[grpc][Gpr_To_Absl_Logging] Migrating from gpr to absl logging GPR_ASSERT
Replacing GPR_ASSERT with absl CHECK
Will not be replacing CHECK with CHECK_EQ , CHECK_NE etc because there are too many callsites. Only a few - which fit into single - line regex will be changed. This would be small in number just to reduce the load later.
Replacing CHECK with CHECK_EQ , CHECK_NE etc could be done using Cider-V once these changes are submitted if we want to clean up later. Given that we have 5000+ instances of GPR_ASSERT to edit, Doing it manually is too much work for both the author and reviewer.
<!--
If you know who should review your pull request, please assign it to that
person, otherwise the pull request would get assigned randomly.
If your pull request is for a specific language, please add the appropriate
lang label.
-->
Closes#36267
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36267 from tanvi-jagtap:tjagtap_grpc_assert_02 3aed626101
PiperOrigin-RevId: 623469007
See #36176. The only difference is a temporary shim for Secure credentials types, which was already discussed and approved separately.
Closes#36242
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36242 from drfloob:reland/36176 f07bebe289
PiperOrigin-RevId: 621879911
Instead, build a library and re-use that across compilations.
This still invokes a link step per target, and we'll want to deal with that at some point too, but at least this makes some progress to not being as wasteful with our compilation resources.
Additionally: remove bm_pollset -- it was having some problems compiling, and we really don't need it anymore.
Closes#36197
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36197 from ctiller:maintain-this-shite 9955026e23
PiperOrigin-RevId: 620946543
also:
- remove tail recursion from promise endpoint read completion (actually overflowed stack!)
- remove retry filter from benchmark - we probably don't want this long term, but for now nobody else is using this benchmark and our use case doesn't use grpc retries so.... good enough
Closes#36050
COPYBARA_INTEGRATE_REVIEW=https://github.com/grpc/grpc/pull/36050 from ctiller:cgbm 65b1c26767
PiperOrigin-RevId: 612577071
In real services most of our time ends up in the `Read1()` function,
which populates one byte into the bit buffer.
Change this to read in as many as possible bytes at a time into that
buffer.
Additionally, generate all possible (to some depth) parser geometries,
and add a benchmark for them. Run that benchmark and select the best
geometry for decoding base64 strings (since this is the main use-case).
(gives about a 30% speed boost parsing base64 then huffman encoded
random binary strings)
---------
Co-authored-by: ctiller <ctiller@users.noreply.github.com>
This PR implements a work-stealing thread pool for use inside
EventEngine implementations. Because of historical risks here, I've
guarded the new implementation behind an experiment flag:
`GRPC_EXPERIMENTS=work_stealing`. Current default behavior is the
original thread pool implementation.
Benchmarks look very promising:
```
bazel test \
--test_timeout=300 \
--config=opt -c opt \
--test_output=streamed \
--test_arg='--benchmark_format=csv' \
--test_arg='--benchmark_min_time=0.15' \
--test_arg='--benchmark_filter=_FanOut' \
--test_arg='--benchmark_repetitions=15' \
--test_arg='--benchmark_report_aggregates_only=true' \
test/cpp/microbenchmarks:bm_thread_pool
```
2023-05-04: `bm_thread_pool` benchmark results on my local machine (64
core ThreadRipper PRO 3995WX, 256GB memory), comparing this PR to
master:
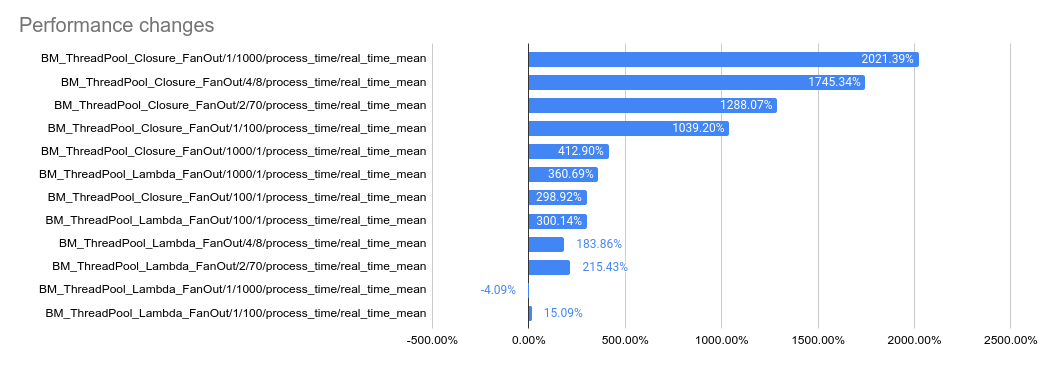
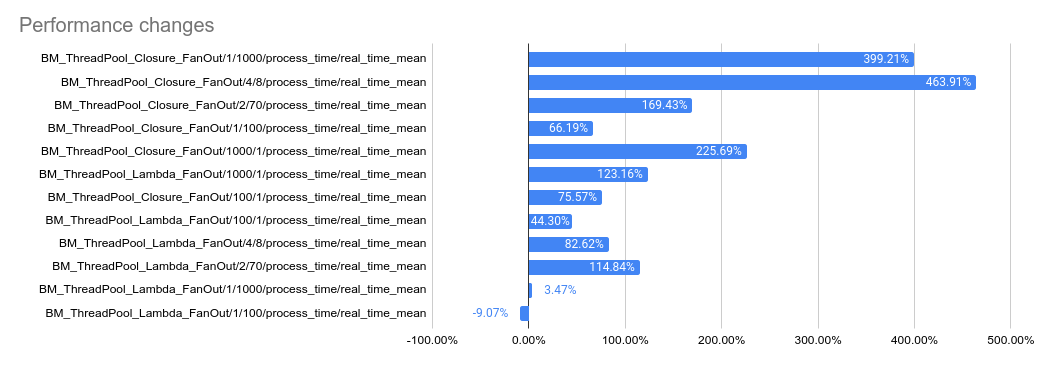
2023-05-04: `bm_thread_pool` benchmark results in the Linux RBE
environment (unsure of machine configuration, likely small), comparing
this PR to master.
