mirror of https://github.com/grpc/grpc.git
[protobuf] Add third_party/utf8_range as a subtree (#32794)
This is a prerequisite for upgrading to protobuf 22.x (upb and protobuf now depend on utf8_range) Currently utf8_range isn't referenced by anything, but it's better to bring the subtree in advance to make the protobuf upgrade PR smaller.pull/32801/head
parent
4e2f92bf9c
commit
6f81b87122
41 changed files with 4800 additions and 0 deletions
@ -0,0 +1,11 @@ |
||||
build --cxxopt=-std=c++14 --host_cxxopt=-std=c++14 |
||||
|
||||
build:asan --copt=-fsanitize=address --linkopt=-fsanitize=address |
||||
build:msan --copt=-fsanitize=memory --linkopt=-fsanitize=memory |
||||
build:tsan --copt=-fsanitize=thread --linkopt=-fsanitize=thread |
||||
build:ubsan --copt=-fsanitize=undefined --linkopt=-fsanitize=undefined --action_env=UBSAN_OPTIONS=halt_on_error=1:print_stacktrace=1 |
||||
# Workaround for the fact that Bazel links with $CC, not $CXX |
||||
# https://github.com/bazelbuild/bazel/issues/11122#issuecomment-613746748 |
||||
build:ubsan --copt=-fno-sanitize=function --copt=-fno-sanitize=vptr |
||||
# Workaround for https://bugs.llvm.org/show_bug.cgi?id=16404 |
||||
build:ubsan --linkopt=--rtlib=compiler-rt --linkopt=-lunwind |
||||
@ -0,0 +1,36 @@ |
||||
name: Bazel Tests |
||||
|
||||
on: |
||||
push: |
||||
branches: |
||||
- main |
||||
pull_request: |
||||
branches: |
||||
- main |
||||
workflow_dispatch: |
||||
|
||||
jobs: |
||||
|
||||
ubuntu: |
||||
runs-on: ${{ matrix.os }} |
||||
|
||||
strategy: |
||||
fail-fast: false # Don't cancel all jobs if one fails. |
||||
matrix: |
||||
include: |
||||
- { NAME: "Debug", CC: clang, os: ubuntu-20.04, flags: "-c dbg" } |
||||
- { NAME: "Optmized", CC: clang, os: ubuntu-20.04, flags: "-c opt" } |
||||
- { NAME: "GCC Optimized", CC: gcc, os: ubuntu-20.04, flags: "-c opt" } |
||||
- { NAME: "ASAN", CC: clang, os: ubuntu-20.04, flags: "--config=asan -c dbg" } |
||||
- { NAME: "UBSAN", CC: clang, os: ubuntu-20.04, flags: "--config=ubsan -c dbg", install: "libunwind-dev" } |
||||
- { NAME: "macOS", CC: clang, os: macos-11, flags: "" } |
||||
|
||||
name: Bazel ${{ matrix.NAME }} |
||||
|
||||
steps: |
||||
- uses: actions/checkout@v2 |
||||
- name: Install dependencies |
||||
run: sudo apt update && sudo apt install -y ${{ matrix.install }} |
||||
if: matrix.install != '' |
||||
- name: Run tests |
||||
run: cd ${{ github.workspace }} && CC=${{ matrix.CC }} bazel test --test_output=errors ... ${{ matrix.flags }} |
||||
@ -0,0 +1,61 @@ |
||||
name: CMake Tests |
||||
|
||||
on: |
||||
push: |
||||
branches: |
||||
- main |
||||
pull_request: |
||||
branches: |
||||
- main |
||||
workflow_dispatch: |
||||
|
||||
env: |
||||
GOOGLETEST_PINNED_COMMIT: 4c9a3bb62bf3ba1f1010bf96f9c8ed767b363774 |
||||
ABSEIL_PINNED_COMMIT: 273292d1cfc0a94a65082ee350509af1d113344d |
||||
INSTALL_DIR: /tmp/install |
||||
|
||||
jobs: |
||||
install: |
||||
name: CMake |
||||
runs-on: ubuntu-20.04 |
||||
steps: |
||||
- uses: actions/checkout@v2 |
||||
- name: Install Googletest |
||||
run: | |
||||
git clone --no-checkout https://github.com/google/googletest |
||||
git -C googletest reset --hard $GOOGLETEST_PINNED_COMMIT |
||||
cd googletest && cmake . -DCMAKE_INSTALL_PREFIX=$INSTALL_DIR && make install -j20 |
||||
- name: Install Abseil |
||||
run: | |
||||
git clone --no-checkout https://github.com/abseil/abseil-cpp |
||||
git -C abseil-cpp reset --hard $ABSEIL_PINNED_COMMIT |
||||
cd abseil-cpp && cmake . -DCMAKE_INSTALL_PREFIX=$INSTALL_DIR && make install -j20 |
||||
- name: Configure |
||||
run: cd ${{ github.workspace }} && cmake . -DCMAKE_INSTALL_PREFIX=$INSTALL_DIR |
||||
- name: Build |
||||
run: cd ${{ github.workspace }} && cmake --build . -j20 |
||||
- name: Test |
||||
run: cd ${{ github.workspace }} && ctest |
||||
|
||||
test: |
||||
name: Cmake Install |
||||
runs-on: ubuntu-20.04 |
||||
steps: |
||||
- uses: actions/checkout@v2 |
||||
- name: Install Googletest |
||||
run: | |
||||
git clone --no-checkout https://github.com/google/googletest |
||||
git -C googletest reset --hard $GOOGLETEST_PINNED_COMMIT |
||||
cd googletest && cmake . -DCMAKE_INSTALL_PREFIX=$INSTALL_DIR && make install -j20 |
||||
- name: Download Abseil |
||||
run: | |
||||
git clone --no-checkout https://github.com/abseil/abseil-cpp /tmp/abseil-cpp |
||||
git -C /tmp/abseil-cpp reset --hard $ABSEIL_PINNED_COMMIT |
||||
- name: Configure |
||||
run: cd ${{ github.workspace }} && cmake . -DABSL_ROOT_DIR=/tmp/abseil-cpp -DCMAKE_INSTALL_PREFIX=$INSTALL_DIR |
||||
- name: Build |
||||
run: cd ${{ github.workspace }} && cmake --build . -j20 |
||||
- name: Install |
||||
run: cd ${{ github.workspace }} && make install |
||||
- name: Test |
||||
run: cd ${{ github.workspace }} && ctest |
||||
@ -0,0 +1,2 @@ |
||||
# Ignore the bazel symlinks |
||||
/bazel-* |
||||
@ -0,0 +1,55 @@ |
||||
# Copyright 2022 Google LLC |
||||
# |
||||
# Use of this source code is governed by an MIT-style |
||||
# license that can be found in the LICENSE file or at |
||||
# https://opensource.org/licenses/MIT. |
||||
|
||||
package(default_visibility = ["//visibility:public"]) |
||||
|
||||
licenses(["notice"]) |
||||
|
||||
exports_files(["LICENSE"]) |
||||
|
||||
# TODO(b/252876197) Remove this once callers have been Bazelified. |
||||
filegroup( |
||||
name = "utf8_range_srcs", |
||||
srcs = [ |
||||
"naive.c", |
||||
"range2-neon.c", |
||||
"range2-sse.c", |
||||
"utf8_range.h", |
||||
], |
||||
visibility = [ |
||||
"@com_google_protobuf//:__subpackages__", |
||||
"@upb//:__subpackages__", |
||||
], |
||||
) |
||||
|
||||
cc_library( |
||||
name = "utf8_range", |
||||
srcs = [ |
||||
"naive.c", |
||||
"range2-neon.c", |
||||
"range2-sse.c", |
||||
], |
||||
hdrs = ["utf8_range.h"], |
||||
) |
||||
|
||||
cc_library( |
||||
name = "utf8_validity", |
||||
srcs = ["utf8_validity.cc"], |
||||
hdrs = ["utf8_validity.h"], |
||||
deps = [ |
||||
"@com_google_absl//absl/strings", |
||||
], |
||||
) |
||||
|
||||
cc_test( |
||||
name = "utf8_validity_test", |
||||
srcs = ["utf8_validity_test.cc"], |
||||
deps = [ |
||||
":utf8_validity", |
||||
"@com_google_absl//absl/strings", |
||||
"@com_google_googletest//:gtest_main", |
||||
], |
||||
) |
||||
@ -0,0 +1,81 @@ |
||||
cmake_minimum_required (VERSION 3.5) |
||||
project (utf8_range C CXX) |
||||
|
||||
# option() honor variables |
||||
if (POLICY CMP0077) |
||||
cmake_policy(SET CMP0077 NEW) |
||||
endif (POLICY CMP0077) |
||||
|
||||
option (utf8_range_ENABLE_TESTS "Build test suite" ON) |
||||
option (utf8_range_ENABLE_INSTALL "Configure installation" ON) |
||||
|
||||
## |
||||
# Create the lightweight C library |
||||
add_library (utf8_range STATIC |
||||
naive.c |
||||
range2-neon.c |
||||
range2-sse.c |
||||
) |
||||
|
||||
## |
||||
# A heavier-weight C++ wrapper that supports Abseil. |
||||
add_library (utf8_validity STATIC utf8_validity.cc) |
||||
|
||||
# Load Abseil dependency. |
||||
if (NOT TARGET absl::strings) |
||||
if (NOT ABSL_ROOT_DIR) |
||||
find_package(absl REQUIRED CONFIG) |
||||
else () |
||||
set(ABSL_ENABLE_INSTALL ${utf8_range_ENABLE_INSTALL}) |
||||
set(ABSL_PROPAGATE_CXX_STD ON) |
||||
add_subdirectory(${ABSL_ROOT_DIR} third_party/abseil-cpp) |
||||
endif () |
||||
endif () |
||||
target_link_libraries(utf8_validity PUBLIC absl::strings) |
||||
|
||||
# Configure tests. |
||||
if (utf8_range_ENABLE_TESTS) |
||||
enable_testing() |
||||
|
||||
find_package(GTest REQUIRED) |
||||
|
||||
add_executable(tests utf8_validity_test.cc) |
||||
target_link_libraries(tests utf8_validity GTest::gmock_main) |
||||
|
||||
add_test(NAME utf8_validity_test COMMAND tests) |
||||
|
||||
add_custom_target(check |
||||
COMMAND tests |
||||
DEPENDS tests |
||||
) |
||||
endif () |
||||
|
||||
# Configure installation. |
||||
if (utf8_range_ENABLE_INSTALL) |
||||
include(CMakePackageConfigHelpers) |
||||
include(GNUInstallDirs) |
||||
|
||||
install(EXPORT ${PROJECT_NAME}-targets |
||||
DESTINATION "${CMAKE_INSTALL_LIBDIR}/cmake/${PROJECT_NAME}" |
||||
NAMESPACE utf8_range:: |
||||
) |
||||
install(TARGETS utf8_validity utf8_range EXPORT ${PROJECT_NAME}-targets |
||||
RUNTIME DESTINATION ${CMAKE_INSTALL_BINDIR} |
||||
LIBRARY DESTINATION ${CMAKE_INSTALL_LIBDIR} |
||||
ARCHIVE DESTINATION ${CMAKE_INSTALL_LIBDIR} |
||||
) |
||||
|
||||
configure_package_config_file( |
||||
cmake/${PROJECT_NAME}-config.cmake.in |
||||
"${CMAKE_CURRENT_BINARY_DIR}/${PROJECT_NAME}-config.cmake" |
||||
INSTALL_DESTINATION "${CMAKE_INSTALL_LIBDIR}/cmake/${PROJECT_NAME}" |
||||
) |
||||
install(FILES "${PROJECT_BINARY_DIR}/${PROJECT_NAME}-config.cmake" |
||||
DESTINATION "${CMAKE_INSTALL_LIBDIR}/cmake/${PROJECT_NAME}" |
||||
) |
||||
|
||||
# Install public headers explicitly. |
||||
install(FILES utf8_range.h utf8_validity.h |
||||
DESTINATION ${CMAKE_INSTALL_INCLUDEDIR} |
||||
) |
||||
endif () |
||||
@ -0,0 +1,31 @@ |
||||
# How to Contribute |
||||
|
||||
This repository is currently a read-only clone of internal Google code for use |
||||
in open-source projects. We don't currently have a mechanism to upstream |
||||
changes, but if you'd like to contribute, please reach out to us to discuss your |
||||
proposed changes. |
||||
|
||||
## Contributor License Agreement |
||||
|
||||
Contributions to this project must be accompanied by a Contributor License |
||||
Agreement (CLA). You (or your employer) retain the copyright to your |
||||
contribution; this simply gives us permission to use and redistribute your |
||||
contributions as part of the project. Head over to |
||||
<https://cla.developers.google.com/> to see your current agreements on file or |
||||
to sign a new one. |
||||
|
||||
You generally only need to submit a CLA once, so if you've already submitted one |
||||
(even if it was for a different project), you probably don't need to do it |
||||
again. |
||||
|
||||
## Code Reviews |
||||
|
||||
All submissions, including submissions by project members, require review. We |
||||
use GitHub pull requests for this purpose. Consult |
||||
[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more |
||||
information on using pull requests. |
||||
|
||||
## Community Guidelines |
||||
|
||||
This project follows |
||||
[Google's Open Source Community Guidelines](https://opensource.google/conduct/). |
||||
@ -0,0 +1,22 @@ |
||||
MIT License |
||||
|
||||
Copyright (c) 2019 Yibo Cai |
||||
Copyright 2022 Google LLC |
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy |
||||
of this software and associated documentation files (the "Software"), to deal |
||||
in the Software without restriction, including without limitation the rights |
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell |
||||
copies of the Software, and to permit persons to whom the Software is |
||||
furnished to do so, subject to the following conditions: |
||||
|
||||
The above copyright notice and this permission notice shall be included in all |
||||
copies or substantial portions of the Software. |
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR |
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, |
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE |
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER |
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, |
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE |
||||
SOFTWARE. |
||||
@ -0,0 +1,264 @@ |
||||
[](https://travis-ci.com/cyb70289/utf8) |
||||
|
||||
# Fast UTF-8 validation with Range algorithm (NEON+SSE4+AVX2) |
||||
|
||||
This is a brand new algorithm to leverage SIMD for fast UTF-8 string validation. Both **NEON**(armv8a) and **SSE4** versions are implemented. **AVX2** implementation contributed by [ioioioio](https://github.com/ioioioio). |
||||
|
||||
Four UTF-8 validation methods are compared on both x86 and Arm platforms. Benchmark result shows range base algorithm is the best solution on Arm, and achieves same performance as [Lemire's approach](https://lemire.me/blog/2018/05/16/validating-utf-8-strings-using-as-little-as-0-7-cycles-per-byte/) on x86. |
||||
|
||||
* Range based algorithm |
||||
* range-neon.c: NEON version |
||||
* range-sse.c: SSE4 version |
||||
* range-avx2.c: AVX2 version |
||||
* range2-neon.c, range2-sse.c: Process two blocks in one iteration |
||||
* [Lemire's SIMD implementation](https://github.com/lemire/fastvalidate-utf-8) |
||||
* lemire-sse.c: SSE4 version |
||||
* lemire-avx2.c: AVX2 version |
||||
* lemire-neon.c: NEON porting |
||||
* naive.c: Naive UTF-8 validation byte by byte |
||||
* lookup.c: [Lookup-table method](http://bjoern.hoehrmann.de/utf-8/decoder/dfa/) |
||||
|
||||
## About the code |
||||
|
||||
* Run "make" to build. Built and tested with gcc-7.3. |
||||
* Run "./utf8" to see all command line options. |
||||
* Benchmark |
||||
* Run "./utf8 bench" to bechmark all algorithms with [default test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt). |
||||
* Run "./utf8 bench size NUM" to benchmark specified string size. |
||||
* Run "./utf8 test" to test all algorithms with positive and negative test cases. |
||||
* To benchmark or test specific algorithm, run something like "./utf8 bench range". |
||||
|
||||
## Benchmark result (MB/s) |
||||
|
||||
### Method |
||||
1. Generate UTF-8 test buffer per [test file](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) or buffer size. |
||||
1. Call validation sub-routines in a loop until 1G bytes are checked. |
||||
1. Calculate speed(MB/s) of validating UTF-8 strings. |
||||
|
||||
### NEON(armv8a) |
||||
Test case | naive | lookup | lemire | range | range2 |
||||
:-------- | :---- | :----- | :----- | :---- | :----- |
||||
[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 562.25 | 412.84 | 1198.50 | 1411.72 | **1579.85** |
||||
32 bytes | 651.55 | 441.70 | 891.38 | 1003.95 | **1043.58** |
||||
33 bytes | 660.00 | 446.78 | 588.77 | 1009.31 | **1048.12** |
||||
129 bytes | 771.89 | 402.55 | 938.07 | 1283.77 | **1401.76** |
||||
1K bytes | 811.92 | 411.58 | 1188.96 | 1398.15 | **1560.23** |
||||
8K bytes | 812.25 | 412.74 | 1198.90 | 1412.18 | **1580.65** |
||||
64K bytes | 817.35 | 412.24 | 1200.20 | 1415.11 | **1583.86** |
||||
1M bytes | 815.70 | 411.93 | 1200.93 | 1415.65 | **1585.40** |
||||
|
||||
### SSE4(E5-2650) |
||||
Test case | naive | lookup | lemire | range | range2 |
||||
:-------- | :---- | :----- | :----- | :---- | :----- |
||||
[UTF-demo.txt](https://raw.githubusercontent.com/cyb70289/utf8/master/UTF-8-demo.txt) | 753.70 | 310.41 | 3954.74 | 3945.60 | **3986.13** |
||||
32 bytes | 1135.76 | 364.07 | **2890.52** | 2351.81 | 2173.02 |
||||
33 bytes | 1161.85 | 376.29 | 1352.95 | **2239.55** | 2041.43 |
||||
129 bytes | 1161.22 | 322.47 | 2742.49 | **3315.33** | 3249.35 |
||||
1K bytes | 1310.95 | 310.72 | 3755.88 | 3781.23 | **3874.17** |
||||
8K bytes | 1348.32 | 307.93 | 3860.71 | 3922.81 | **3968.93** |
||||
64K bytes | 1301.34 | 308.39 | 3935.15 | 3973.50 | **3983.44** |
||||
1M bytes | 1279.78 | 309.06 | 3923.51 | 3953.00 | **3960.49** |
||||
|
||||
## Range algorithm analysis |
||||
|
||||
Basic idea: |
||||
* Load 16 bytes |
||||
* Leverage SIMD to calculate value range for each byte efficiently |
||||
* Validate 16 bytes at once |
||||
|
||||
### UTF-8 coding format |
||||
|
||||
http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf, page 94 |
||||
|
||||
Table 3-7. Well-Formed UTF-8 Byte Sequences |
||||
|
||||
Code Points | First Byte | Second Byte | Third Byte | Fourth Byte | |
||||
:---------- | :--------- | :---------- | :--------- | :---------- | |
||||
U+0000..U+007F | 00..7F | | | | |
||||
U+0080..U+07FF | C2..DF | 80..BF | | | |
||||
U+0800..U+0FFF | E0 | ***A0***..BF| 80..BF | | |
||||
U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | | |
||||
U+D000..U+D7FF | ED | 80..***9F***| 80..BF | | |
||||
U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | | |
||||
U+10000..U+3FFFF | F0 | ***90***..BF| 80..BF | 80..BF | |
||||
U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF | |
||||
U+100000..U+10FFFF | F4 | 80..***8F***| 80..BF | 80..BF | |
||||
|
||||
To summarise UTF-8 encoding: |
||||
* Depending on First Byte, one legal character can be 1, 2, 3, 4 bytes |
||||
* For First Byte within C0..DF, character length = 2 |
||||
* For First Byte within E0..EF, character length = 3 |
||||
* For First Byte within F0..F4, character length = 4 |
||||
* C0, C1, F5..FF are not allowed |
||||
* Second,Third,Fourth Bytes must lie in 80..BF. |
||||
* There are four **special cases** for Second Byte, shown ***bold italic*** in above table. |
||||
|
||||
### Range table |
||||
|
||||
Range table maps range index 0 ~ 15 to minimal and maximum values allowed. Our task is to observe input string, find the pattern and set correct range index for each byte, then validate input string. |
||||
|
||||
Index | Min | Max | Byte type |
||||
:---- | :-- | :-- | :-------- |
||||
0 | 00 | 7F | First Byte, ASCII |
||||
1,2,3 | 80 | BF | Second, Third, Fourth Bytes |
||||
4 | A0 | BF | Second Byte after E0 |
||||
5 | 80 | 9F | Second Byte after ED |
