In real services most of our time ends up in the `Read1()` function,
which populates one byte into the bit buffer.
Change this to read in as many as possible bytes at a time into that
buffer.
Additionally, generate all possible (to some depth) parser geometries,
and add a benchmark for them. Run that benchmark and select the best
geometry for decoding base64 strings (since this is the main use-case).
(gives about a 30% speed boost parsing base64 then huffman encoded
random binary strings)
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This PR implements a work-stealing thread pool for use inside
EventEngine implementations. Because of historical risks here, I've
guarded the new implementation behind an experiment flag:
`GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the
original thread pool implementation.
Benchmarks look very promising:
```
bazel test \
--test_timeout=300 \
--config=opt -c opt \
--test_output=streamed \
--test_arg='--benchmark_format=csv' \
--test_arg='--benchmark_min_time=0.15' \
--test_arg='--benchmark_filter=_FanOut' \
--test_arg='--benchmark_repetitions=15' \
--test_arg='--benchmark_report_aggregates_only=true' \
test/cpp/microbenchmarks:bm_thread_pool
```
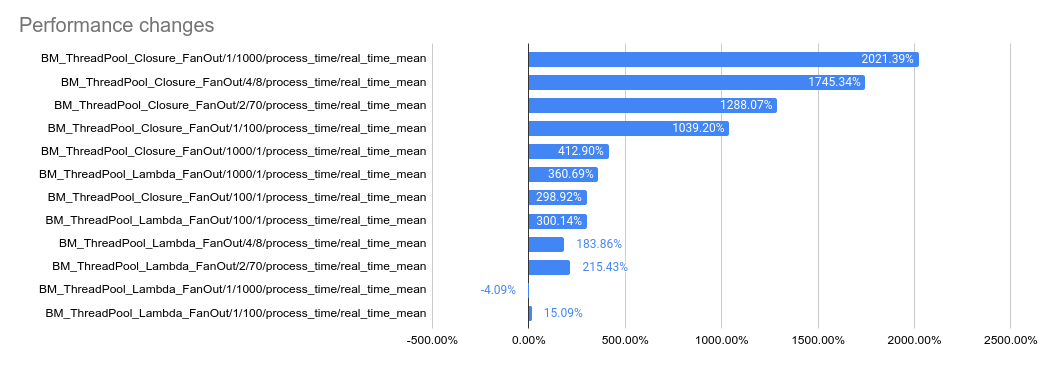
2023-05-04: `bm_thread_pool` benchmark results on my local machine (64
core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to
master:
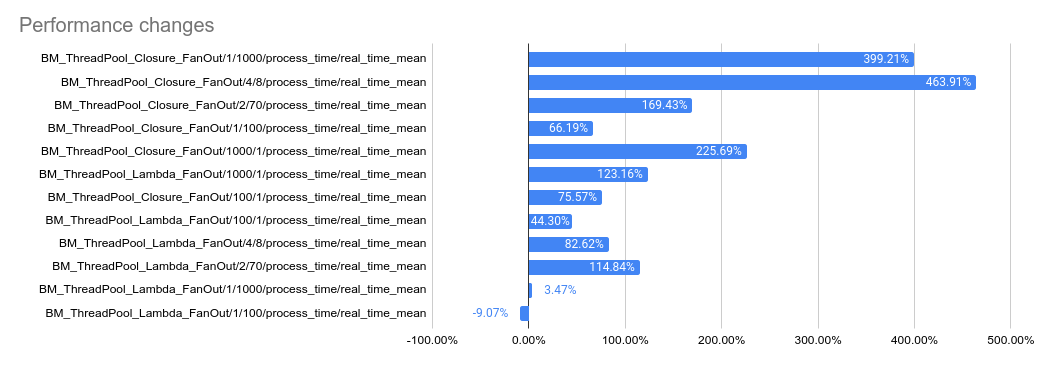
2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE
environment (unsure of machine configuration, likely small), comparing
this PR to master.
---------
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
(hopefully last try)
Add new channel arg GRPC_ARG_ABSOLUTE_MAX_METADATA_SIZE as hard limit
for metadata. Change GRPC_ARG_MAX_METADATA_SIZE to be a soft limit.
Behavior is as follows:
Hard limit
(1) if hard limit is explicitly set, this will be used.
(2) if hard limit is not explicitly set, maximum of default and soft
limit * 1.25 (if soft limit is set) will be used.
Soft limit
(1) if soft limit is explicitly set, this will be used.
(2) if soft limit is not explicitly set, maximum of default and hard
limit * 0.8 (if hard limit is set) will be used.
Requests between soft and hard limit will be rejected randomly, requests
above hard limit will be rejected.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
The pooled allocator currently has an ABA issue in the allocation path.
This change should fix that - algorithm is described reasonably well in
the PR.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
* Update include
* Clean up `grpc_empty_slice()`
* Clean up `grpc_slice_malloc()`
* Clean up `grpc_slice_unref()`
* Clean up `grpc_slice_ref()`
* Clean up `grpc_slice_split_tail()`
* Clean up `grpc_slice_split_head()`
* Clean up `grpc_slice_sub()`
* Clean up `grpc_slice_buffer_add()`
* Clean up `grpc_slice_buffer_add_indexed()`
* Clean up `grpc_slice_buffer_pop()`
* Clean up `grpc_slice_from_static_buffer()`
* Clean up `grpc_slice_from_copied_buffer()`
* Clean up `grpc_metadata_array_init()`
* Clean up `grpc_metadata_array_destroy()`
* Clean up `gpr_inf_future()`
* Clean up `gpr_time_0()`
* Clean up `grpc_byte_buffer_copy()`
* Clean up `grpc_byte_buffer_destroy()`
* Clean up `grpc_byte_buffer_length()`
* Clean up `grpc_byte_buffer_reader_init()`
* Clean up `grpc_byte_buffer_reader_destroy()`
* Clean up `grpc_byte_buffer_reader_next()`
* Clean up `grpc_byte_buffer_reader_peek()`
* Clean up `grpc_raw_byte_buffer_create()`
* Clean up `grpc_slice_new_with_user_data()`
* Clean up `grpc_slice_new_with_len()`
* Clean up `grpc_call_start_batch()`
* Clean up `grpc_call_cancel_with_status()`
* Clean up `grpc_call_failed_before_recv_message()`
* Clean up `grpc_call_ref()`
* Clean up `grpc_call_unref()`
* Clean up `grpc_call_error_to_string()`
* Fix typos
* Automated change: Fix sanity tests
* Precondition ChannelArgs with EventEngines
If an EventEngine is not explicitly provided to ChannelArgs, the default
EventEngine will be set when ChannelArgs are preconditioned.
