This PR implements a work-stealing thread pool for use inside
EventEngine implementations. Because of historical risks here, I've
guarded the new implementation behind an experiment flag:
`GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the
original thread pool implementation.
Benchmarks look very promising:
```
bazel test \
--test_timeout=300 \
--config=opt -c opt \
--test_output=streamed \
--test_arg='--benchmark_format=csv' \
--test_arg='--benchmark_min_time=0.15' \
--test_arg='--benchmark_filter=_FanOut' \
--test_arg='--benchmark_repetitions=15' \
--test_arg='--benchmark_report_aggregates_only=true' \
test/cpp/microbenchmarks:bm_thread_pool
```
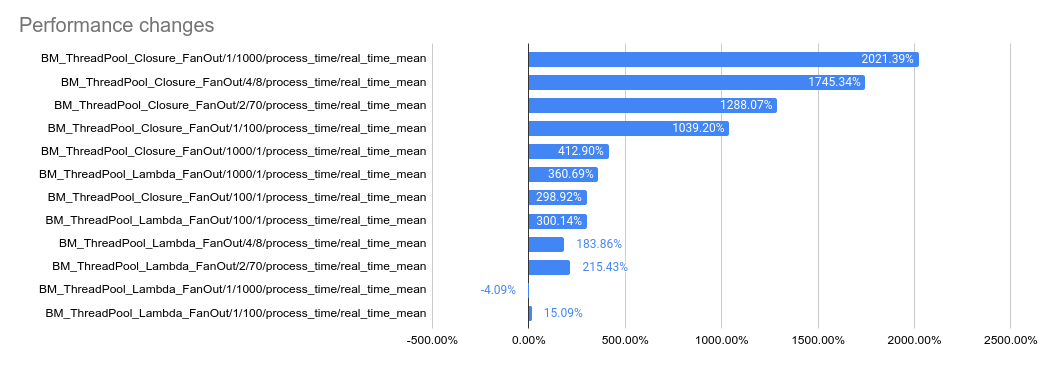
2023-05-04: `bm_thread_pool` benchmark results on my local machine (64
core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to
master:
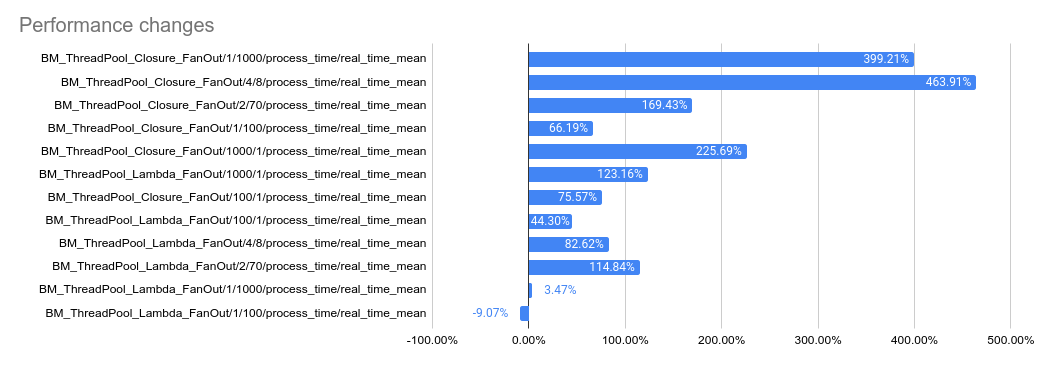
2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE
environment (unsure of machine configuration, likely small), comparing
this PR to master.
---------
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
Reverts grpc/grpc#33002. Breaks internal builds:
`.../privacy_context:filters does not depend on a module exporting
'.../src/core/lib/channel/context.h'`
Change call attributes to be stored in a `ChunkedVector` instead of
`std::map<>`, so that the storage can be allocated on the arena. This
means that we're now doing a linear search instead of a map lookup, but
the total number of attributes is expected to be low enough that that
should be okay.
Also, we now hide the actual data structure inside of the
`ServiceConfigCallData` object, which required some changes to the
`ConfigSelector` API. Previously, the `ConfigSelector` would return a
`CallConfig` struct, and the client channel would then use the data in
that struct to populate the `ServiceConfigCallData`. This PR changes
that such that the client channel creates the `ServiceConfigCallData`
before invoking the `ConfigSelector`, and it passes the
`ServiceConfigCallData` into the `ConfigSelector` so that the
`ConfigSelector` can populate it directly.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
As Protobuf is going to support Cord to reduce memory copy when
[de]serializing Cord fields, gRPC is going to leverage it. This
implementation is based on the internal one but it's slightly modified
to use the public APIs of Cord. only
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
This bug occurred when the same xDS server was configured twice in the
same bootstrap config, once in an authority and again as the top-level
server. In that case, we were incorrectly failing to de-dup them and
were creating a separate channel for the LRS stream than the one that
already existed for the ADS stream. We fix this by canonicalizing the
server keys the same way in both cases.
