unified platform for image classification, object detection, relationship detection, [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and multimodal image descriptions.
## Dataset Structure
@@ -51,7 +51,7 @@ Open Images V7 is structured in multiple components catering to varied computer
- **Segmentation Masks**: These detail the exact boundary of 2.8M objects across 350 classes.
- **Visual Relationships**: 3.3M annotations indicating object relationships, properties, and actions.
- **Localized Narratives**: 675k descriptions combining voice, text, and mouse traces.
-- **Point-Level Labels**: 66.4M labels across 1.4M images, suitable for zero/few-shot semantic segmentation.
+- **Point-Level Labels**: 66.4M labels across 1.4M images, suitable for zero/few-shot [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation).
## Applications
@@ -69,7 +69,7 @@ Typically, datasets come with a YAML (Yet Another Markup Language) file that del
## Usage
-To train a YOLOv8n model on the Open Images V7 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the Open Images V7 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! warning
@@ -191,10 +191,10 @@ Ultralytics provides several YOLOv8 pretrained models for the Open Images V7 dat
The Open Images V7 dataset supports a variety of computer vision tasks including:
-- **Image Classification**
+- **[Image Classification](https://www.ultralytics.com/glossary/image-classification)**
- **Object Detection**
- **Instance Segmentation**
- **Visual Relationship Detection**
- **Multimodal Image Descriptions**
-Its comprehensive annotations and broad scope make it suitable for training and evaluating advanced machine learning models, as highlighted in practical use cases detailed in our [applications](#applications) section.
+Its comprehensive annotations and broad scope make it suitable for training and evaluating advanced [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models, as highlighted in practical use cases detailed in our [applications](#applications) section.
diff --git a/docs/en/datasets/detect/roboflow-100.md b/docs/en/datasets/detect/roboflow-100.md
index 844326c381..6b3c540e03 100644
--- a/docs/en/datasets/detect/roboflow-100.md
+++ b/docs/en/datasets/detect/roboflow-100.md
@@ -35,7 +35,7 @@ This structure enables a diverse and extensive testing ground for object detecti
## Benchmarking
-Dataset benchmarking evaluates machine learning model performance on specific datasets using standardized metrics like accuracy, mean average precision and F1-score.
+Dataset benchmarking evaluates machine learning model performance on specific datasets using standardized metrics like [accuracy](https://www.ultralytics.com/glossary/accuracy), [mean average precision](https://www.ultralytics.com/glossary/mean-average-precision-map) and F1-score.
!!! tip "Benchmarking"
@@ -85,7 +85,7 @@ Dataset benchmarking evaluates machine learning model performance on specific da
## Applications
-Roboflow 100 is invaluable for various applications related to computer vision and deep learning. Researchers and engineers can use this benchmark to:
+Roboflow 100 is invaluable for various applications related to [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl). Researchers and engineers can use this benchmark to:
- Evaluate the performance of object detection models in a multi-domain context.
- Test the adaptability of models to real-world scenarios beyond common object recognition.
@@ -127,7 +127,7 @@ If you use the Roboflow 100 dataset in your research or development work, please
Our thanks go to the Roboflow team and all the contributors for their hard work in creating and sustaining the Roboflow 100 dataset.
-If you are interested in exploring more datasets to enhance your object detection and machine learning projects, feel free to visit [our comprehensive dataset collection](../index.md).
+If you are interested in exploring more datasets to enhance your object detection and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) projects, feel free to visit [our comprehensive dataset collection](../index.md).
## FAQ
@@ -183,7 +183,7 @@ To use the Roboflow 100 dataset for benchmarking, you can implement the RF100Ben
### Which domains are covered by the Roboflow 100 dataset?
-The **Roboflow 100** dataset spans seven domains, each providing unique challenges and applications for object detection models:
+The **Roboflow 100** dataset spans seven domains, each providing unique challenges and applications for [object detection](https://www.ultralytics.com/glossary/object-detection) models:
1. **Aerial**: 7 datasets, 9,683 images, 24 classes
2. **Video Games**: 7 datasets, 11,579 images, 88 classes
diff --git a/docs/en/datasets/detect/signature.md b/docs/en/datasets/detect/signature.md
index 0d76e11f50..5746d57e02 100644
--- a/docs/en/datasets/detect/signature.md
+++ b/docs/en/datasets/detect/signature.md
@@ -6,7 +6,7 @@ keywords: Signature Detection Dataset, document verification, fraud detection, c
# Signature Detection Dataset
-This dataset focuses on detecting human written signatures within documents. It includes a variety of document types with annotated signatures, providing valuable insights for applications in document verification and fraud detection. Essential for training computer vision algorithms, this dataset aids in identifying signatures in various document formats, supporting research and practical applications in document analysis.
+This dataset focuses on detecting human written signatures within documents. It includes a variety of document types with annotated signatures, providing valuable insights for applications in document verification and fraud detection. Essential for training [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) algorithms, this dataset aids in identifying signatures in various document formats, supporting research and practical applications in document analysis.
## Dataset Structure
@@ -31,7 +31,7 @@ A YAML (Yet Another Markup Language) file defines the dataset configuration, inc
## Usage
-To train a YOLOv8n model on the signature detection dataset for 100 epochs with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the signature detection dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, use the provided code samples. For a comprehensive list of available parameters, refer to the model's [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -93,7 +93,7 @@ The dataset has been released available under the [AGPL-3.0 License](https://git
### What is the Signature Detection Dataset, and how can it be used?
-The Signature Detection Dataset is a collection of annotated images aimed at detecting human signatures within various document types. It can be applied in computer vision tasks such as object detection and tracking, primarily for document verification, fraud detection, and archival research. This dataset helps train models to recognize signatures in different contexts, making it valuable for both research and practical applications.
+The Signature Detection Dataset is a collection of annotated images aimed at detecting human signatures within various document types. It can be applied in computer vision tasks such as [object detection](https://www.ultralytics.com/glossary/object-detection) and tracking, primarily for document verification, fraud detection, and archival research. This dataset helps train models to recognize signatures in different contexts, making it valuable for both research and practical applications.
### How do I train a YOLOv8n model on the Signature Detection Dataset?
@@ -131,7 +131,7 @@ The Signature Detection Dataset can be used for:
1. **Document Verification**: Automatically verifying the presence and authenticity of human signatures in documents.
2. **Fraud Detection**: Identifying forged or fraudulent signatures in legal and financial documents.
3. **Archival Research**: Assisting historians and archivists in the digital analysis and cataloging of historical documents.
-4. **Education**: Supporting academic research and teaching in the fields of computer vision and machine learning.
+4. **Education**: Supporting academic research and teaching in the fields of computer vision and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml).
### How can I perform inference using a model trained on the Signature Detection Dataset?
diff --git a/docs/en/datasets/detect/sku-110k.md b/docs/en/datasets/detect/sku-110k.md
index 145468321e..c6cddc483f 100644
--- a/docs/en/datasets/detect/sku-110k.md
+++ b/docs/en/datasets/detect/sku-110k.md
@@ -6,7 +6,7 @@ keywords: SKU-110k, dataset, object detection, retail shelf images, deep learnin
# SKU-110k Dataset
-The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
+The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in [object detection](https://www.ultralytics.com/glossary/object-detection) tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
@@ -37,7 +37,7 @@ The SKU-110k dataset is organized into three main subsets:
## Applications
-The SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of computer vision.
+The SKU-110k dataset is widely used for training and evaluating deep learning models in object detection tasks, especially in densely packed scenes such as retail shelf displays. The dataset's diverse set of SKU categories and densely packed object arrangements make it a valuable resource for researchers and practitioners in the field of [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv).
## Dataset YAML
@@ -51,7 +51,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the SKU-110K dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the SKU-110K dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -151,7 +151,7 @@ Refer to the [Dataset Structure](#dataset-structure) section for more details.
The SKU-110k dataset configuration is defined in a YAML file, which includes details about the dataset's paths, classes, and other relevant information. The `SKU-110K.yaml` file is maintained at [SKU-110K.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/SKU-110K.yaml). For example, you can train a model using this configuration as shown in our [Usage](#usage) section.
-### What are the key features of the SKU-110k dataset in the context of deep learning?
+### What are the key features of the SKU-110k dataset in the context of [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl)?
The SKU-110k dataset features images of store shelves from around the world, showcasing densely packed objects that pose significant challenges for object detectors:
diff --git a/docs/en/datasets/detect/visdrone.md b/docs/en/datasets/detect/visdrone.md
index c1060e9989..99b182cb4e 100644
--- a/docs/en/datasets/detect/visdrone.md
+++ b/docs/en/datasets/detect/visdrone.md
@@ -6,7 +6,7 @@ keywords: VisDrone, drone dataset, computer vision, object detection, object tra
# VisDrone Dataset
-The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.
+The [VisDrone Dataset](https://github.com/VisDrone/VisDrone-Dataset) is a large-scale benchmark created by the AISKYEYE team at the Lab of [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml) and Data Mining, Tianjin University, China. It contains carefully annotated ground truth data for various computer vision tasks related to drone-based image and video analysis.
@@ -33,7 +33,7 @@ The VisDrone dataset is organized into five main subsets, each focusing on a spe
## Applications
-The VisDrone dataset is widely used for training and evaluating deep learning models in drone-based computer vision tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.
+The VisDrone dataset is widely used for training and evaluating deep learning models in drone-based [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks such as object detection, object tracking, and crowd counting. The dataset's diverse set of sensor data, object annotations, and attributes make it a valuable resource for researchers and practitioners in the field of drone-based computer vision.
## Dataset YAML
@@ -47,7 +47,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the VisDrone dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the VisDrone dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -76,7 +76,7 @@ The VisDrone dataset contains a diverse set of images and videos captured by dro

-- **Task 1**: Object detection in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
+- **Task 1**: [Object detection](https://www.ultralytics.com/glossary/object-detection) in images - This image demonstrates an example of object detection in images, where objects are annotated with bounding boxes. The dataset provides a wide variety of images taken from different locations, environments, and densities to facilitate the development of models for this task.
The example showcases the variety and complexity of the data in the VisDrone dataset and highlights the importance of high-quality sensor data for drone-based computer vision tasks.
@@ -100,7 +100,7 @@ If you use the VisDrone dataset in your research or development work, please cit
doi={10.1109/TPAMI.2021.3119563}}
```
-We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and Data Mining, Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
+We would like to acknowledge the AISKYEYE team at the Lab of Machine Learning and [Data Mining](https://www.ultralytics.com/glossary/data-mining), Tianjin University, China, for creating and maintaining the VisDrone dataset as a valuable resource for the drone-based computer vision research community. For more information about the VisDrone dataset and its creators, visit the [VisDrone Dataset GitHub repository](https://github.com/VisDrone/VisDrone-Dataset).
## FAQ
@@ -150,7 +150,7 @@ The VisDrone dataset is divided into five main subsets, each tailored for a spec
4. **Task 4**: Multi-object tracking.
5. **Task 5**: Crowd counting.
-These subsets are widely used for training and evaluating deep learning models in drone-based applications such as surveillance, traffic monitoring, and public safety.
+These subsets are widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in drone-based applications such as surveillance, traffic monitoring, and public safety.
### Where can I find the configuration file for the VisDrone dataset in Ultralytics?
diff --git a/docs/en/datasets/detect/voc.md b/docs/en/datasets/detect/voc.md
index 0afc920529..7dc67fb5a4 100644
--- a/docs/en/datasets/detect/voc.md
+++ b/docs/en/datasets/detect/voc.md
@@ -13,7 +13,7 @@ The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes
- VOC dataset includes two main challenges: VOC2007 and VOC2012.
- The dataset comprises 20 object categories, including common objects like cars, bicycles, and animals, as well as more specific categories such as boats, sofas, and dining tables.
- Annotations include object bounding boxes and class labels for object detection and classification tasks, and segmentation masks for the segmentation tasks.
-- VOC provides standardized evaluation metrics like mean Average Precision (mAP) for object detection and classification, making it suitable for comparing model performance.
+- VOC provides standardized evaluation metrics like [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) for object detection and classification, making it suitable for comparing model performance.
## Dataset Structure
@@ -25,7 +25,7 @@ The VOC dataset is split into three subsets:
## Applications
-The VOC dataset is widely used for training and evaluating deep learning models in object detection (such as YOLO, Faster R-CNN, and SSD), instance segmentation (such as Mask R-CNN), and image classification. The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
+The VOC dataset is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in object detection (such as YOLO, Faster R-CNN, and SSD), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) (such as Mask R-CNN), and [image classification](https://www.ultralytics.com/glossary/image-classification). The dataset's diverse set of object categories, large number of annotated images, and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners.
## Dataset YAML
@@ -39,7 +39,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n model on the VOC dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n model on the VOC dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -91,13 +91,13 @@ If you use the VOC dataset in your research or development work, please cite the
}
```
-We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
+We would like to acknowledge the PASCAL VOC Consortium for creating and maintaining this valuable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the VOC dataset and its creators, visit the [PASCAL VOC dataset website](http://host.robots.ox.ac.uk/pascal/VOC/).
## FAQ
### What is the PASCAL VOC dataset and why is it important for computer vision tasks?
-The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a renowned benchmark for object detection, segmentation, and classification in computer vision. It includes comprehensive annotations like bounding boxes, class labels, and segmentation masks across 20 different object categories. Researchers use it widely to evaluate the performance of models like Faster R-CNN, YOLO, and Mask R-CNN due to its standardized evaluation metrics such as mean Average Precision (mAP).
+The [PASCAL VOC](http://host.robots.ox.ac.uk/pascal/VOC/) (Visual Object Classes) dataset is a renowned benchmark for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification in computer vision. It includes comprehensive annotations like bounding boxes, class labels, and segmentation masks across 20 different object categories. Researchers use it widely to evaluate the performance of models like Faster R-CNN, YOLO, and Mask R-CNN due to its standardized evaluation metrics such as mean Average Precision (mAP).
### How do I train a YOLOv8 model using the VOC dataset?
@@ -130,8 +130,8 @@ The VOC dataset includes two main challenges: VOC2007 and VOC2012. These challen
### How does the PASCAL VOC dataset enhance model benchmarking and evaluation?
-The PASCAL VOC dataset enhances model benchmarking and evaluation through its detailed annotations and standardized metrics like mean Average Precision (mAP). These metrics are crucial for assessing the performance of object detection and classification models. The dataset's diverse and complex images ensure comprehensive model evaluation across various real-world scenarios.
+The PASCAL VOC dataset enhances model benchmarking and evaluation through its detailed annotations and standardized metrics like mean Average [Precision](https://www.ultralytics.com/glossary/precision) (mAP). These metrics are crucial for assessing the performance of object detection and classification models. The dataset's diverse and complex images ensure comprehensive model evaluation across various real-world scenarios.
-### How do I use the VOC dataset for semantic segmentation in YOLO models?
+### How do I use the VOC dataset for [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation) in YOLO models?
To use the VOC dataset for semantic segmentation tasks with YOLO models, you need to configure the dataset properly in a YAML file. The YAML file defines paths and classes needed for training segmentation models. Check the VOC dataset YAML configuration file at [VOC.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/VOC.yaml) for detailed setups.
diff --git a/docs/en/datasets/detect/xview.md b/docs/en/datasets/detect/xview.md
index e7e2f3d3f7..df8e493357 100644
--- a/docs/en/datasets/detect/xview.md
+++ b/docs/en/datasets/detect/xview.md
@@ -6,7 +6,7 @@ keywords: xView dataset, overhead imagery, satellite images, object detection, h
# xView Dataset
-The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four computer vision frontiers:
+The [xView](http://xviewdataset.org/) dataset is one of the largest publicly available datasets of overhead imagery, containing images from complex scenes around the world annotated using bounding boxes. The goal of the xView dataset is to accelerate progress in four [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) frontiers:
1. Reduce minimum resolution for detection.
2. Improve learning efficiency.
@@ -19,8 +19,8 @@ xView builds on the success of challenges like Common Objects in Context (COCO)
- xView contains over 1 million object instances across 60 classes.
- The dataset has a resolution of 0.3 meters, providing higher resolution imagery than most public satellite imagery datasets.
-- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with bounding box annotation.
-- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for PyTorch.
+- xView features a diverse collection of small, rare, fine-grained, and multi-type objects with [bounding box](https://www.ultralytics.com/glossary/bounding-box) annotation.
+- Comes with a pre-trained baseline model using the TensorFlow object detection API and an example for [PyTorch](https://www.ultralytics.com/glossary/pytorch).
## Dataset Structure
@@ -42,7 +42,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a model on the xView dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a model on the xView dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -71,7 +71,7 @@ The xView dataset contains high-resolution satellite images with a diverse set o