||||
6 | 90 | BF | Second Byte after F0 |
||||
7 | 80 | 8F | Second Byte after F4 |
||||
8 | C2 | F4 | First Byte, non-ASCII |
||||
9..15(NEON) | FF | 00 | Illegal: unsigned char >= 255 && unsigned char <= 0 |
||||
9..15(SSE) | 7F | 80 | Illegal: signed char >= 127 && signed char <= -128 |
||||
|
||||
### Calculate byte ranges (ignore special cases) |
||||
|
||||
Ignoring the four special cases(E0,ED,F0,F4), how should we set range index for each byte? |
||||
|
||||
* Set range index to 0(00..7F) for all bytes by default |
||||
* Find non-ASCII First Byte (C0..FF), set their range index to 8(C2..F4) |
||||
* For First Byte within C0..DF, set next byte's range index to 1(80..BF) |
||||
* For First Byte within E0..EF, set next two byte's range index to 2,1(80..BF) in sequence |
||||
* For First Byte within F0..FF, set next three byte's range index to 3,2,1(80..BF) in sequence |
||||
|
||||
To implement above operations efficiently with SIMD: |
||||
* For 16 input bytes, use lookup table to map C0..DF to 1, E0..EF to 2, F0..FF to 3, others to 0. Save to first_len. |
||||
* Map C0..FF to 8, we get range indices for First Byte. |
||||
* Shift first_len one byte, we get range indices for Second Byte. |
||||
* Saturate substract first_len by one(3->2, 2->1, 1->0, 0->0), then shift two bytes, we get range indices for Third Byte. |
||||
* Saturate substract first_len by two(3->1, 2->0, 1->0, 0->0), then shift three bytes, we get range indices for Fourth Byte. |
||||
|
||||
Example(assume no previous data) |
||||
|
||||
Input | F1 | 80 | 80 | 80 | 80 | C2 | 80 | 80 | ... |
||||
:---- | :- | :- | :- | :- | :- | :- | :- | :- | :-- |
||||
*first_len* |*3* |*0* |*0* |*0* |*0* |*1* |*0* |*0* |*...* |
||||
First Byte | 8 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | ... |
||||
Second Byte | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 0 | ... |
||||
Third Byte | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | ... |
||||
Fourth Byte | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | ... |
||||
Range index | 8 | 3 | 2 | 1 | 0 | 8 | 1 | 0 | ... |
||||
|
||||
```c |
||||
Range_index = First_Byte | Second_Byte | Third_Byte | Fourth_Byte |
||||
``` |
||||
|
||||
#### Error handling |
||||
|
||||
* C0,C1,F5..FF are not included in range table and will always be detected. |
||||
* Illegal 80..BF will have range index 0(00..7F) and be detected. |
||||
* Based on First Byte, according Second, Third and Fourth Bytes will have range index 1/2/3, to make sure they must lie in 80..BF. |
||||
* If non-ASCII First Byte overlaps, above algorithm will set range index of the latter First Byte to 9,10,11, which are illegal ranges. E.g, Input = F1 80 C2 90 --> Range index = 8 3 10 1, where 10 indicates error. See table below. |
||||
|
||||
Overlapped non-ASCII First Byte |
||||
|
||||
Input | F1 | 80 | C2 | 90 |
||||
:---- | :- | :- | :- | :- |
||||
*first_len* |*3* |*0* |*1* |*0* |
||||
First Byte | 8 | 0 | 8 | 0 |
||||
Second Byte | 0 | 3 | 0 | 1 |
||||
Third Byte | 0 | 0 | 2 | 0 |
||||
Fourth Byte | 0 | 0 | 0 | 1 |
||||
Range index | 8 | 3 |***10***| 1 |
||||
|
||||
### Adjust Second Byte range for special cases |
||||
|
||||
Range index adjustment for four special cases |
||||
|
||||
First Byte | Second Byte | Before adjustment | Correct index | Adjustment | |
||||
:--------- | :---------- | :---------------- | :------------ | :--------- |
||||
E0 | A0..BF | 2 | 4 | **2** |
||||
ED | 80..9F | 2 | 5 | **3** |
||||
F0 | 90..BF | 3 | 6 | **3** |
||||
F4 | 80..8F | 3 | 7 | **4** |
||||
|
||||
Range index adjustment can be reduced to below problem: |
||||
|
||||
***Given 16 bytes, replace E0 with 2, ED with 3, F0 with 3, F4 with 4, others with 0.*** |
||||
|
||||
A naive SIMD approach: |
||||
1. Compare 16 bytes with E0, get the mask for eacy byte (FF if equal, 00 otherwise) |
||||
1. And the mask with 2 to get adjustment for E0 |
||||
1. Repeat step 1,2 for ED,F0,F4 |
||||
|
||||
At least **eight** operations are required for naive approach. |
||||
|
||||
Observing special bytes(E0,ED,F0,F4) are close to each other, we can do much better using lookup table. |
||||
|
||||
#### NEON |
||||
|
||||
NEON ```tbl``` instruction is very convenient for table lookup: |
||||
* Table can be up to 16x4 bytes in size |
||||
* Return zero if index is out of range |
||||
|
||||
Leverage these features, we can solve the problem with as few as **two** operations: |
||||
* Precreate a 16x2 lookup table, where table[0]=2, table[13]=3, table[16]=3, table[20]=4, table[others]=0. |
||||
* Substract input bytes with E0 (E0 -> 0, ED -> 13, F0 -> 16, F4 -> 20). |
||||
* Use the substracted byte as index of lookup table and get range adjustment directly. |
||||
* For indices less than 32, we get zero or required adjustment value per input byte |
||||
* For out of bound indices, we get zero per ```tbl``` behaviour |
||||
|
||||
#### SSE |
||||
|
||||
SSE ```pshufb``` instruction is not as friendly as NEON ```tbl``` in this case: |
||||
* Table can only be 16 bytes in size |
||||
* Out of bound indices are handled this way: |
||||
* If 7-th bit of index is 0, least four bits are used as index (E.g, index 0x73 returns 3rd element) |
||||
* If 7-th bit of index is 1, return 0 (E.g, index 0x83 returns 0) |
||||
|
||||
We can still leverage these features to solve the problem in **five** operations: |
||||
* Precreate two tables: |
||||
* table_df[1] = 2, table_df[14] = 3, table_df[others] = 0 |
||||
* table_ef[1] = 3, table_ef[5] = 4, table_ef[others] = 0 |
||||
* Substract input bytes with EF (E0 -> 241, ED -> 254, F0 -> 1, F4 -> 5) to get the temporary indices |
||||
* Get range index for E0,ED |
||||
* Saturate substract temporary indices with 240 (E0 -> 1, ED -> 14, all values below 240 becomes 0) |
||||
* Use substracted indices to look up table_df, get the correct adjustment |
||||
* Get range index for F0,F4 |
||||
* Saturate add temporary indices with 112(0x70) (F0 -> 0x71, F4 -> 0x75, all values above 16 will be larger than 128(7-th bit set)) |
||||
* Use added indices to look up table_ef, get the correct adjustment (index 0x71,0x75 returns 1st,5th elements, per ```pshufb``` behaviour) |
||||
|
||||
#### Error handling |
||||
|
||||
* For overlapped non-ASCII First Byte, range index before adjustment is 9,10,11. After adjustment (adds 2,3,4 or 0), the range index will be 9 to 15, which is still illegal in range table. So the error will be detected. |
||||
|
||||
### Handling remaining bytes |
||||
|
||||
For remaining input less than 16 bytes, we will fallback to naive byte by byte approach to validate them, which is actually faster than SIMD processing. |
||||
* Look back last 16 bytes buffer to find First Byte. At most three bytes need to look back. Otherwise we either happen to be at character boundray, or there are some errors we already detected. |
||||
* Validate string byte by byte starting from the First Byte. |
||||
|
||||
## Tests |
||||
|
||||
It's necessary to design test cases to cover corner cases as more as possible. |
||||
|
||||
### Positive cases |
||||
|
||||
1. Prepare correct characters |
||||
2. Validate correct characters |
||||
3. Validate long strings |
||||
* Round concatenate characters starting from first character to 1024 bytes |
||||
* Validate 1024 bytes string |
||||
* Shift 1 byte, validate 1025 bytes string |
||||
* Shift 2 bytes, Validate 1026 bytes string |
||||
* ... |
||||
* Shift 16 bytes, validate 1040 bytes string |
||||
4. Repeat step3, test buffer starting from second character |
||||
5. Repeat step3, test buffer starting from third character |
||||
6. ... |
||||
|
||||
### Negative cases |
||||
|
||||
1. Prepare bad characters and bad strings |
||||
* Bad character |
||||
* Bad character cross 16 bytes boundary |
||||
* Bad character cross last 16 bytes and remaining bytes boundary |
||||
2. Test long strings |
||||
* Prepare correct long strings same as positive cases |
||||
* Append bad characters |
||||
* Shift one byte for each iteration |
||||
* Validate each shift |
||||
|
||||
## Code breakdown |
||||
|
||||
Below table shows how 16 bytes input are processed step by step. See [range-neon.c](range-neon.c) for according code. |
||||
|
||||
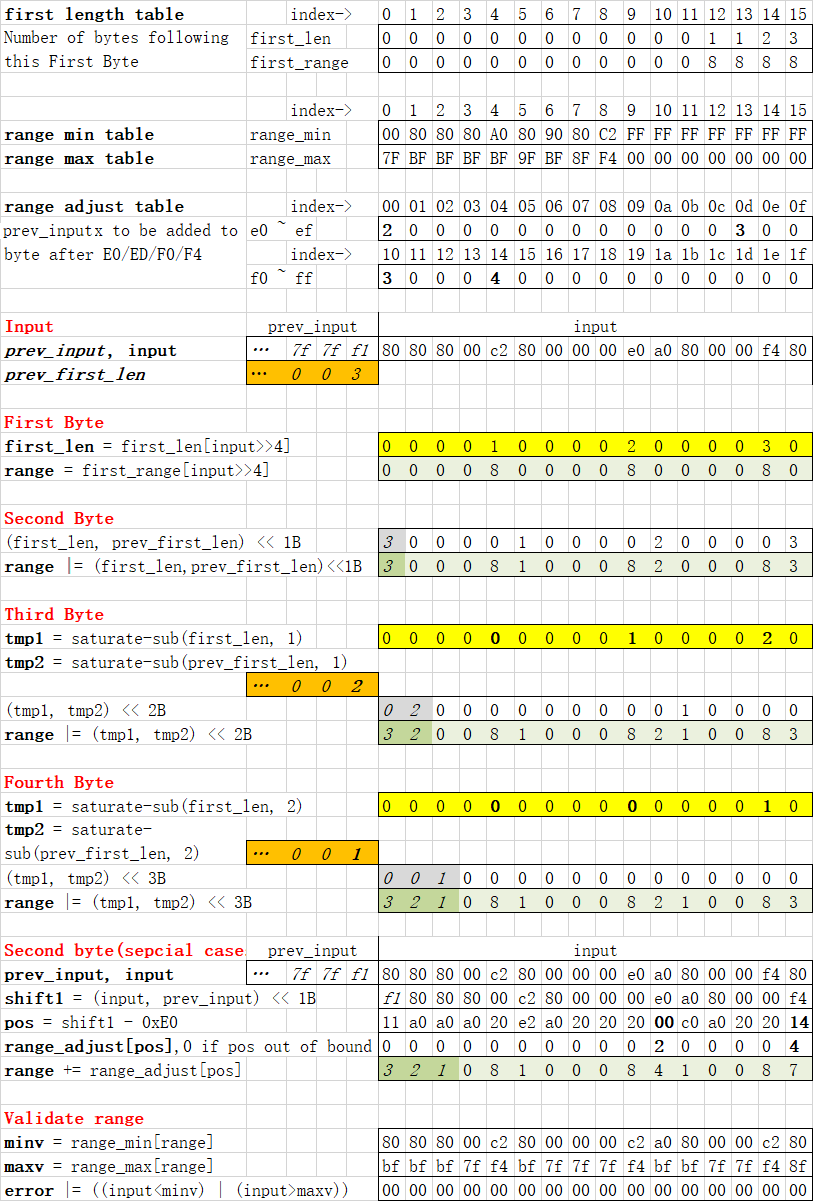 |
||||
@ -0,0 +1,31 @@ |
||||
workspace(name = "utf8_range") |
||||
|
||||
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive") |
||||
load("//:workspace_deps.bzl", "utf8_range_deps") |
||||
|
||||
utf8_range_deps() |
||||
|
||||
http_archive( |
||||
name = "com_google_googletest", |
||||
sha256 = "81964fe578e9bd7c94dfdb09c8e4d6e6759e19967e397dbea48d1c10e45d0df2", |
||||
strip_prefix = "googletest-release-1.12.1", |
||||
urls = [ |
||||
"https://mirror.bazel.build/github.com/google/googletest/archive/refs/tags/release-1.12.1.tar.gz", |
||||
"https://github.com/google/googletest/archive/refs/tags/release-1.12.1.tar.gz", |
||||
], |
||||
) |
||||
|
||||
http_archive( |
||||
name = "rules_fuzzing", |
||||
sha256 = "d9002dd3cd6437017f08593124fdd1b13b3473c7b929ceb0e60d317cb9346118", |
||||
strip_prefix = "rules_fuzzing-0.3.2", |
||||
urls = ["https://github.com/bazelbuild/rules_fuzzing/archive/v0.3.2.zip"], |
||||
) |
||||
|
||||
load("@rules_fuzzing//fuzzing:repositories.bzl", "rules_fuzzing_dependencies") |
||||
|
||||
rules_fuzzing_dependencies() |
||||
|
||||
load("@rules_fuzzing//fuzzing:init.bzl", "rules_fuzzing_init") |
||||
|
||||
rules_fuzzing_init() |
||||
@ -0,0 +1,222 @@ |
||||
#include <sys/time.h> |
||||
|
||||
#include <algorithm> |
||||
#include <cassert> |
||||
#include <cstdint> |
||||
#include <cstdio> |
||||
#include <cstring> |
||||
#include <vector> |
||||
|
||||
static inline int ascii_std(const uint8_t *data, int len) { |
||||
return !std::any_of(data, data + len, [](int8_t b) { return b < 0; }); |
||||
} |
||||
|
||||
static inline int ascii_u64(const uint8_t *data, int len) { |
||||
uint8_t orall = 0; |
||||
|
||||
if (len >= 16) { |
||||
uint64_t or1 = 0, or2 = 0; |
||||
const uint8_t *data2 = data + 8; |
||||
|
||||
do { |
||||
or1 |= *(const uint64_t *)data; |
||||
or2 |= *(const uint64_t *)data2; |
||||
data += 16; |
||||
data2 += 16; |
||||
len -= 16; |
||||
} while (len >= 16); |
||||
|
||||
/*
|
||||
* Idea from Benny Halevy <bhalevy@scylladb.com> |
||||
* - 7-th bit set ==> orall = !(non-zero) - 1 = 0 - 1 = 0xFF |
||||
* - 7-th bit clear ==> orall = !0 - 1 = 1 - 1 = 0x00 |
||||
*/ |
||||
orall = !((or1 | or2) & 0x8080808080808080ULL) - 1; |
||||
} |
||||
|
||||
while (len--) orall |= *data++; |
||||
|
||||
return orall < 0x80; |
||||
} |
||||
|
||||
#if defined(__x86_64__) |
||||
#include <x86intrin.h> |
||||
|
||||
static inline int ascii_simd(const uint8_t *data, int len) { |
||||
if (len >= 32) { |
||||
const uint8_t *data2 = data + 16; |
||||
|
||||
__m128i or1 = _mm_set1_epi8(0), or2 = or1; |
||||
|
||||
while (len >= 32) { |
||||
__m128i input1 = _mm_loadu_si128((const __m128i *)data); |
||||
__m128i input2 = _mm_loadu_si128((const __m128i *)data2); |
||||
|
||||
or1 = _mm_or_si128(or1, input1); |
||||
or2 = _mm_or_si128(or2, input2); |
||||
|
||||
data += 32; |
||||
data2 += 32; |
||||
len -= 32; |
||||
} |
||||
|
||||
or1 = _mm_or_si128(or1, or2); |
||||
if (_mm_movemask_epi8(_mm_cmplt_epi8(or1, _mm_set1_epi8(0)))) return 0; |
||||
} |
||||
|
||||
return ascii_u64(data, len); |
||||
} |
||||
|
||||
#elif defined(__aarch64__) |
||||
#include <arm_neon.h> |
||||
|
||||
static inline int ascii_simd(const uint8_t *data, int len) { |
||||
if (len >= 32) { |
||||
const uint8_t *data2 = data + 16; |
||||
|
||||
uint8x16_t or1 = vdupq_n_u8(0), or2 = or1; |
||||
|
||||
while (len >= 32) { |
||||
const uint8x16_t input1 = vld1q_u8(data); |
||||
const uint8x16_t input2 = vld1q_u8(data2); |
||||
|
||||
or1 = vorrq_u8(or1, input1); |
||||
or2 = vorrq_u8(or2, input2); |
||||
|
||||
data += 32; |
||||
data2 += 32; |
||||
len -= 32; |
||||
} |
||||
|
||||
or1 = vorrq_u8(or1, or2); |
||||
if (vmaxvq_u8(or1) >= 0x80) return 0; |
||||
} |
||||
|
||||
return ascii_u64(data, len); |
||||
} |
||||
|
||||
#endif |
||||
|
||||
struct ftab { |
||||
const char *name; |
||||
int (*func)(const uint8_t *data, int len); |
||||
}; |
||||
|
||||
static const std::vector<ftab> _f = { |
||||
{ |
||||
.name = "std", |
||||
.func = ascii_std, |
||||
}, |
||||
{ |
||||
.name = "u64", |
||||
.func = ascii_u64, |
||||
}, |
||||
{ |
||||
.name = "simd", |
||||
.func = ascii_simd, |
||||
}, |
||||
}; |
||||
|
||||
static void load_test_buf(uint8_t *data, int len) { |
||||
uint8_t v = 0; |
||||
|
||||
for (int i = 0; i < len; ++i) { |
||||
data[i] = v++; |
||||
v &= 0x7F; |
||||
} |
||||
} |
||||
|
||||
static void bench(const struct ftab &f, const uint8_t *data, int len) { |
||||
const int loops = 1024 * 1024 * 1024 / len; |
||||
int ret = 1; |
||||
double time_aligned, time_unaligned, size; |
||||
struct timeval tv1, tv2; |
||||
|
||||
fprintf(stderr, "bench %s (%d bytes)... ", f.name, len); |
||||
|
||||
/* aligned */ |
||||
gettimeofday(&tv1, 0); |
||||
for (int i = 0; i < loops; ++i) ret &= f.func(data, len); |
||||
gettimeofday(&tv2, 0); |
||||
time_aligned = tv2.tv_usec - tv1.tv_usec; |
||||
time_aligned = time_aligned / 1000000 + tv2.tv_sec - tv1.tv_sec; |
||||
|
||||
/* unaligned */ |
||||
gettimeofday(&tv1, 0); |
||||
for (int i = 0; i < loops; ++i) ret &= f.func(data + 1, len); |
||||
gettimeofday(&tv2, 0); |
||||
time_unaligned = tv2.tv_usec - tv1.tv_usec; |
||||
time_unaligned = time_unaligned / 1000000 + tv2.tv_sec - tv1.tv_sec; |
||||
|
||||
printf("%s ", ret ? "pass" : "FAIL"); |
||||
|
||||
size = ((double)len * loops) / (1024 * 1024); |
||||
printf("%.0f/%.0f MB/s\n", size / time_aligned, size / time_unaligned); |
||||
} |
||||
|
||||
static void test(const struct ftab &f, uint8_t *data, int len) { |
||||
int error = 0; |
||||
|
||||
fprintf(stderr, "test %s (%d bytes)... ", f.name, len); |
||||
|
||||
/* positive */ |
||||
error |= !f.func(data, len); |
||||
|
||||
/* negative */ |
||||
if (len < 100 * 1024) { |
||||
for (int i = 0; i < len; ++i) { |
||||
data[i] += 0x80; |
||||
error |= f.func(data, len); |
||||
data[i] -= 0x80; |
||||
} |
||||
} |
||||
|
||||
printf("%s\n", error ? "FAIL" : "pass"); |
||||
} |
||||
|
||||
/* ./ascii [test|bench] [alg] */ |
||||
int main(int argc, const char *argv[]) { |
||||
int do_test = 1, do_bench = 1; |
||||
const char *alg = NULL; |
||||
|
||||
if (argc > 1) { |
||||
do_bench &= !!strcmp(argv[1], "test"); |
||||
do_test &= !!strcmp(argv[1], "bench"); |
||||
} |
||||
|
||||
if (do_bench && argc > 2) alg = argv[2]; |
||||
|
||||
const std::vector<int> size = { |
||||
9, 16 + 1, 32 - 1, 128 + 1, |
||||
1024 + 15, 16 * 1024 + 1, 64 * 1024 + 15, 1024 * 1024}; |
||||
|
||||
int max_size = *std::max_element(size.begin(), size.end()); |
||||
uint8_t *_data = new uint8_t[max_size + 1]; |
||||
assert(((uintptr_t)_data & 7) == 0); |
||||
uint8_t *data = _data + 1; /* Unalign buffer address */ |
||||
|
||||
_data[0] = 0; |
||||
load_test_buf(data, max_size); |
||||
|
||||
if (do_test) { |
||||
printf("==================== Test ====================\n"); |
||||
for (int sz : size) { |
||||
for (auto &f : _f) { |
||||
test(f, data, sz); |
||||
} |
||||
} |
||||
} |
||||
|
||||
if (do_bench) { |
||||
printf("==================== Bench ====================\n"); |
||||
for (int sz : size) { |
||||
for (auto &f : _f) { |
||||
if (!alg || strcmp(alg, f.name) == 0) bench(f, _data, sz); |
||||
} |
||||
printf("-----------------------------------------------\n"); |
||||
} |
||||
} |
||||
|
||||
delete _data; |
||||
return 0; |
||||
} |
||||
@ -0,0 +1,15 @@ |
||||
#include <boost/locale.hpp> |
||||
|
||||
using namespace std; |
||||
|
||||
/* Return 0 on sucess, -1 on error */ |
||||
extern "C" int utf8_boost(const unsigned char* data, int len) { |
||||
try { |
||||
boost::locale::conv::utf_to_utf<char>(data, data + len, |
||||
boost::locale::conv::stop); |
||||
} catch (const boost::locale::conv::conversion_error& ex) { |
||||
return -1; |
||||
} |
||||
|
||||
return 0; |
||||
} |
||||
@ -0,0 +1,7 @@ |
||||
# Depend packages |
||||
if(NOT TARGET absl::strings) |
||||
find_package(absl CONFIG) |
||||
endif() |
||||
|
||||
# Imported targets |
||||
include("${CMAKE_CURRENT_LIST_DIR}/utf8_range-targets.cmake") |
||||
@ -0,0 +1,9 @@ |
||||
load("@rules_fuzzing//fuzzing:cc_defs.bzl", "cc_fuzz_test") |
||||
|
||||
cc_fuzz_test( |
||||
name = "utf8_validity_fuzzer", |
||||
testonly = 1, |
||||
srcs = ["utf8_validity_fuzzer.cc"], |
||||
dicts = ["utf8_fuzzer.dict"], |
||||
deps = ["//:utf8_validity"], |
||||
) |
||||
@ -0,0 +1,7 @@ |
||||
# 1, 2, 3 and 4 letter unicode symbols. Also 16 byte non ascii symbols to faster |
||||
# test the SIMD case |
||||
"z" |
||||
"\xd1\x8f" |
||||
"\xe2\x8f\xa9" |
||||
"\xf0\x9f\x94\x8b" |
||||
"\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f\xd1\x8f" |
||||
@ -0,0 +1,15 @@ |
||||
// Copyright 2022 Google LLC
|
||||
//
|
||||
// Use of this source code is governed by an MIT-style
|
||||
// license that can be found in the LICENSE file or at
|
||||
// https://opensource.org/licenses/MIT.
