commit
33851bb1e5
12 changed files with 207 additions and 10 deletions
@ -0,0 +1,91 @@ |
||||
--- |
||||
comments: true |
||||
description: Brain tumor detection, a leading dataset for medical imaging, integrates with Ultralytics. Discover ways to use it for training YOLO models. |
||||
keywords: Ultralytics, Brain Tumor dataset, object detection, YOLO, YOLO model training, object tracking, computer vision, deep learning models |
||||
--- |
||||
|
||||
# Brain Tumor Dataset |
||||
|
||||
A brain tumor detection dataset consists of medical images from MRI or CT scans, containing information about brain tumor presence, location, and characteristics. This dataset is essential for training computer vision algorithms to automate brain tumor identification, aiding in early diagnosis and treatment planning. |
||||
|
||||
## Dataset Structure |
||||
|
||||
The brain tumor dataset is divided into two subsets: |
||||
|
||||
- **Training set**: Consisting of 893 images, each accompanied by corresponding annotations. |
||||
- **Testing set**: Comprising 223 images, with annotations paired for each one. |
||||
|
||||
## Applications |
||||
|
||||
The application of brain tumor detection using computer vision enables early diagnosis, treatment planning, and monitoring of tumor progression. By analyzing medical imaging data like MRI or CT scans, computer vision systems assist in accurately identifying brain tumors, aiding in timely medical intervention and personalized treatment strategies. |
||||
|
||||
## Dataset YAML |
||||
|
||||
A YAML (Yet Another Markup Language) file is used to define the dataset configuration. It contains information about the dataset's paths, classes, and other relevant information. In the case of the brain tumor dataset, the `brain-tumor.yaml` file is maintained at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/cfg/datasets/brain-tumor.yaml). |
||||
|
||||
!!! Example "ultralytics/cfg/datasets/brain-tumor.yaml" |
||||
|
||||
```yaml |
||||
--8<-- "ultralytics/cfg/datasets/brain-tumor.yaml" |
||||
``` |
||||
|
||||
## Usage |
||||
|
||||
To train a YOLOv8n model on the brain tumor dataset for 100 epochs with an image size of 640, utilize the provided code snippets. For a detailed list of available arguments, consult the model's [Training](../../modes/train.md) page. |
||||
|
||||
!!! Example "Train Example" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load a model |
||||
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training) |
||||
|
||||
# Train the model |
||||
results = model.train(data='brain-tumor.yaml', epochs=100, imgsz=640) |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Start training from a pretrained *.pt model |
||||
yolo detect train data=brain-tumor.yaml model=yolov8n.pt epochs=100 imgsz=640 |
||||
``` |
||||
|
||||
!!! Example "Inference Example" |
||||
|
||||
=== "Python" |
||||
|
||||
```python |
||||
from ultralytics import YOLO |
||||
|
||||
# Load a model |
||||
model = YOLO('path/to/best.pt') # load a brain-tumor fine-tuned model |
||||
|
||||
# Inference using the model |
||||
results = model.predict("https://ultralytics.com/assets/brain-tumor-sample.jpg") |
||||
``` |
||||
|
||||
=== "CLI" |
||||
|
||||
```bash |
||||
# Start prediction with a finetuned *.pt model |
||||
yolo detect predict model='path/to/best.pt' imgsz=640 source="https://ultralytics.com/assets/brain-tumor-sample.jpg" |
||||
``` |
||||
|
||||
|
||||
## Sample Images and Annotations |
||||
|
||||
The brain tumor dataset encompasses a wide array of images featuring diverse object categories and intricate scenes. Presented below are examples of images from the dataset, accompanied by their respective annotations |
||||
|
||||
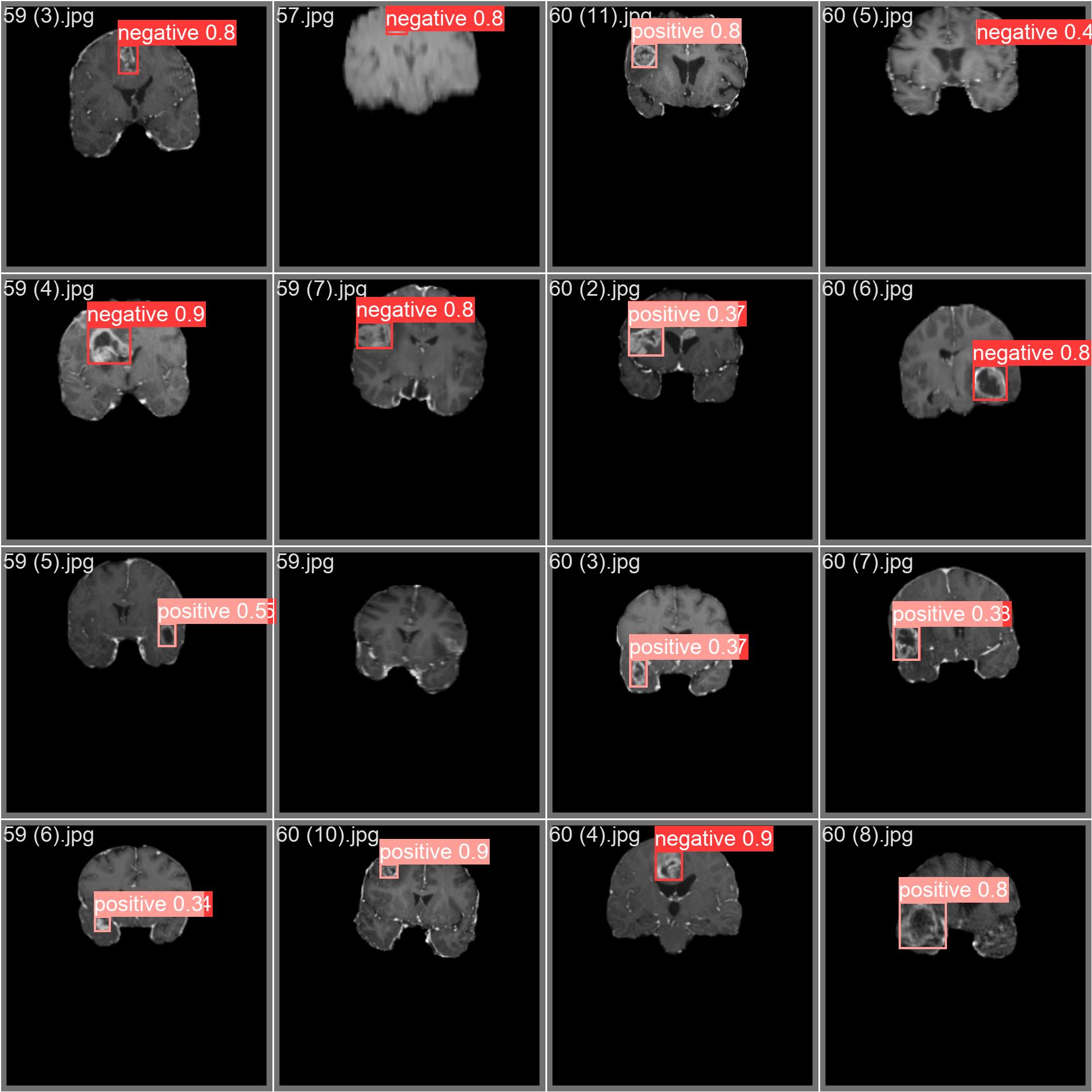 |
