diff --git a/.github/ISSUE_TEMPLATE/bug-report.yml b/.github/ISSUE_TEMPLATE/bug-report.yml
index 482bd55178..430b05957a 100644
--- a/.github/ISSUE_TEMPLATE/bug-report.yml
+++ b/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -2,13 +2,13 @@
name: 🐛 Bug Report
# title: " "
-description: Problems with YOLOv8
+description: Problems with Ultralytics YOLO
labels: [bug, triage]
body:
- type: markdown
attributes:
value: |
- Thank you for submitting a YOLOv8 🐛 Bug Report!
+ Thank you for submitting an Ultralytics YOLO 🐛 Bug Report!
- type: checkboxes
attributes:
@@ -17,14 +17,14 @@ body:
Please search the Ultralytics [Docs](https://docs.ultralytics.com) and [issues](https://github.com/ultralytics/ultralytics/issues) to see if a similar bug report already exists.
options:
- label: >
- I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
+ I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
required: true
- type: dropdown
attributes:
- label: YOLOv8 Component
+ label: Ultralytics YOLO Component
description: |
- Please select the part of YOLOv8 where you found the bug.
+ Please select the Ultralytics YOLO component where you found the bug.
multiple: true
options:
- "Install"
@@ -43,16 +43,16 @@ body:
- type: textarea
attributes:
label: Bug
- description: Provide console output with error messages and/or screenshots of the bug.
+ description: Please provide as much information as possible. Copy and paste console output and error messages. Use [Markdown](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) to format text, code and logs. If necessary, include screenshots for visual elements only. Providing detailed information will help us resolve the issue more efficiently.
placeholder: |
- 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ 💡 ProTip! Include as much information as possible (logs, tracebacks, screenshots, etc.) to receive the most helpful response.
validations:
required: true
- type: textarea
attributes:
label: Environment
- description: Please specify the software and hardware you used to produce the bug.
+ description: Many issues are often related to dependency versions and hardware. Please provide the output of `yolo checks` or `ultralytics.checks()` command to help us diagnose the problem.
placeholder: |
Paste output of `yolo checks` or `ultralytics.checks()` command, i.e.:
```
@@ -68,20 +68,19 @@ body:
CUDA None
```
validations:
- required: false
+ required: true
- type: textarea
attributes:
label: Minimal Reproducible Example
description: >
- When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to **reproduce** the problem.
- This is referred to by community members as creating a [minimal reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/).
+ When asking a question, people will be better able to provide help if you provide code that they can easily understand and use to **reproduce** the problem. This is referred to by community members as creating a [minimal reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/).
placeholder: |
```
# Code to reproduce your issue here
```
validations:
- required: false
+ required: true
- type: textarea
attributes:
@@ -92,7 +91,7 @@ body:
attributes:
label: Are you willing to submit a PR?
description: >
- (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve YOLOv8 for everyone, especially if you have a good understanding of how to implement a fix or feature.
- See the YOLOv8 [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
+ (Optional) We encourage you to submit a [Pull Request](https://github.com/ultralytics/ultralytics/pulls) (PR) to help improve Ultralytics YOLO for everyone, especially if you have a good understanding of how to implement a fix or feature.
+ See the Ultralytics YOLO [Contributing Guide](https://docs.ultralytics.com/help/contributing) to get started.
options:
- label: Yes I'd like to help by submitting a PR!
diff --git a/.github/ISSUE_TEMPLATE/question.yml b/.github/ISSUE_TEMPLATE/question.yml
index 45e55010b2..f957b43d6d 100644
--- a/.github/ISSUE_TEMPLATE/question.yml
+++ b/.github/ISSUE_TEMPLATE/question.yml
@@ -1,14 +1,14 @@
# Ultralytics YOLO 🚀, AGPL-3.0 license
name: ❓ Question
-description: Ask a YOLOv8 question
+description: Ask an Ultralytics YOLO question
# title: " "
labels: [question]
body:
- type: markdown
attributes:
value: |
- Thank you for asking a YOLOv8 ❓ Question!
+ Thank you for asking an Ultralytics YOLO ❓ Question!
- type: checkboxes
attributes:
@@ -17,15 +17,15 @@ body:
Please search the Ultralytics [Docs](https://docs.ultralytics.com), [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) to see if a similar question already exists.
options:
- label: >
- I have searched the YOLOv8 [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
+ I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
required: true
- type: textarea
attributes:
label: Question
- description: What is your question?
+ description: What is your question? Please provide as much information as possible. Include detailed code examples to reproduce the problem and describe the context in which the issue occurs. Format your text and code using [Markdown](https://docs.github.com/en/get-started/writing-on-github/getting-started-with-writing-and-formatting-on-github/basic-writing-and-formatting-syntax) for clarity and readability. Following these guidelines will help us assist you more effectively.
placeholder: |
- 💡 ProTip! Include as much information as possible (screenshots, logs, tracebacks etc.) to receive the most helpful response.
+ 💡 ProTip! Include as much information as possible (logs, tracebacks, screenshots etc.) to receive the most helpful response.
validations:
required: true
diff --git a/.github/workflows/ci.yaml b/.github/workflows/ci.yaml
index 2bec2fe51d..c25847c241 100644
--- a/.github/workflows/ci.yaml
+++ b/.github/workflows/ci.yaml
@@ -206,7 +206,7 @@ jobs:
strategy:
fail-fast: false
matrix:
- os: [ubuntu-latest, windows-latest, macos-14]
+ os: [ubuntu-latest, macos-14]
python-version: ["3.11"]
torch: [latest]
include:
diff --git a/.github/workflows/docker.yaml b/.github/workflows/docker.yaml
index d9e0f7c1a6..d798cbec18 100644
--- a/.github/workflows/docker.yaml
+++ b/.github/workflows/docker.yaml
@@ -23,6 +23,10 @@ on:
type: boolean
description: Use Dockerfile-arm64
default: true
+ Dockerfile-jetson-jetpack6:
+ type: boolean
+ description: Use Dockerfile-jetson-jetpack6
+ default: true
Dockerfile-jetson-jetpack5:
type: boolean
description: Use Dockerfile-jetson-jetpack5
@@ -62,6 +66,9 @@ jobs:
- dockerfile: "Dockerfile-arm64"
tags: "latest-arm64"
platforms: "linux/arm64"
+ - dockerfile: "Dockerfile-jetson-jetpack6"
+ tags: "latest-jetson-jetpack6"
+ platforms: "linux/arm64"
- dockerfile: "Dockerfile-jetson-jetpack5"
tags: "latest-jetson-jetpack5"
platforms: "linux/arm64"
diff --git a/docker/Dockerfile b/docker/Dockerfile
index 25e9c4e2bd..cdba060cad 100644
--- a/docker/Dockerfile
+++ b/docker/Dockerfile
@@ -6,7 +6,6 @@
FROM pytorch/pytorch:2.3.1-cuda12.1-cudnn8-runtime
# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
# Avoid DDP error "MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 library" https://github.com/pytorch/pytorch/issues/37377
ENV MKL_THREADING_LAYER=GNU
@@ -26,12 +25,12 @@ RUN apt update \
RUN apt upgrade --no-install-recommends -y openssl tar
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents and assign permissions
-COPY . $APP_HOME
+COPY . .
RUN git remote set-url origin https://github.com/ultralytics/ultralytics.git
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
# Install pip packages
RUN python3 -m pip install --upgrade pip wheel
@@ -62,7 +61,7 @@ RUN rm -rf tmp
# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus '"device=2,3"' $t
# Pull and Run with local directory access
-# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/shared/datasets:/usr/src/datasets $t
+# t=ultralytics/ultralytics:latest && sudo docker pull $t && sudo docker run -it --ipc=host --gpus all -v "$(pwd)"/shared/datasets:/datasets $t
# Kill all
# sudo docker kill $(sudo docker ps -q)
diff --git a/docker/Dockerfile-arm64 b/docker/Dockerfile-arm64
index d9ec75296e..179ea7eb20 100644
--- a/docker/Dockerfile-arm64
+++ b/docker/Dockerfile-arm64
@@ -6,9 +6,6 @@
# Start FROM Debian image for arm64v8 https://hub.docker.com/r/arm64v8/debian (new)
FROM arm64v8/debian:bookworm-slim
-# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
-
# Downloads to user config dir
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
@@ -21,20 +18,19 @@ RUN apt update \
&& apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop gcc libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents and assign permissions
-COPY . $APP_HOME
+COPY . .