|
||||
|
||||
#include "utf8_validity.h" |
||||
|
||||
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) { |
||||
utf8_range::IsStructurallyValid( |
||||
absl::string_view(reinterpret_cast<const char *>(data), size)); |
||||
utf8_range::SpanStructurallyValid( |
||||
absl::string_view(reinterpret_cast<const char *>(data), size)); |
||||
return 0; |
||||
} |
||||
@ -0,0 +1,233 @@ |
||||
// Adapted from https://github.com/lemire/fastvalidate-utf-8
|
||||
|
||||
#ifdef __AVX2__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stddef.h> |
||||
#include <stdint.h> |
||||
#include <string.h> |
||||
#include <x86intrin.h> |
||||
|
||||
/*
|
||||
* legal utf-8 byte sequence |
||||
* http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf - page 94
|
||||
* |
||||
* Code Points 1st 2s 3s 4s |
||||
* U+0000..U+007F 00..7F |
||||
* U+0080..U+07FF C2..DF 80..BF |
||||
* U+0800..U+0FFF E0 A0..BF 80..BF |
||||
* U+1000..U+CFFF E1..EC 80..BF 80..BF |
||||
* U+D000..U+D7FF ED 80..9F 80..BF |
||||
* U+E000..U+FFFF EE..EF 80..BF 80..BF |
||||
* U+10000..U+3FFFF F0 90..BF 80..BF 80..BF |
||||
* U+40000..U+FFFFF F1..F3 80..BF 80..BF 80..BF |
||||
* U+100000..U+10FFFF F4 80..8F 80..BF 80..BF |
||||
* |
||||
*/ |
||||
|
||||
#if 0 |
||||
static void print256(const char *s, const __m256i v256) |
||||
{ |
||||
const unsigned char *v8 = (const unsigned char *)&v256; |
||||
if (s) |
||||
printf("%s:\t", s); |
||||
for (int i = 0; i < 32; i++) |
||||
printf("%02x ", v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
static inline __m256i push_last_byte_of_a_to_b(__m256i a, __m256i b) { |
||||
return _mm256_alignr_epi8(b, _mm256_permute2x128_si256(a, b, 0x21), 15); |
||||
} |
||||
|
||||
static inline __m256i push_last_2bytes_of_a_to_b(__m256i a, __m256i b) { |
||||
return _mm256_alignr_epi8(b, _mm256_permute2x128_si256(a, b, 0x21), 14); |
||||
} |
||||
|
||||
// all byte values must be no larger than 0xF4
|
||||
static inline void avxcheckSmallerThan0xF4(__m256i current_bytes, |
||||
__m256i *has_error) { |
||||
// unsigned, saturates to 0 below max
|
||||
*has_error = _mm256_or_si256( |
||||
*has_error, _mm256_subs_epu8(current_bytes, _mm256_set1_epi8(0xF4))); |
||||
} |
||||
|
||||
static inline __m256i avxcontinuationLengths(__m256i high_nibbles) { |
||||
return _mm256_shuffle_epi8( |
||||
_mm256_setr_epi8(1, 1, 1, 1, 1, 1, 1, 1, // 0xxx (ASCII)
|
||||
0, 0, 0, 0, // 10xx (continuation)
|
||||
2, 2, // 110x
|
||||
3, // 1110
|
||||
4, // 1111, next should be 0 (not checked here)
|
||||
1, 1, 1, 1, 1, 1, 1, 1, // 0xxx (ASCII)
|
||||
0, 0, 0, 0, // 10xx (continuation)
|
||||
2, 2, // 110x
|
||||
3, // 1110
|
||||
4 // 1111, next should be 0 (not checked here)
|
||||
), |
||||
high_nibbles); |
||||
} |
||||
|
||||
static inline __m256i avxcarryContinuations(__m256i initial_lengths, |
||||
__m256i previous_carries) { |
||||
|
||||
__m256i right1 = _mm256_subs_epu8( |
||||
push_last_byte_of_a_to_b(previous_carries, initial_lengths), |
||||
_mm256_set1_epi8(1)); |
||||
__m256i sum = _mm256_add_epi8(initial_lengths, right1); |
||||
|
||||
__m256i right2 = _mm256_subs_epu8( |
||||
push_last_2bytes_of_a_to_b(previous_carries, sum), _mm256_set1_epi8(2)); |
||||
return _mm256_add_epi8(sum, right2); |
||||
} |
||||
|
||||
static inline void avxcheckContinuations(__m256i initial_lengths, |
||||
__m256i carries, __m256i *has_error) { |
||||
|
||||
// overlap || underlap
|
||||
// carry > length && length > 0 || !(carry > length) && !(length > 0)
|
||||
// (carries > length) == (lengths > 0)
|
||||
__m256i overunder = _mm256_cmpeq_epi8( |
||||
_mm256_cmpgt_epi8(carries, initial_lengths), |
||||
_mm256_cmpgt_epi8(initial_lengths, _mm256_setzero_si256())); |
||||
|
||||
*has_error = _mm256_or_si256(*has_error, overunder); |
||||
} |
||||
|
||||
// when 0xED is found, next byte must be no larger than 0x9F
|
||||
// when 0xF4 is found, next byte must be no larger than 0x8F
|
||||
// next byte must be continuation, ie sign bit is set, so signed < is ok
|
||||
static inline void avxcheckFirstContinuationMax(__m256i current_bytes, |
||||
__m256i off1_current_bytes, |
||||
__m256i *has_error) { |
||||
__m256i maskED = |
||||
_mm256_cmpeq_epi8(off1_current_bytes, _mm256_set1_epi8(0xED)); |
||||
__m256i maskF4 = |
||||
_mm256_cmpeq_epi8(off1_current_bytes, _mm256_set1_epi8(0xF4)); |
||||
|
||||
__m256i badfollowED = _mm256_and_si256( |
||||
_mm256_cmpgt_epi8(current_bytes, _mm256_set1_epi8(0x9F)), maskED); |
||||
__m256i badfollowF4 = _mm256_and_si256( |
||||
_mm256_cmpgt_epi8(current_bytes, _mm256_set1_epi8(0x8F)), maskF4); |
||||
|
||||
*has_error = |
||||
_mm256_or_si256(*has_error, _mm256_or_si256(badfollowED, badfollowF4)); |
||||
} |
||||
|
||||
// map off1_hibits => error condition
|
||||
// hibits off1 cur
|
||||
// C => < C2 && true
|
||||
// E => < E1 && < A0
|
||||
// F => < F1 && < 90
|
||||
// else false && false
|
||||
static inline void avxcheckOverlong(__m256i current_bytes, |
||||
__m256i off1_current_bytes, __m256i hibits, |
||||
__m256i previous_hibits, |
||||
__m256i *has_error) { |
||||
__m256i off1_hibits = push_last_byte_of_a_to_b(previous_hibits, hibits); |
||||
__m256i initial_mins = _mm256_shuffle_epi8( |
||||
_mm256_setr_epi8(-128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, -128, // 10xx => false
|
||||
0xC2, -128, // 110x
|
||||
0xE1, // 1110
|
||||
0xF1, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, -128, -128, // 10xx => false
|
||||
0xC2, -128, // 110x
|
||||
0xE1, // 1110
|
||||
0xF1), |
||||
off1_hibits); |
||||
|
||||
__m256i initial_under = _mm256_cmpgt_epi8(initial_mins, off1_current_bytes); |
||||
|
||||
__m256i second_mins = _mm256_shuffle_epi8( |
||||
_mm256_setr_epi8(-128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, -128, // 10xx => false
|
||||
127, 127, // 110x => true
|
||||
0xA0, // 1110
|
||||
0x90, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, -128, -128, // 10xx => false
|
||||
127, 127, // 110x => true
|
||||
0xA0, // 1110
|
||||
0x90), |
||||
off1_hibits); |
||||
__m256i second_under = _mm256_cmpgt_epi8(second_mins, current_bytes); |
||||
*has_error = _mm256_or_si256(*has_error, |
||||
_mm256_and_si256(initial_under, second_under)); |
||||
} |
||||
|
||||
struct avx_processed_utf_bytes { |
||||
__m256i rawbytes; |
||||
__m256i high_nibbles; |
||||
__m256i carried_continuations; |
||||
}; |
||||
|
||||
static inline void avx_count_nibbles(__m256i bytes, |
||||
struct avx_processed_utf_bytes *answer) { |
||||
answer->rawbytes = bytes; |
||||
answer->high_nibbles = |
||||
_mm256_and_si256(_mm256_srli_epi16(bytes, 4), _mm256_set1_epi8(0x0F)); |
||||
} |
||||
|
||||
// check whether the current bytes are valid UTF-8
|
||||
// at the end of the function, previous gets updated
|
||||
static struct avx_processed_utf_bytes |
||||
avxcheckUTF8Bytes(__m256i current_bytes, |
||||
struct avx_processed_utf_bytes *previous, |
||||
__m256i *has_error) { |
||||
struct avx_processed_utf_bytes pb; |
||||
avx_count_nibbles(current_bytes, &pb); |
||||
|
||||
avxcheckSmallerThan0xF4(current_bytes, has_error); |
||||
|
||||
__m256i initial_lengths = avxcontinuationLengths(pb.high_nibbles); |
||||
|
||||
pb.carried_continuations = |
||||
avxcarryContinuations(initial_lengths, previous->carried_continuations); |
||||
|
||||
avxcheckContinuations(initial_lengths, pb.carried_continuations, has_error); |
||||
|
||||
__m256i off1_current_bytes = |
||||
push_last_byte_of_a_to_b(previous->rawbytes, pb.rawbytes); |
||||
avxcheckFirstContinuationMax(current_bytes, off1_current_bytes, has_error); |
||||
|
||||
avxcheckOverlong(current_bytes, off1_current_bytes, pb.high_nibbles, |
||||
previous->high_nibbles, has_error); |
||||
return pb; |
||||
} |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_lemire_avx2(const unsigned char *src, int len) { |
||||
size_t i = 0; |
||||
__m256i has_error = _mm256_setzero_si256(); |
||||
struct avx_processed_utf_bytes previous = { |
||||
.rawbytes = _mm256_setzero_si256(), |
||||
.high_nibbles = _mm256_setzero_si256(), |
||||
.carried_continuations = _mm256_setzero_si256()}; |
||||
if (len >= 32) { |
||||
for (; i <= len - 32; i += 32) { |
||||
__m256i current_bytes = _mm256_loadu_si256((const __m256i *)(src + i)); |
||||
previous = avxcheckUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} |
||||
} |
||||
|
||||
// last part
|
||||
if (i < len) { |
||||
char buffer[32]; |
||||
memset(buffer, 0, 32); |
||||
memcpy(buffer, src + i, len - i); |
||||
__m256i current_bytes = _mm256_loadu_si256((const __m256i *)(buffer)); |
||||
previous = avxcheckUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} else { |
||||
has_error = _mm256_or_si256( |
||||
_mm256_cmpgt_epi8(previous.carried_continuations, |
||||
_mm256_setr_epi8(9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, |
||||
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, |
||||
9, 9, 9, 9, 9, 9, 9, 1)), |
||||
has_error); |
||||
} |
||||
|
||||
return _mm256_testz_si256(has_error, has_error) ? 0 : -1; |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,215 @@ |
||||
// Adapted from https://github.com/lemire/fastvalidate-utf-8
|
||||
|
||||
#ifdef __aarch64__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stddef.h> |
||||
#include <stdint.h> |
||||
#include <string.h> |
||||
#include <inttypes.h> |
||||
#include <arm_neon.h> |
||||
|
||||
/*
|
||||
* legal utf-8 byte sequence |
||||
* http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf - page 94
|
||||
* |
||||
* Code Points 1st 2s 3s 4s |
||||
* U+0000..U+007F 00..7F |
||||
* U+0080..U+07FF C2..DF 80..BF |
||||
* U+0800..U+0FFF E0 A0..BF 80..BF |
||||
* U+1000..U+CFFF E1..EC 80..BF 80..BF |
||||
* U+D000..U+D7FF ED 80..9F 80..BF |
||||
* U+E000..U+FFFF EE..EF 80..BF 80..BF |
||||
* U+10000..U+3FFFF F0 90..BF 80..BF 80..BF |
||||
* U+40000..U+FFFFF F1..F3 80..BF 80..BF 80..BF |
||||
* U+100000..U+10FFFF F4 80..8F 80..BF 80..BF |
||||
* |
||||
*/ |
||||
|
||||
#if 0 |
||||
static void print128(const char *s, const int8x16_t *v128) |
||||
{ |
||||
int8_t v8[16]; |
||||
vst1q_s8(v8, *v128); |
||||
|
||||
if (s) |
||||
printf("%s:\t", s); |
||||
for (int i = 0; i < 16; ++i) |
||||
printf("%02x ", (unsigned char)v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
// all byte values must be no larger than 0xF4
|
||||
static inline void checkSmallerThan0xF4(int8x16_t current_bytes, |
||||
int8x16_t *has_error) { |
||||
// unsigned, saturates to 0 below max
|
||||
*has_error = vorrq_s8(*has_error, |
||||
vreinterpretq_s8_u8(vqsubq_u8(vreinterpretq_u8_s8(current_bytes), vdupq_n_u8(0xF4)))); |
||||
} |
||||
|
||||
static const int8_t _nibbles[] = { |
||||
1, 1, 1, 1, 1, 1, 1, 1, // 0xxx (ASCII)
|
||||
0, 0, 0, 0, // 10xx (continuation)
|
||||
2, 2, // 110x
|
||||
3, // 1110
|
||||
4, // 1111, next should be 0 (not checked here)
|
||||
}; |
||||
|
||||
static inline int8x16_t continuationLengths(int8x16_t high_nibbles) { |
||||
return vqtbl1q_s8(vld1q_s8(_nibbles), vreinterpretq_u8_s8(high_nibbles)); |
||||
} |
||||
|
||||
static inline int8x16_t carryContinuations(int8x16_t initial_lengths, |
||||
int8x16_t previous_carries) { |
||||
|
||||
int8x16_t right1 = |
||||
vreinterpretq_s8_u8(vqsubq_u8(vreinterpretq_u8_s8(vextq_s8(previous_carries, initial_lengths, 16 - 1)), |
||||
vdupq_n_u8(1))); |
||||
int8x16_t sum = vaddq_s8(initial_lengths, right1); |
||||
|
||||
int8x16_t right2 = vreinterpretq_s8_u8(vqsubq_u8(vreinterpretq_u8_s8(vextq_s8(previous_carries, sum, 16 - 2)), |
||||
vdupq_n_u8(2))); |
||||
return vaddq_s8(sum, right2); |
||||
} |
||||
|
||||
static inline void checkContinuations(int8x16_t initial_lengths, int8x16_t carries, |
||||
int8x16_t *has_error) { |
||||
|
||||
// overlap || underlap
|
||||
// carry > length && length > 0 || !(carry > length) && !(length > 0)
|
||||
// (carries > length) == (lengths > 0)
|
||||
uint8x16_t overunder = |
||||
vceqq_u8(vcgtq_s8(carries, initial_lengths), |
||||
vcgtq_s8(initial_lengths, vdupq_n_s8(0))); |
||||
|
||||
*has_error = vorrq_s8(*has_error, vreinterpretq_s8_u8(overunder)); |
||||
} |
||||
|
||||
// when 0xED is found, next byte must be no larger than 0x9F
|
||||
// when 0xF4 is found, next byte must be no larger than 0x8F
|
||||
// next byte must be continuation, ie sign bit is set, so signed < is ok
|
||||
static inline void checkFirstContinuationMax(int8x16_t current_bytes, |
||||
int8x16_t off1_current_bytes, |
||||
int8x16_t *has_error) { |
||||
uint8x16_t maskED = vceqq_s8(off1_current_bytes, vdupq_n_s8(0xED)); |
||||
uint8x16_t maskF4 = vceqq_s8(off1_current_bytes, vdupq_n_s8(0xF4)); |
||||
|
||||
uint8x16_t badfollowED = |
||||
vandq_u8(vcgtq_s8(current_bytes, vdupq_n_s8(0x9F)), maskED); |
||||
uint8x16_t badfollowF4 = |
||||
vandq_u8(vcgtq_s8(current_bytes, vdupq_n_s8(0x8F)), maskF4); |
||||
|
||||
*has_error = vorrq_s8(*has_error, vreinterpretq_s8_u8(vorrq_u8(badfollowED, badfollowF4))); |
||||
} |
||||
|
||||
static const int8_t _initial_mins[] = { |
||||
-128, -128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, // 10xx => false
|
||||
0xC2, -128, // 110x
|
||||
0xE1, // 1110
|
||||
0xF1, |
||||
}; |
||||
|
||||
static const int8_t _second_mins[] = { |
||||
-128, -128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, // 10xx => false
|
||||
127, 127, // 110x => true
|
||||
0xA0, // 1110
|
||||
0x90, |
||||
}; |
||||
|
||||
// map off1_hibits => error condition
|
||||
// hibits off1 cur
|
||||
// C => < C2 && true
|
||||
// E => < E1 && < A0
|
||||
// F => < F1 && < 90
|
||||
// else false && false
|
||||
static inline void checkOverlong(int8x16_t current_bytes, |
||||
int8x16_t off1_current_bytes, int8x16_t hibits, |
||||
int8x16_t previous_hibits, int8x16_t *has_error) { |
||||
int8x16_t off1_hibits = vextq_s8(previous_hibits, hibits, 16 - 1); |
||||
int8x16_t initial_mins = vqtbl1q_s8(vld1q_s8(_initial_mins), vreinterpretq_u8_s8(off1_hibits)); |
||||
|
||||
uint8x16_t initial_under = vcgtq_s8(initial_mins, off1_current_bytes); |
||||
|
||||
int8x16_t second_mins = vqtbl1q_s8(vld1q_s8(_second_mins), vreinterpretq_u8_s8(off1_hibits)); |
||||
uint8x16_t second_under = vcgtq_s8(second_mins, current_bytes); |
||||
*has_error = |
||||
vorrq_s8(*has_error, vreinterpretq_s8_u8(vandq_u8(initial_under, second_under))); |
||||
} |
||||
|
||||
struct processed_utf_bytes { |
||||
int8x16_t rawbytes; |
||||
int8x16_t high_nibbles; |
||||
int8x16_t carried_continuations; |
||||
}; |
||||
|
||||
static inline void count_nibbles(int8x16_t bytes, |
||||
struct processed_utf_bytes *answer) { |
||||
answer->rawbytes = bytes; |
||||
answer->high_nibbles = |
||||
vreinterpretq_s8_u8(vshrq_n_u8(vreinterpretq_u8_s8(bytes), 4)); |
||||
} |
||||
|
||||
// check whether the current bytes are valid UTF-8
|
||||
// at the end of the function, previous gets updated
|
||||
static inline struct processed_utf_bytes |
||||
checkUTF8Bytes(int8x16_t current_bytes, struct processed_utf_bytes *previous, |
||||
int8x16_t *has_error) { |
||||
struct processed_utf_bytes pb; |
||||
count_nibbles(current_bytes, &pb); |
||||
|
||||
checkSmallerThan0xF4(current_bytes, has_error); |
||||
|
||||
int8x16_t initial_lengths = continuationLengths(pb.high_nibbles); |
||||
|
||||
pb.carried_continuations = |
||||
carryContinuations(initial_lengths, previous->carried_continuations); |
||||
|
||||
checkContinuations(initial_lengths, pb.carried_continuations, has_error); |
||||
|
||||
int8x16_t off1_current_bytes = |
||||
vextq_s8(previous->rawbytes, pb.rawbytes, 16 - 1); |
||||
checkFirstContinuationMax(current_bytes, off1_current_bytes, has_error); |
||||
|
||||
checkOverlong(current_bytes, off1_current_bytes, pb.high_nibbles, |
||||
previous->high_nibbles, has_error); |
||||
return pb; |
||||
} |
||||
|
||||
static const int8_t _verror[] = {9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 1}; |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_lemire(const unsigned char *src, int len) { |
||||
size_t i = 0; |
||||
int8x16_t has_error = vdupq_n_s8(0); |
||||
struct processed_utf_bytes previous = {.rawbytes = vdupq_n_s8(0), |
||||
.high_nibbles = vdupq_n_s8(0), |
||||
.carried_continuations = |
||||
vdupq_n_s8(0)}; |
||||
if (len >= 16) { |
||||
for (; i <= len - 16; i += 16) { |
||||
int8x16_t current_bytes = vld1q_s8((int8_t*)(src + i)); |
||||
previous = checkUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} |
||||
} |
||||
|
||||
// last part
|
||||
if (i < len) { |
||||
char buffer[16]; |
||||
memset(buffer, 0, 16); |
||||
memcpy(buffer, src + i, len - i); |
||||
int8x16_t current_bytes = vld1q_s8((int8_t *)buffer); |
||||
previous = checkUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} else { |
||||
has_error = |
||||
vorrq_s8(vreinterpretq_s8_u8(vcgtq_s8(previous.carried_continuations, |
||||
vld1q_s8(_verror))), |
||||
has_error); |
||||
} |
||||
|
||||
return vmaxvq_u8(vreinterpretq_u8_s8(has_error)) == 0 ? 0 : -1; |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,206 @@ |
||||
// Adapted from https://github.com/lemire/fastvalidate-utf-8
|
||||
|
||||
#ifdef __x86_64__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stddef.h> |
||||
#include <stdint.h> |
||||
#include <string.h> |
||||
#include <x86intrin.h> |
||||
|
||||
/*
|
||||
* legal utf-8 byte sequence |
||||
* http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf - page 94
|
||||
* |
||||
* Code Points 1st 2s 3s 4s |
||||
* U+0000..U+007F 00..7F |
||||
* U+0080..U+07FF C2..DF 80..BF |
||||
* U+0800..U+0FFF E0 A0..BF 80..BF |
||||
* U+1000..U+CFFF E1..EC 80..BF 80..BF |
||||
* U+D000..U+D7FF ED 80..9F 80..BF |
||||
* U+E000..U+FFFF EE..EF 80..BF 80..BF |
||||
* U+10000..U+3FFFF F0 90..BF 80..BF 80..BF |
||||
* U+40000..U+FFFFF F1..F3 80..BF 80..BF 80..BF |
||||
* U+100000..U+10FFFF F4 80..8F 80..BF 80..BF |
||||
* |
||||
*/ |
||||
|
||||
#if 0 |
||||
static void print128(const char *s, const __m128i *v128) |
||||
{ |
||||
const unsigned char *v8 = (const unsigned char *)v128; |
||||
if (s) |
||||
printf("%s: ", s); |
||||
for (int i = 0; i < 16; i++) |
||||
printf("%02x ", v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
// all byte values must be no larger than 0xF4
|
||||
static inline void checkSmallerThan0xF4(__m128i current_bytes, |
||||
__m128i *has_error) { |
||||
// unsigned, saturates to 0 below max
|
||||
*has_error = _mm_or_si128(*has_error, |
||||
_mm_subs_epu8(current_bytes, _mm_set1_epi8(0xF4))); |
||||
} |
||||
|
||||
static inline __m128i continuationLengths(__m128i high_nibbles) { |
||||
return _mm_shuffle_epi8( |
||||
_mm_setr_epi8(1, 1, 1, 1, 1, 1, 1, 1, // 0xxx (ASCII)
|
||||
0, 0, 0, 0, // 10xx (continuation)
|
||||
2, 2, // 110x
|
||||
3, // 1110
|
||||
4), // 1111, next should be 0 (not checked here)
|
||||
high_nibbles); |
||||
} |
||||
|
||||
static inline __m128i carryContinuations(__m128i initial_lengths, |
||||
__m128i previous_carries) { |
||||
|
||||
__m128i right1 = |
||||
_mm_subs_epu8(_mm_alignr_epi8(initial_lengths, previous_carries, 16 - 1), |
||||
_mm_set1_epi8(1)); |
||||
__m128i sum = _mm_add_epi8(initial_lengths, right1); |
||||
|
||||
__m128i right2 = _mm_subs_epu8(_mm_alignr_epi8(sum, previous_carries, 16 - 2), |
||||
_mm_set1_epi8(2)); |
||||
return _mm_add_epi8(sum, right2); |
||||
} |
||||
|
||||
static inline void checkContinuations(__m128i initial_lengths, __m128i carries, |
||||
__m128i *has_error) { |
||||
|
||||
// overlap || underlap
|
||||
// carry > length && length > 0 || !(carry > length) && !(length > 0)
|
||||
// (carries > length) == (lengths > 0)
|
||||
__m128i overunder = |
||||
_mm_cmpeq_epi8(_mm_cmpgt_epi8(carries, initial_lengths), |
||||
_mm_cmpgt_epi8(initial_lengths, _mm_setzero_si128())); |
||||
|
||||
*has_error = _mm_or_si128(*has_error, overunder); |
||||
} |
||||
|
||||
// when 0xED is found, next byte must be no larger than 0x9F
|