-- **Overhead Imagery**: This image demonstrates an example of object detection in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
+- **Overhead Imagery**: This image demonstrates an example of [object detection](https://www.ultralytics.com/glossary/object-detection) in overhead imagery, where objects are annotated with bounding boxes. The dataset provides high-resolution satellite images to facilitate the development of models for this task.
The example showcases the variety and complexity of the data in the xView dataset and highlights the importance of high-quality satellite imagery for object detection tasks.
@@ -137,11 +137,11 @@ The xView dataset stands out due to its comprehensive set of features:
- Over 1 million object instances across 60 distinct classes.
- High-resolution imagery at 0.3 meters.
- Diverse object types including small, rare, and fine-grained objects, all annotated with bounding boxes.
-- Availability of a pre-trained baseline model and examples in TensorFlow and PyTorch.
+- Availability of a pre-trained baseline model and examples in [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) and PyTorch.
### What is the dataset structure of xView, and how is it annotated?
-The xView dataset comprises high-resolution satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It encompasses over 1 million objects across 60 classes in approximately 1,400 km² of imagery. Each object within the dataset is annotated with bounding boxes, making it ideal for training and evaluating deep learning models for object detection in overhead imagery. For a detailed overview, you can look at the dataset structure section [here](#dataset-structure).
+The xView dataset comprises high-resolution satellite images collected from WorldView-3 satellites at a 0.3m ground sample distance. It encompasses over 1 million objects across 60 classes in approximately 1,400 km² of imagery. Each object within the dataset is annotated with bounding boxes, making it ideal for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models for object detection in overhead imagery. For a detailed overview, you can look at the dataset structure section [here](#dataset-structure).
### How do I cite the xView dataset in my research?
diff --git a/docs/en/datasets/explorer/api.md b/docs/en/datasets/explorer/api.md
index 905142efa7..6c716c14c5 100644
--- a/docs/en/datasets/explorer/api.md
+++ b/docs/en/datasets/explorer/api.md
@@ -50,7 +50,7 @@ dataframe = explorer.get_similar(idx=0)
!!! note
- Embeddings table for a given dataset and model pair is only created once and reused. These use [LanceDB](https://lancedb.github.io/lancedb/) under the hood, which scales on-disk, so you can create and reuse embeddings for large datasets like COCO without running out of memory.
+ [Embeddings](https://www.ultralytics.com/glossary/embeddings) table for a given dataset and model pair is only created once and reused. These use [LanceDB](https://lancedb.github.io/lancedb/) under the hood, which scales on-disk, so you can create and reuse embeddings for large datasets like COCO without running out of memory.
In case you want to force update the embeddings table, you can pass `force=True` to `create_embeddings_table` method.
@@ -339,7 +339,7 @@ Try our GUI Demo based on Explorer API
### What is the Ultralytics Explorer API used for?
-The Ultralytics Explorer API is designed for comprehensive dataset exploration. It allows users to filter and search datasets using SQL queries, vector similarity search, and semantic search. This powerful Python API can handle large datasets, making it ideal for various computer vision tasks using Ultralytics models.
+The Ultralytics Explorer API is designed for comprehensive dataset exploration. It allows users to filter and search datasets using SQL queries, vector similarity search, and semantic search. This powerful Python API can handle large datasets, making it ideal for various [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks using Ultralytics models.
### How do I install the Ultralytics Explorer API?
diff --git a/docs/en/datasets/explorer/dashboard.md b/docs/en/datasets/explorer/dashboard.md
index 160d2b7abe..3bc3a21e46 100644
--- a/docs/en/datasets/explorer/dashboard.md
+++ b/docs/en/datasets/explorer/dashboard.md
@@ -36,7 +36,7 @@ pip install ultralytics[explorer]
## Vector Semantic Similarity Search
-Semantic search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar embeddings. In the UI, you can select one of more images and search for the images similar to them. This can be useful when you want to find images similar to a given image or a set of images that don't perform as expected.
+Semantic search is a technique for finding similar images to a given image. It is based on the idea that similar images will have similar [embeddings](https://www.ultralytics.com/glossary/embeddings). In the UI, you can select one of more images and search for the images similar to them. This can be useful when you want to find images similar to a given image or a set of images that don't perform as expected.
For example:
In this VOC Exploration dashboard, user selects a couple airplane images like this:
@@ -79,7 +79,7 @@ This is a Demo build using the Explorer API. You can use the API to build your o
### What is Ultralytics Explorer GUI and how do I install it?
-Ultralytics Explorer GUI is a powerful interface that unlocks advanced data exploration capabilities using the [Ultralytics Explorer API](api.md). It allows you to run semantic/vector similarity search, SQL queries, and natural language queries using the Ask AI feature powered by Large Language Models (LLMs).
+Ultralytics Explorer GUI is a powerful interface that unlocks advanced data exploration capabilities using the [Ultralytics Explorer API](api.md). It allows you to run semantic/vector similarity search, SQL queries, and natural language queries using the Ask AI feature powered by [Large Language Models](https://www.ultralytics.com/glossary/large-language-model-llm) (LLMs).
To install the Explorer GUI, you can use pip:
@@ -91,7 +91,7 @@ Note: To use the Ask AI feature, you'll need to set the OpenAI API key: `yolo se
### How does the semantic search feature in Ultralytics Explorer GUI work?
-The semantic search feature in Ultralytics Explorer GUI allows you to find images similar to a given image based on their embeddings. This technique is useful for identifying and exploring images that share visual similarities. To use this feature, select one or more images in the UI and execute a search for similar images. The result will display images that closely resemble the selected ones, facilitating efficient dataset exploration and anomaly detection.
+The semantic search feature in Ultralytics Explorer GUI allows you to find images similar to a given image based on their embeddings. This technique is useful for identifying and exploring images that share visual similarities. To use this feature, select one or more images in the UI and execute a search for similar images. The result will display images that closely resemble the selected ones, facilitating efficient dataset exploration and [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection).
Learn more about semantic search and other features by visiting the [Feature Overview](#vector-semantic-similarity-search) section.
diff --git a/docs/en/datasets/explorer/index.md b/docs/en/datasets/explorer/index.md
index d1092a7625..d7e7ab66d4 100644
--- a/docs/en/datasets/explorer/index.md
+++ b/docs/en/datasets/explorer/index.md
@@ -44,7 +44,7 @@ Learn more about the Explorer API [here](api.md).
## GUI Explorer Usage
-The GUI demo runs in your browser allowing you to create embeddings for your dataset and search for similar images, run SQL queries and perform semantic search. It can be run using the following command:
+The GUI demo runs in your browser allowing you to create [embeddings](https://www.ultralytics.com/glossary/embeddings) for your dataset and search for similar images, run SQL queries and perform semantic search. It can be run using the following command:
```bash
yolo explorer
@@ -63,7 +63,7 @@ yolo explorer
### What is Ultralytics Explorer and how can it help with CV datasets?
-Ultralytics Explorer is a powerful tool designed for exploring computer vision (CV) datasets through semantic search, SQL queries, vector similarity search, and even natural language. This versatile tool provides both a GUI and a Python API, allowing users to seamlessly interact with their datasets. By leveraging technologies like LanceDB, Ultralytics Explorer ensures efficient, scalable access to large datasets without excessive memory usage. Whether you're performing detailed dataset analysis or exploring data patterns, Ultralytics Explorer streamlines the entire process.
+Ultralytics Explorer is a powerful tool designed for exploring [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) (CV) datasets through semantic search, SQL queries, vector similarity search, and even natural language. This versatile tool provides both a GUI and a Python API, allowing users to seamlessly interact with their datasets. By leveraging technologies like LanceDB, Ultralytics Explorer ensures efficient, scalable access to large datasets without excessive memory usage. Whether you're performing detailed dataset analysis or exploring data patterns, Ultralytics Explorer streamlines the entire process.
Learn more about the [Explorer API](api.md).
diff --git a/docs/en/datasets/index.md b/docs/en/datasets/index.md
index 0a85ce15d0..19e395307b 100644
--- a/docs/en/datasets/index.md
+++ b/docs/en/datasets/index.md
@@ -6,7 +6,7 @@ keywords: Ultralytics, datasets, computer vision, object detection, instance seg
# Datasets Overview
-Ultralytics provides support for various datasets to facilitate computer vision tasks such as detection, instance segmentation, pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.
+Ultralytics provides support for various datasets to facilitate computer vision tasks such as detection, [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), pose estimation, classification, and multi-object tracking. Below is a list of the main Ultralytics datasets, followed by a summary of each computer vision task and the respective datasets.
@@ -21,7 +21,7 @@ Ultralytics provides support for various datasets to facilitate computer vision
## NEW 🚀 Ultralytics Explorer
-Create embeddings for your dataset, search for similar images, run SQL queries, perform semantic search and even search using natural language! You can get started with our GUI app or build your own using the API. Learn more [here](explorer/index.md).
+Create [embeddings](https://www.ultralytics.com/glossary/embeddings) for your dataset, search for similar images, run SQL queries, perform semantic search and even search using natural language! You can get started with our GUI app or build your own using the API. Learn more [here](explorer/index.md).
@@ -32,7 +32,7 @@ Create embeddings for your dataset, search for similar images, run SQL queries,
## [Object Detection](detect/index.md)
-Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
+[Bounding box](https://www.ultralytics.com/glossary/bounding-box) object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
- [COCO](detect/coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
@@ -72,7 +72,7 @@ Pose estimation is a technique used to determine the pose of the object relative
## [Classification](classify/index.md)
-Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
+[Image classification](https://www.ultralytics.com/glossary/image-classification) is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
- [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
- [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
@@ -152,7 +152,7 @@ By following these steps, you can contribute a new dataset that integrates well
## FAQ
-### What datasets does Ultralytics support for object detection?
+### What datasets does Ultralytics support for [object detection](https://www.ultralytics.com/glossary/object-detection)?
Ultralytics supports a wide variety of datasets for object detection, including:
@@ -190,7 +190,7 @@ Ultralytics Explorer offers powerful features for dataset analysis, including:
Explore the [Ultralytics Explorer](explorer/index.md) for more information and to try the [GUI Demo](explorer/index.md).
-### What are the unique features of Ultralytics YOLO models for computer vision?
+### What are the unique features of Ultralytics YOLO models for [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv)?
Ultralytics YOLO models provide several unique features:
diff --git a/docs/en/datasets/obb/dota-v2.md b/docs/en/datasets/obb/dota-v2.md
index 66b3ac5f21..76024cac10 100644
--- a/docs/en/datasets/obb/dota-v2.md
+++ b/docs/en/datasets/obb/dota-v2.md
@@ -6,7 +6,7 @@ keywords: DOTA dataset, object detection, aerial images, oriented bounding boxes
# DOTA Dataset with OBB
-[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing object detection in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).
+[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing [object detection](https://www.ultralytics.com/glossary/object-detection) in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).

@@ -128,7 +128,7 @@ Having a glance at the dataset illustrates its depth:

-- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented Bounding Box annotations, capturing objects in their natural orientation.
+- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented [Bounding Box](https://www.ultralytics.com/glossary/bounding-box) annotations, capturing objects in their natural orientation.
The dataset's richness offers invaluable insights into object detection challenges exclusive to aerial imagery.
diff --git a/docs/en/datasets/obb/dota8.md b/docs/en/datasets/obb/dota8.md
index 0188c31785..f24ea5bce2 100644
--- a/docs/en/datasets/obb/dota8.md
+++ b/docs/en/datasets/obb/dota8.md
@@ -8,7 +8,7 @@ keywords: DOTA8 dataset, Ultralytics, YOLOv8, object detection, debugging, train
## Introduction
-[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented object detection dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented [object detection](https://www.ultralytics.com/glossary/object-detection) dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@@ -24,7 +24,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-obb model on the DOTA8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -121,4 +121,4 @@ Mosaicing combines multiple images into one during training, increasing the vari
### Why should I use Ultralytics YOLOv8 for object detection tasks?
-Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), instance segmentation, and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
+Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index 4ca53497be..edeffb83af 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -6,7 +6,7 @@ keywords: Oriented Bounding Box, OBB Datasets, YOLO, Ultralytics, Object Detecti
# Oriented Bounding Box (OBB) Datasets Overview
-Training a precise object detection model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
+Training a precise [object detection](https://www.ultralytics.com/glossary/object-detection) model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
## Supported OBB Dataset Formats
@@ -18,7 +18,7 @@ The YOLO OBB format designates bounding boxes by their four corner points with c
class_index x1 y1 x2 y2 x3 y3 x4 y4
```
-Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
+Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the [bounding box](https://www.ultralytics.com/glossary/bounding-box)'s center point (xy), width, height, and rotation.
@@ -129,7 +129,7 @@ Training a YOLOv8 model with OBBs involves ensuring your dataset is in the YOLO
yolo obb train data=your_dataset.yaml model=yolov8n-obb.yaml epochs=100 imgsz=640
```
-This ensures your model leverages the detailed OBB annotations for improved detection accuracy.
+This ensures your model leverages the detailed OBB annotations for improved detection [accuracy](https://www.ultralytics.com/glossary/accuracy).
### What datasets are currently supported for OBB training in Ultralytics YOLO models?
diff --git a/docs/en/datasets/pose/coco.md b/docs/en/datasets/pose/coco.md
index 8addbd96e3..20042b40e2 100644
--- a/docs/en/datasets/pose/coco.md
+++ b/docs/en/datasets/pose/coco.md
@@ -37,7 +37,7 @@ The COCO-Pose dataset is split into three subsets:
## Applications
-The COCO-Pose dataset is specifically used for training and evaluating deep learning models in keypoint detection and pose estimation tasks, such as OpenPose. The dataset's large number of annotated images and standardized evaluation metrics make it an essential resource for computer vision researchers and practitioners focused on pose estimation.
+The COCO-Pose dataset is specifically used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in keypoint detection and pose estimation tasks, such as OpenPose. The dataset's large number of annotated images and standardized evaluation metrics make it an essential resource for [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) researchers and practitioners focused on pose estimation.
## Dataset YAML
@@ -51,7 +51,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-pose model on the COCO-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-pose model on the COCO-Pose dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -140,7 +140,7 @@ For more details on the training process and available arguments, check the [tra
### What are the different metrics provided by the COCO-Pose dataset for evaluating model performance?
-The COCO-Pose dataset provides several standardized evaluation metrics for pose estimation tasks, similar to the original COCO dataset. Key metrics include the Object Keypoint Similarity (OKS), which evaluates the accuracy of predicted keypoints against ground truth annotations. These metrics allow for thorough performance comparisons between different models. For instance, the COCO-Pose pretrained models such as YOLOv8n-pose, YOLOv8s-pose, and others have specific performance metrics listed in the documentation, like mAPpose50-95 and mAPpose50.
+The COCO-Pose dataset provides several standardized evaluation metrics for pose estimation tasks, similar to the original COCO dataset. Key metrics include the Object Keypoint Similarity (OKS), which evaluates the [accuracy](https://www.ultralytics.com/glossary/accuracy) of predicted keypoints against ground truth annotations. These metrics allow for thorough performance comparisons between different models. For instance, the COCO-Pose pretrained models such as YOLOv8n-pose, YOLOv8s-pose, and others have specific performance metrics listed in the documentation, like mAPpose50-95 and mAPpose50.
### How is the dataset structured and split for the COCO-Pose dataset?
diff --git a/docs/en/datasets/pose/coco8-pose.md b/docs/en/datasets/pose/coco8-pose.md
index c5847e1129..95157b794e 100644
--- a/docs/en/datasets/pose/coco8-pose.md
+++ b/docs/en/datasets/pose/coco8-pose.md
@@ -8,7 +8,7 @@ keywords: COCO8-Pose, Ultralytics, pose detection dataset, object detection, YOL
## Introduction
-[Ultralytics](https://www.ultralytics.com/) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) COCO8-Pose is a small, but versatile pose detection dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging [object detection](https://www.ultralytics.com/glossary/object-detection) models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@@ -24,7 +24,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-pose model on the COCO8-Pose dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -76,7 +76,7 @@ If you use the COCO dataset in your research or development work, please cite th
}
```
-We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
## FAQ
diff --git a/docs/en/datasets/pose/index.md b/docs/en/datasets/pose/index.md
index 4288497174..9a6b6d930f 100644
--- a/docs/en/datasets/pose/index.md
+++ b/docs/en/datasets/pose/index.md
@@ -34,7 +34,7 @@ Format with Dim = 3
```
-In this format, `` is the index of the class for the object,`` are coordinates of bounding box, and ` ... ` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
+In this format, `` is the index of the class for the object,`` are coordinates of [bounding box](https://www.ultralytics.com/glossary/bounding-box), and ` ... ` are the pixel coordinates of the keypoints. The coordinates are separated by spaces.
### Dataset YAML format
@@ -91,7 +91,7 @@ This section outlines the datasets that are compatible with Ultralytics YOLO for
### COCO-Pose
-- **Description**: COCO-Pose is a large-scale object detection, segmentation, and pose estimation dataset. It is a subset of the popular COCO dataset and focuses on human pose estimation. COCO-Pose includes multiple keypoints for each human instance.
+- **Description**: COCO-Pose is a large-scale [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and pose estimation dataset. It is a subset of the popular COCO dataset and focuses on human pose estimation. COCO-Pose includes multiple keypoints for each human instance.
- **Label Format**: Same as Ultralytics YOLO format as described above, with keypoints for human poses.
- **Number of Classes**: 1 (Human).
- **Keypoints**: 17 keypoints including nose, eyes, ears, shoulders, elbows, wrists, hips, knees, and ankles.
diff --git a/docs/en/datasets/pose/tiger-pose.md b/docs/en/datasets/pose/tiger-pose.md
index 13f62232d6..06333b345b 100644
--- a/docs/en/datasets/pose/tiger-pose.md
+++ b/docs/en/datasets/pose/tiger-pose.md
@@ -37,7 +37,7 @@ A YAML (Yet Another Markup Language) file serves as the means to specify the con
## Usage
-To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-pose model on the Tiger-Pose dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -161,4 +161,4 @@ To perform inference using a YOLOv8 model trained on the Tiger-Pose dataset, you
### What are the benefits of using the Tiger-Pose dataset for pose estimation?
-The Tiger-Pose dataset, despite its manageable size of 210 images for training, provides a diverse collection of images that are ideal for testing pose estimation pipelines. The dataset helps identify potential errors and acts as a preliminary step before working with larger datasets. Additionally, the dataset supports the training and refinement of pose estimation algorithms using advanced tools like [Ultralytics HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics), enhancing model performance and accuracy.
+The Tiger-Pose dataset, despite its manageable size of 210 images for training, provides a diverse collection of images that are ideal for testing pose estimation pipelines. The dataset helps identify potential errors and acts as a preliminary step before working with larger datasets. Additionally, the dataset supports the training and refinement of pose estimation algorithms using advanced tools like [Ultralytics HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics), enhancing model performance and [accuracy](https://www.ultralytics.com/glossary/accuracy).
diff --git a/docs/en/datasets/segment/carparts-seg.md b/docs/en/datasets/segment/carparts-seg.md
index 6283cae8ce..b798cacad1 100644
--- a/docs/en/datasets/segment/carparts-seg.md
+++ b/docs/en/datasets/segment/carparts-seg.md
@@ -6,7 +6,7 @@ keywords: Carparts Segmentation Dataset, Roboflow, computer vision, automotive A
# Roboflow Universe Carparts Segmentation Dataset
-The [Roboflow](https://roboflow.com/?ref=ultralytics) [Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm?ref=ultralytics) is a curated collection of images and videos designed for computer vision applications, specifically focusing on segmentation tasks related to car parts. This dataset provides a diverse set of visuals captured from multiple perspectives, offering valuable annotated examples for training and testing segmentation models.
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Carparts Segmentation Dataset](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm?ref=ultralytics) is a curated collection of images and videos designed for [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) applications, specifically focusing on segmentation tasks related to car parts. This dataset provides a diverse set of visuals captured from multiple perspectives, offering valuable annotated examples for training and testing segmentation models.
Whether you're working on automotive research, developing AI solutions for vehicle maintenance, or exploring computer vision applications, the Carparts Segmentation Dataset serves as a valuable resource for enhancing accuracy and efficiency in your projects.
@@ -18,7 +18,7 @@ Whether you're working on automotive research, developing AI solutions for vehic
allowfullscreen>
- Watch: Carparts Instance Segmentation Using Ultralytics HUB
+ Watch: Carparts [Instance Segmentation](https://www.ultralytics.com/glossary/instance-segmentation) Using Ultralytics HUB
## Dataset Structure
@@ -45,7 +45,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train Ultralytics YOLOv8n model on the Carparts Segmentation dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -156,6 +156,6 @@ The dataset configuration file for the Carparts Segmentation dataset, `carparts-
### Why should I use the Carparts Segmentation Dataset?
-The Carparts Segmentation Dataset provides rich, annotated data essential for developing high-accuracy segmentation models in automotive computer vision. This dataset's diversity and detailed annotations improve model training, making it ideal for applications like vehicle maintenance automation, enhancing vehicle safety systems, and supporting autonomous driving technologies. Partnering with a robust dataset accelerates AI development and ensures better model performance.
+The Carparts Segmentation Dataset provides rich, annotated data essential for developing high-[accuracy](https://www.ultralytics.com/glossary/accuracy) segmentation models in automotive computer vision. This dataset's diversity and detailed annotations improve model training, making it ideal for applications like vehicle maintenance automation, enhancing vehicle safety systems, and supporting autonomous driving technologies. Partnering with a robust dataset accelerates AI development and ensures better model performance.
For more details, visit the [CarParts Segmentation Dataset Page](https://universe.roboflow.com/gianmarco-russo-vt9xr/car-seg-un1pm?ref=ultralytics).
diff --git a/docs/en/datasets/segment/coco.md b/docs/en/datasets/segment/coco.md
index 5c6b56402d..0f403c69af 100644
--- a/docs/en/datasets/segment/coco.md
+++ b/docs/en/datasets/segment/coco.md
@@ -6,7 +6,7 @@ keywords: COCO-Seg, dataset, YOLO models, instance segmentation, object detectio
# COCO-Seg Dataset
-The [COCO-Seg](https://cocodataset.org/#home) dataset, an extension of the COCO (Common Objects in Context) dataset, is specially designed to aid research in object instance segmentation. It uses the same images as COCO but introduces more detailed segmentation annotations. This dataset is a crucial resource for researchers and developers working on instance segmentation tasks, especially for training YOLO models.
+The [COCO-Seg](https://cocodataset.org/#home) dataset, an extension of the COCO (Common Objects in Context) dataset, is specially designed to aid research in object [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation). It uses the same images as COCO but introduces more detailed segmentation annotations. This dataset is a crucial resource for researchers and developers working on instance segmentation tasks, especially for training YOLO models.
## COCO-Seg Pretrained Models
@@ -23,7 +23,7 @@ The [COCO-Seg](https://cocodataset.org/#home) dataset, an extension of the COCO
- COCO-Seg retains the original 330K images from COCO.
- The dataset consists of the same 80 object categories found in the original COCO dataset.
- Annotations now include more detailed instance segmentation masks for each object in the images.
-- COCO-Seg provides standardized evaluation metrics like mean Average Precision (mAP) for object detection, and mean Average Recall (mAR) for instance segmentation tasks, enabling effective comparison of model performance.
+- COCO-Seg provides standardized evaluation metrics like [mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) for object detection, and mean Average [Recall](https://www.ultralytics.com/glossary/recall) (mAR) for instance segmentation tasks, enabling effective comparison of model performance.
## Dataset Structure
@@ -35,7 +35,7 @@ The COCO-Seg dataset is partitioned into three subsets:
## Applications
-COCO-Seg is widely used for training and evaluating deep learning models in instance segmentation, such as the YOLO models. The large number of annotated images, the diversity of object categories, and the standardized evaluation metrics make it an indispensable resource for computer vision researchers and practitioners.
+COCO-Seg is widely used for training and evaluating [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models in instance segmentation, such as the YOLO models. The large number of annotated images, the diversity of object categories, and the standardized evaluation metrics make it an indispensable resource for computer vision researchers and practitioners.
## Dataset YAML
@@ -49,7 +49,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-seg model on the COCO-Seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -101,7 +101,7 @@ If you use the COCO-Seg dataset in your research or development work, please cit
}
```
-We extend our thanks to the COCO Consortium for creating and maintaining this invaluable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+We extend our thanks to the COCO Consortium for creating and maintaining this invaluable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
## FAQ
@@ -141,7 +141,7 @@ The COCO-Seg dataset includes several key features:
- Retains the original 330K images from the COCO dataset.
- Annotates the same 80 object categories found in the original COCO.
- Provides more detailed instance segmentation masks for each object.
-- Uses standardized evaluation metrics such as mean Average Precision (mAP) for object detection and mean Average Recall (mAR) for instance segmentation tasks.
+- Uses standardized evaluation metrics such as mean Average [Precision](https://www.ultralytics.com/glossary/precision) (mAP) for [object detection](https://www.ultralytics.com/glossary/object-detection) and mean Average Recall (mAR) for instance segmentation tasks.
### What pretrained models are available for COCO-Seg, and what are their performance metrics?
diff --git a/docs/en/datasets/segment/coco8-seg.md b/docs/en/datasets/segment/coco8-seg.md
index 50a7f41af9..21abf3d802 100644
--- a/docs/en/datasets/segment/coco8-seg.md
+++ b/docs/en/datasets/segment/coco8-seg.md
@@ -8,7 +8,7 @@ keywords: COCO8-Seg, Ultralytics, segmentation dataset, YOLOv8, COCO 2017, model
## Introduction
-[Ultralytics](https://www.ultralytics.com/) COCO8-Seg is a small, but versatile instance segmentation dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) COCO8-Seg is a small, but versatile [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) dataset composed of the first 8 images of the COCO train 2017 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging segmentation models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@@ -24,7 +24,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-seg model on the COCO8-Seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -76,7 +76,7 @@ If you use the COCO dataset in your research or development work, please cite th
}
```
-We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the computer vision community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
+We would like to acknowledge the COCO Consortium for creating and maintaining this valuable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about the COCO dataset and its creators, visit the [COCO dataset website](https://cocodataset.org/#home).
## FAQ
@@ -121,4 +121,4 @@ The YAML configuration file for the **COCO8-Seg dataset** is available in the Ul
### What are some benefits of using mosaicing during training with the COCO8-Seg dataset?
-Using **mosaicing** during training helps increase the diversity and variety of objects and scenes in each training batch. This technique combines multiple images into a single composite image, enhancing the model's ability to generalize to different object sizes, aspect ratios, and contexts within the scene. Mosaicing is beneficial for improving a model's robustness and accuracy, especially when working with small datasets like COCO8-Seg. For an example of mosaiced images, see the [Sample Images and Annotations](#sample-images-and-annotations) section.
+Using **mosaicing** during training helps increase the diversity and variety of objects and scenes in each training batch. This technique combines multiple images into a single composite image, enhancing the model's ability to generalize to different object sizes, aspect ratios, and contexts within the scene. Mosaicing is beneficial for improving a model's robustness and [accuracy](https://www.ultralytics.com/glossary/accuracy), especially when working with small datasets like COCO8-Seg. For an example of mosaiced images, see the [Sample Images and Annotations](#sample-images-and-annotations) section.
diff --git a/docs/en/datasets/segment/crack-seg.md b/docs/en/datasets/segment/crack-seg.md
index ed66d7cf94..f5ffbe92e0 100644
--- a/docs/en/datasets/segment/crack-seg.md
+++ b/docs/en/datasets/segment/crack-seg.md
@@ -6,9 +6,9 @@ keywords: Roboflow, Crack Segmentation Dataset, Ultralytics, transportation safe
# Roboflow Universe Crack Segmentation Dataset
-The [Roboflow](https://roboflow.com/?ref=ultralytics) [Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr?ref=ultralytics) stands out as an extensive resource designed specifically for individuals involved in transportation and public safety studies. It is equally beneficial for those working on the development of self-driving car models or simply exploring computer vision applications for recreational purposes.
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Crack Segmentation Dataset](https://universe.roboflow.com/university-bswxt/crack-bphdr?ref=ultralytics) stands out as an extensive resource designed specifically for individuals involved in transportation and public safety studies. It is equally beneficial for those working on the development of self-driving car models or simply exploring [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) applications for recreational purposes.
-Comprising a total of 4029 static images captured from diverse road and wall scenarios, this dataset emerges as a valuable asset for tasks related to crack segmentation. Whether you are delving into the intricacies of transportation research or seeking to enhance the accuracy of your self-driving car models, this dataset provides a rich and varied collection of images to support your endeavors.
+Comprising a total of 4029 static images captured from diverse road and wall scenarios, this dataset emerges as a valuable asset for tasks related to crack segmentation. Whether you are delving into the intricacies of transportation research or seeking to enhance the [accuracy](https://www.ultralytics.com/glossary/accuracy) of your self-driving car models, this dataset provides a rich and varied collection of images to support your endeavors.
## Dataset Structure
@@ -34,7 +34,7 @@ A YAML (Yet Another Markup Language) file is employed to outline the configurati
## Usage
-To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train Ultralytics YOLOv8n model on the Crack Segmentation dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -129,7 +129,7 @@ The Crack Segmentation Dataset is exceptionally suited for self-driving car proj
### What unique features does Ultralytics YOLO offer for crack segmentation?
-Ultralytics YOLO offers advanced real-time object detection, segmentation, and classification capabilities that make it ideal for crack segmentation tasks. Its ability to handle large datasets and complex scenarios ensures high accuracy and efficiency. For example, the model [Training](../../modes/train.md), [Predict](../../modes/predict.md), and [Export](../../modes/export.md) modes cover comprehensive functionalities from training to deployment.
+Ultralytics YOLO offers advanced real-time [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification capabilities that make it ideal for crack segmentation tasks. Its ability to handle large datasets and complex scenarios ensures high accuracy and efficiency. For example, the model [Training](../../modes/train.md), [Predict](../../modes/predict.md), and [Export](../../modes/export.md) modes cover comprehensive functionalities from training to deployment.
### How do I cite the Roboflow Crack Segmentation Dataset in my research paper?
diff --git a/docs/en/datasets/segment/index.md b/docs/en/datasets/segment/index.md
index 4d39fc124c..52b1978164 100644
--- a/docs/en/datasets/segment/index.md
+++ b/docs/en/datasets/segment/index.md
@@ -91,9 +91,9 @@ The `train` and `val` fields specify the paths to the directories containing the
## Supported Datasets
-- [COCO](coco.md): A comprehensive dataset for object detection, segmentation, and captioning, featuring over 200K labeled images across a wide range of categories.
+- [COCO](coco.md): A comprehensive dataset for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and captioning, featuring over 200K labeled images across a wide range of categories.
- [COCO8-seg](coco8-seg.md): A compact, 8-image subset of COCO designed for quick testing of segmentation model training, ideal for CI checks and workflow validation in the `ultralytics` repository.
-- [COCO128-seg](coco.md): A smaller dataset for instance segmentation tasks, containing a subset of 128 COCO images with segmentation annotations.
+- [COCO128-seg](coco.md): A smaller dataset for [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) tasks, containing a subset of 128 COCO images with segmentation annotations.
- [Carparts-seg](carparts-seg.md): A specialized dataset focused on the segmentation of car parts, ideal for automotive applications. It includes a variety of vehicles with detailed annotations of individual car components.
- [Crack-seg](crack-seg.md): A dataset tailored for the segmentation of cracks in various surfaces. Essential for infrastructure maintenance and quality control, it provides detailed imagery for training models to identify structural weaknesses.
- [Package-seg](package-seg.md): A dataset dedicated to the segmentation of different types of packaging materials and shapes. It's particularly useful for logistics and warehouse automation, aiding in the development of systems for package handling and sorting.
diff --git a/docs/en/datasets/segment/package-seg.md b/docs/en/datasets/segment/package-seg.md
index db5f62be5f..477072fb57 100644
--- a/docs/en/datasets/segment/package-seg.md
+++ b/docs/en/datasets/segment/package-seg.md
@@ -6,7 +6,7 @@ keywords: Roboflow, Package Segmentation Dataset, computer vision, package ident
# Roboflow Universe Package Segmentation Dataset
-The [Roboflow](https://roboflow.com/?ref=ultralytics) [Package Segmentation Dataset](https://universe.roboflow.com/factorypackage/factory_package?ref=ultralytics) is a curated collection of images specifically tailored for tasks related to package segmentation in the field of computer vision. This dataset is designed to assist researchers, developers, and enthusiasts working on projects related to package identification, sorting, and handling.
+The [Roboflow](https://roboflow.com/?ref=ultralytics) [Package Segmentation Dataset](https://universe.roboflow.com/factorypackage/factory_package?ref=ultralytics) is a curated collection of images specifically tailored for tasks related to package segmentation in the field of [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). This dataset is designed to assist researchers, developers, and enthusiasts working on projects related to package identification, sorting, and handling.
Containing a diverse set of images showcasing various packages in different contexts and environments, the dataset serves as a valuable resource for training and evaluating segmentation models. Whether you are engaged in logistics, warehouse automation, or any application requiring precise package analysis, the Package Segmentation Dataset provides a targeted and comprehensive set of images to enhance the performance of your computer vision algorithms.
@@ -34,7 +34,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train Ultralytics YOLOv8n model on the Package Segmentation dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -63,7 +63,7 @@ The Package Segmentation dataset comprises a varied collection of images and vid

-- This image displays an instance of image object detection, featuring annotated bounding boxes with masks outlining recognized objects. The dataset incorporates a diverse collection of images taken in different locations, environments, and densities. It serves as a comprehensive resource for developing models specific to this task.
+- This image displays an instance of image [object detection](https://www.ultralytics.com/glossary/object-detection), featuring annotated bounding boxes with masks outlining recognized objects. The dataset incorporates a diverse collection of images taken in different locations, environments, and densities. It serves as a comprehensive resource for developing models specific to this task.
- The example emphasizes the diversity and complexity present in the VisDrone dataset, underscoring the significance of high-quality sensor data for computer vision tasks involving drones.
## Citations and Acknowledgments
@@ -136,7 +136,7 @@ This structure ensures a balanced dataset for thorough model training, validatio
### Why should I use Ultralytics YOLOv8 with the Package Segmentation Dataset?
-Ultralytics YOLOv8 provides state-of-the-art accuracy and speed for real-time object detection and segmentation tasks. Using it with the Package Segmentation Dataset allows you to leverage YOLOv8's capabilities for precise package segmentation. This combination is especially beneficial for industries like logistics and warehouse automation, where accurate package identification is critical. For more information, check out our [page on YOLOv8 segmentation](https://docs.ultralytics.com/models/yolov8/).
+Ultralytics YOLOv8 provides state-of-the-art [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed for real-time object detection and segmentation tasks. Using it with the Package Segmentation Dataset allows you to leverage YOLOv8's capabilities for precise package segmentation. This combination is especially beneficial for industries like logistics and warehouse automation, where accurate package identification is critical. For more information, check out our [page on YOLOv8 segmentation](https://docs.ultralytics.com/models/yolov8/).
### How can I access and use the package-seg.yaml file for the Package Segmentation Dataset?
diff --git a/docs/en/datasets/track/index.md b/docs/en/datasets/track/index.md
index a2e5c13107..f9a8b4f81b 100644
--- a/docs/en/datasets/track/index.md
+++ b/docs/en/datasets/track/index.md
@@ -52,7 +52,7 @@ To use Multi-Object Tracking with Ultralytics YOLO, you can start by using the P
yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3 iou=0.5 show
```
-These commands load the YOLOv8 model and use it for tracking objects in the given video source with specific confidence (`conf`) and Intersection over Union (`iou`) thresholds. For more details, refer to the [track mode documentation](../../modes/track.md).
+These commands load the YOLOv8 model and use it for tracking objects in the given video source with specific confidence (`conf`) and [Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (`iou`) thresholds. For more details, refer to the [track mode documentation](../../modes/track.md).
### What are the upcoming features for training trackers in Ultralytics?
@@ -60,7 +60,7 @@ Ultralytics is continuously enhancing its AI models. An upcoming feature will en
### Why should I use Ultralytics YOLO for multi-object tracking?
-Ultralytics YOLO is a state-of-the-art object detection model known for its real-time performance and high accuracy. Using YOLO for multi-object tracking provides several advantages:
+Ultralytics YOLO is a state-of-the-art [object detection](https://www.ultralytics.com/glossary/object-detection) model known for its real-time performance and high [accuracy](https://www.ultralytics.com/glossary/accuracy). Using YOLO for multi-object tracking provides several advantages:
- **Real-time tracking:** Achieve efficient and high-speed tracking ideal for dynamic environments.
- **Flexibility with pre-trained models:** No need to train from scratch; simply use pre-trained detection, segmentation, or Pose models.
diff --git a/docs/en/guides/analytics.md b/docs/en/guides/analytics.md
index 8da149d3f3..7519f0324f 100644
--- a/docs/en/guides/analytics.md
+++ b/docs/en/guides/analytics.md
@@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, data visualization, line graphs, bar plots, pie c
## Introduction
-This guide provides a comprehensive overview of three fundamental types of data visualizations: line graphs, bar plots, and pie charts. Each section includes step-by-step instructions and code snippets on how to create these visualizations using Python.
+This guide provides a comprehensive overview of three fundamental types of [data visualizations](https://www.ultralytics.com/glossary/data-visualization): line graphs, bar plots, and pie charts. Each section includes step-by-step instructions and code snippets on how to create these visualizations using Python.
### Visual Samples
@@ -361,7 +361,7 @@ For further details on configuring the `Analytics` class, visit the [Analytics u
Using Ultralytics YOLOv8 for creating bar plots offers several benefits:
-1. **Real-time Data Visualization**: Seamlessly integrate object detection results into bar plots for dynamic updates.
+1. **Real-time Data Visualization**: Seamlessly integrate [object detection](https://www.ultralytics.com/glossary/object-detection) results into bar plots for dynamic updates.
2. **Ease of Use**: Simple API and functions make it straightforward to implement and visualize data.
3. **Customization**: Customize titles, labels, colors, and more to fit your specific requirements.
4. **Efficiency**: Efficiently handle large amounts of data and update plots in real-time during video processing.
@@ -472,11 +472,11 @@ cv2.destroyAllWindows()
To learn about the complete functionality, see the [Tracking](../modes/track.md) section.
-### What makes Ultralytics YOLOv8 different from other object detection solutions like OpenCV and TensorFlow?
+### What makes Ultralytics YOLOv8 different from other object detection solutions like [OpenCV](https://www.ultralytics.com/glossary/opencv) and [TensorFlow](https://www.ultralytics.com/glossary/tensorflow)?
Ultralytics YOLOv8 stands out from other object detection solutions like OpenCV and TensorFlow for multiple reasons:
-1. **State-of-the-art Accuracy**: YOLOv8 provides superior accuracy in object detection, segmentation, and classification tasks.
+1. **State-of-the-art [Accuracy](https://www.ultralytics.com/glossary/accuracy)**: YOLOv8 provides superior accuracy in object detection, segmentation, and classification tasks.
2. **Ease of Use**: User-friendly API allows for quick implementation and integration without extensive coding.
3. **Real-time Performance**: Optimized for high-speed inference, suitable for real-time applications.
4. **Diverse Applications**: Supports various tasks including multi-object tracking, custom model training, and exporting to different formats like ONNX, TensorRT, and CoreML.
diff --git a/docs/en/guides/azureml-quickstart.md b/docs/en/guides/azureml-quickstart.md
index 92e3d83787..a769eee10d 100644
--- a/docs/en/guides/azureml-quickstart.md
+++ b/docs/en/guides/azureml-quickstart.md
@@ -8,7 +8,7 @@ keywords: YOLOv8, AzureML, machine learning, cloud computing, quickstart, termin
## What is Azure?
-[Azure](https://azure.microsoft.com/) is Microsoft's cloud computing platform, designed to help organizations move their workloads to the cloud from on-premises data centers. With the full spectrum of cloud services including those for computing, databases, analytics, machine learning, and networking, users can pick and choose from these services to develop and scale new applications, or run existing applications, in the public cloud.
+[Azure](https://azure.microsoft.com/) is Microsoft's [cloud computing](https://www.ultralytics.com/glossary/cloud-computing) platform, designed to help organizations move their workloads to the cloud from on-premises data centers. With the full spectrum of cloud services including those for computing, databases, analytics, [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml), and networking, users can pick and choose from these services to develop and scale new applications, or run existing applications, in the public cloud.
## What is Azure Machine Learning (AzureML)?
@@ -71,7 +71,7 @@ Predict:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
```
-Train a detection model for 10 epochs with an initial learning_rate of 0.01:
+Train a detection model for 10 [epochs](https://www.ultralytics.com/glossary/epoch) with an initial learning_rate of 0.01:
```bash
yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
@@ -216,12 +216,12 @@ Yes, AzureML allows you to use both the Ultralytics CLI and the Python interface
Refer to the quickstart guides for more detailed instructions [here](../quickstart.md#use-ultralytics-with-cli) and [here](../quickstart.md#use-ultralytics-with-python).
-### What is the advantage of using Ultralytics YOLOv8 over other object detection models?
+### What is the advantage of using Ultralytics YOLOv8 over other [object detection](https://www.ultralytics.com/glossary/object-detection) models?
Ultralytics YOLOv8 offers several unique advantages over competing object detection models:
- **Speed**: Faster inference and training times compared to models like Faster R-CNN and SSD.
-- **Accuracy**: High accuracy in detection tasks with features like anchor-free design and enhanced augmentation strategies.
+- **[Accuracy](https://www.ultralytics.com/glossary/accuracy)**: High accuracy in detection tasks with features like anchor-free design and enhanced augmentation strategies.
- **Ease of Use**: Intuitive API and CLI for quick setup, making it accessible both to beginners and experts.
To explore more about YOLOv8's features, visit the [Ultralytics YOLO](https://www.ultralytics.com/yolo) page for detailed insights.
diff --git a/docs/en/guides/conda-quickstart.md b/docs/en/guides/conda-quickstart.md
index 7afb202b2a..6b52339260 100644
--- a/docs/en/guides/conda-quickstart.md
+++ b/docs/en/guides/conda-quickstart.md
@@ -10,7 +10,7 @@ keywords: Ultralytics, Conda, setup, installation, environment, guide, machine l
-This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
+This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
@@ -68,7 +68,7 @@ conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cu
## Using Ultralytics
-With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
+With Ultralytics installed, you can now start using its robust features for [object detection](https://www.ultralytics.com/glossary/object-detection), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and more. For example, to predict an image, you can run:
```python
from ultralytics import YOLO
@@ -162,7 +162,7 @@ Yes, you can enhance performance by utilizing a CUDA-enabled environment. Ensure
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
```
-This setup enables GPU acceleration, crucial for intensive tasks like deep learning model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
+This setup enables GPU acceleration, crucial for intensive tasks like [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
### What are the benefits of using Ultralytics Docker images with a Conda environment?
diff --git a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
index 8f8f076746..db61c08196 100644
--- a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
+++ b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
@@ -12,7 +12,7 @@ keywords: Coral Edge TPU, Raspberry Pi, YOLOv8, Ultralytics, TensorFlow Lite, ML
## What is a Coral Edge TPU?
-The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for TensorFlow Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
+The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
@@ -38,7 +38,7 @@ The [existing guide](https://coral.ai/docs/accelerator/get-started/) by Coral on
- [Raspberry Pi 4B](https://www.raspberrypi.com/products/raspberry-pi-4-model-b/) (2GB or more recommended) or [Raspberry Pi 5](https://www.raspberrypi.com/products/raspberry-pi-5/) (Recommended)
- [Raspberry Pi OS](https://www.raspberrypi.com/software/) Bullseye/Bookworm (64-bit) with desktop (Recommended)
- [Coral USB Accelerator](https://coral.ai/products/accelerator/)
-- A non-ARM based platform for exporting an Ultralytics PyTorch model
+- A non-ARM based platform for exporting an Ultralytics [PyTorch](https://www.ultralytics.com/glossary/pytorch) model
## Installation Walkthrough
@@ -154,7 +154,7 @@ Find comprehensive information on the [Predict](../modes/predict.md) page for fu
### What is a Coral Edge TPU and how does it enhance Raspberry Pi's performance with Ultralytics YOLOv8?
-The Coral Edge TPU is a compact device designed to add an Edge TPU coprocessor to your system. This coprocessor enables low-power, high-performance machine learning inference, particularly optimized for TensorFlow Lite models. When using a Raspberry Pi, the Edge TPU accelerates ML model inference, significantly boosting performance, especially for Ultralytics YOLOv8 models. You can read more about the Coral Edge TPU on their [home page](https://coral.ai/products/accelerator).
+The Coral Edge TPU is a compact device designed to add an Edge TPU coprocessor to your system. This coprocessor enables low-power, high-performance [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) inference, particularly optimized for TensorFlow Lite models. When using a Raspberry Pi, the Edge TPU accelerates ML model inference, significantly boosting performance, especially for Ultralytics YOLOv8 models. You can read more about the Coral Edge TPU on their [home page](https://coral.ai/products/accelerator).
### How do I install the Coral Edge TPU runtime on a Raspberry Pi?
diff --git a/docs/en/guides/data-collection-and-annotation.md b/docs/en/guides/data-collection-and-annotation.md
index 7939d12a42..6ca205260e 100644
--- a/docs/en/guides/data-collection-and-annotation.md
+++ b/docs/en/guides/data-collection-and-annotation.md
@@ -35,7 +35,7 @@ You can use public datasets or gather your own custom data. Public datasets like
Custom data collection, on the other hand, allows you to customize your dataset to your specific needs. You might capture images and videos with cameras or drones, scrape the web for images, or use existing internal data from your organization. Custom data gives you more control over its quality and relevance. Combining both public and custom data sources helps create a diverse and comprehensive dataset.
-### Avoiding Bias in Data Collection
+### Avoiding [Bias in](https://www.ultralytics.com/glossary/bias-in-ai) Data Collection
Bias occurs when certain groups or scenarios are underrepresented or overrepresented in your dataset. It leads to a model that performs well on some data but poorly on others. It's crucial to avoid bias so that your computer vision model can perform well in a variety of scenarios.
@@ -44,20 +44,20 @@ Here is how you can avoid bias while collecting data:
- **Diverse Sources**: Collect data from many sources to capture different perspectives and scenarios.
- **Balanced Representation**: Include balanced representation from all relevant groups. For example, consider different ages, genders, and ethnicities.
- **Continuous Monitoring**: Regularly review and update your dataset to identify and address any emerging biases.
-- **Bias Mitigation Techniques**: Use methods like oversampling underrepresented classes, data augmentation, and fairness-aware algorithms.
+- **Bias Mitigation Techniques**: Use methods like oversampling underrepresented classes, [data augmentation](https://www.ultralytics.com/glossary/data-augmentation), and fairness-aware algorithms.
Following these practices helps create a more robust and fair model that can generalize well in real-world applications.
## What is Data Annotation?
-Data annotation is the process of labeling data to make it usable for training machine learning models. In computer vision, this means labeling images or videos with the information that a model needs to learn from. Without properly annotated data, models cannot accurately learn the relationships between inputs and outputs.
+Data annotation is the process of labeling data to make it usable for training [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models. In computer vision, this means labeling images or videos with the information that a model needs to learn from. Without properly annotated data, models cannot accurately learn the relationships between inputs and outputs.
### Types of Data Annotation
Depending on the specific requirements of a [computer vision task](../tasks/index.md), there are different types of data annotation. Here are some examples:
- **Bounding Boxes**: Rectangular boxes drawn around objects in an image, used primarily for object detection tasks. These boxes are defined by their top-left and bottom-right coordinates.
-- **Polygons**: Detailed outlines for objects, allowing for more precise annotation than bounding boxes. Polygons are used in tasks like instance segmentation, where the shape of the object is important.
+- **Polygons**: Detailed outlines for objects, allowing for more precise annotation than bounding boxes. Polygons are used in tasks like [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), where the shape of the object is important.
- **Masks**: Binary masks where each pixel is either part of an object or the background. Masks are used in semantic segmentation tasks to provide pixel-level detail.
- **Keypoints**: Specific points marked within an image to identify locations of interest. Keypoints are used in tasks like pose estimation and facial landmark detection.
@@ -69,11 +69,11 @@ Depending on the specific requirements of a [computer vision task](../tasks/inde
After selecting a type of annotation, it's important to choose the appropriate format for storing and sharing annotations.
-Commonly used formats include [COCO](../datasets/detect/coco.md), which supports various annotation types like object detection, keypoint detection, stuff segmentation, panoptic segmentation, and image captioning, stored in JSON. [Pascal VOC](../datasets/detect/voc.md) uses XML files and is popular for object detection tasks. YOLO, on the other hand, creates a .txt file for each image, containing annotations like object class, coordinates, height, and width, making it suitable for object detection.
+Commonly used formats include [COCO](../datasets/detect/coco.md), which supports various annotation types like [object detection](https://www.ultralytics.com/glossary/object-detection), keypoint detection, stuff segmentation, [panoptic segmentation](https://www.ultralytics.com/glossary/panoptic-segmentation), and image captioning, stored in JSON. [Pascal VOC](../datasets/detect/voc.md) uses XML files and is popular for object detection tasks. YOLO, on the other hand, creates a .txt file for each image, containing annotations like object class, coordinates, height, and width, making it suitable for object detection.
### Techniques of Annotation
-Now, assuming you've chosen a type of annotation and format, it's time to establish clear and objective labeling rules. These rules are like a roadmap for consistency and accuracy throughout the annotation process. Key aspects of these rules include:
+Now, assuming you've chosen a type of annotation and format, it's time to establish clear and objective labeling rules. These rules are like a roadmap for consistency and [accuracy](https://www.ultralytics.com/glossary/accuracy) throughout the annotation process. Key aspects of these rules include:
- **Clarity and Detail**: Make sure your instructions are clear. Use examples and illustrations to understand what's expected.
- **Consistency**: Keep your annotations uniform. Set standard criteria for annotating different types of data, so all annotations follow the same rules.
@@ -98,11 +98,11 @@ These open-source tools are budget-friendly and provide a range of features to m
### Some More Things to Consider Before Annotating Data
-Before you dive into annotating your data, there are a few more things to keep in mind. You should be aware of accuracy, precision, outliers, and quality control to avoid labeling your data in a counterproductive manner.
+Before you dive into annotating your data, there are a few more things to keep in mind. You should be aware of accuracy, [precision](https://www.ultralytics.com/glossary/precision), outliers, and quality control to avoid labeling your data in a counterproductive manner.
#### Understanding Accuracy and Precision
-It's important to understand the difference between accuracy and precision and how it relates to annotation. Accuracy refers to how close the annotated data is to the true values. It helps us measure how closely the labels reflect real-world scenarios. Precision indicates the consistency of annotations. It checks if you are giving the same label to the same object or feature throughout the dataset. High accuracy and precision lead to better-trained models by reducing noise and improving the model's ability to generalize from the training data.
+It's important to understand the difference between accuracy and precision and how it relates to annotation. Accuracy refers to how close the annotated data is to the true values. It helps us measure how closely the labels reflect real-world scenarios. Precision indicates the consistency of annotations. It checks if you are giving the same label to the same object or feature throughout the dataset. High accuracy and precision lead to better-trained models by reducing noise and improving the model's ability to generalize from the [training data](https://www.ultralytics.com/glossary/training-data).
@@ -114,9 +114,9 @@ Outliers are data points that deviate quite a bit from other observations in the
You can use various methods to detect and correct outliers:
-- **Statistical Techniques**: To detect outliers in numerical features like pixel values, bounding box coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
+- **Statistical Techniques**: To detect outliers in numerical features like pixel values, [bounding box](https://www.ultralytics.com/glossary/bounding-box) coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
- **Visual Techniques**: To spot anomalies in categorical features like object classes, colors, or shapes, use visual methods like plotting images, labels, or heat maps.
-- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and anomaly detection algorithms to identify outliers based on data distribution patterns.
+- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) algorithms to identify outliers based on data distribution patterns.
#### Quality Control of Annotated Data
@@ -132,7 +132,7 @@ While reviewing, if you find errors, correct them and update the guidelines to a
## Share Your Thoughts with the Community
-Bouncing your ideas and queries off other computer vision enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
+Bouncing your ideas and queries off other [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
### Where to Find Help and Support
@@ -159,7 +159,7 @@ Ensuring high consistency and accuracy in data annotation involves establishing
### How many images do I need for training Ultralytics YOLO models?
-For effective transfer learning and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 epochs. More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
+For effective [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 [epochs](https://www.ultralytics.com/glossary/epoch). More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
### What are some popular tools for data annotation?
@@ -177,7 +177,7 @@ Different types of data annotation cater to various computer vision tasks:
- **Bounding Boxes**: Used primarily for object detection, these are rectangular boxes around objects in an image.
- **Polygons**: Provide more precise object outlines suitable for instance segmentation tasks.
-- **Masks**: Offer pixel-level detail, used in semantic segmentation to differentiate objects from the background.
+- **Masks**: Offer pixel-level detail, used in [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation) to differentiate objects from the background.
- **Keypoints**: Identify specific points of interest within an image, useful for tasks like pose estimation and facial landmark detection.
Selecting the appropriate annotation type depends on your project's requirements. Learn more about how to implement these annotations and their formats in our [data annotation guide](#what-is-data-annotation).
diff --git a/docs/en/guides/deepstream-nvidia-jetson.md b/docs/en/guides/deepstream-nvidia-jetson.md
index cd114b8690..ab15009b99 100644
--- a/docs/en/guides/deepstream-nvidia-jetson.md
+++ b/docs/en/guides/deepstream-nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA DeepStream?
-[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
+[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate [neural networks](https://www.ultralytics.com/glossary/neural-network-nn) and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
## Prerequisites
@@ -183,7 +183,7 @@ deepstream-app -c deepstream_app_config.txt
!!! tip
- If you want to convert the model to FP16 precision, simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
+ If you want to convert the model to FP16 [precision](https://www.ultralytics.com/glossary/precision), simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
## INT8 Calibration
@@ -219,7 +219,7 @@ If you want to use INT8 precision for inference, you need to follow the steps be
!!! note
- NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
+ NVIDIA recommends at least 500 images to get a good [accuracy](https://www.ultralytics.com/glossary/accuracy). On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
6. Create the `calibration.txt` file with all selected images
@@ -323,7 +323,7 @@ To set up Ultralytics YOLOv8 on an [NVIDIA Jetson](https://www.nvidia.com/en-us/
### What is the benefit of using TensorRT with YOLOv8 on NVIDIA Jetson?
-Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency deep learning inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
+Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
### Can I run Ultralytics YOLOv8 with DeepStream SDK across different NVIDIA Jetson hardware?
diff --git a/docs/en/guides/defining-project-goals.md b/docs/en/guides/defining-project-goals.md
index fcd32f12f2..c5e3c58cf3 100644
--- a/docs/en/guides/defining-project-goals.md
+++ b/docs/en/guides/defining-project-goals.md
@@ -4,7 +4,7 @@ description: Learn how to define clear goals and objectives for your computer vi
keywords: computer vision, project planning, problem statement, measurable objectives, dataset preparation, model selection, YOLOv8, Ultralytics
---
-# A Practical Guide for Defining Your Computer Vision Project
+# A Practical Guide for Defining Your [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) Project
## Introduction
@@ -33,7 +33,7 @@ Consider a computer vision project where you want to [estimate the speed of vehi
-Primary users include traffic management authorities and law enforcement, while secondary stakeholders are highway planners and the public benefiting from safer roads. Key requirements involve evaluating budget, time, and personnel, as well as addressing technical needs like high-resolution cameras and real-time data processing. Additionally, regulatory constraints on privacy and data security must be considered.
+Primary users include traffic management authorities and law enforcement, while secondary stakeholders are highway planners and the public benefiting from safer roads. Key requirements involve evaluating budget, time, and personnel, as well as addressing technical needs like high-resolution cameras and real-time data processing. Additionally, regulatory constraints on privacy and [data security](https://www.ultralytics.com/glossary/data-security) must be considered.
### Setting Measurable Objectives
@@ -41,7 +41,7 @@ Setting measurable objectives is key to the success of a computer vision project
For example, if you are developing a system to estimate vehicle speeds on a highway. You could consider the following measurable objectives:
-- To achieve at least 95% accuracy in speed detection within six months, using a dataset of 10,000 vehicle images.
+- To achieve at least 95% [accuracy](https://www.ultralytics.com/glossary/accuracy) in speed detection within six months, using a dataset of 10,000 vehicle images.
- The system should be able to process real-time video feeds at 30 frames per second with minimal delay.
By setting specific and quantifiable goals, you can effectively track progress, identify areas for improvement, and ensure the project stays on course.
@@ -68,7 +68,7 @@ The order of model selection, dataset preparation, and training approach depends
- **Unique or Limited Data**: If your project is constrained by unique or limited data, begin with dataset preparation. For instance, if you have a rare dataset of medical images, annotate and prepare the data first. Then, select a model that performs well on such data, followed by choosing a suitable training approach.
- - **Example**: Prepare the data first for a facial recognition system with a small dataset. Annotate it, then select a model that works well with limited data, such as a pre-trained model for transfer learning. Finally, decide on a training approach, including data augmentation, to expand the dataset.
+ - **Example**: Prepare the data first for a facial recognition system with a small dataset. Annotate it, then select a model that works well with limited data, such as a pre-trained model for [transfer learning](https://www.ultralytics.com/glossary/transfer-learning). Finally, decide on a training approach, including [data augmentation](https://www.ultralytics.com/glossary/data-augmentation), to expand the dataset.
- **Need for Experimentation**: In projects where experimentation is crucial, start with the training approach. This is common in research projects where you might initially test different training techniques. Refine your model selection after identifying a promising method and prepare the dataset based on your findings.
- **Example**: In a project exploring new methods for detecting manufacturing defects, start with experimenting on a small data subset. Once you find a promising technique, select a model tailored to those findings and prepare a comprehensive dataset.
@@ -79,7 +79,7 @@ Next, let's look at a few common discussion points in the community regarding co
### What Are the Different Computer Vision Tasks?
-The most popular computer vision tasks include image classification, object detection, and image segmentation.
+The most popular computer vision tasks include [image classification](https://www.ultralytics.com/glossary/image-classification), [object detection](https://www.ultralytics.com/glossary/object-detection), and [image segmentation](https://www.ultralytics.com/glossary/image-segmentation).
@@ -103,7 +103,7 @@ If you want to use the classes the model was pre-trained on, a practical approac
- **Edge Devices**: Deploying on edge devices like smartphones or IoT devices requires lightweight models due to their limited computational resources. Example technologies include [TensorFlow Lite](../integrations/tflite.md) and [ONNX Runtime](../integrations/onnx.md), which are optimized for such environments.
- **Cloud Servers**: Cloud deployments can handle more complex models with larger computational demands. Cloud platforms like [AWS](../integrations/amazon-sagemaker.md), Google Cloud, and Azure offer robust hardware options that can scale based on the project's needs.
-- **On-Premise Servers**: For scenarios requiring high data privacy and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
+- **On-Premise Servers**: For scenarios requiring high [data privacy](https://www.ultralytics.com/glossary/data-privacy) and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
- **Hybrid Solutions**: Some projects might benefit from a hybrid approach, where some processing is done on the edge, while more complex analyses are offloaded to the cloud. This can balance performance needs with cost and latency considerations.
Each deployment option offers different benefits and challenges, and the choice depends on specific project requirements like performance, cost, and security.
@@ -158,7 +158,7 @@ For example, "Achieve 95% accuracy in speed detection within six months using a
Deployment options critically impact the performance of your Ultralytics YOLO models. Here are key options:
-- **Edge Devices:** Use lightweight models like TensorFlow Lite or ONNX Runtime for deployment on devices with limited resources.
+- **Edge Devices:** Use lightweight models like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite or ONNX Runtime for deployment on devices with limited resources.
- **Cloud Servers:** Utilize robust cloud platforms like AWS, Google Cloud, or Azure for handling complex models.
- **On-Premise Servers:** High data privacy and security needs may require on-premise deployments.
- **Hybrid Solutions:** Combine edge and cloud approaches for balanced performance and cost-efficiency.
diff --git a/docs/en/guides/distance-calculation.md b/docs/en/guides/distance-calculation.md
index a805b95e6e..443b208b70 100644
--- a/docs/en/guides/distance-calculation.md
+++ b/docs/en/guides/distance-calculation.md
@@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, distance calculation, computer vision, object tra
## What is Distance Calculation?
-Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the bounding box centroid is employed to calculate the distance for bounding boxes highlighted by the user.
+Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the [bounding box](https://www.ultralytics.com/glossary/bounding-box) centroid is employed to calculate the distance for bounding boxes highlighted by the user.
@@ -29,7 +29,7 @@ Measuring the gap between two objects is known as distance calculation within a
## Advantages of Distance Calculation?
-- **Localization Precision:** Enhances accurate spatial positioning in computer vision tasks.
+- **Localization [Precision](https://www.ultralytics.com/glossary/precision):** Enhances accurate spatial positioning in [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks.
- **Size Estimation:** Allows estimation of object size for better contextual understanding.
???+ tip "Distance Calculation"
@@ -112,7 +112,7 @@ Using distance calculation with Ultralytics YOLOv8 offers several advantages:
### Can I perform distance calculation in real-time video streams with Ultralytics YOLOv8?
-Yes, you can perform distance calculation in real-time video streams with Ultralytics YOLOv8. The process involves capturing video frames using OpenCV, running YOLOv8 object detection, and using the `DistanceCalculation` class to calculate distances between objects in successive frames. For a detailed implementation, see the [video stream example](#distance-calculation-using-ultralytics-yolov8).
+Yes, you can perform distance calculation in real-time video streams with Ultralytics YOLOv8. The process involves capturing video frames using [OpenCV](https://www.ultralytics.com/glossary/opencv), running YOLOv8 [object detection](https://www.ultralytics.com/glossary/object-detection), and using the `DistanceCalculation` class to calculate distances between objects in successive frames. For a detailed implementation, see the [video stream example](#distance-calculation-using-ultralytics-yolov8).
### How do I delete points drawn during distance calculation using Ultralytics YOLOv8?
diff --git a/docs/en/guides/docker-quickstart.md b/docs/en/guides/docker-quickstart.md
index 6d08fac0b5..3ee48946c9 100644
--- a/docs/en/guides/docker-quickstart.md
+++ b/docs/en/guides/docker-quickstart.md
@@ -237,7 +237,7 @@ sudo docker pull ultralytics/ultralytics:latest
For detailed steps, refer to our [Docker Quickstart Guide](../quickstart.md).
-### What are the benefits of using Ultralytics Docker images for machine learning projects?
+### What are the benefits of using Ultralytics Docker images for [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) projects?
Using Ultralytics Docker images ensures a consistent environment across different machines, replicating the same software and dependencies. This is particularly useful for collaborating across teams, running models on various hardware, and maintaining reproducibility. For GPU-based training, Ultralytics provides optimized Docker images such as `Dockerfile` for general GPU usage and `Dockerfile-jetson` for NVIDIA Jetson devices. Explore [Ultralytics Docker Hub](https://hub.docker.com/r/ultralytics/ultralytics) for more details.
diff --git a/docs/en/guides/heatmaps.md b/docs/en/guides/heatmaps.md
index 02f99c0d5c..d2ebd4b14b 100644
--- a/docs/en/guides/heatmaps.md
+++ b/docs/en/guides/heatmaps.md
@@ -4,7 +4,7 @@ description: Transform complex data into insightful heatmaps using Ultralytics Y
keywords: Ultralytics, YOLOv8, heatmaps, data visualization, data analysis, complex data, patterns, trends, anomalies
---
-# Advanced Data Visualization: Heatmaps using Ultralytics YOLOv8 🚀
+# Advanced [Data Visualization](https://www.ultralytics.com/glossary/data-visualization): Heatmaps using Ultralytics YOLOv8 🚀
## Introduction to Heatmaps
@@ -359,9 +359,9 @@ cv2.destroyAllWindows()
For further guidance, check the [Tracking Mode](../modes/track.md) page.
-### What makes Ultralytics YOLOv8 heatmaps different from other data visualization tools like those from OpenCV or Matplotlib?
+### What makes Ultralytics YOLOv8 heatmaps different from other data visualization tools like those from [OpenCV](https://www.ultralytics.com/glossary/opencv) or Matplotlib?
-Ultralytics YOLOv8 heatmaps are specifically designed for integration with its object detection and tracking models, providing an end-to-end solution for real-time data analysis. Unlike generic visualization tools like OpenCV or Matplotlib, YOLOv8 heatmaps are optimized for performance and automated processing, supporting features like persistent tracking, decay factor adjustment, and real-time video overlay. For more information on YOLOv8's unique features, visit the [Ultralytics YOLOv8 Introduction](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
+Ultralytics YOLOv8 heatmaps are specifically designed for integration with its [object detection](https://www.ultralytics.com/glossary/object-detection) and tracking models, providing an end-to-end solution for real-time data analysis. Unlike generic visualization tools like OpenCV or Matplotlib, YOLOv8 heatmaps are optimized for performance and automated processing, supporting features like persistent tracking, decay factor adjustment, and real-time video overlay. For more information on YOLOv8's unique features, visit the [Ultralytics YOLOv8 Introduction](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
### How can I visualize only specific object classes in heatmaps using Ultralytics YOLOv8?
@@ -393,4 +393,4 @@ cv2.destroyAllWindows()
### Why should businesses choose Ultralytics YOLOv8 for heatmap generation in data analysis?
-Ultralytics YOLOv8 offers seamless integration of advanced object detection and real-time heatmap generation, making it an ideal choice for businesses looking to visualize data more effectively. The key advantages include intuitive data distribution visualization, efficient pattern detection, and enhanced spatial analysis for better decision-making. Additionally, YOLOv8's cutting-edge features such as persistent tracking, customizable colormaps, and support for various export formats make it superior to other tools like TensorFlow and OpenCV for comprehensive data analysis. Learn more about business applications at [Ultralytics Plans](https://www.ultralytics.com/plans).
+Ultralytics YOLOv8 offers seamless integration of advanced object detection and real-time heatmap generation, making it an ideal choice for businesses looking to visualize data more effectively. The key advantages include intuitive data distribution visualization, efficient pattern detection, and enhanced spatial analysis for better decision-making. Additionally, YOLOv8's cutting-edge features such as persistent tracking, customizable colormaps, and support for various export formats make it superior to other tools like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) and OpenCV for comprehensive data analysis. Learn more about business applications at [Ultralytics Plans](https://www.ultralytics.com/plans).
diff --git a/docs/en/guides/hyperparameter-tuning.md b/docs/en/guides/hyperparameter-tuning.md
index b9b1723d32..d715820f24 100644
--- a/docs/en/guides/hyperparameter-tuning.md
+++ b/docs/en/guides/hyperparameter-tuning.md
@@ -4,19 +4,19 @@ description: Master hyperparameter tuning for Ultralytics YOLO to optimize model
keywords: Ultralytics YOLO, hyperparameter tuning, machine learning, model optimization, genetic algorithms, learning rate, batch size, epochs
---
-# Ultralytics YOLO Hyperparameter Tuning Guide
+# Ultralytics YOLO [Hyperparameter Tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning) Guide
## Introduction
-Hyperparameter tuning is not just a one-time set-up but an iterative process aimed at optimizing the machine learning model's performance metrics, such as accuracy, precision, and recall. In the context of Ultralytics YOLO, these hyperparameters could range from learning rate to architectural details, such as the number of layers or types of activation functions used.
+Hyperparameter tuning is not just a one-time set-up but an iterative process aimed at optimizing the [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) model's performance metrics, such as accuracy, precision, and recall. In the context of Ultralytics YOLO, these hyperparameters could range from learning rate to architectural details, such as the number of layers or types of activation functions used.
### What are Hyperparameters?
Hyperparameters are high-level, structural settings for the algorithm. They are set prior to the training phase and remain constant during it. Here are some commonly tuned hyperparameters in Ultralytics YOLO:
-- **Learning Rate** `lr0`: Determines the step size at each iteration while moving towards a minimum in the loss function.
-- **Batch Size** `batch`: Number of images processed simultaneously in a forward pass.
-- **Number of Epochs** `epochs`: An epoch is one complete forward and backward pass of all the training examples.
+- **Learning Rate** `lr0`: Determines the step size at each iteration while moving towards a minimum in the [loss function](https://www.ultralytics.com/glossary/loss-function).
+- **[Batch Size](https://www.ultralytics.com/glossary/batch-size)** `batch`: Number of images processed simultaneously in a forward pass.
+- **Number of [Epochs](https://www.ultralytics.com/glossary/epoch)** `epochs`: An epoch is one complete forward and backward pass of all the training examples.
- **Architecture Specifics**: Such as channel counts, number of layers, types of activation functions, etc.
@@ -162,7 +162,7 @@ This is a plot displaying fitness (typically a performance metric like AP50) aga
#### tune_results.csv
-A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, precision, recall, as well as the hyperparameters used.
+A CSV file containing detailed results of each iteration during the tuning. Each row in the file represents one iteration, and it includes metrics like fitness score, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), as well as the hyperparameters used.
- **Format**: CSV
- **Usage**: Per-iteration results tracking.
@@ -187,7 +187,7 @@ This file contains scatter plots generated from `tune_results.csv`, helping you
#### weights/
-This directory contains the saved PyTorch models for the last and the best iterations during the hyperparameter tuning process.
+This directory contains the saved [PyTorch](https://www.ultralytics.com/glossary/pytorch) models for the last and the best iterations during the hyperparameter tuning process.
- **`last.pt`**: The last.pt are the weights from the last epoch of training.
- **`best.pt`**: The best.pt weights for the iteration that achieved the best fitness score.
@@ -208,7 +208,7 @@ For deeper insights, you can explore the `Tuner` class source code and accompany
## FAQ
-### How do I optimize the learning rate for Ultralytics YOLO during hyperparameter tuning?
+### How do I optimize the [learning rate](https://www.ultralytics.com/glossary/learning-rate) for Ultralytics YOLO during hyperparameter tuning?
To optimize the learning rate for Ultralytics YOLO, start by setting an initial learning rate using the `lr0` parameter. Common values range from `0.001` to `0.01`. During the hyperparameter tuning process, this value will be mutated to find the optimal setting. You can utilize the `model.tune()` method to automate this process. For example:
@@ -250,7 +250,7 @@ When evaluating model performance during hyperparameter tuning in YOLO, you can
- **AP50**: The average precision at IoU threshold of 0.50.
- **F1-Score**: The harmonic mean of precision and recall.
-- **Precision and Recall**: Individual metrics indicating the model's accuracy in identifying true positives versus false positives and false negatives.
+- **Precision and Recall**: Individual metrics indicating the model's [accuracy](https://www.ultralytics.com/glossary/accuracy) in identifying true positives versus false positives and false negatives.
These metrics help you understand different aspects of your model's performance. Refer to the [Ultralytics YOLO performance metrics](../guides/yolo-performance-metrics.md) guide for a comprehensive overview.
diff --git a/docs/en/guides/index.md b/docs/en/guides/index.md
index e1cb5341c0..1ad70434ab 100644
--- a/docs/en/guides/index.md
+++ b/docs/en/guides/index.md
@@ -6,9 +6,9 @@ keywords: Ultralytics, YOLO, tutorials, guides, object detection, deep learning,
# Comprehensive Tutorials to Ultralytics YOLO
-Welcome to the Ultralytics' YOLO 🚀 Guides! Our comprehensive tutorials cover various aspects of the YOLO object detection model, ranging from training and prediction to deployment. Built on PyTorch, YOLO stands out for its exceptional speed and accuracy in real-time object detection tasks.
+Welcome to the Ultralytics' YOLO 🚀 Guides! Our comprehensive tutorials cover various aspects of the YOLO [object detection](https://www.ultralytics.com/glossary/object-detection) model, ranging from training and prediction to deployment. Built on [PyTorch](https://www.ultralytics.com/glossary/pytorch), YOLO stands out for its exceptional speed and [accuracy](https://www.ultralytics.com/glossary/accuracy) in real-time object detection tasks.
-Whether you're a beginner or an expert in deep learning, our tutorials offer valuable insights into the implementation and optimization of YOLO for your computer vision projects. Let's dive in!
+Whether you're a beginner or an expert in [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl), our tutorials offer valuable insights into the implementation and optimization of YOLO for your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) projects. Let's dive in!
@@ -26,12 +26,12 @@ Whether you're a beginner or an expert in deep learning, our tutorials offer val
Here's a compilation of in-depth guides to help you master different aspects of Ultralytics YOLO.
- [YOLO Common Issues](yolo-common-issues.md) ⭐ RECOMMENDED: Practical solutions and troubleshooting tips to the most frequently encountered issues when working with Ultralytics YOLO models.
-- [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and F1 score used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
-- [Model Deployment Options](model-deployment-options.md): Overview of YOLO model deployment formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
+- [YOLO Performance Metrics](yolo-performance-metrics.md) ⭐ ESSENTIAL: Understand the key metrics like mAP, IoU, and [F1 score](https://www.ultralytics.com/glossary/f1-score) used to evaluate the performance of your YOLO models. Includes practical examples and tips on how to improve detection accuracy and speed.
+- [Model Deployment Options](model-deployment-options.md): Overview of YOLO [model deployment](https://www.ultralytics.com/glossary/model-deployment) formats like ONNX, OpenVINO, and TensorRT, with pros and cons for each to inform your deployment strategy.
- [K-Fold Cross Validation](kfold-cross-validation.md) 🚀 NEW: Learn how to improve model generalization using K-Fold cross-validation technique.
- [Hyperparameter Tuning](hyperparameter-tuning.md) 🚀 NEW: Discover how to optimize your YOLO models by fine-tuning hyperparameters using the Tuner class and genetic evolution algorithms.
- [SAHI Tiled Inference](sahi-tiled-inference.md) 🚀 NEW: Comprehensive guide on leveraging SAHI's sliced inference capabilities with YOLOv8 for object detection in high-resolution images.
-- [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure Machine Learning platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
+- [AzureML Quickstart](azureml-quickstart.md) 🚀 NEW: Get up and running with Ultralytics YOLO models on Microsoft's Azure [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml) platform. Learn how to train, deploy, and scale your object detection projects in the cloud.
- [Conda Quickstart](conda-quickstart.md) 🚀 NEW: Step-by-step guide to setting up a [Conda](https://anaconda.org/conda-forge/ultralytics) environment for Ultralytics. Learn how to install and start using the Ultralytics package efficiently with Conda.
- [Docker Quickstart](docker-quickstart.md) 🚀 NEW: Complete guide to setting up and using Ultralytics YOLO models with [Docker](https://hub.docker.com/r/ultralytics/ultralytics). Learn how to install Docker, manage GPU support, and run YOLO models in isolated containers for consistent development and deployment.
- [Raspberry Pi](raspberry-pi.md) 🚀 NEW: Quickstart tutorial to run YOLO models to the latest Raspberry Pi hardware.
@@ -47,7 +47,7 @@ Here's a compilation of in-depth guides to help you master different aspects of
- [Defining A Computer Vision Project's Goals](defining-project-goals.md) 🚀 NEW: Walk through how to effectively define clear and measurable goals for your computer vision project. Learn the importance of a well-defined problem statement and how it creates a roadmap for your project.
- [Data Collection and Annotation](data-collection-and-annotation.md) 🚀 NEW: Explore the tools, techniques, and best practices for collecting and annotating data to create high-quality inputs for your computer vision models.
- [Preprocessing Annotated Data](preprocessing_annotated_data.md) 🚀 NEW: Learn about preprocessing and augmenting image data in computer vision projects using YOLOv8, including normalization, dataset augmentation, splitting, and exploratory data analysis (EDA).
-- [Tips for Model Training](model-training-tips.md) 🚀 NEW: Explore tips on optimizing batch sizes, using mixed precision, applying pre-trained weights, and more to make training your computer vision model a breeze.
+- [Tips for Model Training](model-training-tips.md) 🚀 NEW: Explore tips on optimizing [batch sizes](https://www.ultralytics.com/glossary/batch-size), using [mixed precision](https://www.ultralytics.com/glossary/mixed-precision), applying pre-trained weights, and more to make training your computer vision model a breeze.
- [Insights on Model Evaluation and Fine-Tuning](model-evaluation-insights.md) 🚀 NEW: Gain insights into the strategies and best practices for evaluating and fine-tuning your computer vision models. Learn about the iterative process of refining models to achieve optimal results.
- [A Guide on Model Testing](model-testing.md) 🚀 NEW: A thorough guide on testing your computer vision models in realistic settings. Learn how to verify accuracy, reliability, and performance in line with project goals.
- [Best Practices for Model Deployment](model-deployment-practices.md) 🚀 NEW: Walk through tips and best practices for efficiently deploying models in computer vision projects, with a focus on optimization, troubleshooting, and security.
@@ -89,7 +89,7 @@ For detailed dataset formatting and additional options, refer to our [Tips for M
### What performance metrics should I use to evaluate my YOLO model?
-Evaluating your YOLO model performance is crucial to understanding its efficacy. Key metrics include Mean Average Precision (mAP), Intersection over Union (IoU), and F1 score. These metrics help assess the accuracy and precision of object detection tasks. You can learn more about these metrics and how to improve your model in our [YOLO Performance Metrics](yolo-performance-metrics.md) guide.
+Evaluating your YOLO model performance is crucial to understanding its efficacy. Key metrics include [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP), [Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU), and F1 score. These metrics help assess the accuracy and [precision](https://www.ultralytics.com/glossary/precision) of object detection tasks. You can learn more about these metrics and how to improve your model in our [YOLO Performance Metrics](yolo-performance-metrics.md) guide.
### Why should I use Ultralytics HUB for my computer vision projects?
@@ -97,7 +97,7 @@ Ultralytics HUB is a no-code platform that simplifies managing, training, and de
### What are the common issues faced during YOLO model training, and how can I resolve them?
-Common issues during YOLO model training include data formatting errors, model architecture mismatches, and insufficient training data. To address these, ensure your dataset is correctly formatted, check for compatible model versions, and augment your training data. For a comprehensive list of solutions, refer to our [YOLO Common Issues](yolo-common-issues.md) guide.
+Common issues during YOLO model training include data formatting errors, model architecture mismatches, and insufficient [training data](https://www.ultralytics.com/glossary/training-data). To address these, ensure your dataset is correctly formatted, check for compatible model versions, and augment your training data. For a comprehensive list of solutions, refer to our [YOLO Common Issues](yolo-common-issues.md) guide.
### How can I deploy my YOLO model for real-time object detection on edge devices?
diff --git a/docs/en/guides/instance-segmentation-and-tracking.md b/docs/en/guides/instance-segmentation-and-tracking.md
index 52a11a3ae0..95e91a8caf 100644
--- a/docs/en/guides/instance-segmentation-and-tracking.md
+++ b/docs/en/guides/instance-segmentation-and-tracking.md
@@ -6,9 +6,9 @@ keywords: instance segmentation, tracking, YOLOv8, Ultralytics, object detection
# Instance Segmentation and Tracking using Ultralytics YOLOv8 🚀
-## What is Instance Segmentation?
+## What is [Instance Segmentation](https://www.ultralytics.com/glossary/instance-segmentation)?
-[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike semantic segmentation, it uniquely labels and precisely delineates each object, crucial for tasks like object detection and medical imaging.
+[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) instance segmentation involves identifying and outlining individual objects in an image, providing a detailed understanding of spatial distribution. Unlike [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation), it uniquely labels and precisely delineates each object, crucial for tasks like [object detection](https://www.ultralytics.com/glossary/object-detection) and medical imaging.
There are two types of instance segmentation tracking available in the Ultralytics package:
@@ -194,7 +194,7 @@ Instance segmentation identifies and outlines individual objects within an image
### Why should I use Ultralytics YOLOv8 for instance segmentation and tracking over other models like Mask R-CNN or Faster R-CNN?
-Ultralytics YOLOv8 offers real-time performance, superior accuracy, and ease of use compared to other models like Mask R-CNN or Faster R-CNN. YOLOv8 provides a seamless integration with Ultralytics HUB, allowing users to manage models, datasets, and training pipelines efficiently. Discover more about the benefits of YOLOv8 in the [Ultralytics blog](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
+Ultralytics YOLOv8 offers real-time performance, superior [accuracy](https://www.ultralytics.com/glossary/accuracy), and ease of use compared to other models like Mask R-CNN or Faster R-CNN. YOLOv8 provides a seamless integration with Ultralytics HUB, allowing users to manage models, datasets, and training pipelines efficiently. Discover more about the benefits of YOLOv8 in the [Ultralytics blog](https://www.ultralytics.com/blog/introducing-ultralytics-yolov8).
### How can I implement object tracking using Ultralytics YOLOv8?
diff --git a/docs/en/guides/isolating-segmentation-objects.md b/docs/en/guides/isolating-segmentation-objects.md
index 0954dc1954..737510e984 100644
--- a/docs/en/guides/isolating-segmentation-objects.md
+++ b/docs/en/guides/isolating-segmentation-objects.md
@@ -96,7 +96,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
1. For more info on `c.masks.xy` see [Masks Section from Predict Mode](../modes/predict.md#masks).
- 2. Here the values are cast into `np.int32` for compatibility with `drawContours()` function from OpenCV.
+ 2. Here the values are cast into `np.int32` for compatibility with `drawContours()` function from [OpenCV](https://www.ultralytics.com/glossary/opencv).
3. The OpenCV `drawContours()` function expects contours to have a shape of `[N, 1, 2]` expand section below for more details.
@@ -178,7 +178,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
iso_crop = isolated[y1:y2, x1:x2]
```
- 1. For more information on bounding box results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
+ 1. For more information on [bounding box](https://www.ultralytics.com/glossary/bounding-box) results, see [Boxes Section from Predict Mode](../modes/predict.md/#boxes)
??? question "What does this code do?"
@@ -253,7 +253,7 @@ After performing the [Segment Task](../tasks/segment.md), it's sometimes desirab
_ = cv2.imwrite(f"{img_name}_{label}-{ci}.png", iso_crop)
```
- - In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the object detection (in case of multiple instances with the same class name).
+ - In this example, the `img_name` is the base-name of the source image file, `label` is the detected class-name, and `ci` is the index of the [object detection](https://www.ultralytics.com/glossary/object-detection) (in case of multiple instances with the same class name).
## Full Example code
diff --git a/docs/en/guides/kfold-cross-validation.md b/docs/en/guides/kfold-cross-validation.md
index a0a345339a..381aef0e2a 100644
--- a/docs/en/guides/kfold-cross-validation.md
+++ b/docs/en/guides/kfold-cross-validation.md
@@ -8,13 +8,13 @@ keywords: Ultralytics, YOLO, K-Fold Cross Validation, object detection, sklearn,
## Introduction
-This comprehensive guide illustrates the implementation of K-Fold Cross Validation for object detection datasets within the Ultralytics ecosystem. We'll leverage the YOLO detection format and key Python libraries such as sklearn, pandas, and PyYaml to guide you through the necessary setup, the process of generating feature vectors, and the execution of a K-Fold dataset split.
+This comprehensive guide illustrates the implementation of K-Fold Cross Validation for [object detection](https://www.ultralytics.com/glossary/object-detection) datasets within the Ultralytics ecosystem. We'll leverage the YOLO detection format and key Python libraries such as sklearn, pandas, and PyYaml to guide you through the necessary setup, the process of generating feature vectors, and the execution of a K-Fold dataset split.
-Whether your project involves the Fruit Detection dataset or a custom data source, this tutorial aims to help you comprehend and apply K-Fold Cross Validation to bolster the reliability and robustness of your machine learning models. While we're applying `k=5` folds for this tutorial, keep in mind that the optimal number of folds can vary depending on your dataset and the specifics of your project.
+Whether your project involves the Fruit Detection dataset or a custom data source, this tutorial aims to help you comprehend and apply K-Fold Cross Validation to bolster the reliability and robustness of your [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models. While we're applying `k=5` folds for this tutorial, keep in mind that the optimal number of folds can vary depending on your dataset and the specifics of your project.
Without further ado, let's dive in!
@@ -285,7 +285,7 @@ Remember that although we used YOLO in this guide, these steps are mostly transf
### What is K-Fold Cross Validation and why is it useful in object detection?
-K-Fold Cross Validation is a technique where the dataset is divided into 'k' subsets (folds) to evaluate model performance more reliably. Each fold serves as both training and validation data. In the context of object detection, using K-Fold Cross Validation helps to ensure your Ultralytics YOLO model's performance is robust and generalizable across different data splits, enhancing its reliability. For detailed instructions on setting up K-Fold Cross Validation with Ultralytics YOLO, refer to [K-Fold Cross Validation with Ultralytics](#introduction).
+K-Fold Cross Validation is a technique where the dataset is divided into 'k' subsets (folds) to evaluate model performance more reliably. Each fold serves as both training and [validation data](https://www.ultralytics.com/glossary/validation-data). In the context of object detection, using K-Fold Cross Validation helps to ensure your Ultralytics YOLO model's performance is robust and generalizable across different data splits, enhancing its reliability. For detailed instructions on setting up K-Fold Cross Validation with Ultralytics YOLO, refer to [K-Fold Cross Validation with Ultralytics](#introduction).
### How do I implement K-Fold Cross Validation using Ultralytics YOLO?
@@ -301,11 +301,11 @@ For a comprehensive guide, see the [K-Fold Dataset Split](#k-fold-dataset-split)
### Why should I use Ultralytics YOLO for object detection?
-Ultralytics YOLO offers state-of-the-art, real-time object detection with high accuracy and efficiency. It's versatile, supporting multiple computer vision tasks such as detection, segmentation, and classification. Additionally, it integrates seamlessly with tools like Ultralytics HUB for no-code model training and deployment. For more details, explore the benefits and features on our [Ultralytics YOLO page](https://www.ultralytics.com/yolo).
+Ultralytics YOLO offers state-of-the-art, real-time object detection with high [accuracy](https://www.ultralytics.com/glossary/accuracy) and efficiency. It's versatile, supporting multiple [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks such as detection, segmentation, and classification. Additionally, it integrates seamlessly with tools like Ultralytics HUB for no-code model training and deployment. For more details, explore the benefits and features on our [Ultralytics YOLO page](https://www.ultralytics.com/yolo).
### How can I ensure my annotations are in the correct format for Ultralytics YOLO?
-Your annotations should follow the YOLO detection format. Each annotation file must list the object class, alongside its bounding box coordinates in the image. The YOLO format ensures streamlined and standardized data processing for training object detection models. For more information on proper annotation formatting, visit the [YOLO detection format guide](../datasets/detect/index.md).
+Your annotations should follow the YOLO detection format. Each annotation file must list the object class, alongside its [bounding box](https://www.ultralytics.com/glossary/bounding-box) coordinates in the image. The YOLO format ensures streamlined and standardized data processing for training object detection models. For more information on proper annotation formatting, visit the [YOLO detection format guide](../datasets/detect/index.md).
### Can I use K-Fold Cross Validation with custom datasets other than Fruit Detection?
diff --git a/docs/en/guides/model-deployment-options.md b/docs/en/guides/model-deployment-options.md
index 635716e581..c2ecf8b649 100644
--- a/docs/en/guides/model-deployment-options.md
+++ b/docs/en/guides/model-deployment-options.md
@@ -24,7 +24,7 @@ Let's walk through the different YOLOv8 deployment options. For a detailed walkt
#### PyTorch
-PyTorch is an open-source machine learning library widely used for applications in deep learning and artificial intelligence. It provides a high level of flexibility and speed, which has made it a favorite among researchers and developers.
+PyTorch is an open-source machine learning library widely used for applications in [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) and [artificial intelligence](https://www.ultralytics.com/glossary/artificial-intelligence-ai). It provides a high level of flexibility and speed, which has made it a favorite among researchers and developers.
- **Performance Benchmarks**: PyTorch is known for its ease of use and flexibility, which may result in a slight trade-off in raw performance when compared to other frameworks that are more specialized and optimized.
@@ -60,7 +60,7 @@ TorchScript extends PyTorch's capabilities by allowing the exportation of models
#### ONNX
-The Open Neural Network Exchange (ONNX) is a format that allows for model interoperability across different frameworks, which can be critical when deploying to various platforms.
+The Open [Neural Network](https://www.ultralytics.com/glossary/neural-network-nn) Exchange (ONNX) is a format that allows for model interoperability across different frameworks, which can be critical when deploying to various platforms.
- **Performance Benchmarks**: ONNX models may experience a variable performance depending on the specific runtime they are deployed on.
@@ -84,9 +84,9 @@ OpenVINO is an Intel toolkit designed to facilitate the deployment of deep learn
- **Compatibility and Integration**: Works best within the Intel ecosystem but also supports a range of other platforms.
-- **Community Support and Ecosystem**: Backed by Intel, with a solid user base especially in the computer vision domain.
+- **Community Support and Ecosystem**: Backed by Intel, with a solid user base especially in the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) domain.
-- **Case Studies**: Often utilized in IoT and edge computing scenarios where Intel hardware is prevalent.
+- **Case Studies**: Often utilized in IoT and [edge computing](https://www.ultralytics.com/glossary/edge-computing) scenarios where Intel hardware is prevalent.
- **Maintenance and Updates**: Intel regularly updates OpenVINO to support the latest deep learning models and Intel hardware.
@@ -128,7 +128,7 @@ CoreML is Apple's machine learning framework, optimized for on-device performanc
- **Maintenance and Updates**: Regularly updated by Apple to support the latest machine learning advancements and Apple hardware.
-- **Security Considerations**: Benefits from Apple's focus on user privacy and data security.
+- **Security Considerations**: Benefits from Apple's focus on user privacy and [data security](https://www.ultralytics.com/glossary/data-security).
- **Hardware Acceleration**: Takes full advantage of Apple's neural engine and GPU for accelerated machine learning tasks.
@@ -236,7 +236,7 @@ PaddlePaddle is an open-source deep learning framework developed by Baidu. It is
- **Maintenance and Updates**: Regularly updated with a focus on serving Chinese language AI applications and services.
-- **Security Considerations**: Emphasizes data privacy and security, catering to Chinese data governance standards.
+- **Security Considerations**: Emphasizes [data privacy](https://www.ultralytics.com/glossary/data-privacy) and security, catering to Chinese data governance standards.
- **Hardware Acceleration**: Supports various hardware accelerations, including Baidu's own Kunlun chips.
@@ -329,7 +329,7 @@ For more insights, check out our [blog post](https://www.ultralytics.com/blog/ac
### Can I deploy YOLOv8 models on mobile devices?
-Yes, YOLOv8 models can be deployed on mobile devices using TensorFlow Lite (TF Lite) for both Android and iOS platforms. TF Lite is designed for mobile and embedded devices, providing efficient on-device inference.
+Yes, YOLOv8 models can be deployed on mobile devices using [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite (TF Lite) for both Android and iOS platforms. TF Lite is designed for mobile and embedded devices, providing efficient on-device inference.
!!! example
@@ -356,13 +356,13 @@ When choosing a deployment format for YOLOv8, consider the following factors:
- **Performance**: Some formats like TensorRT provide exceptional speeds on NVIDIA GPUs, while OpenVINO is optimized for Intel hardware.
- **Compatibility**: ONNX offers broad compatibility across different platforms.
- **Ease of Integration**: Formats like CoreML or TF Lite are tailored for specific ecosystems like iOS and Android, respectively.
-- **Community Support**: Formats like PyTorch and TensorFlow have extensive community resources and support.
+- **Community Support**: Formats like [PyTorch](https://www.ultralytics.com/glossary/pytorch) and TensorFlow have extensive community resources and support.
For a comparative analysis, refer to our [export formats documentation](../modes/export.md#export-formats).
### How can I deploy YOLOv8 models in a web application?
-To deploy YOLOv8 models in a web application, you can use TensorFlow.js (TF.js), which allows for running machine learning models directly in the browser. This approach eliminates the need for backend infrastructure and provides real-time performance.
+To deploy YOLOv8 models in a web application, you can use TensorFlow.js (TF.js), which allows for running [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models directly in the browser. This approach eliminates the need for backend infrastructure and provides real-time performance.
1. Export the YOLOv8 model to the TF.js format.
2. Integrate the exported model into your web application.
diff --git a/docs/en/guides/model-deployment-practices.md b/docs/en/guides/model-deployment-practices.md
index df485abd45..f259779ceb 100644
--- a/docs/en/guides/model-deployment-practices.md
+++ b/docs/en/guides/model-deployment-practices.md
@@ -4,7 +4,7 @@ description: Learn essential tips, insights, and best practices for deploying co
keywords: Model Deployment, Machine Learning Model Deployment, ML Model Deployment, AI Model Deployment, How to Deploy a Machine Learning Model, How to Deploy ML Models
---
-# Best Practices for Model Deployment
+# Best Practices for [Model Deployment](https://www.ultralytics.com/glossary/model-deployment)
## Introduction
@@ -31,13 +31,13 @@ With respect to YOLOv8, you can [export your model](../modes/export.md) to diffe
### Choosing a Deployment Environment
-Choosing where to deploy your computer vision model depends on multiple factors. Different environments have unique benefits and challenges, so it's essential to pick the one that best fits your needs.
+Choosing where to deploy your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) model depends on multiple factors. Different environments have unique benefits and challenges, so it's essential to pick the one that best fits your needs.
#### Cloud Deployment
Cloud deployment is great for applications that need to scale up quickly and handle large amounts of data. Platforms like AWS, [Google Cloud](../yolov5/environments/google_cloud_quickstart_tutorial.md), and Azure make it easy to manage your models from training to deployment. They offer services like [AWS SageMaker](../integrations/amazon-sagemaker.md), Google AI Platform, and [Azure Machine Learning](./azureml-quickstart.md) to help you throughout the process.
-However, using the cloud can be expensive, especially with high data usage, and you might face latency issues if your users are far from the data centers. To manage costs and performance, it's important to optimize resource use and ensure compliance with data privacy rules.
+However, using the cloud can be expensive, especially with high data usage, and you might face latency issues if your users are far from the data centers. To manage costs and performance, it's important to optimize resource use and ensure compliance with [data privacy](https://www.ultralytics.com/glossary/data-privacy) rules.
#### Edge Deployment
@@ -65,7 +65,7 @@ Pruning reduces the size of the model by removing weights that contribute little
### Model Quantization
-Quantization converts the model's weights and activations from high precision (like 32-bit floats) to lower precision (like 8-bit integers). By reducing the model size, it speeds up inference. Quantization-aware training (QAT) is a method where the model is trained with quantization in mind, preserving accuracy better than post-training quantization. By handling quantization during the training phase, the model learns to adjust to lower precision, maintaining performance while reducing computational demands.
+Quantization converts the model's weights and activations from high [precision](https://www.ultralytics.com/glossary/precision) (like 32-bit floats) to lower precision (like 8-bit integers). By reducing the model size, it speeds up inference. Quantization-aware training (QAT) is a method where the model is trained with quantization in mind, preserving accuracy better than post-training quantization. By handling quantization during the training phase, the model learns to adjust to lower precision, maintaining performance while reducing computational demands.
@@ -73,7 +73,7 @@ Quantization converts the model's weights and activations from high precision (l
### Knowledge Distillation
-Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's accuracy. This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
+Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's [accuracy](https://www.ultralytics.com/glossary/accuracy). This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
@@ -98,7 +98,7 @@ When deploying YOLOv8, several factors can affect model accuracy. Converting mod
### Inferences Are Taking Longer Than You Expected
-When deploying machine learning models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
+When deploying [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
- **Implement Warm-Up Runs**: Initial runs often include setup overhead, which can skew latency measurements. Perform a few warm-up inferences before measuring latency. Excluding these initial runs provides a more accurate measurement of the model's performance.
- **Optimize the Inference Engine:** Double-check that the inference engine is fully optimized for your specific GPU architecture. Use the latest drivers and software versions tailored to your hardware to ensure maximum performance and compatibility.
@@ -124,7 +124,7 @@ It's essential to control who can access your model and its data to prevent unau
### Model Obfuscation
-Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in neural networks, to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
+Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in [neural networks](https://www.ultralytics.com/glossary/neural-network-nn), to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
## Share Ideas With Your Peers
diff --git a/docs/en/guides/model-evaluation-insights.md b/docs/en/guides/model-evaluation-insights.md
index 22c44e5df0..ef9389c266 100644
--- a/docs/en/guides/model-evaluation-insights.md
+++ b/docs/en/guides/model-evaluation-insights.md
@@ -24,19 +24,19 @@ _Quick Tip:_ When running inferences, if you aren't seeing any predictions and y
### Intersection over Union
-Intersection over Union (IoU) is a metric in object detection that measures how well the predicted bounding box overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
+[Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) is a metric in [object detection](https://www.ultralytics.com/glossary/object-detection) that measures how well the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
-### Mean Average Precision
+### Mean Average [Precision](https://www.ultralytics.com/glossary/precision)
-Mean Average Precision (mAP) is a way to measure how well an object detection model performs. It looks at the precision of detecting each object class, averages these scores, and gives an overall number that shows how accurately the model can identify and classify objects.
+[Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) is a way to measure how well an object detection model performs. It looks at the precision of detecting each object class, averages these scores, and gives an overall number that shows how accurately the model can identify and classify objects.
Let's focus on two specific mAP metrics:
-- *mAP@.5:* Measures the average precision at a single IoU (Intersection over Union) threshold of 0.5. This metric checks if the model can correctly find objects with a looser accuracy requirement. It focuses on whether the object is roughly in the right place, not needing perfect placement. It helps see if the model is generally good at spotting objects.
+- *mAP@.5:* Measures the average precision at a single IoU (Intersection over Union) threshold of 0.5. This metric checks if the model can correctly find objects with a looser [accuracy](https://www.ultralytics.com/glossary/accuracy) requirement. It focuses on whether the object is roughly in the right place, not needing perfect placement. It helps see if the model is generally good at spotting objects.
- *mAP@.5:.95:* Averages the mAP values calculated at multiple IoU thresholds, from 0.5 to 0.95 in 0.05 increments. This metric is more detailed and strict. It gives a fuller picture of how accurately the model can find objects at different levels of strictness and is especially useful for applications that need precise object detection.
Other mAP metrics include mAP@0.75, which uses a stricter IoU threshold of 0.75, and mAP@small, medium, and large, which evaluate precision across objects of different sizes.
@@ -111,9 +111,9 @@ Fine-tuning involves taking a pre-trained model and adjusting its parameters to
Fine-tuning a model means paying close attention to several vital parameters and techniques to achieve optimal performance. Here are some essential tips to guide you through the process.
-### Starting With a Higher Learning Rate
+### Starting With a Higher [Learning Rate](https://www.ultralytics.com/glossary/learning-rate)
-Usually, during the initial training epochs, the learning rate starts low and gradually increases to stabilize the training process. However, since your model has already learned some features from the previous dataset, starting with a higher learning rate right away can be more beneficial.
+Usually, during the initial training [epochs](https://www.ultralytics.com/glossary/epoch), the learning rate starts low and gradually increases to stabilize the training process. However, since your model has already learned some features from the previous dataset, starting with a higher learning rate right away can be more beneficial.
When evaluating your YOLOv8 model, you can set the `warmup_epochs` validation parameter to `warmup_epochs=0` to prevent the learning rate from starting too high. By following this process, the training will continue from the provided weights, adjusting to the nuances of your new data.
@@ -123,7 +123,7 @@ Image tiling can improve detection accuracy for small objects. By dividing large
## Engage with the Community
-Sharing your ideas and questions with other computer vision enthusiasts can inspire creative solutions to roadblocks in your projects. Here are some excellent ways to learn, troubleshoot, and connect.
+Sharing your ideas and questions with other [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) enthusiasts can inspire creative solutions to roadblocks in your projects. Here are some excellent ways to learn, troubleshoot, and connect.
### Finding Help and Support
@@ -136,7 +136,7 @@ Sharing your ideas and questions with other computer vision enthusiasts can insp
## Final Thoughts
-Evaluating and fine-tuning your computer vision model are important steps for successful model deployment. These steps help make sure that your model is accurate, efficient, and suited to your overall application. The key to training the best model possible is continuous experimentation and learning. Don't hesitate to tweak parameters, try new techniques, and explore different datasets. Keep experimenting and pushing the boundaries of what's possible!
+Evaluating and fine-tuning your computer vision model are important steps for successful [model deployment](https://www.ultralytics.com/glossary/model-deployment). These steps help make sure that your model is accurate, efficient, and suited to your overall application. The key to training the best model possible is continuous experimentation and learning. Don't hesitate to tweak parameters, try new techniques, and explore different datasets. Keep experimenting and pushing the boundaries of what's possible!
## FAQ
@@ -156,8 +156,8 @@ To handle variable image sizes during evaluation, use the `rect=true` parameter
Improving mean average precision (mAP) for a YOLOv8 model involves several steps:
-1. **Tuning Hyperparameters**: Experiment with different learning rates, batch sizes, and image augmentations.
-2. **Data Augmentation**: Use techniques like Mosaic and MixUp to create diverse training samples.
+1. **Tuning Hyperparameters**: Experiment with different learning rates, [batch sizes](https://www.ultralytics.com/glossary/batch-size), and image augmentations.
+2. **[Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation)**: Use techniques like Mosaic and MixUp to create diverse training samples.
3. **Image Tiling**: Split larger images into smaller tiles to improve detection accuracy for small objects.
Refer to our detailed guide on [model fine-tuning](#tips-for-fine-tuning-your-model) for specific strategies.
diff --git a/docs/en/guides/model-monitoring-and-maintenance.md b/docs/en/guides/model-monitoring-and-maintenance.md
index ab5e417a3b..2aedc8e3a3 100644
--- a/docs/en/guides/model-monitoring-and-maintenance.md
+++ b/docs/en/guides/model-monitoring-and-maintenance.md
@@ -34,8 +34,8 @@ Here are some best practices to keep in mind while monitoring your computer visi
You can use automated monitoring tools to make it easier to monitor models after deployment. Many tools offer real-time insights and alerting capabilities. Here are some examples of open-source model monitoring tools that can work together:
- **[Prometheus](https://prometheus.io/)**: Prometheus is an open-source monitoring tool that collects and stores metrics for detailed performance tracking. It integrates easily with Kubernetes and Docker, collecting data at set intervals and storing it in a time-series database. Prometheus can also scrape HTTP endpoints to gather real-time metrics. Collected data can be queried using the PromQL language.
-- **[Grafana](https://grafana.com/)**: Grafana is an open-source data visualization and monitoring tool that allows you to query, visualize, alert on, and understand your metrics no matter where they are stored. It works well with Prometheus and offers advanced data visualization features. You can create custom dashboards to show important metrics for your computer vision models, like inference latency, error rates, and resource usage. Grafana turns collected data into easy-to-read dashboards with line graphs, heat maps, and histograms. It also supports alerts, which can be sent through channels like Slack to quickly notify teams of any issues.
-- **[Evidently AI](https://www.evidentlyai.com/)**: Evidently AI is an open-source tool designed for monitoring and debugging machine learning models in production. It generates interactive reports from pandas DataFrames, helping analyze machine learning models. Evidently AI can detect data drift, model performance degradation, and other issues that may arise with your deployed models.
+- **[Grafana](https://grafana.com/)**: Grafana is an open-source [data visualization](https://www.ultralytics.com/glossary/data-visualization) and monitoring tool that allows you to query, visualize, alert on, and understand your metrics no matter where they are stored. It works well with Prometheus and offers advanced data visualization features. You can create custom dashboards to show important metrics for your computer vision models, like inference latency, error rates, and resource usage. Grafana turns collected data into easy-to-read dashboards with line graphs, heat maps, and histograms. It also supports alerts, which can be sent through channels like Slack to quickly notify teams of any issues.
+- **[Evidently AI](https://www.evidentlyai.com/)**: Evidently AI is an open-source tool designed for monitoring and debugging [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models in production. It generates interactive reports from pandas DataFrames, helping analyze machine learning models. Evidently AI can detect data drift, model performance degradation, and other issues that may arise with your deployed models.
The three tools introduced above, Evidently AI, Prometheus, and Grafana, can work together seamlessly as a fully open-source ML monitoring solution that is ready for production. Evidently AI is used to collect and calculate metrics, Prometheus stores these metrics, and Grafana displays them and sets up alerts. While there are many other tools available, this setup is an exciting open-source option that provides robust capabilities for monitoring and maintaining your models.
@@ -45,7 +45,7 @@ The three tools introduced above, Evidently AI, Prometheus, and Grafana, can wor
### Anomaly Detection and Alert Systems
-An anomaly is any data point or pattern that deviates quite a bit from what is expected. With respect to computer vision models, anomalies can be images that are very different from the ones the model was trained on. These unexpected images can be signs of issues like changes in data distribution, outliers, or behaviors that might reduce model performance. Setting up alert systems to detect these anomalies is an important part of model monitoring.
+An anomaly is any data point or pattern that deviates quite a bit from what is expected. With respect to [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models, anomalies can be images that are very different from the ones the model was trained on. These unexpected images can be signs of issues like changes in data distribution, outliers, or behaviors that might reduce model performance. Setting up alert systems to detect these anomalies is an important part of model monitoring.
By setting standard performance levels and limits for key metrics, you can catch problems early. When performance goes outside these limits, alerts are triggered, prompting quick fixes. Regularly updating and retraining models with new data keeps them relevant and accurate as the data changes.
@@ -69,7 +69,7 @@ Here are several methods to detect data drift:
**Continuous Monitoring**: Regularly monitor the model's input data and outputs for signs of drift. Track key metrics and compare them against historical data to identify significant changes.
-**Statistical Techniques**: Use methods like the Kolmogorov-Smirnov test or Population Stability Index (PSI) to detect changes in data distributions. These tests compare the distribution of new data with the training data to identify significant differences.
+**Statistical Techniques**: Use methods like the Kolmogorov-Smirnov test or Population Stability Index (PSI) to detect changes in data distributions. These tests compare the distribution of new data with the [training data](https://www.ultralytics.com/glossary/training-data) to identify significant differences.
**Feature Drift**: Monitor individual features for drift. Sometimes, the overall data distribution may remain stable, but individual features may drift. Identifying which features are drifting helps in fine-tuning the retraining process.
@@ -91,7 +91,7 @@ Regardless of the method, validation and testing are a must after updates. It is
### Deciding When to Retrain Your Model
-The frequency of retraining your computer vision model depends on data changes and model performance. Retrain your model whenever you observe a significant performance drop or detect data drift. Regular evaluations can help determine the right retraining schedule by testing the model against new data. Monitoring performance metrics and data patterns lets you decide if your model needs more frequent updates to maintain accuracy.
+The frequency of retraining your computer vision model depends on data changes and model performance. Retrain your model whenever you observe a significant performance drop or detect data drift. Regular evaluations can help determine the right retraining schedule by testing the model against new data. Monitoring performance metrics and data patterns lets you decide if your model needs more frequent updates to maintain [accuracy](https://www.ultralytics.com/glossary/accuracy).
@@ -108,8 +108,8 @@ These are some of the key elements that should be included in project documentat
- **[Project Overview](./steps-of-a-cv-project.md)**: Provide a high-level summary of the project, including the problem statement, solution approach, expected outcomes, and project scope. Explain the role of computer vision in addressing the problem and outline the stages and deliverables.
- **Model Architecture**: Detail the structure and design of the model, including its components, layers, and connections. Explain the chosen hyperparameters and the rationale behind these choices.
- **[Data Preparation](./data-collection-and-annotation.md)**: Describe the data sources, types, formats, sizes, and preprocessing steps. Discuss data quality, reliability, and any transformations applied before training the model.
-- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and loss functions. Explain how the model was trained and any challenges encountered during training.
-- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, precision, recall, and F1-score. Include performance results and an analysis of these metrics.
+- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and [loss functions](https://www.ultralytics.com/glossary/loss-function). Explain how the model was trained and any challenges encountered during training.
+- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1-score. Include performance results and an analysis of these metrics.
- **[Deployment Steps](./model-deployment-options.md)**: Outline the steps taken to deploy the model, including the tools and platforms used, deployment configurations, and any specific challenges or considerations.
- **Monitoring and Maintenance Procedure**: Provide a detailed plan for monitoring the model's performance post-deployment. Include methods for detecting and addressing data and model drift, and describe the process for regular updates and retraining.
@@ -155,7 +155,7 @@ Maintaining computer vision models involves regular updates, retraining, and mon
Data drift detection is essential because it helps identify when the statistical properties of the input data change over time, which can degrade model performance. Techniques like continuous monitoring, statistical tests (e.g., Kolmogorov-Smirnov test), and feature drift analysis can help spot issues early. Addressing data drift ensures that your model remains accurate and relevant in changing environments. Learn more about data drift detection in our [Data Drift Detection](#data-drift-detection) section.
-### What tools can I use for anomaly detection in computer vision models?
+### What tools can I use for [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) in computer vision models?
For anomaly detection in computer vision models, tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) are highly effective. These tools can help you set up alert systems to detect unusual data points or patterns that deviate from expected behavior. Configurable alerts and standardized messages can help you respond quickly to potential issues. Explore more in our [Anomaly Detection and Alert Systems](#anomaly-detection-and-alert-systems) section.
@@ -168,5 +168,5 @@ Effective documentation of a computer vision project should include:
- **Data Preparation**: Information on data sources, preprocessing steps, and transformations.
- **Training Process**: Description of the training procedure, datasets used, and challenges encountered.
- **Evaluation Metrics**: Metrics used for performance evaluation and analysis.
-- **Deployment Steps**: Steps taken for model deployment and any specific challenges.
+- **Deployment Steps**: Steps taken for [model deployment](https://www.ultralytics.com/glossary/model-deployment) and any specific challenges.
- **Monitoring and Maintenance Procedure**: Plan for ongoing monitoring and maintenance. For more comprehensive guidelines, refer to our [Documentation](#documentation) section.
diff --git a/docs/en/guides/model-testing.md b/docs/en/guides/model-testing.md
index 71ff69b0be..8d32467955 100644
--- a/docs/en/guides/model-testing.md
+++ b/docs/en/guides/model-testing.md
@@ -10,19 +10,19 @@ keywords: Overfitting and Underfitting in Machine Learning, Model Testing, Data
After [training](./model-training-tips.md) and [evaluating](./model-evaluation-insights.md) your model, it's time to test it. Model testing involves assessing how well it performs in real-world scenarios. Testing considers factors like accuracy, reliability, fairness, and how easy it is to understand the model's decisions. The goal is to make sure the model performs as intended, delivers the expected results, and fits into the [overall objective of your application](./defining-project-goals.md) or project.
-Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your computer vision models.
+Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models.
## Model Testing Vs. Model Evaluation
First, let's understand the difference between model evaluation and testing with an example.
-Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, precision, recall, and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
+Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
After evaluation, you test the model using images from a pet store to see how well it identifies cats and dogs in more varied and realistic conditions. You check if it can correctly label cats and dogs when they are moving, in different lighting conditions, or partially obscured by objects like toys or furniture. Model testing checks that the model behaves as expected outside the controlled evaluation environment.
## Preparing for Model Testing
-Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. Training data teaches the model while testing data verifies its accuracy.
+Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. [Training data](https://www.ultralytics.com/glossary/training-data) teaches the model while testing data verifies its accuracy.
Here are two points to keep in mind before testing your model:
@@ -61,7 +61,7 @@ If you want to test your trained YOLOv8 model on multiple images stored in a fol
If you are interested in testing the basic YOLOv8 model to understand whether it can be used for your application without custom training, you can use the prediction mode. While the model is pre-trained on datasets like COCO, running predictions on your own dataset can give you a quick sense of how well it might perform in your specific context.
-## Overfitting and Underfitting in Machine Learning
+## Overfitting and [Underfitting](https://www.ultralytics.com/glossary/underfitting) in [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml)
When testing a machine learning model, especially in computer vision, it's important to watch out for overfitting and underfitting. These issues can significantly affect how well your model works with new data.
@@ -71,7 +71,7 @@ Overfitting happens when your model learns the training data too well, including
#### Signs of Overfitting
-- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or test data, it's likely overfitting.
+- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or [test data](https://www.ultralytics.com/glossary/test-data), it's likely overfitting.
- **Visual Inspection:** Sometimes, you can see overfitting if your model is too sensitive to minor changes or irrelevant details in images.
### Underfitting
@@ -102,7 +102,7 @@ Data leakage can be tricky to spot and often comes from hidden biases in the tra
- **Camera Bias:** Different angles, lighting, shadows, and camera movements can introduce unwanted patterns.
- **Overlay Bias:** Logos, timestamps, or other overlays in images can mislead the model.
- **Font and Object Bias:** Specific fonts or objects that frequently appear in certain classes can skew the model's learning.
-- **Spatial Bias:** Imbalances in foreground-background, bounding box distributions, and object locations can affect training.
+- **Spatial Bias:** Imbalances in foreground-background, [bounding box](https://www.ultralytics.com/glossary/bounding-box) distributions, and object locations can affect training.
- **Label and Domain Bias:** Incorrect labels or shifts in data types can lead to leakage.
### Detecting Data Leakage
@@ -139,13 +139,13 @@ These resources will help you navigate challenges and remain updated on the late
## In Summary
-Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like overfitting and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
+Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like [overfitting](https://www.ultralytics.com/glossary/overfitting) and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
## FAQ
### What are the key differences between model evaluation and model testing in computer vision?
-Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as accuracy, precision, recall, and F1 score, providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
+Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as [accuracy](https://www.ultralytics.com/glossary/accuracy), precision, recall, and [F1 score](https://www.ultralytics.com/glossary/f1-score), providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
### How can I test my Ultralytics YOLOv8 model on multiple images?
@@ -155,7 +155,7 @@ To test your Ultralytics YOLOv8 model on multiple images, you can use the [predi
To address **overfitting**:
-- Regularization techniques like dropout.
+- [Regularization](https://www.ultralytics.com/glossary/regularization) techniques like dropout.
- Increase the size of the training dataset.
- Simplify the model architecture.
@@ -163,7 +163,7 @@ To address **underfitting**:
- Use a more complex model.
- Provide more relevant features.
-- Increase training iterations or epochs.
+- Increase training iterations or [epochs](https://www.ultralytics.com/glossary/epoch).
Review misclassified images, perform thorough error analysis, and regularly track performance metrics to maintain a balance. For more information on these concepts, explore our section on [Overfitting and Underfitting](#overfitting-and-underfitting-in-machine-learning).
@@ -190,7 +190,7 @@ Post-testing, if the model performance meets the project goals, proceed with dep
- Error analysis.
- Gathering more diverse and high-quality data.
-- Hyperparameter tuning.
+- [Hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning).
- Retraining the model.
Gain insights from the [Model Testing Vs. Model Evaluation](#model-testing-vs-model-evaluation) section to refine and enhance model effectiveness in real-world applications.
diff --git a/docs/en/guides/model-training-tips.md b/docs/en/guides/model-training-tips.md
index 932a412ffb..725081a244 100644
--- a/docs/en/guides/model-training-tips.md
+++ b/docs/en/guides/model-training-tips.md
@@ -18,22 +18,22 @@ One of the most important steps when working on a [computer vision project](./st
allowfullscreen>
- Watch: Model Training Tips | How to Handle Large Datasets | Batch Size, GPU Utilization and Mixed Precision
+ Watch: Model Training Tips | How to Handle Large Datasets | Batch Size, GPU Utilization and [Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision)
So, what is [model training](../modes/train.md)? Model training is the process of teaching your model to recognize visual patterns and make predictions based on your data. It directly impacts the performance and accuracy of your application. In this guide, we'll cover best practices, optimization techniques, and troubleshooting tips to help you train your computer vision models effectively.
-## How to Train a Machine Learning Model
+## How to Train a [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml) Model
A computer vision model is trained by adjusting its internal parameters to minimize errors. Initially, the model is fed a large set of labeled images. It makes predictions about what is in these images, and the predictions are compared to the actual labels or contents to calculate errors. These errors show how far off the model's predictions are from the true values.
-During training, the model iteratively makes predictions, calculates errors, and updates its parameters through a process called backpropagation. In this process, the model adjusts its internal parameters (weights and biases) to reduce the errors. By repeating this cycle many times, the model gradually improves its accuracy. Over time, it learns to recognize complex patterns such as shapes, colors, and textures.
+During training, the model iteratively makes predictions, calculates errors, and updates its parameters through a process called [backpropagation](https://www.ultralytics.com/glossary/backpropagation). In this process, the model adjusts its internal parameters (weights and biases) to reduce the errors. By repeating this cycle many times, the model gradually improves its accuracy. Over time, it learns to recognize complex patterns such as shapes, colors, and textures.
-This learning process makes it possible for the computer vision model to perform various [tasks](../tasks/index.md), including [object detection](../tasks/detect.md), [instance segmentation](../tasks/segment.md), and [image classification](../tasks/classify.md). The ultimate goal is to create a model that can generalize its learning to new, unseen images so that it can accurately understand visual data in real-world applications.
+This learning process makes it possible for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) model to perform various [tasks](../tasks/index.md), including [object detection](../tasks/detect.md), [instance segmentation](../tasks/segment.md), and [image classification](../tasks/classify.md). The ultimate goal is to create a model that can generalize its learning to new, unseen images so that it can accurately understand visual data in real-world applications.
Now that we know what is happening behind the scenes when we train a model, let's look at points to consider when training a model.
@@ -46,7 +46,7 @@ There are a few different aspects to think about when you are planning on using
When training models on large datasets, efficiently utilizing your GPU is key. Batch size is an important factor. It is the number of data samples that a machine learning model processes in a single training iteration.
Using the maximum batch size supported by your GPU, you can fully take advantage of its capabilities and reduce the time model training takes. However, you want to avoid running out of GPU memory. If you encounter memory errors, reduce the batch size incrementally until the model trains smoothly.
-With respect to YOLOv8, you can set the `batch_size` parameter in the [training configuration](../modes/train.md) to match your GPU capacity. Also, setting `batch=-1` in your training script will automatically determine the batch size that can be efficiently processed based on your device's capabilities. By fine-tuning the batch size, you can make the most of your GPU resources and improve the overall training process.
+With respect to YOLOv8, you can set the `batch_size` parameter in the [training configuration](../modes/train.md) to match your GPU capacity. Also, setting `batch=-1` in your training script will automatically determine the [batch size](https://www.ultralytics.com/glossary/batch-size) that can be efficiently processed based on your device's capabilities. By fine-tuning the batch size, you can make the most of your GPU resources and improve the overall training process.
### Subset Training
@@ -72,19 +72,19 @@ Caching can be controlled when training YOLOv8 using the `cache` parameter:
### Mixed Precision Training
-Mixed precision training uses both 16-bit (FP16) and 32-bit (FP32) floating-point types. The strengths of both FP16 and FP32 are leveraged by using FP16 for faster computation and FP32 to maintain precision where needed. Most of the neural network's operations are done in FP16 to benefit from faster computation and lower memory usage. However, a master copy of the model's weights is kept in FP32 to ensure accuracy during the weight update steps. You can handle larger models or larger batch sizes within the same hardware constraints.
+Mixed precision training uses both 16-bit (FP16) and 32-bit (FP32) floating-point types. The strengths of both FP16 and FP32 are leveraged by using FP16 for faster computation and FP32 to maintain precision where needed. Most of the [neural network](https://www.ultralytics.com/glossary/neural-network-nn)'s operations are done in FP16 to benefit from faster computation and lower memory usage. However, a master copy of the model's weights is kept in FP32 to ensure accuracy during the weight update steps. You can handle larger models or larger batch sizes within the same hardware constraints.
-To implement mixed precision training, you'll need to modify your training scripts and ensure your hardware (like GPUs) supports it. Many modern deep learning frameworks, such as Tensorflow, offer built-in support for mixed precision.
+To implement mixed precision training, you'll need to modify your training scripts and ensure your hardware (like GPUs) supports it. Many modern [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) frameworks, such as [Tensorflow](https://www.ultralytics.com/glossary/tensorflow), offer built-in support for mixed precision.
Mixed precision training is straightforward when working with YOLOv8. You can use the `amp` flag in your training configuration. Setting `amp=True` enables Automatic Mixed Precision (AMP) training. Mixed precision training is a simple yet effective way to optimize your model training process.
### Pre-trained Weights
-Using pretrained weights is a smart way to speed up your model's training process. Pretrained weights come from models already trained on large datasets, giving your model a head start. Transfer learning adapts pretrained models to new, related tasks. Fine-tuning a pre-trained model involves starting with these weights and then continuing training on your specific dataset. This method of training results in faster training times and often better performance because the model starts with a solid understanding of basic features.
+Using pretrained weights is a smart way to speed up your model's training process. Pretrained weights come from models already trained on large datasets, giving your model a head start. [Transfer learning](https://www.ultralytics.com/glossary/transfer-learning) adapts pretrained models to new, related tasks. Fine-tuning a pre-trained model involves starting with these weights and then continuing training on your specific dataset. This method of training results in faster training times and often better performance because the model starts with a solid understanding of basic features.
The `pretrained` parameter makes transfer learning easy with YOLOv8. Setting `pretrained=True` will use default pre-trained weights, or you can specify a path to a custom pre-trained model. Using pre-trained weights and transfer learning effectively boosts your model's capabilities and reduces training costs.
@@ -92,14 +92,14 @@ The `pretrained` parameter makes transfer learning easy with YOLOv8. Setting `pr
There are a couple of other techniques to consider when handling a large dataset:
-- **Learning Rate Schedulers**: Implementing learning rate schedulers dynamically adjusts the learning rate during training. A well-tuned learning rate can prevent the model from overshooting minima and improve stability. When training YOLOv8, the `lrf` parameter helps manage learning rate scheduling by setting the final learning rate as a fraction of the initial rate.
+- **[Learning Rate](https://www.ultralytics.com/glossary/learning-rate) Schedulers**: Implementing learning rate schedulers dynamically adjusts the learning rate during training. A well-tuned learning rate can prevent the model from overshooting minima and improve stability. When training YOLOv8, the `lrf` parameter helps manage learning rate scheduling by setting the final learning rate as a fraction of the initial rate.
- **Distributed Training**: For handling large datasets, distributed training can be a game-changer. You can reduce the training time by spreading the training workload across multiple GPUs or machines.
## The Number of Epochs To Train For
When training a model, an epoch refers to one complete pass through the entire training dataset. During an epoch, the model processes each example in the training set once and updates its parameters based on the learning algorithm. Multiple epochs are usually needed to allow the model to learn and refine its parameters over time.
-A common question that comes up is how to determine the number of epochs to train the model for. A good starting point is 300 epochs. If the model overfits early, you can reduce the number of epochs. If overfitting does not occur after 300 epochs, you can extend the training to 600, 1200, or more epochs.
+A common question that comes up is how to determine the number of epochs to train the model for. A good starting point is 300 epochs. If the model overfits early, you can reduce the number of epochs. If [overfitting](https://www.ultralytics.com/glossary/overfitting) does not occur after 300 epochs, you can extend the training to 600, 1200, or more epochs.
However, the ideal number of epochs can vary based on your dataset's size and project goals. Larger datasets might require more epochs for the model to learn effectively, while smaller datasets might need fewer epochs to avoid overfitting. With respect to YOLOv8, you can set the `epochs` parameter in your training script.
@@ -107,7 +107,7 @@ However, the ideal number of epochs can vary based on your dataset's size and pr
Early stopping is a valuable technique for optimizing model training. By monitoring validation performance, you can halt training once the model stops improving. You can save computational resources and prevent overfitting.
-The process involves setting a patience parameter that determines how many epochs to wait for an improvement in validation metrics before stopping training. If the model's performance does not improve within these epochs, training is stopped to avoid wasting time and resources.
+The process involves setting a patience parameter that determines how many [epochs](https://www.ultralytics.com/glossary/epoch) to wait for an improvement in validation metrics before stopping training. If the model's performance does not improve within these epochs, training is stopped to avoid wasting time and resources.
@@ -125,7 +125,7 @@ Local training provides greater control and customization, letting you tailor yo
## Selecting an Optimizer
-An optimizer is an algorithm that adjusts the weights of your neural network to minimize the loss function, which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
+An optimizer is an algorithm that adjusts the weights of your neural network to minimize the [loss function](https://www.ultralytics.com/glossary/loss-function), which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
You can also fine-tune optimizer parameters to improve model performance. Adjusting the learning rate sets the size of the steps when updating parameters. For stability, you might start with a moderate learning rate and gradually decrease it over time to improve long-term learning. Additionally, setting the momentum determines how much influence past updates have on current updates. A common value for momentum is around 0.9. It generally provides a good balance.
@@ -147,7 +147,7 @@ Different optimizers have various strengths and weaknesses. Let's take a glimpse
- **RMSProp (Root Mean Square Propagation)**:
- Adjusts the learning rate for each parameter by dividing the gradient by a running average of the magnitudes of recent gradients.
- - Helps in handling the vanishing gradient problem and is effective for recurrent neural networks.
+ - Helps in handling the vanishing gradient problem and is effective for [recurrent neural networks](https://www.ultralytics.com/glossary/recurrent-neural-network-rnn).
For YOLOv8, the `optimizer` parameter lets you choose from various optimizers, including SGD, Adam, AdamW, NAdam, RAdam, and RMSProp, or you can set it to `auto` for automatic selection based on model configuration.
@@ -168,7 +168,7 @@ Using these resources will help you solve challenges and stay up-to-date with th
## Key Takeaways
-Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed precision training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
+Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed [precision](https://www.ultralytics.com/glossary/precision) training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
## FAQ
@@ -178,7 +178,7 @@ To improve GPU utilization, set the `batch_size` parameter in your training conf
### What is mixed precision training, and how do I enable it in YOLOv8?
-Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model accuracy. To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
+Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model [accuracy](https://www.ultralytics.com/glossary/accuracy). To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
### How does multiscale training enhance YOLOv8 model performance?
diff --git a/docs/en/guides/nvidia-jetson.md b/docs/en/guides/nvidia-jetson.md
index db1b9b79f4..f352c76b8c 100644
--- a/docs/en/guides/nvidia-jetson.md
+++ b/docs/en/guides/nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA Jetson?
-NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and deep learning models directly on the device, without needing to rely on cloud computing resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
+NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models directly on the device, without needing to rely on [cloud computing](https://www.ultralytics.com/glossary/cloud-computing) resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
## NVIDIA Jetson Series Comparison
@@ -46,7 +46,7 @@ For a more detailed comparison table, please visit the **Technical Specification
## What is NVIDIA JetPack?
-[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and computer vision. It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
+[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
## Flash JetPack to NVIDIA Jetson
@@ -110,7 +110,7 @@ For a native installation without Docker, please refer to the steps below.
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
+Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
1. Update packages list, install pip and upgrade to latest
@@ -280,7 +280,7 @@ The YOLOv8n model in PyTorch format is converted to TensorRT to run inference wi
## NVIDIA Jetson Orin YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
### Comparison Chart
diff --git a/docs/en/guides/object-blurring.md b/docs/en/guides/object-blurring.md
index 709ca1bd60..315bcd76ea 100644
--- a/docs/en/guides/object-blurring.md
+++ b/docs/en/guides/object-blurring.md
@@ -92,7 +92,7 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
### How can I implement real-time object blurring using YOLOv8?
-To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for object detection and OpenCV for applying the blur effect. Here's a simplified version:
+To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for [object detection](https://www.ultralytics.com/glossary/object-detection) and OpenCV for applying the blur effect. Here's a simplified version:
```python
import cv2
@@ -132,7 +132,7 @@ For more detailed applications, check the [advantages of object blurring section
### Can I use Ultralytics YOLOv8 to blur faces in a video for privacy reasons?
-Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with OpenCV to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
+Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with [OpenCV](https://www.ultralytics.com/glossary/opencv) to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
### How does YOLOv8 compare to other object detection models like Faster R-CNN for object blurring?
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index 749ffbe8fa..bdec66e42d 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, YOLOv8, Ultralytics, real-time object detection, AI,
## What is Object Counting?
-Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and deep learning capabilities.
+Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) capabilities.
@@ -340,12 +340,12 @@ count_specific_classes("path/to/video.mp4", "output_specific_classes.avi", "yolo
In this example, `classes_to_count=[0, 2]`, which means it counts objects of class `0` and `2` (e.g., person and car).
-### Why should I use YOLOv8 over other object detection models for real-time applications?
+### Why should I use YOLOv8 over other [object detection](https://www.ultralytics.com/glossary/object-detection) models for real-time applications?
Ultralytics YOLOv8 provides several advantages over other object detection models like Faster R-CNN, SSD, and previous YOLO versions:
1. **Speed and Efficiency:** YOLOv8 offers real-time processing capabilities, making it ideal for applications requiring high-speed inference, such as surveillance and autonomous driving.
-2. **Accuracy:** It provides state-of-the-art accuracy for object detection and tracking tasks, reducing the number of false positives and improving overall system reliability.
+2. **[Accuracy](https://www.ultralytics.com/glossary/accuracy):** It provides state-of-the-art accuracy for object detection and tracking tasks, reducing the number of false positives and improving overall system reliability.
3. **Ease of Integration:** YOLOv8 offers seamless integration with various platforms and devices, including mobile and edge devices, which is crucial for modern AI applications.
4. **Flexibility:** Supports various tasks like object detection, segmentation, and tracking with configurable models to meet specific use-case requirements.
diff --git a/docs/en/guides/object-cropping.md b/docs/en/guides/object-cropping.md
index 09adb625d3..f4b50ed027 100644
--- a/docs/en/guides/object-cropping.md
+++ b/docs/en/guides/object-cropping.md
@@ -25,7 +25,7 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
- **Focused Analysis**: YOLOv8 facilitates targeted object cropping, allowing for in-depth examination or processing of individual items within a scene.
- **Reduced Data Volume**: By extracting only relevant objects, object cropping helps in minimizing data size, making it efficient for storage, transmission, or subsequent computational tasks.
-- **Enhanced Precision**: YOLOv8's object detection accuracy ensures that the cropped objects maintain their spatial relationships, preserving the integrity of the visual information for detailed analysis.
+- **Enhanced Precision**: YOLOv8's [object detection](https://www.ultralytics.com/glossary/object-detection) [accuracy](https://www.ultralytics.com/glossary/accuracy) ensures that the cropped objects maintain their spatial relationships, preserving the integrity of the visual information for detailed analysis.
## Visuals
@@ -100,7 +100,7 @@ Object cropping with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
### What is object cropping in Ultralytics YOLOv8 and how does it work?
-Object cropping using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves isolating and extracting specific objects from an image or video based on YOLOv8's detection capabilities. This process allows for focused analysis, reduced data volume, and enhanced precision by leveraging YOLOv8 to identify objects with high accuracy and crop them accordingly. For an in-depth tutorial, refer to the [object cropping example](#object-cropping-using-ultralytics-yolov8).
+Object cropping using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves isolating and extracting specific objects from an image or video based on YOLOv8's detection capabilities. This process allows for focused analysis, reduced data volume, and enhanced [precision](https://www.ultralytics.com/glossary/precision) by leveraging YOLOv8 to identify objects with high accuracy and crop them accordingly. For an in-depth tutorial, refer to the [object cropping example](#object-cropping-using-ultralytics-yolov8).
### Why should I use Ultralytics YOLOv8 for object cropping over other solutions?
diff --git a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
index 63fbb7a904..154ec7a893 100644
--- a/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
+++ b/docs/en/guides/optimizing-openvino-latency-vs-throughput-modes.md
@@ -10,7 +10,7 @@ keywords: Ultralytics YOLO, OpenVINO optimization, deep learning, model inferenc
## Introduction
-When deploying deep learning models, particularly those for object detection such as Ultralytics YOLO models, achieving optimal performance is crucial. This guide delves into leveraging Intel's OpenVINO toolkit to optimize inference, focusing on latency and throughput. Whether you're working on consumer-grade applications or large-scale deployments, understanding and applying these optimization strategies will ensure your models run efficiently on various devices.
+When deploying [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models, particularly those for [object detection](https://www.ultralytics.com/glossary/object-detection) such as Ultralytics YOLO models, achieving optimal performance is crucial. This guide delves into leveraging Intel's OpenVINO toolkit to optimize inference, focusing on latency and throughput. Whether you're working on consumer-grade applications or large-scale deployments, understanding and applying these optimization strategies will ensure your models run efficiently on various devices.
## Optimizing for Latency
@@ -123,6 +123,6 @@ Yes, Ultralytics YOLO models are highly versatile and can be integrated with var
- **TensorRT:** For NVIDIA GPU optimization, follow the [TensorRT integration guide](https://docs.ultralytics.com/integrations/tensorrt/).
- **CoreML:** For Apple devices, refer to our [CoreML export instructions](https://docs.ultralytics.com/integrations/coreml/).
-- **TensorFlow.js:** For web and Node.js apps, see the [TF.js conversion guide](https://docs.ultralytics.com/integrations/tfjs/).
+- **[TensorFlow](https://www.ultralytics.com/glossary/tensorflow).js:** For web and Node.js apps, see the [TF.js conversion guide](https://docs.ultralytics.com/integrations/tfjs/).
Explore more integrations on the [Ultralytics Integrations page](https://docs.ultralytics.com/integrations/).
diff --git a/docs/en/guides/preprocessing_annotated_data.md b/docs/en/guides/preprocessing_annotated_data.md
index 36fcf9f9c1..fcd329c743 100644
--- a/docs/en/guides/preprocessing_annotated_data.md
+++ b/docs/en/guides/preprocessing_annotated_data.md
@@ -4,7 +4,7 @@ description: Learn essential data preprocessing techniques for annotated compute
keywords: data preprocessing, computer vision, image resizing, normalization, data augmentation, training dataset, validation dataset, test dataset, YOLOv8
---
-# Data Preprocessing Techniques for Annotated Computer Vision Data
+# Data Preprocessing Techniques for Annotated [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) Data
## Introduction
@@ -33,7 +33,7 @@ You can resize your images using the following methods:
To make resizing a simpler task, you can use the following tools:
-- **OpenCV**: A popular computer vision library with extensive functions for image processing.
+- **[OpenCV](https://www.ultralytics.com/glossary/opencv)**: A popular computer vision library with extensive functions for image processing.
- **PIL (Pillow)**: A Python Imaging Library for opening, manipulating, and saving image files.
With respect to YOLOv8, the 'imgsz' parameter during [model training](../modes/train.md) allows for flexible input sizes. When set to a specific size, such as 640, the model will resize input images so their largest dimension is 640 pixels while maintaining the original aspect ratio.
@@ -65,7 +65,7 @@ The most commonly discussed data preprocessing step is data augmentation. Data a
Here are some other benefits of data augmentation:
- **Creates a More Robust Dataset**: Data augmentation can make the model more robust to variations and distortions in the input data. This includes changes in lighting, orientation, and scale.
-- **Cost-Effective**: Data augmentation is a cost-effective way to increase the amount of training data without collecting and labeling new data.
+- **Cost-Effective**: Data augmentation is a cost-effective way to increase the amount of [training data](https://www.ultralytics.com/glossary/training-data) without collecting and labeling new data.
- **Better Use of Data**: Every available data point is used to its maximum potential by creating new variations
#### Data Augmentation Methods
@@ -96,7 +96,7 @@ Here's what each step of preprocessing would look like for this project:
- Resizing Images: Since YOLOv8 handles flexible input sizes and performs resizing automatically, manual resizing is not required. The model will adjust the image size according to the specified 'imgsz' parameter during training.
- Normalizing Pixel Values: YOLOv8 automatically normalizes pixel values to a range of 0 to 1 during preprocessing, so it's not required.
- Splitting the Dataset: Divide the dataset into training (70%), validation (20%), and test (10%) sets using tools like scikit-learn.
-- Data Augmentation: Modify the dataset configuration file (.yaml) to include data augmentation techniques such as random crops, horizontal flips, and brightness adjustments.
+- [Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation): Modify the dataset configuration file (.yaml) to include data augmentation techniques such as random crops, horizontal flips, and brightness adjustments.
These steps make sure the dataset is prepared without any potential issues and is ready for Exploratory Data Analysis (EDA).
@@ -120,7 +120,7 @@ Common tools for visualizations include:
### Using Ultralytics Explorer for EDA
-For a more advanced approach to EDA, you can use the Ultralytics Explorer tool. It offers robust capabilities for exploring computer vision datasets. By supporting semantic search, SQL queries, and vector similarity search, the tool makes it easy to analyze and understand your data. With Ultralytics Explorer, you can create embeddings for your dataset to find similar images, run SQL queries for detailed analysis, and perform semantic searches, all through a user-friendly graphical interface.
+For a more advanced approach to EDA, you can use the Ultralytics Explorer tool. It offers robust capabilities for exploring computer vision datasets. By supporting semantic search, SQL queries, and vector similarity search, the tool makes it easy to analyze and understand your data. With Ultralytics Explorer, you can create [embeddings](https://www.ultralytics.com/glossary/embeddings) for your dataset to find similar images, run SQL queries for detailed analysis, and perform semantic searches, all through a user-friendly graphical interface.
@@ -151,7 +151,7 @@ Data preprocessing is essential in computer vision projects because it ensures t
### How can I use Ultralytics YOLO for data augmentation?
-For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce overfitting, and improve model generalization.
+For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce [overfitting](https://www.ultralytics.com/glossary/overfitting), and improve model generalization.
### What are the best data normalization techniques for computer vision data?
@@ -164,7 +164,7 @@ For YOLOv8, normalization is handled automatically, including conversion to RGB
### How should I split my annotated dataset for training?
-To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or TensorFlow for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
+To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
### Can I handle varying image sizes in YOLOv8 without manual resizing?
diff --git a/docs/en/guides/queue-management.md b/docs/en/guides/queue-management.md
index 993d414102..9fb4897edf 100644
--- a/docs/en/guides/queue-management.md
+++ b/docs/en/guides/queue-management.md
@@ -187,7 +187,7 @@ Using Ultralytics YOLOv8 for queue management offers several benefits:
For more details, explore our [Queue Management](https://docs.ultralytics.com/reference/solutions/queue_management/) solutions.
-### Why should I choose Ultralytics YOLOv8 over competitors like TensorFlow or Detectron2 for queue management?
+### Why should I choose Ultralytics YOLOv8 over competitors like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) or Detectron2 for queue management?
Ultralytics YOLOv8 has several advantages over TensorFlow and Detectron2 for queue management:
diff --git a/docs/en/guides/raspberry-pi.md b/docs/en/guides/raspberry-pi.md
index 25d45068a8..c25557e8a3 100644
--- a/docs/en/guides/raspberry-pi.md
+++ b/docs/en/guides/raspberry-pi.md
@@ -49,7 +49,7 @@ The first thing to do after getting your hands on a Raspberry Pi is to flash a m
## Set Up Ultralytics
-There are two ways of setting up Ultralytics package on Raspberry Pi to build your next Computer Vision project. You can use either of them.
+There are two ways of setting up Ultralytics package on Raspberry Pi to build your next [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) project. You can use either of them.
- [Start with Docker](#start-with-docker)
- [Start without Docker](#start-without-docker)
@@ -70,7 +70,7 @@ After this is done, skip to [Use NCNN on Raspberry Pi section](#use-ncnn-on-rasp
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the PyTorch models to other different formats.
+Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats.
1. Update packages list, install pip and upgrade to latest
@@ -136,7 +136,7 @@ The YOLOv8n model in PyTorch format is converted to NCNN to run inference with t
## Raspberry Pi 5 vs Raspberry Pi 4 YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
!!! note
diff --git a/docs/en/guides/region-counting.md b/docs/en/guides/region-counting.md
index f2be9d4574..a27c2b4e53 100644
--- a/docs/en/guides/region-counting.md
+++ b/docs/en/guides/region-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, effici
## What is Object Counting in Regions?
-[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced computer vision. This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
+[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
@@ -23,7 +23,7 @@ keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, effici
## Advantages of Object Counting in Regions?
-- **Precision and Accuracy:** Object counting in regions with advanced computer vision ensures precise and accurate counts, minimizing errors often associated with manual counting.
+- **[Precision](https://www.ultralytics.com/glossary/precision) and Accuracy:** Object counting in regions with advanced computer vision ensures precise and accurate counts, minimizing errors often associated with manual counting.
- **Efficiency Improvement:** Automated object counting enhances operational efficiency, providing real-time results and streamlining processes across different applications.
- **Versatility and Application:** The versatility of object counting in regions makes it applicable across various domains, from manufacturing and surveillance to traffic monitoring, contributing to its widespread utility and effectiveness.
@@ -75,21 +75,21 @@ python yolov8_region_counter.py --source "path/to/video.mp4" --view-img
### Optional Arguments
-| Name | Type | Default | Description |
-| -------------------- | ------ | ------------ | ------------------------------------------ |
-| `--source` | `str` | `None` | Path to video file, for webcam 0 |
-| `--line_thickness` | `int` | `2` | Bounding Box thickness |
-| `--save-img` | `bool` | `False` | Save the predicted video/image |
-| `--weights` | `str` | `yolov8n.pt` | Weights file path |
-| `--classes` | `list` | `None` | Detect specific classes i.e. --classes 0 2 |
-| `--region-thickness` | `int` | `2` | Region Box thickness |
-| `--track-thickness` | `int` | `2` | Tracking line thickness |
+| Name | Type | Default | Description |
+| -------------------- | ------ | ------------ | --------------------------------------------------------------------------- |
+| `--source` | `str` | `None` | Path to video file, for webcam 0 |
+| `--line_thickness` | `int` | `2` | [Bounding Box](https://www.ultralytics.com/glossary/bounding-box) thickness |
+| `--save-img` | `bool` | `False` | Save the predicted video/image |
+| `--weights` | `str` | `yolov8n.pt` | Weights file path |
+| `--classes` | `list` | `None` | Detect specific classes i.e. --classes 0 2 |
+| `--region-thickness` | `int` | `2` | Region Box thickness |
+| `--track-thickness` | `int` | `2` | Tracking line thickness |
## FAQ
### What is object counting in specified regions using Ultralytics YOLOv8?
-Object counting in specified regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves detecting and tallying the number of objects within defined areas using advanced computer vision. This precise method enhances efficiency and accuracy across various applications like manufacturing, surveillance, and traffic monitoring.
+Object counting in specified regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics) involves detecting and tallying the number of objects within defined areas using advanced computer vision. This precise method enhances efficiency and [accuracy](https://www.ultralytics.com/glossary/accuracy) across various applications like manufacturing, surveillance, and traffic monitoring.
### How do I run the object counting script with Ultralytics YOLOv8?
diff --git a/docs/en/guides/ros-quickstart.md b/docs/en/guides/ros-quickstart.md
index 227286de0d..27371131dd 100644
--- a/docs/en/guides/ros-quickstart.md
+++ b/docs/en/guides/ros-quickstart.md
@@ -69,7 +69,7 @@ Apart from the ROS environment, you will need to install the following dependenc
## Use Ultralytics with ROS `sensor_msgs/Image`
-The `sensor_msgs/Image` [message type](https://docs.ros.org/en/api/sensor_msgs/html/msg/Image.html) is commonly used in ROS for representing image data. It contains fields for encoding, height, width, and pixel data, making it suitable for transmitting images captured by cameras or other sensors. Image messages are widely used in robotic applications for tasks such as visual perception, object detection, and navigation.
+The `sensor_msgs/Image` [message type](https://docs.ros.org/en/api/sensor_msgs/html/msg/Image.html) is commonly used in ROS for representing image data. It contains fields for encoding, height, width, and pixel data, making it suitable for transmitting images captured by cameras or other sensors. Image messages are widely used in robotic applications for tasks such as visual perception, [object detection](https://www.ultralytics.com/glossary/object-detection), and navigation.
@@ -360,7 +360,7 @@ A point cloud is a collection of data points defined within a three-dimensional
Point Clouds can be obtained using various sensors:
- 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-precision 3D maps.
+ 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-[precision](https://www.ultralytics.com/glossary/precision) 3D maps.
2. **Depth Cameras**: Capture depth information for each pixel, allowing for 3D reconstruction of the scene.
3. **Stereo Cameras**: Utilize two or more cameras to obtain depth information through triangulation.
4. **Structured Light Scanners**: Project a known pattern onto a surface and measure the deformation to calculate depth.
diff --git a/docs/en/guides/sahi-tiled-inference.md b/docs/en/guides/sahi-tiled-inference.md
index 6b23b21c7f..1137d6b84f 100644
--- a/docs/en/guides/sahi-tiled-inference.md
+++ b/docs/en/guides/sahi-tiled-inference.md
@@ -6,7 +6,7 @@ keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, High-re
# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
-Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
+Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced [object detection](https://www.ultralytics.com/glossary/object-detection) performance.
@@ -31,7 +31,7 @@ SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimi
- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
-- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
+- **High [Accuracy](https://www.ultralytics.com/glossary/accuracy)**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
## What is Sliced Inference?
@@ -202,7 +202,7 @@ If you use SAHI in your research or development work, please cite the original S
}
```
-We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
+We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
## FAQ
diff --git a/docs/en/guides/security-alarm-system.md b/docs/en/guides/security-alarm-system.md
index 4b5cdeebd2..d90e44a583 100644
--- a/docs/en/guides/security-alarm-system.md
+++ b/docs/en/guides/security-alarm-system.md
@@ -8,10 +8,10 @@ keywords: YOLOv8, Security Alarm System, real-time object detection, Ultralytics
-The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
+The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
- **Real-time Detection:** YOLOv8's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
-- **Accuracy:** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
+- **[Accuracy](https://www.ultralytics.com/glossary/accuracy):** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.
@@ -22,7 +22,7 @@ The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanc
allowfullscreen>
- Watch: Security Alarm System Project with Ultralytics YOLOv8 Object Detection
+ Watch: Security Alarm System Project with Ultralytics YOLOv8 [Object Detection](https://www.ultralytics.com/glossary/object-detection)
### Code
@@ -193,8 +193,8 @@ Running Ultralytics YOLOv8 on a standard setup typically requires around 5GB of
### What makes Ultralytics YOLOv8 different from other object detection models like Faster R-CNN or SSD?
-Ultralytics YOLOv8 provides an edge over models like Faster R-CNN or SSD with its real-time detection capabilities and higher accuracy. Its unique architecture allows it to process images much faster without compromising on precision, making it ideal for time-sensitive applications like security alarm systems. For a comprehensive comparison of object detection models, you can explore our [guide](https://docs.ultralytics.com/models/).
+Ultralytics YOLOv8 provides an edge over models like Faster R-CNN or SSD with its real-time detection capabilities and higher accuracy. Its unique architecture allows it to process images much faster without compromising on [precision](https://www.ultralytics.com/glossary/precision), making it ideal for time-sensitive applications like security alarm systems. For a comprehensive comparison of object detection models, you can explore our [guide](https://docs.ultralytics.com/models/).
### How can I reduce the frequency of false positives in my security system using Ultralytics YOLOv8?
-To reduce false positives, ensure your Ultralytics YOLOv8 model is adequately trained with a diverse and well-annotated dataset. Fine-tuning hyperparameters and regularly updating the model with new data can significantly improve detection accuracy. Detailed hyperparameter tuning techniques can be found in our [hyperparameter tuning guide](../guides/hyperparameter-tuning.md).
+To reduce false positives, ensure your Ultralytics YOLOv8 model is adequately trained with a diverse and well-annotated dataset. Fine-tuning hyperparameters and regularly updating the model with new data can significantly improve detection accuracy. Detailed [hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning) techniques can be found in our [hyperparameter tuning guide](../guides/hyperparameter-tuning.md).
diff --git a/docs/en/guides/speed-estimation.md b/docs/en/guides/speed-estimation.md
index 9b76d0a3a0..6f3726c921 100644
--- a/docs/en/guides/speed-estimation.md
+++ b/docs/en/guides/speed-estimation.md
@@ -8,7 +8,7 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
## What is Speed Estimation?
-[Speed estimation](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects) is the process of calculating the rate of movement of an object within a given context, often employed in computer vision applications. Using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) you can now calculate the speed of object using [object tracking](../modes/track.md) alongside distance and time data, crucial for tasks like traffic and surveillance. The accuracy of speed estimation directly influences the efficiency and reliability of various applications, making it a key component in the advancement of intelligent systems and real-time decision-making processes.
+[Speed estimation](https://www.ultralytics.com/blog/ultralytics-yolov8-for-speed-estimation-in-computer-vision-projects) is the process of calculating the rate of movement of an object within a given context, often employed in [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) applications. Using [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) you can now calculate the speed of object using [object tracking](../modes/track.md) alongside distance and time data, crucial for tasks like traffic and surveillance. The accuracy of speed estimation directly influences the efficiency and reliability of various applications, making it a key component in the advancement of intelligent systems and real-time decision-making processes.
@@ -104,7 +104,7 @@ keywords: Ultralytics YOLOv8, speed estimation, object tracking, computer vision
### How do I estimate object speed using Ultralytics YOLOv8?
-Estimating object speed with Ultralytics YOLOv8 involves combining object detection and tracking techniques. First, you need to detect objects in each frame using the YOLOv8 model. Then, track these objects across frames to calculate their movement over time. Finally, use the distance traveled by the object between frames and the frame rate to estimate its speed.
+Estimating object speed with Ultralytics YOLOv8 involves combining [object detection](https://www.ultralytics.com/glossary/object-detection) and tracking techniques. First, you need to detect objects in each frame using the YOLOv8 model. Then, track these objects across frames to calculate their movement over time. Finally, use the distance traveled by the object between frames and the frame rate to estimate its speed.
**Example**:
@@ -152,7 +152,7 @@ Using Ultralytics YOLOv8 for speed estimation offers significant advantages in t
For more applications, see [advantages of speed estimation](#advantages-of-speed-estimation).
-### Can YOLOv8 be integrated with other AI frameworks like TensorFlow or PyTorch?
+### Can YOLOv8 be integrated with other AI frameworks like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) or [PyTorch](https://www.ultralytics.com/glossary/pytorch)?
Yes, YOLOv8 can be integrated with other AI frameworks like TensorFlow and PyTorch. Ultralytics provides support for exporting YOLOv8 models to various formats like ONNX, TensorRT, and CoreML, ensuring smooth interoperability with other ML frameworks.
@@ -166,7 +166,7 @@ Learn more about exporting models in our [guide on export](../modes/export.md).
### How accurate is the speed estimation using Ultralytics YOLOv8?
-The accuracy of speed estimation using Ultralytics YOLOv8 depends on several factors, including the quality of the object tracking, the resolution and frame rate of the video, and environmental variables. While the speed estimator provides reliable estimates, it may not be 100% accurate due to variances in frame processing speed and object occlusion.
+The [accuracy](https://www.ultralytics.com/glossary/accuracy) of speed estimation using Ultralytics YOLOv8 depends on several factors, including the quality of the object tracking, the resolution and frame rate of the video, and environmental variables. While the speed estimator provides reliable estimates, it may not be 100% accurate due to variances in frame processing speed and object occlusion.
**Note**: Always consider margin of error and validate the estimates with ground truth data when possible.
diff --git a/docs/en/guides/steps-of-a-cv-project.md b/docs/en/guides/steps-of-a-cv-project.md
index ec9b84ff2f..bbdbef5f35 100644
--- a/docs/en/guides/steps-of-a-cv-project.md
+++ b/docs/en/guides/steps-of-a-cv-project.md
@@ -8,7 +8,7 @@ keywords: Computer Vision, AI, Object Detection, Image Classification, Instance
## Introduction
-Computer vision is a subfield of artificial intelligence (AI) that helps computers see and understand the world like humans do. It processes and analyzes images or videos to extract information, recognize patterns, and make decisions based on that data.
+Computer vision is a subfield of [artificial intelligence](https://www.ultralytics.com/glossary/artificial-intelligence-ai) (AI) that helps computers see and understand the world like humans do. It processes and analyzes images or videos to extract information, recognize patterns, and make decisions based on that data.
@@ -18,7 +18,7 @@ Computer vision is a subfield of artificial intelligence (AI) that helps compute
allowfullscreen>
- Watch: How to Do Computer Vision Projects | A Step-by-Step Guide
+ Watch: How to Do [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) Projects | A Step-by-Step Guide
Computer vision techniques like [object detection](../tasks/detect.md), [image classification](../tasks/classify.md), and [instance segmentation](../tasks/segment.md) can be applied across various industries, from [autonomous driving](https://www.ultralytics.com/solutions/ai-in-self-driving) to [medical imaging](https://www.ultralytics.com/solutions/ai-in-healthcare) to gain valuable insights.
@@ -60,7 +60,7 @@ Here are some examples of project objectives and the computer vision tasks that
- **Computer Vision Task:** Image segmentation is suitable for medical imaging because it provides accurate and detailed boundaries of tumors that are crucial for assessing size, shape, and treatment planning.
- **Objective:** To create a digital system that categorizes various documents (e.g., invoices, receipts, legal paperwork) to improve organizational efficiency and document retrieval.
- - **Computer Vision Task:** Image classification is ideal here as it handles one document at a time, without needing to consider the document's position in the image. This approach simplifies and accelerates the sorting process.
+ - **Computer Vision Task:** [Image classification](https://www.ultralytics.com/glossary/image-classification) is ideal here as it handles one document at a time, without needing to consider the document's position in the image. This approach simplifies and accelerates the sorting process.
### Step 1.5: Selecting the Right Model and Training Approach
@@ -68,13 +68,13 @@ After understanding the project objective and suitable computer vision tasks, an
Depending on the objective, you might choose to select the model first or after seeing what data you are able to collect in Step 2. For example, suppose your project is highly dependent on the availability of specific types of data. In that case, it may be more practical to gather and analyze the data first before selecting a model. On the other hand, if you have a clear understanding of the model requirements, you can choose the model first and then collect data that fits those specifications.
-Choosing between training from scratch or using transfer learning affects how you prepare your data. Training from scratch requires a diverse dataset to build the model's understanding from the ground up. Transfer learning, on the other hand, allows you to use a pre-trained model and adapt it with a smaller, more specific dataset. Also, choosing a specific model to train will determine how you need to prepare your data, such as resizing images or adding annotations, according to the model's specific requirements.
+Choosing between training from scratch or using [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) affects how you prepare your data. Training from scratch requires a diverse dataset to build the model's understanding from the ground up. Transfer learning, on the other hand, allows you to use a pre-trained model and adapt it with a smaller, more specific dataset. Also, choosing a specific model to train will determine how you need to prepare your data, such as resizing images or adding annotations, according to the model's specific requirements.
-Note: When choosing a model, consider its [deployment](./model-deployment-options.md) to ensure compatibility and performance. For example, lightweight models are ideal for edge computing due to their efficiency on resource-constrained devices. To learn more about the key points related to defining your project, read [our guide](./defining-project-goals.md) on defining your project's goals and selecting the right model.
+Note: When choosing a model, consider its [deployment](./model-deployment-options.md) to ensure compatibility and performance. For example, lightweight models are ideal for [edge computing](https://www.ultralytics.com/glossary/edge-computing) due to their efficiency on resource-constrained devices. To learn more about the key points related to defining your project, read [our guide](./defining-project-goals.md) on defining your project's goals and selecting the right model.
Before getting into the hands-on work of a computer vision project, it's important to have a clear understanding of these details. Double-check that you've considered the following before moving on to Step 2:
@@ -93,8 +93,8 @@ Some libraries, like Ultralytics, provide [built-in support for various datasets
However, if you choose to collect images or take your own pictures, you'll need to annotate your data. Data annotation is the process of labeling your data to impart knowledge to your model. The type of data annotation you'll work with depends on your specific computer vision technique. Here are some examples:
- **Image Classification:** You'll label the entire image as a single class.
-- **Object Detection:** You'll draw bounding boxes around each object in the image and label each box.
-- **Image Segmentation:** You'll label each pixel in the image according to the object it belongs to, creating detailed object boundaries.
+- **[Object Detection](https://www.ultralytics.com/glossary/object-detection):** You'll draw bounding boxes around each object in the image and label each box.
+- **[Image Segmentation](https://www.ultralytics.com/glossary/image-segmentation):** You'll label each pixel in the image according to the object it belongs to, creating detailed object boundaries.
@@ -102,14 +102,14 @@ However, if you choose to collect images or take your own pictures, you'll need
[Data collection and annotation](./data-collection-and-annotation.md) can be a time-consuming manual effort. Annotation tools can help make this process easier. Here are some useful open annotation tools: [LabeI Studio](https://github.com/HumanSignal/label-studio), [CVAT](https://github.com/cvat-ai/cvat), and [Labelme](https://github.com/labelmeai/labelme).
-## Step 3: Data Augmentation and Splitting Your Dataset
+## Step 3: [Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation) and Splitting Your Dataset
After collecting and annotating your image data, it's important to first split your dataset into training, validation, and test sets before performing data augmentation. Splitting your dataset before augmentation is crucial to test and validate your model on original, unaltered data. It helps accurately assess how well the model generalizes to new, unseen data.
Here's how to split your data:
- **Training Set:** It is the largest portion of your data, typically 70-80% of the total, used to train your model.
-- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent overfitting.
+- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent [overfitting](https://www.ultralytics.com/glossary/overfitting).
- **Test Set:** The remaining 10-15% of your data is set aside as the test set. It is used to evaluate the model's performance on unseen data after training is complete.
After splitting your data, you can perform data augmentation by applying transformations like rotating, scaling, and flipping images to artificially increase the size of your dataset. Data augmentation makes your model more robust to variations and improves its performance on unseen images.
@@ -118,7 +118,7 @@ After splitting your data, you can perform data augmentation by applying transfo
-Libraries like OpenCV, Albumentations, and TensorFlow offer flexible augmentation functions that you can use. Additionally, some libraries, such as Ultralytics, have [built-in augmentation settings](../modes/train.md) directly within its model training function, simplifying the process.
+Libraries like [OpenCV](https://www.ultralytics.com/glossary/opencv), Albumentations, and [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) offer flexible augmentation functions that you can use. Additionally, some libraries, such as Ultralytics, have [built-in augmentation settings](../modes/train.md) directly within its model training function, simplifying the process.
To understand your data better, you can use tools like [Matplotlib](https://matplotlib.org/) or [Seaborn](https://seaborn.pydata.org/) to visualize the images and analyze their distribution and characteristics. Visualizing your data helps identify patterns, anomalies, and the effectiveness of your augmentation techniques. You can also use [Ultralytics Explorer](../datasets/explorer/index.md), a tool for exploring computer vision datasets with semantic search, SQL queries, and vector similarity search.
@@ -134,23 +134,23 @@ Once your dataset is ready for training, you can focus on setting up the necessa
First, you'll need to make sure your environment is configured correctly. Typically, this includes the following:
-- Installing essential libraries and frameworks like TensorFlow, PyTorch, or [Ultralytics](../quickstart.md).
+- Installing essential libraries and frameworks like TensorFlow, [PyTorch](https://www.ultralytics.com/glossary/pytorch), or [Ultralytics](../quickstart.md).
- If you are using a GPU, installing libraries like CUDA and cuDNN will help enable GPU acceleration and speed up the training process.
-Then, you can load your training and validation datasets into your environment. Normalize and preprocess the data through resizing, format conversion, or augmentation. With your model selected, configure the layers and specify hyperparameters. Compile the model by setting the loss function, optimizer, and performance metrics.
+Then, you can load your training and validation datasets into your environment. Normalize and preprocess the data through resizing, format conversion, or augmentation. With your model selected, configure the layers and specify hyperparameters. Compile the model by setting the [loss function](https://www.ultralytics.com/glossary/loss-function), optimizer, and performance metrics.
-Libraries like Ultralytics simplify the training process. You can [start training](../modes/train.md) by feeding data into the model with minimal code. These libraries handle weight adjustments, backpropagation, and validation automatically. They also offer tools to monitor progress and adjust hyperparameters easily. After training, save the model and its weights with a few commands.
+Libraries like Ultralytics simplify the training process. You can [start training](../modes/train.md) by feeding data into the model with minimal code. These libraries handle weight adjustments, [backpropagation](https://www.ultralytics.com/glossary/backpropagation), and validation automatically. They also offer tools to monitor progress and adjust hyperparameters easily. After training, save the model and its weights with a few commands.
It's important to keep in mind that proper dataset management is vital for efficient training. Use version control for datasets to track changes and ensure reproducibility. Tools like [DVC (Data Version Control)](../integrations/dvc.md) can help manage large datasets.
-## Step 5: Model Evaluation and Model Finetuning
+## Step 5: Model Evaluation and Model [Finetuning](https://www.ultralytics.com/glossary/fine-tuning)
-It's important to assess your model's performance using various metrics and refine it to improve accuracy. [Evaluating](../modes/val.md) helps identify areas where the model excels and where it may need improvement. Fine-tuning ensures the model is optimized for the best possible performance.
+It's important to assess your model's performance using various metrics and refine it to improve [accuracy](https://www.ultralytics.com/glossary/accuracy). [Evaluating](../modes/val.md) helps identify areas where the model excels and where it may need improvement. Fine-tuning ensures the model is optimized for the best possible performance.
-- **[Performance Metrics](./yolo-performance-metrics.md):** Use metrics like accuracy, precision, recall, and F1-score to evaluate your model's performance. These metrics provide insights into how well your model is making predictions.
+- **[Performance Metrics](./yolo-performance-metrics.md):** Use metrics like accuracy, [precision](https://www.ultralytics.com/glossary/precision), recall, and F1-score to evaluate your model's performance. These metrics provide insights into how well your model is making predictions.
- **[Hyperparameter Tuning](./hyperparameter-tuning.md):** Adjust hyperparameters to optimize model performance. Techniques like grid search or random search can help find the best hyperparameter values.
-- Fine-Tuning: Make small adjustments to the model architecture or training process to enhance performance. This might involve tweaking learning rates, batch sizes, or other model parameters.
+- Fine-Tuning: Make small adjustments to the model architecture or training process to enhance performance. This might involve tweaking [learning rates](https://www.ultralytics.com/glossary/learning-rate), [batch sizes](https://www.ultralytics.com/glossary/batch-size), or other model parameters.
## Step 6: Model Testing
@@ -158,9 +158,9 @@ In this step, you can make sure that your model performs well on completely unse
It's important to thoroughly test and debug any common issues that may arise. Test your model on a separate test dataset that was not used during training or validation. This dataset should represent real-world scenarios to ensure the model's performance is consistent and reliable.
-Also, address common problems such as overfitting, underfitting, and data leakage. Use techniques like cross-validation and anomaly detection to identify and fix these issues.
+Also, address common problems such as overfitting, [underfitting](https://www.ultralytics.com/glossary/underfitting), and data leakage. Use techniques like cross-validation and [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) to identify and fix these issues.
-## Step 7: Model Deployment
+## Step 7: [Model Deployment](https://www.ultralytics.com/glossary/model-deployment)
Once your model has been thoroughly tested, it's time to deploy it. Deployment involves making your model available for use in a production environment. Here are the steps to deploy a computer vision model:
@@ -222,7 +222,7 @@ Tools like [Label Studio](https://github.com/HumanSignal/label-studio), [CVAT](h
Splitting your dataset before augmentation helps validate model performance on original, unaltered data. Follow these steps:
- **Training Set**: 70-80% of your data.
-- **Validation Set**: 10-15% for hyperparameter tuning.
+- **Validation Set**: 10-15% for [hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning).
- **Test Set**: Remaining 10-15% for final evaluation.
After splitting, apply data augmentation techniques like rotation, scaling, and flipping to increase dataset diversity. Libraries such as Albumentations and OpenCV can help. Ultralytics also offers [built-in augmentation settings](../modes/train.md) for convenience.
diff --git a/docs/en/guides/streamlit-live-inference.md b/docs/en/guides/streamlit-live-inference.md
index 84e1bce8ee..e8fb5c9165 100644
--- a/docs/en/guides/streamlit-live-inference.md
+++ b/docs/en/guides/streamlit-live-inference.md
@@ -8,7 +8,7 @@ keywords: Streamlit, YOLOv8, Real-time Object Detection, Streamlit Application,
## Introduction
-Streamlit makes it simple to build and deploy interactive web applications. Combining this with Ultralytics YOLOv8 allows for real-time object detection and analysis directly in your browser. YOLOv8 high accuracy and speed ensure seamless performance for live video streams, making it ideal for applications in security, retail, and beyond.
+Streamlit makes it simple to build and deploy interactive web applications. Combining this with Ultralytics YOLOv8 allows for real-time [object detection](https://www.ultralytics.com/glossary/object-detection) and analysis directly in your browser. YOLOv8 high accuracy and speed ensure seamless performance for live video streams, making it ideal for applications in security, retail, and beyond.
@@ -18,7 +18,7 @@ Streamlit makes it simple to build and deploy interactive web applications. Comb
allowfullscreen>
- Watch: How to Use Streamlit with Ultralytics for Real-Time Computer Vision in Your Browser
+ Watch: How to Use Streamlit with Ultralytics for Real-Time [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) in Your Browser
| Aquaculture | Animals husbandry |
@@ -128,7 +128,7 @@ For more details on the practical setup, refer to the [Streamlit Application Cod
Using Ultralytics YOLOv8 with Streamlit for real-time object detection offers several advantages:
-- **Seamless Real-Time Detection**: Achieve high-accuracy, real-time object detection directly from webcam feeds.
+- **Seamless Real-Time Detection**: Achieve high-[accuracy](https://www.ultralytics.com/glossary/accuracy), real-time object detection directly from webcam feeds.
- **User-Friendly Interface**: Streamlit's intuitive interface allows easy use and deployment without extensive technical knowledge.
- **Resource Efficiency**: YOLOv8's optimized algorithms ensure high-speed processing with minimal computational resources.
diff --git a/docs/en/guides/triton-inference-server.md b/docs/en/guides/triton-inference-server.md
index 05edf54f43..1233ba9ae1 100644
--- a/docs/en/guides/triton-inference-server.md
+++ b/docs/en/guides/triton-inference-server.md
@@ -6,7 +6,7 @@ keywords: Triton Inference Server, YOLOv8, Ultralytics, NVIDIA, deep learning, A
# Triton Inference Server with Ultralytics YOLOv8
-The [Triton Inference Server](https://developer.nvidia.com/triton-inference-server) (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. It provides a cloud inference solution optimized for NVIDIA GPUs. Triton simplifies the deployment of AI models at scale in production. Integrating Ultralytics YOLOv8 with Triton Inference Server allows you to deploy scalable, high-performance deep learning inference workloads. This guide provides steps to set up and test the integration.
+The [Triton Inference Server](https://developer.nvidia.com/triton-inference-server) (formerly known as TensorRT Inference Server) is an open-source software solution developed by NVIDIA. It provides a cloud inference solution optimized for NVIDIA GPUs. Triton simplifies the deployment of AI models at scale in production. Integrating Ultralytics YOLOv8 with Triton Inference Server allows you to deploy scalable, high-performance [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) inference workloads. This guide provides steps to set up and test the integration.
@@ -21,7 +21,7 @@ The [Triton Inference Server](https://developer.nvidia.com/triton-inference-serv
## What is Triton Inference Server?
-Triton Inference Server is designed to deploy a variety of AI models in production. It supports a wide range of deep learning and machine learning frameworks, including TensorFlow, PyTorch, ONNX Runtime, and many others. Its primary use cases are:
+Triton Inference Server is designed to deploy a variety of AI models in production. It supports a wide range of deep learning and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) frameworks, including TensorFlow, [PyTorch](https://www.ultralytics.com/glossary/pytorch), ONNX Runtime, and many others. Its primary use cases are:
- Serving multiple models from a single server instance.
- Dynamic model loading and unloading without server restart.
@@ -216,7 +216,7 @@ This setup can help you efficiently deploy YOLOv8 models at scale on Triton Infe
Integrating [Ultralytics YOLOv8](../models/yolov8.md) with [NVIDIA Triton Inference Server](https://developer.nvidia.com/triton-inference-server) provides several advantages:
- **Scalable AI Inference**: Triton allows serving multiple models from a single server instance, supporting dynamic model loading and unloading, making it highly scalable for diverse AI workloads.
-- **High Performance**: Optimized for NVIDIA GPUs, Triton Inference Server ensures high-speed inference operations, perfect for real-time applications such as object detection.
+- **High Performance**: Optimized for NVIDIA GPUs, Triton Inference Server ensures high-speed inference operations, perfect for real-time applications such as [object detection](https://www.ultralytics.com/glossary/object-detection).
- **Ensemble and Model Versioning**: Triton's ensemble mode enables combining multiple models to improve results, and its model versioning supports A/B testing and rolling updates.
For detailed instructions on setting up and running YOLOv8 with Triton, you can refer to the [setup guide](#setting-up-triton-model-repository).
@@ -256,11 +256,11 @@ results = model("path/to/image.jpg")
For an in-depth guide on setting up and running Triton Server with YOLOv8, refer to the [running triton inference server](#running-triton-inference-server) section.
-### How does Ultralytics YOLOv8 compare to TensorFlow and PyTorch models for deployment?
+### How does Ultralytics YOLOv8 compare to [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) and PyTorch models for deployment?
[Ultralytics YOLOv8](https://docs.ultralytics.com/models/yolov8/) offers several unique advantages compared to TensorFlow and PyTorch models for deployment:
-- **Real-time Performance**: Optimized for real-time object detection tasks, YOLOv8 provides state-of-the-art accuracy and speed, making it ideal for applications requiring live video analytics.
+- **Real-time Performance**: Optimized for real-time object detection tasks, YOLOv8 provides state-of-the-art [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed, making it ideal for applications requiring live video analytics.
- **Ease of Use**: YOLOv8 integrates seamlessly with Triton Inference Server and supports diverse export formats (ONNX, TensorRT, CoreML), making it flexible for various deployment scenarios.
- **Advanced Features**: YOLOv8 includes features like dynamic model loading, model versioning, and ensemble inference, which are crucial for scalable and reliable AI deployments.
diff --git a/docs/en/guides/view-results-in-terminal.md b/docs/en/guides/view-results-in-terminal.md
index c599f6643a..cb6ce1c087 100644
--- a/docs/en/guides/view-results-in-terminal.md
+++ b/docs/en/guides/view-results-in-terminal.md
@@ -58,7 +58,7 @@ The VSCode compatible protocols for viewing images using the integrated terminal
1. See [plot method parameters](../modes/predict.md#plot-method-parameters) to see possible arguments to use.
-4. Now, use OpenCV to convert the `numpy.ndarray` to `bytes` data. Then use `io.BytesIO` to make a "file-like" object.
+4. Now, use [OpenCV](https://www.ultralytics.com/glossary/opencv) to convert the `numpy.ndarray` to `bytes` data. Then use `io.BytesIO` to make a "file-like" object.
```{ .py .annotate }
import io
diff --git a/docs/en/guides/vision-eye.md b/docs/en/guides/vision-eye.md
index 891a589b24..48cff2746d 100644
--- a/docs/en/guides/vision-eye.md
+++ b/docs/en/guides/vision-eye.md
@@ -8,7 +8,7 @@ keywords: VisionEye, YOLOv8, Ultralytics, object mapping, object tracking, dista
## What is VisionEye Object Mapping?
-[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) VisionEye offers the capability for computers to identify and pinpoint objects, simulating the observational precision of the human eye. This functionality enables computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
+[Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) VisionEye offers the capability for computers to identify and pinpoint objects, simulating the observational [precision](https://www.ultralytics.com/glossary/precision) of the human eye. This functionality enables computers to discern and focus on specific objects, much like the way the human eye observes details from a particular viewpoint.
## Samples
@@ -182,7 +182,7 @@ For any inquiries, feel free to post your questions in the [Ultralytics Issue Se
### How do I start using VisionEye Object Mapping with Ultralytics YOLOv8?
-To start using VisionEye Object Mapping with Ultralytics YOLOv8, first, you'll need to install the Ultralytics YOLO package via pip. Then, you can use the sample code provided in the documentation to set up object detection with VisionEye. Here's a simple example to get you started:
+To start using VisionEye Object Mapping with Ultralytics YOLOv8, first, you'll need to install the Ultralytics YOLO package via pip. Then, you can use the sample code provided in the documentation to set up [object detection](https://www.ultralytics.com/glossary/object-detection) with VisionEye. Here's a simple example to get you started:
```python
import cv2
@@ -292,7 +292,7 @@ For detailed instructions, refer to the [VisionEye with Distance Calculation](#s
### Why should I use Ultralytics YOLOv8 for object mapping and tracking?
-Ultralytics YOLOv8 is renowned for its speed, accuracy, and ease of integration, making it a top choice for object mapping and tracking. Key advantages include:
+Ultralytics YOLOv8 is renowned for its speed, [accuracy](https://www.ultralytics.com/glossary/accuracy), and ease of integration, making it a top choice for object mapping and tracking. Key advantages include:
1. **State-of-the-art Performance**: Delivers high accuracy in real-time object detection.
2. **Flexibility**: Supports various tasks such as detection, tracking, and distance calculation.
@@ -301,7 +301,7 @@ Ultralytics YOLOv8 is renowned for its speed, accuracy, and ease of integration,
For more information on applications and benefits, check out the [Ultralytics YOLOv8 documentation](https://docs.ultralytics.com/models/yolov8/).
-### How can I integrate VisionEye with other machine learning tools like Comet or ClearML?
+### How can I integrate VisionEye with other [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) tools like Comet or ClearML?
Ultralytics YOLOv8 can integrate seamlessly with various machine learning tools like Comet and ClearML, enhancing experiment tracking, collaboration, and reproducibility. Follow the detailed guides on [how to use YOLOv5 with Comet](https://www.ultralytics.com/blog/how-to-use-yolov5-with-comet) and [integrate YOLOv8 with ClearML](https://docs.ultralytics.com/integrations/clearml/) to get started.
diff --git a/docs/en/guides/workouts-monitoring.md b/docs/en/guides/workouts-monitoring.md
index e042acfa75..4585631683 100644
--- a/docs/en/guides/workouts-monitoring.md
+++ b/docs/en/guides/workouts-monitoring.md
@@ -179,7 +179,7 @@ You can watch a [YouTube video demonstration](https://www.youtube.com/watch?v=LG
### How accurate is Ultralytics YOLOv8 in detecting and tracking exercises?
-Ultralytics YOLOv8 is highly accurate in detecting and tracking exercises due to its state-of-the-art pose estimation capabilities. It can accurately track key body landmarks and joints, providing real-time feedback on exercise form and performance metrics. The model's pretrained weights and robust architecture ensure high precision and reliability. For real-world examples, check out the [real-world applications](#real-world-applications) section in the documentation, which showcases pushups and pullups counting.
+Ultralytics YOLOv8 is highly accurate in detecting and tracking exercises due to its state-of-the-art pose estimation capabilities. It can accurately track key body landmarks and joints, providing real-time feedback on exercise form and performance metrics. The model's pretrained weights and robust architecture ensure high [precision](https://www.ultralytics.com/glossary/precision) and reliability. For real-world examples, check out the [real-world applications](#real-world-applications) section in the documentation, which showcases pushups and pullups counting.
### Can I use Ultralytics YOLOv8 for custom workout routines?
diff --git a/docs/en/guides/yolo-common-issues.md b/docs/en/guides/yolo-common-issues.md
index 77351eaa06..6da5d164e9 100644
--- a/docs/en/guides/yolo-common-issues.md
+++ b/docs/en/guides/yolo-common-issues.md
@@ -33,7 +33,7 @@ Installation errors can arise due to various reasons, such as incompatible versi
- You're using Python 3.8 or later as recommended.
-- Ensure that you have the correct version of PyTorch (1.8 or later) installed.
+- Ensure that you have the correct version of [PyTorch](https://www.ultralytics.com/glossary/pytorch) (1.8 or later) installed.
- Consider using virtual environments to avoid conflicts.
@@ -86,7 +86,7 @@ model.train(data="/path/to/your/data.yaml", batch=4)
**Issue**: Training is slow on a single GPU, and you want to speed up the process using multiple GPUs.
-**Solution**: Increasing the batch size can accelerate training, but it's essential to consider GPU memory capacity. To speed up training with multiple GPUs, follow these steps:
+**Solution**: Increasing the [batch size](https://www.ultralytics.com/glossary/batch-size) can accelerate training, but it's essential to consider GPU memory capacity. To speed up training with multiple GPUs, follow these steps:
- Ensure that you have multiple GPUs available.
@@ -109,7 +109,7 @@ model.train(data="/path/to/your/data.yaml", batch=32, multi_scale=True)
- Precision
- Recall
-- Mean Average Precision (mAP)
+- [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP)
You can access these metrics from the training logs or by using tools like TensorBoard or wandb for visualization. Implementing early stopping based on these metrics can help you achieve better results.
@@ -119,7 +119,7 @@ You can access these metrics from the training logs or by using tools like Tenso
**Solution**: To track and visualize training progress, you can consider using the following tools:
-- [TensorBoard](https://www.tensorflow.org/tensorboard): TensorBoard is a popular choice for visualizing training metrics, including loss, accuracy, and more. You can integrate it with your YOLOv8 training process.
+- [TensorBoard](https://www.tensorflow.org/tensorboard): TensorBoard is a popular choice for visualizing training metrics, including loss, [accuracy](https://www.ultralytics.com/glossary/accuracy), and more. You can integrate it with your YOLOv8 training process.
- [Comet](https://bit.ly/yolov8-readme-comet): Comet provides an extensive toolkit for experiment tracking and comparison. It allows you to track metrics, hyperparameters, and even model weights. Integration with YOLO models is also straightforward, providing you with a complete overview of your experiment cycle.
- [Ultralytics HUB](https://hub.ultralytics.com/): Ultralytics HUB offers a specialized environment for tracking YOLO models, giving you a one-stop platform to manage metrics, datasets, and even collaborate with your team. Given its tailored focus on YOLO, it offers more customized tracking options.
@@ -145,17 +145,17 @@ Here are some things to keep in mind, if you are facing issues related to model
**Dataset Format and Labels**
-- Importance: The foundation of any machine learning model lies in the quality and format of the data it is trained on.
+- Importance: The foundation of any [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) model lies in the quality and format of the data it is trained on.
- Recommendation: Ensure that your custom dataset and its associated labels adhere to the expected format. It's crucial to verify that annotations are accurate and of high quality. Incorrect or subpar annotations can derail the model's learning process, leading to unpredictable outcomes.
**Model Convergence**
-- Importance: Achieving model convergence ensures that the model has sufficiently learned from the training data.
+- Importance: Achieving model convergence ensures that the model has sufficiently learned from the [training data](https://www.ultralytics.com/glossary/training-data).
-- Recommendation: When training a model 'from scratch', it's vital to ensure that the model reaches a satisfactory level of convergence. This might necessitate a longer training duration, with more epochs, compared to when you're fine-tuning an existing model.
+- Recommendation: When training a model 'from scratch', it's vital to ensure that the model reaches a satisfactory level of convergence. This might necessitate a longer training duration, with more [epochs](https://www.ultralytics.com/glossary/epoch), compared to when you're fine-tuning an existing model.
-**Learning Rate and Batch Size**
+**[Learning Rate](https://www.ultralytics.com/glossary/learning-rate) and Batch Size**
- Importance: These hyperparameters play a pivotal role in determining how the model updates its weights during training.
@@ -207,9 +207,9 @@ yolo task=detect mode=segment model=yolov8n-seg.pt source='path/to/car.mp4' show
#### Understanding Precision Metrics in YOLOv8
-**Issue**: Confusion regarding the difference between box precision, mask precision, and confusion matrix precision in YOLOv8.
+**Issue**: Confusion regarding the difference between box precision, mask precision, and [confusion matrix](https://www.ultralytics.com/glossary/confusion-matrix) precision in YOLOv8.
-**Solution**: Box precision measures the accuracy of predicted bounding boxes compared to the actual ground truth boxes using IoU (Intersection over Union) as the metric. Mask precision assesses the agreement between predicted segmentation masks and ground truth masks in pixel-wise object classification. Confusion matrix precision, on the other hand, focuses on overall classification accuracy across all classes and does not consider the geometric accuracy of predictions. It's important to note that a bounding box can be geometrically accurate (true positive) even if the class prediction is wrong, leading to differences between box precision and confusion matrix precision. These metrics evaluate distinct aspects of a model's performance, reflecting the need for different evaluation metrics in various tasks.
+**Solution**: Box precision measures the accuracy of predicted bounding boxes compared to the actual ground truth boxes using IoU (Intersection over Union) as the metric. Mask precision assesses the agreement between predicted segmentation masks and ground truth masks in pixel-wise object classification. Confusion matrix precision, on the other hand, focuses on overall classification accuracy across all classes and does not consider the geometric accuracy of predictions. It's important to note that a [bounding box](https://www.ultralytics.com/glossary/bounding-box) can be geometrically accurate (true positive) even if the class prediction is wrong, leading to differences between box precision and confusion matrix precision. These metrics evaluate distinct aspects of a model's performance, reflecting the need for different evaluation metrics in various tasks.
#### Extracting Object Dimensions in YOLOv8
@@ -280,7 +280,7 @@ These resources should provide a solid foundation for troubleshooting and improv
## Conclusion
-Troubleshooting is an integral part of any development process, and being equipped with the right knowledge can significantly reduce the time and effort spent in resolving issues. This guide aimed to address the most common challenges faced by users of the YOLOv8 model within the Ultralytics ecosystem. By understanding and addressing these common issues, you can ensure smoother project progress and achieve better results with your computer vision tasks.
+Troubleshooting is an integral part of any development process, and being equipped with the right knowledge can significantly reduce the time and effort spent in resolving issues. This guide aimed to address the most common challenges faced by users of the YOLOv8 model within the Ultralytics ecosystem. By understanding and addressing these common issues, you can ensure smoother project progress and achieve better results with your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) tasks.
Remember, the Ultralytics community is a valuable resource. Engaging with fellow developers and experts can provide additional insights and solutions that might not be covered in standard documentation. Always keep learning, experimenting, and sharing your experiences to contribute to the collective knowledge of the community.
@@ -312,7 +312,7 @@ This sets the training process to the first GPU. Consult the `nvidia-smi` comman
### How can I monitor and track my YOLOv8 model training progress?
-Tracking and visualizing training progress can be efficiently managed through tools like [TensorBoard](https://www.tensorflow.org/tensorboard), [Comet](https://bit.ly/yolov8-readme-comet), and [Ultralytics HUB](https://hub.ultralytics.com/). These tools allow you to log and visualize metrics such as loss, precision, recall, and mAP. Implementing [early stopping](#continuous-monitoring-parameters) based on these metrics can also help achieve better training outcomes.
+Tracking and visualizing training progress can be efficiently managed through tools like [TensorBoard](https://www.tensorflow.org/tensorboard), [Comet](https://bit.ly/yolov8-readme-comet), and [Ultralytics HUB](https://hub.ultralytics.com/). These tools allow you to log and visualize metrics such as loss, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and mAP. Implementing [early stopping](#continuous-monitoring-parameters) based on these metrics can also help achieve better training outcomes.
### What should I do if YOLOv8 is not recognizing my dataset format?
diff --git a/docs/en/guides/yolo-performance-metrics.md b/docs/en/guides/yolo-performance-metrics.md
index d885b9eab3..aeed82355d 100644
--- a/docs/en/guides/yolo-performance-metrics.md
+++ b/docs/en/guides/yolo-performance-metrics.md
@@ -8,7 +8,7 @@ keywords: YOLOv8 performance metrics, mAP, IoU, F1 Score, Precision, Recall, obj
## Introduction
-Performance metrics are key tools to evaluate the accuracy and efficiency of object detection models. They shed light on how effectively a model can identify and localize objects within images. Additionally, they help in understanding the model's handling of false positives and false negatives. These insights are crucial for evaluating and enhancing the model's performance. In this guide, we will explore various performance metrics associated with YOLOv8, their significance, and how to interpret them.
+Performance metrics are key tools to evaluate the [accuracy](https://www.ultralytics.com/glossary/accuracy) and efficiency of [object detection](https://www.ultralytics.com/glossary/object-detection) models. They shed light on how effectively a model can identify and localize objects within images. Additionally, they help in understanding the model's handling of false positives and false negatives. These insights are crucial for evaluating and enhancing the model's performance. In this guide, we will explore various performance metrics associated with YOLOv8, their significance, and how to interpret them.
@@ -18,14 +18,14 @@ Performance metrics are key tools to evaluate the accuracy and efficiency of obj
allowfullscreen>
- Watch: Ultralytics YOLOv8 Performance Metrics | MAP, F1 Score, Precision, IoU & Accuracy
+ Watch: Ultralytics YOLOv8 Performance Metrics | MAP, F1 Score, [Precision](https://www.ultralytics.com/glossary/precision), IoU & Accuracy
## Object Detection Metrics
Let's start by discussing some metrics that are not only important to YOLOv8 but are broadly applicable across different object detection models.
-- **Intersection over Union (IoU):** IoU is a measure that quantifies the overlap between a predicted bounding box and a ground truth bounding box. It plays a fundamental role in evaluating the accuracy of object localization.
+- **[Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU):** IoU is a measure that quantifies the overlap between a predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) and a ground truth bounding box. It plays a fundamental role in evaluating the accuracy of object localization.
- **Average Precision (AP):** AP computes the area under the precision-recall curve, providing a single value that encapsulates the model's precision and recall performance.
@@ -77,15 +77,15 @@ For users validating on the COCO dataset, additional metrics are calculated usin
The model.val() function, apart from producing numeric metrics, also yields visual outputs that can provide a more intuitive understanding of the model's performance. Here's a breakdown of the visual outputs you can expect:
-- **F1 Score Curve (`F1_curve.png`)**: This curve represents the F1 score across various thresholds. Interpreting this curve can offer insights into the model's balance between false positives and false negatives over different thresholds.
+- **F1 Score Curve (`F1_curve.png`)**: This curve represents the [F1 score](https://www.ultralytics.com/glossary/f1-score) across various thresholds. Interpreting this curve can offer insights into the model's balance between false positives and false negatives over different thresholds.
-- **Precision-Recall Curve (`PR_curve.png`)**: An integral visualization for any classification problem, this curve showcases the trade-offs between precision and recall at varied thresholds. It becomes especially significant when dealing with imbalanced classes.
+- **Precision-Recall Curve (`PR_curve.png`)**: An integral visualization for any classification problem, this curve showcases the trade-offs between precision and [recall](https://www.ultralytics.com/glossary/recall) at varied thresholds. It becomes especially significant when dealing with imbalanced classes.
- **Precision Curve (`P_curve.png`)**: A graphical representation of precision values at different thresholds. This curve helps in understanding how precision varies as the threshold changes.
- **Recall Curve (`R_curve.png`)**: Correspondingly, this graph illustrates how the recall values change across different thresholds.
-- **Confusion Matrix (`confusion_matrix.png`)**: The confusion matrix provides a detailed view of the outcomes, showcasing the counts of true positives, true negatives, false positives, and false negatives for each class.
+- **[Confusion Matrix](https://www.ultralytics.com/glossary/confusion-matrix) (`confusion_matrix.png`)**: The confusion matrix provides a detailed view of the outcomes, showcasing the counts of true positives, true negatives, false positives, and false negatives for each class.
- **Normalized Confusion Matrix (`confusion_matrix_normalized.png`)**: This visualization is a normalized version of the confusion matrix. It represents the data in proportions rather than raw counts. This format makes it simpler to compare the performance across classes.
@@ -123,7 +123,7 @@ It's important to understand the metrics. Here's what some of the commonly obser
- **Low Precision:** The model may be detecting too many non-existent objects. Adjusting confidence thresholds might reduce this.
-- **Low Recall:** The model could be missing real objects. Improving feature extraction or using more data might help.
+- **Low Recall:** The model could be missing real objects. Improving [feature extraction](https://www.ultralytics.com/glossary/feature-extraction) or using more data might help.
- **Imbalanced F1 Score:** There's a disparity between precision and recall.
@@ -177,7 +177,7 @@ Happy object detecting!
## FAQ
-### What is the significance of Mean Average Precision (mAP) in evaluating YOLOv8 model performance?
+### What is the significance of [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) in evaluating YOLOv8 model performance?
Mean Average Precision (mAP) is crucial for evaluating YOLOv8 models as it provides a single metric encapsulating precision and recall across multiple classes. mAP@0.50 measures precision at an IoU threshold of 0.50, focusing on the model's ability to detect objects correctly. mAP@0.50:0.95 averages precision across a range of IoU thresholds, offering a comprehensive assessment of detection performance. High mAP scores indicate that the model effectively balances precision and recall, essential for applications like autonomous driving and surveillance.
diff --git a/docs/en/help/FAQ.md b/docs/en/help/FAQ.md
index 24472e77f4..234fb9e82f 100644
--- a/docs/en/help/FAQ.md
+++ b/docs/en/help/FAQ.md
@@ -12,7 +12,7 @@ This FAQ section addresses common questions and issues users might encounter whi
### What is Ultralytics and what does it offer?
-Ultralytics is a computer vision AI company specializing in state-of-the-art object detection and image segmentation models, with a focus on the YOLO (You Only Look Once) family. Their offerings include:
+Ultralytics is a [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) AI company specializing in state-of-the-art object detection and [image segmentation](https://www.ultralytics.com/glossary/image-segmentation) models, with a focus on the YOLO (You Only Look Once) family. Their offerings include:
- Open-source implementations of [YOLOv5](https://docs.ultralytics.com/models/yolov5/) and [YOLOv8](https://docs.ultralytics.com/models/yolov8/)
- A wide range of [pre-trained models](https://docs.ultralytics.com/models/) for various computer vision tasks
@@ -41,7 +41,7 @@ Detailed installation instructions can be found in the [quickstart guide](https:
Minimum requirements:
- Python 3.7+
-- PyTorch 1.7+
+- [PyTorch](https://www.ultralytics.com/glossary/pytorch) 1.7+
- CUDA-compatible GPU (for GPU acceleration)
Recommended setup:
@@ -80,10 +80,10 @@ For a more in-depth guide, including data preparation and advanced training opti
Ultralytics offers a diverse range of pretrained YOLOv8 models for various tasks:
- Object Detection: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x
-- Instance Segmentation: YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, YOLOv8x-seg
+- [Instance Segmentation](https://www.ultralytics.com/glossary/instance-segmentation): YOLOv8n-seg, YOLOv8s-seg, YOLOv8m-seg, YOLOv8l-seg, YOLOv8x-seg
- Classification: YOLOv8n-cls, YOLOv8s-cls, YOLOv8m-cls, YOLOv8l-cls, YOLOv8x-cls
-These models vary in size and complexity, offering different trade-offs between speed and accuracy. Explore the full range of [pretrained models](https://docs.ultralytics.com/models/yolov8/) to find the best fit for your project.
+These models vary in size and complexity, offering different trade-offs between speed and [accuracy](https://www.ultralytics.com/glossary/accuracy). Explore the full range of [pretrained models](https://docs.ultralytics.com/models/yolov8/) to find the best fit for your project.
### How do I perform inference using a trained Ultralytics model?
@@ -113,7 +113,7 @@ Absolutely! Ultralytics models are designed for versatile deployment across vari
- Edge devices: Optimize inference on devices like NVIDIA Jetson or Intel Neural Compute Stick using TensorRT, ONNX, or OpenVINO.
- Mobile: Deploy on Android or iOS devices by converting models to TFLite or Core ML.
-- Cloud: Leverage frameworks like TensorFlow Serving or PyTorch Serve for scalable cloud deployments.
+- Cloud: Leverage frameworks like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Serving or PyTorch Serve for scalable cloud deployments.
- Web: Implement in-browser inference using ONNX.js or TensorFlow.js.
Ultralytics provides export functions to convert models to various formats for deployment. Explore the wide range of [deployment options](https://docs.ultralytics.com/guides/model-deployment-options/) to find the best solution for your use case.
@@ -124,7 +124,7 @@ Key distinctions include:
- Architecture: YOLOv8 features an improved backbone and head design for enhanced performance.
- Performance: YOLOv8 generally offers superior accuracy and speed compared to YOLOv5.
-- Tasks: YOLOv8 natively supports object detection, instance segmentation, and classification in a unified framework.
+- Tasks: YOLOv8 natively supports [object detection](https://www.ultralytics.com/glossary/object-detection), instance segmentation, and classification in a unified framework.
- Codebase: YOLOv8 is implemented with a more modular and extensible architecture, facilitating easier customization and extension.
- Training: YOLOv8 incorporates advanced training techniques like multi-dataset training and hyperparameter evolution for improved results.
@@ -174,9 +174,9 @@ Explore the [YOLO models page](https://docs.ultralytics.com/models/yolov8/) for
Enhancing your YOLO model's performance can be achieved through several techniques:
-1. Hyperparameter Tuning: Experiment with different hyperparameters using the [Hyperparameter Tuning Guide](https://docs.ultralytics.com/guides/hyperparameter-tuning/) to optimize model performance.
-2. Data Augmentation: Implement techniques like flip, scale, rotate, and color adjustments to enhance your training dataset and improve model generalization.
-3. Transfer Learning: Leverage pre-trained models and fine-tune them on your specific dataset using the [Train YOLOv8](https://docs.ultralytics.com/modes/train/) guide.
+1. [Hyperparameter Tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning): Experiment with different hyperparameters using the [Hyperparameter Tuning Guide](https://docs.ultralytics.com/guides/hyperparameter-tuning/) to optimize model performance.
+2. [Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation): Implement techniques like flip, scale, rotate, and color adjustments to enhance your training dataset and improve model generalization.
+3. [Transfer Learning](https://www.ultralytics.com/glossary/transfer-learning): Leverage pre-trained models and fine-tune them on your specific dataset using the [Train YOLOv8](https://docs.ultralytics.com/modes/train/) guide.
4. Export to Efficient Formats: Convert your model to optimized formats like TensorRT or ONNX for faster inference using the [Export guide](../modes/export.md).
5. Benchmarking: Utilize the [Benchmark Mode](https://docs.ultralytics.com/modes/benchmark/) to measure and improve inference speed and accuracy systematically.
diff --git a/docs/en/help/contributing.md b/docs/en/help/contributing.md
index 4078a6ce30..1dad4f5314 100644
--- a/docs/en/help/contributing.md
+++ b/docs/en/help/contributing.md
@@ -135,7 +135,7 @@ We encourage all contributors to familiarize themselves with the terms of the AG
Thank you for your interest in contributing to [Ultralytics](https://www.ultralytics.com/) [open-source](https://github.com/ultralytics) YOLO projects. Your participation is essential in shaping the future of our software and building a vibrant community of innovation and collaboration. Whether you're enhancing code, reporting bugs, or suggesting new features, your contributions are invaluable.
-We're excited to see your ideas come to life and appreciate your commitment to advancing object detection technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
+We're excited to see your ideas come to life and appreciate your commitment to advancing [object detection](https://www.ultralytics.com/glossary/object-detection) technology. Together, let's continue to grow and innovate in this exciting open-source journey. Happy coding! 🚀🌟
## FAQ
diff --git a/docs/en/help/index.md b/docs/en/help/index.md
index 9d9aa851b9..e8f2eecd7a 100644
--- a/docs/en/help/index.md
+++ b/docs/en/help/index.md
@@ -20,9 +20,9 @@ We encourage you to review these resources for a seamless and productive experie
## FAQ
-### What is Ultralytics YOLO and how does it benefit my machine learning projects?
+### What is Ultralytics YOLO and how does it benefit my [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) projects?
-Ultralytics YOLO (You Only Look Once) is a state-of-the-art, real-time object detection model. Its latest version, YOLOv8, enhances speed, accuracy, and versatility, making it ideal for a wide range of applications, from real-time video analytics to advanced machine learning research. YOLO's efficiency in detecting objects in images and videos has made it the go-to solution for businesses and researchers looking to integrate robust computer vision capabilities into their projects.
+Ultralytics YOLO (You Only Look Once) is a state-of-the-art, real-time [object detection](https://www.ultralytics.com/glossary/object-detection) model. Its latest version, YOLOv8, enhances speed, [accuracy](https://www.ultralytics.com/glossary/accuracy), and versatility, making it ideal for a wide range of applications, from real-time video analytics to advanced machine learning research. YOLO's efficiency in detecting objects in images and videos has made it the go-to solution for businesses and researchers looking to integrate robust [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) capabilities into their projects.
For more details on YOLOv8, visit the [YOLOv8 documentation](../tasks/detect.md).
@@ -32,7 +32,7 @@ Contributing to Ultralytics YOLO repositories is straightforward. Start by revie
### Why should I use Ultralytics HUB for my machine learning projects?
-Ultralytics HUB offers a seamless, no-code solution for managing your machine learning projects. It enables you to generate, train, and deploy AI models like YOLOv8 effortlessly. Unique features include cloud training, real-time tracking, and intuitive dataset management. Ultralytics HUB simplifies the entire workflow, from data processing to model deployment, making it an indispensable tool for both beginners and advanced users.
+Ultralytics HUB offers a seamless, no-code solution for managing your machine learning projects. It enables you to generate, train, and deploy AI models like YOLOv8 effortlessly. Unique features include cloud training, real-time tracking, and intuitive dataset management. Ultralytics HUB simplifies the entire workflow, from data processing to [model deployment](https://www.ultralytics.com/glossary/model-deployment), making it an indispensable tool for both beginners and advanced users.
To get started, visit [Ultralytics HUB Quickstart](../hub/quickstart.md).
@@ -42,7 +42,7 @@ Continuous Integration (CI) in Ultralytics involves automated processes that ens
Learn more in the [Continuous Integration (CI) Guide](../help/CI.md).
-### How is data privacy handled by Ultralytics?
+### How is [data privacy](https://www.ultralytics.com/glossary/data-privacy) handled by Ultralytics?
Ultralytics takes data privacy seriously. Our [Privacy Policy](../help/privacy.md) outlines how we collect and use anonymized data to improve the YOLO package while prioritizing user privacy and control. We adhere to strict data protection regulations to ensure your information is secure at all times.
diff --git a/docs/en/help/privacy.md b/docs/en/help/privacy.md
index 3683b1aea5..567a72aea5 100644
--- a/docs/en/help/privacy.md
+++ b/docs/en/help/privacy.md
@@ -19,7 +19,7 @@ keywords: Ultralytics, data collection, YOLO, Python package, Google Analytics,
- **System Information**: We collect general non-identifiable information about your computing environment to ensure our package performs well across various systems.
- **Performance Data**: Understanding the performance of our models during training, validation, and inference helps us in identifying optimization opportunities.
-For more information about Google Analytics and data privacy, visit [Google Analytics Privacy](https://support.google.com/analytics/answer/6004245).
+For more information about Google Analytics and [data privacy](https://www.ultralytics.com/glossary/data-privacy), visit [Google Analytics Privacy](https://support.google.com/analytics/answer/6004245).
### How We Use This Data
diff --git a/docs/en/hub/app/android.md b/docs/en/hub/app/android.md
index 0f3f0b820f..bca298fa9d 100644
--- a/docs/en/hub/app/android.md
+++ b/docs/en/hub/app/android.md
@@ -4,7 +4,7 @@ description: Experience real-time object detection on Android with Ultralytics.
keywords: Ultralytics, Android app, real-time object detection, YOLO models, TensorFlow Lite, FP16 quantization, INT8 quantization, hardware delegates, mobile AI, download app
---
-# Ultralytics Android App: Real-time Object Detection with YOLO Models
+# Ultralytics Android App: Real-time [Object Detection](https://www.ultralytics.com/glossary/object-detection) with YOLO Models
@@ -29,7 +29,7 @@ keywords: Ultralytics, Android app, real-time object detection, YOLO models, Ten
-The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
+The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
@@ -44,7 +44,7 @@ The Ultralytics Android App is a powerful tool that allows you to run YOLO model
## Quantization and Acceleration
-To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
+To achieve real-time performance on your Android device, YOLO models are quantized to either FP16 or INT8 [precision](https://www.ultralytics.com/glossary/precision). Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's [accuracy](https://www.ultralytics.com/glossary/accuracy).
### FP16 Quantization
@@ -52,7 +52,7 @@ FP16 (or half-precision) quantization converts the model's 32-bit floating-point
### INT8 Quantization
-INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in mean average precision (mAP) due to the lower numerical precision.
+INT8 (or 8-bit integer) quantization further reduces the model's size and computation requirements by converting its 32-bit floating-point numbers to 8-bit integers. This quantization method can result in a significant speedup, but it may lead to a slight reduction in [mean average precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP) due to the lower numerical precision.
!!! tip "mAP Reduction in INT8 Models"
@@ -65,7 +65,7 @@ Different delegates are available on Android devices to accelerate model inferen
1. **CPU**: The default option, with reasonable performance on most devices.
2. **GPU**: Utilizes the device's GPU for faster inference. It can provide a significant performance boost on devices with powerful GPUs.
3. **Hexagon**: Leverages Qualcomm's Hexagon DSP for faster and more efficient processing. This option is available on devices with Qualcomm Snapdragon processors.
-4. **NNAPI**: The Android Neural Networks API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).
+4. **NNAPI**: The Android [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn) API (NNAPI) serves as an abstraction layer for running ML models on Android devices. NNAPI can utilize various hardware accelerators, such as CPU, GPU, and dedicated AI chips (e.g., Google's Edge TPU, or the Pixel Neural Core).
Here's a table showing the primary vendors, their product lines, popular devices, and supported delegates:
diff --git a/docs/en/hub/app/index.md b/docs/en/hub/app/index.md
index 9266a0bd4d..e812d68678 100644
--- a/docs/en/hub/app/index.md
+++ b/docs/en/hub/app/index.md
@@ -31,11 +31,11 @@ keywords: Ultralytics HUB, YOLO models, mobile app, iOS, Android, hardware accel
-Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and Neural Network API (NNAPI) delegates to achieve impressive performance on your mobile device.
+Welcome to the Ultralytics HUB App! We are excited to introduce this powerful mobile app that allows you to run YOLOv5 and YOLOv8 models directly on your [iOS](https://apps.apple.com/xk/app/ultralytics/id1583935240) and [Android](https://play.google.com/store/apps/details?id=com.ultralytics.ultralytics_app) devices. With the HUB App, you can utilize hardware acceleration features like Apple's Neural Engine (ANE) or Android GPU and [Neural Network](https://www.ultralytics.com/glossary/neural-network-nn) API (NNAPI) delegates to achieve impressive performance on your mobile device.
## Features
-- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time object detection and image recognition tasks.
+- **Run YOLOv5 and YOLOv8 models**: Experience the power of YOLO models on your mobile device for real-time [object detection](https://www.ultralytics.com/glossary/object-detection) and [image recognition](https://www.ultralytics.com/glossary/image-recognition) tasks.
- **Hardware Acceleration**: Benefit from Apple ANE on iOS devices or Android GPU and NNAPI delegates for optimized performance.
- **Custom Model Training**: Train custom models with the Ultralytics HUB platform and preview them live using the HUB App.
- **Mobile Compatibility**: The HUB App supports both iOS and Android devices, bringing the power of YOLO models to a wide range of users.
diff --git a/docs/en/hub/app/ios.md b/docs/en/hub/app/ios.md
index 5468633f5d..be896fe80b 100644
--- a/docs/en/hub/app/ios.md
+++ b/docs/en/hub/app/ios.md
@@ -4,7 +4,7 @@ description: Discover the Ultralytics iOS App for running YOLO models on your iP
keywords: Ultralytics, iOS App, YOLO models, real-time object detection, Apple Neural Engine, Core ML, FP16 quantization, INT8 quantization, machine learning
---
-# Ultralytics iOS App: Real-time Object Detection with YOLO Models
+# Ultralytics iOS App: Real-time [Object Detection](https://www.ultralytics.com/glossary/object-detection) with YOLO Models
@@ -44,7 +44,7 @@ The Ultralytics iOS App is a powerful tool that allows you to run YOLO models di
## Quantization and Acceleration
-To achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 precision. Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's accuracy.
+To achieve real-time performance on your iOS device, YOLO models are quantized to either FP16 or INT8 [precision](https://www.ultralytics.com/glossary/precision). Quantization is a process that reduces the numerical precision of the model's weights and biases, thus reducing the model's size and the amount of computation required. This results in faster inference times without significantly affecting the model's [accuracy](https://www.ultralytics.com/glossary/accuracy).
### FP16 Quantization
@@ -56,7 +56,7 @@ INT8 (or 8-bit integer) quantization further reduces the model's size and comput
## Apple Neural Engine
-The Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate machine learning tasks, particularly for neural networks, allowing for faster and more efficient execution of your YOLO models.
+The Apple Neural Engine (ANE) is a dedicated hardware component integrated into Apple's A-series and M-series chips. It's designed to accelerate [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) tasks, particularly for [neural networks](https://www.ultralytics.com/glossary/neural-network-nn), allowing for faster and more efficient execution of your YOLO models.
By combining quantized YOLO models with the Apple Neural Engine, the Ultralytics iOS App achieves real-time object detection on your iOS device without compromising on accuracy or performance.
diff --git a/docs/en/hub/cloud-training.md b/docs/en/hub/cloud-training.md
index 557e2847d8..f030367311 100644
--- a/docs/en/hub/cloud-training.md
+++ b/docs/en/hub/cloud-training.md
@@ -44,7 +44,7 @@ Most of the times, you will use the Epochs training. The number of epochs can be
!!! note
- When using the Epochs training, the [account balance](./pro.md#account-balance) is deducted after every epoch.
+ When using the Epochs training, the [account balance](./pro.md#account-balance) is deducted after every [epoch](https://www.ultralytics.com/glossary/epoch).
Also, after every epoch, we check if you have enough [account balance](./pro.md#account-balance) for the next epoch. In case you don't have enough [account balance](./pro.md#account-balance) for the next epoch, we will stop the training session, allowing you to resume training your model from the last checkpoint saved.
diff --git a/docs/en/hub/index.md b/docs/en/hub/index.md
index 77b98b61ce..24dbdd3f57 100644
--- a/docs/en/hub/index.md
+++ b/docs/en/hub/index.md
@@ -49,7 +49,7 @@ We hope that the resources here will help you get the most out of HUB. Please br
## Introduction
-[Ultralytics HUB](https://www.ultralytics.com/hub) is designed to be user-friendly and intuitive, allowing users to quickly upload their datasets and train new YOLO models. It also offers a range of pre-trained models to choose from, making it extremely easy for users to get started. Once a model is trained, it can be effortlessly previewed in the [Ultralytics HUB App](app/index.md) before being deployed for real-time classification, object detection, and instance segmentation tasks.
+[Ultralytics HUB](https://www.ultralytics.com/hub) is designed to be user-friendly and intuitive, allowing users to quickly upload their datasets and train new YOLO models. It also offers a range of pre-trained models to choose from, making it extremely easy for users to get started. Once a model is trained, it can be effortlessly previewed in the [Ultralytics HUB App](app/index.md) before being deployed for real-time classification, [object detection](https://www.ultralytics.com/glossary/object-detection), and [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) tasks.
## [Detection](detect.md)
-Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing bounding boxes around them. The detected objects are classified into different categories based on their features. YOLOv8 can detect multiple objects in a single image or video frame with high accuracy and speed.
+Detection is the primary task supported by YOLOv8. It involves detecting objects in an image or video frame and drawing bounding boxes around them. The detected objects are classified into different categories based on their features. YOLOv8 can detect multiple objects in a single image or video frame with high [accuracy](https://www.ultralytics.com/glossary/accuracy) and speed.
[Detection Examples](detect.md){ .md-button }
## [Segmentation](segment.md)
-Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each region is assigned a label based on its content. This task is useful in applications such as image segmentation and medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
+Segmentation is a task that involves segmenting an image into different regions based on the content of the image. Each region is assigned a label based on its content. This task is useful in applications such as [image segmentation](https://www.ultralytics.com/glossary/image-segmentation) and medical imaging. YOLOv8 uses a variant of the U-Net architecture to perform segmentation.
[Segmentation Examples](segment.md){ .md-button }
@@ -114,7 +114,7 @@ For more details and implementation tips, visit our [pose estimation examples](p
### Why should I choose Ultralytics YOLOv8 for oriented object detection (OBB)?
-Oriented Object Detection (OBB) with YOLOv8 provides enhanced precision by detecting objects with an additional angle parameter. This feature is beneficial for applications requiring accurate localization of rotated objects, such as aerial imagery analysis and warehouse automation.
+Oriented Object Detection (OBB) with YOLOv8 provides enhanced [precision](https://www.ultralytics.com/glossary/precision) by detecting objects with an additional angle parameter. This feature is beneficial for applications requiring accurate localization of rotated objects, such as aerial imagery analysis and warehouse automation.
- **Increased Precision:** The angle component reduces false positives for rotated objects.
- **Versatile Applications:** Useful for tasks in geospatial analysis, robotics, etc.
diff --git a/docs/en/tasks/obb.md b/docs/en/tasks/obb.md
index 186ffbb078..9175d82786 100644
--- a/docs/en/tasks/obb.md
+++ b/docs/en/tasks/obb.md
@@ -5,7 +5,7 @@ keywords: Oriented Bounding Boxes, OBB, Object Detection, YOLOv8, Ultralytics, D
model_name: yolov8n-obb
---
-# Oriented Bounding Boxes Object Detection
+# Oriented Bounding Boxes [Object Detection](https://www.ultralytics.com/glossary/object-detection)
@@ -55,7 +55,7 @@ YOLOv8 pretrained OBB models are shown here, which are pretrained on the [DOTAv1
## Train
-Train YOLOv8n-obb on the `dota8.yaml` dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
+Train YOLOv8n-obb on the `dota8.yaml` dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
@@ -103,7 +103,7 @@ OBB dataset format can be found in detail in the [Dataset Guide](../datasets/obb
## Val
-Validate trained YOLOv8n-obb model accuracy on the DOTA8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n-obb model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the DOTA8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
diff --git a/docs/en/tasks/pose.md b/docs/en/tasks/pose.md
index ead809d418..ca0d5feca6 100644
--- a/docs/en/tasks/pose.md
+++ b/docs/en/tasks/pose.md
@@ -117,7 +117,7 @@ YOLO pose dataset format can be found in detail in the [Dataset Guide](../datase
## Val
-Validate trained YOLOv8n-pose model accuracy on the COCO128-pose dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n-pose model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO128-pose dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
diff --git a/docs/en/tasks/segment.md b/docs/en/tasks/segment.md
index e1c43eea0c..73398d1814 100644
--- a/docs/en/tasks/segment.md
+++ b/docs/en/tasks/segment.md
@@ -9,7 +9,7 @@ model_name: yolov8n-seg
-Instance segmentation goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
+[Instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
The output of an instance segmentation model is a set of masks or contours that outline each object in the image, along with class labels and confidence scores for each object. Instance segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
@@ -47,7 +47,7 @@ YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models
## Train
-Train YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
+Train YOLOv8n-seg on the COCO128-seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
@@ -84,7 +84,7 @@ YOLO segmentation dataset format can be found in detail in the [Dataset Guide](.
## Val
-Validate trained YOLOv8n-seg model accuracy on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n-seg model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
@@ -204,7 +204,7 @@ To train a YOLOv8 segmentation model on a custom dataset, you first need to prep
Check the [Configuration](../usage/cfg.md) page for more available arguments.
-### What is the difference between object detection and instance segmentation in YOLOv8?
+### What is the difference between [object detection](https://www.ultralytics.com/glossary/object-detection) and instance segmentation in YOLOv8?
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, whereas instance segmentation not only identifies the bounding boxes but also delineates the exact shape of each object. YOLOv8 instance segmentation models provide masks or contours that outline each detected object, which is particularly useful for tasks where knowing the precise shape of objects is important, such as medical imaging or autonomous driving.
@@ -238,7 +238,7 @@ Loading and validating a pretrained YOLOv8 segmentation model is straightforward
yolo segment val model=yolov8n-seg.pt
```
-These steps will provide you with validation metrics like Mean Average Precision (mAP), crucial for assessing model performance.
+These steps will provide you with validation metrics like [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP), crucial for assessing model performance.
### How can I export a YOLOv8 segmentation model to ONNX format?
diff --git a/docs/en/usage/callbacks.md b/docs/en/usage/callbacks.md
index 083b65879f..2886f8f512 100644
--- a/docs/en/usage/callbacks.md
+++ b/docs/en/usage/callbacks.md
@@ -57,22 +57,22 @@ Here are all supported callbacks. See callbacks [source code](https://github.com
### Trainer Callbacks
-| Callback | Description |
-| --------------------------- | ------------------------------------------------------- |
-| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
-| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
-| `on_train_start` | Triggered when the training starts |
-| `on_train_epoch_start` | Triggered at the start of each training epoch |
-| `on_train_batch_start` | Triggered at the start of each training batch |
-| `optimizer_step` | Triggered during the optimizer step |
-| `on_before_zero_grad` | Triggered before gradients are zeroed |
-| `on_train_batch_end` | Triggered at the end of each training batch |
-| `on_train_epoch_end` | Triggered at the end of each training epoch |
-| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
-| `on_model_save` | Triggered when the model is saved |
-| `on_train_end` | Triggered when the training process ends |
-| `on_params_update` | Triggered when model parameters are updated |
-| `teardown` | Triggered when the training process is being cleaned up |
+| Callback | Description |
+| --------------------------- | ------------------------------------------------------------------------------------------- |
+| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
+| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
+| `on_train_start` | Triggered when the training starts |
+| `on_train_epoch_start` | Triggered at the start of each training [epoch](https://www.ultralytics.com/glossary/epoch) |
+| `on_train_batch_start` | Triggered at the start of each training batch |
+| `optimizer_step` | Triggered during the optimizer step |
+| `on_before_zero_grad` | Triggered before gradients are zeroed |
+| `on_train_batch_end` | Triggered at the end of each training batch |
+| `on_train_epoch_end` | Triggered at the end of each training epoch |
+| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
+| `on_model_save` | Triggered when the model is saved |
+| `on_train_end` | Triggered when the training process ends |
+| `on_params_update` | Triggered when model parameters are updated |
+| `teardown` | Triggered when the training process is being cleaned up |
### Validator Callbacks
@@ -199,7 +199,7 @@ For more comprehensive usage, refer to the [Prediction Guide](../modes/predict.m
Ultralytics YOLO supports various practical implementations of callbacks to enhance and customize different phases like training, validation, and prediction. Some practical examples include:
1. **Logging Custom Metrics**: Log additional metrics at different stages, such as the end of training or validation epochs.
-2. **Data Augmentation**: Implement custom data transformations or augmentations during prediction or training batches.
+2. **[Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation)**: Implement custom data transformations or augmentations during prediction or training batches.
3. **Intermediate Results**: Save intermediate results such as predictions or frames for further analysis or visualization.
Example: Combining frames with prediction results during prediction using `on_predict_batch_end`:
diff --git a/docs/en/usage/cfg.md b/docs/en/usage/cfg.md
index 2d0ce1dd94..aecc5fc646 100644
--- a/docs/en/usage/cfg.md
+++ b/docs/en/usage/cfg.md
@@ -4,7 +4,7 @@ description: Optimize your YOLO model's performance with the right settings and
keywords: YOLO, hyperparameters, configuration, training, validation, prediction, model settings, Ultralytics, performance optimization, machine learning
---
-YOLO settings and hyperparameters play a critical role in the model's performance, speed, and accuracy. These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
+YOLO settings and hyperparameters play a critical role in the model's performance, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy). These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
@@ -57,9 +57,9 @@ YOLO models can be used for a variety of tasks, including detection, segmentatio
- **Pose**: For identifying objects and estimating their keypoints in an image or video.
- **OBB**: Oriented (i.e. rotated) bounding boxes suitable for satellite or medical imagery.
-| Argument | Default | Description |
-| -------- | ---------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `task` | `'detect'` | Specifies the YOLO task to be executed. Options include `detect` for object detection, `segment` for segmentation, `classify` for classification, `pose` for pose estimation and `OBB` for oriented bounding boxes. Each task is tailored to specific types of output and problems within image and video analysis. |
+| Argument | Default | Description |
+| -------- | ---------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `task` | `'detect'` | Specifies the YOLO task to be executed. Options include `detect` for [object detection](https://www.ultralytics.com/glossary/object-detection), `segment` for segmentation, `classify` for classification, `pose` for pose estimation and `OBB` for oriented bounding boxes. Each task is tailored to specific types of output and problems within image and video analysis. |
[Tasks Guide](../tasks/index.md){ .md-button }
@@ -82,7 +82,7 @@ YOLO models can be used in different modes depending on the specific problem you
## Train Settings
-The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, learning rate, momentum, and weight decay. Additionally, the choice of optimizer, loss function, and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
+The training settings for YOLO models encompass various hyperparameters and configurations used during the training process. These settings influence the model's performance, speed, and accuracy. Key training settings include batch size, [learning rate](https://www.ultralytics.com/glossary/learning-rate), momentum, and weight decay. Additionally, the choice of optimizer, [loss function](https://www.ultralytics.com/glossary/loss-function), and training dataset composition can impact the training process. Careful tuning and experimentation with these settings are crucial for optimizing performance.
{% include "macros/train-args.md" %}
@@ -90,7 +90,7 @@ The training settings for YOLO models encompass various hyperparameters and conf
The `batch` argument can be configured in three ways:
- - **Fixed Batch Size**: Set an integer value (e.g., `batch=16`), specifying the number of images per batch directly.
+ - **Fixed [Batch Size](https://www.ultralytics.com/glossary/batch-size)**: Set an integer value (e.g., `batch=16`), specifying the number of images per batch directly.
- **Auto Mode (60% GPU Memory)**: Use `batch=-1` to automatically adjust batch size for approximately 60% CUDA memory utilization.
- **Auto Mode with Utilization Fraction**: Set a fraction value (e.g., `batch=0.70`) to adjust batch size based on the specified fraction of GPU memory usage.
@@ -116,7 +116,7 @@ The val (validation) settings for YOLO models involve various hyperparameters an
{% include "macros/validation-args.md" %}
-Careful tuning and experimentation with these settings are crucial to ensure optimal performance on the validation dataset and detect and prevent overfitting.
+Careful tuning and experimentation with these settings are crucial to ensure optimal performance on the validation dataset and detect and prevent [overfitting](https://www.ultralytics.com/glossary/overfitting).
[Val Guide](../modes/val.md){ .md-button }
@@ -132,7 +132,7 @@ It is crucial to thoughtfully configure these settings to ensure the exported mo
## Augmentation Settings
-Augmentation techniques are essential for improving the robustness and performance of YOLO models by introducing variability into the training data, helping the model generalize better to unseen data. The following table outlines the purpose and effect of each augmentation argument:
+Augmentation techniques are essential for improving the robustness and performance of YOLO models by introducing variability into the [training data](https://www.ultralytics.com/glossary/training-data), helping the model generalize better to unseen data. The following table outlines the purpose and effect of each augmentation argument:
{% include "macros/augmentation-args.md" %}
@@ -149,19 +149,19 @@ Logging, checkpoints, plotting, and file management are important considerations
Effective logging, checkpointing, plotting, and file management can help you keep track of the model's progress and make it easier to debug and optimize the training process.
-| Argument | Default | Description |
-| ---------- | -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
-| `project` | `'runs'` | Specifies the root directory for saving training runs. Each run will be saved in a separate subdirectory within this directory. |
-| `name` | `'exp'` | Defines the name of the experiment. If not specified, YOLO automatically increments this name for each run, e.g., `exp`, `exp2`, etc., to avoid overwriting previous experiments. |
-| `exist_ok` | `False` | Determines whether to overwrite an existing experiment directory if one with the same name already exists. Setting this to `True` allows overwriting, while `False` prevents it. |
-| `plots` | `False` | Controls the generation and saving of training and validation plots. Set to `True` to create plots such as loss curves, precision-recall curves, and sample predictions. Useful for visually tracking model performance over time. |
-| `save` | `False` | Enables the saving of training checkpoints and final model weights. Set to `True` to periodically save model states, allowing training to be resumed from these checkpoints or models to be deployed. |
+| Argument | Default | Description |
+| ---------- | -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `project` | `'runs'` | Specifies the root directory for saving training runs. Each run will be saved in a separate subdirectory within this directory. |
+| `name` | `'exp'` | Defines the name of the experiment. If not specified, YOLO automatically increments this name for each run, e.g., `exp`, `exp2`, etc., to avoid overwriting previous experiments. |
+| `exist_ok` | `False` | Determines whether to overwrite an existing experiment directory if one with the same name already exists. Setting this to `True` allows overwriting, while `False` prevents it. |
+| `plots` | `False` | Controls the generation and saving of training and validation plots. Set to `True` to create plots such as loss curves, [precision](https://www.ultralytics.com/glossary/precision)-[recall](https://www.ultralytics.com/glossary/recall) curves, and sample predictions. Useful for visually tracking model performance over time. |
+| `save` | `False` | Enables the saving of training checkpoints and final model weights. Set to `True` to periodically save model states, allowing training to be resumed from these checkpoints or models to be deployed. |
## FAQ
### How do I improve the performance of my YOLO model during training?
-Improving YOLO model performance involves tuning hyperparameters like batch size, learning rate, momentum, and weight decay. Adjusting augmentation settings, selecting the right optimizer, and employing techniques like early stopping or mixed precision can also help. For detailed guidance on training settings, refer to the [Train Guide](../modes/train.md).
+Improving YOLO model performance involves tuning hyperparameters like batch size, learning rate, momentum, and weight decay. Adjusting augmentation settings, selecting the right optimizer, and employing techniques like early stopping or [mixed precision](https://www.ultralytics.com/glossary/mixed-precision) can also help. For detailed guidance on training settings, refer to the [Train Guide](../modes/train.md).
### What are the key hyperparameters to consider for YOLO model accuracy?
diff --git a/docs/en/usage/cli.md b/docs/en/usage/cli.md
index 3e6c4b37a5..d1d7c8de48 100644
--- a/docs/en/usage/cli.md
+++ b/docs/en/usage/cli.md
@@ -35,7 +35,7 @@ The YOLO command line interface (CLI) allows for simple single-line commands wit
=== "Train"
- Train a detection model for 10 epochs with an initial learning_rate of 0.01
+ Train a detection model for 10 [epochs](https://www.ultralytics.com/glossary/epoch) with an initial learning_rate of 0.01
```bash
yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
```
@@ -109,7 +109,7 @@ Train YOLOv8n on the COCO8 dataset for 100 epochs at image size 640. For a full
## Val
-Validate trained YOLOv8n model accuracy on the COCO8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO8 dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
@@ -221,7 +221,7 @@ This will create `default_copy.yaml`, which you can then pass as `cfg=default_co
### How do I use the Ultralytics YOLOv8 command line interface (CLI) for model training?
-To train a YOLOv8 model using the CLI, you can execute a simple one-line command in the terminal. For example, to train a detection model for 10 epochs with a learning rate of 0.01, you would run:
+To train a YOLOv8 model using the CLI, you can execute a simple one-line command in the terminal. For example, to train a detection model for 10 epochs with a [learning rate](https://www.ultralytics.com/glossary/learning-rate) of 0.01, you would run:
```bash
yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
@@ -241,7 +241,7 @@ Each task can be customized with various arguments. For detailed syntax and exam
### How can I validate the accuracy of a trained YOLOv8 model using the CLI?
-To validate a YOLOv8 model's accuracy, use the `val` mode. For example, to validate a pretrained detection model with a batch size of 1 and image size of 640, run:
+To validate a YOLOv8 model's accuracy, use the `val` mode. For example, to validate a pretrained detection model with a [batch size](https://www.ultralytics.com/glossary/batch-size) of 1 and image size of 640, run:
```bash
yolo val model=yolov8n.pt data=coco8.yaml batch=1 imgsz=640
diff --git a/docs/en/usage/engine.md b/docs/en/usage/engine.md
index 7e43e08e26..dc44047ff7 100644
--- a/docs/en/usage/engine.md
+++ b/docs/en/usage/engine.md
@@ -128,7 +128,7 @@ For more details on the customization and source code, see the [`BaseTrainer` Re
### How can I add a callback to the Ultralytics YOLOv8 DetectionTrainer?
-You can add callbacks to monitor and modify the training process in Ultralytics YOLOv8 `DetectionTrainer`. For instance, here's how you can add a callback to log model weights after every training epoch:
+You can add callbacks to monitor and modify the training process in Ultralytics YOLOv8 `DetectionTrainer`. For instance, here's how you can add a callback to log model weights after every training [epoch](https://www.ultralytics.com/glossary/epoch):
```python
from ultralytics.models.yolo.detect import DetectionTrainer
@@ -153,8 +153,8 @@ For further details on callback events and entry points, refer to our [Callbacks
Ultralytics YOLOv8 offers a high-level abstraction on powerful engine executors, making it ideal for rapid development and customization. Key benefits include:
- **Ease of Use**: Both command-line and Python interfaces simplify complex tasks.
-- **Performance**: Optimized for real-time object detection and various vision AI applications.
-- **Customization**: Easily extendable for custom models, loss functions, and dataloaders.
+- **Performance**: Optimized for real-time [object detection](https://www.ultralytics.com/glossary/object-detection) and various vision AI applications.
+- **Customization**: Easily extendable for custom models, [loss functions](https://www.ultralytics.com/glossary/loss-function), and dataloaders.
Learn more about YOLOv8's capabilities by visiting [Ultralytics YOLO](https://www.ultralytics.com/yolo).
diff --git a/docs/en/usage/python.md b/docs/en/usage/python.md
index 66b2e6c61d..5236af0a1d 100644
--- a/docs/en/usage/python.md
+++ b/docs/en/usage/python.md
@@ -6,7 +6,7 @@ keywords: YOLOv8, Python, object detection, segmentation, classification, machin
# Python Usage
-Welcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into your Python projects for object detection, segmentation, and classification. Here, you'll learn how to load and use pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable resource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced object detection capabilities. Let's get started!
+Welcome to the YOLOv8 Python Usage documentation! This guide is designed to help you seamlessly integrate YOLOv8 into your Python projects for [object detection](https://www.ultralytics.com/glossary/object-detection), segmentation, and classification. Here, you'll learn how to load and use pretrained models, train new models, and perform predictions on images. The easy-to-use Python interface is a valuable resource for anyone looking to incorporate YOLOv8 into their Python projects, allowing you to quickly implement advanced object detection capabilities. Let's get started!
@@ -80,7 +80,7 @@ Train mode is used for training a YOLOv8 model on a custom dataset. In this mode
## [Val](../modes/val.md)
-Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its accuracy and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
+Val mode is used for validating a YOLOv8 model after it has been trained. In this mode, the model is evaluated on a validation set to measure its [accuracy](https://www.ultralytics.com/glossary/accuracy) and generalization performance. This mode can be used to tune the hyperparameters of the model to improve its performance.
!!! example "Val"
@@ -355,7 +355,7 @@ See more detailed examples in our [Predict Mode](../modes/predict.md) section.
### What are the different modes available in YOLOv8?
-Ultralytics YOLOv8 provides various modes to cater to different machine learning workflows. These include:
+Ultralytics YOLOv8 provides various modes to cater to different [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) workflows. These include:
- **[Train](../modes/train.md)**: Train a model using custom datasets.
- **[Val](../modes/val.md)**: Validate model performance on a validation set.
diff --git a/docs/en/usage/simple-utilities.md b/docs/en/usage/simple-utilities.md
index a5636ca635..e40a2478ee 100644
--- a/docs/en/usage/simple-utilities.md
+++ b/docs/en/usage/simple-utilities.md
@@ -31,7 +31,7 @@ The `ultralytics` package comes with a myriad of utilities that can support, enh
### Auto Labeling / Annotations
-Dataset annotation is a very resource intensive and time-consuming process. If you have a YOLO object detection model trained on a reasonable amount of data, you can use it and [SAM](../models/sam.md) to auto-annotate additional data (segmentation format).
+Dataset annotation is a very resource intensive and time-consuming process. If you have a YOLO [object detection](https://www.ultralytics.com/glossary/object-detection) model trained on a reasonable amount of data, you can use it and [SAM](../models/sam.md) to auto-annotate additional data (segmentation format).
```{ .py .annotate }
from ultralytics.data.annotator import auto_annotate
@@ -86,7 +86,7 @@ convert_coco( # (1)!
For additional information about the `convert_coco` function, [visit the reference page](../reference/data/converter.md#ultralytics.data.converter.convert_coco)
-### Get Bounding Box Dimensions
+### Get [Bounding Box](https://www.ultralytics.com/glossary/bounding-box) Dimensions
```{.py .annotate }
from ultralytics.utils.plotting import Annotator
@@ -585,7 +585,7 @@ make_divisible(7, 2)
## FAQ
-### What utilities are included in the Ultralytics package to enhance machine learning workflows?
+### What utilities are included in the Ultralytics package to enhance [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) workflows?
The Ultralytics package includes a variety of utilities designed to streamline and optimize machine learning workflows. Key utilities include [auto-annotation](../reference/data/annotator.md#ultralytics.data.annotator.auto_annotate) for labeling datasets, converting COCO to YOLO format with [convert_coco](../reference/data/converter.md#ultralytics.data.converter.convert_coco), compressing images, and dataset auto-splitting. These tools aim to reduce manual effort, ensure consistency, and enhance data processing efficiency.
diff --git a/docs/en/yolov5/environments/aws_quickstart_tutorial.md b/docs/en/yolov5/environments/aws_quickstart_tutorial.md
index ffa6a2c936..0e5daf2fe9 100644
--- a/docs/en/yolov5/environments/aws_quickstart_tutorial.md
+++ b/docs/en/yolov5/environments/aws_quickstart_tutorial.md
@@ -6,7 +6,7 @@ keywords: YOLOv5, AWS, Deep Learning, Machine Learning, AWS EC2, YOLOv5 setup, D
# YOLOv5 🚀 on AWS Deep Learning Instance: Your Complete Guide
-Setting up a high-performance deep learning environment can be daunting for newcomers, but fear not! 🛠️ With this guide, we'll walk you through the process of getting YOLOv5 up and running on an AWS Deep Learning instance. By leveraging the power of Amazon Web Services (AWS), even those new to machine learning can get started quickly and cost-effectively. The AWS platform's scalability is perfect for both experimentation and production deployment.
+Setting up a high-performance deep learning environment can be daunting for newcomers, but fear not! 🛠️ With this guide, we'll walk you through the process of getting YOLOv5 up and running on an AWS Deep Learning instance. By leveraging the power of Amazon Web Services (AWS), even those new to [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) can get started quickly and cost-effectively. The AWS platform's scalability is perfect for both experimentation and production deployment.
Other quickstart options for YOLOv5 include our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) , [GCP Deep Learning VM](./google_cloud_quickstart_tutorial.md), and our Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) .
@@ -24,7 +24,7 @@ In the EC2 dashboard, you'll find the **Launch Instance** button which is your g
### Selecting the Right Amazon Machine Image (AMI)
-Here's where you choose the operating system and software stack for your instance. Type 'Deep Learning' into the search field and select the latest Ubuntu-based Deep Learning AMI, unless your needs dictate otherwise. Amazon's Deep Learning AMIs come pre-installed with popular frameworks and GPU drivers to streamline your setup process.
+Here's where you choose the operating system and software stack for your instance. Type '[Deep Learning](https://www.ultralytics.com/glossary/deep-learning-dl)' into the search field and select the latest Ubuntu-based Deep Learning AMI, unless your needs dictate otherwise. Amazon's Deep Learning AMIs come pre-installed with popular frameworks and GPU drivers to streamline your setup process.