* channel_idle_filter: EE from channel_args
* grpclb: EE from channel_args
* weighted_target: ee from channel_args
* sanitize
* xds cluster manager
* posix native resolver: own an EE ref from iomgr initialization
* reviewer feedback
* reviewer feedback
* iwyu
* iwyu
* change ownership and remove unneeded methods
* clang_format and use consistent engine naming
* store EE ref in channel_stack and use it in channel idle filter
* don't store a separate shared_ptr in NativeDNSResolver
* add GetEventEngine() method to LB policy helper interface
* stop holding refs to the EE instance in LB policies
* clang-format
* change channel stack to get EE instance from channel args
* update XdsWrrLocalityLb
* fix lb_policy_test
* precondition channel_args in ServerBuilder and microbenchmark fixtures
* add required engine to channel_stack test
* sanitize
* dep fix
* add EE to filter fuzzer
* precondition BM_IsolatedFilter channelargs
* fix
* remove unused using statement
* iwyu again??
* remove preconditioning from C++ surface API
* fix bm_call_create
* Automated change: Fix sanity tests
* iwyu
* rm this->
* rm unused deps
* add internal EE arg macro
* precondition filter_fuzzer
* Automated change: Fix sanity tests
* iwyu
* ChannelStackBuilder requires preconditioned ChannelArgs
* iwyu
* iwyu again?
* rm build.SetChannelArgs; rm unused declaration
* fix nullptr string creation
Co-authored-by: Mark D. Roth <roth@google.com>
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
* ThreadPool benchmarks
These are nearly identical to the EventEngine benchmarks at the moment. We can consider removing the redundant tests from the EventEngine code and focusing on EventEngine-specific things (e.g., timer cancellation)
* rm unused header
* rm leak
* fix: moved dependencies
* begin c++
* Automated change: Fix sanity tests
* progress
* progress
* missing-files
* Automated change: Fix sanity tests
* moved-from-stats
* remove old benchmark cruft, get tests compiling
* iwyu
* Automated change: Fix sanity tests
* fix
* fix
* fixes
* fixes
* add needed constructor
* Automated change: Fix sanity tests
* iwyu
* fix
* fix?
* fix
* fix
* Remove ResetDefaultEventEngine
Now that it is a weak_ptr, there's no need to explicitly reset it. When
the tracked shared_ptr is deleted, the weak_ptr will fail to lock, and a
new default EventEngine will be created.
* forget existing engine with FactoryReset
* add visibility
* fix
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
Co-authored-by: AJ Heller <hork@google.com>
* Remove ResetDefaultEventEngine
Now that it is a weak_ptr, there's no need to explicitly reset it. When
the tracked shared_ptr is deleted, the weak_ptr will fail to lock, and a
new default EventEngine will be created.
* forget existing engine with FactoryReset
* init/shutdown in event engine for now
* fix
* fix
* fix windows deadlock
* Automated change: Fix sanity tests
* fix
* better windows fix
Co-authored-by: AJ Heller <hork@google.com>
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
* Reland x2: Make GetDefaultEventEngine return a shared_ptr
* remove thread leak from NativeDNSResolver
This is not going to work for resolvers that support cancellation.
* give resolvers bounded lifetimes
Some resolver own EventEngines. EventEngines cannot run off the end of
the process since they have unjoined threads (problematic in a small set
of environments). This gives resolvers bounded lifetimes, and allows
replacement of resolvers without ASAN issues of deleting resolvers in
active use (occurs in tests).
* fix
* fix windows
* fix surface init test
* fix
* sanitize
* use after move
* the test must wait for the callback to be destroyed
* windows fix: delete the resolver on iomgr shutdown, not before
* Make TimerManager threads non-joinable
On gRPC shutdown, any unjoined TimerManager threads will cause TSAN to
detect thread leaks. This fix resolves issues I saw in end2end test
shutdown in another PR, where a single timer manager thread was always
alive after the test ended.
The long-term solution is to integrate the new ThreadPool here, but this
unblocks me for now.
* backport fix
* fix
* shared_ptr<EventEngine> in EventEngine benchmarks
* [WIP] EventEngine::Run microbenchmarks
* Add fanout impl and fix tracking of time spent doing work in threads
* tune down benchmarks; fix fanout counting logic.
* tune down closure fanout tests
* format
* odr
* reviewer feedback
* unify some fanout logic; add a large-AnyInvocable test
lambdas that take an allocation are about 10x slower
* reviewer feedback
* fix invalid vector access
* rm DNS
* format
* copy params for each lambda callback
This fixes segfaults when we cannot ensure all callbacks are complete
before exiting the test.
* s/promise/Notification/g bm_exec_ctx
* ODR and leak
* fix division by zero
* fix
{kind=link}
{kind=link}