RUN git remote set-url origin https://github.com/ultralytics/ultralytics.git
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
# Remove python3.11/EXTERNALLY-MANAGED to avoid 'externally-managed-environment' issue, Debian 12 Bookworm error
RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
# Install pip packages
-# Install tensorstore from .whl because PyPI does not include aarch64 binaries
RUN python3 -m pip install --upgrade pip wheel
-RUN pip install --no-cache-dir https://github.com/ultralytics/assets/releases/download/v0.0.0/tensorstore-0.1.59-cp311-cp311-linux_aarch64.whl -e ".[export]"
+RUN pip install --no-cache-dir -e ".[export]"
# Creates a symbolic link to make 'python' point to 'python3'
RUN ln -sf /usr/bin/python3 /usr/bin/python
@@ -52,4 +48,4 @@ RUN ln -sf /usr/bin/python3 /usr/bin/python
# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host $t
# Pull and Run with local volume mounted
-# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/usr/src/datasets $t
+# t=ultralytics/ultralytics:latest-arm64 && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/docker/Dockerfile-conda b/docker/Dockerfile-conda
index 1f8fe67516..305e6d1c2d 100644
--- a/docker/Dockerfile-conda
+++ b/docker/Dockerfile-conda
@@ -37,4 +37,4 @@ RUN conda config --set solver libmamba && \
# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host $t
# Pull and Run with local volume mounted
-# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/usr/src/datasets $t
+# t=ultralytics/ultralytics:latest-conda && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/docker/Dockerfile-cpu b/docker/Dockerfile-cpu
index be9d3e0b3c..054aee6be3 100644
--- a/docker/Dockerfile-cpu
+++ b/docker/Dockerfile-cpu
@@ -5,9 +5,6 @@
# Start FROM Ubuntu image https://hub.docker.com/_/ubuntu
FROM ubuntu:23.10
-# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
-
# Downloads to user config dir
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
@@ -19,12 +16,12 @@ RUN apt update \
&& apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents (previously used git clone to avoid permission errors)
-COPY . $APP_HOME
+COPY . .
RUN git remote set-url origin https://github.com/ultralytics/ultralytics.git
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
@@ -57,4 +54,4 @@ RUN ln -sf /usr/bin/python3 /usr/bin/python
# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host --name NAME $t
# Pull and Run with local volume mounted
-# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/usr/src/datasets $t
+# t=ultralytics/ultralytics:latest-cpu && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/docker/Dockerfile-jetson-jetpack4 b/docker/Dockerfile-jetson-jetpack4
index 12931ad30f..dadf4513c4 100644
--- a/docker/Dockerfile-jetson-jetpack4
+++ b/docker/Dockerfile-jetson-jetpack4
@@ -5,9 +5,6 @@
# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-cuda
FROM nvcr.io/nvidia/l4t-cuda:10.2.460-runtime
-# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
-
# Downloads to user config dir
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
@@ -27,27 +24,27 @@ RUN ln -sf /usr/bin/python3.8 /usr/bin/python3
RUN ln -s /usr/bin/pip3 /usr/bin/pip
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents and assign permissions
-COPY . $APP_HOME
-RUN chown -R root:root $APP_HOME
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+COPY . .
+RUN chown -R root:root .
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
-# Download onnxruntime-gpu, TensorRT, PyTorch and Torchvision
+# Download onnxruntime-gpu 1.8.0 and tensorrt 8.2.0.6
# Other versions can be seen in https://elinux.org/Jetson_Zoo and https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
ADD https://nvidia.box.com/shared/static/gjqofg7rkg97z3gc8jeyup6t8n9j8xjw.whl onnxruntime_gpu-1.8.0-cp38-cp38-linux_aarch64.whl
ADD https://forums.developer.nvidia.com/uploads/short-url/hASzFOm9YsJx6VVFrDW1g44CMmv.whl tensorrt-8.2.0.6-cp38-none-linux_aarch64.whl
-ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-1.11.0a0+gitbc2c6ed-cp38-cp38-linux_aarch64.whl \
- torch-1.11.0a0+gitbc2c6ed-cp38-cp38-linux_aarch64.whl
-ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.12.0a0+9b5a3fe-cp38-cp38-linux_aarch64.whl \
- torchvision-0.12.0a0+9b5a3fe-cp38-cp38-linux_aarch64.whl
# Install pip packages
RUN python3 -m pip install --upgrade pip wheel
-RUN pip install onnxruntime_gpu-1.8.0-cp38-cp38-linux_aarch64.whl tensorrt-8.2.0.6-cp38-none-linux_aarch64.whl \
- torch-1.11.0a0+gitbc2c6ed-cp38-cp38-linux_aarch64.whl torchvision-0.12.0a0+9b5a3fe-cp38-cp38-linux_aarch64.whl
+RUN pip install --no-cache-dir \
+ onnxruntime_gpu-1.8.0-cp38-cp38-linux_aarch64.whl \
+ tensorrt-8.2.0.6-cp38-none-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-1.11.0a0+gitbc2c6ed-cp38-cp38-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.12.0a0+9b5a3fe-cp38-cp38-linux_aarch64.whl
RUN pip install --no-cache-dir -e ".[export]"
+RUN rm *.whl
# Usage Examples -------------------------------------------------------------------------------------------------------
diff --git a/docker/Dockerfile-jetson-jetpack5 b/docker/Dockerfile-jetson-jetpack5
index b71db9e5f0..07e81ab791 100644
--- a/docker/Dockerfile-jetson-jetpack5
+++ b/docker/Dockerfile-jetson-jetpack5
@@ -5,9 +5,6 @@
# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-pytorch
FROM nvcr.io/nvidia/l4t-pytorch:r35.2.1-pth2.0-py3
-# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
-
# Downloads to user config dir
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
@@ -21,12 +18,12 @@ RUN apt update \
&& apt install --no-install-recommends -y gcc git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents and assign permissions
-COPY . $APP_HOME
+COPY . .
RUN git remote set-url origin https://github.com/ultralytics/ultralytics.git
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
# Remove opencv-python from Ultralytics dependencies as it conflicts with opencv-python installed in base image
RUN grep -v "opencv-python" pyproject.toml > temp.toml && mv temp.toml pyproject.toml
@@ -38,6 +35,7 @@ ADD https://nvidia.box.com/shared/static/mvdcltm9ewdy2d5nurkiqorofz1s53ww.whl on
RUN python3 -m pip install --upgrade pip wheel
RUN pip install onnxruntime_gpu-1.15.1-cp38-cp38-linux_aarch64.whl
RUN pip install --no-cache-dir -e ".[export]"
+RUN rm *.whl
# Usage Examples -------------------------------------------------------------------------------------------------------
diff --git a/docker/Dockerfile-jetson-jetpack6 b/docker/Dockerfile-jetson-jetpack6
new file mode 100644
index 0000000000..7d3d09468d
--- /dev/null
+++ b/docker/Dockerfile-jetson-jetpack6
@@ -0,0 +1,49 @@
+# Ultralytics YOLO 🚀, AGPL-3.0 license
+# Builds ultralytics/ultralytics:jetson-jetpack6 image on DockerHub https://hub.docker.com/r/ultralytics/ultralytics
+# Supports JetPack6.x for YOLOv8 on Jetson AGX Orin, Orin NX and Orin Nano Series
+
+# Start FROM https://catalog.ngc.nvidia.com/orgs/nvidia/containers/l4t-jetpack
+FROM nvcr.io/nvidia/l4t-jetpack:r36.3.0
+
+# Downloads to user config dir
+ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
+ /root/.config/Ultralytics/
+
+# Install dependencies
+RUN apt update && \
+ apt install --no-install-recommends -y git python3-pip libopenmpi-dev libopenblas-base libomp-dev
+
+# Create working directory
+WORKDIR /ultralytics
+
+# Copy contents and assign permissions
+COPY . .
+RUN chown -R root:root .
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
+
+# Download onnxruntime-gpu 1.18.0 from https://elinux.org/Jetson_Zoo and https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
+ADD https://nvidia.box.com/shared/static/48dtuob7meiw6ebgfsfqakc9vse62sg4.whl onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl
+
+# Pip install onnxruntime-gpu, torch, torchvision and ultralytics
+RUN python3 -m pip install --upgrade pip wheel
+RUN pip install --no-cache-dir \
+ onnxruntime_gpu-1.18.0-cp310-cp310-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torch-2.3.0-cp310-cp310-linux_aarch64.whl \
+ https://github.com/ultralytics/assets/releases/download/v0.0.0/torchvision-0.18.0a0+6043bc2-cp310-cp310-linux_aarch64.whl
+RUN pip install --no-cache-dir -e ".[export]"
+RUN rm *.whl
+
+# Usage Examples -------------------------------------------------------------------------------------------------------
+
+# Build and Push
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker build --platform linux/arm64 -f docker/Dockerfile-jetson-jetpack6 -t $t . && sudo docker push $t
+
+# Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker run -it --ipc=host $t
+
+# Pull and Run
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker pull $t && sudo docker run -it --ipc=host $t
+
+# Pull and Run with NVIDIA runtime
+# t=ultralytics/ultralytics:latest-jetson-jetpack6 && sudo docker pull $t && sudo docker run -it --ipc=host --runtime=nvidia $t
diff --git a/docker/Dockerfile-python b/docker/Dockerfile-python
index 9ee42cc87d..ffecbab9c0 100644
--- a/docker/Dockerfile-python
+++ b/docker/Dockerfile-python
@@ -5,9 +5,6 @@
# Use the official Python 3.10 slim-bookworm as base image
FROM python:3.10-slim-bookworm
-# Set environment variables
-ENV APP_HOME /usr/src/ultralytics
-
# Downloads to user config dir
ADD https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.ttf \
https://github.com/ultralytics/assets/releases/download/v0.0.0/Arial.Unicode.ttf \
@@ -19,12 +16,12 @@ RUN apt update \
&& apt install --no-install-recommends -y python3-pip git zip unzip wget curl htop libgl1 libglib2.0-0 libpython3-dev gnupg g++ libusb-1.0-0
# Create working directory
-WORKDIR $APP_HOME
+WORKDIR /ultralytics
# Copy contents and assign permissions
-COPY . $APP_HOME
+COPY . .