@@ -92,4 +92,4 @@ sudo swapon /swapfile # activate swap file
free -h # verify swap memory
```
-And that's it! 🎉 You've successfully created an AWS Deep Learning instance and run YOLOv5. Whether you're just starting with object detection or scaling up for production, this setup can help you achieve your machine learning goals. Happy training, validating, and deploying! If you encounter any hiccups along the way, the robust AWS documentation and the active Ultralytics community are here to support you.
+And that's it! 🎉 You've successfully created an AWS Deep Learning instance and run YOLOv5. Whether you're just starting with [object detection](https://www.ultralytics.com/glossary/object-detection) or scaling up for production, this setup can help you achieve your machine learning goals. Happy training, validating, and deploying! If you encounter any hiccups along the way, the robust AWS documentation and the active Ultralytics community are here to support you.
diff --git a/docs/en/yolov5/environments/azureml_quickstart_tutorial.md b/docs/en/yolov5/environments/azureml_quickstart_tutorial.md
index 2fd33a861d..82a083d15e 100644
--- a/docs/en/yolov5/environments/azureml_quickstart_tutorial.md
+++ b/docs/en/yolov5/environments/azureml_quickstart_tutorial.md
@@ -61,7 +61,7 @@ Train the YOLOv5 model:
python train.py
```
-Validate the model for Precision, Recall, and mAP
+Validate the model for [Precision](https://www.ultralytics.com/glossary/precision), [Recall](https://www.ultralytics.com/glossary/recall), and mAP
```bash
python val.py --weights yolov5s.pt
diff --git a/docs/en/yolov5/environments/docker_image_quickstart_tutorial.md b/docs/en/yolov5/environments/docker_image_quickstart_tutorial.md
index 93c9f0a16a..55b92316dc 100644
--- a/docs/en/yolov5/environments/docker_image_quickstart_tutorial.md
+++ b/docs/en/yolov5/environments/docker_image_quickstart_tutorial.md
@@ -36,7 +36,7 @@ sudo docker run --ipc=host -it ultralytics/yolov5:latest
### Container with local file access:
-To run a container with access to local files (e.g., COCO training data in `/datasets`), use the `-v` flag:
+To run a container with access to local files (e.g., COCO [training data](https://www.ultralytics.com/glossary/training-data) in `/datasets`), use the `-v` flag:
```bash
sudo docker run --ipc=host -it -v "$(pwd)"/datasets:/usr/src/datasets ultralytics/yolov5:latest
diff --git a/docs/en/yolov5/environments/google_cloud_quickstart_tutorial.md b/docs/en/yolov5/environments/google_cloud_quickstart_tutorial.md
index cdd397dc17..65ad9c3d62 100644
--- a/docs/en/yolov5/environments/google_cloud_quickstart_tutorial.md
+++ b/docs/en/yolov5/environments/google_cloud_quickstart_tutorial.md
@@ -6,13 +6,13 @@ keywords: YOLOv5, Google Cloud Platform, GCP, Deep Learning VM, object detection
# Mastering YOLOv5 🚀 Deployment on Google Cloud Platform (GCP) Deep Learning Virtual Machine (VM) ⭐
-Embarking on the journey of artificial intelligence and machine learning can be exhilarating, especially when you leverage the power and flexibility of a cloud platform. Google Cloud Platform (GCP) offers robust tools tailored for machine learning enthusiasts and professionals alike. One such tool is the Deep Learning VM that is preconfigured for data science and ML tasks. In this tutorial, we will navigate through the process of setting up YOLOv5 on a GCP Deep Learning VM. Whether you're taking your first steps in ML or you're a seasoned practitioner, this guide is designed to provide you with a clear pathway to implementing object detection models powered by YOLOv5.
+Embarking on the journey of [artificial intelligence](https://www.ultralytics.com/glossary/artificial-intelligence-ai) and machine learning can be exhilarating, especially when you leverage the power and flexibility of a cloud platform. Google Cloud Platform (GCP) offers robust tools tailored for machine learning enthusiasts and professionals alike. One such tool is the Deep Learning VM that is preconfigured for data science and ML tasks. In this tutorial, we will navigate through the process of setting up YOLOv5 on a GCP Deep Learning VM. Whether you're taking your first steps in ML or you're a seasoned practitioner, this guide is designed to provide you with a clear pathway to implementing object detection models powered by YOLOv5.
🆓 Plus, if you're a fresh GCP user, you're in luck with a [$300 free credit offer](https://cloud.google.com/free/docs/free-cloud-features#free-trial) to kickstart your projects.
In addition to GCP, explore other accessible quickstart options for YOLOv5, like our [Colab Notebook](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb) for a browser-based experience, or the scalability of [Amazon AWS](./aws_quickstart_tutorial.md). Furthermore, container aficionados can utilize our official Docker image at [Docker Hub](https://hub.docker.com/r/ultralytics/yolov5) for an encapsulated environment.
-## Step 1: Create and Configure Your Deep Learning VM
+## Step 1: Create and Configure Your [Deep Learning](https://www.ultralytics.com/glossary/deep-learning-dl) VM
Let's begin by creating a virtual machine that's tuned for deep learning:
@@ -42,7 +42,7 @@ cd yolov5
pip install -r requirements.txt
```
-This setup process ensures you're working with a Python environment version 3.8.0 or newer and PyTorch 1.8 or above. Our scripts smoothly download [models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) rending from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases), making it hassle-free to start model training.
+This setup process ensures you're working with a Python environment version 3.8.0 or newer and [PyTorch](https://www.ultralytics.com/glossary/pytorch) 1.8 or above. Our scripts smoothly download [models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) rending from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases), making it hassle-free to start model training.
## Step 3: Train and Deploy Your YOLOv5 Models 🌐
@@ -62,7 +62,7 @@ python detect.py --weights yolov5s.pt --source path/to/images
python export.py --weights yolov5s.pt --include onnx coreml tflite
```
-With just a few commands, YOLOv5 allows you to train custom object detection models tailored to your specific needs or utilize pre-trained weights for quick results on a variety of tasks.
+With just a few commands, YOLOv5 allows you to train custom [object detection](https://www.ultralytics.com/glossary/object-detection) models tailored to your specific needs or utilize pre-trained weights for quick results on a variety of tasks.

