description: Access object detection capabilities of YOLOv8 via our RESTful API. Learn how to use the YOLO Inference API with Python or CLI for swift object detection.
The YOLO Inference API allows you to access the YOLOv8 object detection capabilities via a RESTful API. This enables you to run object detection on images without the need to install and set up the YOLOv8 environment locally.
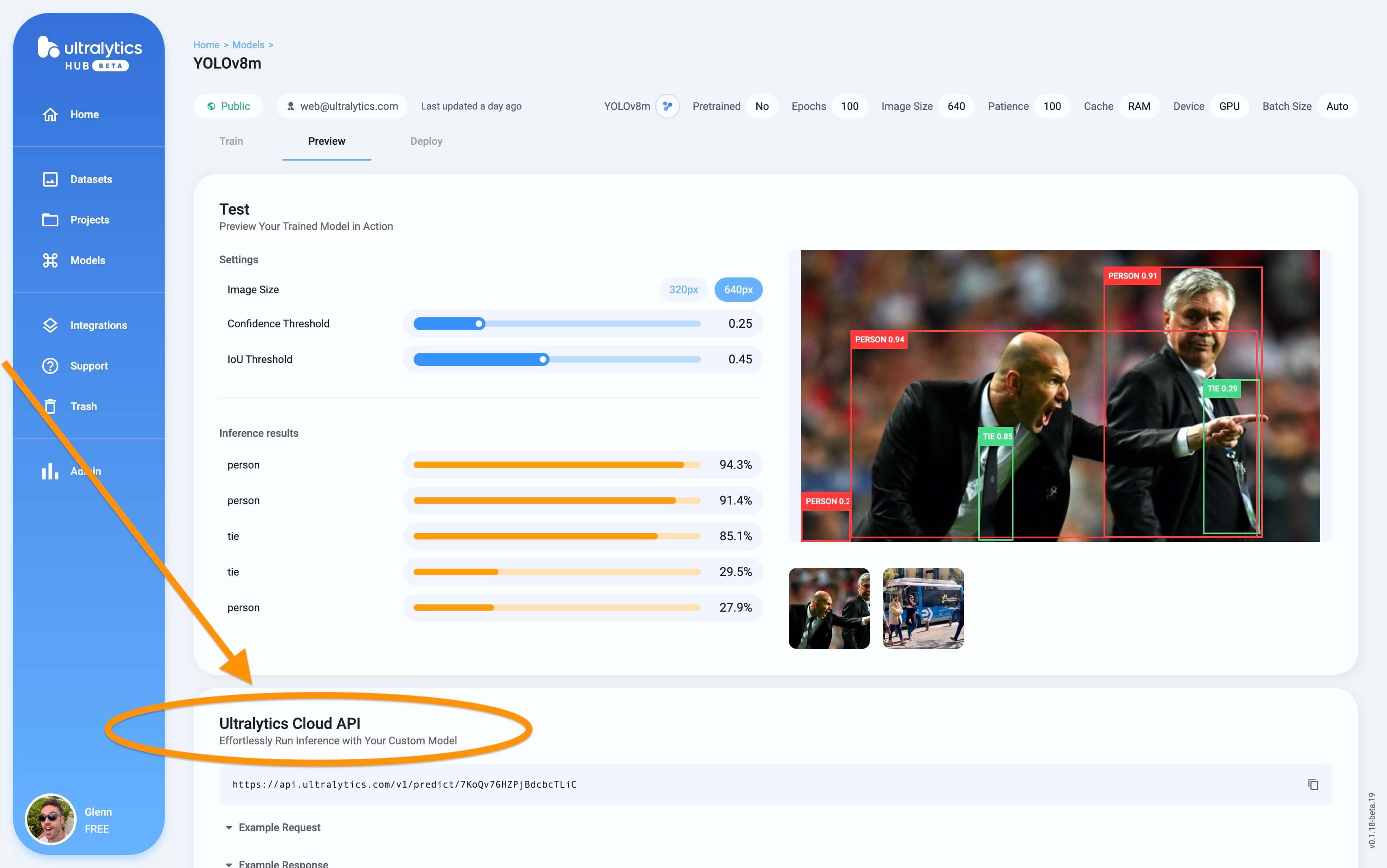 Screenshot of the Inference API section in the trained model Preview tab.