As a separate follow-up item, I will work on trying to find a better way
to key these maps that does not suffer from this kind of fragility.
We shouldn't depend on how much the compression algorithm compresses the
bytes to. This is causing flakiness internally.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
Expand server promises to run with C++ end2end tests.
Across connected_channel/call/batch_builder/pipe/transport:
- fix a bug where read errors weren't propagated from transport to call
so that we can populate failed_before_recv_message for the c++ bindings
- ensure those errors are not, however, used to populate the returned
call status
Add a new latch call arg to lazily propagate the bound CQ for a server
call (and client call, but here it's used degenerately - it's always
populated). This allows server calls to be properly bound to
pollsets.(1)/(2)
In call.cc:
- move some profiling code from FilterStackCall to Call, and then use it
in PromiseBasedCall (this should be cleaned up with tracing work)
- implement GetServerAuthority
In server.cc:
- use an RAII pattern on `MatchResult` to avoid a bug whereby a tag
could be dropped if we cancel a request after it's been matched but
before it's published
- fix deadline export to ServerContext
In resource_quota_server.cc:
- fix some long standing flakes (that were finally obvious with the new
test code) - it's legal here to have client calls not arrive at the
server due to resource starvation, work through that (includes adding
expectations during a `Step` call, which required some small tweaks to
cq_verifier)
In the C++ end2end_test.cc:
- strengthen a flaky test so it passes consistently (it's likely we'll
revisit this with the fuzzing efforts to strengthen it into an actually
robust test)
(1) It's time to remove this concept
(2) Surprisingly the only test that *reliably* demonstrates this not
being done is time_change_test
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This reverts commit 4b46dbc19e.
Reason: this seems to be breaking load reports in certain cases,
b/276944116
Let's revert so this doesn't accidentally get released.
This PR aims to de-experimentalize the APIs for GCP Observability.
We would have ideally wanted public feedback before declaring the APIs
stable, but we need stable APIs for GA.
Changes made after API review with @markdroth@veblush, @ctiller and the
entire Core/C++ team -
* The old experimental APIs `grpc::experimental::GcpObservabilityInit`
and `grpc::experimental::GcpObservabilityClose` are now deprecated and
will be deleted after v.1.55 release.
* The new API gets rid of the Close method and follows the RAII idiom
with a single `grpc::GcpObservability::Init()` call that returns an
`GcpObservability` object, the lifetime of which controls when
observability data is flushed.
* The `GcpObservability` class could in the future add more methods. For
example, a debug method that shows the current configuration.
* Document that GcpObservability initialization and flushing (on
`GcpObservability` destruction) are blocking calls.
* Document that gRPC is still usable if GcpObservability initialization
failed. (Added a test to prove the same).
* Since we don't have a good way to flush stats and tracing with
OpenCensus, the examples required users to sleep for 25 seconds. This
sleep is now part of `GcpObservability` destruction.
Additional Implementation details -
* `GcpObservability::Init` is now marked with `GRPC_MUST_USE_RESULT` to
make sure that the results are used. We ideally want users to store it,
but this is better than nothing.
* Added a note on GCP Observability lifetime guarantees.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
Notes:
- `+trace` fixtures haven't run since 2016, so they're disabled for now
(7ad2d0b463 (diff-780fce7267c34170c1d0ea15cc9f65a7f4b79fefe955d185c44e8b3251cf9e38R76))
- all current fixtures define `FEATURE_MASK_SUPPORTS_AUTHORITY_HEADER`
and hence `authority_not_supported` has not been run in years - deleted
- bad_hostname similarly hasn't been triggered in a long while, so
deleted
- load_reporting_hook has never been enabled, so deleted
(f23fb4cf31/test/core/end2end/generate_tests.bzl (L145-L148))
- filter_latency & filter_status_code rely on global variables and so
don't convert particularly cleanly - and their value seems marginal, so
deleted
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This PR also centralizes the client channel resolver selection. Resolver
selection is still done using the plugin system, but when the Ares and
native client channel resolvers go away, we can consider bootstrapping
this differently.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
Implement listeners, connection, endpoints for `FuzzingEventEngine`.
Allows the fuzzer to select write sizes and delays, connection delays,
and port assignments.