||||
// when 0xF4 is found, next byte must be no larger than 0x8F
|
||||
// next byte must be continuation, ie sign bit is set, so signed < is ok
|
||||
static inline void checkFirstContinuationMax(__m128i current_bytes, |
||||
__m128i off1_current_bytes, |
||||
__m128i *has_error) { |
||||
__m128i maskED = _mm_cmpeq_epi8(off1_current_bytes, _mm_set1_epi8(0xED)); |
||||
__m128i maskF4 = _mm_cmpeq_epi8(off1_current_bytes, _mm_set1_epi8(0xF4)); |
||||
|
||||
__m128i badfollowED = |
||||
_mm_and_si128(_mm_cmpgt_epi8(current_bytes, _mm_set1_epi8(0x9F)), maskED); |
||||
__m128i badfollowF4 = |
||||
_mm_and_si128(_mm_cmpgt_epi8(current_bytes, _mm_set1_epi8(0x8F)), maskF4); |
||||
|
||||
*has_error = _mm_or_si128(*has_error, _mm_or_si128(badfollowED, badfollowF4)); |
||||
} |
||||
|
||||
// map off1_hibits => error condition
|
||||
// hibits off1 cur
|
||||
// C => < C2 && true
|
||||
// E => < E1 && < A0
|
||||
// F => < F1 && < 90
|
||||
// else false && false
|
||||
static inline void checkOverlong(__m128i current_bytes, |
||||
__m128i off1_current_bytes, __m128i hibits, |
||||
__m128i previous_hibits, __m128i *has_error) { |
||||
__m128i off1_hibits = _mm_alignr_epi8(hibits, previous_hibits, 16 - 1); |
||||
__m128i initial_mins = _mm_shuffle_epi8( |
||||
_mm_setr_epi8(-128, -128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, // 10xx => false
|
||||
0xC2, -128, // 110x
|
||||
0xE1, // 1110
|
||||
0xF1), |
||||
off1_hibits); |
||||
|
||||
__m128i initial_under = _mm_cmpgt_epi8(initial_mins, off1_current_bytes); |
||||
|
||||
__m128i second_mins = _mm_shuffle_epi8( |
||||
_mm_setr_epi8(-128, -128, -128, -128, -128, -128, -128, -128, -128, -128, |
||||
-128, -128, // 10xx => false
|
||||
127, 127, // 110x => true
|
||||
0xA0, // 1110
|
||||
0x90), |
||||
off1_hibits); |
||||
__m128i second_under = _mm_cmpgt_epi8(second_mins, current_bytes); |
||||
*has_error = |
||||
_mm_or_si128(*has_error, _mm_and_si128(initial_under, second_under)); |
||||
} |
||||
|
||||
struct processed_utf_bytes { |
||||
__m128i rawbytes; |
||||
__m128i high_nibbles; |
||||
__m128i carried_continuations; |
||||
}; |
||||
|
||||
static inline void count_nibbles(__m128i bytes, |
||||
struct processed_utf_bytes *answer) { |
||||
answer->rawbytes = bytes; |
||||
answer->high_nibbles = |
||||
_mm_and_si128(_mm_srli_epi16(bytes, 4), _mm_set1_epi8(0x0F)); |
||||
} |
||||
|
||||
// check whether the current bytes are valid UTF-8
|
||||
// at the end of the function, previous gets updated
|
||||
static inline struct processed_utf_bytes |
||||
checkUTF8Bytes(__m128i current_bytes, struct processed_utf_bytes *previous, |
||||
__m128i *has_error) { |
||||
|
||||
struct processed_utf_bytes pb; |
||||
count_nibbles(current_bytes, &pb); |
||||
|
||||
checkSmallerThan0xF4(current_bytes, has_error); |
||||
|
||||
__m128i initial_lengths = continuationLengths(pb.high_nibbles); |
||||
|
||||
pb.carried_continuations = |
||||
carryContinuations(initial_lengths, previous->carried_continuations); |
||||
|
||||
checkContinuations(initial_lengths, pb.carried_continuations, has_error); |
||||
|
||||
__m128i off1_current_bytes = |
||||
_mm_alignr_epi8(pb.rawbytes, previous->rawbytes, 16 - 1); |
||||
checkFirstContinuationMax(current_bytes, off1_current_bytes, has_error); |
||||
|
||||
checkOverlong(current_bytes, off1_current_bytes, pb.high_nibbles, |
||||
previous->high_nibbles, has_error); |
||||
return pb; |
||||
} |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_lemire(const unsigned char *src, int len) { |
||||
size_t i = 0; |
||||
__m128i has_error = _mm_setzero_si128(); |
||||
struct processed_utf_bytes previous = {.rawbytes = _mm_setzero_si128(), |
||||
.high_nibbles = _mm_setzero_si128(), |
||||
.carried_continuations = |
||||
_mm_setzero_si128()}; |
||||
if (len >= 16) { |
||||
for (; i <= len - 16; i += 16) { |
||||
__m128i current_bytes = _mm_loadu_si128((const __m128i *)(src + i)); |
||||
previous = checkUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} |
||||
} |
||||
|
||||
// last part
|
||||
if (i < len) { |
||||
char buffer[16]; |
||||
memset(buffer, 0, 16); |
||||
memcpy(buffer, src + i, len - i); |
||||
__m128i current_bytes = _mm_loadu_si128((const __m128i *)(buffer)); |
||||
previous = checkUTF8Bytes(current_bytes, &previous, &has_error); |
||||
} else { |
||||
has_error = |
||||
_mm_or_si128(_mm_cmpgt_epi8(previous.carried_continuations, |
||||
_mm_setr_epi8(9, 9, 9, 9, 9, 9, 9, 9, 9, 9, |
||||
9, 9, 9, 9, 9, 1)), |
||||
has_error); |
||||
} |
||||
|
||||
return _mm_testz_si128(has_error, has_error) ? 0 : -1; |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,41 @@ |
||||
#include <stdio.h> |
||||
|
||||
/* http://bjoern.hoehrmann.de/utf-8/decoder/dfa */ |
||||
/* Optimized version based on Rich Felker's variant. */ |
||||
#define UTF8_ACCEPT 0 |
||||
#define UTF8_REJECT 12 |
||||
|
||||
static const unsigned char utf8d[] = { |
||||
/* The first part of the table maps bytes to character classes that
|
||||
* to reduce the size of the transition table and create bitmasks. */ |
||||
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, |
||||
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, |
||||
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, |
||||
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0, |
||||
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1, 9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9, |
||||
7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7, 7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7, |
||||
8,8,2,2,2,2,2,2,2,2,2,2,2,2,2,2, 2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2, |
||||
10,3,3,3,3,3,3,3,3,3,3,3,3,4,3,3, 11,6,6,6,5,8,8,8,8,8,8,8,8,8,8,8 |
||||
}; |
||||
/* Note: Splitting the table improves performance on ARM due to its simpler
|
||||
* addressing modes not being able to encode x[y + 256]. */ |
||||
static const unsigned char utf8s[] = { |
||||
/* The second part is a transition table that maps a combination
|
||||
* of a state of the automaton and a character class to a state. */ |
||||
0,12,24,36,60,96,84,12,12,12,48,72, 12,12,12,12,12,12,12,12,12,12,12,12, |
||||
12, 0,12,12,12,12,12, 0,12, 0,12,12, 12,24,12,12,12,12,12,24,12,24,12,12, |
||||
12,12,12,12,12,12,12,24,12,12,12,12, 12,24,12,12,12,12,12,12,12,24,12,12, |
||||
12,12,12,12,12,12,12,36,12,36,12,12, 12,36,12,12,12,12,12,36,12,36,12,12, |
||||
12,36,12,12,12,12,12,12,12,12,12,12 |
||||
}; |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_lookup(const unsigned char *data, int len) |
||||
{ |
||||
int state = 0; |
||||
|
||||
while (len-- && state != UTF8_REJECT) |
||||
state = utf8s[state + utf8d[*data++]]; |
||||
|
||||
return state == UTF8_ACCEPT ? 0 : -1; |
||||
} |
||||
@ -0,0 +1,405 @@ |
||||
#include <stdio.h> |
||||
#include <stdlib.h> |
||||
#include <string.h> |
||||
#include <inttypes.h> |
||||
#include <sys/types.h> |
||||
#include <sys/stat.h> |
||||
#include <sys/time.h> |
||||
#include <fcntl.h> |
||||
#include <unistd.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
int utf8_lookup(const unsigned char *data, int len); |
||||
int utf8_boost(const unsigned char *data, int len); |
||||
int utf8_lemire(const unsigned char *data, int len); |
||||
int utf8_range(const unsigned char *data, int len); |
||||
int utf8_range2(const unsigned char *data, int len); |
||||
#ifdef __AVX2__ |
||||
int utf8_lemire_avx2(const unsigned char *data, int len); |
||||
int utf8_range_avx2(const unsigned char *data, int len); |
||||
#endif |
||||
|
||||
static struct ftab { |
||||
const char *name; |
||||
int (*func)(const unsigned char *data, int len); |
||||
} ftab[] = { |
||||
{ |
||||
.name = "naive", |
||||
.func = utf8_naive, |
||||
}, |
||||
{ |
||||
.name = "lookup", |
||||
.func = utf8_lookup, |
||||
}, |
||||
{ |
||||
.name = "lemire", |
||||
.func = utf8_lemire, |
||||
}, |
||||
{ |
||||
.name = "range", |
||||
.func = utf8_range, |
||||
}, |
||||
{ |
||||
.name = "range2", |
||||
.func = utf8_range2, |
||||
}, |
||||
#ifdef __AVX2__ |
||||
{ |
||||
.name = "lemire_avx2", |
||||
.func = utf8_lemire_avx2, |
||||
}, |
||||
{ |
||||
.name = "range_avx2", |
||||
.func = utf8_range_avx2, |
||||
}, |
||||
#endif |
||||
#ifdef BOOST |
||||
{ |
||||
.name = "boost", |
||||
.func = utf8_boost, |
||||
}, |
||||
#endif |
||||
}; |
||||
|
||||
static unsigned char *load_test_buf(int len) |
||||
{ |
||||
const char utf8[] = "\xF0\x90\xBF\x80"; |
||||
const int utf8_len = sizeof(utf8)/sizeof(utf8[0]) - 1; |
||||
|
||||
unsigned char *data = malloc(len); |
||||
unsigned char *p = data; |
||||
|
||||
while (len >= utf8_len) { |
||||
memcpy(p, utf8, utf8_len); |
||||
p += utf8_len; |
||||
len -= utf8_len; |
||||
} |
||||
|
||||
while (len--) |
||||
*p++ = 0x7F; |
||||
|
||||
return data; |
||||
} |
||||
|
||||
static unsigned char *load_test_file(int *len) |
||||
{ |
||||
unsigned char *data; |
||||
int fd; |
||||
struct stat stat; |
||||
|
||||
fd = open("./UTF-8-demo.txt", O_RDONLY); |
||||
if (fd == -1) { |
||||
printf("Failed to open UTF-8-demo.txt!\n"); |
||||
exit(1); |
||||
} |
||||
if (fstat(fd, &stat) == -1) { |
||||
printf("Failed to get file size!\n"); |
||||
exit(1); |
||||
} |
||||
|
||||
*len = stat.st_size; |
||||
data = malloc(*len); |
||||
if (read(fd, data, *len) != *len) { |
||||
printf("Failed to read file!\n"); |
||||
exit(1); |
||||
} |
||||
|
||||
utf8_range(data, *len); |
||||
#ifdef __AVX2__ |
||||
utf8_range_avx2(data, *len); |
||||
#endif |
||||
close(fd); |
||||
|
||||
return data; |
||||
} |
||||
|
||||
static void print_test(const unsigned char *data, int len) |
||||
{ |
||||
while (len--) |
||||
printf("\\x%02X", *data++); |
||||
|
||||
printf("\n"); |
||||
} |
||||
|
||||
struct test { |
||||
const unsigned char *data; |
||||
int len; |
||||
}; |
||||
|
||||
static void prepare_test_buf(unsigned char *buf, const struct test *pos, |
||||
int pos_len, int pos_idx) |
||||
{ |
||||
/* Round concatenate correct tokens to 1024 bytes */ |
||||
int buf_idx = 0; |
||||
while (buf_idx < 1024) { |
||||
int buf_len = 1024 - buf_idx; |
||||
|
||||
if (buf_len >= pos[pos_idx].len) { |
||||
memcpy(buf+buf_idx, pos[pos_idx].data, pos[pos_idx].len); |
||||
buf_idx += pos[pos_idx].len; |
||||
} else { |
||||
memset(buf+buf_idx, 0, buf_len); |
||||
buf_idx += buf_len; |
||||
} |
||||
|
||||
if (++pos_idx == pos_len) |
||||
pos_idx = 0; |
||||
} |
||||
} |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
static int test_manual(const struct ftab *ftab) |
||||
{ |
||||
#pragma GCC diagnostic push |
||||
#pragma GCC diagnostic ignored "-Wpointer-sign" |
||||
/* positive tests */ |
||||
static const struct test pos[] = { |
||||
{"", 0}, |
||||
{"\x00", 1}, |
||||
{"\x66", 1}, |
||||
{"\x7F", 1}, |
||||
{"\x00\x7F", 2}, |
||||
{"\x7F\x00", 2}, |
||||
{"\xC2\x80", 2}, |
||||
{"\xDF\xBF", 2}, |
||||
{"\xE0\xA0\x80", 3}, |
||||
{"\xE0\xA0\xBF", 3}, |
||||
{"\xED\x9F\x80", 3}, |
||||
{"\xEF\x80\xBF", 3}, |
||||
{"\xF0\x90\xBF\x80", 4}, |
||||
{"\xF2\x81\xBE\x99", 4}, |
||||
{"\xF4\x8F\x88\xAA", 4}, |
||||
}; |
||||
|
||||
/* negative tests */ |
||||
static const struct test neg[] = { |
||||
{"\x80", 1}, |
||||
{"\xBF", 1}, |
||||
{"\xC0\x80", 2}, |
||||
{"\xC1\x00", 2}, |
||||
{"\xC2\x7F", 2}, |
||||
{"\xDF\xC0", 2}, |
||||
{"\xE0\x9F\x80", 3}, |
||||
{"\xE0\xC2\x80", 3}, |
||||
{"\xED\xA0\x80", 3}, |
||||
{"\xED\x7F\x80", 3}, |
||||
{"\xEF\x80\x00", 3}, |
||||
{"\xF0\x8F\x80\x80", 4}, |
||||
{"\xF0\xEE\x80\x80", 4}, |
||||
{"\xF2\x90\x91\x7F", 4}, |
||||
{"\xF4\x90\x88\xAA", 4}, |
||||
{"\xF4\x00\xBF\xBF", 4}, |
||||
{"\x00\x00\x00\x00\x00\xC2\x80\x00\x00\x00\xE1\x80\x80\x00\x00\xC2" \
|
||||
"\xC2\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\xC2\xC2\x80\x00\x00\xE1\x80\x80\x00\x00\x00", |
||||
16}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80" \
|
||||
"\x80", 33}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80" \
|
||||
"\xC2\x80", 34}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF0" \
|
||||
"\x80\x80\x80", 35}, |
||||
}; |
||||
#pragma GCC diagnostic push |
||||
|
||||
/* Test single token */ |
||||
for (int i = 0; i < sizeof(pos)/sizeof(pos[0]); ++i) { |
||||
if (ftab->func(pos[i].data, pos[i].len) != 0) { |
||||
printf("FAILED positive test: "); |
||||
print_test(pos[i].data, pos[i].len); |
||||
return -1; |
||||
} |
||||
} |
||||
for (int i = 0; i < sizeof(neg)/sizeof(neg[0]); ++i) { |
||||
if (ftab->func(neg[i].data, neg[i].len) == 0) { |
||||
printf("FAILED negitive test: "); |
||||
print_test(neg[i].data, neg[i].len); |
||||
return -1; |
||||
} |
||||
} |
||||
|
||||
/* Test shifted buffer to cover 1k length */ |
||||
/* buffer size must be greater than 1024 + 16 + max(test string length) */ |
||||
const int max_size = 1024*2; |
||||
uint64_t buf64[max_size/8 + 2]; |
||||
/* Offset 8 bytes by 1 byte */ |
||||
unsigned char *buf = ((unsigned char *)buf64) + 1; |
||||
int buf_len; |
||||
|
||||
for (int i = 0; i < sizeof(pos)/sizeof(pos[0]); ++i) { |
||||
/* Positive test: shift 16 bytes, validate each shift */ |
||||
prepare_test_buf(buf, pos, sizeof(pos)/sizeof(pos[0]), i); |
||||
buf_len = 1024; |
||||
for (int j = 0; j < 16; ++j) { |
||||
if (ftab->func(buf, buf_len) != 0) { |
||||
printf("FAILED positive test: "); |
||||
print_test(buf, buf_len); |
||||
return -1; |
||||
} |
||||
for (int k = buf_len; k >= 1; --k) |
||||
buf[k] = buf[k-1]; |
||||
buf[0] = '\x55'; |
||||
++buf_len; |
||||
} |
||||
|
||||
/* Negative test: trunk last non ascii */ |
||||
while (buf_len >= 1 && buf[buf_len-1] <= 0x7F) |
||||
--buf_len; |
||||
if (buf_len && ftab->func(buf, buf_len-1) == 0) { |
||||
printf("FAILED negitive test: "); |
||||
print_test(buf, buf_len); |
||||
return -1; |
||||
} |
||||
} |
||||
|
||||
/* Negative test */ |
||||
for (int i = 0; i < sizeof(neg)/sizeof(neg[0]); ++i) { |
||||
/* Append one error token, shift 16 bytes, validate each shift */ |
||||
int pos_idx = i % (sizeof(pos)/sizeof(pos[0])); |
||||
prepare_test_buf(buf, pos, sizeof(pos)/sizeof(pos[0]), pos_idx); |
||||
memcpy(buf+1024, neg[i].data, neg[i].len); |
||||
buf_len = 1024 + neg[i].len; |
||||
for (int j = 0; j < 16; ++j) { |
||||
if (ftab->func(buf, buf_len) == 0) { |
||||
printf("FAILED negative test: "); |
||||
print_test(buf, buf_len); |
||||
return -1; |
||||
} |
||||
for (int k = buf_len; k >= 1; --k) |
||||
buf[k] = buf[k-1]; |
||||
buf[0] = '\x66'; |
||||
++buf_len; |
||||
} |
||||
} |
||||
|
||||
return 0; |
||||
} |
||||
|
||||
static int test(const unsigned char *data, int len, const struct ftab *ftab) |
||||
{ |
||||
int ret_standard = ftab->func(data, len); |
||||
int ret_manual = test_manual(ftab); |
||||
printf("%s\n", ftab->name); |
||||
printf("standard test: %s\n", ret_standard ? "FAIL" : "pass"); |
||||
printf("manual test: %s\n", ret_manual ? "FAIL" : "pass"); |
||||
|
||||
return ret_standard | ret_manual; |
||||
} |
||||
|
||||
static int bench(const unsigned char *data, int len, const struct ftab *ftab) |
||||
{ |
||||
const int loops = 1024*1024*1024/len; |
||||
int ret = 0; |
||||
double time, size; |
||||
struct timeval tv1, tv2; |
||||
|
||||
fprintf(stderr, "bench %s... ", ftab->name); |
||||
gettimeofday(&tv1, 0); |
||||
for (int i = 0; i < loops; ++i) |
||||
ret |= ftab->func(data, len); |
||||
gettimeofday(&tv2, 0); |
||||
printf("%s\n", ret?"FAIL":"pass"); |
||||
|
||||
time = tv2.tv_usec - tv1.tv_usec; |
||||
time = time / 1000000 + tv2.tv_sec - tv1.tv_sec; |
||||
size = ((double)len * loops) / (1024*1024); |
||||
printf("time: %.4f s\n", time); |
||||
printf("data: %.0f MB\n", size); |
||||
printf("BW: %.2f MB/s\n", size / time); |
||||
|
||||
return 0; |
||||
} |
||||
|
||||
static void usage(const char *bin) |
||||
{ |
||||
printf("Usage:\n"); |
||||
printf("%s test [alg] ==> test all or one algorithm\n", bin); |
||||
printf("%s bench [alg] ==> benchmark all or one algorithm\n", bin); |
||||
printf("%s bench size NUM ==> benchmark with specific buffer size\n", bin); |
||||
printf("alg = "); |
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) |
||||
printf("%s ", ftab[i].name); |
||||
printf("\nNUM = buffer size in bytes, 1 ~ 67108864(64M)\n"); |
||||
} |
||||
|
||||
int main(int argc, char *argv[]) |
||||
{ |
||||
int len = 0; |
||||
unsigned char *data; |
||||
const char *alg = NULL; |
||||
int (*tb)(const unsigned char *data, int len, const struct ftab *ftab); |
||||
|
||||
tb = NULL; |
||||
if (argc >= 2) { |
||||
if (strcmp(argv[1], "test") == 0) |
||||
tb = test; |
||||
else if (strcmp(argv[1], "bench") == 0) |
||||
tb = bench; |
||||
if (argc >= 3) { |
||||
alg = argv[2]; |
||||
if (strcmp(alg, "size") == 0) { |
||||
if (argc < 4) { |
||||
tb = NULL; |
||||
} else { |
||||
alg = NULL; |
||||
len = atoi(argv[3]); |
||||
if (len <= 0 || len > 67108864) { |
||||
printf("Buffer size error!\n\n"); |
||||
tb = NULL; |
||||
} |
||||
} |
||||
} |
||||
} |
||||
} |
||||
|
||||
if (tb == NULL) { |
||||
usage(argv[0]); |
||||
return 1; |
||||
} |
||||
|
||||
/* Load UTF8 test buffer */ |
||||
if (len) |
||||
data = load_test_buf(len); |
||||
else |
||||
data = load_test_file(&len); |
||||
|
||||
int ret = 0; |
||||
if (tb == bench) |
||||
printf("=============== Bench UTF8 (%d bytes) ===============\n", len); |
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) { |
||||
if (alg && strcmp(alg, ftab[i].name) != 0) |
||||
continue; |
||||
ret |= tb((const unsigned char *)data, len, &ftab[i]); |
||||
printf("\n"); |
||||
} |
||||
|
||||
#if 0 |
||||
if (tb == bench) { |
||||
printf("==================== Bench ASCII ====================\n"); |
||||
/* Change test buffer to ascii */ |
||||
for (int i = 0; i < len; i++) |
||||
data[i] &= 0x7F; |
||||
|
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) { |
||||
if (alg && strcmp(alg, ftab[i].name) != 0) |
||||
continue; |
||||
tb((const unsigned char *)data, len, &ftab[i]); |
||||
printf("\n"); |
||||
} |
||||
} |
||||
#endif |
||||
|
||||
free(data); |
||||
|
||||
return ret; |
||||
} |
||||
@ -0,0 +1,92 @@ |
||||
#include <stdio.h> |
||||
|
||||
/*
|
||||
* http://www.unicode.org/versions/Unicode6.0.0/ch03.pdf - page 94
|
||||
* |
||||
* Table 3-7. Well-Formed UTF-8 Byte Sequences |
||||
* |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | Code Points | First Byte | Second Byte | Third Byte | Fourth Byte | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+0000..U+007F | 00..7F | | | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+0080..U+07FF | C2..DF | 80..BF | | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+0800..U+0FFF | E0 | A0..BF | 80..BF | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+1000..U+CFFF | E1..EC | 80..BF | 80..BF | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+D000..U+D7FF | ED | 80..9F | 80..BF | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+E000..U+FFFF | EE..EF | 80..BF | 80..BF | | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+10000..U+3FFFF | F0 | 90..BF | 80..BF | 80..BF | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+40000..U+FFFFF | F1..F3 | 80..BF | 80..BF | 80..BF | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
* | U+100000..U+10FFFF | F4 | 80..8F | 80..BF | 80..BF | |
||||
* +--------------------+------------+-------------+------------+-------------+ |
||||
*/ |
||||
|
||||
/* Return 0 - success, >0 - index(1 based) of first error char */ |
||||
int utf8_naive(const unsigned char *data, int len) |
||||
{ |
||||
int err_pos = 1; |
||||
|
||||
while (len) { |
||||
int bytes; |
||||
const unsigned char byte1 = data[0]; |
||||
|
||||
/* 00..7F */ |
||||
if (byte1 <= 0x7F) { |
||||
bytes = 1; |
||||
/* C2..DF, 80..BF */ |
||||
} else if (len >= 2 && byte1 >= 0xC2 && byte1 <= 0xDF && |
||||
(signed char)data[1] <= (signed char)0xBF) { |
||||
bytes = 2; |
||||
} else if (len >= 3) { |
||||
