From 151a803ed0119560f59dbe7b73824dbdcae08fc6 Mon Sep 17 00:00:00 2001
From: "Irving.Gao" <58903762+Irvingao@users.noreply.github.com>
Date: Tue, 24 May 2022 11:38:50 +0800
Subject: [PATCH] [Feature] Support DDOD: Disentangle Your Dense Object
Detector(ACM MM2021 oral) (#7279)
* add ddod feature
* add ddod feature
* modify new
* [Feature] modify ddod code0225
* [Feature] modify ddod code0226
* [Feature] modify ddod code0228
* [Feature] modify ddod code0228#7279
* [Feature] modify ddod code0301
* [Feature] modify ddod code0301 test draft
* [Feature] modify ddod code0301 test
* [Feature] modify ddod code0301 extra
* [Feature] modify ddod code0301 delete src/mmtrack
* [Feature] modify ddod code0302
* [Feature] modify ddod code0302(2)
* [Feature] modify ddod code0303
* [Feature] modify ddod code0303(2)
* [Feature] modify ddod code0303(3)
* [Feature] modify ddod code0305
* [Feature] modify ddod code0305(2) delete diou
* [Feature] modify ddod code0305(3)
* modify ddod code0306
* [Feature] modify ddod code0307
* [Feature] modify ddod code0311
* [Feature] modify ddod code0311(2)
* [Feature] modify ddod code0313
* update
* [Feature] modify ddod code0319
* fix
* fix lint
* [Feature] modify ddod code0321
* update readme
* [0502] compute common vars at once for get_target
* [0504] update ddod conflicts
* [0518] seperate reg and cls loss and get_target compute
* [0518] merge ATSSCostAssigner to ATSSAssigner
* [0518] refine ATSSAssigner
* [0518] refine ATSSAssigner 2
* [0518] refine ATSSAssigner 2
* [0518] refine ATSSAssigner 3
* [0519] fix bugs
* update
* fix lr
* update weight
Co-authored-by: hha <1286304229@qq.com>
---
configs/ddod/README.md | 31 +
configs/ddod/ddod_r50_fpn_1x_coco.py | 67 ++
configs/ddod/metafile.yml | 33 +
mmdet/core/bbox/assigners/atss_assigner.py | 65 +-
mmdet/models/dense_heads/__init__.py | 3 +-
mmdet/models/dense_heads/ddod_head.py | 778 ++++++++++++++++++
mmdet/models/detectors/__init__.py | 3 +-
mmdet/models/detectors/ddod.py | 19 +
.../test_dense_heads/test_ddod_head.py | 72 ++
tests/test_utils/test_assigner.py | 1 +
10 files changed, 1065 insertions(+), 7 deletions(-)
create mode 100644 configs/ddod/README.md