||||
|
||||
- **Mosaiced Image**: Displayed here is a training batch comprising mosaiced dataset images. Mosaicing, a training technique, consolidates multiple images into one, enhancing batch diversity. This approach aids in improving the model's capacity to generalize across various object sizes, aspect ratios, and contexts. |
||||
|
||||
This example highlights the diversity and intricacy of images within the brain tumor dataset, underscoring the advantages of incorporating mosaicing during the training phase. |
||||
|
||||
## Citations and Acknowledgments |
||||
|
||||
The dataset has been released available under the [AGPL-3.0 License](https://github.com/ultralytics/ultralytics/blob/main/LICENSE). |
||||
@ -0,0 +1,69 @@ |
||||
--- |
||||
comments: true |
||||
description: Learn how to optimize Ultralytics YOLOv8 models with Intel OpenVINO for maximum performance. Discover expert techniques to minimize latency and maximize throughput for real-time object detection applications. |
||||
keywords: Ultralytics, YOLOv8, OpenVINO, optimization, latency, throughput, inference, object detection, deep learning, machine learning, guide, Intel |
||||
--- |
||||
|
||||
# Optimizing OpenVINO Inference for Ultralytics YOLO Models: A Comprehensive Guide |
||||
|
||||
<img width="1024" src="https://github.com/RizwanMunawar/RizwanMunawar/assets/62513924/2b181f68-aa91-4514-ba09-497cc3c83b00" alt="OpenVINO Ecosystem"> |
||||
|
||||
## Introduction |
||||
|
||||
When deploying deep learning models, particularly those for object detection such as Ultralytics YOLO models, achieving optimal performance is crucial. This guide delves into leveraging Intel's OpenVINO toolkit to optimize inference, focusing on latency and throughput. Whether you're working on consumer-grade applications or large-scale deployments, understanding and applying these optimization strategies will ensure your models run efficiently on various devices. |
||||
|
||||
## Optimizing for Latency |
||||
|
||||
Latency optimization is vital for applications requiring immediate response from a single model given a single input, typical in consumer scenarios. The goal is to minimize the delay between input and inference result. However, achieving low latency involves careful consideration, especially when running concurrent inferences or managing multiple models. |
||||
|
||||
### Key Strategies for Latency Optimization: |
||||
|
||||
- **Single Inference per Device:** The simplest way to achieve low latency is by limiting to one inference at a time per device. Additional concurrency often leads to increased latency. |
||||
- **Leveraging Sub-Devices:** Devices like multi-socket CPUs or multi-tile GPUs can execute multiple requests with minimal latency increase by utilizing their internal sub-devices. |
||||
- **OpenVINO Performance Hints:** Utilizing OpenVINO's `ov::hint::PerformanceMode::LATENCY` for the `ov::hint::performance_mode` property during model compilation simplifies performance tuning, offering a device-agnostic and future-proof approach. |
||||
|
||||
### Managing First-Inference Latency: |
||||
|
||||
- **Model Caching:** To mitigate model load and compile times impacting latency, use model caching where possible. For scenarios where caching isn't viable, CPUs generally offer the fastest model load times. |
||||
- **Model Mapping vs. Reading:** To reduce load times, OpenVINO replaced model reading with mapping. However, if the model is on a removable or network drive, consider using `ov::enable_mmap(false)` to switch back to reading. |
||||
- **AUTO Device Selection:** This mode begins inference on the CPU, shifting to an accelerator once ready, seamlessly reducing first-inference latency. |
||||
|
||||