RUN git remote set-url origin https://github.com/ultralytics/ultralytics.git
-ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt $APP_HOME
+ADD https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt .
# Remove python3.11/EXTERNALLY-MANAGED or use 'pip install --break-system-packages' avoid 'externally-managed-environment' Ubuntu nightly error
# RUN rm -rf /usr/lib/python3.11/EXTERNALLY-MANAGED
@@ -54,4 +51,4 @@ RUN rm -rf tmp
# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host $t
# Pull and Run with local volume mounted
-# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/usr/src/datasets $t
+# t=ultralytics/ultralytics:latest-python && sudo docker pull $t && sudo docker run -it --ipc=host -v "$(pwd)"/shared/datasets:/datasets $t
diff --git a/docs/en/datasets/classify/cifar10.md b/docs/en/datasets/classify/cifar10.md
index 65370f3cf4..513f838319 100644
--- a/docs/en/datasets/classify/cifar10.md
+++ b/docs/en/datasets/classify/cifar10.md
@@ -100,22 +100,22 @@ To train a YOLO model on the CIFAR-10 dataset using Ultralytics, you can follow
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- # Load a model
- model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
- # Train the model
- results = model.train(data="cifar10", epochs=100, imgsz=32)
- ```
+ # Train the model
+ results = model.train(data="cifar10", epochs=100, imgsz=32)
+ ```
=== "CLI"
- ```bash
- # Start training from a pretrained *.pt model
- yolo detect train data=cifar10 model=yolov8n-cls.pt epochs=100 imgsz=32
- ```
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=cifar10 model=yolov8n-cls.pt epochs=100 imgsz=32
+ ```
For more details, refer to the model [Training](../../modes/train.md) page.
diff --git a/docs/en/datasets/classify/imagenette.md b/docs/en/datasets/classify/imagenette.md
index 1aa924d233..b667192aec 100644
--- a/docs/en/datasets/classify/imagenette.md
+++ b/docs/en/datasets/classify/imagenette.md
@@ -126,22 +126,22 @@ To train a YOLO model on the ImageNette dataset for 100 epochs, you can use the
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- # Load a model
- model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
+ # Load a model
+ model = YOLO("yolov8n-cls.pt") # load a pretrained model (recommended for training)
- # Train the model
- results = model.train(data="imagenette", epochs=100, imgsz=224)
- ```
+ # Train the model
+ results = model.train(data="imagenette", epochs=100, imgsz=224)
+ ```
=== "CLI"
- ```bash
- # Start training from a pretrained *.pt model
- yolo detect train data=imagenette model=yolov8n-cls.pt epochs=100 imgsz=224
- ```
+ ```bash
+ # Start training from a pretrained *.pt model
+ yolo detect train data=imagenette model=yolov8n-cls.pt epochs=100 imgsz=224
+ ```
For more details, see the [Training](../../modes/train.md) documentation page.
diff --git a/docs/en/datasets/detect/sku-110k.md b/docs/en/datasets/detect/sku-110k.md
index 75651de375..d426d0f830 100644
--- a/docs/en/datasets/detect/sku-110k.md
+++ b/docs/en/datasets/detect/sku-110k.md
@@ -8,6 +8,17 @@ keywords: SKU-110k, dataset, object detection, retail shelf images, deep learnin
The [SKU-110k](https://github.com/eg4000/SKU110K_CVPR19) dataset is a collection of densely packed retail shelf images, designed to support research in object detection tasks. Developed by Eran Goldman et al., the dataset contains over 110,000 unique store keeping unit (SKU) categories with densely packed objects, often looking similar or even identical, positioned in close proximity.
+
+
+
+
+ Watch: How to Train YOLOv10 on SKU-110k Dataset using Ultralytics | Retail Dataset
+
+

## Key Features
diff --git a/docs/en/datasets/track/index.md b/docs/en/datasets/track/index.md
index 1a25596a74..507a2a02ea 100644
--- a/docs/en/datasets/track/index.md
+++ b/docs/en/datasets/track/index.md
@@ -39,18 +39,18 @@ To use Multi-Object Tracking with Ultralytics YOLO, you can start by using the P
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- model = YOLO("yolov8n.pt") # Load the YOLOv8 model
- results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
- ```
+ model = YOLO("yolov8n.pt") # Load the YOLOv8 model
+ results = model.track(source="https://youtu.be/LNwODJXcvt4", conf=0.3, iou=0.5, show=True)
+ ```
=== "CLI"
- ```bash
- yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3 iou=0.5 show
- ```
+ ```bash
+ yolo track model=yolov8n.pt source="https://youtu.be/LNwODJXcvt4" conf=0.3 iou=0.5 show
+ ```
These commands load the YOLOv8 model and use it for tracking objects in the given video source with specific confidence (`conf`) and Intersection over Union (`iou`) thresholds. For more details, refer to the [track mode documentation](../../modes/track.md).
diff --git a/docs/en/guides/streamlit-live-inference.md b/docs/en/guides/streamlit-live-inference.md
index 7deb8c70e9..ed1f654109 100644
--- a/docs/en/guides/streamlit-live-inference.md
+++ b/docs/en/guides/streamlit-live-inference.md
@@ -97,19 +97,19 @@ Then, you can create a basic Streamlit application to run live inference:
=== "Python"
- ```python
- from ultralytics import solutions
+ ```python
+ from ultralytics import solutions
- solutions.inference()
+ solutions.inference()
- ### Make sure to run the file using command `streamlit run `
- ```
+ ### Make sure to run the file using command `streamlit run `
+ ```
- === "CLI"
+ === "CLI"
- ```bash
- yolo streamlit-predict
- ```
+ ```bash
+ yolo streamlit-predict
+ ```
For more details on the practical setup, refer to the [Streamlit Application Code section](#streamlit-application-code) of the documentation.
diff --git a/docs/en/integrations/dvc.md b/docs/en/integrations/dvc.md
index 71a8a2f564..7e5c918108 100644
--- a/docs/en/integrations/dvc.md
+++ b/docs/en/integrations/dvc.md
@@ -180,9 +180,9 @@ Integrating DVCLive with Ultralytics YOLOv8 is straightforward. Start by install
=== "CLI"
- ```bash
- pip install ultralytics dvclive
- ```
+ ```bash
+ pip install ultralytics dvclive
+ ```
Next, initialize a Git repository and configure DVCLive in your project:
@@ -190,13 +190,13 @@ Next, initialize a Git repository and configure DVCLive in your project:
=== "CLI"
- ```bash
- git init -q
- git config --local user.email "you@example.com"
- git config --local user.name "Your Name"
- dvc init -q
- git commit -m "DVC init"
- ```
+ ```bash
+ git init -q
+ git config --local user.email "you@example.com"
+ git config --local user.name "Your Name"
+ dvc init -q
+ git commit -m "DVC init"
+ ```
Follow our [YOLOv8 Installation guide](../quickstart.md) for detailed setup instructions.
@@ -262,9 +262,9 @@ DVCLive offers powerful tools to visualize the results of YOLOv8 experiments. He
=== "CLI"
- ```bash
- dvc plots diff $(dvc exp list --names-only)
- ```
+ ```bash
+ dvc plots diff $(dvc exp list --names-only)
+ ```
To display these plots in a Jupyter Notebook, use:
diff --git a/docs/en/integrations/ibm-watsonx.md b/docs/en/integrations/ibm-watsonx.md
new file mode 100644
index 0000000000..da53b9c048
--- /dev/null
+++ b/docs/en/integrations/ibm-watsonx.md
@@ -0,0 +1,323 @@
+---
+comments: true
+description: Dive into our detailed integration guide on using IBM Watson to train a YOLOv8 model. Uncover key features and step-by-step instructions on model training.
+keywords: IBM Watsonx, IBM Watsonx AI, What is Watson?, IBM Watson Integration, IBM Watson Features, YOLOv8, Ultralytics, Model Training, GPU, TPU, cloud computing
+---
+
+# A Step-by-Step Guide to Training YOLOv8 Models with IBM Watsonx
+
+Nowadays, scalable [computer vision solutions](../guides/steps-of-a-cv-project.md) are becoming more common and transforming the way we handle visual data. A great example is IBM Watsonx, an advanced AI and data platform that simplifies the development, deployment, and management of AI models. It offers a complete suite for the entire AI lifecycle and seamless integration with IBM Cloud services.