const unsigned char byte2 = data[1]; |
||||
|
||||
/* Is byte2, byte3 between 0x80 ~ 0xBF */ |
||||
const int byte2_ok = (signed char)byte2 <= (signed char)0xBF; |
||||
const int byte3_ok = (signed char)data[2] <= (signed char)0xBF; |
||||
|
||||
if (byte2_ok && byte3_ok && |
||||
/* E0, A0..BF, 80..BF */ |
||||
((byte1 == 0xE0 && byte2 >= 0xA0) || |
||||
/* E1..EC, 80..BF, 80..BF */ |
||||
(byte1 >= 0xE1 && byte1 <= 0xEC) || |
||||
/* ED, 80..9F, 80..BF */ |
||||
(byte1 == 0xED && byte2 <= 0x9F) || |
||||
/* EE..EF, 80..BF, 80..BF */ |
||||
(byte1 >= 0xEE && byte1 <= 0xEF))) { |
||||
bytes = 3; |
||||
} else if (len >= 4) { |
||||
/* Is byte4 between 0x80 ~ 0xBF */ |
||||
const int byte4_ok = (signed char)data[3] <= (signed char)0xBF; |
||||
|
||||
if (byte2_ok && byte3_ok && byte4_ok && |
||||
/* F0, 90..BF, 80..BF, 80..BF */ |
||||
((byte1 == 0xF0 && byte2 >= 0x90) || |
||||
/* F1..F3, 80..BF, 80..BF, 80..BF */ |
||||
(byte1 >= 0xF1 && byte1 <= 0xF3) || |
||||
/* F4, 80..8F, 80..BF, 80..BF */ |
||||
(byte1 == 0xF4 && byte2 <= 0x8F))) { |
||||
bytes = 4; |
||||
} else { |
||||
return err_pos; |
||||
} |
||||
} else { |
||||
return err_pos; |
||||
} |
||||
} else { |
||||
return err_pos; |
||||
} |
||||
|
||||
len -= bytes; |
||||
err_pos += bytes; |
||||
data += bytes; |
||||
} |
||||
|
||||
return 0; |
||||
} |
||||
@ -0,0 +1,277 @@ |
||||
#ifdef __AVX2__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stdint.h> |
||||
#include <x86intrin.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
|
||||
#if 0 |
||||
static void print256(const char *s, const __m256i v256) |
||||
{ |
||||
const unsigned char *v8 = (const unsigned char *)&v256; |
||||
if (s) |
||||
printf("%s:\t", s); |
||||
for (int i = 0; i < 32; i++) |
||||
printf("%02x ", v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
/*
|
||||
* Map high nibble of "First Byte" to legal character length minus 1 |
||||
* 0x00 ~ 0xBF --> 0 |
||||
* 0xC0 ~ 0xDF --> 1 |
||||
* 0xE0 ~ 0xEF --> 2 |
||||
* 0xF0 ~ 0xFF --> 3 |
||||
*/ |
||||
static const int8_t _first_len_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
}; |
||||
|
||||
/* Map "First Byte" to 8-th item of range table (0xC2 ~ 0xF4) */ |
||||
static const int8_t _first_range_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
}; |
||||
|
||||
/*
|
||||
* Range table, map range index to min and max values |
||||
* Index 0 : 00 ~ 7F (First Byte, ascii) |
||||
* Index 1,2,3: 80 ~ BF (Second, Third, Fourth Byte) |
||||
* Index 4 : A0 ~ BF (Second Byte after E0) |
||||
* Index 5 : 80 ~ 9F (Second Byte after ED) |
||||
* Index 6 : 90 ~ BF (Second Byte after F0) |
||||
* Index 7 : 80 ~ 8F (Second Byte after F4) |
||||
* Index 8 : C2 ~ F4 (First Byte, non ascii) |
||||
* Index 9~15 : illegal: i >= 127 && i <= -128 |
||||
*/ |
||||
static const int8_t _range_min_tbl[] = { |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, |
||||
}; |
||||
static const int8_t _range_max_tbl[] = { |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, |
||||
}; |
||||
|
||||
/*
|
||||
* Tables for fast handling of four special First Bytes(E0,ED,F0,F4), after |
||||
* which the Second Byte are not 80~BF. It contains "range index adjustment". |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | First Byte | original range| range adjustment | adjusted range | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | E0 | 2 | 2 | 4 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | ED | 2 | 3 | 5 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F0 | 3 | 3 | 6 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F4 | 4 | 4 | 8 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
*/ |
||||
/* index1 -> E0, index14 -> ED */ |
||||
static const int8_t _df_ee_tbl[] = { |
||||
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, |
||||
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, |
||||
}; |
||||
/* index1 -> F0, index5 -> F4 */ |
||||
static const int8_t _ef_fe_tbl[] = { |
||||
0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, |
||||
0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, |
||||
}; |
||||
|
||||
#define RET_ERR_IDX 0 /* Define 1 to return index of first error char */ |
||||
|
||||
static inline __m256i push_last_byte_of_a_to_b(__m256i a, __m256i b) { |
||||
return _mm256_alignr_epi8(b, _mm256_permute2x128_si256(a, b, 0x21), 15); |
||||
} |
||||
|
||||
static inline __m256i push_last_2bytes_of_a_to_b(__m256i a, __m256i b) { |
||||
return _mm256_alignr_epi8(b, _mm256_permute2x128_si256(a, b, 0x21), 14); |
||||
} |
||||
|
||||
static inline __m256i push_last_3bytes_of_a_to_b(__m256i a, __m256i b) { |
||||
return _mm256_alignr_epi8(b, _mm256_permute2x128_si256(a, b, 0x21), 13); |
||||
} |
||||
|
||||
/* 5x faster than naive method */ |
||||
/* Return 0 - success, -1 - error, >0 - first error char(if RET_ERR_IDX = 1) */ |
||||
int utf8_range_avx2(const unsigned char *data, int len) |
||||
{ |
||||
#if RET_ERR_IDX |
||||
int err_pos = 1; |
||||
#endif |
||||
|
||||
if (len >= 32) { |
||||
__m256i prev_input = _mm256_set1_epi8(0); |
||||
__m256i prev_first_len = _mm256_set1_epi8(0); |
||||
|
||||
/* Cached tables */ |
||||
const __m256i first_len_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_first_len_tbl); |
||||
const __m256i first_range_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_first_range_tbl); |
||||
const __m256i range_min_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_range_min_tbl); |
||||
const __m256i range_max_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_range_max_tbl); |
||||
const __m256i df_ee_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_df_ee_tbl); |
||||
const __m256i ef_fe_tbl = |
||||
_mm256_loadu_si256((const __m256i *)_ef_fe_tbl); |
||||
|
||||
#if !RET_ERR_IDX |
||||
__m256i error1 = _mm256_set1_epi8(0); |
||||
__m256i error2 = _mm256_set1_epi8(0); |
||||
#endif |
||||
|
||||
while (len >= 32) { |
||||
const __m256i input = _mm256_loadu_si256((const __m256i *)data); |
||||
|
||||
/* high_nibbles = input >> 4 */ |
||||
const __m256i high_nibbles = |
||||
_mm256_and_si256(_mm256_srli_epi16(input, 4), _mm256_set1_epi8(0x0F)); |
||||
|
||||
/* first_len = legal character length minus 1 */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* first_len = first_len_tbl[high_nibbles] */ |
||||
__m256i first_len = _mm256_shuffle_epi8(first_len_tbl, high_nibbles); |
||||
|
||||
/* First Byte: set range index to 8 for bytes within 0xC0 ~ 0xFF */ |
||||
/* range = first_range_tbl[high_nibbles] */ |
||||
__m256i range = _mm256_shuffle_epi8(first_range_tbl, high_nibbles); |
||||
|
||||
/* Second Byte: set range index to first_len */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* range |= (first_len, prev_first_len) << 1 byte */ |
||||
range = _mm256_or_si256( |
||||
range, push_last_byte_of_a_to_b(prev_first_len, first_len)); |
||||
|
||||
/* Third Byte: set range index to saturate_sub(first_len, 1) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 1 for E0~EF, 2 for F0~FF */ |
||||
__m256i tmp1, tmp2; |
||||
|
||||
/* tmp1 = (first_len, prev_first_len) << 2 bytes */ |
||||
tmp1 = push_last_2bytes_of_a_to_b(prev_first_len, first_len); |
||||
/* tmp2 = saturate_sub(tmp1, 1) */ |
||||
tmp2 = _mm256_subs_epu8(tmp1, _mm256_set1_epi8(1)); |
||||
|
||||
/* range |= tmp2 */ |
||||
range = _mm256_or_si256(range, tmp2); |
||||
|
||||
/* Fourth Byte: set range index to saturate_sub(first_len, 2) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 0 for E0~EF, 1 for F0~FF */ |
||||
/* tmp1 = (first_len, prev_first_len) << 3 bytes */ |
||||
tmp1 = push_last_3bytes_of_a_to_b(prev_first_len, first_len); |
||||
/* tmp2 = saturate_sub(tmp1, 2) */ |
||||
tmp2 = _mm256_subs_epu8(tmp1, _mm256_set1_epi8(2)); |
||||
/* range |= tmp2 */ |
||||
range = _mm256_or_si256(range, tmp2); |
||||
|
||||
/*
|
||||
* Now we have below range indices caluclated |
||||
* Correct cases: |
||||
* - 8 for C0~FF |
||||
* - 3 for 1st byte after F0~FF |
||||
* - 2 for 1st byte after E0~EF or 2nd byte after F0~FF |
||||
* - 1 for 1st byte after C0~DF or 2nd byte after E0~EF or |
||||
* 3rd byte after F0~FF |
||||
* - 0 for others |
||||
* Error cases: |
||||
* 9,10,11 if non ascii First Byte overlaps |
||||
* E.g., F1 80 C2 90 --> 8 3 10 2, where 10 indicates error |
||||
*/ |
||||
|
||||
/* Adjust Second Byte range for special First Bytes(E0,ED,F0,F4) */ |
||||
/* Overlaps lead to index 9~15, which are illegal in range table */ |
||||
__m256i shift1, pos, range2; |
||||
/* shift1 = (input, prev_input) << 1 byte */ |
||||
shift1 = push_last_byte_of_a_to_b(prev_input, input); |
||||
pos = _mm256_sub_epi8(shift1, _mm256_set1_epi8(0xEF)); |
||||
/*
|
||||
* shift1: | EF F0 ... FE | FF 00 ... ... DE | DF E0 ... EE | |
||||
* pos: | 0 1 15 | 16 17 239| 240 241 255| |
||||
* pos-240: | 0 0 0 | 0 0 0 | 0 1 15 | |
||||
* pos+112: | 112 113 127| >= 128 | >= 128 | |
||||
*/ |
||||
tmp1 = _mm256_subs_epu8(pos, _mm256_set1_epi8(240)); |
||||
range2 = _mm256_shuffle_epi8(df_ee_tbl, tmp1); |
||||
tmp2 = _mm256_adds_epu8(pos, _mm256_set1_epi8(112)); |
||||
range2 = _mm256_add_epi8(range2, _mm256_shuffle_epi8(ef_fe_tbl, tmp2)); |
||||
|
||||
range = _mm256_add_epi8(range, range2); |
||||
|
||||
/* Load min and max values per calculated range index */ |
||||
__m256i minv = _mm256_shuffle_epi8(range_min_tbl, range); |
||||
__m256i maxv = _mm256_shuffle_epi8(range_max_tbl, range); |
||||
|
||||
/* Check value range */ |
||||
#if RET_ERR_IDX |
||||
__m256i error = _mm256_cmpgt_epi8(minv, input); |
||||
error = _mm256_or_si256(error, _mm256_cmpgt_epi8(input, maxv)); |
||||
/* 5% performance drop from this conditional branch */ |
||||
if (!_mm256_testz_si256(error, error)) |
||||
break; |
||||
#else |
||||
error1 = _mm256_or_si256(error1, _mm256_cmpgt_epi8(minv, input)); |
||||
error2 = _mm256_or_si256(error2, _mm256_cmpgt_epi8(input, maxv)); |
||||
#endif |
||||
|
||||
prev_input = input; |
||||
prev_first_len = first_len; |
||||
|
||||
data += 32; |
||||
len -= 32; |
||||
#if RET_ERR_IDX |
||||
err_pos += 32; |
||||
#endif |
||||
} |
||||
|
||||
#if RET_ERR_IDX |
||||
/* Error in first 16 bytes */ |
||||
if (err_pos == 1) |
||||
goto do_naive; |
||||
#else |
||||
__m256i error = _mm256_or_si256(error1, error2); |
||||
if (!_mm256_testz_si256(error, error)) |
||||
return -1; |
||||
#endif |
||||
|
||||
/* Find previous token (not 80~BF) */ |
||||
int32_t token4 = _mm256_extract_epi32(prev_input, 7); |
||||
const int8_t *token = (const int8_t *)&token4; |
||||
int lookahead = 0; |
||||
if (token[3] > (int8_t)0xBF) |
||||
lookahead = 1; |
||||
else if (token[2] > (int8_t)0xBF) |
||||
lookahead = 2; |
||||
else if (token[1] > (int8_t)0xBF) |
||||
lookahead = 3; |
||||
|
||||
data -= lookahead; |
||||
len += lookahead; |
||||
#if RET_ERR_IDX |
||||
err_pos -= lookahead; |
||||
#endif |
||||
} |
||||
|
||||
/* Check remaining bytes with naive method */ |
||||
#if RET_ERR_IDX |
||||
int err_pos2; |
||||
do_naive: |
||||
err_pos2 = utf8_naive(data, len); |
||||
if (err_pos2) |
||||
return err_pos + err_pos2 - 1; |
||||
return 0; |
||||
#else |
||||
return utf8_naive(data, len); |
||||
#endif |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,228 @@ |
||||
#ifdef __aarch64__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stdint.h> |
||||
#include <arm_neon.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
|
||||
#if 0 |
||||
static void print128(const char *s, const uint8x16_t v128) |
||||
{ |
||||
unsigned char v8[16]; |
||||
vst1q_u8(v8, v128); |
||||
|
||||
if (s) |
||||
printf("%s:\t", s); |
||||
for (int i = 0; i < 16; ++i) |
||||
printf("%02x ", v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
/*
|
||||
* Map high nibble of "First Byte" to legal character length minus 1 |
||||
* 0x00 ~ 0xBF --> 0 |
||||
* 0xC0 ~ 0xDF --> 1 |
||||
* 0xE0 ~ 0xEF --> 2 |
||||
* 0xF0 ~ 0xFF --> 3 |
||||
*/ |
||||
static const uint8_t _first_len_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
}; |
||||
|
||||
/* Map "First Byte" to 8-th item of range table (0xC2 ~ 0xF4) */ |
||||
static const uint8_t _first_range_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
}; |
||||
|
||||
/*
|
||||
* Range table, map range index to min and max values |
||||
* Index 0 : 00 ~ 7F (First Byte, ascii) |
||||
* Index 1,2,3: 80 ~ BF (Second, Third, Fourth Byte) |
||||
* Index 4 : A0 ~ BF (Second Byte after E0) |
||||
* Index 5 : 80 ~ 9F (Second Byte after ED) |
||||
* Index 6 : 90 ~ BF (Second Byte after F0) |
||||
* Index 7 : 80 ~ 8F (Second Byte after F4) |
||||
* Index 8 : C2 ~ F4 (First Byte, non ascii) |
||||
* Index 9~15 : illegal: u >= 255 && u <= 0 |
||||
*/ |
||||
static const uint8_t _range_min_tbl[] = { |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, |
||||
}; |
||||
static const uint8_t _range_max_tbl[] = { |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, |
||||
}; |
||||
|
||||
/*
|
||||
* This table is for fast handling four special First Bytes(E0,ED,F0,F4), after |
||||
* which the Second Byte are not 80~BF. It contains "range index adjustment". |
||||
* - The idea is to minus byte with E0, use the result(0~31) as the index to |
||||
* lookup the "range index adjustment". Then add the adjustment to original |
||||
* range index to get the correct range. |
||||
* - Range index adjustment |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | First Byte | original range| range adjustment | adjusted range | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | E0 | 2 | 2 | 4 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | ED | 2 | 3 | 5 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F0 | 3 | 3 | 6 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F4 | 4 | 4 | 8 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* - Below is a uint8x16x2 table, data is interleaved in NEON register. So I'm |
||||
* putting it vertically. 1st column is for E0~EF, 2nd column for F0~FF. |
||||
*/ |
||||
static const uint8_t _range_adjust_tbl[] = { |
||||
/* index -> 0~15 16~31 <- index */ |
||||
/* E0 -> */ 2, 3, /* <- F0 */ |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 4, /* <- F4 */ |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
0, 0, |
||||
/* ED -> */ 3, 0, |
||||
0, 0, |
||||
0, 0, |
||||
}; |
||||
|
||||
/* 2x ~ 4x faster than naive method */ |
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_range(const unsigned char *data, int len) |
||||
{ |
||||
if (len >= 16) { |
||||
uint8x16_t prev_input = vdupq_n_u8(0); |
||||
uint8x16_t prev_first_len = vdupq_n_u8(0); |
||||
|
||||
/* Cached tables */ |
||||
const uint8x16_t first_len_tbl = vld1q_u8(_first_len_tbl); |
||||
const uint8x16_t first_range_tbl = vld1q_u8(_first_range_tbl); |
||||
const uint8x16_t range_min_tbl = vld1q_u8(_range_min_tbl); |
||||
const uint8x16_t range_max_tbl = vld1q_u8(_range_max_tbl); |
||||
const uint8x16x2_t range_adjust_tbl = vld2q_u8(_range_adjust_tbl); |
||||
|
||||
/* Cached values */ |
||||
const uint8x16_t const_1 = vdupq_n_u8(1); |
||||
const uint8x16_t const_2 = vdupq_n_u8(2); |
||||
const uint8x16_t const_e0 = vdupq_n_u8(0xE0); |
||||
|
||||
/* We use two error registers to remove a dependency. */ |
||||
uint8x16_t error1 = vdupq_n_u8(0); |
||||
uint8x16_t error2 = vdupq_n_u8(0); |
||||
|
||||
while (len >= 16) { |
||||
const uint8x16_t input = vld1q_u8(data); |
||||
|
||||
/* high_nibbles = input >> 4 */ |
||||
const uint8x16_t high_nibbles = vshrq_n_u8(input, 4); |
||||
|
||||
/* first_len = legal character length minus 1 */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* first_len = first_len_tbl[high_nibbles] */ |
||||
const uint8x16_t first_len = |
||||
vqtbl1q_u8(first_len_tbl, high_nibbles); |
||||
|
||||
/* First Byte: set range index to 8 for bytes within 0xC0 ~ 0xFF */ |
||||
/* range = first_range_tbl[high_nibbles] */ |
||||
uint8x16_t range = vqtbl1q_u8(first_range_tbl, high_nibbles); |
||||
|
||||
/* Second Byte: set range index to first_len */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* range |= (first_len, prev_first_len) << 1 byte */ |
||||
range = |
||||
vorrq_u8(range, vextq_u8(prev_first_len, first_len, 15)); |
||||
|
||||
/* Third Byte: set range index to saturate_sub(first_len, 1) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 1 for E0~EF, 2 for F0~FF */ |
||||
uint8x16_t tmp1, tmp2; |
||||
/* tmp1 = (first_len, prev_first_len) << 2 bytes */ |
||||
tmp1 = vextq_u8(prev_first_len, first_len, 14); |
||||
/* tmp1 = saturate_sub(tmp1, 1) */ |
||||
tmp1 = vqsubq_u8(tmp1, const_1); |
||||
/* range |= tmp1 */ |
||||
range = vorrq_u8(range, tmp1); |
||||
|
||||
/* Fourth Byte: set range index to saturate_sub(first_len, 2) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 0 for E0~EF, 1 for F0~FF */ |
||||
/* tmp2 = (first_len, prev_first_len) << 3 bytes */ |
||||
tmp2 = vextq_u8(prev_first_len, first_len, 13); |
||||
/* tmp2 = saturate_sub(tmp2, 2) */ |
||||
tmp2 = vqsubq_u8(tmp2, const_2); |
||||
/* range |= tmp2 */ |
||||
range = vorrq_u8(range, tmp2); |
||||
|
||||
/*
|
||||
* Now we have below range indices caluclated |
||||
* Correct cases: |
||||
* - 8 for C0~FF |
||||
* - 3 for 1st byte after F0~FF |
||||
* - 2 for 1st byte after E0~EF or 2nd byte after F0~FF |
||||
* - 1 for 1st byte after C0~DF or 2nd byte after E0~EF or |
||||
* 3rd byte after F0~FF |
||||
* - 0 for others |
||||
* Error cases: |
||||
* 9,10,11 if non ascii First Byte overlaps |
||||
* E.g., F1 80 C2 90 --> 8 3 10 2, where 10 indicates error |
||||
*/ |
||||
|
||||
/* Adjust Second Byte range for special First Bytes(E0,ED,F0,F4) */ |
||||
/* See _range_adjust_tbl[] definition for details */ |
||||
/* Overlaps lead to index 9~15, which are illegal in range table */ |
||||
uint8x16_t shift1 = vextq_u8(prev_input, input, 15); |
||||
uint8x16_t pos = vsubq_u8(shift1, const_e0); |
||||
range = vaddq_u8(range, vqtbl2q_u8(range_adjust_tbl, pos)); |
||||
|
||||
/* Load min and max values per calculated range index */ |
||||
uint8x16_t minv = vqtbl1q_u8(range_min_tbl, range); |
||||
uint8x16_t maxv = vqtbl1q_u8(range_max_tbl, range); |
||||
|
||||
/* Check value range */ |
||||
error1 = vorrq_u8(error1, vcltq_u8(input, minv)); |
||||
error2 = vorrq_u8(error2, vcgtq_u8(input, maxv)); |
||||
|
||||
prev_input = input; |
||||
prev_first_len = first_len; |
||||
|
||||
data += 16; |
||||
len -= 16; |
||||
} |
||||
/* Merge our error counters together */ |
||||
error1 = vorrq_u8(error1, error2); |
||||
|
||||
/* Delay error check till loop ends */ |
||||
if (vmaxvq_u8(error1)) |
||||
return -1; |
||||
|
||||
/* Find previous token (not 80~BF) */ |
||||
uint32_t token4; |
||||
vst1q_lane_u32(&token4, vreinterpretq_u32_u8(prev_input), 3); |
||||
|
||||
const int8_t *token = (const int8_t *)&token4; |
||||
int lookahead = 0; |
||||
if (token[3] > (int8_t)0xBF) |
||||
lookahead = 1; |
||||
else if (token[2] > (int8_t)0xBF) |
||||
lookahead = 2; |
||||
else if (token[1] > (int8_t)0xBF) |
||||
lookahead = 3; |
||||
|
||||
data -= lookahead; |
||||
len += lookahead; |
||||
} |
||||
|
||||
/* Check remaining bytes with naive method */ |
||||
return utf8_naive(data, len); |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,255 @@ |
||||
#ifdef __x86_64__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stdint.h> |
||||
#include <x86intrin.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
|
||||
#if 0 |
||||
static void print128(const char *s, const __m128i v128) |
||||
{ |
||||
const unsigned char *v8 = (const unsigned char *)&v128; |
||||
if (s) |
||||
printf("%s:\t", s); |
||||
for (int i = 0; i < 16; i++) |
||||
printf("%02x ", v8[i]); |
||||
printf("\n"); |
||||
} |
||||
#endif |
||||
|
||||
/*
|
||||
* Map high nibble of "First Byte" to legal character length minus 1 |
||||
* 0x00 ~ 0xBF --> 0 |
||||
* 0xC0 ~ 0xDF --> 1 |
||||
* 0xE0 ~ 0xEF --> 2 |
||||
* 0xF0 ~ 0xFF --> 3 |
