Reasoning:
* This benchmark will need to be rewritten to work with the new transport API by EOY anyhow, and the API is fairly different.
* Deleting this saves us from having to migrate the `grpc_endpoint` implementation to `EventEngine::Endpoint`.
Closes#36514
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36514 from drfloob:nix-bm_chttp2_transport e6c6edf39f
PiperOrigin-RevId: 630408686
[grpc][Gpr_To_Absl_Logging] Migrating from gpr to absl logging GPR_ASSERT
Replacing GPR_ASSERT with absl CHECK
These changes have been made using string replacement and regex.
Will not be replacing all instances of CHECK with CHECK_EQ , CHECK_NE etc because there are too many callsites. Only ones which are doable using very simple regex with least chance of failure will be replaced.
Given that we have 5000+ instances of GPR_ASSERT to edit, Doing it manually is too much work for both the author and reviewer.
<!--
If you know who should review your pull request, please assign it to that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the appropriate
lang label.
-->
Closes#36405
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36405 from tanvi-jagtap:tjagtap_microbenchmarks_01 0dcec5d852
PiperOrigin-RevId: 626522246
[grpc][Gpr_To_Absl_Logging] Migrating from gpr to absl logging GPR_ASSERT
Replacing GPR_ASSERT with absl CHECK
Will not be replacing CHECK with CHECK_EQ , CHECK_NE etc because there are too many callsites. Only a few - which fit into single - line regex will be changed. This would be small in number just to reduce the load later.
Replacing CHECK with CHECK_EQ , CHECK_NE etc could be done using Cider-V once these changes are submitted if we want to clean up later. Given that we have 5000+ instances of GPR_ASSERT to edit, Doing it manually is too much work for both the author and reviewer.
<!--
If you know who should review your pull request, please assign it to that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the appropriate
lang label.
-->
Closes#36267
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36267 from tanvi-jagtap:tjagtap_grpc_assert_02 3aed626101
PiperOrigin-RevId: 623469007
See #36176. The only difference is a temporary shim for Secure credentials types, which was already discussed and approved separately.
Closes#36242
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36242 from drfloob:reland/36176 f07bebe289
PiperOrigin-RevId: 621879911
Instead, build a library and re-use that across compilations.
This still invokes a link step per target, and we'll want to deal with that at some point too, but at least this makes some progress to not being as wasteful with our compilation resources.
Additionally: remove bm_pollset -- it was having some problems compiling, and we really don't need it anymore.
Closes#36197
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36197 from ctiller:maintain-this-shite 9955026e23
PiperOrigin-RevId: 620946543
Internally, use `std::vector` instead of `ChunkedVector` to hold extra metadatum.
I'm not totally convinced this is the right move, so it's going to be a try it and monitor for a month or so thing... I might roll back if performance is actually affected (but I think we'll see some wins and losses and overall about a wash).
Closes#36118
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36118 from ctiller:YUPYUPYUP 68e0acd0a2
PiperOrigin-RevId: 620902195
also:
- remove tail recursion from promise endpoint read completion (actually overflowed stack!)
- remove retry filter from benchmark - we probably don't want this long term, but for now nobody else is using this benchmark and our use case doesn't use grpc retries so.... good enough
Closes#36050
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36050 from ctiller:cgbm 65b1c26767
PiperOrigin-RevId: 612577071
This adds the following new targets:
- `channel`: A virtual interface for a channel.
- `legacy_channel`: A channel implementation that supports the filter stack and call v2.
- `channel_create`: A standalone function to create a channel.
- `server_interface`: A base class with a few accessor methods used in surface/call.cc.
- `server`: The actual server implementation.
- `api_trace`, `call_tracer`, `server_call_tracer_filter`, `call_finalization`: These were split out of `grpc_base` to avoid various dependency problems.
- `compression`: This is a combination of the previously existing `compression_internal` target and the compression code that was part of `grpc_base`.
Closes#35924
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/35924 from markdroth:channel_interface 94a7fffddb
PiperOrigin-RevId: 612512438
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
Expand our fuzzing capabilities by allowing fuzzers to choose the bits
that go into random number distribution generators.
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
Lets us sever the dependency between stats & exec ctx (finally).
More work likely needs to go into the *mechanism* used here (I'm not a
fan of the per thread index), but that's also something we can address
later.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: Mark D. Roth <roth@google.com>
Co-authored-by: markdroth <markdroth@users.noreply.github.com>
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
In real services most of our time ends up in the `Read1()` function,
which populates one byte into the bit buffer.
Change this to read in as many as possible bytes at a time into that
buffer.
Additionally, generate all possible (to some depth) parser geometries,
and add a benchmark for them. Run that benchmark and select the best
geometry for decoding base64 strings (since this is the main use-case).
(gives about a 30% speed boost parsing base64 then huffman encoded
random binary strings)
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This PR implements a work-stealing thread pool for use inside
EventEngine implementations. Because of historical risks here, I've
guarded the new implementation behind an experiment flag:
`GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the
original thread pool implementation.