+
+You can train [Ultralytics YOLOv8 models](https://github.com/ultralytics/ultralytics) using IBM Watsonx. It's a good option for enterprises interested in efficient [model training](../modes/train.md), fine-tuning for specific tasks, and improving [model performance](../guides/model-evaluation-insights.md) with robust tools and a user-friendly setup. In this guide, we'll walk you through the process of training YOLOv8 with IBM Watsonx, covering everything from setting up your environment to evaluating your trained models. Let's get started!
+
+## What is IBM Watsonx?
+
+[Watsonx](https://www.ibm.com/watsonx) is IBM's cloud-based platform designed for commercial generative AI and scientific data. IBM Watsonx's three components - watsonx.ai, watsonx.data, and watsonx.governance - come together to create an end-to-end, trustworthy AI platform that can accelerate AI projects aimed at solving business problems. It provides powerful tools for building, training, and [deploying machine learning models](../guides/model-deployment-options.md) and makes it easy to connect with various data sources.
+
+
+
+
+
+Its user-friendly interface and collaborative capabilities streamline the development process and help with efficient model management and deployment. Whether for computer vision, predictive analytics, natural language processing, or other AI applications, IBM Watsonx provides the tools and support needed to drive innovation.
+
+## Key Features of IBM Watsonx
+
+IBM Watsonx is made of three main components: watsonx.ai, watsonx.data, and watsonx.governance. Each component offers features that cater to different aspects of AI and data management. Let's take a closer look at them.
+
+### [Watsonx.ai](https://www.ibm.com/products/watsonx-ai)
+
+Watsonx.ai provides powerful tools for AI development and offers access to IBM-supported custom models, third-party models like [Llama 3](https://www.ultralytics.com/blog/getting-to-know-metas-llama-3), and IBM's own Granite models. It includes the Prompt Lab for experimenting with AI prompts, the Tuning Studio for improving model performance with labeled data, and the Flows Engine for simplifying generative AI application development. Also, it offers comprehensive tools for automating the AI model lifecycle and connecting to various APIs and libraries.
+
+### [Watsonx.data](https://www.ibm.com/products/watsonx-data)
+
+Watsonx.data supports both cloud and on-premises deployments through the IBM Storage Fusion HCI integration. Its user-friendly console provides centralized access to data across environments and makes data exploration easy with common SQL. It optimizes workloads with efficient query engines like Presto and Spark, accelerates data insights with an AI-powered semantic layer, includes a vector database for AI relevance, and supports open data formats for easy sharing of analytics and AI data.
+
+### [Watsonx.governance](https://www.ibm.com/products/watsonx-governance)
+
+Watsonx.governance makes compliance easier by automatically identifying regulatory changes and enforcing policies. It links requirements to internal risk data and provides up-to-date AI factsheets. The platform helps manage risk with alerts and tools to detect issues such as [bias and drift](../guides/model-monitoring-and-maintenance.md). It also automates the monitoring and documentation of the AI lifecycle, organizes AI development with a model inventory, and enhances collaboration with user-friendly dashboards and reporting tools.
+
+## How to Train YOLOv8 Using IBM Watsonx
+
+You can use IBM Watsonx to accelerate your YOLOv8 model training workflow.
+
+### Prerequisites
+
+You need an [IBM Cloud account](https://cloud.ibm.com/registration) to create a [watsonx.ai](https://www.ibm.com/products/watsonx-ai) project, and you'll also need a [Kaggle](./kaggle.md) account to load the data set.
+
+### Step 1: Set Up Your Environment
+
+First, you'll need to set up an IBM account to use a Jupyter Notebook. Log in to [watsonx.ai](https://eu-de.dataplatform.cloud.ibm.com/registration/stepone?preselect_region=true) using your IBM Cloud account.
+
+Then, create a [watsonx.ai project](https://www.ibm.com/docs/en/watsonx/saas?topic=projects-creating-project), and a [Jupyter Notebook](https://www.ibm.com/docs/en/watsonx/saas?topic=editor-creating-managing-notebooks).
+
+Once you do so, a notebook environment will open for you to load your data set. You can use the code from this tutorial to tackle a simple object detection model training task.
+
+### Step 2: Install and Import Relevant Libraries
+
+Next, you can install and import the necessary Python libraries.
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required packages
+ pip install torch torchvision torchaudio
+ pip install opencv-contrib-python-headless
+ pip install ultralytics==8.0.196
+ ```
+
+For detailed instructions and best practices related to the installation process, check our [Ultralytics Installation guide](../quickstart.md). While installing the required packages for YOLOv8, if you encounter any difficulties, consult our [Common Issues guide](../guides/yolo-common-issues.md) for solutions and tips.
+
+Then, you can import the needed packages.
+
+!!! Example "Import Relevant Libraries"
+
+ === "Python"
+
+ ```python
+ # Import ultralytics
+ import ultralytics
+
+ ultralytics.checks()
+
+ # Import packages to retrieve and display image files
+ ```
+
+### Step 3: Load the Data
+
+For this tutorial, we will use a [marine litter dataset](https://www.kaggle.com/datasets/atiqishrak/trash-dataset-icra19) available on Kaggle. With this dataset, we will custom-train a YOLOv8 model to detect and classify litter and biological objects in underwater images.
+
+We can load the dataset directly into the notebook using the Kaggle API. First, create a free Kaggle account. Once you have created an account, you'll need to generate an API key. Directions for generating your key can be found in the [Kaggle API documentation](https://github.com/Kaggle/kaggle-api/blob/main/docs/README.md) under the section "API credentials".
+
+Copy and paste your Kaggle username and API key into the following code. Then run the code to install the API and load the dataset into Watsonx.
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install kaggle
+ pip install kaggle
+ ```
+
+After installing Kaggle, we can load the dataset into Watsonx.
+
+!!! Example "Load the Data"
+
+ === "Python"
+
+ ```python
+ # Replace "username" string with your username
+ os.environ["KAGGLE_USERNAME"] = "username"
+ # Replace "apiKey" string with your key
+ os.environ["KAGGLE_KEY"] = "apiKey"
+
+ # Load dataset
+ !kaggle datasets download atiqishrak/trash-dataset-icra19 --unzip
+
+ # Store working directory path as work_dir
+ work_dir = os.getcwd()
+
+ # Print work_dir path
+ print(os.getcwd())
+
+ # Print work_dir contents
+ print(os.listdir(f"{work_dir}"))
+
+ # Print trash_ICRA19 subdirectory contents
+ print(os.listdir(f"{work_dir}/trash_ICRA19"))
+ ```
+
+After loading the dataset, we printed and saved our working directory. We have also printed the contents of our working directory to confirm the "trash_ICRA19" data set was loaded properly.
+
+If you see "trash_ICRA19" among the directory's contents, then it has loaded successfully. You should see three files/folders: a `config.yaml` file, a `videos_for_testing` directory, and a `dataset` directory. We will ignore the `videos_for_testing` directory, so feel free to delete it.
+
+We will use the config.yaml file and the contents of the dataset directory to train our object detection model. Here is a sample image from our marine litter data set.
+
+
+
+
+
+### Step 4: Preprocess the Data
+
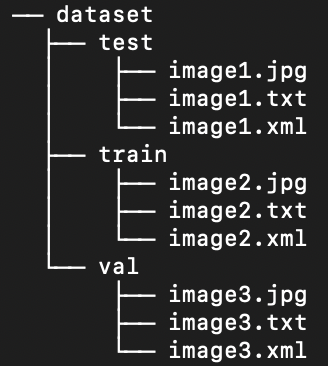
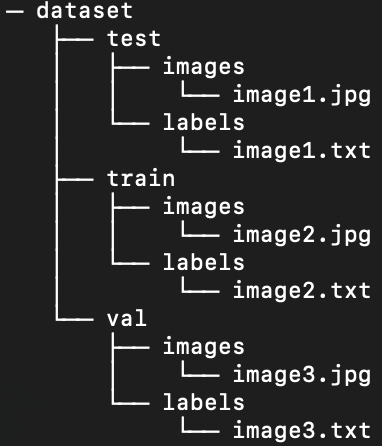
+Fortunately, all labels in the marine litter data set are already formatted as YOLO .txt files. However, we need to rearrange the structure of the image and label directories in order to help our model process the image and labels. Right now, our loaded data set directory follows this structure:
+
+
+
+
+
+But, YOLO models by default require separate images and labels in subdirectories within the train/val/test split. We need to reorganize the directory into the following structure:
+
+
+
+
+
+To reorganize the data set directory, we can run the following script:
+
+!!! Example "Preprocess the Data"
+
+ === "Python"
+
+ ```python
+ # Function to reorganize dir
+ def organize_files(directory):
+ for subdir in ["train", "test", "val"]:
+ subdir_path = os.path.join(directory, subdir)
+ if not os.path.exists(subdir_path):
+ continue
+
+ images_dir = os.path.join(subdir_path, "images")
+ labels_dir = os.path.join(subdir_path, "labels")
+
+ # Create image and label subdirs if non-existent
+ os.makedirs(images_dir, exist_ok=True)
+ os.makedirs(labels_dir, exist_ok=True)
+
+ # Move images and labels to respective subdirs
+ for filename in os.listdir(subdir_path):
+ if filename.endswith(".txt"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(labels_dir, filename))
+ elif filename.endswith(".jpg") or filename.endswith(".png") or filename.endswith(".jpeg"):
+ shutil.move(os.path.join(subdir_path, filename), os.path.join(images_dir, filename))
+ # Delete .xml files
+ elif filename.endswith(".xml"):
+ os.remove(os.path.join(subdir_path, filename))
+
+
+ if __name__ == "__main__":
+ directory = f"{work_dir}/trash_ICRA19/dataset"
+ organize_files(directory)
+ ```
+
+Next, we need to modify the .yaml file for the data set. This is the setup we will use in our .yaml file. Class ID numbers start from 0:
+
+```yaml
+path: /path/to/dataset/directory # root directory for dataset
+train: train/images # train images subdirectory
+val: train/images # validation images subdirectory
+test: test/images # test images subdirectory
+
+# Classes
+names:
+ 0: plastic
+ 1: bio
+ 2: rov
+```
+
+Run the following script to delete the current contents of config.yaml and replace it with the above contents that reflect our new data set directory structure. Be certain to replace the work_dir portion of the root directory path in line 4 with your own working directory path we retrieved earlier. Leave the train, val, and test subdirectory definitions. Also, do not change {work_dir} in line 23 of the code.