I made a few modifications to the test suite to admit this event engine
to pass the client & server tests:
1. the test factories return shared_ptr<> to admit us to return the same
event engine for both the oracle and the implementation - necessary
because FuzzingEventEngine forms a closed world of addresses & ports.
2. removed the WaitForSingleOwner calls - these seem unnecessary, and we
don't ask our users to do this - tested existing linux tests 1000x
across debug, asan, tsan with this change
Additionally, the event engine overrides the global port picker logic so
that port assignments are made by the fuzzer too.
This PR is a step along a longer journey, and has some outstanding
brethren PR's, and some follow-up work:
* #32603 will convert all the core e2e tests into a more malleable form
* we'll then use #32667 to turn all of these into fuzzers
* finally we'll integrate this into that work and turn all core e2e
tests into fuzzers over timer & callback reorderings and io
size/spacings
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This reverts commit 7bd9267f32.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
(hopefully last try)
Add new channel arg GRPC_ARG_ABSOLUTE_MAX_METADATA_SIZE as hard limit
for metadata. Change GRPC_ARG_MAX_METADATA_SIZE to be a soft limit.
Behavior is as follows:
Hard limit
(1) if hard limit is explicitly set, this will be used.
(2) if hard limit is not explicitly set, maximum of default and soft
limit * 1.25 (if soft limit is set) will be used.
Soft limit
(1) if soft limit is explicitly set, this will be used.
(2) if soft limit is not explicitly set, maximum of default and hard
limit * 0.8 (if hard limit is set) will be used.
Requests between soft and hard limit will be rejected randomly, requests
above hard limit will be rejected.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
Earlier, we were simply using a 64 bit random number, but the spec
actually calls for UUIDv4.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
This PR is a small code change with a lot of new test data.
[In OpenSSL, there are two flags that configure CRL checks. Coping
relevant
section:](https://www.openssl.org/docs/man1.0.2/man3/X509_VERIFY_PARAM_get_depth.html)
> - X509_V_FLAG_CRL_CHECK enables CRL checking for the certificate chain
leaf certificate. An error occurs if a suitable CRL cannot be found.
> - X509_V_FLAG_CRL_CHECK_ALL enables CRL checking for the entire
certificate chain.
We currently only set `X509_V_FLAG_CRL_CHECK`, so we will only ever
check if the leaf certificate is revoked. We should check the whole
chain. I am open to making this a user configuration if we want to do it
that way, but we certainly need to be able to check the whole chain.
So, this PR contains the small code change in
`ssl_transport_security.cc` to use the `X509_V_FLAG_CRL_CHECK_ALL` flag.
Then the rest of the changes are in tests. I've added all the necessary
files to have a chain built that looks as follows
`Root CA -> Revoked Intermediate CA -> Leaf Certificate`, and added a
test for this case as well.
You can verify that on master this new test will fail (i.e. the
handshake will succeed even though the intermediate CA is revoked) by
checking out this branch, running `git checkout master --
./src/core/tsi/ssl_transport_security.cc`, then running the test.
I also slightly reorganized test/core/tsi/test_creds/ so that the CRLs
are in their own directory, which is the way our API intends to accept
CRLs.
Fixing TSAN data races of the kind -
https://source.cloud.google.com/results/invocations/c3f02253-0d0b-44e6-917d-07e4bc0d3d62/targets/%2F%2Ftest%2Fcpp%2Fperformance:writes_per_rpc_test@poller%3Dpoll/log
I think the original issue was the non-atomic load in
writes_per_rpc_test.cc but also making the change to use barriers
instead of relaxed atomics (probably unimportant but I'll prefer safety
in the absence of otherwise comments).
Could probably also use std::atomic but feeling a bit lazy to make the
changes throughout.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
This PR adds the view `grpc.io/client/api_latency` for GCP Observability
which aims to collect the end-to-end time taken by a call.
Changes made to support this -
1) A global interceptor factory registration is created for stats
plugins.
2) OpenCensus plugin now provides a new interceptor that's responsible
for collecting the new latency.
3) Gcp Observability registers this plugin.
4) A new OpenCensus measurement and view is created for api latency.
Note that this is internal as of now, since it's not clear if it should
be exposed as public experimental API. Leaving that decision for the
future.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
This PR adds annotations to client attempt spans and server spans on
messages of the form -
* `Send message: 1026 bytes`
* `Send compressed message: 31 bytes` (if message was compressed)
* `Received message: 31 bytes`
* `Received decompressed message: 1026 bytes` (if message needed to be
decompressed)
Note that the compressed and decompressed annotations are not present if
compression/decompression was not performed.
<!--
If you know who should review your pull request, please assign it to
that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the
appropriate
lang label.
-->
{kind=link}
{kind=link}