Benchmarks look very promising:
```
bazel test \
--test_timeout=300 \
--config=opt -c opt \
--test_output=streamed \
--test_arg='--benchmark_format=csv' \
--test_arg='--benchmark_min_time=0.15' \
--test_arg='--benchmark_filter=_FanOut' \
--test_arg='--benchmark_repetitions=15' \
--test_arg='--benchmark_report_aggregates_only=true' \
test/cpp/microbenchmarks:bm_thread_pool
```
2023-05-04: `bm_thread_pool` benchmark results on my local machine (64
core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to
master:
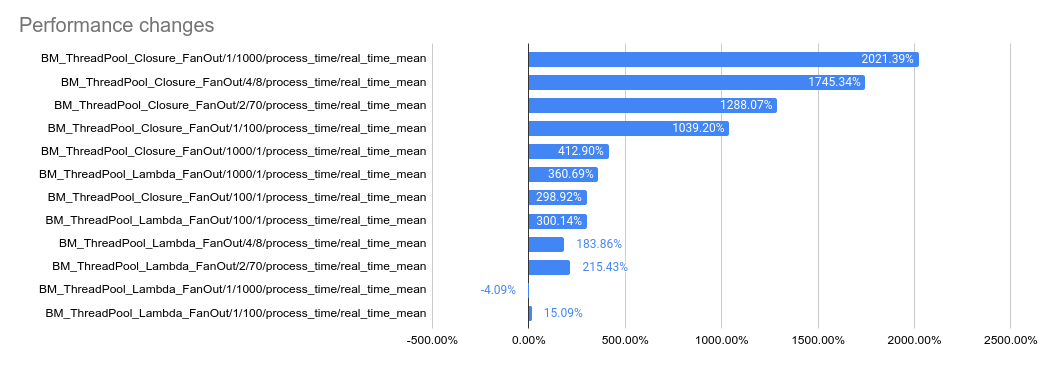
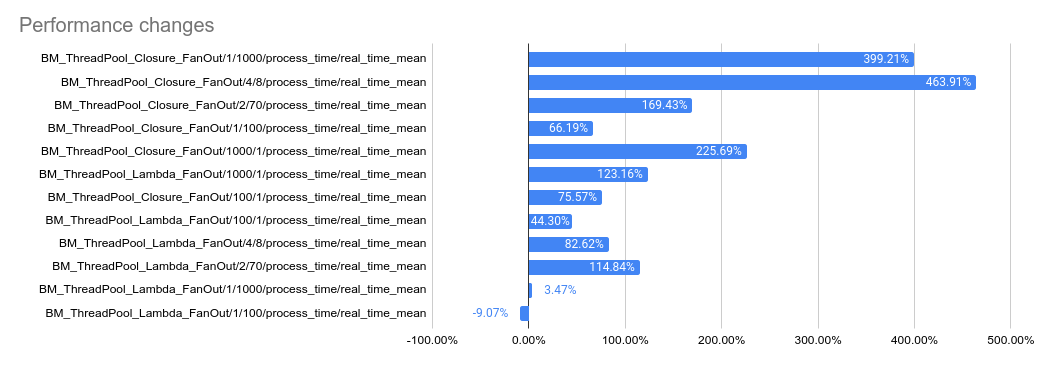
2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE
environment (unsure of machine configuration, likely small), comparing
this PR to master.
---------
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
(hopefully last try)
Add new channel arg GRPC_ARG_ABSOLUTE_MAX_METADATA_SIZE as hard limit
for metadata. Change GRPC_ARG_MAX_METADATA_SIZE to be a soft limit.
Behavior is as follows:
Hard limit
(1) if hard limit is explicitly set, this will be used.
(2) if hard limit is not explicitly set, maximum of default and soft
limit * 1.25 (if soft limit is set) will be used.
Soft limit
(1) if soft limit is explicitly set, this will be used.
(2) if soft limit is not explicitly set, maximum of default and hard
limit * 0.8 (if hard limit is set) will be used.
Requests between soft and hard limit will be rejected randomly, requests
above hard limit will be rejected.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
The pooled allocator currently has an ABA issue in the allocation path.
This change should fix that - algorithm is described reasonably well in
the PR.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
* Update include
* Clean up `grpc_empty_slice()`
* Clean up `grpc_slice_malloc()`
* Clean up `grpc_slice_unref()`
* Clean up `grpc_slice_ref()`
* Clean up `grpc_slice_split_tail()`
* Clean up `grpc_slice_split_head()`
* Clean up `grpc_slice_sub()`
* Clean up `grpc_slice_buffer_add()`
* Clean up `grpc_slice_buffer_add_indexed()`
* Clean up `grpc_slice_buffer_pop()`
* Clean up `grpc_slice_from_static_buffer()`
* Clean up `grpc_slice_from_copied_buffer()`
* Clean up `grpc_metadata_array_init()`
* Clean up `grpc_metadata_array_destroy()`
* Clean up `gpr_inf_future()`
* Clean up `gpr_time_0()`
* Clean up `grpc_byte_buffer_copy()`
* Clean up `grpc_byte_buffer_destroy()`
* Clean up `grpc_byte_buffer_length()`
* Clean up `grpc_byte_buffer_reader_init()`
* Clean up `grpc_byte_buffer_reader_destroy()`
* Clean up `grpc_byte_buffer_reader_next()`
* Clean up `grpc_byte_buffer_reader_peek()`
* Clean up `grpc_raw_byte_buffer_create()`
* Clean up `grpc_slice_new_with_user_data()`
* Clean up `grpc_slice_new_with_len()`
* Clean up `grpc_call_start_batch()`
* Clean up `grpc_call_cancel_with_status()`
* Clean up `grpc_call_failed_before_recv_message()`
* Clean up `grpc_call_ref()`
* Clean up `grpc_call_unref()`
* Clean up `grpc_call_error_to_string()`
* Fix typos
* Automated change: Fix sanity tests
{kind=link}
{kind=link}