+
+!!! Example "Edit the .yaml File"
+
+ === "Python"
+
+ ```python
+ # Contents of new confg.yaml file
+ def update_yaml_file(file_path):
+ data = {
+ "path": "work_dir/trash_ICRA19/dataset",
+ "train": "train/images",
+ "val": "train/images",
+ "test": "test/images",
+ "names": {0: "plastic", 1: "bio", 2: "rov"},
+ }
+
+ # Ensures the "names" list appears after the sub/directories
+ names_data = data.pop("names")
+ with open(file_path, "w") as yaml_file:
+ yaml.dump(data, yaml_file)
+ yaml_file.write("\n")
+ yaml.dump({"names": names_data}, yaml_file)
+
+
+ if __name__ == "__main__":
+ file_path = f"{work_dir}/trash_ICRA19/config.yaml" # .yaml file path
+ update_yaml_file(file_path)
+ print(f"{file_path} updated successfully.")
+ ```
+
+### Step 5: Train the YOLOv8 model
+
+Run the following command-line code to fine tune a pretrained default YOLOv8 model.
+
+!!! Example "Train the YOLOv8 model"
+
+ === "CLI"
+
+ ```bash
+ !yolo task=detect mode=train data={work_dir}/trash_ICRA19/config.yaml model=yolov8s.pt epochs=2 batch=32 lr0=.04 plots=True
+ ```
+
+Here's a closer look at the parameters in the model training command:
+
+- **task**: It specifies the computer vision task for which you are using the specified YOLO model and data set.
+- **mode**: Denotes the purpose for which you are loading the specified model and data. Since we are training a model, it is set to "train." Later, when we test our model's performance, we will set it to "predict."
+- **epochs**: This delimits the number of times YOLOv8 will pass through our entire data set.
+- **batch**: The numerical value stipulates the training batch sizes. Batches are the number of images a model processes before it updates its parameters.
+- **lr0**: Specifies the model's initial learning rate.
+- **plots**: Directs YOLO to generate and save plots of our model's training and evaluation metrics.
+
+For a detailed understanding of the model training process and best practices, refer to the [YOLOv8 Model Training guide](../modes/train.md). This guide will help you get the most out of your experiments and ensure you're using YOLOv8 effectively.
+
+### Step 6: Test the Model
+
+We can now run inference to test the performance of our fine-tuned model:
+
+!!! Example "Test the YOLOv8 model"
+
+ === "CLI"
+
+ ```bash
+ !yolo task=detect mode=predict source={work_dir}/trash_ICRA19/dataset/test/images model={work_dir}/runs/detect/train/weights/best.pt conf=0.5 iou=.5 save=True save_txt=True
+ ```
+
+This brief script generates predicted labels for each image in our test set, as well as new output image files that overlay the predicted bounding box atop the original image.
+
+Predicted .txt labels for each image are saved via the `save_txt=True` argument and the output images with bounding box overlays are generated through the `save=True` argument.
+The parameter `conf=0.5` informs the model to ignore all predictions with a confidence level of less than 50%.
+
+Lastly, `iou=.5` directs the model to ignore boxes in the same class with an overlap of 50% or greater. It helps to reduce potential duplicate boxes generated for the same object.
+we can load the images with predicted bounding box overlays to view how our model performs on a handful of images.
+
+!!! Example "Display Predictions"
+
+ === "Python"
+
+ ```python
+ # Show the first ten images from the preceding prediction task
+ for pred_dir in glob.glob(f"{work_dir}/runs/detect/predict/*.jpg")[:10]:
+ img = Image.open(pred_dir)
+ display(img)
+ ```
+
+The code above displays ten images from the test set with their predicted bounding boxes, accompanied by class name labels and confidence levels.
+
+### Step 7: Evaluate the Model
+
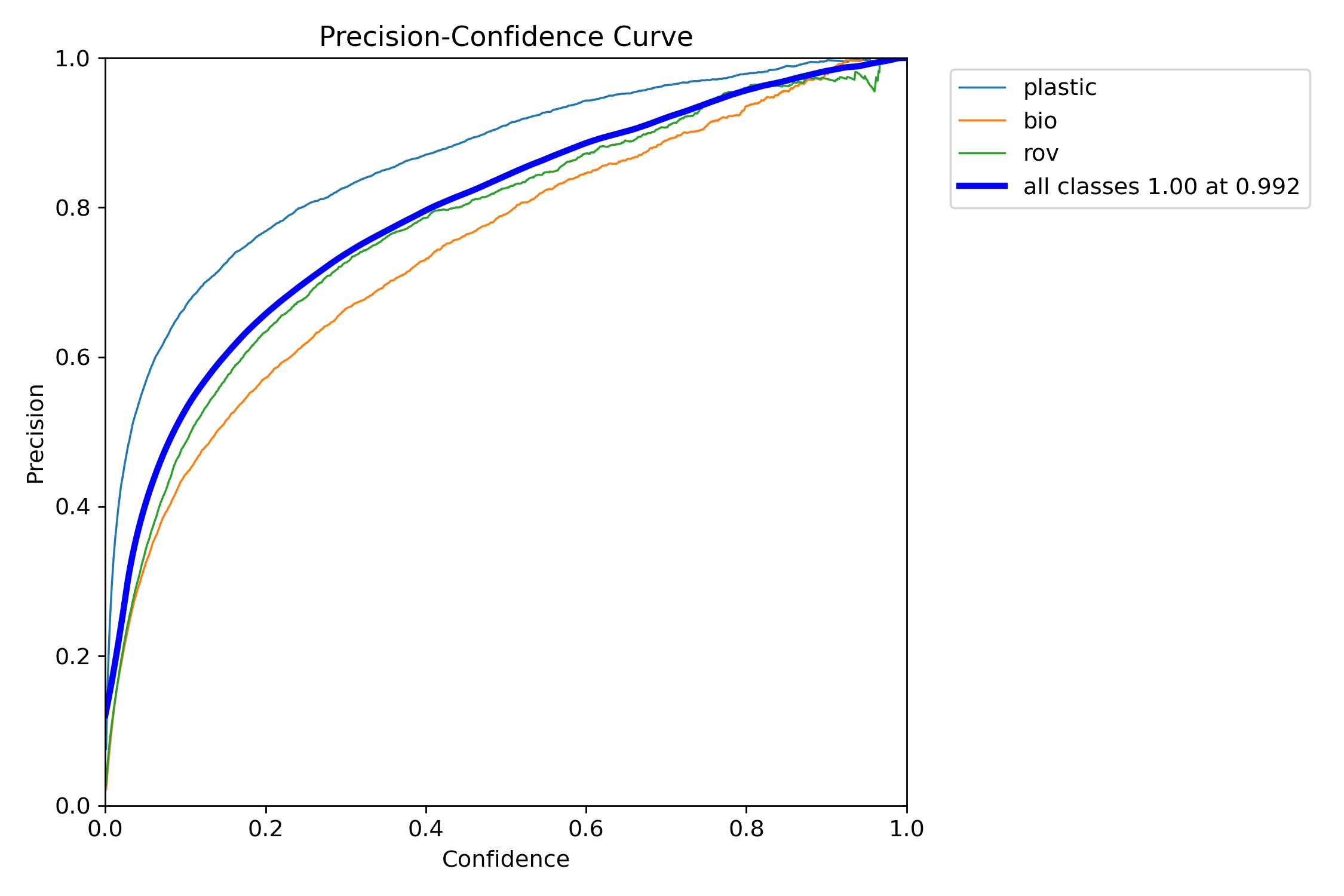
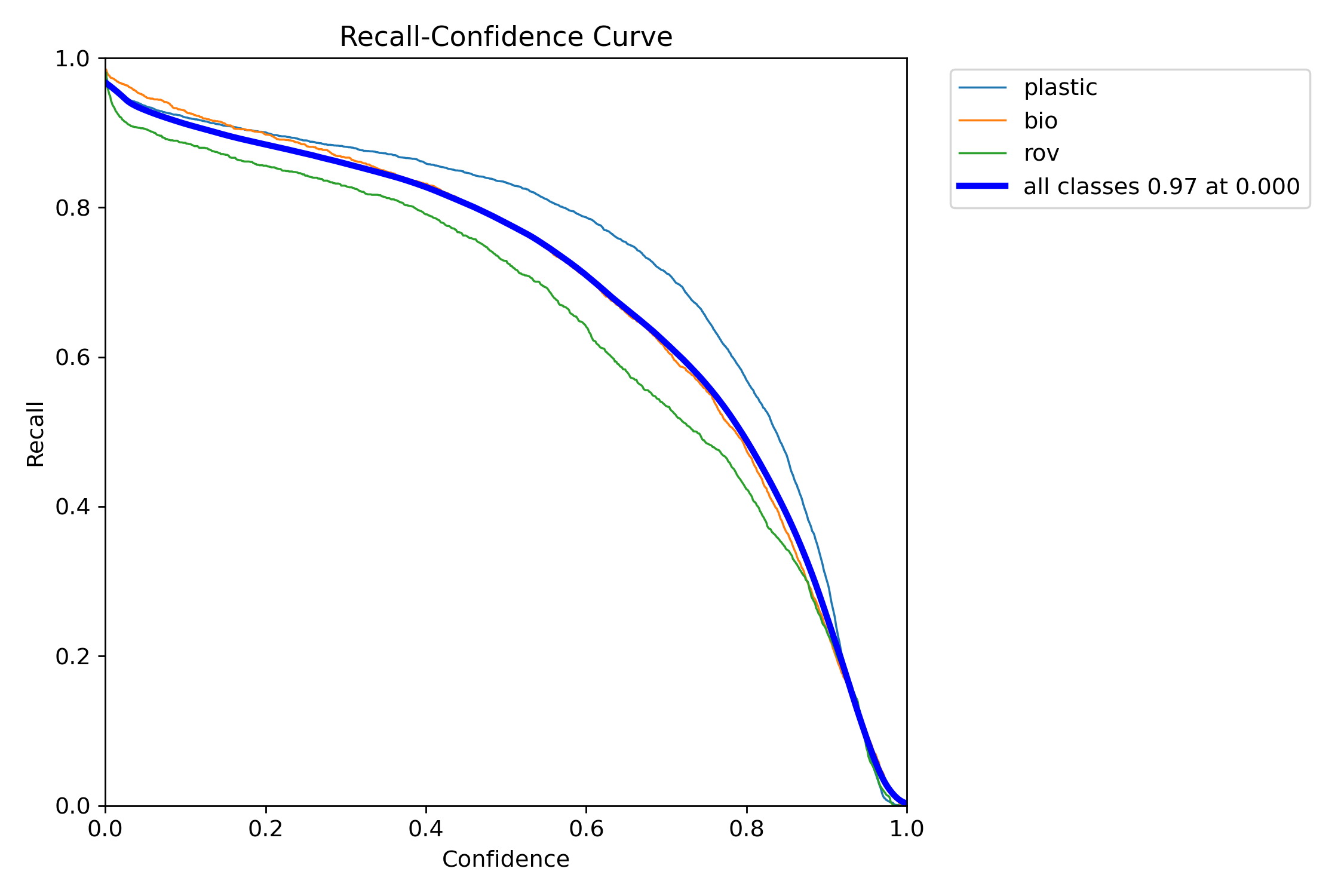
+We can produce visualizations of the model's precision and recall for each class. These visualizations are saved in the home directory, under the train folder. The precision score is displayed in the P_curve.png:
+
+
+
+
+
+The graph shows an exponential increase in precision as the model's confidence level for predictions increases. However, the model precision has not yet leveled out at a certain confidence level after two epochs.
+
+The recall graph (R_curve.png) displays an inverse trend:
+
+
+
+
+
+Unlike precision, recall moves in the opposite direction, showing greater recall with lower confidence instances and lower recall with higher confidence instances. This is an apt example of the trade-off in precision and recall for classification models.
+
+### Step 8: Calculating Intersection Over Union
+
+You can measure the prediction accuracy by calculating the IoU between a predicted bounding box and a ground truth bounding box for the same object. Check out [IBM's tutorial on training YOLOv8](https://developer.ibm.com/tutorials/awb-train-yolo-object-detection-model-in-python/) for more details.
+
+## Summary
+
+We explored IBM Watsonx key features, and how to train a YOLOv8 model using IBM Watsonx. We also saw how IBM Watsonx can enhance your AI workflows with advanced tools for model building, data management, and compliance.