@@ -80,7 +80,7 @@ free -h # confirm the memory increment
### Concluding Thoughts
-Congratulations! You are now empowered to harness the capabilities of YOLOv5 with the computational prowess of Google Cloud Platform. This combination provides scalability, efficiency, and versatility for your object detection tasks. Whether for personal projects, academic research, or industrial applications, you have taken a pivotal step into the world of AI and machine learning on the cloud.
+Congratulations! You are now empowered to harness the capabilities of YOLOv5 with the computational prowess of Google Cloud Platform. This combination provides scalability, efficiency, and versatility for your object detection tasks. Whether for personal projects, academic research, or industrial applications, you have taken a pivotal step into the world of AI and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) on the cloud.
Do remember to document your journey, share insights with the Ultralytics community, and leverage the collaborative arenas such as [GitHub discussions](https://github.com/ultralytics/yolov5/discussions) to grow further. Now, go forth and innovate with YOLOv5 and GCP! 🌟
diff --git a/docs/en/yolov5/index.md b/docs/en/yolov5/index.md
index ba4e4e3ab8..3605058463 100644
--- a/docs/en/yolov5/index.md
+++ b/docs/en/yolov5/index.md
@@ -22,11 +22,11 @@ keywords: YOLOv5, Ultralytics, object detection, computer vision, deep learning,
-Welcome to the Ultralytics' YOLOv5🚀 Documentation! YOLOv5, the fifth iteration of the revolutionary "You Only Look Once" object detection model, is designed to deliver high-speed, high-accuracy results in real-time.
+Welcome to the Ultralytics' YOLOv5🚀 Documentation! YOLOv5, the fifth iteration of the revolutionary "You Only Look Once" [object detection](https://www.ultralytics.com/glossary/object-detection) model, is designed to deliver high-speed, high-accuracy results in real-time.
-Built on PyTorch, this powerful deep learning framework has garnered immense popularity for its versatility, ease of use, and high performance. Our documentation guides you through the installation process, explains the architectural nuances of the model, showcases various use-cases, and provides a series of detailed tutorials. These resources will help you harness the full potential of YOLOv5 for your computer vision projects. Let's get started!
+Built on PyTorch, this powerful [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) framework has garnered immense popularity for its versatility, ease of use, and high performance. Our documentation guides you through the installation process, explains the architectural nuances of the model, showcases various use-cases, and provides a series of detailed tutorials. These resources will help you harness the full potential of YOLOv5 for your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) projects. Let's get started!
@@ -42,10 +42,10 @@ Here's a compilation of comprehensive tutorials that will guide you through diff
- [Test-Time Augmentation (TTA)](tutorials/test_time_augmentation.md): Explore how to use TTA to improve your model's prediction accuracy.
- [Model Ensembling](tutorials/model_ensembling.md): Learn the strategy of combining multiple models for improved performance.
- [Model Pruning/Sparsity](tutorials/model_pruning_and_sparsity.md): Understand pruning and sparsity concepts, and how to create a more efficient model.
-- [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md): Discover the process of automated hyperparameter tuning for better model performance.
-- [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md): Learn how to implement transfer learning by freezing layers in YOLOv5.
+- [Hyperparameter Evolution](tutorials/hyperparameter_evolution.md): Discover the process of automated [hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning) for better model performance.
+- [Transfer Learning with Frozen Layers](tutorials/transfer_learning_with_frozen_layers.md): Learn how to implement [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) by freezing layers in YOLOv5.
- [Architecture Summary](tutorials/architecture_description.md) 🌟 Delve into the structural details of the YOLOv5 model.
-- [Roboflow for Datasets](tutorials/roboflow_datasets_integration.md): Understand how to utilize Roboflow for dataset management, labeling, and active learning.
+- [Roboflow for Datasets](tutorials/roboflow_datasets_integration.md): Understand how to utilize Roboflow for dataset management, labeling, and [active learning](https://www.ultralytics.com/glossary/active-learning).
- [ClearML Logging](tutorials/clearml_logging_integration.md) 🌟 Learn how to integrate ClearML for efficient logging during your model training.
- [YOLOv5 with Neural Magic](tutorials/neural_magic_pruning_quantization.md) Discover how to use Neural Magic's Deepsparse to prune and quantize your YOLOv5 model.
- [Comet Logging](tutorials/comet_logging_integration.md) 🌟 NEW: Explore how to utilize Comet for improved model training logging.
@@ -95,7 +95,7 @@ We're excited to see the innovative ways you'll use YOLOv5. Dive in, experiment,
### What are the key features of Ultralytics YOLOv5?
-Ultralytics YOLOv5 is renowned for its high-speed and high-accuracy object detection capabilities. Built on PyTorch, it is versatile and user-friendly, making it suitable for various computer vision projects. Key features include real-time inference, support for multiple training tricks like Test-Time Augmentation (TTA) and Model Ensembling, and compatibility with export formats such as TFLite, ONNX, CoreML, and TensorRT. To delve deeper into how Ultralytics YOLOv5 can elevate your project, explore our [TFLite, ONNX, CoreML, TensorRT Export guide](tutorials/model_export.md).
+Ultralytics YOLOv5 is renowned for its high-speed and high-[accuracy](https://www.ultralytics.com/glossary/accuracy) object detection capabilities. Built on [PyTorch](https://www.ultralytics.com/glossary/pytorch), it is versatile and user-friendly, making it suitable for various computer vision projects. Key features include real-time inference, support for multiple training tricks like Test-Time Augmentation (TTA) and Model Ensembling, and compatibility with export formats such as TFLite, ONNX, CoreML, and TensorRT. To delve deeper into how Ultralytics YOLOv5 can elevate your project, explore our [TFLite, ONNX, CoreML, TensorRT Export guide](tutorials/model_export.md).
### How can I train a custom YOLOv5 model on my dataset?
@@ -107,7 +107,7 @@ Ultralytics YOLOv5 is preferred over models like RCNN due to its superior speed
### How can I optimize YOLOv5 model performance during training?
-Optimizing YOLOv5 model performance involves tuning various hyperparameters and incorporating techniques like data augmentation and transfer learning. Ultralytics provides comprehensive resources on hyperparameter evolution and pruning/sparsity to improve model efficiency. You can discover practical tips in our [Tips for Best Training Results guide](tutorials/tips_for_best_training_results.md), which offers actionable insights for achieving optimal performance during training.
+Optimizing YOLOv5 model performance involves tuning various hyperparameters and incorporating techniques like [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) and transfer learning. Ultralytics provides comprehensive resources on hyperparameter evolution and pruning/sparsity to improve model efficiency. You can discover practical tips in our [Tips for Best Training Results guide](tutorials/tips_for_best_training_results.md), which offers actionable insights for achieving optimal performance during training.
### What environments are supported for running YOLOv5 applications?
diff --git a/docs/en/yolov5/quickstart_tutorial.md b/docs/en/yolov5/quickstart_tutorial.md
index 582dfcbda8..e6ddb8fd38 100644
--- a/docs/en/yolov5/quickstart_tutorial.md
+++ b/docs/en/yolov5/quickstart_tutorial.md
@@ -6,7 +6,7 @@ keywords: YOLOv5, Quickstart, real-time object detection, AI, ML, PyTorch, infer
# YOLOv5 Quickstart 🚀
-Embark on your journey into the dynamic realm of real-time object detection with YOLOv5! This guide is crafted to serve as a comprehensive starting point for AI enthusiasts and professionals aiming to master YOLOv5. From initial setup to advanced training techniques, we've got you covered. By the end of this guide, you'll have the knowledge to implement YOLOv5 into your projects confidently. Let's ignite the engines and soar into YOLOv5!
+Embark on your journey into the dynamic realm of real-time [object detection](https://www.ultralytics.com/glossary/object-detection) with YOLOv5! This guide is crafted to serve as a comprehensive starting point for AI enthusiasts and professionals aiming to master YOLOv5. From initial setup to advanced training techniques, we've got you covered. By the end of this guide, you'll have the knowledge to implement YOLOv5 into your projects confidently. Let's ignite the engines and soar into YOLOv5!
## Install
@@ -18,7 +18,7 @@ cd yolov5
pip install -r requirements.txt # install dependencies
```
-## Inference with PyTorch Hub
+## Inference with [PyTorch](https://www.ultralytics.com/glossary/pytorch) Hub
Experience the simplicity of YOLOv5 [PyTorch Hub](./tutorials/pytorch_hub_model_loading.md) inference, where [models](https://github.com/ultralytics/yolov5/tree/master/models) are seamlessly downloaded from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
@@ -57,7 +57,7 @@ python detect.py --weights yolov5s.pt --source 0 #
## Training
-Replicate the YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) benchmarks with the instructions below. The necessary [models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) are pulled directly from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training YOLOv5n/s/m/l/x on a V100 GPU should typically take 1/2/4/6/8 days respectively (note that [Multi-GPU](./tutorials/multi_gpu_training.md) setups work faster). Maximize performance by using the highest possible `--batch-size` or use `--batch-size -1` for the YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092) feature. The following batch sizes are ideal for V100-16GB GPUs.
+Replicate the YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) benchmarks with the instructions below. The necessary [models](https://github.com/ultralytics/yolov5/tree/master/models) and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) are pulled directly from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training YOLOv5n/s/m/l/x on a V100 GPU should typically take 1/2/4/6/8 days respectively (note that [Multi-GPU](./tutorials/multi_gpu_training.md) setups work faster). Maximize performance by using the highest possible `--batch-size` or use `--batch-size -1` for the YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092) feature. The following [batch sizes](https://www.ultralytics.com/glossary/batch-size) are ideal for V100-16GB GPUs.
```bash
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
@@ -69,4 +69,4 @@ python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml -
-To conclude, YOLOv5 is not only a state-of-the-art tool for object detection but also a testament to the power of machine learning in transforming the way we interact with the world through visual understanding. As you progress through this guide and begin applying YOLOv5 to your projects, remember that you are at the forefront of a technological revolution, capable of achieving remarkable feats. Should you need further insights or support from fellow visionaries, you're invited to our [GitHub repository](https://github.com/ultralytics/yolov5) home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
+To conclude, YOLOv5 is not only a state-of-the-art tool for object detection but also a testament to the power of [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) in transforming the way we interact with the world through visual understanding. As you progress through this guide and begin applying YOLOv5 to your projects, remember that you are at the forefront of a technological revolution, capable of achieving remarkable feats. Should you need further insights or support from fellow visionaries, you're invited to our [GitHub repository](https://github.com/ultralytics/yolov5) home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
diff --git a/docs/en/yolov5/tutorials/architecture_description.md b/docs/en/yolov5/tutorials/architecture_description.md
index bb9ade6976..53788270ce 100644
--- a/docs/en/yolov5/tutorials/architecture_description.md
+++ b/docs/en/yolov5/tutorials/architecture_description.md
@@ -6,7 +6,7 @@ keywords: YOLOv5 architecture, object detection, Ultralytics, YOLO, model struct
# Ultralytics YOLOv5 Architecture
-YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
+YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and [image recognition](https://www.ultralytics.com/glossary/image-recognition).
## 1. Model Structure
@@ -104,9 +104,9 @@ SPPF time: 0.20780706405639648
## 2. Data Augmentation Techniques
-YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce overfitting. These techniques include:
+YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce [overfitting](https://www.ultralytics.com/glossary/overfitting). These techniques include:
-- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage object detection models to better handle various object scales and translations.
+- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage [object detection](https://www.ultralytics.com/glossary/object-detection) models to better handle various object scales and translations.