||||
*/ |
||||
static const int8_t _first_len_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
}; |
||||
|
||||
/* Map "First Byte" to 8-th item of range table (0xC2 ~ 0xF4) */ |
||||
static const int8_t _first_range_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
}; |
||||
|
||||
/*
|
||||
* Range table, map range index to min and max values |
||||
* Index 0 : 00 ~ 7F (First Byte, ascii) |
||||
* Index 1,2,3: 80 ~ BF (Second, Third, Fourth Byte) |
||||
* Index 4 : A0 ~ BF (Second Byte after E0) |
||||
* Index 5 : 80 ~ 9F (Second Byte after ED) |
||||
* Index 6 : 90 ~ BF (Second Byte after F0) |
||||
* Index 7 : 80 ~ 8F (Second Byte after F4) |
||||
* Index 8 : C2 ~ F4 (First Byte, non ascii) |
||||
* Index 9~15 : illegal: i >= 127 && i <= -128 |
||||
*/ |
||||
static const int8_t _range_min_tbl[] = { |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, |
||||
}; |
||||
static const int8_t _range_max_tbl[] = { |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, |
||||
}; |
||||
|
||||
/*
|
||||
* Tables for fast handling of four special First Bytes(E0,ED,F0,F4), after |
||||
* which the Second Byte are not 80~BF. It contains "range index adjustment". |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | First Byte | original range| range adjustment | adjusted range | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | E0 | 2 | 2 | 4 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | ED | 2 | 3 | 5 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F0 | 3 | 3 | 6 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F4 | 4 | 4 | 8 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
*/ |
||||
/* index1 -> E0, index14 -> ED */ |
||||
static const int8_t _df_ee_tbl[] = { |
||||
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, |
||||
}; |
||||
/* index1 -> F0, index5 -> F4 */ |
||||
static const int8_t _ef_fe_tbl[] = { |
||||
0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, |
||||
}; |
||||
|
||||
#define RET_ERR_IDX 0 /* Define 1 to return index of first error char */ |
||||
|
||||
/* 5x faster than naive method */ |
||||
/* Return 0 - success, -1 - error, >0 - first error char(if RET_ERR_IDX = 1) */ |
||||
int utf8_range(const unsigned char *data, int len) |
||||
{ |
||||
#if RET_ERR_IDX |
||||
int err_pos = 1; |
||||
#endif |
||||
|
||||
if (len >= 16) { |
||||
__m128i prev_input = _mm_set1_epi8(0); |
||||
__m128i prev_first_len = _mm_set1_epi8(0); |
||||
|
||||
/* Cached tables */ |
||||
const __m128i first_len_tbl = |
||||
_mm_loadu_si128((const __m128i *)_first_len_tbl); |
||||
const __m128i first_range_tbl = |
||||
_mm_loadu_si128((const __m128i *)_first_range_tbl); |
||||
const __m128i range_min_tbl = |
||||
_mm_loadu_si128((const __m128i *)_range_min_tbl); |
||||
const __m128i range_max_tbl = |
||||
_mm_loadu_si128((const __m128i *)_range_max_tbl); |
||||
const __m128i df_ee_tbl = |
||||
_mm_loadu_si128((const __m128i *)_df_ee_tbl); |
||||
const __m128i ef_fe_tbl = |
||||
_mm_loadu_si128((const __m128i *)_ef_fe_tbl); |
||||
|
||||
__m128i error = _mm_set1_epi8(0); |
||||
|
||||
while (len >= 16) { |
||||
const __m128i input = _mm_loadu_si128((const __m128i *)data); |
||||
|
||||
/* high_nibbles = input >> 4 */ |
||||
const __m128i high_nibbles = |
||||
_mm_and_si128(_mm_srli_epi16(input, 4), _mm_set1_epi8(0x0F)); |
||||
|
||||
/* first_len = legal character length minus 1 */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* first_len = first_len_tbl[high_nibbles] */ |
||||
__m128i first_len = _mm_shuffle_epi8(first_len_tbl, high_nibbles); |
||||
|
||||
/* First Byte: set range index to 8 for bytes within 0xC0 ~ 0xFF */ |
||||
/* range = first_range_tbl[high_nibbles] */ |
||||
__m128i range = _mm_shuffle_epi8(first_range_tbl, high_nibbles); |
||||
|
||||
/* Second Byte: set range index to first_len */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* range |= (first_len, prev_first_len) << 1 byte */ |
||||
range = _mm_or_si128( |
||||
range, _mm_alignr_epi8(first_len, prev_first_len, 15)); |
||||
|
||||
/* Third Byte: set range index to saturate_sub(first_len, 1) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 1 for E0~EF, 2 for F0~FF */ |
||||
__m128i tmp; |
||||
/* tmp = (first_len, prev_first_len) << 2 bytes */ |
||||
tmp = _mm_alignr_epi8(first_len, prev_first_len, 14); |
||||
/* tmp = saturate_sub(tmp, 1) */ |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(1)); |
||||
/* range |= tmp */ |
||||
range = _mm_or_si128(range, tmp); |
||||
|
||||
/* Fourth Byte: set range index to saturate_sub(first_len, 2) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 0 for E0~EF, 1 for F0~FF */ |
||||
/* tmp = (first_len, prev_first_len) << 3 bytes */ |
||||
tmp = _mm_alignr_epi8(first_len, prev_first_len, 13); |
||||
/* tmp = saturate_sub(tmp, 2) */ |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(2)); |
||||
/* range |= tmp */ |
||||
range = _mm_or_si128(range, tmp); |
||||
|
||||
/*
|
||||
* Now we have below range indices caluclated |
||||
* Correct cases: |
||||
* - 8 for C0~FF |
||||
* - 3 for 1st byte after F0~FF |
||||
* - 2 for 1st byte after E0~EF or 2nd byte after F0~FF |
||||
* - 1 for 1st byte after C0~DF or 2nd byte after E0~EF or |
||||
* 3rd byte after F0~FF |
||||
* - 0 for others |
||||
* Error cases: |
||||
* 9,10,11 if non ascii First Byte overlaps |
||||
* E.g., F1 80 C2 90 --> 8 3 10 2, where 10 indicates error |
||||
*/ |
||||
|
||||
/* Adjust Second Byte range for special First Bytes(E0,ED,F0,F4) */ |
||||
/* Overlaps lead to index 9~15, which are illegal in range table */ |
||||
__m128i shift1, pos, range2; |
||||
/* shift1 = (input, prev_input) << 1 byte */ |
||||
shift1 = _mm_alignr_epi8(input, prev_input, 15); |
||||
pos = _mm_sub_epi8(shift1, _mm_set1_epi8(0xEF)); |
||||
/*
|
||||
* shift1: | EF F0 ... FE | FF 00 ... ... DE | DF E0 ... EE | |
||||
* pos: | 0 1 15 | 16 17 239| 240 241 255| |
||||
* pos-240: | 0 0 0 | 0 0 0 | 0 1 15 | |
||||
* pos+112: | 112 113 127| >= 128 | >= 128 | |
||||
*/ |
||||
tmp = _mm_subs_epu8(pos, _mm_set1_epi8(0xF0)); |
||||
range2 = _mm_shuffle_epi8(df_ee_tbl, tmp); |
||||
tmp = _mm_adds_epu8(pos, _mm_set1_epi8(0x70)); |
||||
range2 = _mm_add_epi8(range2, _mm_shuffle_epi8(ef_fe_tbl, tmp)); |
||||
|
||||
range = _mm_add_epi8(range, range2); |
||||
|
||||
/* Load min and max values per calculated range index */ |
||||
__m128i minv = _mm_shuffle_epi8(range_min_tbl, range); |
||||
__m128i maxv = _mm_shuffle_epi8(range_max_tbl, range); |
||||
|
||||
/* Check value range */ |
||||
#if RET_ERR_IDX |
||||
error = _mm_cmplt_epi8(input, minv); |
||||
error = _mm_or_si128(error, _mm_cmpgt_epi8(input, maxv)); |
||||
/* 5% performance drop from this conditional branch */ |
||||
if (!_mm_testz_si128(error, error)) |
||||
break; |
||||
#else |
||||
/* error |= (input < minv) | (input > maxv) */ |
||||
tmp = _mm_or_si128( |
||||
_mm_cmplt_epi8(input, minv), |
||||
_mm_cmpgt_epi8(input, maxv) |
||||
); |
||||
error = _mm_or_si128(error, tmp); |
||||
#endif |
||||
|
||||
prev_input = input; |
||||
prev_first_len = first_len; |
||||
|
||||
data += 16; |
||||
len -= 16; |
||||
#if RET_ERR_IDX |
||||
err_pos += 16; |
||||
#endif |
||||
} |
||||
|
||||
#if RET_ERR_IDX |
||||
/* Error in first 16 bytes */ |
||||
if (err_pos == 1) |
||||
goto do_naive; |
||||
#else |
||||
if (!_mm_testz_si128(error, error)) |
||||
return -1; |
||||
#endif |
||||
|
||||
/* Find previous token (not 80~BF) */ |
||||
int32_t token4 = _mm_extract_epi32(prev_input, 3); |
||||
const int8_t *token = (const int8_t *)&token4; |
||||
int lookahead = 0; |
||||
if (token[3] > (int8_t)0xBF) |
||||
lookahead = 1; |
||||
else if (token[2] > (int8_t)0xBF) |
||||
lookahead = 2; |
||||
else if (token[1] > (int8_t)0xBF) |
||||
lookahead = 3; |
||||
|
||||
data -= lookahead; |
||||
len += lookahead; |
||||
#if RET_ERR_IDX |
||||
err_pos -= lookahead; |
||||
#endif |
||||
} |
||||
|
||||
/* Check remaining bytes with naive method */ |
||||
#if RET_ERR_IDX |
||||
int err_pos2; |
||||
do_naive: |
||||
err_pos2 = utf8_naive(data, len); |
||||
if (err_pos2) |
||||
return err_pos + err_pos2 - 1; |
||||
return 0; |
||||
#else |
||||
return utf8_naive(data, len); |
||||
#endif |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,157 @@ |
||||
/*
|
||||
* Process 2x16 bytes in each iteration. |
||||
* Comments removed for brevity. See range-neon.c for details. |
||||
*/ |
||||
#ifdef __aarch64__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stdint.h> |
||||
#include <arm_neon.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
|
||||
static const uint8_t _first_len_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
}; |
||||
|
||||
static const uint8_t _first_range_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
}; |
||||
|
||||
static const uint8_t _range_min_tbl[] = { |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, |
||||
}; |
||||
static const uint8_t _range_max_tbl[] = { |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, |
||||
}; |
||||
|
||||
static const uint8_t _range_adjust_tbl[] = { |
||||
2, 3, 0, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, |
||||
}; |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_range2(const unsigned char *data, int len) |
||||
{ |
||||
if (len >= 32) { |
||||
uint8x16_t prev_input = vdupq_n_u8(0); |
||||
uint8x16_t prev_first_len = vdupq_n_u8(0); |
||||
|
||||
const uint8x16_t first_len_tbl = vld1q_u8(_first_len_tbl); |
||||
const uint8x16_t first_range_tbl = vld1q_u8(_first_range_tbl); |
||||
const uint8x16_t range_min_tbl = vld1q_u8(_range_min_tbl); |
||||
const uint8x16_t range_max_tbl = vld1q_u8(_range_max_tbl); |
||||
const uint8x16x2_t range_adjust_tbl = vld2q_u8(_range_adjust_tbl); |
||||
|
||||
const uint8x16_t const_1 = vdupq_n_u8(1); |
||||
const uint8x16_t const_2 = vdupq_n_u8(2); |
||||
const uint8x16_t const_e0 = vdupq_n_u8(0xE0); |
||||
|
||||
uint8x16_t error1 = vdupq_n_u8(0); |
||||
uint8x16_t error2 = vdupq_n_u8(0); |
||||
uint8x16_t error3 = vdupq_n_u8(0); |
||||
uint8x16_t error4 = vdupq_n_u8(0); |
||||
|
||||
while (len >= 32) { |
||||
/******************* two blocks interleaved **********************/ |
||||
|
||||
#if defined(__GNUC__) && !defined(__clang__) && (__GNUC__ < 8) |
||||
/* gcc doesn't support vldq1_u8_x2 until version 8 */ |
||||
const uint8x16_t input_a = vld1q_u8(data); |
||||
const uint8x16_t input_b = vld1q_u8(data + 16); |
||||
#else |
||||
/* Forces a double load on Clang */ |
||||
const uint8x16x2_t input_pair = vld1q_u8_x2(data); |
||||
const uint8x16_t input_a = input_pair.val[0]; |
||||
const uint8x16_t input_b = input_pair.val[1]; |
||||
#endif |
||||
|
||||
const uint8x16_t high_nibbles_a = vshrq_n_u8(input_a, 4); |
||||
const uint8x16_t high_nibbles_b = vshrq_n_u8(input_b, 4); |
||||
|
||||
const uint8x16_t first_len_a = |
||||
vqtbl1q_u8(first_len_tbl, high_nibbles_a); |
||||
const uint8x16_t first_len_b = |
||||
vqtbl1q_u8(first_len_tbl, high_nibbles_b); |
||||
|
||||
uint8x16_t range_a = vqtbl1q_u8(first_range_tbl, high_nibbles_a); |
||||
uint8x16_t range_b = vqtbl1q_u8(first_range_tbl, high_nibbles_b); |
||||
|
||||
range_a = |
||||
vorrq_u8(range_a, vextq_u8(prev_first_len, first_len_a, 15)); |
||||
range_b = |
||||
vorrq_u8(range_b, vextq_u8(first_len_a, first_len_b, 15)); |
||||
|
||||
uint8x16_t tmp1_a, tmp2_a, tmp1_b, tmp2_b; |
||||
tmp1_a = vextq_u8(prev_first_len, first_len_a, 14); |
||||
tmp1_a = vqsubq_u8(tmp1_a, const_1); |
||||
range_a = vorrq_u8(range_a, tmp1_a); |
||||
|
||||
tmp1_b = vextq_u8(first_len_a, first_len_b, 14); |
||||
tmp1_b = vqsubq_u8(tmp1_b, const_1); |
||||
range_b = vorrq_u8(range_b, tmp1_b); |
||||
|
||||
tmp2_a = vextq_u8(prev_first_len, first_len_a, 13); |
||||
tmp2_a = vqsubq_u8(tmp2_a, const_2); |
||||
range_a = vorrq_u8(range_a, tmp2_a); |
||||
|
||||
tmp2_b = vextq_u8(first_len_a, first_len_b, 13); |
||||
tmp2_b = vqsubq_u8(tmp2_b, const_2); |
||||
range_b = vorrq_u8(range_b, tmp2_b); |
||||
|
||||
uint8x16_t shift1_a = vextq_u8(prev_input, input_a, 15); |
||||
uint8x16_t pos_a = vsubq_u8(shift1_a, const_e0); |
||||
range_a = vaddq_u8(range_a, vqtbl2q_u8(range_adjust_tbl, pos_a)); |
||||
|
||||
uint8x16_t shift1_b = vextq_u8(input_a, input_b, 15); |
||||
uint8x16_t pos_b = vsubq_u8(shift1_b, const_e0); |
||||
range_b = vaddq_u8(range_b, vqtbl2q_u8(range_adjust_tbl, pos_b)); |
||||
|
||||
uint8x16_t minv_a = vqtbl1q_u8(range_min_tbl, range_a); |
||||
uint8x16_t maxv_a = vqtbl1q_u8(range_max_tbl, range_a); |
||||
|
||||
uint8x16_t minv_b = vqtbl1q_u8(range_min_tbl, range_b); |
||||
uint8x16_t maxv_b = vqtbl1q_u8(range_max_tbl, range_b); |
||||
|
||||
error1 = vorrq_u8(error1, vcltq_u8(input_a, minv_a)); |
||||
error2 = vorrq_u8(error2, vcgtq_u8(input_a, maxv_a)); |
||||
|
||||
error3 = vorrq_u8(error3, vcltq_u8(input_b, minv_b)); |
||||
error4 = vorrq_u8(error4, vcgtq_u8(input_b, maxv_b)); |
||||
|
||||
/************************ next iteration *************************/ |
||||
prev_input = input_b; |
||||
prev_first_len = first_len_b; |
||||
|
||||
data += 32; |
||||
len -= 32; |
||||
} |
||||
error1 = vorrq_u8(error1, error2); |
||||
error1 = vorrq_u8(error1, error3); |
||||
error1 = vorrq_u8(error1, error4); |
||||
|
||||
if (vmaxvq_u8(error1)) |
||||
return -1; |
||||
|
||||
uint32_t token4; |
||||
vst1q_lane_u32(&token4, vreinterpretq_u32_u8(prev_input), 3); |
||||
|
||||
const int8_t *token = (const int8_t *)&token4; |
||||
int lookahead = 0; |
||||
if (token[3] > (int8_t)0xBF) |
||||
lookahead = 1; |
||||
else if (token[2] > (int8_t)0xBF) |
||||
lookahead = 2; |
||||
else if (token[1] > (int8_t)0xBF) |
||||
lookahead = 3; |
||||
|
||||
data -= lookahead; |
||||
len += lookahead; |
||||
} |
||||
|
||||
return utf8_naive(data, len); |
||||
} |
||||
|
||||
#endif |
||||
@ -0,0 +1,170 @@ |
||||
/*
|
||||
* Process 2x16 bytes in each iteration. |
||||
* Comments removed for brevity. See range-sse.c for details. |
||||
*/ |
||||
#ifdef __SSE4_1__ |
||||
|
||||
#include <stdio.h> |
||||
#include <stdint.h> |
||||
#include <x86intrin.h> |
||||
|
||||
int utf8_naive(const unsigned char *data, int len); |
||||
|
||||
static const int8_t _first_len_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3, |
||||
}; |
||||
|
||||
static const int8_t _first_range_tbl[] = { |
||||
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8, |
||||
}; |
||||
|
||||
static const int8_t _range_min_tbl[] = { |
||||
0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, |
||||
0xC2, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F, |
||||
}; |
||||
static const int8_t _range_max_tbl[] = { |
||||
0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, |
||||
0xF4, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, 0x80, |
||||
}; |
||||
|
||||
static const int8_t _df_ee_tbl[] = { |
||||
0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0, |
||||
}; |
||||
static const int8_t _ef_fe_tbl[] = { |
||||
0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, |
||||
}; |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
int utf8_range2(const unsigned char *data, int len) |
||||
{ |
||||
if (len >= 32) { |
||||
__m128i prev_input = _mm_set1_epi8(0); |
||||
__m128i prev_first_len = _mm_set1_epi8(0); |
||||
|
||||
const __m128i first_len_tbl = |
||||
_mm_loadu_si128((const __m128i *)_first_len_tbl); |
||||
const __m128i first_range_tbl = |
||||
_mm_loadu_si128((const __m128i *)_first_range_tbl); |
||||
const __m128i range_min_tbl = |
||||
_mm_loadu_si128((const __m128i *)_range_min_tbl); |
||||
const __m128i range_max_tbl = |
||||
_mm_loadu_si128((const __m128i *)_range_max_tbl); |
||||
const __m128i df_ee_tbl = |
||||
_mm_loadu_si128((const __m128i *)_df_ee_tbl); |
||||
const __m128i ef_fe_tbl = |
||||
_mm_loadu_si128((const __m128i *)_ef_fe_tbl); |
||||
|
||||
__m128i error = _mm_set1_epi8(0); |
||||
|
||||
while (len >= 32) { |
||||
/***************************** block 1 ****************************/ |
||||
const __m128i input_a = _mm_loadu_si128((const __m128i *)data); |
||||
|
||||
__m128i high_nibbles = |
||||
_mm_and_si128(_mm_srli_epi16(input_a, 4), _mm_set1_epi8(0x0F)); |
||||
|
||||
__m128i first_len_a = _mm_shuffle_epi8(first_len_tbl, high_nibbles); |
||||
|
||||
__m128i range_a = _mm_shuffle_epi8(first_range_tbl, high_nibbles); |
||||
|
||||
range_a = _mm_or_si128( |
||||
range_a, _mm_alignr_epi8(first_len_a, prev_first_len, 15)); |
||||
|
||||
__m128i tmp; |
||||
tmp = _mm_alignr_epi8(first_len_a, prev_first_len, 14); |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(1)); |
||||
range_a = _mm_or_si128(range_a, tmp); |
||||
|
||||
tmp = _mm_alignr_epi8(first_len_a, prev_first_len, 13); |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(2)); |
||||
range_a = _mm_or_si128(range_a, tmp); |
||||
|
||||
__m128i shift1, pos, range2; |
||||
shift1 = _mm_alignr_epi8(input_a, prev_input, 15); |
||||
pos = _mm_sub_epi8(shift1, _mm_set1_epi8(0xEF)); |
||||
tmp = _mm_subs_epu8(pos, _mm_set1_epi8(0xF0)); |
||||
range2 = _mm_shuffle_epi8(df_ee_tbl, tmp); |
||||
tmp = _mm_adds_epu8(pos, _mm_set1_epi8(0x70)); |
||||
range2 = _mm_add_epi8(range2, _mm_shuffle_epi8(ef_fe_tbl, tmp)); |
||||
|
||||
range_a = _mm_add_epi8(range_a, range2); |
||||
|
||||
__m128i minv = _mm_shuffle_epi8(range_min_tbl, range_a); |
||||
__m128i maxv = _mm_shuffle_epi8(range_max_tbl, range_a); |
||||
|
||||
tmp = _mm_or_si128( |
||||
_mm_cmplt_epi8(input_a, minv), |
||||
_mm_cmpgt_epi8(input_a, maxv) |
||||
); |
||||
error = _mm_or_si128(error, tmp); |
||||
|
||||
/***************************** block 2 ****************************/ |
||||
const __m128i input_b = _mm_loadu_si128((const __m128i *)(data+16)); |
||||
|
||||
high_nibbles = |
||||
_mm_and_si128(_mm_srli_epi16(input_b, 4), _mm_set1_epi8(0x0F)); |
||||
|
||||
__m128i first_len_b = _mm_shuffle_epi8(first_len_tbl, high_nibbles); |
||||
|
||||
__m128i range_b = _mm_shuffle_epi8(first_range_tbl, high_nibbles); |
||||
|
||||
range_b = _mm_or_si128( |
||||
range_b, _mm_alignr_epi8(first_len_b, first_len_a, 15)); |
||||
|
||||
|
||||
tmp = _mm_alignr_epi8(first_len_b, first_len_a, 14); |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(1)); |
||||
range_b = _mm_or_si128(range_b, tmp); |
||||
|
||||
tmp = _mm_alignr_epi8(first_len_b, first_len_a, 13); |
||||
tmp = _mm_subs_epu8(tmp, _mm_set1_epi8(2)); |
||||
range_b = _mm_or_si128(range_b, tmp); |
||||
|
||||
shift1 = _mm_alignr_epi8(input_b, input_a, 15); |
||||
pos = _mm_sub_epi8(shift1, _mm_set1_epi8(0xEF)); |
||||
tmp = _mm_subs_epu8(pos, _mm_set1_epi8(0xF0)); |
||||
range2 = _mm_shuffle_epi8(df_ee_tbl, tmp); |
||||
tmp = _mm_adds_epu8(pos, _mm_set1_epi8(0x70)); |
||||
range2 = _mm_add_epi8(range2, _mm_shuffle_epi8(ef_fe_tbl, tmp)); |
||||
|
||||
range_b = _mm_add_epi8(range_b, range2); |
||||
|
||||
minv = _mm_shuffle_epi8(range_min_tbl, range_b); |
||||
maxv = _mm_shuffle_epi8(range_max_tbl, range_b); |
||||
|
||||
|
||||
tmp = _mm_or_si128( |
||||
_mm_cmplt_epi8(input_b, minv), |
||||
_mm_cmpgt_epi8(input_b, maxv) |
||||
); |
||||
error = _mm_or_si128(error, tmp); |
||||
|
||||
/************************ next iteration **************************/ |
||||
prev_input = input_b; |
||||
prev_first_len = first_len_b; |
||||
|
||||
data += 32; |
||||
len -= 32; |
||||
} |
||||
|
||||
if (!_mm_testz_si128(error, error)) |
||||
return -1; |
||||
|
||||
int32_t token4 = _mm_extract_epi32(prev_input, 3); |
||||
const int8_t *token = (const int8_t *)&token4; |
||||
int lookahead = 0; |
||||
if (token[3] > (int8_t)0xBF) |
||||
lookahead = 1; |
||||
else if (token[2] > (int8_t)0xBF) |
||||
lookahead = 2; |
||||
else if (token[1] > (int8_t)0xBF) |
||||
lookahead = 3; |
||||
|
||||
data -= lookahead; |
||||
len += lookahead; |
||||
} |
||||
|
||||
return utf8_naive(data, len); |
||||
} |
||||
|
||||
#endif |
||||
Binary file not shown.
