This PR implements a work-stealing thread pool for use inside
EventEngine implementations. Because of historical risks here, I've
guarded the new implementation behind an experiment flag:
`GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the
original thread pool implementation.
Benchmarks look very promising:
```
bazel test \
--test_timeout=300 \
--config=opt -c opt \
--test_output=streamed \
--test_arg='--benchmark_format=csv' \
--test_arg='--benchmark_min_time=0.15' \
--test_arg='--benchmark_filter=_FanOut' \
--test_arg='--benchmark_repetitions=15' \
--test_arg='--benchmark_report_aggregates_only=true' \
test/cpp/microbenchmarks:bm_thread_pool
```
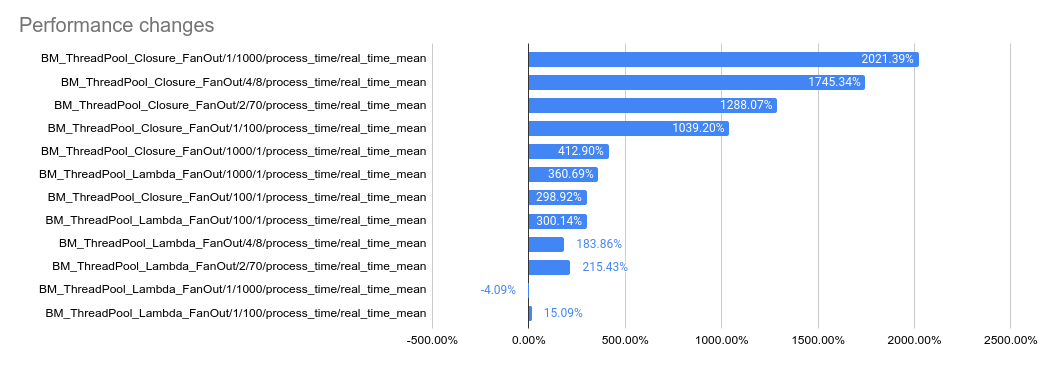
2023-05-04: `bm_thread_pool` benchmark results on my local machine (64
core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to
master:
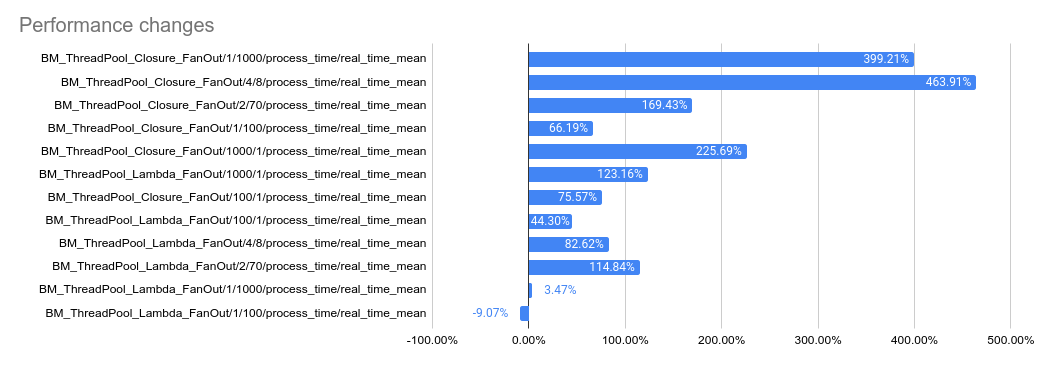
2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE
environment (unsure of machine configuration, likely small), comparing
this PR to master.
---------
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
(hopefully last try)
Add new channel arg GRPC_ARG_ABSOLUTE_MAX_METADATA_SIZE as hard limit
for metadata. Change GRPC_ARG_MAX_METADATA_SIZE to be a soft limit.
Behavior is as follows:
Hard limit
(1) if hard limit is explicitly set, this will be used.
(2) if hard limit is not explicitly set, maximum of default and soft
limit * 1.25 (if soft limit is set) will be used.
Soft limit
(1) if soft limit is explicitly set, this will be used.
(2) if soft limit is not explicitly set, maximum of default and hard
limit * 0.8 (if hard limit is set) will be used.
Requests between soft and hard limit will be rejected randomly, requests
above hard limit will be rejected.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
The pooled allocator currently has an ABA issue in the allocation path.