@@ -138,9 +138,9 @@ YOLOv5 applies several sophisticated training strategies to enhance the model's
- **Multiscale Training**: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
- **AutoAnchor**: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
-- **Warmup and Cosine LR Scheduler**: A method to adjust the learning rate to enhance model performance.
+- **Warmup and Cosine LR Scheduler**: A method to adjust the [learning rate](https://www.ultralytics.com/glossary/learning-rate) to enhance model performance.
- **Exponential Moving Average (EMA)**: A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
-- **Mixed Precision Training**: A method to perform operations in half-precision format, reducing memory usage and enhancing computational speed.
+- **[Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision) Training**: A method to perform operations in half-[precision](https://www.ultralytics.com/glossary/precision) format, reducing memory usage and enhancing computational speed.
- **Hyperparameter Evolution**: A strategy to automatically tune hyperparameters to achieve optimal performance.
## 4. Additional Features
@@ -153,7 +153,7 @@ The loss in YOLOv5 is computed as a combination of three individual loss compone
- **Objectness Loss (BCE Loss)**: Another Binary Cross-Entropy loss, calculates the error in detecting whether an object is present in a particular grid cell or not.
- **Location Loss (CIoU Loss)**: Complete IoU loss, measures the error in localizing the object within the grid cell.
-The overall loss function is depicted by:
+The overall [loss function](https://www.ultralytics.com/glossary/loss-function) is depicted by:

@@ -176,7 +176,7 @@ The YOLOv5 architecture makes some important changes to the box prediction strat
However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
-The revised formulas for calculating the predicted bounding box are as follows:
+The revised formulas for calculating the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) are as follows:
![bx]()
![by]()
@@ -193,7 +193,7 @@ Compare the height and width scaling ratio(relative to anchor) before and after
### 4.4 Build Targets
-The build target process in YOLOv5 is critical for training efficiency and model accuracy. It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
+The build target process in YOLOv5 is critical for training efficiency and model [accuracy](https://www.ultralytics.com/glossary/accuracy). It involves assigning ground truth boxes to the appropriate grid cells in the output map and matching them with the appropriate anchor boxes.
This process follows these steps:
diff --git a/docs/en/yolov5/tutorials/clearml_logging_integration.md b/docs/en/yolov5/tutorials/clearml_logging_integration.md
index 90012d193c..f8ee5c348e 100644
--- a/docs/en/yolov5/tutorials/clearml_logging_integration.md
+++ b/docs/en/yolov5/tutorials/clearml_logging_integration.md
@@ -14,7 +14,7 @@ keywords: ClearML, YOLOv5, machine learning, experiment tracking, data versionin
🔨 Track every YOLOv5 training run in the experiment manager
-🔧 Version and easily access your custom training data with the integrated ClearML Data Versioning Tool
+🔧 Version and easily access your custom [training data](https://www.ultralytics.com/glossary/training-data) with the integrated ClearML Data Versioning Tool
🔦 Remotely train and monitor your YOLOv5 training runs using ClearML Agent
@@ -85,8 +85,8 @@ This will capture:
- Console output
- Scalars (mAP_0.5, mAP_0.5:0.95, precision, recall, losses, learning rates, ...)
- General info such as machine details, runtime, creation date etc.
-- All produced plots such as label correlogram and confusion matrix
-- Images with bounding boxes per epoch
+- All produced plots such as label correlogram and [confusion matrix](https://www.ultralytics.com/glossary/confusion-matrix)
+- Images with bounding boxes per [epoch](https://www.ultralytics.com/glossary/epoch)
- Mosaic per epoch
- Validation images per epoch
diff --git a/docs/en/yolov5/tutorials/comet_logging_integration.md b/docs/en/yolov5/tutorials/comet_logging_integration.md
index 63608fc2cd..c5f20dda93 100644
--- a/docs/en/yolov5/tutorials/comet_logging_integration.md
+++ b/docs/en/yolov5/tutorials/comet_logging_integration.md
@@ -12,7 +12,7 @@ This guide will cover how to use YOLOv5 with [Comet](https://bit.ly/yolov5-readm
## About Comet
-Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize machine learning and deep learning models.
+Comet builds tools that help data scientists, engineers, and team leaders accelerate and optimize [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models.
Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://www.comet.com/docs/v2/guides/comet-dashboard/code-panels/about-panels/?utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
@@ -72,7 +72,7 @@ By default, Comet will log the following items
## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
+- Box Loss, Object Loss, Classification Loss for the training and [validation data](https://www.ultralytics.com/glossary/validation-data)
- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
- Precision and Recall for the validation data
@@ -83,7 +83,7 @@ By default, Comet will log the following items
## Visualizations
-- Confusion Matrix of the model predictions on the validation data
+- [Confusion Matrix](https://www.ultralytics.com/glossary/confusion-matrix) of the model predictions on the validation data
- Plots for the PR and F1 curves across all classes
- Correlogram of the Class Labels
@@ -120,9 +120,9 @@ python train.py \
By default, model predictions (images, ground truth labels and bounding boxes) will be logged to Comet.
-You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's Object Detection Custom Panel. This frequency corresponds to every Nth batch of data per epoch. In the example below, we are logging every 2nd batch of data for each epoch.
+You can control the frequency of logged predictions and the associated images by passing the `bbox_interval` command line argument. Predictions can be visualized using Comet's [Object Detection](https://www.ultralytics.com/glossary/object-detection) Custom Panel. This frequency corresponds to every Nth batch of data per [epoch](https://www.ultralytics.com/glossary/epoch). In the example below, we are logging every 2nd batch of data for each epoch.
-**Note:** The YOLOv5 validation dataloader will default to a batch size of 32, so you will have to set the logging frequency accordingly.
+**Note:** The YOLOv5 validation dataloader will default to a [batch size](https://www.ultralytics.com/glossary/batch-size) of 32, so you will have to set the logging frequency accordingly.
Here is an [example project using the Panel](https://www.comet.com/examples/comet-example-yolov5?shareable=YcwMiJaZSXfcEXpGOHDD12vA1&utm_source=yolov5&utm_medium=partner&utm_campaign=partner_yolov5_2022&utm_content=github)
@@ -152,7 +152,7 @@ env COMET_MAX_IMAGE_UPLOADS=200 python train.py \
### Logging Class Level Metrics
-Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, precision, recall, f1 for each class.
+Use the `COMET_LOG_PER_CLASS_METRICS` environment variable to log mAP, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), f1 for each class.
```shell
env COMET_LOG_PER_CLASS_METRICS=true python train.py \
diff --git a/docs/en/yolov5/tutorials/hyperparameter_evolution.md b/docs/en/yolov5/tutorials/hyperparameter_evolution.md
index 8b2a132479..3db460b126 100644
--- a/docs/en/yolov5/tutorials/hyperparameter_evolution.md
+++ b/docs/en/yolov5/tutorials/hyperparameter_evolution.md
@@ -61,7 +61,7 @@ copy_paste: 0.0 # segment copy-paste (probability)
## 2. Define Fitness
-Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and Recall `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).
+Fitness is the value we seek to maximize. In YOLOv5 we define a default fitness function as a weighted combination of metrics: `mAP@0.5` contributes 10% of the weight and `mAP@0.5:0.95` contributes the remaining 90%, with [Precision `P` and [Recall](https://www.ultralytics.com/glossary/recall) `R`](https://en.wikipedia.org/wiki/Precision_and_recall) absent. You may adjust these as you see fit or use the default fitness definition in utils/metrics.py (recommended).
```python
def fitness(x):
@@ -72,7 +72,7 @@ def fitness(x):
## 3. Evolve
-Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is finetuning COCO128 for 10 epochs using pretrained YOLOv5s. The base scenario training command is:
+Evolution is performed about a base scenario which we seek to improve upon. The base scenario in this example is [finetuning](https://www.ultralytics.com/glossary/fine-tuning) COCO128 for 10 [epochs](https://www.ultralytics.com/glossary/epoch) using pretrained YOLOv5s. The base scenario training command is:
```bash
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache
diff --git a/docs/en/yolov5/tutorials/model_ensembling.md b/docs/en/yolov5/tutorials/model_ensembling.md
index f358106537..814c896921 100644
--- a/docs/en/yolov5/tutorials/model_ensembling.md
+++ b/docs/en/yolov5/tutorials/model_ensembling.md
@@ -4,11 +4,11 @@ description: Learn how to use YOLOv5 model ensembling during testing and inferen
keywords: YOLOv5, model ensembling, testing, inference, mAP, Recall, Ultralytics, object detection, PyTorch
---
-📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and Recall.
+📚 This guide explains how to use YOLOv5 🚀 **model ensembling** during testing and inference for improved mAP and [Recall](https://www.ultralytics.com/glossary/recall).
From [https://en.wikipedia.org/wiki/Ensemble_learning](https://en.wikipedia.org/wiki/Ensemble_learning):
-> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different training data sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
+> Ensemble modeling is a process where multiple diverse models are created to predict an outcome, either by using many different modeling algorithms or using different [training data](https://www.ultralytics.com/glossary/training-data) sets. The ensemble model then aggregates the prediction of each base model and results in once final prediction for the unseen data. The motivation for using ensemble models is to reduce the generalization error of the prediction. As long as the base models are diverse and independent, the prediction error of the model decreases when the ensemble approach is used. The approach seeks the wisdom of crowds in making a prediction. Even though the ensemble model has multiple base models within the model, it acts and performs as a single model.
## Before You Start
diff --git a/docs/en/yolov5/tutorials/model_export.md b/docs/en/yolov5/tutorials/model_export.md
index dc68c84c10..e5f0c73007 100644
--- a/docs/en/yolov5/tutorials/model_export.md
+++ b/docs/en/yolov5/tutorials/model_export.md
@@ -6,7 +6,7 @@ keywords: YOLOv5 export, TFLite, ONNX, CoreML, TensorRT, model conversion, YOLOv
# TFLite, ONNX, CoreML, TensorRT Export
-📚 This guide explains how to export a trained YOLOv5 🚀 model from PyTorch to ONNX and TorchScript formats.
+📚 This guide explains how to export a trained YOLOv5 🚀 model from [PyTorch](https://www.ultralytics.com/glossary/pytorch) to ONNX and TorchScript formats.
## Before You Start
@@ -103,7 +103,7 @@ This command exports a pretrained YOLOv5s model to TorchScript and ONNX formats.
python export.py --weights yolov5s.pt --include torchscript onnx
```
-💡 ProTip: Add `--half` to export models at FP16 half precision for smaller file sizes
+💡 ProTip: Add `--half` to export models at FP16 half [precision](https://www.ultralytics.com/glossary/precision) for smaller file sizes
Output:
@@ -205,7 +205,7 @@ results.print() # or .show(), .save(), .crop(), .pandas(), etc.
## OpenCV DNN inference
-OpenCV inference with ONNX models:
+[OpenCV](https://www.ultralytics.com/glossary/opencv) inference with ONNX models:
```bash
python export.py --weights yolov5s.pt --include onnx
diff --git a/docs/en/yolov5/tutorials/multi_gpu_training.md b/docs/en/yolov5/tutorials/multi_gpu_training.md
index 4a56570fdd..53f3a1c1fd 100644
--- a/docs/en/yolov5/tutorials/multi_gpu_training.md
+++ b/docs/en/yolov5/tutorials/multi_gpu_training.md
@@ -18,7 +18,7 @@ pip install -r requirements.txt # install
💡 ProTip! **Docker Image** is recommended for all Multi-GPU trainings. See [Docker Quickstart Guide](../environments/docker_image_quickstart_tutorial.md)
-💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **PyTorch>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
+💡 ProTip! `torch.distributed.run` replaces `torch.distributed.launch` in **[PyTorch](https://www.ultralytics.com/glossary/pytorch)>=1.9**. See [docs](https://pytorch.org/docs/stable/distributed.html) for details.
## Training
@@ -69,7 +69,7 @@ python -m torch.distributed.run --nproc_per_node 2 train.py --batch 64 --data co
Use SyncBatchNorm (click to expand)
-[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase accuracy for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.
+[SyncBatchNorm](https://pytorch.org/docs/master/generated/torch.nn.SyncBatchNorm.html) could increase [accuracy](https://www.ultralytics.com/glossary/accuracy) for multiple gpu training, however, it will slow down training by a significant factor. It is **only** available for Multiple GPU DistributedDataParallel training.
It is best used when the batch-size on **each** GPU is small (<= 8).
@@ -121,7 +121,7 @@ python -m torch.distributed.run --master_port 1234 --nproc_per_node 2 ...
## Results
-DDP profiling results on an [AWS EC2 P4d instance](../environments/aws_quickstart_tutorial.md) with 8x A100 SXM4-40GB for YOLOv5l for 1 COCO epoch.
+DDP profiling results on an [AWS EC2 P4d instance](../environments/aws_quickstart_tutorial.md) with 8x A100 SXM4-40GB for YOLOv5l for 1 COCO [epoch](https://www.ultralytics.com/glossary/epoch).
Profiling code
diff --git a/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md b/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
index 663a5d1484..1d2a9bcad4 100644
--- a/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
+++ b/docs/en/yolov5/tutorials/neural_magic_pruning_quantization.md
@@ -30,7 +30,7 @@ DeepSparse is an inference runtime with exceptional performance on CPUs. For ins
-For the first time, your deep learning workloads can meet the performance demands of production without the complexity and costs of hardware accelerators. Put simply, DeepSparse gives you the performance of GPUs and the simplicity of software:
+For the first time, your [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) workloads can meet the performance demands of production without the complexity and costs of hardware accelerators. Put simply, DeepSparse gives you the performance of GPUs and the simplicity of software:
- **Flexible Deployments**: Run consistently across cloud, data center, and edge with any hardware provider from Intel to AMD to ARM
- **Infinite Scalability**: Scale vertically to 100s of cores, out with standard Kubernetes, or fully-abstracted with Serverless
@@ -40,7 +40,7 @@ For the first time, your deep learning workloads can meet the performance demand
DeepSparse takes advantage of model sparsity to gain its performance speedup.
-Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to execute a network, while maintaining high accuracy. DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns, vertical stripes of computation that fit in cache.
+Sparsification through pruning and quantization is a broadly studied technique, allowing order-of-magnitude reductions in the size and compute needed to execute a network, while maintaining high [accuracy](https://www.ultralytics.com/glossary/accuracy). DeepSparse is sparsity-aware, meaning it skips the zeroed out parameters, shrinking amount of compute in a forward pass. Since the sparse computation is now memory bound, DeepSparse executes the network depth-wise, breaking the problem into Tensor Columns, vertical stripes of computation that fit in cache.
@@ -122,7 +122,7 @@ apt-get install libgl1
#### HTTP Server
-DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
+DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including [object detection](https://www.ultralytics.com/glossary/object-detection) with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
Spin up the Server with the pruned-quantized YOLOv5s:
diff --git a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
index b00d94db4c..27e26f144f 100644
--- a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
+++ b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
@@ -4,7 +4,7 @@ description: Learn how to load YOLOv5 from PyTorch Hub for seamless model infere
keywords: YOLOv5, PyTorch Hub, model loading, Ultralytics, object detection, machine learning, AI, tutorial, inference
---
-📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
+📚 This guide explains how to load YOLOv5 🚀 from [PyTorch](https://www.ultralytics.com/glossary/pytorch) Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
## Before You Start
@@ -44,7 +44,7 @@ results.pandas().xyxy[0]
### Detailed Example
-This example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
+This example shows **batched inference** with **PIL** and **[OpenCV](https://www.ultralytics.com/glossary/opencv)** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
```python
import cv2
diff --git a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
index 3047e48c2e..55728f21e7 100644
--- a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
+++ b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
@@ -52,7 +52,7 @@ We have released a custom training tutorial demonstrating all of the above capab
## Active Learning
-The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
+The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your [model deployments](https://www.ultralytics.com/glossary/model-deployment) by using a battle tested [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) pipeline.
@@ -96,10 +96,10 @@ dataset = project.version("YOUR VERSION").download("yolov5")
This code will download your dataset in a format compatible with YOLOv5, allowing you to quickly begin training your model. For more details, refer to the [Exporting Data](#exporting-data) section.
-### What is active learning and how does it work with YOLOv5 and Roboflow?
+### What is [active learning](https://www.ultralytics.com/glossary/active-learning) and how does it work with YOLOv5 and Roboflow?
Active learning is a machine learning strategy that iteratively improves a model by intelligently selecting the most informative data points to label. With the Roboflow and YOLOv5 integration, you can implement active learning to continuously enhance your model's performance. This involves deploying a model, capturing new data, using the model to make predictions, and then manually verifying or correcting those predictions to further train the model. For more insights into active learning see the [Active Learning](#active-learning) section above.
### How can I use Ultralytics environments for training YOLOv5 models on different platforms?
-Ultralytics provides ready-to-use environments with pre-installed dependencies like CUDA, CUDNN, Python, and PyTorch, making it easier to kickstart your training projects. These environments are available on various platforms such as Google Cloud, AWS, Azure, and Docker. You can also access free GPU notebooks via [Paperspace](https://bit.ly/yolov5-paperspace-notebook), [Google Colab](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb), and [Kaggle](https://www.kaggle.com/ultralytics/yolov5). For specific setup instructions, visit the [Supported Environments](#supported-environments) section of the documentation.
+Ultralytics provides ready-to-use environments with pre-installed dependencies like CUDA, CUDNN, Python, and [PyTorch](https://www.ultralytics.com/glossary/pytorch), making it easier to kickstart your training projects. These environments are available on various platforms such as Google Cloud, AWS, Azure, and Docker. You can also access free GPU notebooks via [Paperspace](https://bit.ly/yolov5-paperspace-notebook), [Google Colab](https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb), and [Kaggle](https://www.kaggle.com/ultralytics/yolov5). For specific setup instructions, visit the [Supported Environments](#supported-environments) section of the documentation.
diff --git a/docs/en/yolov5/tutorials/test_time_augmentation.md b/docs/en/yolov5/tutorials/test_time_augmentation.md
index d2b959171c..336ad3f79b 100644
--- a/docs/en/yolov5/tutorials/test_time_augmentation.md
+++ b/docs/en/yolov5/tutorials/test_time_augmentation.md
@@ -6,7 +6,7 @@ keywords: YOLOv5, Test-Time Augmentation, TTA, machine learning, deep learning,
# Test-Time Augmentation (TTA)
-📚 This guide explains how to use Test Time Augmentation (TTA) during testing and inference for improved mAP and Recall with YOLOv5 🚀.
+📚 This guide explains how to use Test Time Augmentation (TTA) during testing and inference for improved mAP and [Recall](https://www.ultralytics.com/glossary/recall) with YOLOv5 🚀.
## Before You Start
diff --git a/docs/en/yolov5/tutorials/tips_for_best_training_results.md b/docs/en/yolov5/tutorials/tips_for_best_training_results.md
index c24435d93c..634297203e 100644
--- a/docs/en/yolov5/tutorials/tips_for_best_training_results.md
+++ b/docs/en/yolov5/tutorials/tips_for_best_training_results.md
@@ -8,7 +8,7 @@ keywords: YOLOv5 training, mAP, dataset best practices, model selection, trainin
Most of the time good results can be obtained with no changes to the models or training settings, **provided your dataset is sufficiently large and well labelled**. If at first you don't get good results, there are steps you might be able to take to improve, but we always recommend users **first train with all default settings** before considering any changes. This helps establish a performance baseline and spot areas for improvement.
-If you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, confusion matrix, training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.
+If you have questions about your training results **we recommend you provide the maximum amount of information possible** if you expect a helpful response, including results plots (train losses, val losses, P, R, mAP), PR curve, [confusion matrix](https://www.ultralytics.com/glossary/confusion-matrix), training mosaics, test results and dataset statistics images such as labels.png. All of these are located in your `project/name` directory, typically `yolov5/runs/train/exp`.
We've put together a full guide for users looking to get the best results on their YOLOv5 trainings below.
@@ -18,7 +18,7 @@ We've put together a full guide for users looking to get the best results on the
- **Instances per class.** ≥ 10000 instances (labeled objects) per class recommended
- **Image variety.** Must be representative of deployed environment. For real-world use cases we recommend images from different times of day, different seasons, different weather, different lighting, different angles, different sources (scraped online, collected locally, different cameras) etc.
- **Label consistency.** All instances of all classes in all images must be labelled. Partial labelling will not work.
-- **Label accuracy.** Labels must closely enclose each object. No space should exist between an object and it's bounding box. No objects should be missing a label.
+- **Label [accuracy](https://www.ultralytics.com/glossary/accuracy).** Labels must closely enclose each object. No space should exist between an object and it's [bounding box](https://www.ultralytics.com/glossary/bounding-box). No objects should be missing a label.
- **Label verification.** View `train_batch*.jpg` on train start to verify your labels appear correct, i.e. see [example](./train_custom_data.md#local-logging) mosaic.
- **Background images.** Background images are images with no objects that are added to a dataset to reduce False Positives (FP). We recommend about 0-10% background images to help reduce FPs (COCO has 1000 background images for reference, 1% of the total). No labels are required for background images.
@@ -53,13 +53,13 @@ python train.py --data custom.yaml --weights '' --cfg yolov5s.yaml
Before modifying anything, **first train with default settings to establish a performance baseline**. A full list of train.py settings can be found in the [train.py](https://github.com/ultralytics/yolov5/blob/master/train.py) argparser.
-- **Epochs.** Start with 300 epochs. If this overfits early then you can reduce epochs. If overfitting does not occur after 300 epochs, train longer, i.e. 600, 1200 etc. epochs.
+- **[Epochs](https://www.ultralytics.com/glossary/epoch).** Start with 300 epochs. If this overfits early then you can reduce epochs. If [overfitting](https://www.ultralytics.com/glossary/overfitting) does not occur after 300 epochs, train longer, i.e. 600, 1200 etc. epochs.
- **Image size.** COCO trains at native resolution of `--img 640`, though due to the high amount of small objects in the dataset it can benefit from training at higher resolutions such as `--img 1280`. If there are many small objects then custom datasets will benefit from training at native or higher resolution. Best inference results are obtained at the same `--img` as the training was run at, i.e. if you train at `--img 1280` you should also test and detect at `--img 1280`.
-- **Batch size.** Use the largest `--batch-size` that your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided.
+- **[Batch size](https://www.ultralytics.com/glossary/batch-size).** Use the largest `--batch-size` that your hardware allows for. Small batch sizes produce poor batchnorm statistics and should be avoided.
- **Hyperparameters.** Default hyperparameters are in [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml). We recommend you train with default hyperparameters first before thinking of modifying any. In general, increasing augmentation hyperparameters will reduce and delay overfitting, allowing for longer trainings and higher final mAP. Reduction in loss component gain hyperparameters like `hyp['obj']` will help reduce overfitting in those specific loss components. For an automated method of optimizing these hyperparameters, see our [Hyperparameter Evolution Tutorial](./hyperparameter_evolution.md).
## Further Reading
-If you'd like to know more, a good place to start is Karpathy's 'Recipe for Training Neural Networks', which has great ideas for training that apply broadly across all ML domains: [https://karpathy.github.io/2019/04/25/recipe/](https://karpathy.github.io/2019/04/25/recipe/)
+If you'd like to know more, a good place to start is Karpathy's 'Recipe for Training [Neural Networks](https://www.ultralytics.com/glossary/neural-network-nn)', which has great ideas for training that apply broadly across all ML domains: [https://karpathy.github.io/2019/04/25/recipe/](https://karpathy.github.io/2019/04/25/recipe/)
Good luck 🍀 and let us know if you have any other questions!
diff --git a/docs/en/yolov5/tutorials/train_custom_data.md b/docs/en/yolov5/tutorials/train_custom_data.md
index 6119bc3a7c..aa093e4b81 100644
--- a/docs/en/yolov5/tutorials/train_custom_data.md
+++ b/docs/en/yolov5/tutorials/train_custom_data.md
@@ -77,7 +77,7 @@ Export in `YOLOv5 Pytorch` format, then copy the snippet into your training scri
### 2.1 Create `dataset.yaml`
-[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](https://cocodataset.org/) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of overfitting. [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or `*.txt` files with image paths) and 2) a class `names` dictionary:
+[COCO128](https://www.kaggle.com/ultralytics/coco128) is an example small tutorial dataset composed of the first 128 images in [COCO](https://cocodataset.org/) train2017. These same 128 images are used for both training and validation to verify our training pipeline is capable of [overfitting](https://www.ultralytics.com/glossary/overfitting). [data/coco128.yaml](https://github.com/ultralytics/yolov5/blob/master/data/coco128.yaml), shown below, is the dataset config file that defines 1) the dataset root directory `path` and relative paths to `train` / `val` / `test` image directories (or `*.txt` files with image paths) and 2) a class `names` dictionary:
```yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
@@ -183,11 +183,11 @@ You can use ClearML Data to version your dataset and then pass it to YOLOv5 simp
Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
-This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
+This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including [precision](https://www.ultralytics.com/glossary/precision)-[recall](https://www.ultralytics.com/glossary/recall) (PR) curves and confusion matrices.
-Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+Results file `results.csv` is updated after each [epoch](https://www.ultralytics.com/glossary/epoch), and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
```python
from utils.plots import plot_results
@@ -202,8 +202,8 @@ plot_results("path/to/results.csv") # plot 'results.csv' as 'results.png'
Once your model is trained you can use your best checkpoint `best.pt` to:
- Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](./pytorch_hub_model_loading.md) inference on new images and videos
-- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
-- [Export](./model_export.md) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
+- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) [accuracy](https://www.ultralytics.com/glossary/accuracy) on train, val and test splits
+- [Export](./model_export.md) to [TensorFlow](https://www.ultralytics.com/glossary/tensorflow), Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
- [Evolve](./hyperparameter_evolution.md) hyperparameters to improve performance
- [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
diff --git a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
index be6a087015..9e689ad3eb 100644
--- a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
+++ b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
@@ -4,7 +4,7 @@ description: Learn to freeze YOLOv5 layers for efficient transfer learning, redu
keywords: YOLOv5, transfer learning, freeze layers, machine learning, deep learning, model training, PyTorch, Ultralytics
---
-📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
+📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **[transfer learning](https://www.ultralytics.com/glossary/transfer-learning)**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
## Before You Start
@@ -121,7 +121,7 @@ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --i
### Accuracy Comparison
-The results show that freezing speeds up training, but reduces final accuracy slightly.
+The results show that freezing speeds up training, but reduces final [accuracy](https://www.ultralytics.com/glossary/accuracy) slightly.

 @@ -32,7 +32,7 @@ Create embeddings for your dataset, search for similar images, run SQL queries,
## [Object Detection](detect/index.md)
-Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
+[Bounding box](https://www.ultralytics.com/glossary/bounding-box) object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
- [COCO](detect/coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
@@ -72,7 +72,7 @@ Pose estimation is a technique used to determine the pose of the object relative
## [Classification](classify/index.md)
-Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
+[Image classification](https://www.ultralytics.com/glossary/image-classification) is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
- [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
- [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
@@ -152,7 +152,7 @@ By following these steps, you can contribute a new dataset that integrates well
## FAQ
-### What datasets does Ultralytics support for object detection?
+### What datasets does Ultralytics support for [object detection](https://www.ultralytics.com/glossary/object-detection)?
Ultralytics supports a wide variety of datasets for object detection, including:
@@ -190,7 +190,7 @@ Ultralytics Explorer offers powerful features for dataset analysis, including:
Explore the [Ultralytics Explorer](explorer/index.md) for more information and to try the [GUI Demo](explorer/index.md).
-### What are the unique features of Ultralytics YOLO models for computer vision?
+### What are the unique features of Ultralytics YOLO models for [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv)?
Ultralytics YOLO models provide several unique features:
diff --git a/docs/en/datasets/obb/dota-v2.md b/docs/en/datasets/obb/dota-v2.md
index 66b3ac5f21..76024cac10 100644
--- a/docs/en/datasets/obb/dota-v2.md
+++ b/docs/en/datasets/obb/dota-v2.md
@@ -6,7 +6,7 @@ keywords: DOTA dataset, object detection, aerial images, oriented bounding boxes
# DOTA Dataset with OBB
-[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing object detection in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).
+[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing [object detection](https://www.ultralytics.com/glossary/object-detection) in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).

@@ -128,7 +128,7 @@ Having a glance at the dataset illustrates its depth:

-- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented Bounding Box annotations, capturing objects in their natural orientation.
+- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented [Bounding Box](https://www.ultralytics.com/glossary/bounding-box) annotations, capturing objects in their natural orientation.
The dataset's richness offers invaluable insights into object detection challenges exclusive to aerial imagery.
diff --git a/docs/en/datasets/obb/dota8.md b/docs/en/datasets/obb/dota8.md
index 0188c31785..f24ea5bce2 100644
--- a/docs/en/datasets/obb/dota8.md
+++ b/docs/en/datasets/obb/dota8.md
@@ -8,7 +8,7 @@ keywords: DOTA8 dataset, Ultralytics, YOLOv8, object detection, debugging, train
## Introduction
-[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented object detection dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented [object detection](https://www.ultralytics.com/glossary/object-detection) dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@@ -24,7 +24,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-obb model on the DOTA8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -121,4 +121,4 @@ Mosaicing combines multiple images into one during training, increasing the vari
### Why should I use Ultralytics YOLOv8 for object detection tasks?
-Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), instance segmentation, and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
+Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index 4ca53497be..edeffb83af 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -6,7 +6,7 @@ keywords: Oriented Bounding Box, OBB Datasets, YOLO, Ultralytics, Object Detecti
# Oriented Bounding Box (OBB) Datasets Overview
-Training a precise object detection model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
+Training a precise [object detection](https://www.ultralytics.com/glossary/object-detection) model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
## Supported OBB Dataset Formats
@@ -18,7 +18,7 @@ The YOLO OBB format designates bounding boxes by their four corner points with c
class_index x1 y1 x2 y2 x3 y3 x4 y4
```
-Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
+Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the [bounding box](https://www.ultralytics.com/glossary/bounding-box)'s center point (xy), width, height, and rotation.
@@ -32,7 +32,7 @@ Create embeddings for your dataset, search for similar images, run SQL queries,
## [Object Detection](detect/index.md)
-Bounding box object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
+[Bounding box](https://www.ultralytics.com/glossary/bounding-box) object detection is a computer vision technique that involves detecting and localizing objects in an image by drawing a bounding box around each object.
- [Argoverse](detect/argoverse.md): A dataset containing 3D tracking and motion forecasting data from urban environments with rich annotations.
- [COCO](detect/coco.md): Common Objects in Context (COCO) is a large-scale object detection, segmentation, and captioning dataset with 80 object categories.
@@ -72,7 +72,7 @@ Pose estimation is a technique used to determine the pose of the object relative
## [Classification](classify/index.md)
-Image classification is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
+[Image classification](https://www.ultralytics.com/glossary/image-classification) is a computer vision task that involves categorizing an image into one or more predefined classes or categories based on its visual content.
- [Caltech 101](classify/caltech101.md): A dataset containing images of 101 object categories for image classification tasks.
- [Caltech 256](classify/caltech256.md): An extended version of Caltech 101 with 256 object categories and more challenging images.
@@ -152,7 +152,7 @@ By following these steps, you can contribute a new dataset that integrates well
## FAQ
-### What datasets does Ultralytics support for object detection?
+### What datasets does Ultralytics support for [object detection](https://www.ultralytics.com/glossary/object-detection)?
Ultralytics supports a wide variety of datasets for object detection, including:
@@ -190,7 +190,7 @@ Ultralytics Explorer offers powerful features for dataset analysis, including:
Explore the [Ultralytics Explorer](explorer/index.md) for more information and to try the [GUI Demo](explorer/index.md).
-### What are the unique features of Ultralytics YOLO models for computer vision?
+### What are the unique features of Ultralytics YOLO models for [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv)?
Ultralytics YOLO models provide several unique features:
diff --git a/docs/en/datasets/obb/dota-v2.md b/docs/en/datasets/obb/dota-v2.md
index 66b3ac5f21..76024cac10 100644
--- a/docs/en/datasets/obb/dota-v2.md
+++ b/docs/en/datasets/obb/dota-v2.md
@@ -6,7 +6,7 @@ keywords: DOTA dataset, object detection, aerial images, oriented bounding boxes
# DOTA Dataset with OBB
-[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing object detection in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).
+[DOTA](https://captain-whu.github.io/DOTA/index.html) stands as a specialized dataset, emphasizing [object detection](https://www.ultralytics.com/glossary/object-detection) in aerial images. Originating from the DOTA series of datasets, it offers annotated images capturing a diverse array of aerial scenes with Oriented Bounding Boxes (OBB).

@@ -128,7 +128,7 @@ Having a glance at the dataset illustrates its depth:

-- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented Bounding Box annotations, capturing objects in their natural orientation.
+- **DOTA examples**: This snapshot underlines the complexity of aerial scenes and the significance of Oriented [Bounding Box](https://www.ultralytics.com/glossary/bounding-box) annotations, capturing objects in their natural orientation.
The dataset's richness offers invaluable insights into object detection challenges exclusive to aerial imagery.
diff --git a/docs/en/datasets/obb/dota8.md b/docs/en/datasets/obb/dota8.md
index 0188c31785..f24ea5bce2 100644
--- a/docs/en/datasets/obb/dota8.md
+++ b/docs/en/datasets/obb/dota8.md
@@ -8,7 +8,7 @@ keywords: DOTA8 dataset, Ultralytics, YOLOv8, object detection, debugging, train
## Introduction
-[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented object detection dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
+[Ultralytics](https://www.ultralytics.com/) DOTA8 is a small, but versatile oriented [object detection](https://www.ultralytics.com/glossary/object-detection) dataset composed of the first 8 images of 8 images of the split DOTAv1 set, 4 for training and 4 for validation. This dataset is ideal for testing and debugging object detection models, or for experimenting with new detection approaches. With 8 images, it is small enough to be easily manageable, yet diverse enough to test training pipelines for errors and act as a sanity check before training larger datasets.
This dataset is intended for use with Ultralytics [HUB](https://hub.ultralytics.com/) and [YOLOv8](https://github.com/ultralytics/ultralytics).
@@ -24,7 +24,7 @@ A YAML (Yet Another Markup Language) file is used to define the dataset configur
## Usage
-To train a YOLOv8n-obb model on the DOTA8 dataset for 100 epochs with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
+To train a YOLOv8n-obb model on the DOTA8 dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) with an image size of 640, you can use the following code snippets. For a comprehensive list of available arguments, refer to the model [Training](../../modes/train.md) page.
!!! example "Train Example"
@@ -121,4 +121,4 @@ Mosaicing combines multiple images into one during training, increasing the vari
### Why should I use Ultralytics YOLOv8 for object detection tasks?
-Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), instance segmentation, and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
+Ultralytics YOLOv8 provides state-of-the-art real-time object detection capabilities, including features like oriented bounding boxes (OBB), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and a highly versatile training pipeline. It's suitable for various applications and offers pretrained models for efficient fine-tuning. Explore further about the advantages and usage in the [Ultralytics YOLOv8 documentation](https://github.com/ultralytics/ultralytics).
diff --git a/docs/en/datasets/obb/index.md b/docs/en/datasets/obb/index.md
index 4ca53497be..edeffb83af 100644
--- a/docs/en/datasets/obb/index.md
+++ b/docs/en/datasets/obb/index.md
@@ -6,7 +6,7 @@ keywords: Oriented Bounding Box, OBB Datasets, YOLO, Ultralytics, Object Detecti
# Oriented Bounding Box (OBB) Datasets Overview
-Training a precise object detection model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
+Training a precise [object detection](https://www.ultralytics.com/glossary/object-detection) model with oriented bounding boxes (OBB) requires a thorough dataset. This guide explains the various OBB dataset formats compatible with Ultralytics YOLO models, offering insights into their structure, application, and methods for format conversions.
## Supported OBB Dataset Formats
@@ -18,7 +18,7 @@ The YOLO OBB format designates bounding boxes by their four corner points with c
class_index x1 y1 x2 y2 x3 y3 x4 y4
```
-Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the bounding box's center point (xy), width, height, and rotation.
+Internally, YOLO processes losses and outputs in the `xywhr` format, which represents the [bounding box](https://www.ultralytics.com/glossary/bounding-box)'s center point (xy), width, height, and rotation.