@ -0,0 +1,21 @@ |
||||
#ifndef THIRD_PARTY_UTF8_RANGE_UTF8_RANGE_H_ |
||||
#define THIRD_PARTY_UTF8_RANGE_UTF8_RANGE_H_ |
||||
|
||||
#ifdef __cplusplus |
||||
extern "C" { |
||||
#endif |
||||
|
||||
#if (defined(__ARM_NEON) && defined(__aarch64__)) || defined(__SSE4_1__) |
||||
int utf8_range2(const unsigned char* data, int len); |
||||
#else |
||||
int utf8_naive(const unsigned char* data, int len); |
||||
static inline int utf8_range2(const unsigned char* data, int len) { |
||||
return utf8_naive(data, len); |
||||
} |
||||
#endif |
||||
|
||||
#ifdef __cplusplus |
||||
} // extern "C"
|
||||
#endif |
||||
|
||||
#endif // THIRD_PARTY_UTF8_RANGE_UTF8_RANGE_H_
|
||||
@ -0,0 +1,11 @@ |
||||
CC = gcc
|
||||
CPPFLAGS = -g -O3 -Wall -march=native
|
||||
|
||||
OBJS = main.o iconv.o naive.o
|
||||
|
||||
utf8to16: ${OBJS} |
||||
gcc $^ -o $@
|
||||
|
||||
.PHONY: clean |
||||
clean: |
||||
rm -f utf8to16 *.o
|
||||
@ -0,0 +1,51 @@ |
||||
#include <stdio.h> |
||||
#include <stdlib.h> |
||||
#include <errno.h> |
||||
#include <iconv.h> |
||||
|
||||
static iconv_t s_cd; |
||||
|
||||
/* Call iconv_open only once so the benchmark will be faster? */ |
||||
static void __attribute__ ((constructor)) init_iconv(void) |
||||
{ |
||||
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__ |
||||
s_cd = iconv_open("UTF-16LE", "UTF-8"); |
||||
#else |
||||
s_cd = iconv_open("UTF-16BE", "UTF-8"); |
||||
#endif |
||||
if (s_cd == (iconv_t)-1) { |
||||
perror("iconv_open"); |
||||
exit(1); |
||||
} |
||||
} |
||||
|
||||
/*
|
||||
* Parameters: |
||||
* - buf8, len8: input utf-8 string |
||||
* - buf16: buffer to store decoded utf-16 string |
||||
* - *len16: on entry - utf-16 buffer length in bytes |
||||
* on exit - length in bytes of valid decoded utf-16 string |
||||
* Returns: |
||||
* - 0: success |
||||
* - >0: error position of input utf-8 string |
||||
* - -1: utf-16 buffer overflow |
||||
* LE/BE depends on host |
||||
*/ |
||||
int utf8_to16_iconv(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t *len16) |
||||
{ |
||||
size_t ret, len16_save = *len16; |
||||
const unsigned char *buf8_0 = buf8; |
||||
|
||||
ret = iconv(s_cd, (char **)&buf8, &len8, (char **)&buf16, len16); |
||||
|
||||
*len16 = len16_save - *len16; |
||||
|
||||
if (ret != (size_t)-1) |
||||
return 0; |
||||
|
||||
if (errno == E2BIG) |
||||
return -1; /* Output buffer full */ |
||||
|
||||
return buf8 - buf8_0 + 1; /* EILSEQ, EINVAL, error position */ |
||||
} |
||||
@ -0,0 +1,424 @@ |
||||
#include <stdio.h> |
||||
#include <stdlib.h> |
||||
#include <string.h> |
||||
#include <inttypes.h> |
||||
#include <sys/types.h> |
||||
#include <sys/stat.h> |
||||
#include <sys/time.h> |
||||
#include <fcntl.h> |
||||
#include <unistd.h> |
||||
|
||||
int utf8_to16_iconv(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t *len16); |
||||
int utf8_to16_naive(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t *len16); |
||||
|
||||
static struct ftab { |
||||
const char *name; |
||||
int (*func)(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t *len16); |
||||
} ftab[] = { |
||||
{ |
||||
.name = "iconv", |
||||
.func = utf8_to16_iconv, |
||||
}, { |
||||
.name = "naive", |
||||
.func = utf8_to16_naive, |
||||
}, |
||||
}; |
||||
|
||||
static unsigned char *load_test_buf(int len) |
||||
{ |
||||
const char utf8[] = "\xF0\x90\xBF\x80"; |
||||
const int utf8_len = sizeof(utf8)/sizeof(utf8[0]) - 1; |
||||
|
||||
unsigned char *data = malloc(len); |
||||
unsigned char *p = data; |
||||
|
||||
while (len >= utf8_len) { |
||||
memcpy(p, utf8, utf8_len); |
||||
p += utf8_len; |
||||
len -= utf8_len; |
||||
} |
||||
|
||||
while (len--) |
||||
*p++ = 0x7F; |
||||
|
||||
return data; |
||||
} |
||||
|
||||
static unsigned char *load_test_file(int *len) |
||||
{ |
||||
unsigned char *data; |
||||
int fd; |
||||
struct stat stat; |
||||
|
||||
fd = open("../UTF-8-demo.txt", O_RDONLY); |
||||
if (fd == -1) { |
||||
printf("Failed to open ../UTF-8-demo.txt!\n"); |
||||
exit(1); |
||||
} |
||||
if (fstat(fd, &stat) == -1) { |
||||
printf("Failed to get file size!\n"); |
||||
exit(1); |
||||
} |
||||
|
||||
*len = stat.st_size; |
||||
data = malloc(*len); |
||||
if (read(fd, data, *len) != *len) { |
||||
printf("Failed to read file!\n"); |
||||
exit(1); |
||||
} |
||||
|
||||
close(fd); |
||||
|
||||
return data; |
||||
} |
||||
|
||||
static void print_test(const unsigned char *data, int len) |
||||
{ |
||||
printf(" [len=%d] \"", len); |
||||
while (len--) |
||||
printf("\\x%02X", *data++); |
||||
|
||||
printf("\"\n"); |
||||
} |
||||
|
||||
struct test { |
||||
const unsigned char *data; |
||||
int len; |
||||
}; |
||||
|
||||
static void prepare_test_buf(unsigned char *buf, const struct test *pos, |
||||
int pos_len, int pos_idx) |
||||
{ |
||||
/* Round concatenate correct tokens to 1024 bytes */ |
||||
int buf_idx = 0; |
||||
while (buf_idx < 1024) { |
||||
int buf_len = 1024 - buf_idx; |
||||
|
||||
if (buf_len >= pos[pos_idx].len) { |
||||
memcpy(buf+buf_idx, pos[pos_idx].data, pos[pos_idx].len); |
||||
buf_idx += pos[pos_idx].len; |
||||
} else { |
||||
memset(buf+buf_idx, 0, buf_len); |
||||
buf_idx += buf_len; |
||||
} |
||||
|
||||
if (++pos_idx == pos_len) |
||||
pos_idx = 0; |
||||
} |
||||
} |
||||
|
||||
/* Return 0 on success, -1 on error */ |
||||
static int test_manual(const struct ftab *ftab, unsigned short *buf16, |
||||
unsigned short *_buf16) |
||||
{ |
||||
#define LEN16 4096 |
||||
|
||||
#pragma GCC diagnostic push |
||||
#pragma GCC diagnostic ignored "-Wpointer-sign" |
||||
/* positive tests */ |
||||
static const struct test pos[] = { |
||||
{"", 0}, |
||||
{"\x00", 1}, |
||||
{"\x66", 1}, |
||||
{"\x7F", 1}, |
||||
{"\x00\x7F", 2}, |
||||
{"\x7F\x00", 2}, |
||||
{"\xC2\x80", 2}, |
||||
{"\xDF\xBF", 2}, |
||||
{"\xE0\xA0\x80", 3}, |
||||
{"\xE0\xA0\xBF", 3}, |
||||
{"\xED\x9F\x80", 3}, |
||||
{"\xEF\x80\xBF", 3}, |
||||
{"\xF0\x90\xBF\x80", 4}, |
||||
{"\xF2\x81\xBE\x99", 4}, |
||||
{"\xF4\x8F\x88\xAA", 4}, |
||||
}; |
||||
|
||||
/* negative tests */ |
||||
static const struct test neg[] = { |
||||
{"\x80", 1}, |
||||
{"\xBF", 1}, |
||||
{"\xC0\x80", 2}, |
||||
{"\xC1\x00", 2}, |
||||
{"\xC2\x7F", 2}, |
||||
{"\xDF\xC0", 2}, |
||||
{"\xE0\x9F\x80", 3}, |
||||
{"\xE0\xC2\x80", 3}, |
||||
{"\xED\xA0\x80", 3}, |
||||
{"\xED\x7F\x80", 3}, |
||||
{"\xEF\x80\x00", 3}, |
||||
{"\xF0\x8F\x80\x80", 4}, |
||||
{"\xF0\xEE\x80\x80", 4}, |
||||
{"\xF2\x90\x91\x7F", 4}, |
||||
{"\xF4\x90\x88\xAA", 4}, |
||||
{"\xF4\x00\xBF\xBF", 4}, |
||||
{"\x00\x00\x00\x00\x00\xC2\x80\x00\x00\x00\xE1\x80\x80\x00\x00\xC2" \
|
||||
"\xC2\x80\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\xC2\xC2\x80\x00\x00\xE1\x80\x80\x00\x00\x00", |
||||
16}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1", |
||||
32}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80" \
|
||||
"\x80", 33}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF1\x80" \
|
||||
"\xC2\x80", 34}, |
||||
{"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00" \
|
||||
"\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xF0" \
|
||||
"\x80\x80\x80", 35}, |
||||
}; |
||||
#pragma GCC diagnostic push |
||||
|
||||
size_t len16 = LEN16, _len16 = LEN16; |
||||
int ret, _ret; |
||||
|
||||
/* Test single token */ |
||||
for (int i = 0; i < sizeof(pos)/sizeof(pos[0]); ++i) { |
||||
ret = ftab->func(pos[i].data, pos[i].len, buf16, &len16); |
||||
_ret = utf8_to16_iconv(pos[i].data, pos[i].len, _buf16, &_len16); |
||||
if (ret != _ret || len16 != _len16 || memcmp(buf16, _buf16, len16)) { |
||||
printf("FAILED positive test(%d:%d, %lu:%lu): ", |
||||
ret, _ret, len16, _len16); |
||||
print_test(pos[i].data, pos[i].len); |
||||
return -1; |
||||
} |
||||
len16 = _len16 = LEN16; |
||||
} |
||||
for (int i = 0; i < sizeof(neg)/sizeof(neg[0]); ++i) { |
||||
ret = ftab->func(neg[i].data, neg[i].len, buf16, &len16); |
||||
_ret = utf8_to16_iconv(neg[i].data, neg[i].len, _buf16, &_len16); |
||||
if (ret != _ret || len16 != _len16 || memcmp(buf16, _buf16, len16)) { |
||||
printf("FAILED negitive test(%d:%d, %lu:%lu): ", |
||||
ret, _ret, len16, _len16); |
||||
print_test(neg[i].data, neg[i].len); |
||||
return -1; |
||||
} |
||||
len16 = _len16 = LEN16; |
||||
} |
||||
|
||||
/* Test shifted buffer to cover 1k length */ |
||||
/* buffer size must be greater than 1024 + 16 + max(test string length) */ |
||||
const int max_size = 1024*2; |
||||
uint64_t buf64[max_size/8 + 2]; |
||||
/* Offset 8 bytes by 1 byte */ |
||||
unsigned char *buf = ((unsigned char *)buf64) + 1; |
||||
int buf_len; |
||||
|
||||
for (int i = 0; i < sizeof(pos)/sizeof(pos[0]); ++i) { |
||||
/* Positive test: shift 16 bytes, validate each shift */ |
||||
prepare_test_buf(buf, pos, sizeof(pos)/sizeof(pos[0]), i); |
||||
buf_len = 1024; |
||||
for (int j = 0; j < 16; ++j) { |
||||
ret = ftab->func(buf, buf_len, buf16, &len16); |
||||
_ret = utf8_to16_iconv(buf, buf_len, _buf16, &_len16); |
||||
if (ret != _ret || len16 != _len16 || \
|
||||
memcmp(buf16, _buf16, len16)) { |
||||
printf("FAILED positive test(%d:%d, %lu:%lu): ", |
||||
ret, _ret, len16, _len16); |
||||
print_test(buf, buf_len); |
||||
return -1; |
||||
} |
||||
len16 = _len16 = LEN16; |
||||
for (int k = buf_len; k >= 1; --k) |
||||
buf[k] = buf[k-1]; |
||||
buf[0] = '\x55'; |
||||
++buf_len; |
||||
} |
||||
|
||||
/* Negative test: trunk last non ascii */ |
||||
while (buf_len >= 1 && buf[buf_len-1] <= 0x7F) |
||||
--buf_len; |
||||
if (buf_len) { |
||||
ret = ftab->func(buf, buf_len-1, buf16, &len16); |
||||
_ret = utf8_to16_iconv(buf, buf_len-1, _buf16, &_len16); |
||||
if (ret != _ret || len16 != _len16 || \
|
||||
memcmp(buf16, _buf16, len16)) { |
||||
printf("FAILED negative test(%d:%d, %lu:%lu): ", |
||||
ret, _ret, len16, _len16); |
||||
print_test(buf, buf_len-1); |
||||
return -1; |
||||
} |
||||
len16 = _len16 = LEN16; |
||||
} |
||||
} |
||||
|
||||
/* Negative test */ |
||||
for (int i = 0; i < sizeof(neg)/sizeof(neg[0]); ++i) { |
||||
/* Append one error token, shift 16 bytes, validate each shift */ |
||||
int pos_idx = i % (sizeof(pos)/sizeof(pos[0])); |
||||
prepare_test_buf(buf, pos, sizeof(pos)/sizeof(pos[0]), pos_idx); |
||||
memcpy(buf+1024, neg[i].data, neg[i].len); |
||||
buf_len = 1024 + neg[i].len; |
||||
for (int j = 0; j < 16; ++j) { |
||||
ret = ftab->func(buf, buf_len, buf16, &len16); |
||||
_ret = utf8_to16_iconv(buf, buf_len, _buf16, &_len16); |
||||
if (ret != _ret || len16 != _len16 || \
|
||||
memcmp(buf16, _buf16, len16)) { |
||||
printf("FAILED negative test(%d:%d, %lu:%lu): ", |
||||
ret, _ret, len16, _len16); |
||||
print_test(buf, buf_len); |
||||
return -1; |
||||
} |
||||
len16 = _len16 = LEN16; |
||||
for (int k = buf_len; k >= 1; --k) |
||||
buf[k] = buf[k-1]; |
||||
buf[0] = '\x66'; |
||||
++buf_len; |
||||
} |
||||
} |
||||
|
||||
return 0; |
||||
} |
||||
|
||||
static void test(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t len16, const struct ftab *ftab) |
||||
{ |
||||
/* Use iconv as the reference answer */ |
||||
if (strcmp(ftab->name, "iconv") == 0) |
||||
return; |
||||
|
||||
printf("%s\n", ftab->name); |
||||
|
||||
/* Test file or buffer */ |
||||
size_t _len16 = len16; |
||||
unsigned short *_buf16 = (unsigned short *)malloc(_len16); |
||||
if (utf8_to16_iconv(buf8, len8, _buf16, &_len16)) { |
||||
printf("Invalid test file or buffer!\n"); |
||||
exit(1); |
||||
} |
||||
printf("standard test: "); |
||||
if (ftab->func(buf8, len8, buf16, &len16) || len16 != _len16 || \
|
||||
memcmp(buf16, _buf16, len16) != 0) |
||||
printf("FAIL\n"); |
||||
else |
||||
printf("pass\n"); |
||||
free(_buf16); |
||||
|
||||
/* Manual cases */ |
||||
unsigned short *mbuf8 = (unsigned short *)malloc(LEN16); |
||||
unsigned short *mbuf16 = (unsigned short *)malloc(LEN16); |
||||
printf("manual test: %s\n", |
||||
test_manual(ftab, mbuf8, mbuf16) ? "FAIL" : "pass"); |
||||
free(mbuf8); |
||||
free(mbuf16); |
||||
printf("\n"); |
||||
} |
||||
|
||||
static void bench(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t len16, const struct ftab *ftab) |
||||
{ |
||||
const int loops = 1024*1024*1024/len8; |
||||
int ret = 0; |
||||
double time, size; |
||||
struct timeval tv1, tv2; |
||||
|
||||
fprintf(stderr, "bench %s... ", ftab->name); |
||||
gettimeofday(&tv1, 0); |
||||
for (int i = 0; i < loops; ++i) |
||||
ret |= ftab->func(buf8, len8, buf16, &len16); |
||||
gettimeofday(&tv2, 0); |
||||
printf("%s\n", ret?"FAIL":"pass"); |
||||
|
||||
time = tv2.tv_usec - tv1.tv_usec; |
||||
time = time / 1000000 + tv2.tv_sec - tv1.tv_sec; |
||||
size = ((double)len8 * loops) / (1024*1024); |
||||
printf("time: %.4f s\n", time); |
||||
printf("data: %.0f MB\n", size); |
||||
printf("BW: %.2f MB/s\n", size / time); |
||||
printf("\n"); |
||||
} |
||||
|
||||
static void usage(const char *bin) |
||||
{ |
||||
printf("Usage:\n"); |
||||
printf("%s test [alg] ==> test all or one algorithm\n", bin); |
||||
printf("%s bench [alg] ==> benchmark all or one algorithm\n", bin); |
||||
printf("%s bench size NUM ==> benchmark with specific buffer size\n", bin); |
||||
printf("alg = "); |
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) |
||||
printf("%s ", ftab[i].name); |
||||
printf("\nNUM = buffer size in bytes, 1 ~ 67108864(64M)\n"); |
||||
} |
||||
|
||||
int main(int argc, char *argv[]) |
||||
{ |
||||
int len8 = 0, len16; |
||||
unsigned char *buf8; |
||||
unsigned short *buf16; |
||||
const char *alg = NULL; |
||||
void (*tb)(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t len16, const struct ftab *ftab); |
||||
|
||||
tb = NULL; |
||||
if (argc >= 2) { |
||||
if (strcmp(argv[1], "test") == 0) |
||||
tb = test; |
||||
else if (strcmp(argv[1], "bench") == 0) |
||||
tb = bench; |
||||
if (argc >= 3) { |
||||
alg = argv[2]; |
||||
if (strcmp(alg, "size") == 0) { |
||||
if (argc < 4) { |
||||
tb = NULL; |
||||
} else { |
||||
alg = NULL; |
||||
len8 = atoi(argv[3]); |
||||
if (len8 <= 0 || len8 > 67108864) { |
||||
printf("Buffer size error!\n\n"); |
||||
tb = NULL; |
||||
} |
||||
} |
||||
} |
||||
} |
||||
} |
||||
|
||||
if (tb == NULL) { |
||||
usage(argv[0]); |
||||
return 1; |
||||
} |
||||
|
||||
/* Load UTF8 test buffer */ |
||||
if (len8) |
||||
buf8 = load_test_buf(len8); |
||||
else |
||||
buf8 = load_test_file(&len8); |
||||
|
||||
/* Prepare UTF16 buffer large enough */ |
||||
len16 = len8 * 2; |
||||
buf16 = (unsigned short *)malloc(len16); |
||||
|
||||
if (tb == bench) |
||||
printf("============== Bench UTF8 (%d bytes) ==============\n", len8); |
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) { |
||||
if (alg && strcmp(alg, ftab[i].name) != 0) |
||||
continue; |
||||
tb((const unsigned char *)buf8, len8, buf16, len16, &ftab[i]); |
||||
} |
||||
|
||||
#if 0 |
||||
if (tb == bench) { |
||||
printf("==================== Bench ASCII ====================\n"); |
||||
/* Change test buffer to ascii */ |
||||
for (int i = 0; i < len; i++) |
||||
data[i] &= 0x7F; |
||||
|
||||
for (int i = 0; i < sizeof(ftab)/sizeof(ftab[0]); ++i) { |
||||
if (alg && strcmp(alg, ftab[i].name) != 0) |
||||
continue; |
||||
tb((const unsigned char *)data, len, &ftab[i]); |
||||
printf("\n"); |
||||
} |
||||
} |
||||
#endif |
||||
|
||||
return 0; |
||||
} |
||||
@ -0,0 +1,133 @@ |
||||
#include <stdio.h> |
||||
|
||||
/*
|
||||
* UTF-8 to UTF-16 |
||||
* Table from https://woboq.com/blog/utf-8-processing-using-simd.html
|
||||
* |
||||
* +-------------------------------------+-------------------+ |
||||
* | UTF-8 | UTF-16LE (HI LO) | |
||||
* +-------------------------------------+-------------------+ |
||||
* | 0aaaaaaa | 00000000 0aaaaaaa | |
||||
* +-------------------------------------+-------------------+ |
||||
* | 110bbbbb 10aaaaaa | 00000bbb bbaaaaaa | |
||||
* +-------------------------------------+-------------------+ |
||||
* | 1110cccc 10bbbbbb 10aaaaaa | ccccbbbb bbaaaaaa | |
||||
* +-------------------------------------+-------------------+ |
||||
* | 11110ddd 10ddcccc 10bbbbbb 10aaaaaa | 110110uu uuccccbb | |
||||
* + uuuu = ddddd - 1 | 110111bb bbaaaaaa | |
||||
* +-------------------------------------+-------------------+ |
||||
*/ |
||||
|
||||
/*
|
||||
* Parameters: |
||||
* - buf8, len8: input utf-8 string |
||||
* - buf16: buffer to store decoded utf-16 string |
||||
* - *len16: on entry - utf-16 buffer length in bytes |
||||
* on exit - length in bytes of valid decoded utf-16 string |
||||
* Returns: |
||||
* - 0: success |
||||
* - >0: error position of input utf-8 string |
||||
* - -1: utf-16 buffer overflow |
||||
* LE/BE depends on host |
||||
*/ |
||||
int utf8_to16_naive(const unsigned char *buf8, size_t len8, |
||||
unsigned short *buf16, size_t *len16) |
||||
{ |
||||
int err_pos = 1; |
||||
size_t len16_left = *len16; |
||||
|
||||
*len16 = 0; |
||||
|
||||
while (len8) { |
||||
unsigned char b0, b1, b2, b3; |
||||
unsigned int u; |
||||
|
||||
/* Output buffer full */ |
||||
if (len16_left < 2) |
||||
return -1; |
||||
|
||||
/* 1st byte */ |
||||
b0 = buf8[0]; |
||||
|
||||
if ((b0 & 0x80) == 0) { |
||||
/* 0aaaaaaa -> 00000000 0aaaaaaa */ |
||||
*buf16++ = b0; |
||||
++buf8; |
||||
--len8; |
||||
++err_pos; |
||||
*len16 += 2; |
||||
len16_left -= 2; |
||||
continue; |
||||
} |
||||
|
||||
/* Character length */ |
||||
size_t clen = b0 & 0xF0; |
||||
clen >>= 4; /* 10xx, 110x, 1110, 1111 */ |
||||
clen -= 12; /* -4~-1, 0/1, 2, 3 */ |
||||
clen += !clen; /* -4~-1, 1, 2, 3 */ |
||||
|
||||
/* String too short or invalid 1st byte (10xxxxxx) */ |
||||
if (len8 <= clen) |
||||
return err_pos; |
||||
|
||||
/* Trailing bytes must be within 0x80 ~ 0xBF */ |
||||
b1 = buf8[1]; |
||||
if ((signed char)b1 >= (signed char)0xC0) |
||||
return err_pos; |
||||
b1 &= 0x3F; |
||||
|
||||
++clen; |
||||
if (clen == 2) { |
||||
u = b0 & 0x1F; |
||||
u <<= 6; |
||||
u |= b1; |
||||
if (u <= 0x7F) |
||||
return err_pos; |
||||
*buf16++ = u; |
||||
} else { |
||||
b2 = buf8[2]; |
||||
if ((signed char)b2 >= (signed char)0xC0) |
||||
return err_pos; |
||||
b2 &= 0x3F; |
||||
if (clen == 3) { |
||||
u = b0 & 0x0F; |
||||
u <<= 6; |
||||
u |= b1; |
||||
u <<= 6; |
||||
u |= b2; |
||||
if (u <= 0x7FF || (u >= 0xD800 && u <= 0xDFFF)) |
||||
return err_pos; |
||||
*buf16++ = u; |
||||
} else { |
||||
/* clen == 4 */ |
||||
if (len16_left < 4) |
||||
return -1; /* Output buffer full */ |
||||
b3 = buf8[3]; |
||||
if ((signed char)b3 >= (signed char)0xC0) |
||||
return err_pos; |
||||
u = b0 & 0x07; |
||||
u <<= 6; |
||||
u |= b1; |
||||
u <<= 6; |
||||
u |= b2; |
||||
u <<= 6; |
||||
u |= (b3 & 0x3F); |
||||
if (u <= 0xFFFF || u > 0x10FFFF) |
||||
return err_pos; |
||||
u -= 0x10000; |
||||
*buf16++ = (((u >> 10) & 0x3FF) | 0xD800); |
||||
*buf16++ = ((u & 0x3FF) | 0xDC00); |
||||
*len16 += 2; |
||||
len16_left -= 2; |
||||
} |
||||
} |
||||
|
||||
buf8 += clen; |
||||
len8 -= clen; |
||||
err_pos += clen; |
||||
*len16 += 2; |
||||
len16_left -= 2; |
||||
} |
||||
|
||||
return 0; |
||||
} |
||||
@ -0,0 +1,458 @@ |
||||
// Copyright 2022 Google LLC
|
||||
//
|
||||
// Use of this source code is governed by an MIT-style
|
||||
// license that can be found in the LICENSE file or at
|
||||
// https://opensource.org/licenses/MIT.
|
||||
|
||||
/* This is a wrapper for the Google range-sse.cc algorithm which checks whether a
|
||||
* sequence of bytes is a valid UTF-8 sequence and finds the longest valid prefix of |
||||
* the UTF-8 sequence. |
||||
* |
||||
* The key difference is that it checks for as much ASCII symbols as possible |
||||
* and then falls back to the range-sse.cc algorithm. The changes to the |
||||
* algorithm are cosmetic, mostly to trick the clang compiler to produce optimal |
||||
* code. |
||||
* |
||||
* For API see the utf8_validity.h header. |
||||
*/ |
||||
#include "utf8_validity.h" |
||||
|
||||
#include <cstddef> |
||||
#include <cstdint> |
||||
|
||||
#include "absl/strings/ascii.h" |
||||
#include "absl/strings/string_view.h" |
||||
|
||||
#ifdef __SSE4_1__ |
||||
#include <emmintrin.h> |
||||
#include <smmintrin.h> |
||||
#include <tmmintrin.h> |
||||
#endif |
||||
|
||||
namespace utf8_range { |
||||
namespace { |
||||
|
||||
inline uint64_t UNALIGNED_LOAD64(const void* p) { |
||||
uint64_t t; |
||||
memcpy(&t, p, sizeof t); |
||||
return t; |
||||
} |
||||
|
||||
inline bool TrailByteOk(const char c) { |
||||
return static_cast<int8_t>(c) <= static_cast<int8_t>(0xBF); |
||||
} |
||||
|
||||
/* If ReturnPosition is false then it returns 1 if |data| is a valid utf8
|
||||
* sequence, otherwise returns 0. |
||||
* If ReturnPosition is set to true, returns the length in bytes of the prefix |
||||
of |data| that is all structurally valid UTF-8. |
||||
*/ |
||||
template <bool ReturnPosition> |
||||
size_t ValidUTF8Span(const char* data, const char* end) { |
||||
/* We return err_pos in the loop which is always 0 if !ReturnPosition */ |
||||
size_t err_pos = 0; |
||||
size_t codepoint_bytes = 0; |
||||
/* The early check is done because of early continue's on codepoints of all
|
||||
* sizes, i.e. we first check for ascii and if it is, we call continue, then |
||||
* for 2 byte codepoints, etc. This is done in order to reduce indentation and |
||||
* improve readability of the codepoint validity check. |
||||
*/ |
||||
while (data + codepoint_bytes < end) { |
||||
if (ReturnPosition) { |
||||
err_pos += codepoint_bytes; |
||||
} |
||||
data += codepoint_bytes; |
||||
const size_t len = end - data; |
||||
const unsigned char byte1 = data[0]; |
||||
|
||||
/* We do not skip many ascii bytes at the same time as this function is
|
||||
used for tail checking (< 16 bytes) and for non x86 platforms. We also |
||||
don't think that cases where non-ASCII codepoints are followed by ascii |
||||
happen often. For small strings it also introduces some penalty. For |
||||
purely ascii UTF8 strings (which is the overwhelming case) we call |
||||
SkipAscii function which is multiplatform and extremely fast. |
||||
*/ |
||||
/* [00..7F] ASCII -> 1 byte */ |
||||
if (absl::ascii_isascii(byte1)) { |
||||
codepoint_bytes = 1; |
||||
continue; |
||||
} |
||||
/* [C2..DF], [80..BF] -> 2 bytes */ |
||||
if (len >= 2 && byte1 >= 0xC2 && byte1 <= 0xDF && TrailByteOk(data[1])) { |
||||
codepoint_bytes = 2; |
||||
continue; |
||||
} |
||||
if (len >= 3) { |
||||
const unsigned char byte2 = data[1]; |
||||
const unsigned char byte3 = data[2]; |
||||
|
||||
/* Is byte2, byte3 between [0x80, 0xBF]
|
||||
* Check for 0x80 was done above. |
||||
*/ |
||||
if (!TrailByteOk(byte2) || !TrailByteOk(byte3)) { |
||||
return err_pos; |
||||
} |
||||
|
||||
if (/* E0, A0..BF, 80..BF */ |
||||
((byte1 == 0xE0 && byte2 >= 0xA0) || |
||||
/* E1..EC, 80..BF, 80..BF */ |
||||
(byte1 >= 0xE1 && byte1 <= 0xEC) || |
||||
/* ED, 80..9F, 80..BF */ |
||||
(byte1 == 0xED && byte2 <= 0x9F) || |
||||
/* EE..EF, 80..BF, 80..BF */ |
||||
(byte1 >= 0xEE && byte1 <= 0xEF))) { |
||||
codepoint_bytes = 3; |
||||
continue; |
||||
} |
||||
if (len >= 4) { |
||||
const unsigned char byte4 = data[3]; |
||||
/* Is byte4 between 0x80 ~ 0xBF */ |
||||
if (!TrailByteOk(byte4)) { |
||||
return err_pos; |
||||
} |
||||
|
||||
if (/* F0, 90..BF, 80..BF, 80..BF */ |
||||
((byte1 == 0xF0 && byte2 >= 0x90) || |
||||
/* F1..F3, 80..BF, 80..BF, 80..BF */ |
||||
(byte1 >= 0xF1 && byte1 <= 0xF3) || |
||||
/* F4, 80..8F, 80..BF, 80..BF */ |
||||
(byte1 == 0xF4 && byte2 <= 0x8F))) { |
||||
codepoint_bytes = 4; |
||||
continue; |
||||
} |
||||
} |
||||
} |
||||
return err_pos; |
||||
} |
||||
if (ReturnPosition) { |
||||
err_pos += codepoint_bytes; |
||||
} |
||||
/* if ReturnPosition is false, this returns 1.