This change should fix that - algorithm is described reasonably well in
the PR.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
* Update include
* Clean up `grpc_empty_slice()`
* Clean up `grpc_slice_malloc()`
* Clean up `grpc_slice_unref()`
* Clean up `grpc_slice_ref()`
* Clean up `grpc_slice_split_tail()`
* Clean up `grpc_slice_split_head()`
* Clean up `grpc_slice_sub()`
* Clean up `grpc_slice_buffer_add()`
* Clean up `grpc_slice_buffer_add_indexed()`
* Clean up `grpc_slice_buffer_pop()`
* Clean up `grpc_slice_from_static_buffer()`
* Clean up `grpc_slice_from_copied_buffer()`
* Clean up `grpc_metadata_array_init()`
* Clean up `grpc_metadata_array_destroy()`
* Clean up `gpr_inf_future()`
* Clean up `gpr_time_0()`
* Clean up `grpc_byte_buffer_copy()`
* Clean up `grpc_byte_buffer_destroy()`
* Clean up `grpc_byte_buffer_length()`
* Clean up `grpc_byte_buffer_reader_init()`
* Clean up `grpc_byte_buffer_reader_destroy()`
* Clean up `grpc_byte_buffer_reader_next()`
* Clean up `grpc_byte_buffer_reader_peek()`
* Clean up `grpc_raw_byte_buffer_create()`
* Clean up `grpc_slice_new_with_user_data()`
* Clean up `grpc_slice_new_with_len()`
* Clean up `grpc_call_start_batch()`
* Clean up `grpc_call_cancel_with_status()`
* Clean up `grpc_call_failed_before_recv_message()`
* Clean up `grpc_call_ref()`
* Clean up `grpc_call_unref()`
* Clean up `grpc_call_error_to_string()`
* Fix typos
* Automated change: Fix sanity tests
* Precondition ChannelArgs with EventEngines
If an EventEngine is not explicitly provided to ChannelArgs, the default
EventEngine will be set when ChannelArgs are preconditioned.
* channel_idle_filter: EE from channel_args
* grpclb: EE from channel_args
* weighted_target: ee from channel_args
* sanitize
* xds cluster manager
* posix native resolver: own an EE ref from iomgr initialization
* reviewer feedback
* reviewer feedback
* iwyu
* iwyu
* change ownership and remove unneeded methods
* clang_format and use consistent engine naming
* store EE ref in channel_stack and use it in channel idle filter
* don't store a separate shared_ptr in NativeDNSResolver
* add GetEventEngine() method to LB policy helper interface
* stop holding refs to the EE instance in LB policies
* clang-format
* change channel stack to get EE instance from channel args
* update XdsWrrLocalityLb
* fix lb_policy_test
* precondition channel_args in ServerBuilder and microbenchmark fixtures
* add required engine to channel_stack test
* sanitize
* dep fix
* add EE to filter fuzzer
* precondition BM_IsolatedFilter channelargs
* fix
* remove unused using statement
* iwyu again??
* remove preconditioning from C++ surface API
* fix bm_call_create
* Automated change: Fix sanity tests
* iwyu
* rm this->
* rm unused deps
* add internal EE arg macro
* precondition filter_fuzzer
* Automated change: Fix sanity tests
* iwyu
* ChannelStackBuilder requires preconditioned ChannelArgs
* iwyu
* iwyu again?
* rm build.SetChannelArgs; rm unused declaration
* fix nullptr string creation
Co-authored-by: Mark D. Roth <roth@google.com>
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
* ThreadPool benchmarks
These are nearly identical to the EventEngine benchmarks at the moment. We can consider removing the redundant tests from the EventEngine code and focusing on EventEngine-specific things (e.g., timer cancellation)
* rm unused header
* rm leak
* fix: moved dependencies
* begin c++
* Automated change: Fix sanity tests
* progress
* progress
* missing-files
* Automated change: Fix sanity tests
* moved-from-stats
* remove old benchmark cruft, get tests compiling
* iwyu
* Automated change: Fix sanity tests
* fix
* fix
* fixes
* fixes
* add needed constructor
* Automated change: Fix sanity tests
* iwyu
* fix
* fix?
* fix
* fix
* Remove ResetDefaultEventEngine
Now that it is a weak_ptr, there's no need to explicitly reset it. When
the tracked shared_ptr is deleted, the weak_ptr will fail to lock, and a
new default EventEngine will be created.
* forget existing engine with FactoryReset
* add visibility
* fix
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
Co-authored-by: AJ Heller <hork@google.com>
* Remove ResetDefaultEventEngine
Now that it is a weak_ptr, there's no need to explicitly reset it. When
the tracked shared_ptr is deleted, the weak_ptr will fail to lock, and a
new default EventEngine will be created.