create mode 100644 configs/ddod/ddod_r50_fpn_1x_coco.py
create mode 100644 configs/ddod/metafile.yml
create mode 100644 mmdet/models/dense_heads/ddod_head.py
create mode 100644 mmdet/models/detectors/ddod.py
create mode 100644 tests/test_models/test_dense_heads/test_ddod_head.py
diff --git a/configs/ddod/README.md b/configs/ddod/README.md
new file mode 100644
index 000000000..9ab1f4869
--- /dev/null
+++ b/configs/ddod/README.md
@@ -0,0 +1,31 @@
+# DDOD
+
+> [Disentangle Your Dense Object Detector](https://arxiv.org/pdf/2107.02963.pdf)
+
+
+
+## Abstract
+
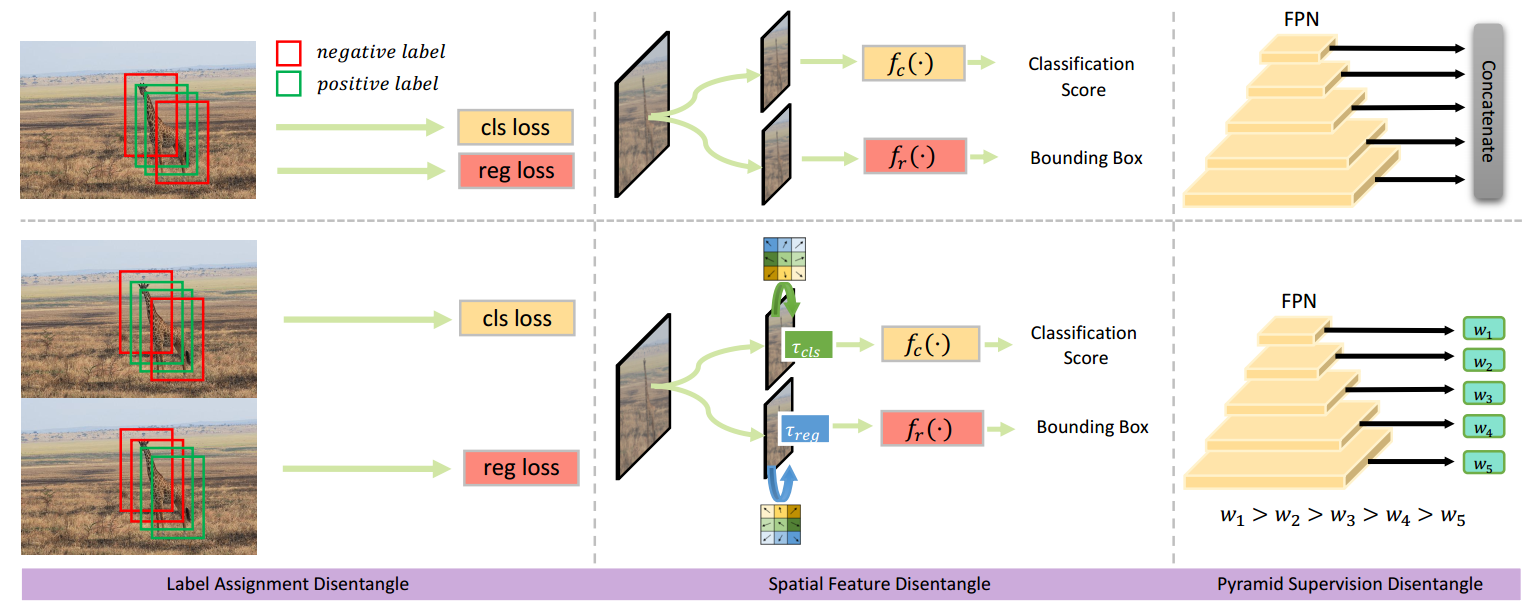
+Deep learning-based dense object detectors have achieved great success in the past few years and have been applied to numerous multimedia applications such as video understanding. However, the current training pipeline for dense detectors is compromised to lots of conjunctions that may not hold. In this paper, we investigate three such important conjunctions: 1) only samples assigned as positive in classification head are used to train the regression head; 2) classification and regression share the same input feature and computational fields defined by the parallel head architecture; and 3) samples distributed in different feature pyramid layers are treated equally when computing the loss. We first carry out a series of pilot experiments to show disentangling such conjunctions can lead to persistent performance improvement. Then, based on these findings, we propose Disentangled Dense Object Detector(DDOD), in which simple and effective disentanglement mechanisms are designed and integrated into the current state-of-the-art dense object detectors. Extensive experiments on MS COCO benchmark show that our approach can lead to 2.0 mAP, 2.4 mAP and 2.2 mAP absolute improvements on RetinaNet, FCOS, and ATSS baselines with negligible extra overhead. Notably, our best model reaches 55.0 mAP on the COCO test-dev set and 93.5 AP on the hard subset of WIDER FACE, achieving new state-of-the-art performance on these two competitive benchmarks. Code is available at https://github.com/zehuichen123/DDOD.
+
+
+
+