|
||||
* if ReturnPosition is true, this returns err_pos. |
||||
*/ |
||||
return err_pos + (1 - ReturnPosition); |
||||
} |
||||
|
||||
/* Returns the number of bytes needed to skip backwards to get to the first
|
||||
byte of codepoint. |
||||
*/ |
||||
inline int CodepointSkipBackwards(int32_t codepoint_word) { |
||||
const int8_t* const codepoint = |
||||
reinterpret_cast<const int8_t*>(&codepoint_word); |
||||
if (!TrailByteOk(codepoint[3])) { |
||||
return 1; |
||||
} else if (!TrailByteOk(codepoint[2])) { |
||||
return 2; |
||||
} else if (!TrailByteOk(codepoint[1])) { |
||||
return 3; |
||||
} |
||||
return 0; |
||||
} |
||||
|
||||
/* Skipping over ASCII as much as possible, per 8 bytes. It is intentional
|
||||
as most strings to check for validity consist only of 1 byte codepoints. |
||||
*/ |
||||
inline const char* SkipAscii(const char* data, const char* end) { |
||||
while (8 <= end - data && |
||||
(UNALIGNED_LOAD64(data) & 0x8080808080808080) == 0) { |
||||
data += 8; |
||||
} |
||||
while (data < end && absl::ascii_isascii(*data)) { |
||||
++data; |
||||
} |
||||
return data; |
||||
} |
||||
|
||||
template <bool ReturnPosition> |
||||
size_t ValidUTF8(const char* data, size_t len) { |
||||
if (len == 0) return 1 - ReturnPosition; |
||||
const char* const end = data + len; |
||||
data = SkipAscii(data, end); |
||||
/* SIMD algorithm always outperforms the naive version for any data of
|
||||
length >=16. |
||||
*/ |
||||
if (end - data < 16) { |
||||
return (ReturnPosition ? (data - (end - len)) : 0) + |
||||
ValidUTF8Span<ReturnPosition>(data, end); |
||||
} |
||||
#ifndef __SSE4_1__ |
||||
return (ReturnPosition ? (data - (end - len)) : 0) + |
||||
ValidUTF8Span<ReturnPosition>(data, end); |
||||
#else |
||||
/* This code checks that utf-8 ranges are structurally valid 16 bytes at once
|
||||
* using superscalar instructions. |
||||
* The mapping between ranges of codepoint and their corresponding utf-8 |
||||
* sequences is below. |
||||
*/ |
||||
|
||||
/*
|
||||
* U+0000...U+007F 00...7F |
||||
* U+0080...U+07FF C2...DF 80...BF |
||||
* U+0800...U+0FFF E0 A0...BF 80...BF |
||||
* U+1000...U+CFFF E1...EC 80...BF 80...BF |
||||
* U+D000...U+D7FF ED 80...9F 80...BF |
||||
* U+E000...U+FFFF EE...EF 80...BF 80...BF |
||||
* U+10000...U+3FFFF F0 90...BF 80...BF 80...BF |
||||
* U+40000...U+FFFFF F1...F3 80...BF 80...BF 80...BF |
||||
* U+100000...U+10FFFF F4 80...8F 80...BF 80...BF |
||||
*/ |
||||
|
||||
/* First we compute the type for each byte, as given by the table below.
|
||||
* This type will be used as an index later on. |
||||
*/ |
||||
|
||||
/*
|
||||
* Index Min Max Byte Type |
||||
* 0 00 7F Single byte sequence |
||||
* 1,2,3 80 BF Second, third and fourth byte for many of the sequences. |
||||
* 4 A0 BF Second byte after E0 |
||||
* 5 80 9F Second byte after ED |
||||
* 6 90 BF Second byte after F0 |
||||
* 7 80 8F Second byte after F4 |
||||
* 8 C2 F4 First non ASCII byte |
||||
* 9..15 7F 80 Invalid byte |
||||
*/ |
||||
|
||||
/* After the first step we compute the index for all bytes, then we permute
|
||||
the bytes according to their indices to check the ranges from the range |
||||
table. |
||||
* The range for a given type can be found in the range_min_table and |
||||
range_max_table, the range for type/index X is in range_min_table[X] ... |
||||
range_max_table[X]. |
||||
*/ |
||||
|
||||
/* Algorithm:
|
||||
* Put index zero to all bytes. |
||||
* Find all non ASCII characters, give them index 8. |
||||
* For each tail byte in a codepoint sequence, give it an index corresponding |
||||
to the 1 based index from the end. |
||||
* If the first byte of the codepoint is in the [C0...DF] range, we write |
||||
index 1 in the following byte. |
||||
* If the first byte of the codepoint is in the range [E0...EF], we write |
||||
indices 2 and 1 in the next two bytes. |
||||
* If the first byte of the codepoint is in the range [F0...FF] we write |
||||
indices 3,2,1 into the next three bytes. |
||||
* For finding the number of bytes we need to look at high nibbles (4 bits) |
||||
and do the lookup from the table, it can be done with shift by 4 + shuffle |
||||
instructions. We call it `first_len`. |
||||
* Then we shift first_len by 8 bits to get the indices of the 2nd bytes. |
||||
* Saturating sub 1 and shift by 8 bits to get the indices of the 3rd bytes. |
||||
* Again to get the indices of the 4th bytes. |
||||
* Take OR of all that 4 values and check within range. |
||||
*/ |
||||
/* For example:
|
||||
* input C3 80 68 E2 80 20 A6 F0 A0 80 AC 20 F0 93 80 80 |
||||
* first_len 1 0 0 2 0 0 0 3 0 0 0 0 3 0 0 0 |
||||
* 1st byte 8 0 0 8 0 0 0 8 0 0 0 0 8 0 0 0 |
||||
* 2nd byte 0 1 0 0 2 0 0 0 3 0 0 0 0 3 0 0 // Shift + sub
|
||||
* 3rd byte 0 0 0 0 0 1 0 0 0 2 0 0 0 0 2 0 // Shift + sub
|
||||
* 4th byte 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 // Shift + sub
|
||||
* Index 8 1 0 8 2 1 0 8 3 2 1 0 8 3 2 1 // OR of results
|
||||
*/ |
||||
|
||||
/* Checking for errors:
|
||||
* Error checking is done by looking up the high nibble (4 bits) of each byte |
||||
against an error checking table. |
||||
* Because the lookup value for the second byte depends of the value of the |
||||
first byte in codepoint, we use saturated operations to adjust the index. |
||||
* Specifically we need to add 2 for E0, 3 for ED, 3 for F0 and 4 for F4 to |
||||
match the correct index. |
||||
* If we subtract from all bytes EF then EO -> 241, ED -> 254, F0 -> 1, |
||||
F4 -> 5 |
||||
* Do saturating sub 240, then E0 -> 1, ED -> 14 and we can do lookup to |
||||
match the adjustment |
||||
* Add saturating 112, then F0 -> 113, F4 -> 117, all that were > 16 will |
||||
be more 128 and lookup in ef_fe_table will return 0 but for F0 |
||||
and F4 it will be 4 and 5 accordingly |
||||
*/ |
||||
/*
|
||||
* Then just check the appropriate ranges with greater/smaller equal |
||||
instructions. Check tail with a naive algorithm. |
||||
* To save from previous 16 byte checks we just align previous_first_len to |
||||
get correct continuations of the codepoints. |
||||
*/ |
||||
|
||||
/*
|
||||
* Map high nibble of "First Byte" to legal character length minus 1 |
||||
* 0x00 ~ 0xBF --> 0 |
||||
* 0xC0 ~ 0xDF --> 1 |
||||
* 0xE0 ~ 0xEF --> 2 |
||||
* 0xF0 ~ 0xFF --> 3 |
||||
*/ |
||||
const __m128i first_len_table = |
||||
_mm_setr_epi8(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 3); |
||||
|
||||
/* Map "First Byte" to 8-th item of range table (0xC2 ~ 0xF4) */ |
||||
const __m128i first_range_table = |
||||
_mm_setr_epi8(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 8, 8, 8, 8); |
||||
|
||||
/*
|
||||
* Range table, map range index to min and max values |
||||
*/ |
||||
const __m128i range_min_table = |
||||
_mm_setr_epi8(0x00, 0x80, 0x80, 0x80, 0xA0, 0x80, 0x90, 0x80, 0xC2, 0x7F, |
||||
0x7F, 0x7F, 0x7F, 0x7F, 0x7F, 0x7F); |
||||
|
||||
const __m128i range_max_table = |
||||
_mm_setr_epi8(0x7F, 0xBF, 0xBF, 0xBF, 0xBF, 0x9F, 0xBF, 0x8F, 0xF4, 0x80, |
||||
0x80, 0x80, 0x80, 0x80, 0x80, 0x80); |
||||
|
||||
/*
|
||||
* Tables for fast handling of four special First Bytes(E0,ED,F0,F4), after |
||||
* which the Second Byte are not 80~BF. It contains "range index adjustment". |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | First Byte | original range| range adjustment | adjusted range | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | E0 | 2 | 2 | 4 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | ED | 2 | 3 | 5 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F0 | 3 | 3 | 6 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
* | F4 | 4 | 4 | 8 | |
||||
* +------------+---------------+------------------+----------------+ |
||||
*/ |
||||
|
||||
/* df_ee_table[1] -> E0, df_ee_table[14] -> ED as ED - E0 = 13 */ |
||||
// The values represent the adjustment in the Range Index table for a correct
|
||||
// index.
|
||||
const __m128i df_ee_table = |
||||
_mm_setr_epi8(0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 0); |
||||
|
||||
/* ef_fe_table[1] -> F0, ef_fe_table[5] -> F4, F4 - F0 = 4 */ |
||||
// The values represent the adjustment in the Range Index table for a correct
|
||||
// index.
|
||||
const __m128i ef_fe_table = |
||||
_mm_setr_epi8(0, 3, 0, 0, 0, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0); |
||||
|
||||
__m128i prev_input = _mm_set1_epi8(0); |
||||
__m128i prev_first_len = _mm_set1_epi8(0); |
||||
__m128i error = _mm_set1_epi8(0); |
||||
while (end - data >= 16) { |
||||
const __m128i input = |
||||
_mm_loadu_si128(reinterpret_cast<const __m128i*>(data)); |
||||
|
||||
/* high_nibbles = input >> 4 */ |
||||
const __m128i high_nibbles = |
||||
_mm_and_si128(_mm_srli_epi16(input, 4), _mm_set1_epi8(0x0F)); |
||||
|
||||
/* first_len = legal character length minus 1 */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* first_len = first_len_table[high_nibbles] */ |
||||
__m128i first_len = _mm_shuffle_epi8(first_len_table, high_nibbles); |
||||
|
||||
/* First Byte: set range index to 8 for bytes within 0xC0 ~ 0xFF */ |
||||
/* range = first_range_table[high_nibbles] */ |
||||
__m128i range = _mm_shuffle_epi8(first_range_table, high_nibbles); |
||||
|
||||
/* Second Byte: set range index to first_len */ |
||||
/* 0 for 00~7F, 1 for C0~DF, 2 for E0~EF, 3 for F0~FF */ |
||||
/* range |= (first_len, prev_first_len) << 1 byte */ |
||||
range = _mm_or_si128(range, _mm_alignr_epi8(first_len, prev_first_len, 15)); |
||||
|
||||
/* Third Byte: set range index to saturate_sub(first_len, 1) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 1 for E0~EF, 2 for F0~FF */ |
||||
__m128i tmp1; |
||||
__m128i tmp2; |
||||
/* tmp1 = saturate_sub(first_len, 1) */ |
||||
tmp1 = _mm_subs_epu8(first_len, _mm_set1_epi8(1)); |
||||
/* tmp2 = saturate_sub(prev_first_len, 1) */ |
||||
tmp2 = _mm_subs_epu8(prev_first_len, _mm_set1_epi8(1)); |
||||
/* range |= (tmp1, tmp2) << 2 bytes */ |
||||
range = _mm_or_si128(range, _mm_alignr_epi8(tmp1, tmp2, 14)); |
||||
|
||||
/* Fourth Byte: set range index to saturate_sub(first_len, 2) */ |
||||
/* 0 for 00~7F, 0 for C0~DF, 0 for E0~EF, 1 for F0~FF */ |
||||
/* tmp1 = saturate_sub(first_len, 2) */ |
||||
tmp1 = _mm_subs_epu8(first_len, _mm_set1_epi8(2)); |
||||
/* tmp2 = saturate_sub(prev_first_len, 2) */ |
||||
tmp2 = _mm_subs_epu8(prev_first_len, _mm_set1_epi8(2)); |
||||
/* range |= (tmp1, tmp2) << 3 bytes */ |
||||
range = _mm_or_si128(range, _mm_alignr_epi8(tmp1, tmp2, 13)); |
||||
|
||||
/*
|
||||
* Now we have below range indices calculated |
||||
* Correct cases: |
||||
* - 8 for C0~FF |
||||
* - 3 for 1st byte after F0~FF |
||||
* - 2 for 1st byte after E0~EF or 2nd byte after F0~FF |
||||
* - 1 for 1st byte after C0~DF or 2nd byte after E0~EF or |
||||
* 3rd byte after F0~FF |
||||
* - 0 for others |
||||
* Error cases: |
||||
* >9 for non ascii First Byte overlapping |
||||
* E.g., F1 80 C2 90 --> 8 3 10 2, where 10 indicates error |
||||
*/ |
||||
|
||||
/* Adjust Second Byte range for special First Bytes(E0,ED,F0,F4) */ |
||||
/* Overlaps lead to index 9~15, which are illegal in range table */ |
||||
__m128i shift1; |
||||
__m128i pos; |
||||
__m128i range2; |
||||
/* shift1 = (input, prev_input) << 1 byte */ |
||||
shift1 = _mm_alignr_epi8(input, prev_input, 15); |
||||
pos = _mm_sub_epi8(shift1, _mm_set1_epi8(0xEF)); |
||||
/*
|
||||
* shift1: | EF F0 ... FE | FF 00 ... ... DE | DF E0 ... EE | |
||||
* pos: | 0 1 15 | 16 17 239| 240 241 255| |
||||
* pos-240: | 0 0 0 | 0 0 0 | 0 1 15 | |
||||
* pos+112: | 112 113 127| >= 128 | >= 128 | |
||||
*/ |
||||
tmp1 = _mm_subs_epu8(pos, _mm_set1_epi8(-16)); |
||||
range2 = _mm_shuffle_epi8(df_ee_table, tmp1); |
||||
tmp2 = _mm_adds_epu8(pos, _mm_set1_epi8(112)); |
||||
range2 = _mm_add_epi8(range2, _mm_shuffle_epi8(ef_fe_table, tmp2)); |
||||
|
||||
range = _mm_add_epi8(range, range2); |
||||
|
||||
/* Load min and max values per calculated range index */ |
||||
__m128i min_range = _mm_shuffle_epi8(range_min_table, range); |
||||
__m128i max_range = _mm_shuffle_epi8(range_max_table, range); |
||||
|
||||
/* Check value range */ |
||||
if (ReturnPosition) { |
||||
error = _mm_cmplt_epi8(input, min_range); |
||||
error = _mm_or_si128(error, _mm_cmpgt_epi8(input, max_range)); |
||||
/* 5% performance drop from this conditional branch */ |
||||
if (!_mm_testz_si128(error, error)) { |
||||
break; |
||||
} |
||||
} else { |
||||
error = _mm_or_si128(error, _mm_cmplt_epi8(input, min_range)); |
||||
error = _mm_or_si128(error, _mm_cmpgt_epi8(input, max_range)); |
||||
} |
||||
|
||||
prev_input = input; |
||||
prev_first_len = first_len; |
||||
|
||||
data += 16; |
||||
} |
||||
/* If we got to the end, we don't need to skip any bytes backwards */ |
||||
if (ReturnPosition && (data - (end - len)) == 0) { |
||||
return ValidUTF8Span<true>(data, end); |
||||
} |
||||
/* Find previous codepoint (not 80~BF) */ |
||||
data -= CodepointSkipBackwards(_mm_extract_epi32(prev_input, 3)); |
||||
if (ReturnPosition) { |
||||
return (data - (end - len)) + ValidUTF8Span<true>(data, end); |
||||
} |
||||
/* Test if there was any error */ |
||||
if (!_mm_testz_si128(error, error)) { |
||||
return 0; |
||||
} |
||||
/* Check the tail */ |
||||
return ValidUTF8Span<false>(data, end); |
||||
#endif |
||||
} |
||||
|
||||
} // namespace
|
||||
|
||||
bool IsStructurallyValid(absl::string_view str) { |
||||
return ValidUTF8</*ReturnPosition=*/false>(str.data(), str.size()); |
||||
} |
||||
|
||||
size_t SpanStructurallyValid(absl::string_view str) { |
||||
return ValidUTF8</*ReturnPosition=*/true>(str.data(), str.size()); |
||||
} |
||||
|
||||
} // namespace utf8_range
|
||||
@ -0,0 +1,23 @@ |
||||
// Copyright 2022 Google LLC
|
||||
//
|
||||
// Use of this source code is governed by an MIT-style
|
||||
// license that can be found in the LICENSE file or at
|
||||
// https://opensource.org/licenses/MIT.
|
||||
|
||||
#ifndef THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_ |
||||
#define THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_ |
||||
|
||||
#include "absl/strings/string_view.h" |
||||
|
||||
namespace utf8_range { |
||||
|
||||
// Returns true if the sequence of characters is a valid UTF-8 sequence.
|
||||
bool IsStructurallyValid(absl::string_view str); |
||||
|
||||
// Returns the length in bytes of the prefix of str that is all
|
||||
// structurally valid UTF-8.
|
||||
size_t SpanStructurallyValid(absl::string_view str); |
||||
|
||||
} // namespace utf8_range
|
||||
|
||||
#endif // THIRD_PARTY_UTF8_RANGE_UTF8_VALIDITY_H_
|
||||
@ -0,0 +1,76 @@ |
||||
#include "utf8_validity.h" |
||||
|
||||
#include "gtest/gtest.h" |
||||
#include "absl/strings/string_view.h" |
||||
|
||||
namespace utf8_range { |
||||
|
||||
TEST(Utf8Validity, SpanStructurallyValid) { |
||||
// Test simple good strings
|
||||
EXPECT_EQ(4, SpanStructurallyValid("abcd")); |
||||
EXPECT_EQ(4, SpanStructurallyValid(absl::string_view("a\0cd", 4))); // NULL
|
||||
EXPECT_EQ(4, SpanStructurallyValid("ab\xc2\x81")); // 2-byte
|
||||
EXPECT_EQ(4, SpanStructurallyValid("a\xe2\x81\x81")); // 3-byte
|
||||
EXPECT_EQ(4, SpanStructurallyValid("\xf2\x81\x81\x81")); // 4
|
||||
|
||||
// Test simple bad strings
|
||||
EXPECT_EQ(3, SpanStructurallyValid("abc\x80")); // bad char
|
||||
EXPECT_EQ(3, SpanStructurallyValid("abc\xc2")); // trunc 2
|
||||
EXPECT_EQ(2, SpanStructurallyValid("ab\xe2\x81")); // trunc 3
|
||||
EXPECT_EQ(1, SpanStructurallyValid("a\xf2\x81\x81")); // trunc 4
|
||||
EXPECT_EQ(2, SpanStructurallyValid("ab\xc0\x81")); // not 1
|
||||
EXPECT_EQ(1, SpanStructurallyValid("a\xe0\x81\x81")); // not 2
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xf0\x81\x81\x81")); // not 3
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xf4\xbf\xbf\xbf")); // big
|
||||
// surrogate min, max
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xED\xA0\x80")); // U+D800
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xED\xBF\xBF")); // U+DFFF
|
||||
|
||||
// non-shortest forms should all return false
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xc0\x80")); |
||||
EXPECT_EQ(0, SpanStructurallyValid("\xc1\xbf")); |
||||
EXPECT_EQ(0, SpanStructurallyValid("\xe0\x80\x80")); |
||||
EXPECT_EQ(0, SpanStructurallyValid("\xe0\x9f\xbf")); |
||||
EXPECT_EQ(0, SpanStructurallyValid("\xf0\x80\x80\x80")); |
||||
EXPECT_EQ(0, SpanStructurallyValid("\xf0\x83\xbf\xbf")); |
||||
|
||||
// This string unchecked caused GWS to crash 7/2006:
|
||||
// invalid sequence 0xc7 0xc8 0xcd 0xcb
|
||||
EXPECT_EQ(0, SpanStructurallyValid("\xc7\xc8\xcd\xcb")); |
||||
} |
||||
|
||||
TEST(Utf8Validity, IsStructurallyValid) { |
||||
// Test simple good strings
|
||||
EXPECT_TRUE(IsStructurallyValid("abcd")); |
||||
EXPECT_TRUE(IsStructurallyValid(absl::string_view("a\0cd", 4))); // NULL
|
||||
EXPECT_TRUE(IsStructurallyValid("ab\xc2\x81")); // 2-byte
|
||||
EXPECT_TRUE(IsStructurallyValid("a\xe2\x81\x81")); // 3-byte
|
||||
EXPECT_TRUE(IsStructurallyValid("\xf2\x81\x81\x81")); // 4
|
||||
|
||||
// Test simple bad strings
|
||||
EXPECT_FALSE(IsStructurallyValid("abc\x80")); // bad char
|
||||
EXPECT_FALSE(IsStructurallyValid("abc\xc2")); // trunc 2
|
||||
EXPECT_FALSE(IsStructurallyValid("ab\xe2\x81")); // trunc 3
|
||||
EXPECT_FALSE(IsStructurallyValid("a\xf2\x81\x81")); // trunc 4
|
||||
EXPECT_FALSE(IsStructurallyValid("ab\xc0\x81")); // not 1
|
||||
EXPECT_FALSE(IsStructurallyValid("a\xe0\x81\x81")); // not 2
|
||||
EXPECT_FALSE(IsStructurallyValid("\xf0\x81\x81\x81")); // not 3
|
||||
EXPECT_FALSE(IsStructurallyValid("\xf4\xbf\xbf\xbf")); // big
|
||||
// surrogate min, max
|
||||
EXPECT_FALSE(IsStructurallyValid("\xED\xA0\x80")); // U+D800
|
||||
EXPECT_FALSE(IsStructurallyValid("\xED\xBF\xBF")); // U+DFFF
|
||||
|
||||
// non-shortest forms should all return false
|
||||
EXPECT_FALSE(IsStructurallyValid("\xc0\x80")); |
||||
EXPECT_FALSE(IsStructurallyValid("\xc1\xbf")); |
||||
EXPECT_FALSE(IsStructurallyValid("\xe0\x80\x80")); |
||||
EXPECT_FALSE(IsStructurallyValid("\xe0\x9f\xbf")); |
||||
EXPECT_FALSE(IsStructurallyValid("\xf0\x80\x80\x80")); |
||||
EXPECT_FALSE(IsStructurallyValid("\xf0\x83\xbf\xbf")); |
||||
|
||||
// This string unchecked caused GWS to crash 7/2006:
|
||||
// invalid sequence 0xc7 0xc8 0xcd 0xcb
|
||||
EXPECT_FALSE(IsStructurallyValid("\xc7\xc8\xcd\xcb")); |
||||
} |
||||
|
||||
} // namespace utf8_range
|
||||
@ -0,0 +1,11 @@ |
||||
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive") |
||||
load("@bazel_tools//tools/build_defs/repo:utils.bzl", "maybe") |
||||
|
||||
def utf8_range_deps(): |
||||
maybe( |
||||
http_archive, |
||||
name = "com_google_absl", |
||||
url = "https://github.com/abseil/abseil-cpp/archive/8c0b94e793a66495e0b1f34a5eb26bd7dc672db0.zip", |
||||
strip_prefix = "abseil-cpp-8c0b94e793a66495e0b1f34a5eb26bd7dc672db0", |
||||
sha256 = "b9f490fae1c0d89a19073a081c3c588452461e5586e4ae31bc50a8f36339135e", |
||||
) |
||||
Loading…
Reference in new issue