 -This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
+This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
@@ -68,7 +68,7 @@ conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cu
## Using Ultralytics
-With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
+With Ultralytics installed, you can now start using its robust features for [object detection](https://www.ultralytics.com/glossary/object-detection), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and more. For example, to predict an image, you can run:
```python
from ultralytics import YOLO
@@ -162,7 +162,7 @@ Yes, you can enhance performance by utilizing a CUDA-enabled environment. Ensure
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
```
-This setup enables GPU acceleration, crucial for intensive tasks like deep learning model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
+This setup enables GPU acceleration, crucial for intensive tasks like [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
### What are the benefits of using Ultralytics Docker images with a Conda environment?
diff --git a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
index 8f8f076746..db61c08196 100644
--- a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
+++ b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
@@ -12,7 +12,7 @@ keywords: Coral Edge TPU, Raspberry Pi, YOLOv8, Ultralytics, TensorFlow Lite, ML
## What is a Coral Edge TPU?
-The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for TensorFlow Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
+The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
-This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and machine learning endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
+This guide provides a comprehensive introduction to setting up a Conda environment for your Ultralytics projects. Conda is an open-source package and environment management system that offers an excellent alternative to pip for installing packages and dependencies. Its isolated environments make it particularly well-suited for data science and [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) endeavors. For more details, visit the Ultralytics Conda package on [Anaconda](https://anaconda.org/conda-forge/ultralytics) and check out the Ultralytics feedstock repository for package updates on [GitHub](https://github.com/conda-forge/ultralytics-feedstock/).
[](https://anaconda.org/conda-forge/ultralytics)
[](https://anaconda.org/conda-forge/ultralytics)
@@ -68,7 +68,7 @@ conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cu
## Using Ultralytics
-With Ultralytics installed, you can now start using its robust features for object detection, instance segmentation, and more. For example, to predict an image, you can run:
+With Ultralytics installed, you can now start using its robust features for [object detection](https://www.ultralytics.com/glossary/object-detection), [instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation), and more. For example, to predict an image, you can run:
```python
from ultralytics import YOLO
@@ -162,7 +162,7 @@ Yes, you can enhance performance by utilizing a CUDA-enabled environment. Ensure
conda install -c pytorch -c nvidia -c conda-forge pytorch torchvision pytorch-cuda=11.8 ultralytics
```
-This setup enables GPU acceleration, crucial for intensive tasks like deep learning model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
+This setup enables GPU acceleration, crucial for intensive tasks like [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) model training and inference. For more information, visit the [Ultralytics installation guide](../quickstart.md).
### What are the benefits of using Ultralytics Docker images with a Conda environment?
diff --git a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
index 8f8f076746..db61c08196 100644
--- a/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
+++ b/docs/en/guides/coral-edge-tpu-on-raspberry-pi.md
@@ -12,7 +12,7 @@ keywords: Coral Edge TPU, Raspberry Pi, YOLOv8, Ultralytics, TensorFlow Lite, ML
## What is a Coral Edge TPU?
-The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for TensorFlow Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
+The Coral Edge TPU is a compact device that adds an Edge TPU coprocessor to your system. It enables low-power, high-performance ML inference for [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite models. Read more at the [Coral Edge TPU home page](https://coral.ai/products/accelerator).
 @@ -114,9 +114,9 @@ Outliers are data points that deviate quite a bit from other observations in the
You can use various methods to detect and correct outliers:
-- **Statistical Techniques**: To detect outliers in numerical features like pixel values, bounding box coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
+- **Statistical Techniques**: To detect outliers in numerical features like pixel values, [bounding box](https://www.ultralytics.com/glossary/bounding-box) coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
- **Visual Techniques**: To spot anomalies in categorical features like object classes, colors, or shapes, use visual methods like plotting images, labels, or heat maps.
-- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and anomaly detection algorithms to identify outliers based on data distribution patterns.
+- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) algorithms to identify outliers based on data distribution patterns.
#### Quality Control of Annotated Data
@@ -132,7 +132,7 @@ While reviewing, if you find errors, correct them and update the guidelines to a
## Share Your Thoughts with the Community
-Bouncing your ideas and queries off other computer vision enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
+Bouncing your ideas and queries off other [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
### Where to Find Help and Support
@@ -159,7 +159,7 @@ Ensuring high consistency and accuracy in data annotation involves establishing
### How many images do I need for training Ultralytics YOLO models?
-For effective transfer learning and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 epochs. More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
+For effective [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 [epochs](https://www.ultralytics.com/glossary/epoch). More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
### What are some popular tools for data annotation?
@@ -177,7 +177,7 @@ Different types of data annotation cater to various computer vision tasks:
- **Bounding Boxes**: Used primarily for object detection, these are rectangular boxes around objects in an image.
- **Polygons**: Provide more precise object outlines suitable for instance segmentation tasks.
-- **Masks**: Offer pixel-level detail, used in semantic segmentation to differentiate objects from the background.
+- **Masks**: Offer pixel-level detail, used in [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation) to differentiate objects from the background.
- **Keypoints**: Identify specific points of interest within an image, useful for tasks like pose estimation and facial landmark detection.
Selecting the appropriate annotation type depends on your project's requirements. Learn more about how to implement these annotations and their formats in our [data annotation guide](#what-is-data-annotation).
diff --git a/docs/en/guides/deepstream-nvidia-jetson.md b/docs/en/guides/deepstream-nvidia-jetson.md
index cd114b8690..ab15009b99 100644
--- a/docs/en/guides/deepstream-nvidia-jetson.md
+++ b/docs/en/guides/deepstream-nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA DeepStream?
-[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
+[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate [neural networks](https://www.ultralytics.com/glossary/neural-network-nn) and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
## Prerequisites
@@ -183,7 +183,7 @@ deepstream-app -c deepstream_app_config.txt
!!! tip
- If you want to convert the model to FP16 precision, simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
+ If you want to convert the model to FP16 [precision](https://www.ultralytics.com/glossary/precision), simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
## INT8 Calibration
@@ -219,7 +219,7 @@ If you want to use INT8 precision for inference, you need to follow the steps be
!!! note
- NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
+ NVIDIA recommends at least 500 images to get a good [accuracy](https://www.ultralytics.com/glossary/accuracy). On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
6. Create the `calibration.txt` file with all selected images
@@ -323,7 +323,7 @@ To set up Ultralytics YOLOv8 on an [NVIDIA Jetson](https://www.nvidia.com/en-us/
### What is the benefit of using TensorRT with YOLOv8 on NVIDIA Jetson?
-Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency deep learning inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
+Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
### Can I run Ultralytics YOLOv8 with DeepStream SDK across different NVIDIA Jetson hardware?
diff --git a/docs/en/guides/defining-project-goals.md b/docs/en/guides/defining-project-goals.md
index fcd32f12f2..c5e3c58cf3 100644
--- a/docs/en/guides/defining-project-goals.md
+++ b/docs/en/guides/defining-project-goals.md
@@ -4,7 +4,7 @@ description: Learn how to define clear goals and objectives for your computer vi
keywords: computer vision, project planning, problem statement, measurable objectives, dataset preparation, model selection, YOLOv8, Ultralytics
---
-# A Practical Guide for Defining Your Computer Vision Project
+# A Practical Guide for Defining Your [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) Project
## Introduction
@@ -33,7 +33,7 @@ Consider a computer vision project where you want to [estimate the speed of vehi
@@ -114,9 +114,9 @@ Outliers are data points that deviate quite a bit from other observations in the
You can use various methods to detect and correct outliers:
-- **Statistical Techniques**: To detect outliers in numerical features like pixel values, bounding box coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
+- **Statistical Techniques**: To detect outliers in numerical features like pixel values, [bounding box](https://www.ultralytics.com/glossary/bounding-box) coordinates, or object sizes, you can use methods such as box plots, histograms, or z-scores.
- **Visual Techniques**: To spot anomalies in categorical features like object classes, colors, or shapes, use visual methods like plotting images, labels, or heat maps.
-- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and anomaly detection algorithms to identify outliers based on data distribution patterns.
+- **Algorithmic Methods**: Use tools like clustering (e.g., K-means clustering, DBSCAN) and [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) algorithms to identify outliers based on data distribution patterns.
#### Quality Control of Annotated Data
@@ -132,7 +132,7 @@ While reviewing, if you find errors, correct them and update the guidelines to a
## Share Your Thoughts with the Community
-Bouncing your ideas and queries off other computer vision enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
+Bouncing your ideas and queries off other [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) enthusiasts can help accelerate your projects. Here are some great ways to learn, troubleshoot, and network:
### Where to Find Help and Support
@@ -159,7 +159,7 @@ Ensuring high consistency and accuracy in data annotation involves establishing
### How many images do I need for training Ultralytics YOLO models?
-For effective transfer learning and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 epochs. More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
+For effective [transfer learning](https://www.ultralytics.com/glossary/transfer-learning) and object detection with Ultralytics YOLO models, start with a minimum of a few hundred annotated objects per class. If training for just one class, begin with at least 100 annotated images and train for approximately 100 [epochs](https://www.ultralytics.com/glossary/epoch). More complex tasks might require thousands of images per class to achieve high reliability and performance. Quality annotations are crucial, so ensure your data collection and annotation processes are rigorous and aligned with your project's specific goals. Explore detailed training strategies in the [YOLOv8 training guide](../modes/train.md).
### What are some popular tools for data annotation?
@@ -177,7 +177,7 @@ Different types of data annotation cater to various computer vision tasks:
- **Bounding Boxes**: Used primarily for object detection, these are rectangular boxes around objects in an image.
- **Polygons**: Provide more precise object outlines suitable for instance segmentation tasks.
-- **Masks**: Offer pixel-level detail, used in semantic segmentation to differentiate objects from the background.
+- **Masks**: Offer pixel-level detail, used in [semantic segmentation](https://www.ultralytics.com/glossary/semantic-segmentation) to differentiate objects from the background.
- **Keypoints**: Identify specific points of interest within an image, useful for tasks like pose estimation and facial landmark detection.
Selecting the appropriate annotation type depends on your project's requirements. Learn more about how to implement these annotations and their formats in our [data annotation guide](#what-is-data-annotation).
diff --git a/docs/en/guides/deepstream-nvidia-jetson.md b/docs/en/guides/deepstream-nvidia-jetson.md
index cd114b8690..ab15009b99 100644
--- a/docs/en/guides/deepstream-nvidia-jetson.md
+++ b/docs/en/guides/deepstream-nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA DeepStream?
-[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate neural networks and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
+[NVIDIA's DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) is a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio, and image understanding. It's ideal for vision AI developers, software partners, startups, and OEMs building IVA (Intelligent Video Analytics) apps and services. You can now create stream-processing pipelines that incorporate [neural networks](https://www.ultralytics.com/glossary/neural-network-nn) and other complex processing tasks like tracking, video encoding/decoding, and video rendering. These pipelines enable real-time analytics on video, image, and sensor data. DeepStream's multi-platform support gives you a faster, easier way to develop vision AI applications and services on-premise, at the edge, and in the cloud.
## Prerequisites
@@ -183,7 +183,7 @@ deepstream-app -c deepstream_app_config.txt
!!! tip
- If you want to convert the model to FP16 precision, simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
+ If you want to convert the model to FP16 [precision](https://www.ultralytics.com/glossary/precision), simply set `model-engine-file=model_b1_gpu0_fp16.engine` and `network-mode=2` inside `config_infer_primary_yoloV8.txt`
## INT8 Calibration
@@ -219,7 +219,7 @@ If you want to use INT8 precision for inference, you need to follow the steps be
!!! note
- NVIDIA recommends at least 500 images to get a good accuracy. On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
+ NVIDIA recommends at least 500 images to get a good [accuracy](https://www.ultralytics.com/glossary/accuracy). On this example, 1000 images are chosen to get better accuracy (more images = more accuracy). You can set it from **head -1000**. For example, for 2000 images, **head -2000**. This process can take a long time.
6. Create the `calibration.txt` file with all selected images
@@ -323,7 +323,7 @@ To set up Ultralytics YOLOv8 on an [NVIDIA Jetson](https://www.nvidia.com/en-us/
### What is the benefit of using TensorRT with YOLOv8 on NVIDIA Jetson?
-Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency deep learning inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
+Using TensorRT with YOLOv8 optimizes the model for inference, significantly reducing latency and improving throughput on NVIDIA Jetson devices. TensorRT provides high-performance, low-latency [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) inference through layer fusion, precision calibration, and kernel auto-tuning. This leads to faster and more efficient execution, particularly useful for real-time applications like video analytics and autonomous machines.
### Can I run Ultralytics YOLOv8 with DeepStream SDK across different NVIDIA Jetson hardware?
diff --git a/docs/en/guides/defining-project-goals.md b/docs/en/guides/defining-project-goals.md
index fcd32f12f2..c5e3c58cf3 100644
--- a/docs/en/guides/defining-project-goals.md
+++ b/docs/en/guides/defining-project-goals.md
@@ -4,7 +4,7 @@ description: Learn how to define clear goals and objectives for your computer vi
keywords: computer vision, project planning, problem statement, measurable objectives, dataset preparation, model selection, YOLOv8, Ultralytics
---
-# A Practical Guide for Defining Your Computer Vision Project
+# A Practical Guide for Defining Your [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) Project
## Introduction
@@ -33,7 +33,7 @@ Consider a computer vision project where you want to [estimate the speed of vehi

 @@ -103,7 +103,7 @@ If you want to use the classes the model was pre-trained on, a practical approac
- **Edge Devices**: Deploying on edge devices like smartphones or IoT devices requires lightweight models due to their limited computational resources. Example technologies include [TensorFlow Lite](../integrations/tflite.md) and [ONNX Runtime](../integrations/onnx.md), which are optimized for such environments.
- **Cloud Servers**: Cloud deployments can handle more complex models with larger computational demands. Cloud platforms like [AWS](../integrations/amazon-sagemaker.md), Google Cloud, and Azure offer robust hardware options that can scale based on the project's needs.
-- **On-Premise Servers**: For scenarios requiring high data privacy and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
+- **On-Premise Servers**: For scenarios requiring high [data privacy](https://www.ultralytics.com/glossary/data-privacy) and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
- **Hybrid Solutions**: Some projects might benefit from a hybrid approach, where some processing is done on the edge, while more complex analyses are offloaded to the cloud. This can balance performance needs with cost and latency considerations.
Each deployment option offers different benefits and challenges, and the choice depends on specific project requirements like performance, cost, and security.
@@ -158,7 +158,7 @@ For example, "Achieve 95% accuracy in speed detection within six months using a
Deployment options critically impact the performance of your Ultralytics YOLO models. Here are key options:
-- **Edge Devices:** Use lightweight models like TensorFlow Lite or ONNX Runtime for deployment on devices with limited resources.
+- **Edge Devices:** Use lightweight models like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite or ONNX Runtime for deployment on devices with limited resources.
- **Cloud Servers:** Utilize robust cloud platforms like AWS, Google Cloud, or Azure for handling complex models.
- **On-Premise Servers:** High data privacy and security needs may require on-premise deployments.
- **Hybrid Solutions:** Combine edge and cloud approaches for balanced performance and cost-efficiency.
diff --git a/docs/en/guides/distance-calculation.md b/docs/en/guides/distance-calculation.md
index a805b95e6e..443b208b70 100644
--- a/docs/en/guides/distance-calculation.md
+++ b/docs/en/guides/distance-calculation.md
@@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, distance calculation, computer vision, object tra
## What is Distance Calculation?
-Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the bounding box centroid is employed to calculate the distance for bounding boxes highlighted by the user.
+Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the [bounding box](https://www.ultralytics.com/glossary/bounding-box) centroid is employed to calculate the distance for bounding boxes highlighted by the user.
@@ -103,7 +103,7 @@ If you want to use the classes the model was pre-trained on, a practical approac
- **Edge Devices**: Deploying on edge devices like smartphones or IoT devices requires lightweight models due to their limited computational resources. Example technologies include [TensorFlow Lite](../integrations/tflite.md) and [ONNX Runtime](../integrations/onnx.md), which are optimized for such environments.
- **Cloud Servers**: Cloud deployments can handle more complex models with larger computational demands. Cloud platforms like [AWS](../integrations/amazon-sagemaker.md), Google Cloud, and Azure offer robust hardware options that can scale based on the project's needs.
-- **On-Premise Servers**: For scenarios requiring high data privacy and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
+- **On-Premise Servers**: For scenarios requiring high [data privacy](https://www.ultralytics.com/glossary/data-privacy) and security, deploying on-premise might be necessary. This involves significant upfront hardware investment but allows full control over the data and infrastructure.
- **Hybrid Solutions**: Some projects might benefit from a hybrid approach, where some processing is done on the edge, while more complex analyses are offloaded to the cloud. This can balance performance needs with cost and latency considerations.
Each deployment option offers different benefits and challenges, and the choice depends on specific project requirements like performance, cost, and security.
@@ -158,7 +158,7 @@ For example, "Achieve 95% accuracy in speed detection within six months using a
Deployment options critically impact the performance of your Ultralytics YOLO models. Here are key options:
-- **Edge Devices:** Use lightweight models like TensorFlow Lite or ONNX Runtime for deployment on devices with limited resources.
+- **Edge Devices:** Use lightweight models like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite or ONNX Runtime for deployment on devices with limited resources.
- **Cloud Servers:** Utilize robust cloud platforms like AWS, Google Cloud, or Azure for handling complex models.
- **On-Premise Servers:** High data privacy and security needs may require on-premise deployments.
- **Hybrid Solutions:** Combine edge and cloud approaches for balanced performance and cost-efficiency.
diff --git a/docs/en/guides/distance-calculation.md b/docs/en/guides/distance-calculation.md
index a805b95e6e..443b208b70 100644
--- a/docs/en/guides/distance-calculation.md
+++ b/docs/en/guides/distance-calculation.md
@@ -8,7 +8,7 @@ keywords: Ultralytics, YOLOv8, distance calculation, computer vision, object tra
## What is Distance Calculation?
-Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the bounding box centroid is employed to calculate the distance for bounding boxes highlighted by the user.
+Measuring the gap between two objects is known as distance calculation within a specified space. In the case of [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics), the [bounding box](https://www.ultralytics.com/glossary/bounding-box) centroid is employed to calculate the distance for bounding boxes highlighted by the user.

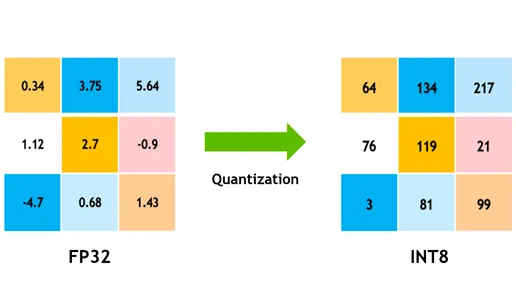 @@ -73,7 +73,7 @@ Quantization converts the model's weights and activations from high precision (l
### Knowledge Distillation
-Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's accuracy. This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
+Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's [accuracy](https://www.ultralytics.com/glossary/accuracy). This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
@@ -73,7 +73,7 @@ Quantization converts the model's weights and activations from high precision (l
### Knowledge Distillation
-Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's accuracy. This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
+Knowledge distillation involves training a smaller, simpler model (the student) to mimic the outputs of a larger, more complex model (the teacher). The student model learns to approximate the teacher's predictions, resulting in a compact model that retains much of the teacher's [accuracy](https://www.ultralytics.com/glossary/accuracy). This technique is beneficial for creating efficient models suitable for deployment on edge devices with constrained resources.
 @@ -98,7 +98,7 @@ When deploying YOLOv8, several factors can affect model accuracy. Converting mod
### Inferences Are Taking Longer Than You Expected
-When deploying machine learning models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
+When deploying [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
- **Implement Warm-Up Runs**: Initial runs often include setup overhead, which can skew latency measurements. Perform a few warm-up inferences before measuring latency. Excluding these initial runs provides a more accurate measurement of the model's performance.
- **Optimize the Inference Engine:** Double-check that the inference engine is fully optimized for your specific GPU architecture. Use the latest drivers and software versions tailored to your hardware to ensure maximum performance and compatibility.
@@ -124,7 +124,7 @@ It's essential to control who can access your model and its data to prevent unau
### Model Obfuscation
-Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in neural networks, to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
+Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in [neural networks](https://www.ultralytics.com/glossary/neural-network-nn), to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
## Share Ideas With Your Peers
diff --git a/docs/en/guides/model-evaluation-insights.md b/docs/en/guides/model-evaluation-insights.md
index 22c44e5df0..ef9389c266 100644
--- a/docs/en/guides/model-evaluation-insights.md
+++ b/docs/en/guides/model-evaluation-insights.md
@@ -24,19 +24,19 @@ _Quick Tip:_ When running inferences, if you aren't seeing any predictions and y
### Intersection over Union
-Intersection over Union (IoU) is a metric in object detection that measures how well the predicted bounding box overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
+[Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) is a metric in [object detection](https://www.ultralytics.com/glossary/object-detection) that measures how well the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
@@ -98,7 +98,7 @@ When deploying YOLOv8, several factors can affect model accuracy. Converting mod
### Inferences Are Taking Longer Than You Expected
-When deploying machine learning models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
+When deploying [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) models, it's important that they run efficiently. If inferences are taking longer than expected, it can affect the user experience and the effectiveness of your application. Here are some steps to help you identify and resolve the problem:
- **Implement Warm-Up Runs**: Initial runs often include setup overhead, which can skew latency measurements. Perform a few warm-up inferences before measuring latency. Excluding these initial runs provides a more accurate measurement of the model's performance.
- **Optimize the Inference Engine:** Double-check that the inference engine is fully optimized for your specific GPU architecture. Use the latest drivers and software versions tailored to your hardware to ensure maximum performance and compatibility.
@@ -124,7 +124,7 @@ It's essential to control who can access your model and its data to prevent unau
### Model Obfuscation
-Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in neural networks, to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
+Protecting your model from being reverse-engineered or misuse can be done through model obfuscation. It involves encrypting model parameters, such as weights and biases in [neural networks](https://www.ultralytics.com/glossary/neural-network-nn), to make it difficult for unauthorized individuals to understand or alter the model. You can also obfuscate the model's architecture by renaming layers and parameters or adding dummy layers, making it harder for attackers to reverse-engineer it. You can also serve the model in a secure environment, like a secure enclave or using a trusted execution environment (TEE), can provide an extra layer of protection during inference.
## Share Ideas With Your Peers
diff --git a/docs/en/guides/model-evaluation-insights.md b/docs/en/guides/model-evaluation-insights.md
index 22c44e5df0..ef9389c266 100644
--- a/docs/en/guides/model-evaluation-insights.md
+++ b/docs/en/guides/model-evaluation-insights.md
@@ -24,19 +24,19 @@ _Quick Tip:_ When running inferences, if you aren't seeing any predictions and y
### Intersection over Union
-Intersection over Union (IoU) is a metric in object detection that measures how well the predicted bounding box overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.
+[Intersection over Union](https://www.ultralytics.com/glossary/intersection-over-union-iou) (IoU) is a metric in [object detection](https://www.ultralytics.com/glossary/object-detection) that measures how well the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) overlaps with the ground truth bounding box. IoU values range from 0 to 1, where one stands for a perfect match. IoU is essential because it measures how closely the predicted boundaries match the actual object boundaries.

 @@ -108,8 +108,8 @@ These are some of the key elements that should be included in project documentat
- **[Project Overview](./steps-of-a-cv-project.md)**: Provide a high-level summary of the project, including the problem statement, solution approach, expected outcomes, and project scope. Explain the role of computer vision in addressing the problem and outline the stages and deliverables.
- **Model Architecture**: Detail the structure and design of the model, including its components, layers, and connections. Explain the chosen hyperparameters and the rationale behind these choices.
- **[Data Preparation](./data-collection-and-annotation.md)**: Describe the data sources, types, formats, sizes, and preprocessing steps. Discuss data quality, reliability, and any transformations applied before training the model.
-- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and loss functions. Explain how the model was trained and any challenges encountered during training.
-- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, precision, recall, and F1-score. Include performance results and an analysis of these metrics.
+- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and [loss functions](https://www.ultralytics.com/glossary/loss-function). Explain how the model was trained and any challenges encountered during training.
+- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1-score. Include performance results and an analysis of these metrics.
- **[Deployment Steps](./model-deployment-options.md)**: Outline the steps taken to deploy the model, including the tools and platforms used, deployment configurations, and any specific challenges or considerations.
- **Monitoring and Maintenance Procedure**: Provide a detailed plan for monitoring the model's performance post-deployment. Include methods for detecting and addressing data and model drift, and describe the process for regular updates and retraining.
@@ -155,7 +155,7 @@ Maintaining computer vision models involves regular updates, retraining, and mon
Data drift detection is essential because it helps identify when the statistical properties of the input data change over time, which can degrade model performance. Techniques like continuous monitoring, statistical tests (e.g., Kolmogorov-Smirnov test), and feature drift analysis can help spot issues early. Addressing data drift ensures that your model remains accurate and relevant in changing environments. Learn more about data drift detection in our [Data Drift Detection](#data-drift-detection) section.
-### What tools can I use for anomaly detection in computer vision models?
+### What tools can I use for [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) in computer vision models?
For anomaly detection in computer vision models, tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) are highly effective. These tools can help you set up alert systems to detect unusual data points or patterns that deviate from expected behavior. Configurable alerts and standardized messages can help you respond quickly to potential issues. Explore more in our [Anomaly Detection and Alert Systems](#anomaly-detection-and-alert-systems) section.
@@ -168,5 +168,5 @@ Effective documentation of a computer vision project should include:
- **Data Preparation**: Information on data sources, preprocessing steps, and transformations.
- **Training Process**: Description of the training procedure, datasets used, and challenges encountered.
- **Evaluation Metrics**: Metrics used for performance evaluation and analysis.
-- **Deployment Steps**: Steps taken for model deployment and any specific challenges.
+- **Deployment Steps**: Steps taken for [model deployment](https://www.ultralytics.com/glossary/model-deployment) and any specific challenges.
- **Monitoring and Maintenance Procedure**: Plan for ongoing monitoring and maintenance. For more comprehensive guidelines, refer to our [Documentation](#documentation) section.
diff --git a/docs/en/guides/model-testing.md b/docs/en/guides/model-testing.md
index 71ff69b0be..8d32467955 100644
--- a/docs/en/guides/model-testing.md
+++ b/docs/en/guides/model-testing.md
@@ -10,19 +10,19 @@ keywords: Overfitting and Underfitting in Machine Learning, Model Testing, Data
After [training](./model-training-tips.md) and [evaluating](./model-evaluation-insights.md) your model, it's time to test it. Model testing involves assessing how well it performs in real-world scenarios. Testing considers factors like accuracy, reliability, fairness, and how easy it is to understand the model's decisions. The goal is to make sure the model performs as intended, delivers the expected results, and fits into the [overall objective of your application](./defining-project-goals.md) or project.
-Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your computer vision models.
+Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models.
## Model Testing Vs. Model Evaluation
First, let's understand the difference between model evaluation and testing with an example.
-Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, precision, recall, and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
+Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
After evaluation, you test the model using images from a pet store to see how well it identifies cats and dogs in more varied and realistic conditions. You check if it can correctly label cats and dogs when they are moving, in different lighting conditions, or partially obscured by objects like toys or furniture. Model testing checks that the model behaves as expected outside the controlled evaluation environment.
## Preparing for Model Testing
-Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. Training data teaches the model while testing data verifies its accuracy.
+Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. [Training data](https://www.ultralytics.com/glossary/training-data) teaches the model while testing data verifies its accuracy.
Here are two points to keep in mind before testing your model:
@@ -61,7 +61,7 @@ If you want to test your trained YOLOv8 model on multiple images stored in a fol
If you are interested in testing the basic YOLOv8 model to understand whether it can be used for your application without custom training, you can use the prediction mode. While the model is pre-trained on datasets like COCO, running predictions on your own dataset can give you a quick sense of how well it might perform in your specific context.
-## Overfitting and Underfitting in Machine Learning
+## Overfitting and [Underfitting](https://www.ultralytics.com/glossary/underfitting) in [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml)
When testing a machine learning model, especially in computer vision, it's important to watch out for overfitting and underfitting. These issues can significantly affect how well your model works with new data.
@@ -71,7 +71,7 @@ Overfitting happens when your model learns the training data too well, including
#### Signs of Overfitting
-- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or test data, it's likely overfitting.
+- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or [test data](https://www.ultralytics.com/glossary/test-data), it's likely overfitting.
- **Visual Inspection:** Sometimes, you can see overfitting if your model is too sensitive to minor changes or irrelevant details in images.
### Underfitting
@@ -102,7 +102,7 @@ Data leakage can be tricky to spot and often comes from hidden biases in the tra
- **Camera Bias:** Different angles, lighting, shadows, and camera movements can introduce unwanted patterns.
- **Overlay Bias:** Logos, timestamps, or other overlays in images can mislead the model.
- **Font and Object Bias:** Specific fonts or objects that frequently appear in certain classes can skew the model's learning.
-- **Spatial Bias:** Imbalances in foreground-background, bounding box distributions, and object locations can affect training.
+- **Spatial Bias:** Imbalances in foreground-background, [bounding box](https://www.ultralytics.com/glossary/bounding-box) distributions, and object locations can affect training.
- **Label and Domain Bias:** Incorrect labels or shifts in data types can lead to leakage.
### Detecting Data Leakage
@@ -139,13 +139,13 @@ These resources will help you navigate challenges and remain updated on the late
## In Summary
-Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like overfitting and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
+Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like [overfitting](https://www.ultralytics.com/glossary/overfitting) and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
## FAQ
### What are the key differences between model evaluation and model testing in computer vision?
-Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as accuracy, precision, recall, and F1 score, providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
+Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as [accuracy](https://www.ultralytics.com/glossary/accuracy), precision, recall, and [F1 score](https://www.ultralytics.com/glossary/f1-score), providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
### How can I test my Ultralytics YOLOv8 model on multiple images?
@@ -155,7 +155,7 @@ To test your Ultralytics YOLOv8 model on multiple images, you can use the [predi
To address **overfitting**:
-- Regularization techniques like dropout.
+- [Regularization](https://www.ultralytics.com/glossary/regularization) techniques like dropout.
- Increase the size of the training dataset.
- Simplify the model architecture.
@@ -163,7 +163,7 @@ To address **underfitting**:
- Use a more complex model.
- Provide more relevant features.
-- Increase training iterations or epochs.
+- Increase training iterations or [epochs](https://www.ultralytics.com/glossary/epoch).
Review misclassified images, perform thorough error analysis, and regularly track performance metrics to maintain a balance. For more information on these concepts, explore our section on [Overfitting and Underfitting](#overfitting-and-underfitting-in-machine-learning).
@@ -190,7 +190,7 @@ Post-testing, if the model performance meets the project goals, proceed with dep
- Error analysis.
- Gathering more diverse and high-quality data.
-- Hyperparameter tuning.
+- [Hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning).
- Retraining the model.
Gain insights from the [Model Testing Vs. Model Evaluation](#model-testing-vs-model-evaluation) section to refine and enhance model effectiveness in real-world applications.
diff --git a/docs/en/guides/model-training-tips.md b/docs/en/guides/model-training-tips.md
index 932a412ffb..725081a244 100644
--- a/docs/en/guides/model-training-tips.md
+++ b/docs/en/guides/model-training-tips.md
@@ -18,22 +18,22 @@ One of the most important steps when working on a [computer vision project](./st
allowfullscreen>
@@ -108,8 +108,8 @@ These are some of the key elements that should be included in project documentat
- **[Project Overview](./steps-of-a-cv-project.md)**: Provide a high-level summary of the project, including the problem statement, solution approach, expected outcomes, and project scope. Explain the role of computer vision in addressing the problem and outline the stages and deliverables.
- **Model Architecture**: Detail the structure and design of the model, including its components, layers, and connections. Explain the chosen hyperparameters and the rationale behind these choices.
- **[Data Preparation](./data-collection-and-annotation.md)**: Describe the data sources, types, formats, sizes, and preprocessing steps. Discuss data quality, reliability, and any transformations applied before training the model.
-- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and loss functions. Explain how the model was trained and any challenges encountered during training.
-- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, precision, recall, and F1-score. Include performance results and an analysis of these metrics.
+- **[Training Process](./model-training-tips.md)**: Document the training procedure, including the datasets used, training parameters, and [loss functions](https://www.ultralytics.com/glossary/loss-function). Explain how the model was trained and any challenges encountered during training.
+- **[Evaluation Metrics](./model-evaluation-insights.md)**: Specify the metrics used to evaluate the model's performance, such as accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1-score. Include performance results and an analysis of these metrics.
- **[Deployment Steps](./model-deployment-options.md)**: Outline the steps taken to deploy the model, including the tools and platforms used, deployment configurations, and any specific challenges or considerations.
- **Monitoring and Maintenance Procedure**: Provide a detailed plan for monitoring the model's performance post-deployment. Include methods for detecting and addressing data and model drift, and describe the process for regular updates and retraining.
@@ -155,7 +155,7 @@ Maintaining computer vision models involves regular updates, retraining, and mon
Data drift detection is essential because it helps identify when the statistical properties of the input data change over time, which can degrade model performance. Techniques like continuous monitoring, statistical tests (e.g., Kolmogorov-Smirnov test), and feature drift analysis can help spot issues early. Addressing data drift ensures that your model remains accurate and relevant in changing environments. Learn more about data drift detection in our [Data Drift Detection](#data-drift-detection) section.
-### What tools can I use for anomaly detection in computer vision models?
+### What tools can I use for [anomaly detection](https://www.ultralytics.com/glossary/anomaly-detection) in computer vision models?
For anomaly detection in computer vision models, tools like [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), and [Evidently AI](https://www.evidentlyai.com/) are highly effective. These tools can help you set up alert systems to detect unusual data points or patterns that deviate from expected behavior. Configurable alerts and standardized messages can help you respond quickly to potential issues. Explore more in our [Anomaly Detection and Alert Systems](#anomaly-detection-and-alert-systems) section.
@@ -168,5 +168,5 @@ Effective documentation of a computer vision project should include:
- **Data Preparation**: Information on data sources, preprocessing steps, and transformations.
- **Training Process**: Description of the training procedure, datasets used, and challenges encountered.
- **Evaluation Metrics**: Metrics used for performance evaluation and analysis.
-- **Deployment Steps**: Steps taken for model deployment and any specific challenges.
+- **Deployment Steps**: Steps taken for [model deployment](https://www.ultralytics.com/glossary/model-deployment) and any specific challenges.
- **Monitoring and Maintenance Procedure**: Plan for ongoing monitoring and maintenance. For more comprehensive guidelines, refer to our [Documentation](#documentation) section.
diff --git a/docs/en/guides/model-testing.md b/docs/en/guides/model-testing.md
index 71ff69b0be..8d32467955 100644
--- a/docs/en/guides/model-testing.md
+++ b/docs/en/guides/model-testing.md
@@ -10,19 +10,19 @@ keywords: Overfitting and Underfitting in Machine Learning, Model Testing, Data
After [training](./model-training-tips.md) and [evaluating](./model-evaluation-insights.md) your model, it's time to test it. Model testing involves assessing how well it performs in real-world scenarios. Testing considers factors like accuracy, reliability, fairness, and how easy it is to understand the model's decisions. The goal is to make sure the model performs as intended, delivers the expected results, and fits into the [overall objective of your application](./defining-project-goals.md) or project.
-Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your computer vision models.
+Model testing is quite similar to model evaluation, but they are two distinct [steps in a computer vision project](./steps-of-a-cv-project.md). Model evaluation involves metrics and plots to assess the model's accuracy. On the other hand, model testing checks if the model's learned behavior is the same as expectations. In this guide, we'll explore strategies for testing your [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) models.
## Model Testing Vs. Model Evaluation
First, let's understand the difference between model evaluation and testing with an example.
-Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, precision, recall, and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
+Suppose you have trained a computer vision model to recognize cats and dogs, and you want to deploy this model at a pet store to monitor the animals. During the model evaluation phase, you use a labeled dataset to calculate metrics like accuracy, [precision](https://www.ultralytics.com/glossary/precision), [recall](https://www.ultralytics.com/glossary/recall), and F1 score. For instance, the model might have an accuracy of 98% in distinguishing between cats and dogs in a given dataset.
After evaluation, you test the model using images from a pet store to see how well it identifies cats and dogs in more varied and realistic conditions. You check if it can correctly label cats and dogs when they are moving, in different lighting conditions, or partially obscured by objects like toys or furniture. Model testing checks that the model behaves as expected outside the controlled evaluation environment.
## Preparing for Model Testing
-Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. Training data teaches the model while testing data verifies its accuracy.
+Computer vision models learn from datasets by detecting patterns, making predictions, and evaluating their performance. These [datasets](./preprocessing_annotated_data.md) are usually divided into training and testing sets to simulate real-world conditions. [Training data](https://www.ultralytics.com/glossary/training-data) teaches the model while testing data verifies its accuracy.
Here are two points to keep in mind before testing your model:
@@ -61,7 +61,7 @@ If you want to test your trained YOLOv8 model on multiple images stored in a fol
If you are interested in testing the basic YOLOv8 model to understand whether it can be used for your application without custom training, you can use the prediction mode. While the model is pre-trained on datasets like COCO, running predictions on your own dataset can give you a quick sense of how well it might perform in your specific context.
-## Overfitting and Underfitting in Machine Learning
+## Overfitting and [Underfitting](https://www.ultralytics.com/glossary/underfitting) in [Machine Learning](https://www.ultralytics.com/glossary/machine-learning-ml)
When testing a machine learning model, especially in computer vision, it's important to watch out for overfitting and underfitting. These issues can significantly affect how well your model works with new data.
@@ -71,7 +71,7 @@ Overfitting happens when your model learns the training data too well, including
#### Signs of Overfitting
-- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or test data, it's likely overfitting.
+- **High Training Accuracy, Low Validation Accuracy:** If your model performs very well on training data but poorly on validation or [test data](https://www.ultralytics.com/glossary/test-data), it's likely overfitting.
- **Visual Inspection:** Sometimes, you can see overfitting if your model is too sensitive to minor changes or irrelevant details in images.
### Underfitting
@@ -102,7 +102,7 @@ Data leakage can be tricky to spot and often comes from hidden biases in the tra
- **Camera Bias:** Different angles, lighting, shadows, and camera movements can introduce unwanted patterns.
- **Overlay Bias:** Logos, timestamps, or other overlays in images can mislead the model.
- **Font and Object Bias:** Specific fonts or objects that frequently appear in certain classes can skew the model's learning.
-- **Spatial Bias:** Imbalances in foreground-background, bounding box distributions, and object locations can affect training.
+- **Spatial Bias:** Imbalances in foreground-background, [bounding box](https://www.ultralytics.com/glossary/bounding-box) distributions, and object locations can affect training.
- **Label and Domain Bias:** Incorrect labels or shifts in data types can lead to leakage.
### Detecting Data Leakage
@@ -139,13 +139,13 @@ These resources will help you navigate challenges and remain updated on the late
## In Summary
-Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like overfitting and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
+Building trustworthy computer vision models relies on rigorous model testing. By testing the model with previously unseen data, we can analyze it and spot weaknesses like [overfitting](https://www.ultralytics.com/glossary/overfitting) and data leakage. Addressing these issues before deployment helps the model perform well in real-world applications. It's important to remember that model testing is just as crucial as model evaluation in guaranteeing the model's long-term success and effectiveness.
## FAQ
### What are the key differences between model evaluation and model testing in computer vision?
-Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as accuracy, precision, recall, and F1 score, providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
+Model evaluation and model testing are distinct steps in a computer vision project. Model evaluation involves using a labeled dataset to compute metrics such as [accuracy](https://www.ultralytics.com/glossary/accuracy), precision, recall, and [F1 score](https://www.ultralytics.com/glossary/f1-score), providing insights into the model's performance with a controlled dataset. Model testing, on the other hand, assesses the model's performance in real-world scenarios by applying it to new, unseen data, ensuring the model's learned behavior aligns with expectations outside the evaluation environment. For a detailed guide, refer to the [steps in a computer vision project](./steps-of-a-cv-project.md).
### How can I test my Ultralytics YOLOv8 model on multiple images?
@@ -155,7 +155,7 @@ To test your Ultralytics YOLOv8 model on multiple images, you can use the [predi
To address **overfitting**:
-- Regularization techniques like dropout.
+- [Regularization](https://www.ultralytics.com/glossary/regularization) techniques like dropout.
- Increase the size of the training dataset.
- Simplify the model architecture.
@@ -163,7 +163,7 @@ To address **underfitting**:
- Use a more complex model.
- Provide more relevant features.
-- Increase training iterations or epochs.
+- Increase training iterations or [epochs](https://www.ultralytics.com/glossary/epoch).
Review misclassified images, perform thorough error analysis, and regularly track performance metrics to maintain a balance. For more information on these concepts, explore our section on [Overfitting and Underfitting](#overfitting-and-underfitting-in-machine-learning).
@@ -190,7 +190,7 @@ Post-testing, if the model performance meets the project goals, proceed with dep
- Error analysis.
- Gathering more diverse and high-quality data.
-- Hyperparameter tuning.
+- [Hyperparameter tuning](https://www.ultralytics.com/glossary/hyperparameter-tuning).
- Retraining the model.
Gain insights from the [Model Testing Vs. Model Evaluation](#model-testing-vs-model-evaluation) section to refine and enhance model effectiveness in real-world applications.
diff --git a/docs/en/guides/model-training-tips.md b/docs/en/guides/model-training-tips.md
index 932a412ffb..725081a244 100644
--- a/docs/en/guides/model-training-tips.md
+++ b/docs/en/guides/model-training-tips.md
@@ -18,22 +18,22 @@ One of the most important steps when working on a [computer vision project](./st
allowfullscreen>