* forget existing engine with FactoryReset
* init/shutdown in event engine for now
* fix
* fix
* fix windows deadlock
* Automated change: Fix sanity tests
* fix
* better windows fix
Co-authored-by: AJ Heller <hork@google.com>
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
* Reland x2: Make GetDefaultEventEngine return a shared_ptr
* remove thread leak from NativeDNSResolver
This is not going to work for resolvers that support cancellation.
* give resolvers bounded lifetimes
Some resolver own EventEngines. EventEngines cannot run off the end of
the process since they have unjoined threads (problematic in a small set
of environments). This gives resolvers bounded lifetimes, and allows
replacement of resolvers without ASAN issues of deleting resolvers in
active use (occurs in tests).
* fix
* fix windows
* fix surface init test
* fix
* sanitize
* use after move
* the test must wait for the callback to be destroyed
* windows fix: delete the resolver on iomgr shutdown, not before
* Make TimerManager threads non-joinable
On gRPC shutdown, any unjoined TimerManager threads will cause TSAN to
detect thread leaks. This fix resolves issues I saw in end2end test
shutdown in another PR, where a single timer manager thread was always
alive after the test ended.
The long-term solution is to integrate the new ThreadPool here, but this
unblocks me for now.
* backport fix
* fix
* shared_ptr<EventEngine> in EventEngine benchmarks
* [WIP] EventEngine::Run microbenchmarks
* Add fanout impl and fix tracking of time spent doing work in threads
* tune down benchmarks; fix fanout counting logic.
* tune down closure fanout tests
* format
* odr
* reviewer feedback
* unify some fanout logic; add a large-AnyInvocable test
lambdas that take an allocation are about 10x slower
* reviewer feedback
* fix invalid vector access
* rm DNS
* format
* copy params for each lambda callback
This fixes segfaults when we cannot ensure all callbacks are complete
before exiting the test.
* s/promise/Notification/g bm_exec_ctx
* ODR and leak
* fix division by zero
* fix
* WorkQueue
* weaken the large obj stress test for Windows; documentation
* update comment
* Add WorkQueue microbenchmark. Results below ...
------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
------------------------------------------------------------------------------------------
BM_WorkQueueIntptrPopFront/1 297 ns 297 ns 2343500 items_per_second=3.3679M/s
BM_WorkQueueIntptrPopFront/8 7022 ns 7020 ns 99356 items_per_second=1.13956M/s
BM_WorkQueueIntptrPopFront/64 59606 ns 59590 ns 11770 items_per_second=1074k/s
BM_WorkQueueIntptrPopFront/512 477867 ns 477748 ns 1469 items_per_second=1071.7k/s
BM_WorkQueueIntptrPopFront/4096 3815786 ns 3814925 ns 184 items_per_second=1073.68k/s
I0902 19:05:22.138022069 12 test_config.cc:194] TestEnvironment ends
================================================================================
* use int64_t for times. 0 performance change
------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
------------------------------------------------------------------------------------------
BM_WorkQueueIntptrPopFront/1 277 ns 277 ns 2450292 items_per_second=3.60967M/s
BM_WorkQueueIntptrPopFront/8 6718 ns 6716 ns 105497 items_per_second=1.19126M/s
BM_WorkQueueIntptrPopFront/64 56428 ns 56401 ns 12268 items_per_second=1.13474M/s
BM_WorkQueueIntptrPopFront/512 458953 ns 458817 ns 1550 items_per_second=1.11591M/s
BM_WorkQueueIntptrPopFront/4096 3686357 ns 3685120 ns 191 items_per_second=1.1115M/s
I0902 19:25:31.549382949 12 test_config.cc:194] TestEnvironment ends
================================================================================
* add PopBack tests: same performance profile exactly
* use Mutex instead of Spinlock
It's safer, and so far equally performant in benchmarks of opt builds
* add deque test for comparison. It is faster on all tests.
* Add sparsely-populated multi-threaded benchmarks.
* fix
* fix
* refactor to help thread safety analysis
* Specialize WorkQueue for Closure*s and AnyInvocables
* remove unused callback storage
* add single-threaded benchmark for closure vs invocable
* sanitize
* missing include
* move bm_work_queue to microbenchmarks so it isn't exported
* s/workqueue/work_queue/g
* use nullptr instead of optionals for popped closures
* reviewer test suggestion
* private things are private
* add a work_queue fuzzer
Ran for 10 minutes @ 42 jobs @ 42 workers. Zero failures.
Checked in a selection of 100 good seeds after merging the thousands of
results.
* fix
* fix header guards
* nuke the corpora
* feedback
* sanitize
* Timestamp::Now
* fix
* fuzzers do not work on windows
* windows does not like multithreaded benchmark tests
{kind=link}
{kind=link}