## Optimizing for Throughput |
||||
|
||||
Throughput optimization is crucial for scenarios serving numerous inference requests simultaneously, maximizing resource utilization without significantly sacrificing individual request performance. |
||||
|
||||
### Approaches to Throughput Optimization: |
||||
|
||||
1. **OpenVINO Performance Hints:** A high-level, future-proof method to enhance throughput across devices using performance hints. |
||||
|
||||
```python |
||||
import openvino.properties as props |
||||
import openvino.properties.hint as hints |
||||
|
||||
config = {hints.performance_mode: hints.PerformanceMode.THROUGHPUT} |
||||
compiled_model = core.compile_model(model, "GPU", config) |
||||
``` |
||||
|
||||
2. **Explicit Batching and Streams:** A more granular approach involving explicit batching and the use of streams for advanced performance tuning. |
||||
|
||||
### Designing Throughput-Oriented Applications: |
||||
|
||||
To maximize throughput, applications should: |
||||
|
||||
- Process inputs in parallel, making full use of the device's capabilities. |
||||
- Decompose data flow into concurrent inference requests, scheduled for parallel execution. |
||||
- Utilize the Async API with callbacks to maintain efficiency and avoid device starvation. |
||||
|
||||
### Multi-Device Execution: |
||||
|
||||
OpenVINO's multi-device mode simplifies scaling throughput by automatically balancing inference requests across devices without requiring application-level device management. |
||||
|
||||
## Conclusion |
||||
|
||||
Optimizing Ultralytics YOLO models for latency and throughput with OpenVINO can significantly enhance your application's performance. By carefully applying the strategies outlined in this guide, developers can ensure their models run efficiently, meeting the demands of various deployment scenarios. Remember, the choice between optimizing for latency or throughput depends on your specific application needs and the characteristics of the deployment environment. |
||||
|
||||
For more detailed technical information and the latest updates, refer to the [OpenVINO documentation](https://docs.openvino.ai/latest/index.html) and [Ultralytics YOLO repository](https://github.com/ultralytics/ultralytics). These resources provide in-depth guides, tutorials, and community support to help you get the most out of your deep learning models. |
||||
|
||||
--- |
||||
|
||||
Ensuring your models achieve optimal performance is not just about tweaking configurations; it's about understanding your application's needs and making informed decisions. Whether you're optimizing for real-time responses or maximizing throughput for large-scale processing, the combination of Ultralytics YOLO models and OpenVINO offers a powerful toolkit for developers to deploy high-performance AI solutions. |
||||
@ -0,0 +1,22 @@ |
||||
# Ultralytics YOLO 🚀, AGPL-3.0 license |
||||
# Brain-tumor dataset by Ultralytics |
||||
# Documentation: https://docs.ultralytics.com/datasets/detect/brain-tumor/ |
||||
# Example usage: yolo train data=brain-tumor.yaml |
||||
# parent |
||||
# ├── ultralytics |
||||
# └── datasets |
||||
# └── brain-tumor ← downloads here (4.05 MB) |
||||
|
||||
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] |
||||
path: ../datasets/brain-tumor # dataset root dir |
||||
train: train/images # train images (relative to 'path') 893 images |
||||
val: valid/images # val images (relative to 'path') 223 images |
||||
test: # test images (relative to 'path') |
||||
|
||||
# Classes |
||||
names: |
||||
0: negative |
||||
1: positive |
||||
|
||||
# Download script/URL (optional) |
||||
download: https://ultralytics.com/assets/brain-tumor.zip |
||||
Loading…
Reference in new issue