 @@ -125,7 +125,7 @@ Local training provides greater control and customization, letting you tailor yo
## Selecting an Optimizer
-An optimizer is an algorithm that adjusts the weights of your neural network to minimize the loss function, which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
+An optimizer is an algorithm that adjusts the weights of your neural network to minimize the [loss function](https://www.ultralytics.com/glossary/loss-function), which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
You can also fine-tune optimizer parameters to improve model performance. Adjusting the learning rate sets the size of the steps when updating parameters. For stability, you might start with a moderate learning rate and gradually decrease it over time to improve long-term learning. Additionally, setting the momentum determines how much influence past updates have on current updates. A common value for momentum is around 0.9. It generally provides a good balance.
@@ -147,7 +147,7 @@ Different optimizers have various strengths and weaknesses. Let's take a glimpse
- **RMSProp (Root Mean Square Propagation)**:
- Adjusts the learning rate for each parameter by dividing the gradient by a running average of the magnitudes of recent gradients.
- - Helps in handling the vanishing gradient problem and is effective for recurrent neural networks.
+ - Helps in handling the vanishing gradient problem and is effective for [recurrent neural networks](https://www.ultralytics.com/glossary/recurrent-neural-network-rnn).
For YOLOv8, the `optimizer` parameter lets you choose from various optimizers, including SGD, Adam, AdamW, NAdam, RAdam, and RMSProp, or you can set it to `auto` for automatic selection based on model configuration.
@@ -168,7 +168,7 @@ Using these resources will help you solve challenges and stay up-to-date with th
## Key Takeaways
-Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed precision training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
+Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed [precision](https://www.ultralytics.com/glossary/precision) training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
## FAQ
@@ -178,7 +178,7 @@ To improve GPU utilization, set the `batch_size` parameter in your training conf
### What is mixed precision training, and how do I enable it in YOLOv8?
-Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model accuracy. To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
+Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model [accuracy](https://www.ultralytics.com/glossary/accuracy). To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
### How does multiscale training enhance YOLOv8 model performance?
diff --git a/docs/en/guides/nvidia-jetson.md b/docs/en/guides/nvidia-jetson.md
index db1b9b79f4..f352c76b8c 100644
--- a/docs/en/guides/nvidia-jetson.md
+++ b/docs/en/guides/nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA Jetson?
-NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and deep learning models directly on the device, without needing to rely on cloud computing resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
+NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models directly on the device, without needing to rely on [cloud computing](https://www.ultralytics.com/glossary/cloud-computing) resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
## NVIDIA Jetson Series Comparison
@@ -46,7 +46,7 @@ For a more detailed comparison table, please visit the **Technical Specification
## What is NVIDIA JetPack?
-[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and computer vision. It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
+[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
## Flash JetPack to NVIDIA Jetson
@@ -110,7 +110,7 @@ For a native installation without Docker, please refer to the steps below.
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
+Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
1. Update packages list, install pip and upgrade to latest
@@ -280,7 +280,7 @@ The YOLOv8n model in PyTorch format is converted to TensorRT to run inference wi
## NVIDIA Jetson Orin YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
### Comparison Chart
diff --git a/docs/en/guides/object-blurring.md b/docs/en/guides/object-blurring.md
index 709ca1bd60..315bcd76ea 100644
--- a/docs/en/guides/object-blurring.md
+++ b/docs/en/guides/object-blurring.md
@@ -92,7 +92,7 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
### How can I implement real-time object blurring using YOLOv8?
-To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for object detection and OpenCV for applying the blur effect. Here's a simplified version:
+To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for [object detection](https://www.ultralytics.com/glossary/object-detection) and OpenCV for applying the blur effect. Here's a simplified version:
```python
import cv2
@@ -132,7 +132,7 @@ For more detailed applications, check the [advantages of object blurring section
### Can I use Ultralytics YOLOv8 to blur faces in a video for privacy reasons?
-Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with OpenCV to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
+Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with [OpenCV](https://www.ultralytics.com/glossary/opencv) to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
### How does YOLOv8 compare to other object detection models like Faster R-CNN for object blurring?
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index 749ffbe8fa..bdec66e42d 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, YOLOv8, Ultralytics, real-time object detection, AI,
## What is Object Counting?
-Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and deep learning capabilities.
+Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) capabilities.
@@ -125,7 +125,7 @@ Local training provides greater control and customization, letting you tailor yo
## Selecting an Optimizer
-An optimizer is an algorithm that adjusts the weights of your neural network to minimize the loss function, which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
+An optimizer is an algorithm that adjusts the weights of your neural network to minimize the [loss function](https://www.ultralytics.com/glossary/loss-function), which measures how well the model is performing. In simpler terms, the optimizer helps the model learn by tweaking its parameters to reduce errors. Choosing the right optimizer directly affects how quickly and accurately the model learns.
You can also fine-tune optimizer parameters to improve model performance. Adjusting the learning rate sets the size of the steps when updating parameters. For stability, you might start with a moderate learning rate and gradually decrease it over time to improve long-term learning. Additionally, setting the momentum determines how much influence past updates have on current updates. A common value for momentum is around 0.9. It generally provides a good balance.
@@ -147,7 +147,7 @@ Different optimizers have various strengths and weaknesses. Let's take a glimpse
- **RMSProp (Root Mean Square Propagation)**:
- Adjusts the learning rate for each parameter by dividing the gradient by a running average of the magnitudes of recent gradients.
- - Helps in handling the vanishing gradient problem and is effective for recurrent neural networks.
+ - Helps in handling the vanishing gradient problem and is effective for [recurrent neural networks](https://www.ultralytics.com/glossary/recurrent-neural-network-rnn).
For YOLOv8, the `optimizer` parameter lets you choose from various optimizers, including SGD, Adam, AdamW, NAdam, RAdam, and RMSProp, or you can set it to `auto` for automatic selection based on model configuration.
@@ -168,7 +168,7 @@ Using these resources will help you solve challenges and stay up-to-date with th
## Key Takeaways
-Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed precision training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
+Training computer vision models involves following good practices, optimizing your strategies, and solving problems as they arise. Techniques like adjusting batch sizes, mixed [precision](https://www.ultralytics.com/glossary/precision) training, and starting with pre-trained weights can make your models work better and train faster. Methods like subset training and early stopping help you save time and resources. Staying connected with the community and keeping up with new trends will help you keep improving your model training skills.
## FAQ
@@ -178,7 +178,7 @@ To improve GPU utilization, set the `batch_size` parameter in your training conf
### What is mixed precision training, and how do I enable it in YOLOv8?
-Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model accuracy. To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
+Mixed precision training utilizes both 16-bit (FP16) and 32-bit (FP32) floating-point types to balance computational speed and precision. This approach speeds up training and reduces memory usage without sacrificing model [accuracy](https://www.ultralytics.com/glossary/accuracy). To enable mixed precision training in YOLOv8, set the `amp` parameter to `True` in your training configuration. This activates Automatic Mixed Precision (AMP) training. For more details on this optimization technique, see the [training configuration](../modes/train.md).
### How does multiscale training enhance YOLOv8 model performance?
diff --git a/docs/en/guides/nvidia-jetson.md b/docs/en/guides/nvidia-jetson.md
index db1b9b79f4..f352c76b8c 100644
--- a/docs/en/guides/nvidia-jetson.md
+++ b/docs/en/guides/nvidia-jetson.md
@@ -27,7 +27,7 @@ This comprehensive guide provides a detailed walkthrough for deploying Ultralyti
## What is NVIDIA Jetson?
-NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and deep learning models directly on the device, without needing to rely on cloud computing resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
+NVIDIA Jetson is a series of embedded computing boards designed to bring accelerated AI (artificial intelligence) computing to edge devices. These compact and powerful devices are built around NVIDIA's GPU architecture and are capable of running complex AI algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) models directly on the device, without needing to rely on [cloud computing](https://www.ultralytics.com/glossary/cloud-computing) resources. Jetson boards are often used in robotics, autonomous vehicles, industrial automation, and other applications where AI inference needs to be performed locally with low latency and high efficiency. Additionally, these boards are based on the ARM64 architecture and runs on lower power compared to traditional GPU computing devices.
## NVIDIA Jetson Series Comparison
@@ -46,7 +46,7 @@ For a more detailed comparison table, please visit the **Technical Specification
## What is NVIDIA JetPack?
-[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and computer vision. It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
+[NVIDIA JetPack SDK](https://developer.nvidia.com/embedded/jetpack) powering the Jetson modules is the most comprehensive solution and provides full development environment for building end-to-end accelerated AI applications and shortens time to market. JetPack includes Jetson Linux with bootloader, Linux kernel, Ubuntu desktop environment, and a complete set of libraries for acceleration of GPU computing, multimedia, graphics, and [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). It also includes samples, documentation, and developer tools for both host computer and developer kit, and supports higher level SDKs such as DeepStream for streaming video analytics, Isaac for robotics, and Riva for conversational AI.
## Flash JetPack to NVIDIA Jetson
@@ -110,7 +110,7 @@ For a native installation without Docker, please refer to the steps below.
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the PyTorch models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
+Here we will install Ultralytics package on the Jetson with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats. We will mainly focus on [NVIDIA TensorRT exports](../integrations/tensorrt.md) because TensorRT will make sure we can get the maximum performance out of the Jetson devices.
1. Update packages list, install pip and upgrade to latest
@@ -280,7 +280,7 @@ The YOLOv8n model in PyTorch format is converted to TensorRT to run inference wi
## NVIDIA Jetson Orin YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on 10 different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TensorRT, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on Seeed Studio reComputer J4012 powered by Jetson Orin NX 16GB device at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
### Comparison Chart
diff --git a/docs/en/guides/object-blurring.md b/docs/en/guides/object-blurring.md
index 709ca1bd60..315bcd76ea 100644
--- a/docs/en/guides/object-blurring.md
+++ b/docs/en/guides/object-blurring.md
@@ -92,7 +92,7 @@ Object blurring with [Ultralytics YOLOv8](https://github.com/ultralytics/ultraly
### How can I implement real-time object blurring using YOLOv8?
-To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for object detection and OpenCV for applying the blur effect. Here's a simplified version:
+To implement real-time object blurring with YOLOv8, follow the provided Python example. This involves using YOLOv8 for [object detection](https://www.ultralytics.com/glossary/object-detection) and OpenCV for applying the blur effect. Here's a simplified version:
```python
import cv2
@@ -132,7 +132,7 @@ For more detailed applications, check the [advantages of object blurring section
### Can I use Ultralytics YOLOv8 to blur faces in a video for privacy reasons?
-Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with OpenCV to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
+Yes, Ultralytics YOLOv8 can be configured to detect and blur faces in videos to protect privacy. By training or using a pre-trained model to specifically recognize faces, the detection results can be processed with [OpenCV](https://www.ultralytics.com/glossary/opencv) to apply a blur effect. Refer to our guide on [object detection with YOLOv8](https://docs.ultralytics.com/models/yolov8/) and modify the code to target face detection.
### How does YOLOv8 compare to other object detection models like Faster R-CNN for object blurring?
diff --git a/docs/en/guides/object-counting.md b/docs/en/guides/object-counting.md
index 749ffbe8fa..bdec66e42d 100644
--- a/docs/en/guides/object-counting.md
+++ b/docs/en/guides/object-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, YOLOv8, Ultralytics, real-time object detection, AI,
## What is Object Counting?
-Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and deep learning capabilities.
+Object counting with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves accurate identification and counting of specific objects in videos and camera streams. YOLOv8 excels in real-time applications, providing efficient and precise object counting for various scenarios like crowd analysis and surveillance, thanks to its state-of-the-art algorithms and [deep learning](https://www.ultralytics.com/glossary/deep-learning-dl) capabilities.
 @@ -151,7 +151,7 @@ Data preprocessing is essential in computer vision projects because it ensures t
### How can I use Ultralytics YOLO for data augmentation?
-For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce overfitting, and improve model generalization.
+For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce [overfitting](https://www.ultralytics.com/glossary/overfitting), and improve model generalization.
### What are the best data normalization techniques for computer vision data?
@@ -164,7 +164,7 @@ For YOLOv8, normalization is handled automatically, including conversion to RGB
### How should I split my annotated dataset for training?
-To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or TensorFlow for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
+To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
### Can I handle varying image sizes in YOLOv8 without manual resizing?
diff --git a/docs/en/guides/queue-management.md b/docs/en/guides/queue-management.md
index 993d414102..9fb4897edf 100644
--- a/docs/en/guides/queue-management.md
+++ b/docs/en/guides/queue-management.md
@@ -187,7 +187,7 @@ Using Ultralytics YOLOv8 for queue management offers several benefits:
For more details, explore our [Queue Management](https://docs.ultralytics.com/reference/solutions/queue_management/) solutions.
-### Why should I choose Ultralytics YOLOv8 over competitors like TensorFlow or Detectron2 for queue management?
+### Why should I choose Ultralytics YOLOv8 over competitors like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) or Detectron2 for queue management?
Ultralytics YOLOv8 has several advantages over TensorFlow and Detectron2 for queue management:
diff --git a/docs/en/guides/raspberry-pi.md b/docs/en/guides/raspberry-pi.md
index 25d45068a8..c25557e8a3 100644
--- a/docs/en/guides/raspberry-pi.md
+++ b/docs/en/guides/raspberry-pi.md
@@ -49,7 +49,7 @@ The first thing to do after getting your hands on a Raspberry Pi is to flash a m
## Set Up Ultralytics
-There are two ways of setting up Ultralytics package on Raspberry Pi to build your next Computer Vision project. You can use either of them.
+There are two ways of setting up Ultralytics package on Raspberry Pi to build your next [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) project. You can use either of them.
- [Start with Docker](#start-with-docker)
- [Start without Docker](#start-without-docker)
@@ -70,7 +70,7 @@ After this is done, skip to [Use NCNN on Raspberry Pi section](#use-ncnn-on-rasp
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the PyTorch models to other different formats.
+Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats.
1. Update packages list, install pip and upgrade to latest
@@ -136,7 +136,7 @@ The YOLOv8n model in PyTorch format is converted to NCNN to run inference with t
## Raspberry Pi 5 vs Raspberry Pi 4 YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
!!! note
diff --git a/docs/en/guides/region-counting.md b/docs/en/guides/region-counting.md
index f2be9d4574..a27c2b4e53 100644
--- a/docs/en/guides/region-counting.md
+++ b/docs/en/guides/region-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, effici
## What is Object Counting in Regions?
-[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced computer vision. This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
+[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
@@ -151,7 +151,7 @@ Data preprocessing is essential in computer vision projects because it ensures t
### How can I use Ultralytics YOLO for data augmentation?
-For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce overfitting, and improve model generalization.
+For data augmentation with Ultralytics YOLOv8, you need to modify the dataset configuration file (.yaml). In this file, you can specify various augmentation techniques such as random crops, horizontal flips, and brightness adjustments. This can be effectively done using the training configurations [explained here](../modes/train.md). Data augmentation helps create a more robust dataset, reduce [overfitting](https://www.ultralytics.com/glossary/overfitting), and improve model generalization.
### What are the best data normalization techniques for computer vision data?
@@ -164,7 +164,7 @@ For YOLOv8, normalization is handled automatically, including conversion to RGB
### How should I split my annotated dataset for training?
-To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or TensorFlow for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
+To split your dataset, a common practice is to divide it into 70% for training, 20% for validation, and 10% for testing. It is important to maintain the data distribution of classes across these splits and avoid data leakage by performing augmentation only on the training set. Use tools like scikit-learn or [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) for efficient dataset splitting. See the detailed guide on [dataset preparation](../guides/data-collection-and-annotation.md).
### Can I handle varying image sizes in YOLOv8 without manual resizing?
diff --git a/docs/en/guides/queue-management.md b/docs/en/guides/queue-management.md
index 993d414102..9fb4897edf 100644
--- a/docs/en/guides/queue-management.md
+++ b/docs/en/guides/queue-management.md
@@ -187,7 +187,7 @@ Using Ultralytics YOLOv8 for queue management offers several benefits:
For more details, explore our [Queue Management](https://docs.ultralytics.com/reference/solutions/queue_management/) solutions.
-### Why should I choose Ultralytics YOLOv8 over competitors like TensorFlow or Detectron2 for queue management?
+### Why should I choose Ultralytics YOLOv8 over competitors like [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) or Detectron2 for queue management?
Ultralytics YOLOv8 has several advantages over TensorFlow and Detectron2 for queue management:
diff --git a/docs/en/guides/raspberry-pi.md b/docs/en/guides/raspberry-pi.md
index 25d45068a8..c25557e8a3 100644
--- a/docs/en/guides/raspberry-pi.md
+++ b/docs/en/guides/raspberry-pi.md
@@ -49,7 +49,7 @@ The first thing to do after getting your hands on a Raspberry Pi is to flash a m
## Set Up Ultralytics
-There are two ways of setting up Ultralytics package on Raspberry Pi to build your next Computer Vision project. You can use either of them.
+There are two ways of setting up Ultralytics package on Raspberry Pi to build your next [Computer Vision](https://www.ultralytics.com/glossary/computer-vision-cv) project. You can use either of them.
- [Start with Docker](#start-with-docker)
- [Start without Docker](#start-without-docker)
@@ -70,7 +70,7 @@ After this is done, skip to [Use NCNN on Raspberry Pi section](#use-ncnn-on-rasp
#### Install Ultralytics Package
-Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the PyTorch models to other different formats.
+Here we will install Ultralytics package on the Raspberry Pi with optional dependencies so that we can export the [PyTorch](https://www.ultralytics.com/glossary/pytorch) models to other different formats.
1. Update packages list, install pip and upgrade to latest
@@ -136,7 +136,7 @@ The YOLOv8n model in PyTorch format is converted to NCNN to run inference with t
## Raspberry Pi 5 vs Raspberry Pi 4 YOLOv8 Benchmarks
-YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and accuracy: PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 precision with default input image size of 640.
+YOLOv8 benchmarks were run by the Ultralytics team on nine different model formats measuring speed and [accuracy](https://www.ultralytics.com/glossary/accuracy): PyTorch, TorchScript, ONNX, OpenVINO, TF SavedModel, TF GraphDef, TF Lite, PaddlePaddle, NCNN. Benchmarks were run on both Raspberry Pi 5 and Raspberry Pi 4 at FP32 [precision](https://www.ultralytics.com/glossary/precision) with default input image size of 640.
!!! note
diff --git a/docs/en/guides/region-counting.md b/docs/en/guides/region-counting.md
index f2be9d4574..a27c2b4e53 100644
--- a/docs/en/guides/region-counting.md
+++ b/docs/en/guides/region-counting.md
@@ -8,7 +8,7 @@ keywords: object counting, regions, YOLOv8, computer vision, Ultralytics, effici
## What is Object Counting in Regions?
-[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced computer vision. This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
+[Object counting](../guides/object-counting.md) in regions with [Ultralytics YOLOv8](https://github.com/ultralytics/ultralytics/) involves precisely determining the number of objects within specified areas using advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv). This approach is valuable for optimizing processes, enhancing security, and improving efficiency in various applications.
 @@ -360,7 +360,7 @@ A point cloud is a collection of data points defined within a three-dimensional
Point Clouds can be obtained using various sensors:
- 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-precision 3D maps.
+ 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-[precision](https://www.ultralytics.com/glossary/precision) 3D maps.
2. **Depth Cameras**: Capture depth information for each pixel, allowing for 3D reconstruction of the scene.
3. **Stereo Cameras**: Utilize two or more cameras to obtain depth information through triangulation.
4. **Structured Light Scanners**: Project a known pattern onto a surface and measure the deformation to calculate depth.
diff --git a/docs/en/guides/sahi-tiled-inference.md b/docs/en/guides/sahi-tiled-inference.md
index 6b23b21c7f..1137d6b84f 100644
--- a/docs/en/guides/sahi-tiled-inference.md
+++ b/docs/en/guides/sahi-tiled-inference.md
@@ -6,7 +6,7 @@ keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, High-re
# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
-Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
+Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced [object detection](https://www.ultralytics.com/glossary/object-detection) performance.
@@ -360,7 +360,7 @@ A point cloud is a collection of data points defined within a three-dimensional
Point Clouds can be obtained using various sensors:
- 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-precision 3D maps.
+ 1. **LIDAR (Light Detection and Ranging)**: Uses laser pulses to measure distances to objects and create high-[precision](https://www.ultralytics.com/glossary/precision) 3D maps.
2. **Depth Cameras**: Capture depth information for each pixel, allowing for 3D reconstruction of the scene.
3. **Stereo Cameras**: Utilize two or more cameras to obtain depth information through triangulation.
4. **Structured Light Scanners**: Project a known pattern onto a surface and measure the deformation to calculate depth.
diff --git a/docs/en/guides/sahi-tiled-inference.md b/docs/en/guides/sahi-tiled-inference.md
index 6b23b21c7f..1137d6b84f 100644
--- a/docs/en/guides/sahi-tiled-inference.md
+++ b/docs/en/guides/sahi-tiled-inference.md
@@ -6,7 +6,7 @@ keywords: YOLOv8, SAHI, Sliced Inference, Object Detection, Ultralytics, High-re
# Ultralytics Docs: Using YOLOv8 with SAHI for Sliced Inference
-Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced object detection performance.
+Welcome to the Ultralytics documentation on how to use YOLOv8 with [SAHI](https://github.com/obss/sahi) (Slicing Aided Hyper Inference). This comprehensive guide aims to furnish you with all the essential knowledge you'll need to implement SAHI alongside YOLOv8. We'll deep-dive into what SAHI is, why sliced inference is critical for large-scale applications, and how to integrate these functionalities with YOLOv8 for enhanced [object detection](https://www.ultralytics.com/glossary/object-detection) performance.
 @@ -31,7 +31,7 @@ SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimi
- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
-- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
+- **High [Accuracy](https://www.ultralytics.com/glossary/accuracy)**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
## What is Sliced Inference?
@@ -202,7 +202,7 @@ If you use SAHI in your research or development work, please cite the original S
}
```
-We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
+We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
## FAQ
diff --git a/docs/en/guides/security-alarm-system.md b/docs/en/guides/security-alarm-system.md
index 4b5cdeebd2..d90e44a583 100644
--- a/docs/en/guides/security-alarm-system.md
+++ b/docs/en/guides/security-alarm-system.md
@@ -8,10 +8,10 @@ keywords: YOLOv8, Security Alarm System, real-time object detection, Ultralytics
@@ -31,7 +31,7 @@ SAHI (Slicing Aided Hyper Inference) is an innovative library designed to optimi
- **Seamless Integration**: SAHI integrates effortlessly with YOLO models, meaning you can start slicing and detecting without a lot of code modification.
- **Resource Efficiency**: By breaking down large images into smaller parts, SAHI optimizes the memory usage, allowing you to run high-quality detection on hardware with limited resources.
-- **High Accuracy**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
+- **High [Accuracy](https://www.ultralytics.com/glossary/accuracy)**: SAHI maintains the detection accuracy by employing smart algorithms to merge overlapping detection boxes during the stitching process.
## What is Sliced Inference?
@@ -202,7 +202,7 @@ If you use SAHI in your research or development work, please cite the original S
}
```
-We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the computer vision community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
+We extend our thanks to the SAHI research group for creating and maintaining this invaluable resource for the [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) community. For more information about SAHI and its creators, visit the [SAHI GitHub repository](https://github.com/obss/sahi).
## FAQ
diff --git a/docs/en/guides/security-alarm-system.md b/docs/en/guides/security-alarm-system.md
index 4b5cdeebd2..d90e44a583 100644
--- a/docs/en/guides/security-alarm-system.md
+++ b/docs/en/guides/security-alarm-system.md
@@ -8,10 +8,10 @@ keywords: YOLOv8, Security Alarm System, real-time object detection, Ultralytics
 -The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
+The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
- **Real-time Detection:** YOLOv8's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
-- **Accuracy:** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
+- **[Accuracy](https://www.ultralytics.com/glossary/accuracy):** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.
-The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced computer vision capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
+The Security Alarm System Project utilizing Ultralytics YOLOv8 integrates advanced [computer vision](https://www.ultralytics.com/glossary/computer-vision-cv) capabilities to enhance security measures. YOLOv8, developed by Ultralytics, provides real-time object detection, allowing the system to identify and respond to potential security threats promptly. This project offers several advantages:
- **Real-time Detection:** YOLOv8's efficiency enables the Security Alarm System to detect and respond to security incidents in real-time, minimizing response time.
-- **Accuracy:** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
+- **[Accuracy](https://www.ultralytics.com/glossary/accuracy):** YOLOv8 is known for its accuracy in object detection, reducing false positives and enhancing the reliability of the security alarm system.
- **Integration Capabilities:** The project can be seamlessly integrated with existing security infrastructure, providing an upgraded layer of intelligent surveillance.

 @@ -102,14 +102,14 @@ However, if you choose to collect images or take your own pictures, you'll need
[Data collection and annotation](./data-collection-and-annotation.md) can be a time-consuming manual effort. Annotation tools can help make this process easier. Here are some useful open annotation tools: [LabeI Studio](https://github.com/HumanSignal/label-studio), [CVAT](https://github.com/cvat-ai/cvat), and [Labelme](https://github.com/labelmeai/labelme).
-## Step 3: Data Augmentation and Splitting Your Dataset
+## Step 3: [Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation) and Splitting Your Dataset
After collecting and annotating your image data, it's important to first split your dataset into training, validation, and test sets before performing data augmentation. Splitting your dataset before augmentation is crucial to test and validate your model on original, unaltered data. It helps accurately assess how well the model generalizes to new, unseen data.
Here's how to split your data:
- **Training Set:** It is the largest portion of your data, typically 70-80% of the total, used to train your model.
-- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent overfitting.
+- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent [overfitting](https://www.ultralytics.com/glossary/overfitting).
- **Test Set:** The remaining 10-15% of your data is set aside as the test set. It is used to evaluate the model's performance on unseen data after training is complete.
After splitting your data, you can perform data augmentation by applying transformations like rotating, scaling, and flipping images to artificially increase the size of your dataset. Data augmentation makes your model more robust to variations and improves its performance on unseen images.
@@ -118,7 +118,7 @@ After splitting your data, you can perform data augmentation by applying transfo
@@ -102,14 +102,14 @@ However, if you choose to collect images or take your own pictures, you'll need
[Data collection and annotation](./data-collection-and-annotation.md) can be a time-consuming manual effort. Annotation tools can help make this process easier. Here are some useful open annotation tools: [LabeI Studio](https://github.com/HumanSignal/label-studio), [CVAT](https://github.com/cvat-ai/cvat), and [Labelme](https://github.com/labelmeai/labelme).
-## Step 3: Data Augmentation and Splitting Your Dataset
+## Step 3: [Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation) and Splitting Your Dataset
After collecting and annotating your image data, it's important to first split your dataset into training, validation, and test sets before performing data augmentation. Splitting your dataset before augmentation is crucial to test and validate your model on original, unaltered data. It helps accurately assess how well the model generalizes to new, unseen data.
Here's how to split your data:
- **Training Set:** It is the largest portion of your data, typically 70-80% of the total, used to train your model.
-- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent overfitting.
+- **Validation Set:** Usually around 10-15% of your data; this set is used to tune hyperparameters and validate the model during training, helping to prevent [overfitting](https://www.ultralytics.com/glossary/overfitting).
- **Test Set:** The remaining 10-15% of your data is set aside as the test set. It is used to evaluate the model's performance on unseen data after training is complete.
After splitting your data, you can perform data augmentation by applying transformations like rotating, scaling, and flipping images to artificially increase the size of your dataset. Data augmentation makes your model more robust to variations and improves its performance on unseen images.
@@ -118,7 +118,7 @@ After splitting your data, you can perform data augmentation by applying transfo


 -The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
+The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
-The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes TensorFlow Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
+The Ultralytics Android App is a powerful tool that allows you to run YOLO models directly on your Android device for real-time object detection. This app utilizes [TensorFlow](https://www.ultralytics.com/glossary/tensorflow) Lite for model optimization and various hardware delegates for acceleration, enabling fast and efficient object detection.
 -Instance segmentation goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
+[Instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
The output of an instance segmentation model is a set of masks or contours that outline each object in the image, along with class labels and confidence scores for each object. Instance segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
@@ -47,7 +47,7 @@ YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models
## Train
-Train YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
+Train YOLOv8n-seg on the COCO128-seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
@@ -84,7 +84,7 @@ YOLO segmentation dataset format can be found in detail in the [Dataset Guide](.
## Val
-Validate trained YOLOv8n-seg model accuracy on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n-seg model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
@@ -204,7 +204,7 @@ To train a YOLOv8 segmentation model on a custom dataset, you first need to prep
Check the [Configuration](../usage/cfg.md) page for more available arguments.
-### What is the difference between object detection and instance segmentation in YOLOv8?
+### What is the difference between [object detection](https://www.ultralytics.com/glossary/object-detection) and instance segmentation in YOLOv8?
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, whereas instance segmentation not only identifies the bounding boxes but also delineates the exact shape of each object. YOLOv8 instance segmentation models provide masks or contours that outline each detected object, which is particularly useful for tasks where knowing the precise shape of objects is important, such as medical imaging or autonomous driving.
@@ -238,7 +238,7 @@ Loading and validating a pretrained YOLOv8 segmentation model is straightforward
yolo segment val model=yolov8n-seg.pt
```
-These steps will provide you with validation metrics like Mean Average Precision (mAP), crucial for assessing model performance.
+These steps will provide you with validation metrics like [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP), crucial for assessing model performance.
### How can I export a YOLOv8 segmentation model to ONNX format?
diff --git a/docs/en/usage/callbacks.md b/docs/en/usage/callbacks.md
index 083b65879f..2886f8f512 100644
--- a/docs/en/usage/callbacks.md
+++ b/docs/en/usage/callbacks.md
@@ -57,22 +57,22 @@ Here are all supported callbacks. See callbacks [source code](https://github.com
### Trainer Callbacks
-| Callback | Description |
-| --------------------------- | ------------------------------------------------------- |
-| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
-| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
-| `on_train_start` | Triggered when the training starts |
-| `on_train_epoch_start` | Triggered at the start of each training epoch |
-| `on_train_batch_start` | Triggered at the start of each training batch |
-| `optimizer_step` | Triggered during the optimizer step |
-| `on_before_zero_grad` | Triggered before gradients are zeroed |
-| `on_train_batch_end` | Triggered at the end of each training batch |
-| `on_train_epoch_end` | Triggered at the end of each training epoch |
-| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
-| `on_model_save` | Triggered when the model is saved |
-| `on_train_end` | Triggered when the training process ends |
-| `on_params_update` | Triggered when model parameters are updated |
-| `teardown` | Triggered when the training process is being cleaned up |
+| Callback | Description |
+| --------------------------- | ------------------------------------------------------------------------------------------- |
+| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
+| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
+| `on_train_start` | Triggered when the training starts |
+| `on_train_epoch_start` | Triggered at the start of each training [epoch](https://www.ultralytics.com/glossary/epoch) |
+| `on_train_batch_start` | Triggered at the start of each training batch |
+| `optimizer_step` | Triggered during the optimizer step |
+| `on_before_zero_grad` | Triggered before gradients are zeroed |
+| `on_train_batch_end` | Triggered at the end of each training batch |
+| `on_train_epoch_end` | Triggered at the end of each training epoch |
+| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
+| `on_model_save` | Triggered when the model is saved |
+| `on_train_end` | Triggered when the training process ends |
+| `on_params_update` | Triggered when model parameters are updated |
+| `teardown` | Triggered when the training process is being cleaned up |
### Validator Callbacks
@@ -199,7 +199,7 @@ For more comprehensive usage, refer to the [Prediction Guide](../modes/predict.m
Ultralytics YOLO supports various practical implementations of callbacks to enhance and customize different phases like training, validation, and prediction. Some practical examples include:
1. **Logging Custom Metrics**: Log additional metrics at different stages, such as the end of training or validation epochs.
-2. **Data Augmentation**: Implement custom data transformations or augmentations during prediction or training batches.
+2. **[Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation)**: Implement custom data transformations or augmentations during prediction or training batches.
3. **Intermediate Results**: Save intermediate results such as predictions or frames for further analysis or visualization.
Example: Combining frames with prediction results during prediction using `on_predict_batch_end`:
diff --git a/docs/en/usage/cfg.md b/docs/en/usage/cfg.md
index 2d0ce1dd94..aecc5fc646 100644
--- a/docs/en/usage/cfg.md
+++ b/docs/en/usage/cfg.md
@@ -4,7 +4,7 @@ description: Optimize your YOLO model's performance with the right settings and
keywords: YOLO, hyperparameters, configuration, training, validation, prediction, model settings, Ultralytics, performance optimization, machine learning
---
-YOLO settings and hyperparameters play a critical role in the model's performance, speed, and accuracy. These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
+YOLO settings and hyperparameters play a critical role in the model's performance, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy). These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
-Instance segmentation goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
+[Instance segmentation](https://www.ultralytics.com/glossary/instance-segmentation) goes a step further than object detection and involves identifying individual objects in an image and segmenting them from the rest of the image.
The output of an instance segmentation model is a set of masks or contours that outline each object in the image, along with class labels and confidence scores for each object. Instance segmentation is useful when you need to know not only where objects are in an image, but also what their exact shape is.
@@ -47,7 +47,7 @@ YOLOv8 pretrained Segment models are shown here. Detect, Segment and Pose models
## Train
-Train YOLOv8n-seg on the COCO128-seg dataset for 100 epochs at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
+Train YOLOv8n-seg on the COCO128-seg dataset for 100 [epochs](https://www.ultralytics.com/glossary/epoch) at image size 640. For a full list of available arguments see the [Configuration](../usage/cfg.md) page.
!!! example
@@ -84,7 +84,7 @@ YOLO segmentation dataset format can be found in detail in the [Dataset Guide](.
## Val
-Validate trained YOLOv8n-seg model accuracy on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
+Validate trained YOLOv8n-seg model [accuracy](https://www.ultralytics.com/glossary/accuracy) on the COCO128-seg dataset. No arguments are needed as the `model` retains its training `data` and arguments as model attributes.
!!! example
@@ -204,7 +204,7 @@ To train a YOLOv8 segmentation model on a custom dataset, you first need to prep
Check the [Configuration](../usage/cfg.md) page for more available arguments.
-### What is the difference between object detection and instance segmentation in YOLOv8?
+### What is the difference between [object detection](https://www.ultralytics.com/glossary/object-detection) and instance segmentation in YOLOv8?
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, whereas instance segmentation not only identifies the bounding boxes but also delineates the exact shape of each object. YOLOv8 instance segmentation models provide masks or contours that outline each detected object, which is particularly useful for tasks where knowing the precise shape of objects is important, such as medical imaging or autonomous driving.
@@ -238,7 +238,7 @@ Loading and validating a pretrained YOLOv8 segmentation model is straightforward
yolo segment val model=yolov8n-seg.pt
```
-These steps will provide you with validation metrics like Mean Average Precision (mAP), crucial for assessing model performance.
+These steps will provide you with validation metrics like [Mean Average Precision](https://www.ultralytics.com/glossary/mean-average-precision-map) (mAP), crucial for assessing model performance.
### How can I export a YOLOv8 segmentation model to ONNX format?
diff --git a/docs/en/usage/callbacks.md b/docs/en/usage/callbacks.md
index 083b65879f..2886f8f512 100644
--- a/docs/en/usage/callbacks.md
+++ b/docs/en/usage/callbacks.md
@@ -57,22 +57,22 @@ Here are all supported callbacks. See callbacks [source code](https://github.com
### Trainer Callbacks
-| Callback | Description |
-| --------------------------- | ------------------------------------------------------- |
-| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
-| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
-| `on_train_start` | Triggered when the training starts |
-| `on_train_epoch_start` | Triggered at the start of each training epoch |
-| `on_train_batch_start` | Triggered at the start of each training batch |
-| `optimizer_step` | Triggered during the optimizer step |
-| `on_before_zero_grad` | Triggered before gradients are zeroed |
-| `on_train_batch_end` | Triggered at the end of each training batch |
-| `on_train_epoch_end` | Triggered at the end of each training epoch |
-| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
-| `on_model_save` | Triggered when the model is saved |
-| `on_train_end` | Triggered when the training process ends |
-| `on_params_update` | Triggered when model parameters are updated |
-| `teardown` | Triggered when the training process is being cleaned up |
+| Callback | Description |
+| --------------------------- | ------------------------------------------------------------------------------------------- |
+| `on_pretrain_routine_start` | Triggered at the beginning of pre-training routine |
+| `on_pretrain_routine_end` | Triggered at the end of pre-training routine |
+| `on_train_start` | Triggered when the training starts |
+| `on_train_epoch_start` | Triggered at the start of each training [epoch](https://www.ultralytics.com/glossary/epoch) |
+| `on_train_batch_start` | Triggered at the start of each training batch |
+| `optimizer_step` | Triggered during the optimizer step |
+| `on_before_zero_grad` | Triggered before gradients are zeroed |
+| `on_train_batch_end` | Triggered at the end of each training batch |
+| `on_train_epoch_end` | Triggered at the end of each training epoch |
+| `on_fit_epoch_end` | Triggered at the end of each fit epoch |
+| `on_model_save` | Triggered when the model is saved |
+| `on_train_end` | Triggered when the training process ends |
+| `on_params_update` | Triggered when model parameters are updated |
+| `teardown` | Triggered when the training process is being cleaned up |
### Validator Callbacks
@@ -199,7 +199,7 @@ For more comprehensive usage, refer to the [Prediction Guide](../modes/predict.m
Ultralytics YOLO supports various practical implementations of callbacks to enhance and customize different phases like training, validation, and prediction. Some practical examples include:
1. **Logging Custom Metrics**: Log additional metrics at different stages, such as the end of training or validation epochs.
-2. **Data Augmentation**: Implement custom data transformations or augmentations during prediction or training batches.
+2. **[Data Augmentation](https://www.ultralytics.com/glossary/data-augmentation)**: Implement custom data transformations or augmentations during prediction or training batches.
3. **Intermediate Results**: Save intermediate results such as predictions or frames for further analysis or visualization.
Example: Combining frames with prediction results during prediction using `on_predict_batch_end`:
diff --git a/docs/en/usage/cfg.md b/docs/en/usage/cfg.md
index 2d0ce1dd94..aecc5fc646 100644
--- a/docs/en/usage/cfg.md
+++ b/docs/en/usage/cfg.md
@@ -4,7 +4,7 @@ description: Optimize your YOLO model's performance with the right settings and
keywords: YOLO, hyperparameters, configuration, training, validation, prediction, model settings, Ultralytics, performance optimization, machine learning
---
-YOLO settings and hyperparameters play a critical role in the model's performance, speed, and accuracy. These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.
+YOLO settings and hyperparameters play a critical role in the model's performance, speed, and [accuracy](https://www.ultralytics.com/glossary/accuracy). These settings and hyperparameters can affect the model's behavior at various stages of the model development process, including training, validation, and prediction.


 -To conclude, YOLOv5 is not only a state-of-the-art tool for object detection but also a testament to the power of machine learning in transforming the way we interact with the world through visual understanding. As you progress through this guide and begin applying YOLOv5 to your projects, remember that you are at the forefront of a technological revolution, capable of achieving remarkable feats. Should you need further insights or support from fellow visionaries, you're invited to our [GitHub repository](https://github.com/ultralytics/yolov5) home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
+To conclude, YOLOv5 is not only a state-of-the-art tool for object detection but also a testament to the power of [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) in transforming the way we interact with the world through visual understanding. As you progress through this guide and begin applying YOLOv5 to your projects, remember that you are at the forefront of a technological revolution, capable of achieving remarkable feats. Should you need further insights or support from fellow visionaries, you're invited to our [GitHub repository](https://github.com/ultralytics/yolov5) home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
diff --git a/docs/en/yolov5/tutorials/architecture_description.md b/docs/en/yolov5/tutorials/architecture_description.md
index bb9ade6976..53788270ce 100644
--- a/docs/en/yolov5/tutorials/architecture_description.md
+++ b/docs/en/yolov5/tutorials/architecture_description.md
@@ -6,7 +6,7 @@ keywords: YOLOv5 architecture, object detection, Ultralytics, YOLO, model struct
# Ultralytics YOLOv5 Architecture
-YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
+YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and [image recognition](https://www.ultralytics.com/glossary/image-recognition).
## 1. Model Structure
@@ -104,9 +104,9 @@ SPPF time: 0.20780706405639648
## 2. Data Augmentation Techniques
-YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce overfitting. These techniques include:
+YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce [overfitting](https://www.ultralytics.com/glossary/overfitting). These techniques include:
-- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage object detection models to better handle various object scales and translations.
+- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage [object detection](https://www.ultralytics.com/glossary/object-detection) models to better handle various object scales and translations.

@@ -138,9 +138,9 @@ YOLOv5 applies several sophisticated training strategies to enhance the model's
- **Multiscale Training**: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
- **AutoAnchor**: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
-- **Warmup and Cosine LR Scheduler**: A method to adjust the learning rate to enhance model performance.
+- **Warmup and Cosine LR Scheduler**: A method to adjust the [learning rate](https://www.ultralytics.com/glossary/learning-rate) to enhance model performance.
- **Exponential Moving Average (EMA)**: A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
-- **Mixed Precision Training**: A method to perform operations in half-precision format, reducing memory usage and enhancing computational speed.
+- **[Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision) Training**: A method to perform operations in half-[precision](https://www.ultralytics.com/glossary/precision) format, reducing memory usage and enhancing computational speed.
- **Hyperparameter Evolution**: A strategy to automatically tune hyperparameters to achieve optimal performance.
## 4. Additional Features
@@ -153,7 +153,7 @@ The loss in YOLOv5 is computed as a combination of three individual loss compone
- **Objectness Loss (BCE Loss)**: Another Binary Cross-Entropy loss, calculates the error in detecting whether an object is present in a particular grid cell or not.
- **Location Loss (CIoU Loss)**: Complete IoU loss, measures the error in localizing the object within the grid cell.
-The overall loss function is depicted by:
+The overall [loss function](https://www.ultralytics.com/glossary/loss-function) is depicted by:

@@ -176,7 +176,7 @@ The YOLOv5 architecture makes some important changes to the box prediction strat
However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
-The revised formulas for calculating the predicted bounding box are as follows:
+The revised formulas for calculating the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) are as follows:
 home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
+To conclude, YOLOv5 is not only a state-of-the-art tool for object detection but also a testament to the power of [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) in transforming the way we interact with the world through visual understanding. As you progress through this guide and begin applying YOLOv5 to your projects, remember that you are at the forefront of a technological revolution, capable of achieving remarkable feats. Should you need further insights or support from fellow visionaries, you're invited to our [GitHub repository](https://github.com/ultralytics/yolov5) home to a thriving community of developers and researchers. Keep exploring, keep innovating, and enjoy the marvels of YOLOv5. Happy detecting! 🌠🔍
diff --git a/docs/en/yolov5/tutorials/architecture_description.md b/docs/en/yolov5/tutorials/architecture_description.md
index bb9ade6976..53788270ce 100644
--- a/docs/en/yolov5/tutorials/architecture_description.md
+++ b/docs/en/yolov5/tutorials/architecture_description.md
@@ -6,7 +6,7 @@ keywords: YOLOv5 architecture, object detection, Ultralytics, YOLO, model struct
# Ultralytics YOLOv5 Architecture
-YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, data augmentation strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and image recognition.
+YOLOv5 (v6.0/6.1) is a powerful object detection algorithm developed by Ultralytics. This article dives deep into the YOLOv5 architecture, [data augmentation](https://www.ultralytics.com/glossary/data-augmentation) strategies, training methodologies, and loss computation techniques. This comprehensive understanding will help improve your practical application of object detection in various fields, including surveillance, autonomous vehicles, and [image recognition](https://www.ultralytics.com/glossary/image-recognition).
## 1. Model Structure
@@ -104,9 +104,9 @@ SPPF time: 0.20780706405639648
## 2. Data Augmentation Techniques
-YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce overfitting. These techniques include:
+YOLOv5 employs various data augmentation techniques to improve the model's ability to generalize and reduce [overfitting](https://www.ultralytics.com/glossary/overfitting). These techniques include:
-- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage object detection models to better handle various object scales and translations.
+- **Mosaic Augmentation**: An image processing technique that combines four training images into one in ways that encourage [object detection](https://www.ultralytics.com/glossary/object-detection) models to better handle various object scales and translations.

@@ -138,9 +138,9 @@ YOLOv5 applies several sophisticated training strategies to enhance the model's
- **Multiscale Training**: The input images are randomly rescaled within a range of 0.5 to 1.5 times their original size during the training process.
- **AutoAnchor**: This strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes in your custom data.
-- **Warmup and Cosine LR Scheduler**: A method to adjust the learning rate to enhance model performance.
+- **Warmup and Cosine LR Scheduler**: A method to adjust the [learning rate](https://www.ultralytics.com/glossary/learning-rate) to enhance model performance.
- **Exponential Moving Average (EMA)**: A strategy that uses the average of parameters over past steps to stabilize the training process and reduce generalization error.
-- **Mixed Precision Training**: A method to perform operations in half-precision format, reducing memory usage and enhancing computational speed.
+- **[Mixed Precision](https://www.ultralytics.com/glossary/mixed-precision) Training**: A method to perform operations in half-[precision](https://www.ultralytics.com/glossary/precision) format, reducing memory usage and enhancing computational speed.
- **Hyperparameter Evolution**: A strategy to automatically tune hyperparameters to achieve optimal performance.
## 4. Additional Features
@@ -153,7 +153,7 @@ The loss in YOLOv5 is computed as a combination of three individual loss compone
- **Objectness Loss (BCE Loss)**: Another Binary Cross-Entropy loss, calculates the error in detecting whether an object is present in a particular grid cell or not.
- **Location Loss (CIoU Loss)**: Complete IoU loss, measures the error in localizing the object within the grid cell.
-The overall loss function is depicted by:
+The overall [loss function](https://www.ultralytics.com/glossary/loss-function) is depicted by:

@@ -176,7 +176,7 @@ The YOLOv5 architecture makes some important changes to the box prediction strat
However, in YOLOv5, the formula for predicting the box coordinates has been updated to reduce grid sensitivity and prevent the model from predicting unbounded box dimensions.
-The revised formulas for calculating the predicted bounding box are as follows:
+The revised formulas for calculating the predicted [bounding box](https://www.ultralytics.com/glossary/bounding-box) are as follows:

 @@ -122,7 +122,7 @@ apt-get install libgl1
#### HTTP Server
-DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
+DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including [object detection](https://www.ultralytics.com/glossary/object-detection) with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
Spin up the Server with the pruned-quantized YOLOv5s:
diff --git a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
index b00d94db4c..27e26f144f 100644
--- a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
+++ b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
@@ -4,7 +4,7 @@ description: Learn how to load YOLOv5 from PyTorch Hub for seamless model infere
keywords: YOLOv5, PyTorch Hub, model loading, Ultralytics, object detection, machine learning, AI, tutorial, inference
---
-📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
+📚 This guide explains how to load YOLOv5 🚀 from [PyTorch](https://www.ultralytics.com/glossary/pytorch) Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
## Before You Start
@@ -44,7 +44,7 @@ results.pandas().xyxy[0]
### Detailed Example
-This example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
+This example shows **batched inference** with **PIL** and **[OpenCV](https://www.ultralytics.com/glossary/opencv)** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
```python
import cv2
diff --git a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
index 3047e48c2e..55728f21e7 100644
--- a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
+++ b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
@@ -52,7 +52,7 @@ We have released a custom training tutorial demonstrating all of the above capab
## Active Learning
-The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
+The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your [model deployments](https://www.ultralytics.com/glossary/model-deployment) by using a battle tested [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) pipeline.
@@ -122,7 +122,7 @@ apt-get install libgl1
#### HTTP Server
-DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including object detection with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
+DeepSparse Server runs on top of the popular FastAPI web framework and Uvicorn web server. With just a single CLI command, you can easily setup a model service endpoint with DeepSparse. The Server supports any Pipeline from DeepSparse, including [object detection](https://www.ultralytics.com/glossary/object-detection) with YOLOv5, enabling you to send raw images to the endpoint and receive the bounding boxes.
Spin up the Server with the pruned-quantized YOLOv5s:
diff --git a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
index b00d94db4c..27e26f144f 100644
--- a/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
+++ b/docs/en/yolov5/tutorials/pytorch_hub_model_loading.md
@@ -4,7 +4,7 @@ description: Learn how to load YOLOv5 from PyTorch Hub for seamless model infere
keywords: YOLOv5, PyTorch Hub, model loading, Ultralytics, object detection, machine learning, AI, tutorial, inference
---
-📚 This guide explains how to load YOLOv5 🚀 from PyTorch Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
+📚 This guide explains how to load YOLOv5 🚀 from [PyTorch](https://www.ultralytics.com/glossary/pytorch) Hub at [https://pytorch.org/hub/ultralytics_yolov5](https://pytorch.org/hub/ultralytics_yolov5/).
## Before You Start
@@ -44,7 +44,7 @@ results.pandas().xyxy[0]
### Detailed Example
-This example shows **batched inference** with **PIL** and **OpenCV** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
+This example shows **batched inference** with **PIL** and **[OpenCV](https://www.ultralytics.com/glossary/opencv)** image sources. `results` can be **printed** to console, **saved** to `runs/hub`, **showed** to screen on supported environments, and returned as **tensors** or **pandas** dataframes.
```python
import cv2
diff --git a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
index 3047e48c2e..55728f21e7 100644
--- a/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
+++ b/docs/en/yolov5/tutorials/roboflow_datasets_integration.md
@@ -52,7 +52,7 @@ We have released a custom training tutorial demonstrating all of the above capab
## Active Learning
-The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your model deployments by using a battle tested machine learning pipeline.
+The real world is messy and your model will invariably encounter situations your dataset didn't anticipate. Using [active learning](https://blog.roboflow.com/what-is-active-learning/?ref=ultralytics) is an important strategy to iteratively improve your dataset and model. With the Roboflow and YOLOv5 integration, you can quickly make improvements on your [model deployments](https://www.ultralytics.com/glossary/model-deployment) by using a battle tested [machine learning](https://www.ultralytics.com/glossary/machine-learning-ml) pipeline.

 -Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+Results file `results.csv` is updated after each [epoch](https://www.ultralytics.com/glossary/epoch), and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
```python
from utils.plots import plot_results
@@ -202,8 +202,8 @@ plot_results("path/to/results.csv") # plot 'results.csv' as 'results.png'
Once your model is trained you can use your best checkpoint `best.pt` to:
- Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](./pytorch_hub_model_loading.md) inference on new images and videos
-- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
-- [Export](./model_export.md) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
+- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) [accuracy](https://www.ultralytics.com/glossary/accuracy) on train, val and test splits
+- [Export](./model_export.md) to [TensorFlow](https://www.ultralytics.com/glossary/tensorflow), Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
- [Evolve](./hyperparameter_evolution.md) hyperparameters to improve performance
- [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
diff --git a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
index be6a087015..9e689ad3eb 100644
--- a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
+++ b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
@@ -4,7 +4,7 @@ description: Learn to freeze YOLOv5 layers for efficient transfer learning, redu
keywords: YOLOv5, transfer learning, freeze layers, machine learning, deep learning, model training, PyTorch, Ultralytics
---
-📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
+📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **[transfer learning](https://www.ultralytics.com/glossary/transfer-learning)**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
## Before You Start
@@ -121,7 +121,7 @@ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --i
### Accuracy Comparison
-The results show that freezing speeds up training, but reduces final accuracy slightly.
+The results show that freezing speeds up training, but reduces final [accuracy](https://www.ultralytics.com/glossary/accuracy) slightly.

-Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
+Results file `results.csv` is updated after each [epoch](https://www.ultralytics.com/glossary/epoch), and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
```python
from utils.plots import plot_results
@@ -202,8 +202,8 @@ plot_results("path/to/results.csv") # plot 'results.csv' as 'results.png'
Once your model is trained you can use your best checkpoint `best.pt` to:
- Run [CLI](https://github.com/ultralytics/yolov5#quick-start-examples) or [Python](./pytorch_hub_model_loading.md) inference on new images and videos
-- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) accuracy on train, val and test splits
-- [Export](./model_export.md) to TensorFlow, Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
+- [Validate](https://github.com/ultralytics/yolov5/blob/master/val.py) [accuracy](https://www.ultralytics.com/glossary/accuracy) on train, val and test splits
+- [Export](./model_export.md) to [TensorFlow](https://www.ultralytics.com/glossary/tensorflow), Keras, ONNX, TFlite, TF.js, CoreML and TensorRT formats
- [Evolve](./hyperparameter_evolution.md) hyperparameters to improve performance
- [Improve](https://docs.roboflow.com/adding-data/upload-api?ref=ultralytics) your model by sampling real-world images and adding them to your dataset
diff --git a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
index be6a087015..9e689ad3eb 100644
--- a/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
+++ b/docs/en/yolov5/tutorials/transfer_learning_with_frozen_layers.md
@@ -4,7 +4,7 @@ description: Learn to freeze YOLOv5 layers for efficient transfer learning, redu
keywords: YOLOv5, transfer learning, freeze layers, machine learning, deep learning, model training, PyTorch, Ultralytics
---
-📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **transfer learning**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
+📚 This guide explains how to **freeze** YOLOv5 🚀 layers when **[transfer learning](https://www.ultralytics.com/glossary/transfer-learning)**. Transfer learning is a useful way to quickly retrain a model on new data without having to retrain the entire network. Instead, part of the initial weights are frozen in place, and the rest of the weights are used to compute loss and are updated by the optimizer. This requires less resources than normal training and allows for faster training times, though it may also result in reductions to final trained accuracy.
## Before You Start
@@ -121,7 +121,7 @@ train.py --batch 48 --weights yolov5m.pt --data voc.yaml --epochs 50 --cache --i
### Accuracy Comparison
-The results show that freezing speeds up training, but reduces final accuracy slightly.
+The results show that freezing speeds up training, but reduces final [accuracy](https://www.ultralytics.com/glossary/accuracy) slightly.