---------
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
* ThreadPool benchmarks
These are nearly identical to the EventEngine benchmarks at the moment. We can consider removing the redundant tests from the EventEngine code and focusing on EventEngine-specific things (e.g., timer cancellation)
* rm unused header
* rm leak
* fix: moved dependencies
* [WIP] EventEngine::Run microbenchmarks
* Add fanout impl and fix tracking of time spent doing work in threads
* tune down benchmarks; fix fanout counting logic.
* tune down closure fanout tests
* format
* odr
* reviewer feedback
* unify some fanout logic; add a large-AnyInvocable test
lambdas that take an allocation are about 10x slower
* reviewer feedback
* fix invalid vector access
* rm DNS
* format
* copy params for each lambda callback
This fixes segfaults when we cannot ensure all callbacks are complete
before exiting the test.
* s/promise/Notification/g bm_exec_ctx
* ODR and leak
* fix division by zero
* fix
* WorkQueue
* weaken the large obj stress test for Windows; documentation
* update comment
* Add WorkQueue microbenchmark. Results below ...
------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
------------------------------------------------------------------------------------------
BM_WorkQueueIntptrPopFront/1 297 ns 297 ns 2343500 items_per_second=3.3679M/s
BM_WorkQueueIntptrPopFront/8 7022 ns 7020 ns 99356 items_per_second=1.13956M/s
BM_WorkQueueIntptrPopFront/64 59606 ns 59590 ns 11770 items_per_second=1074k/s
BM_WorkQueueIntptrPopFront/512 477867 ns 477748 ns 1469 items_per_second=1071.7k/s
BM_WorkQueueIntptrPopFront/4096 3815786 ns 3814925 ns 184 items_per_second=1073.68k/s
I0902 19:05:22.138022069 12 test_config.cc:194] TestEnvironment ends
================================================================================
* use int64_t for times. 0 performance change
------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
------------------------------------------------------------------------------------------
BM_WorkQueueIntptrPopFront/1 277 ns 277 ns 2450292 items_per_second=3.60967M/s
BM_WorkQueueIntptrPopFront/8 6718 ns 6716 ns 105497 items_per_second=1.19126M/s
BM_WorkQueueIntptrPopFront/64 56428 ns 56401 ns 12268 items_per_second=1.13474M/s
BM_WorkQueueIntptrPopFront/512 458953 ns 458817 ns 1550 items_per_second=1.11591M/s
BM_WorkQueueIntptrPopFront/4096 3686357 ns 3685120 ns 191 items_per_second=1.1115M/s
I0902 19:25:31.549382949 12 test_config.cc:194] TestEnvironment ends
================================================================================
* add PopBack tests: same performance profile exactly
* use Mutex instead of Spinlock
It's safer, and so far equally performant in benchmarks of opt builds
* add deque test for comparison. It is faster on all tests.
* Add sparsely-populated multi-threaded benchmarks.
* fix
* fix
* refactor to help thread safety analysis
* Specialize WorkQueue for Closure*s and AnyInvocables
* remove unused callback storage
* add single-threaded benchmark for closure vs invocable
* sanitize
* missing include
* move bm_work_queue to microbenchmarks so it isn't exported
* s/workqueue/work_queue/g
* use nullptr instead of optionals for popped closures
* reviewer test suggestion
* private things are private
* add a work_queue fuzzer
Ran for 10 minutes @ 42 jobs @ 42 workers. Zero failures.
Checked in a selection of 100 good seeds after merging the thousands of
results.
* fix
* fix header guards
* nuke the corpora
* feedback
* sanitize
* Timestamp::Now
* fix
* fuzzers do not work on windows
* windows does not like multithreaded benchmark tests
* Refactor end2end tests to exercise each EventEngine
* fix incorrect bazel_only exclusions
* Automated change: Fix sanity tests
* microbenchmark fix
* sanitize, fix iOS flub
* Automated change: Fix sanity tests
* iOS fix
* reviewer feedback
* first pass at excluding EventEngine test expansion
Also caught a few cases where we should not test pollers, but should
test all engines. And two cases where we likely shouldn't be testing
either product.
* end2end fuzzers to be fuzzed differently via EventEngine.
* sanitize
* reviewer feedback
* remove misleading comment
* reviewer feedback: comments
* EE test_init needs to play with our build system
* fix golden file test runner
Co-authored-by: drfloob <drfloob@users.noreply.github.com>
* Fix all lint errors in repo.
* Use strict buildifier by default
* Whoops. That file does not exist
* Attempt fix to buildifier invocation
* Add missing copyright
This replaces gflags. Added TODOs where use of `absl::Duration` or `absl::FlagSaver` might be preferred in follow-up cleanup. Fixes#24493.
This reverts commit da66b7d14e.
NEW:
* Adds references to `absl/flags/declare.h`, new to LTS 2020923.2 imported in commit 5b43440.
* Works around MSVC 2017 compiler error with large help text on flags by reducing the help text.
{kind=link}
{kind=link}