+
+For further details on usage, visit [IBM Watsonx official documentation](https://www.ibm.com/watsonx).
+
+Also, be sure to check out the [Ultralytics integration guide page](./index.md), to learn more about different exciting integrations.
diff --git a/docs/en/integrations/index.md b/docs/en/integrations/index.md
index 49fb4cb413..c1ebe56f7e 100644
--- a/docs/en/integrations/index.md
+++ b/docs/en/integrations/index.md
@@ -53,6 +53,10 @@ Welcome to the Ultralytics Integrations page! This page provides an overview of
- [Kaggle](kaggle.md): Explore how you can use Kaggle to train and evaluate Ultralytics models in a cloud-based environment with pre-installed libraries, GPU support, and a vibrant community for collaboration and sharing.
+- [JupyterLab](jupyterlab.md): Find out how to use JupyterLab's interactive and customizable environment to train and evaluate Ultralytics models with ease and efficiency.
+
+- [IBM Watsonx](ibm-watsonx.md): See how IBM Watsonx simplifies the training and evaluation of Ultralytics models with its cutting-edge AI tools, effortless integration, and advanced model management system.
+
## Deployment Integrations
- [Neural Magic](neural-magic.md): Leverage Quantization Aware Training (QAT) and pruning techniques to optimize Ultralytics models for superior performance and leaner size.
diff --git a/docs/en/integrations/jupyterlab.md b/docs/en/integrations/jupyterlab.md
new file mode 100644
index 0000000000..8e2a68029f
--- /dev/null
+++ b/docs/en/integrations/jupyterlab.md
@@ -0,0 +1,110 @@
+---
+comments: true
+description: Explore our integration guide that explains how you can use JupyterLab to train a YOLOv8 model. We'll also cover key features and tips for common issues.
+keywords: JupyterLab, What is JupyterLab, How to Use JupyterLab, JupyterLab How to Use, YOLOv8, Ultralytics, Model Training, GPU, TPU, cloud computing
+---
+
+# A Guide on How to Use JupyterLab to Train Your YOLOv8 Models
+
+Building deep learning models can be tough, especially when you don't have the right tools or environment to work with. If you are facing this issue, JupyterLab might be the right solution for you. JupyterLab is a user-friendly, web-based platform that makes coding more flexible and interactive. You can use it to handle big datasets, create complex models, and even collaborate with others, all in one place.
+
+You can use JupyterLab to [work on projects](../guides/steps-of-a-cv-project.md) related to [Ultralytics YOLOv8 models](https://github.com/ultralytics/ultralytics). JupyterLab is a great option for efficient model development and experimentation. It makes it easy to start experimenting with and [training YOLOv8 models](../modes/train.md) right from your computer. Let's dive deeper into JupyterLab, its key features, and how you can use it to train YOLOv8 models.
+
+## What is JupyterLab?
+
+JupyterLab is an open-source web-based platform designed for working with Jupyter notebooks, code, and data. It's an upgrade from the traditional Jupyter Notebook interface that provides a more versatile and powerful user experience.
+
+JupyterLab allows you to work with notebooks, text editors, terminals, and other tools all in one place. Its flexible design lets you organize your workspace to fit your needs and makes it easier to perform tasks like data analysis, visualization, and machine learning. JupyterLab also supports real-time collaboration, making it ideal for team projects in research and data science.
+
+## Key Features of JupyterLab
+
+Here are some of the key features that make JupyterLab a great option for model development and experimentation:
+
+- **All-in-One Workspace**: JupyterLab is a one-stop shop for all your data science needs. Unlike the classic Jupyter Notebook, which had separate interfaces for text editing, terminal access, and notebooks, JupyterLab integrates all these features into a single, cohesive environment. You can view and edit various file formats, including JPEG, PDF, and CSV, directly within JupyterLab. An all-in-one workspace lets you access everything you need at your fingertips, streamlining your workflow and saving you time.
+- **Flexible Layouts**: One of JupyterLab's standout features is its flexible layout. You can drag, drop, and resize tabs to create a personalized layout that helps you work more efficiently. The collapsible left sidebar keeps essential tabs like the file browser, running kernels, and command palette within easy reach. You can have multiple windows open at once, allowing you to multitask and manage your projects more effectively.
+- **Interactive Code Consoles**: Code consoles in JupyterLab provide an interactive space to test out snippets of code or functions. They also serve as a log of computations made within a notebook. Creating a new console for a notebook and viewing all kernel activity is straightforward. This feature is especially useful when you're experimenting with new ideas or troubleshooting issues in your code.