In this example, replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `path/to/image.jpg` with the path to the image you want to analyze.
## Example Usage with CLI
You can use the YOLO Inference API with the command-line interface (CLI) by utilizing the `curl` command. Replace `API_KEY` with your actual API key, `MODEL_ID` with the desired model ID, and `image.jpg` with the path to the image you want to analyze:
curl -X POST "https://api.ultralytics.com/v1/predict/MODEL_ID" \
-H "x-api-key: API_KEY" \
-F "image=@/path/to/image.jpg" \
-F "size=640" \
-F "confidence=0.25" \
-F "iou=0.45"
```
## Passing Arguments
This command sends a POST request to the YOLO Inference API with the specified `MODEL_ID` in the URL and the `API_KEY` in the request `headers`, along with the image file specified by `@path/to/image.jpg`.
Here's an example of passing the `size`, `confidence`, and `iou` arguments via the API URL using the `requests` library in Python:
In this example, the `data` dictionary contains the query arguments `size`, `confidence`, and `iou`, which tells the API to run inference at image size 640 with confidence and IoU thresholds of 0.25 and 0.45.
This will send the query parameters along with the file in the POST request. See the table below for a full list of available inference arguments.
The YOLO Inference API returns a JSON list with the detection results. The format of the JSON list will be the same as the one produced locally by the `results[0].tojson()` command.
The JSON list contains information about the detected objects, their coordinates, classes, and confidence scores.
### Detect Model Format
YOLO detection models, such as `yolov8n.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
YOLO segmentation models, such as `yolov8n-seg.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
Note `segments``x` and `y` lengths may vary from one object to another. Larger or more complex objects may have more segment points.
```json
{
"success": True,
"message": "Inference complete.",
"data": [
{
"name": "person",
"class": 0,
"confidence": 0.856913149356842,
"box": {
"x1": 0.1064866065979004,
"y1": 0.2798851860894097,
"x2": 0.8738358497619629,
"y2": 0.9894873725043403
},
"segments": {
"x": [
0.421875,
0.4203124940395355,
0.41718751192092896
...
],
"y": [
0.2888889014720917,
0.2916666567325592,
0.2916666567325592
...
]
}
},
{
"name": "person",
"class": 0,
"confidence": 0.8512625694274902,
"box": {
"x1": 0.5757311820983887,
"y1": 0.053943040635850696,
"x2": 0.8960096359252929,
"y2": 0.985154045952691
},
"segments": {
"x": [
0.7515624761581421,
0.75,
0.7437499761581421
...
],
"y": [
0.0555555559694767,
0.05833333358168602,
0.05833333358168602
...
]
}
},
{
"name": "tie",
"class": 27,
"confidence": 0.6485961675643921,
"box": {
"x1": 0.33911995887756347,
"y1": 0.6057066175672743,
"x2": 0.4081430912017822,
"y2": 0.9916408962673611
},
"segments": {
"x": [
0.37187498807907104,
0.37031251192092896,
0.3687500059604645
...
],
"y": [
0.6111111044883728,
0.6138888597488403,
0.6138888597488403
...
]
}
}
]
}
```
### Pose Model Format
YOLO pose models, such as `yolov8n-pose.pt`, can return JSON responses from local inference, CLI API inference, and Python API inference. All of these methods produce the same JSON response format.
Note COCO-keypoints pretrained models will have 17 human keypoints. The `visible` part of the keypoints indicates whether a keypoint is visible or obscured. Obscured keypoints may be outside the image or may not be visible, i.e. a person's eyes facing away from the camera.