+- **Markdown Preview**: Working with Markdown files is more efficient in JupyterLab, thanks to its simultaneous preview feature. As you write or edit your Markdown file, you can see the formatted output in real-time. It makes it easier to double-check that your documentation looks perfect, saving you from having to switch back and forth between editing and preview modes.
+- **Run Code from Text Files**: If you're sharing a text file with code, JupyterLab makes it easy to run it directly within the platform. You can highlight the code and press Shift + Enter to execute it. It is great for verifying code snippets quickly and helps guarantee that the code you share is functional and error-free.
+
+## Why Should You Use JupyterLab for Your YOLOv8 Projects?
+
+There are multiple platforms for developing and evaluating machine learning models, so what makes JupyterLab stand out? Let's explore some of the unique aspects that JupyterLab offers for your machine-learning projects:
+
+- **Easy Cell Management**: Managing cells in JupyterLab is a breeze. Instead of the cumbersome cut-and-paste method, you can simply drag and drop cells to rearrange them.
+- **Cross-Notebook Cell Copying**: JupyterLab makes it simple to copy cells between different notebooks. You can drag and drop cells from one notebook to another.
+- **Easy Switch to Classic Notebook View**: For those who miss the classic Jupyter Notebook interface, JupyterLab offers an easy switch back. Simply replace `/lab` in the URL with `/tree` to return to the familiar notebook view.
+- **Multiple Views**: JupyterLab supports multiple views of the same notebook, which is particularly useful for long notebooks. You can open different sections side-by-side for comparison or exploration, and any changes made in one view are reflected in the other.
+- **Customizable Themes**: JupyterLab includes a built-in Dark theme for the notebook, which is perfect for late-night coding sessions. There are also themes available for the text editor and terminal, allowing you to customize the appearance of your entire workspace.
+
+## Common Issues While Working with JupyterLab
+
+When working with Kaggle, you might come across some common issues. Here are some tips to help you navigate the platform smoothly:
+
+- **Managing Kernels**: Kernels are crucial because they manage the connection between the code you write in JupyterLab and the environment where it runs. They can also access and share data between notebooks. When you close a Jupyter Notebook, the kernel might still be running because other notebooks could be using it. If you want to completely shut down a kernel, you can select it, right-click, and choose "Shut Down Kernel" from the pop-up menu.
+- **Installing Python Packages**: Sometimes, you might need additional Python packages that aren't pre-installed on the server. You can easily install these packages in your home directory or a virtual environment by using the command `python -m pip install package-name`. To see all installed packages, use `python -m pip list`.
+- **Deploying Flask/FastAPI API to Posit Connect**: You can deploy your Flask and FastAPI APIs to Posit Connect using the [rsconnect-python](https://docs.posit.co/rsconnect-python/) package from the terminal. Doing so makes it easier to integrate your web applications with JupyterLab and share them with others.
+- **Installing JupyterLab Extensions**: JupyterLab supports various extensions to enhance functionality. You can install and customize these extensions to suit your needs. For detailed instructions, refer to [JupyterLab Extensions Guide](https://jupyterlab.readthedocs.io/en/latest/user/extensions.html) for more information.
+- **Using Multiple Versions of Python**: If you need to work with different versions of Python, you can use Jupyter kernels configured with different Python versions.
+
+## How to Use JupyterLab to Try Out YOLOv8
+
+JupyterLab makes it easy to experiment with YOLOv8. To get started, follow these simple steps.
+
+### Step 1: Install JupyterLab
+
+First, you need to install JupyterLab. Open your terminal and run the command:
+
+!!! Tip "Installation"
+
+ === "CLI"
+
+ ```bash
+ # Install the required package for JupyterLab
+ pip install jupyterlab
+ ```
+
+### Step 2: Download the YOLOv8 Tutorial Notebook
+
+Next, download the [tutorial.ipynb](https://github.com/ultralytics/ultralytics/blob/main/examples/tutorial.ipynb) file from the Ultralytics GitHub repository. Save this file to any directory on your local machine.
+
+### Step 3: Launch JupyterLab
+
+Navigate to the directory where you saved the notebook file using your terminal. Then, run the following command to launch JupyterLab:
+
+!!! Example "Usage"
+
+ === "CLI"
+
+ ```bash
+ jupyter lab
+ ```
+
+Once you've run this command, it will open JupyterLab in your default web browser, as shown below.
+
+
+
+### Step 4: Start Experimenting
+
+In JupyterLab, open the tutorial.ipynb notebook. You can now start running the cells to explore and experiment with YOLOv8.
+
+
+
+JupyterLab's interactive environment allows you to modify code, visualize outputs, and document your findings all in one place. You can try out different configurations and understand how YOLOv8 works.
+
+For a detailed understanding of the model training process and best practices, refer to the [YOLOv8 Model Training guide](../modes/train.md). This guide will help you get the most out of your experiments and ensure you're using YOLOv8 effectively.
+
+## Keep Learning about Jupyterlab
+
+If you're excited to learn more about JupyterLab, here are some great resources to get you started:
+
+- [**JupyterLab Documentation**](https://jupyterlab.readthedocs.io/en/stable/getting_started/starting.html): Dive into the official JupyterLab Documentation to explore its features and capabilities. It's a great way to understand how to use this powerful tool to its fullest potential.
+- [**Try It With Binder**](https://mybinder.org/v2/gh/jupyterlab/jupyterlab-demo/HEAD?urlpath=lab/tree/demo): Experiment with JupyterLab without installing anything by using Binder, which lets you launch a live JupyterLab instance directly in your browser. It's a great way to start experimenting immediately.
+- [**Installation Guide**](https://jupyterlab.readthedocs.io/en/stable/getting_started/installation.html): For a step-by-step guide on installing JupyterLab on your local machine, check out the installation guide.
+
+## Summary
+
+We've explored how JupyterLab can be a powerful tool for experimenting with Ultralytics YOLOv8 models. Using its flexible and interactive environment, you can easily set up JupyterLab on your local machine and start working with YOLOv8. JupyterLab makes it simple to [train](../guides/model-training-tips.md) and [evaluate](../guides/model-testing.md) your models, visualize outputs, and [document your findings](../guides/model-monitoring-and-maintenance.md) all in one place.
+
+For more details, visit the [JupyterLab FAQ Page](https://jupyterlab.readthedocs.io/en/stable/getting_started/faq.html).
+
+Interested in more YOLOv8 integrations? Check out the [Ultralytics integration guide](./index.md) to explore additional tools and capabilities for your machine learning projects.
diff --git a/docs/en/integrations/openvino.md b/docs/en/integrations/openvino.md
index de825510a2..37f63b4338 100644
--- a/docs/en/integrations/openvino.md
+++ b/docs/en/integrations/openvino.md
@@ -64,6 +64,8 @@ Export a YOLOv8n model to OpenVINO format and run inference with the exported mo
| `format` | `'openvino'` | format to export to |
| `imgsz` | `640` | image size as scalar or (h, w) list, i.e. (640, 480) |
| `half` | `False` | FP16 quantization |
+| `int8` | `False` | INT8 quantization |
+| `batch` | `1` | batch size for inference |
## Benefits of OpenVINO
@@ -262,14 +264,14 @@ To reproduce the Ultralytics benchmarks above on all export [formats](../modes/e
# Load a YOLOv8n PyTorch model
model = YOLO("yolov8n.pt")
- # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
results = model.benchmarks(data="coco8.yaml")
```
=== "CLI"
```bash
- # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all all export formats
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
yolo benchmark model=yolov8n.pt data=coco8.yaml
```
@@ -295,22 +297,22 @@ Exporting YOLOv8 models to the OpenVINO format can significantly enhance CPU spe
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- # Load a YOLOv8n PyTorch model
- model = YOLO("yolov8n.pt")
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
- # Export the model
- model.export(format="openvino") # creates 'yolov8n_openvino_model/'
- ```
+ # Export the model
+ model.export(format="openvino") # creates 'yolov8n_openvino_model/'
+ ```
=== "CLI"
- ```bash
- # Export a YOLOv8n PyTorch model to OpenVINO format
- yolo export model=yolov8n.pt format=openvino # creates 'yolov8n_openvino_model/'
- ```
+ ```bash
+ # Export a YOLOv8n PyTorch model to OpenVINO format
+ yolo export model=yolov8n.pt format=openvino # creates 'yolov8n_openvino_model/'
+ ```
For more information, refer to the [export formats documentation](../modes/export.md).
@@ -333,22 +335,22 @@ After exporting a YOLOv8 model to OpenVINO format, you can run inference using P
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- # Load the exported OpenVINO model
- ov_model = YOLO("yolov8n_openvino_model/")
+ # Load the exported OpenVINO model
+ ov_model = YOLO("yolov8n_openvino_model/")
- # Run inference
- results = ov_model("https://ultralytics.com/images/bus.jpg")
- ```
+ # Run inference
+ results = ov_model("https://ultralytics.com/images/bus.jpg")
+ ```
=== "CLI"
- ```bash
- # Run inference with the exported model
- yolo predict model=yolov8n_openvino_model source='https://ultralytics.com/images/bus.jpg'
- ```
+ ```bash
+ # Run inference with the exported model
+ yolo predict model=yolov8n_openvino_model source='https://ultralytics.com/images/bus.jpg'
+ ```
Refer to our [predict mode documentation](../modes/predict.md) for more details.
@@ -370,21 +372,21 @@ Yes, you can benchmark YOLOv8 models in various formats including PyTorch, Torch
=== "Python"
- ```python
- from ultralytics import YOLO
+ ```python
+ from ultralytics import YOLO
- # Load a YOLOv8n PyTorch model
- model = YOLO("yolov8n.pt")
+ # Load a YOLOv8n PyTorch model
+ model = YOLO("yolov8n.pt")
- # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
- results = model.benchmarks(data="coco8.yaml")
- ```
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ results = model.benchmarks(data="coco8.yaml")
+ ```
=== "CLI"
- ```bash
- # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
- yolo benchmark model=yolov8n.pt data=coco8.yaml
- ```
+ ```bash
+ # Benchmark YOLOv8n speed and accuracy on the COCO8 dataset for all export formats
+ yolo benchmark model=yolov8n.pt data=coco8.yaml
+ ```
For detailed benchmark results, refer to our [benchmarks section](#openvino-yolov8-benchmarks) and [export formats](../modes/export.md) documentation.
diff --git a/docs/en/models/fast-sam.md b/docs/en/models/fast-sam.md
index 89166563e0..8bd088c2aa 100644
--- a/docs/en/models/fast-sam.md
+++ b/docs/en/models/fast-sam.md
@@ -66,7 +66,6 @@ To perform object detection on an image, use the `predict` method as shown below
```python
from ultralytics import FastSAM
- from ultralytics.models.fastsam import FastSAMPrompt
# Define an inference source
source = "path/to/bus.jpg"
@@ -77,23 +76,17 @@ To perform object detection on an image, use the `predict` method as shown below
# Run inference on an image
everything_results = model(source, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
- # Prepare a Prompt Process object
- prompt_process = FastSAMPrompt(source, everything_results, device="cpu")
+ # Run inference with bboxes prompt
+ results = model(source, bboxes=[439, 437, 524, 709])
- # Everything prompt
- results = prompt_process.everything_prompt()
+ # Run inference with points prompt
+ results = model(source, points=[[200, 200]], labels=[1])
- # Bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
- results = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
+ # Run inference with texts prompt
+ results = model(source, texts="a photo of a dog")
- # Text prompt
- results = prompt_process.text_prompt(text="a photo of a dog")
-
- # Point prompt
- # points default [[0,0]] [[x1,y1],[x2,y2]]
- # point_label default [0] [1,0] 0:background, 1:foreground
- results = prompt_process.point_prompt(points=[[200, 200]], pointlabel=[1])
- prompt_process.plot(annotations=results, output="./")
+ # Run inference with bboxes and points and texts prompt at the same time
+ results = model(source, bboxes=[439, 437, 524, 709], points=[[200, 200]], labels=[1], texts="a photo of a dog")
```
=== "CLI"
@@ -105,6 +98,28 @@ To perform object detection on an image, use the `predict` method as shown below
This snippet demonstrates the simplicity of loading a pre-trained model and running a prediction on an image.
+!!! Example "FastSAMPredictor example"
+
+ This way you can run inference on image and get all the segment `results` once and run prompts inference multiple times without running inference multiple times.
+
+ === "Prompt inference"
+
+ ```python
+ from ultralytics.models.fastsam import FastSAMPredictor
+
+ # Create FastSAMPredictor
+ overrides = dict(conf=0.25, task="segment", mode="predict", model="FastSAM-s.pt", save=False, imgsz=1024)
+ predictor = FastSAMPredictor(overrides=overrides)
+
+ # Segment everything
+ everything_results = predictor("ultralytics/assets/bus.jpg")
+
+ # Prompt inference
+ bbox_results = predictor.prompt(everything_results, bboxes=[[200, 200, 300, 300]])
+ point_results = predictor.prompt(everything_results, points=[200, 200])
+ text_results = predictor.prompt(everything_results, texts="a photo of a dog")
+ ```
+
!!! Note
All the returned `results` in above examples are [Results](../modes/predict.md#working-with-results) object which allows access predicted masks and source image easily.
@@ -270,7 +285,6 @@ To use FastSAM for inference in Python, you can follow the example below:
```python
from ultralytics import FastSAM
-from ultralytics.models.fastsam import FastSAMPrompt
# Define an inference source
source = "path/to/bus.jpg"
@@ -281,21 +295,17 @@ model = FastSAM("FastSAM-s.pt") # or FastSAM-x.pt
# Run inference on an image
everything_results = model(source, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9)
-# Prepare a Prompt Process object
-prompt_process = FastSAMPrompt(source, everything_results, device="cpu")
-
-# Everything prompt
-ann = prompt_process.everything_prompt()
+# Run inference with bboxes prompt
+results = model(source, bboxes=[439, 437, 524, 709])
-# Bounding box prompt
-ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
+# Run inference with points prompt
+results = model(source, points=[[200, 200]], labels=[1])
-# Text prompt
-ann = prompt_process.text_prompt(text="a photo of a dog")
+# Run inference with texts prompt
+results = model(source, texts="a photo of a dog")
-# Point prompt
-ann = prompt_process.point_prompt(points=[[200, 200]], pointlabel=[1])
-prompt_process.plot(annotations=ann, output="./")
+# Run inference with bboxes and points and texts prompt at the same time
+results = model(source, bboxes=[439, 437, 524, 709], points=[[200, 200]], labels=[1], texts="a photo of a dog")
```
For more details on inference methods, check the [Predict Usage](#predict-usage) section of the documentation.
diff --git a/docs/en/reference/hub/google/__init__.md b/docs/en/reference/hub/google/__init__.md
new file mode 100644
index 0000000000..ac8c0441e0
--- /dev/null
+++ b/docs/en/reference/hub/google/__init__.md
@@ -0,0 +1,16 @@
+---
+description: Reference for the GCPRegions class in Ultralytics, which provides functionality for testing and analyzing latency across Google Cloud Platform regions.
+keywords: Ultralytics, GCP, Google Cloud Platform, regions, latency testing, cloud computing, networking, performance analysis
+---
+
+# Reference for `ultralytics/hub/google/__init__.py`
+
+!!! Note
+
+ This file is available at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/hub/google/\_\_init\_\_.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/hub/google/__init__.py). If you spot a problem please help fix it by [contributing](https://docs.ultralytics.com/help/contributing/) a [Pull Request](https://github.com/ultralytics/ultralytics/edit/main/ultralytics/hub/google/__init__.py) 🛠️. Thank you 🙏!
+
+
+
+## ::: ultralytics.hub.google.GCPRegions
+
+
diff --git a/docs/en/reference/models/fastsam/prompt.md b/docs/en/reference/models/fastsam/prompt.md
deleted file mode 100644
index 295b798e29..0000000000
--- a/docs/en/reference/models/fastsam/prompt.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-description: Explore the FastSAM prompt module for image annotation and visualization in Ultralytics, detailed with class methods and attributes.
-keywords: Ultralytics, FastSAM, image annotation, image visualization, FastSAMPrompt, YOLO, python script
----
-
-# Reference for `ultralytics/models/fastsam/prompt.py`
-
-!!! Note
-
- This file is available at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/models/fastsam/prompt.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/models/fastsam/prompt.py). If you spot a problem please help fix it by [contributing](https://docs.ultralytics.com/help/contributing/) a [Pull Request](https://github.com/ultralytics/ultralytics/edit/main/ultralytics/models/fastsam/prompt.py) 🛠️. Thank you 🙏!
-
-
-
-## ::: ultralytics.models.fastsam.prompt.FastSAMPrompt
-
-
diff --git a/docs/en/reference/nn/modules/activation.md b/docs/en/reference/nn/modules/activation.md
new file mode 100644
index 0000000000..09dd92edc6
--- /dev/null
+++ b/docs/en/reference/nn/modules/activation.md
@@ -0,0 +1,16 @@
+---
+description: Explore activation functions in Ultralytics, including the Unified activation function and other custom implementations for neural networks.
+keywords: ultralytics, activation functions, neural networks, Unified activation, AGLU, SiLU, ReLU, PyTorch, deep learning, custom activations
+---
+
+# Reference for `ultralytics/nn/modules/activation.py`
+
+!!! Note
+
+ This file is available at [https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/modules/activation.py](https://github.com/ultralytics/ultralytics/blob/main/ultralytics/nn/modules/activation.py). If you spot a problem please help fix it by [contributing](https://docs.ultralytics.com/help/contributing/) a [Pull Request](https://github.com/ultralytics/ultralytics/edit/main/ultralytics/nn/modules/activation.py) 🛠️. Thank you 🙏!
+
+
+
+## ::: ultralytics.nn.modules.activation.AGLU
+
+
 +
+ +
+ +
+ +
+ +
+ +
+